
안녕하세요. 열 한번째 X-Review입니다. CVPR 2023 Paper list를 확인해보니 Small-Object Detection을 담은 논문은 발표되지 않아 아쉬워서, QueryDet에 이어 CVPR 2022의 Tiny-Object Detection과 관련된 논문 한 편을 읽었습니다. 우선 결론부터 말하자면, 해당 논문은 Tiny(Small)-Object Detection의 성능을 높이는 논문이 아니라, Object Detection을 위한 Interactive Annotation 방법을 소개합니다. 연구실 내 이미 Annotation 작업을 진행해보신 분들도 있으실텐데, 편한 마음으로 논문 한편 읽고 지나간다고 생각해주시면 좋을 것 같습니다. 의료 AI로 유명한 루닛의 한국인 분들이 작성하신 논문이네요. 시작하겠습니다.
Introduction
아마 해당 논문에서 다루는 태스크에 대해 저를 포함하여 익숙치 못하거나 처음 들어본 분들이 많으실 것이라 생각됩니다. 해당 논문에서 다루는 태스크의 큰 범주는 Annotation, 그 중 Interactive Annotation을 다루고 있습니다. Annotation 자체는 익숙해도 딥러닝에서의 Annotation 태스크는 많이들 다크 데이터 팀의 홍주영 연구원님과 황유진 연구원님이 다뤄주신 Active learning, Semi-supervised learning, Incremental learning, continual learning 등을 떠올릴 수 있을 것입니다. 해당 태스크들이 모두 그렇지는 않지만, 하나의 필요성과 아이디어에서 출발한 점이죠. 그 필요성과 아이디어는 다들 아시리라 생각합니다만, 아래의 예시를 통해 다시 짚어보겠습니다.
“분류를 수행하는 태스크에서, Supervised-learning 방법이 SotA인 것은 의심의 여지가 없습니다. 하지만, 데이터는 끊임없이 생성되고 있으나, 현대의 인공지능 모델은 여전히 이전의 데이터 (ImageNet은 무려 2009년에 소개된 데이터 셋으로, 10년이 훌쩍 넘었습니다)를 통해서만 학습하고 있습니다. 물론, 이 점이 잘못되었다고 말하는 것은 아닙니다. ImageNet은 데이터 셋 내 포함된 클래스의 전반적인 특성을 아우를 수 있을 만큼 방대하죠. 그러나 시간이 지나면서, 이전에 보지 못한 새로운 유형을 분류해야할 필요가 생겼다고 생각해봅시다. 예를 들면, 코로나 바이러스를 검출하는 태스크를 진행하고 싶으나 이전의 데이터 셋에서는 코로나 바이러스에 해당하는 사진과 그에 맞는 Annotation이 없을테니, 다른 방법론을 생각해야합니다. (Anomaly detection 등의 Unsupervised learning 기반 방법론이 대표적이라고 생각합니다).
이처럼 이전에 보지 못했던, 이외에도 현대로 오면서 수많은 데이터들이 생성되고 저장되어 데이터 셋을 구축하고 싶으나, 인공지능 학습을 위해서는 해당 이미지 내 Annotation을 통해 라벨을 부착하는 작업이 필요합니다. 하지만, 다들 많이 들어봤겠지만 Annotation 태스크는 “시간이 오래걸리고, 돈이 많이 든다. 작업자의 주관으로 인해 노이즈 데이터가 생성될 위험이 존재한다. 그만큼 작업자의 전문성 지식을 필요로 한다.”와 같은 단점들이 존재합니다. 그래서 사람들이 고민하고, 다음의 아이디어를 제안합니다. “딥러닝 모델과 Annotator (Annotation 주체자)가 Annotation 정보를 상호 교환하는 하는 방식은 어떨까? 바로 이 방법이, Interactive Annotation 입니다.
정보를 상호 교환한다는 말이, 쉽게 이해되셨을 수도 있으나 제게는 굉장히 모호한 개념이였습니다. 정보를 상호교환한다는 것은 모델 혹은 Annotator 그 누구든 상대가 모를만한 정보를 제공해야만 의의가 있을 것인데, 그 과정이 명확치 않았습니다. 마치 아, 그렇구나. 서로 정보를 주고 받는 것이구나 하고 끝낼 수도 있는 문장이지만, 해당 내용이 논문의 전반적인 태스크를 이해하는데에 필수적이니 아래의 동영상을 살펴보며 다시 설명하겠습니다.
영상은 첫 7초 정도만 보셔도 느낌이 오실 것 입니다. 영상의 시작부는 파란색 점이 찍힌 딸기 위 빨간색 테두리 (contour)를 통해 딸기를 분류하는 모습이 보입니다 (이 때 말하는 분류라 함은 클래스 분류도 포함하지만, Segmentation 한다는 의미입니다). 해당 테두리는 하나의 딸기만을 가리키지는 않고, 뒤의 딸기와 겹쳐져 하나로 분류된 것을 볼 수 있습니다. 이 때, 마우스로 뒷편의 딸기에 해당하는 위치에 빨간색 점을 찍으니, 앞편의 딸기 (목적으로 하는 대상)가 정확한 테두리를 가지게 되었습니다.
위 영상을 보니 해당 태스크에 대한 느낌이 오시나요? 모델이 예측한 객체의 테두리를 Annotator가 보고서 잘못 예측되었다고 판단된 객체들만 클릭 몇 번을 통해 인지시켜주니, 모델이 다시 정확히 예측하는 모습을 볼 수 있습니다. 바로 이 점이 Annotator와 모델이 정보를 상호교환한다는 측면입니다. 다양한 방법이 있겠지만 지금 영상에서 보이는 방법은 모델의 예측을 Annotator가 수정하고, 다시 모델이 재학습하는 것 처럼 보입니다. 해당 태스크에 대한 소개가 길었네요. 저도 처음 들어봤던 태스크여서, 영상을 보기 이전에는 궁금증이 꼬리를 물어 한 번에 이해하는 것이 어려웠습니다.
저자는 역시 Large-scale data와 그에 맞는 Annotation이 딥러닝의 성공에 필수적이라고 말합니다. 이를 다른 시점에서는 Supervised-learning의 성능을 이기기 어렵다고도 말할 수 있을까요? 여튼, 그러나 Annotation 작업은 노동 집약적이며 비용이 많이 든다는 단점이 존재합니다 (태스크마다 Annotation의 복잡도가 다르다고 하지만, 복잡한 이미지의 경우 이미지 당 6달러에 육박한다고도 하네요). 그 중에서도, Annotation이 굉장히 어렵다고 평가할 수 있는 작은 물체 (Tiny-object), 악천후, 현미경 촬영 영상 등은 Annotator가 선뜻 Annotation하기는 어려운 데이터들입니다. URP 때는 큰 이미지에서의 Bounding Box를 치는 Annotation이었음에도 불구하고, 순탄치만은 않았으니 더더욱 저자의 심정이 이해됩니다.
또한, 의료 영상과 같은 이미지들은 전문가의 지식이 아니고선 Annotation 하는 것이 사실상 불가능합니다. 앞선 예시에서 코로나 바이러스에 대해 말했는데, 코로나 바이러스의 생김새 등은 일반인들이 알아보기는 사실.. 며칠 간의 교육만으로는 불가능합니다. 따라서 저자는 이러한 의료 영상과 같은 특수 경우를 제외하고서 Annotation Cost가 높은 측면 중 하나인 작은 물체 (Tiny-object)의 관점에서 봤을 때, Annotation에 들이는 Cost와 Effort (이 때의 Cost는 비용 측면뿐만 아니라 노동력을 포함한다고 이해하는 것이 좋습니다)를 줄일 수 있다는 것은 곧 Annotation의 효율성이 높아진다는 의미와 동시에 새로운 Large-scale 데이터 셋의 구축이 가능하여 새로운 학습 데이터 및 모델의 성능 향상에 기여할 수 있을 것으로 보고 있습니다.
이를 함축한 문장이, Abstract의 다음의 두 문장입니다. “주어진 이미지 내의 수십-수백 개의 작은 물체에 대한 Annotating은 힘이 들고 어려운 일이지만, 다수의 CV 태스크에서 필요한 일이다. 이미지 내에는 다수 클래스의 객체들이 포함되어 있지만, 해당 이미지를 multi-class interactive annotation으로 설정한 연구는 좀처럼 이루어지지 않았다.” 이제 저자의 의도와 글의 전체적인 예상 흐름이 이해가 가시리라 생각됩니다. 굉장히 재미있는 태스크로 보입니다.
Related Work
이제 다시 몇몇 개념을 살펴보고 넘어가겠습니다. 이전의 Interactive segmentation (지금은 object detection 이지만, 이전에는 segmentation과 관련된 연구가 더욱 활발했던 것으로 보입니다)에선는 interaction의 수를 줄이는 것에 집중했습니다. 이 때 interaction이란 위 동영상의 딸기 예시처럼 객체 혹은 개체를 분리하고자 객체마다 찍은 파란 (빨간)점에 해당합니다. 즉 interaction의 수를 줄이는 것은 곧 Annotator가 Annotating할 일의 양을 줄이는 것과 같습니다. 이러한 접근법을 “many interaction to one instance”로 부릅니다. 아마 모델이 개체에 많은 점을 찍어놓는 것과 같은, 일종의 confidence score를 높이는 방법에 대한 연구들이 많았습니다. 반대되는 개념은 아니지만, 이후 이미지 내 다양한 객체들이 존재할 때 이들에 다른 색의 점을 찍음으로써 객체의 수를 세는 object counting 방법은 “many ineraction to many instance”로 불립니다.
하지만 이러한 접근법은 Annotator들이 하나의 객체에만 집중하게끔 만들어 놓치는 부분들이 몇몇 있을 수 있습니다. 예를 들어 이미지 내 동그라미와 네모가 다수 존재할 때, 동그라미에 대해 interactive bounding box generation을 수행하고 있다면, Annotator들은 interaction의 대상을 동그라미에 한정하게되는 편향 (one classes to one classes)이 있습니다. 그러므로 저자는 이전의 many-to-one 혹은 many-to-many가 아닌 새로운 “many classes to many classes”로 접근해야한다고 주장합니다. 아래의 표에 잘 정리되어 있습니다.

이러한 저자의 요구를 만족하고자, 저자는 C3Det이라는 Annotation 프레임워크를 제안합니다. 방법론에 들어가서는 C3Det을 구성하는 세 모듈 (LF, C3, UEL)에 대해 소개할 것이므로, 지금은 본 논문의 핵심 Contribution 및 작동 방식 (Interactive 방식)에 대해 알아보겠습니다.
Overview
이전 Introduction에서 해당 태스크에 대해 간략히 설명을 마쳤지만, 딥러닝 측면에서의 고찰도 존재합니다. 이를 Contribution과 함께 살펴보겠습니다. 우선 Annotation의 cost를 줄이고자 저자는 두 전략을 고안했습니다. 첫 번째는, Annotator가 입력으로 객체에 대한 Bounding box가 아닌 객체 내 점 (Point, Interaction)만을 받습니다. 해당 방식은 직관적으로 비용을 줄이는 데에 큰 기여를 할 것으로 보입니다. 두 번째는 Annotator가 선택하지 않은 부분들에 대해서도 선제적으로 검출하여 Annotation하는 부분으로, 이 때의 Annotator는 단순히 모델이 검출하지 못한 객체 혹은 잘못 검출했다고 판단된 객체에 대해서만 다시끔 Annotating을 진행하면 됩니다.
이제는 작동 과정에 대해 알아보도록 하겠습니다. 사실 아래의 Figure 1.만으로도 이해할 수 있습니다. 아래에서 살펴보겠습니다.
- 우선, Annotator가 몇몇의 객체들을 클릭하고 (객체 내 점을 찍음) 해당 객체의 클래스 정보를 제공합니다.
2. C3Det 모델은 해당 정보를 받아 Bounding box를 예측합니다. 이 때, 모델은 Annotator가 정보를 준 객체 뿐만 아니라 정보를 주지 않은 다른 객체들에 대해서도 Bounding box를 검출합니다.
3. Annotator는 모델의 출력을 확인한 다음, Annotation 되지 않은 객체들에 대해 다시 1.의 과정을 수행합니다.
4. 1-3의 과정을 반복하며 모든 객체가 Annotation이 마쳤다고 판단될 시, 해당 과정을 종료합니다.
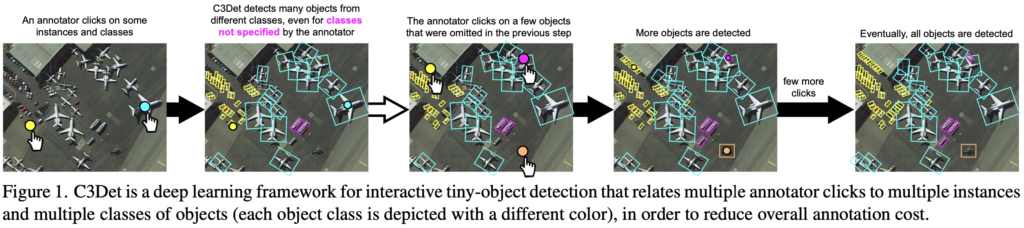
위의 1-4 과정을 담은 그림이 위의 Figure 1. 입니다. 해당 그림을 통해 더욱 자세히 이해할 수 있으며, 저자의 해당 접근 방식에 대한 주요 측면을 살펴보겠습니다. 우선, 2의 Annotator가 정보를 주지 않은 객체들에 대한 Bounding box를 검출하는 측면이 주요한 것으로 보입니다. 만약 Annotator가 객체 중심점에 점을 찍은 이후 정보를 주었다면, CNN 연산의 특징을 생각해봤을 때 근처 부위의 맥락 (Local context)에 대해서는 풍부하지만, 비교적 먼 위치의 동일 객체에 대해서는 그러지 못합니다. 그러므로 저자는 이러한 점을 극복하고자 C3 (Class-wise Collated Correlation) Module을 제안합니다. 해당 모듈은 방법론에서 다시 살펴보도록 하겠습니다.

위의 그림을 살펴보면, GT에 비해, Late-Fusion만을 사용하면 Interaction Point 위치 부근의 객체에 대해서는 잘 검출하지만, 비교적 멀리 떨어진 객체에 대해서는 모델이 다소 부정확히 예측합니다. 이러면 Annotator가 해야하는 일이 많아집니다. 또한 모델을 많이 신뢰하는 Annotator들이라면, 이럴때는 문제가 되겠죠.
원하는 바는 모델 예측과 Annotator의 정보가 일치하도록 유도하는 것이므로, 저자는 Annotator의 입력을 Heatmap으로 구성하여 모델 중간 단계에 삽입 (Late-Fusion)하였습니다. 이는 모델이 Annotator의 정보와 상호 교환하며 학습한다고 볼 수 있습니다. 하지만 제 견해에서는 이는 결국 모델이 Student로써 역할하여 Teacher인 Annotator로부터의 정보를 신뢰하는 방향으로 학습할 것이라고 생각합니다. 이러한 점을 신경쓴 것인지, 저자는 Annotator의 입력과 모델 예측 간의 클래스 균형을 위한 Loss를 사용합니다. 이러한 Late-Fusion의 문제점은 앞서 언급했으며 이를 극복하고자 앞서 언급한 C3 모듈을 통해 C3Det은 Local context 뿐만 아니라 Global Context 또한 효과적으로 학습할 수 있게 되었습니다.
그럼, 여태의 글을 통해 해당 태스크 (Interactive Multi-Class Annotation)와 본 논문의 Contribution, 전체 과정 및 흐름을 알아봤습니다. 그럼 본 논문의 방법론으로 언급된 C3, UEL 등은 어떤 것인지 살펴보도록 하겠습니다.
Method
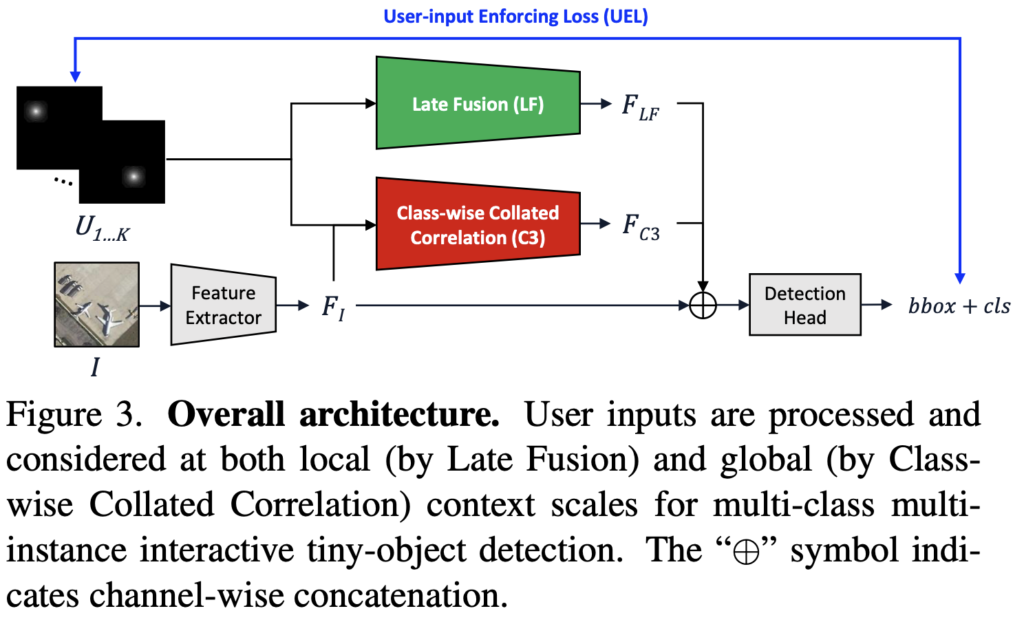
C3Det도 하나의 Convolution Network이므로, 전체적인 구조를 살펴본 후 네트워크 상의 LF, C3, UEL에 대해 이해하겠습니다. 사실 네트워크의 그림을 보면 심플한 구조를 갖고 있습니다. 그럼 전체적인 구조를 먼저 살펴보겠습니다. 수식의 노테이션에 집중하여 읽으면 이해에 도움이 되실 것입니다.
Network Architecture
저자가 고안한 C3Det은 Annotator의 입력 ( U )과 이미지 ( I )를 입력으로 받아, 최대한 많은 수의 Bounding box 및 클래스를 출력합니다. 위 Figure 3.의 네트워크 구조를 살펴보면, U_{1...K} 는 Annotator의 입력을 의미하며 이를 Heatmap으로 나타낸 모습입니다. Annotator의 입력을 \left (u^{pos}_k, u^{cls}_k \right) 로 나타내었을 때, u^{pos}_k 는 2D 위치 좌표, u^{cls}_k \in \{ 1 ... C \}는 객체의 클래스를 의미합니다. 해당 입력 형식의 2D 좌표는 Inference 시 Bounding box의 중심점을 따르도록 학습합니다. 이 때 2D 위치 좌표를 Bounding box로 착각할 수 있으나, User Input으로 Annotator가 이미지 내 마우스 클릭을 한 좌표 (X,Y)에 불과합니다. 아래의 이미지 I 는 Feature Extractor인 CNN을 통과하며 Feature map F_I 를 출력합니다.
이제 U_i 는 LF와 C3 (Class-wise-Collated Correlation) Module을 따로 통과하며, 각각 Local Context와 Global Context를 학습합니다. 이제 각 모듈을 통과한 F_{LF}, F_{C3} 를 이전에 구한 F_I 와 합친 (channel-wise concatenation) 후 다음의 레이어를 통과합니다. C3Det의 구조를 통해 알 수 있듯이, 백본 네트워크를 사소하게 변경한 네트워크이므로 1-Stage, 2-Stage에 개의치 않고 사용할 수 있습니다. 이제, Training Data Synthesis, LF, C3, UEL에 대해 하나씩 살펴보겠습니다.
Training Data Synthesis
합성 데이터 (Synthetic data)란, 실제 데이터의 분포를 토대로 생성한 데이터를 의미합니다. 학습 동안 Ground-Truth Annotation을 흉내내는 방식으로 Annotator의 입력을 정합니다. 균등 분포 (Uniform distribution) N_{\mathcal{U}} 는 \mathcal{U}_{[0, 20]} 을 따르며 임의의 Annotator Input 샘플을 뽑습니다. 임의의 샘플 수 K는 다음의 수식으로 결정되며, K = \min {\left (N_{\mathcal{U}, N_a} \right)} 이 때의 N_a 는 해당 이미지 내 object의 수를 의미합니다. 즉, 20개 혹은 그 보다 작은 수 (object가 20개 보다 작을 때)의 Annotation을 입력합니다. 이러한 작업을 하는 이유에 대한 사견으로는 Annotation 자체가 주관성이 강하여, 이에 대한 객관성을 최대한 가져보고자 진행하지 않았을까 생각됩니다.
Late Fusion Module (LF)
이전 Overview에서 Late Fusion (LF) Module에 대해 훑어봤었습니다. LF는 User Input (Annotation Input)을 네트워크에 포함하는 목적으로, 그 방식은 히트맵 형식으로 표현되며 이는 네트워크가 Local Context를 학습할 수 있도록 돕습니다. 이전 Interactive segmentation 태스크에서도 해당 접근 방식이 다수 존재하였고, 대표적으로 Early Fusion (EF)과 Late Fusion (LF)가 존재합니다. EF는 User-input을 Heatmap 으로 표현한 다음 Input Image인 I 와 결합하여 사용합니다. 반면, LF는 네트워크의 중간 단 레이어에서 결합하는 방식으로, 이전 연구들에서 LF 방식의 성능이 EF에 비해 높은 측면을 고려하여, LF를 택했다고 합니다. 물론 이를 실험에서도 증명하고 있습니다.
그렇다면 이번에는, Heatmap으로 표현하는 방식에 대해 짚고 넘어가야겠네요. 저자는 User input에서 주어진 클래스 정보를 유지하면서 다양한 User input을 다루고자, User input Heatmap을 클래스 별로 묶은 K개를 생성합니다. 이러면 한 묶음 해당 클래스 정보를 유지한 채로 User input 정보를 포함하고 있습니다. 만약 object의 클래스에 대한 Input이 없다면 (Annotating하지 않았거나, 혹은 이미지 내 object가 없는 상황), Heatmap을 0으로 채웁니다. 해당 Heatmap을 통해 모델은 이미지 내 객체가 없음을 단번에 알 수 있겠죠.
추가적으로, 저자는 LF 모듈을 통과한 Heatmap이 Spatial information을 잃는 것을 방지하고자 어느 Global Pooling, Global Average Pooling 등을 하지 않았다고 합니다. 아마 Global Pooling 없이 Padding을 통해 CNN 연산 이후의 Resolution을 유지한 채 Output을 내뱉어 추후 F_{C3}와 F_I 와 결합 시 Spatial information을 강조하는 목적이 아니었을까 생각합니다. LF 모듈은 결과적으로 User input에 직접적으로 반응하여 지역적인 object를 보고 있습니다. (즉, User input 2D position인 u^{pos}_k 에 해당하는 object에, User input class information인 u^{cls}_k 를 할당합니다)
Class-wise Collated Correlation Module (C3)
Late Fusion (LF)을 통해 네트워크가 Local Context 정보를 학습했다면, User Input으로부터 멀리 떨어진 object들에 대해서도 임팩트 줄 수 있는 방법이 필요합니다. 이전 Related Work에서 object counting 태스크에 대해 잠시 소개했는데, 단어 그대로 객체의 수를 세는 태스크입니다. 이런 태스크의 성능 향상을 위해 최근, F_I 와 User input Feature 간 (예를 들어 Heatmap 나 F_{LF} 또한 User input으로 부터의 Feature입니다)의 Correlation 연산 (유사도 계산)을 하는 방법이 추세라고 합니다. 해당 유사도를 통해 Few example (User input)으로부터 더 많은 양의, 비슷한 object의 수를 세는 데에 도움이 됩니다.
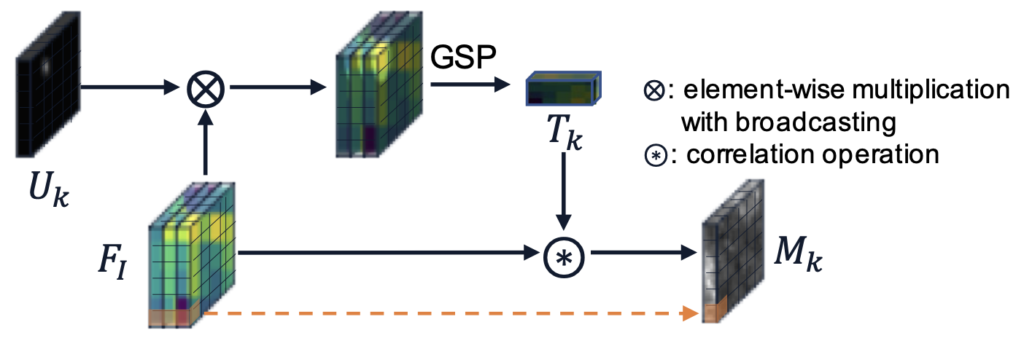
바로 해당 아이디어를 들고와, C3 모듈을 생성합니다. 해당 모듈에서는 F_I 로부터 User input을 기반으로 일종의 Template Feature를 뽑는 것을 목표로 합니다.
- 이는 U_k 와 F_I 간의 Correlation 연산으로 구성되며, 이 때의 Correlation 연산은 Element-wise multiplication with broadcasting 입니다.
- Correlation 연산 이후, GSP (Global Sum Pooling)을 통해 Template Vector T_K 를 만듭니다.
- 해당 Template Vector T_K 를 다시 F_I 와 Correlation 연산을 수행합니다. 이 때의 Correlation 연산은 Element-wise max operation입니다.
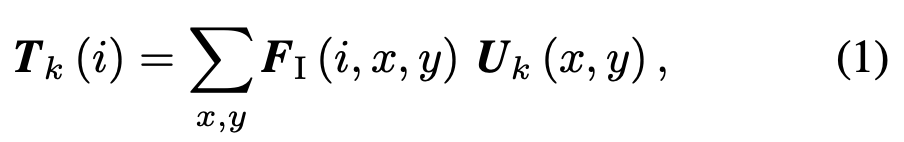
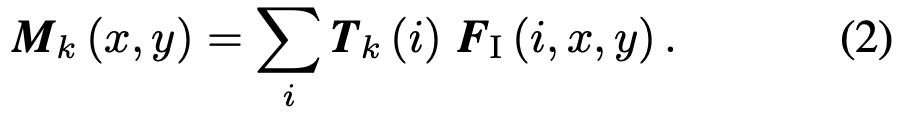
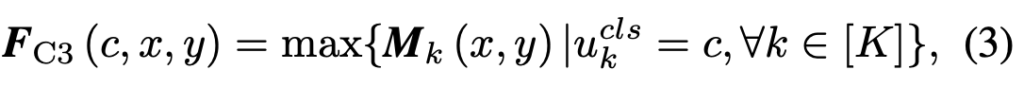
바로 직전 (2)의 부분을 통해 (3)의 F_{C3} 를 얻습니다. 저자는 해당 작업을 Correlation 이후 하나의의 F_{C3}로 Collate하는 순서를 따라 Class-wise Collated Correlation Module, C3로 명합니다 물론, 해당 순서의 반대인 Collated-and-Correlation에 대해서도 확인해봤으며, 이는 User input에 강인한 측면이 있으나 각 object들이 연관되지 않은 single feature representation을 갖는다고 합니다. 그쵸. 아마 생각해보면, Correlation 연산이 Collate 이전에 있는지, 이후에 있는지에 따라 object의 feature representation 방향이 바뀌는 것으로 이해할 수 있습니다.
저자는 Correlation 연산이 Collate 이전에 있는, 현재의 Collated-and-Correlation (C3) 모듈이 더 좋은 성능을 보였으며, 해당 모듈을 통해 User input 뿐만 아닌 Image Feature와의 Correlation을 통해 네트워크가 Global Context를 학습할 수 있다고 봅니다. Tiny-object 관점에서 해당 object가 Image-level에서의의 Context를 갖고자한다면, 해당 방식을 사용하는 것도 유의미할 수 있겠다는 생각이 듭니다. 아래의 그림을 통해, 이해도를 높일 수 있습니다
User-input Enforcing Loss (UEL)
이제, 마지막 Method입니다. User-input Enforcing Loss (UEL)은 User가 object에 대해 특정 클래스로 명하면, C3Det이 예측 결과에 이를 반영하기 위한 Loss입니다. 그렇기에 개념이 단순하죠. 해당 Loss를 통해 User (Annotator)와 Model이 정보를 상호교환하고 있음을 알 수 있습니다. 일전에 우리가 Training-time consistency loss에 대해 설명드리며, User input과 Model prediction 간의 균형을 맞추기 위해 고안되었다고 설명드렸는데, UEL은 클래스와 관련되어, 유저가 특정 클래스를 명명한 결과에 따라 클래스별 균형을 이루는 효과를 가져옵니다. User input을 \left (u^{pos}_k, u^{cls}_k \right) 이라고 할 때, 해당 input과 연관된 ground-truth bounding box인 y^{bbox}_k 를 찾을 수 있습니다. 이는 모든 ground-truth object를 모든 예측 객체 J와 비교하는 방법으로, 각 예측은 당연히 bounding box와 class로 구성됩니다. 해당 방식으로 loss를 구성하며 IoU를 통해 non-zero를 확인한 다음, 해당 클래스에 대해 class-consistency loss를 적용합니다. 아래의 수식을 통해 이해할 수 있습니다.
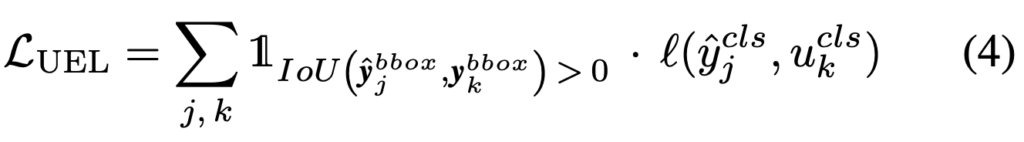
Experimental Results
대망의 실험입니다. 본 논문을 실험이 꽤나 많으며, 이를 모두 담는 것은 다소 무리가 있기에 중요하다고 생각되는 부분, 이를테면 데이터 셋 및 Ablation study, Baseline과의 결과 등을 담아보겠습니다. 사실 담다보면.. 모든 내용을 다 쓸 수도 있겠네요.
Datasets
저자가 실험을 위해 사용한 데이터 셋은, Tiny-DOTA 및 LCell 입니다. 두 데이터 셋은 Tiny-Object를 다량 포함하고 있으며, 특히 LCell 데이터 셋은 세포 사진으로, 한 이미지 내 object의 수가 굉장히 많이 존재합니다. 아래 그림을 통해 해당 데이터 셋의 사진을 확인할 수 있습니다. 하나 알아두어야할 점으로, 저자는 실험을 위해 Larger-Object를 포함하지 않은 이미지만을 사용했으며, Tiny-DOTA 데이터 셋의 경우 Test 데이터에 대한 GT 정보를 공적으로 제공하지 않아 Train 데이터에서 Train / Valid / Test를 나누어 사용한다고 밝힙니다.


Evaluation Procedure
처음보는 태스크다보니 평가 방법이 궁금했을텐데, 저자는 해당 태스크의 공공연한 평가 척도가 없기에 평가는 쉽지 않은 주제라고 언급합니다. 하나의 방법으로 해당 Method의 평가를 위해 Annotator를 초대하는 방법도 존재하지만, 한 두명으로는 안되겠죠. 수 많은 Annotator들이 방법을 수정할 때 마다 매번 평가하는 것은 불가능하며, 때로는 주관적일 수 있습니다. 그러므로 저자는 평가를 위해 Interactive Segmentation 태스크의 예시를 토대로, Detection 태스크다보니 Annotator (User)가 마우스 클릭을 할 때마다의 mAP를 측정합니다.
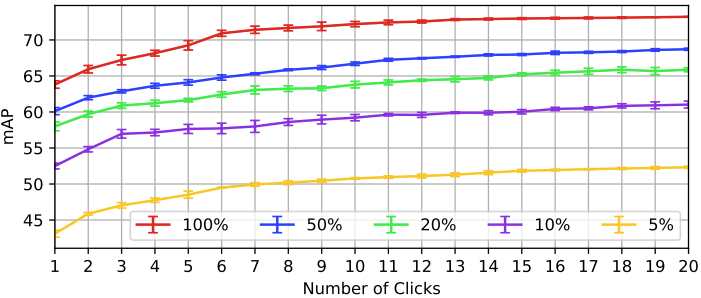
이는 곧 Annotator가 이미지 내 한 번 클릭을 하는지, 두 번 클릭을 하는지에 따라 모델이 출력을 뱉는 수준이 다를테며, 그러니 Detection 모델에서 mAP가 달라지겠죠. 마우스 클릭 수를 1 – 20으로 늘리며 평가했을 때, 1-Stage (Faster-RCNN w/ R50-FPN)와 2-stage (RetinaNet w/ R50)에서 유의미한 성능 향상을 보입니다. Interactive한 특성 상 또한 학습 데이터가 많을 수록 성능이 늘어나는 특성 상, 클릭 수가 늘어나면 성능이 높아지는 것은 당연한 일이지만, 다른 방법론과 비교하면 굉장히 높은 수치로 늘어남을 알 수 있습니다.
아래의 표를 확인하면, Faster-RCNN은 None-Interactive Annotation으로, 마우스 클릭 수에 상관 없이 일정한 성능을 보일 것이라는 것을 한 번에 알 수 있습니다. 다른 방법론들을 훑어보면, User input을 Heatmap으로 변환하여 F_I 와 Concat하는 부분이 입력단인지, (현재는 Half-way 구조입니다) Feature Extractor를 통과한 뒷 부분인지에 따라 Eary Fusion과 Late-Fusion으로 나뉩니다. 두 방법론은 Interactive Segmentation에서 종종 쓰이는 방법론으로, 저자는 해당 방법론을 고안한 방법론에 가져오고자 입력단에서 둘을 합한 다음 Late Fusion의 경우 C3 Module과 UEL Loss를 제거하는 방식을 취합니다. PassThrough는 Interactive 방법론이라기보다는, User input만을 사용한 방법론으로, 성능 향상이 유의미하진 않네요.
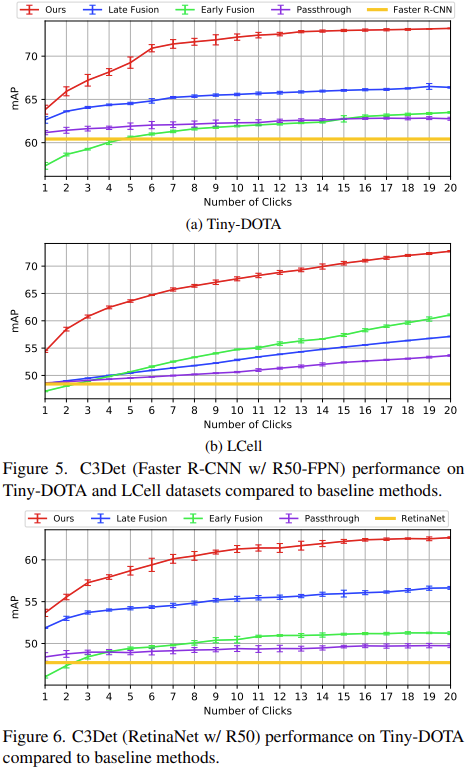
위 실험에서 특이한 점으로 Early-Fusion의 경우 시작 부분 (1-3)에서의 성능이 None-Interactive 방법론보다도 낮은 모습을 보입니다. 이 점에 대한 추측으로는 C3Det은 User input이 모델을 통과하기 전 \left (u^{pos}_k, u^{cls}_k \right) 를 Heatmap으로 변환할 때, u^{pos}_k 를 사전에 정의한 표준편차인 \sigma_{heatmap} 을 통해 2D Gaussian 중심으로 배치하는데, Early Fusion에서는 Heatmap을 그릴 때 User input과 Image를 Concat한 전체에 Heatmap, 즉 Heatmap의 크기가 커지기에 작아지는 Gaussian 인해 u^{pos}_k 에 덜 영향을 줄 것이고, 이 정보가 뒷단의 레이어로 가면 정보를 점차 잃게 되기 때문으로 보입니다.
다음으로는 Training data의 수를 줄였을 때, Interactive Annotation만으로 유의미한 성능을 낼 수 있는지에 대한 분석입니다. 해당 실험은 Tiny-DOTA 데이터 셋에서 이루어졌으며, 해당 실험을 알아보기 위해 하나 짚고 넘어가겠습니다. 윗 부분에서 Tiny-DOTA 데이터 셋을 Train / Valid / Test (70% / 10% / 20%)로 분리했다고 언급했는데, 해당 실험은 Training data를 100%에서 5%만 사용하여 C3Det을 학습한 다음의 성능입니다. Training data의 Annotation 수를 100%에서 5%로 줄여나간 것은 아닙니다.
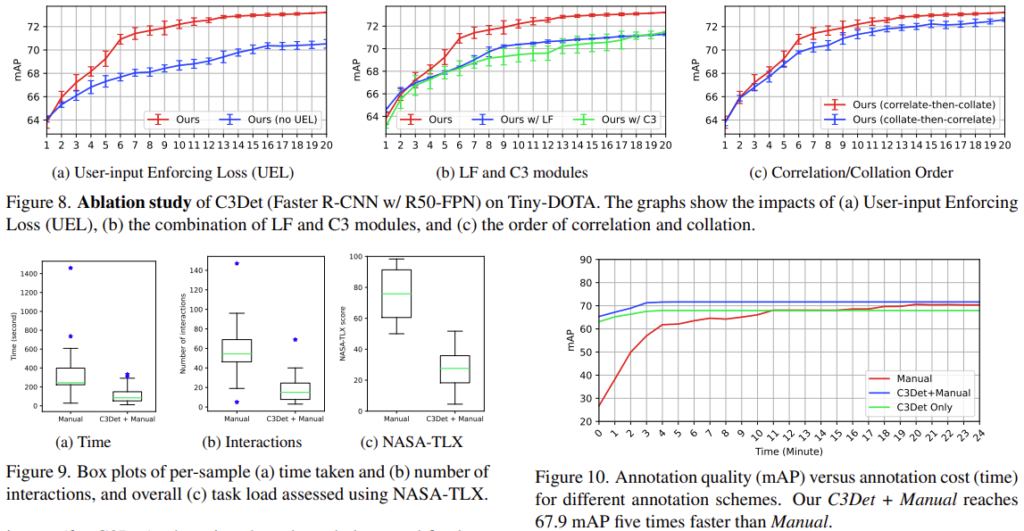
마지막으로는 다양한 Ablation Study입니다. (결국 모든 실험을 다 들고오게 되었네요) 해당 실험은 저자가 제안한 세 모듈을 추가했을 때의 실험이며, 추가적으로 Annotation time과 Annotation Manual (NASA-TLX)을 따른 방법을 적용했을 때의 Time, Interaction입니다. 간단히 살펴보고만 넘어가면 될 것 같습니다.
Small (Tiny) Object Detection 방법론과 관련된 논문으로 착각하여 읽게 되었지만, 나름 유용하고 재밌는 논문으로 보입니다. 또한, CVPR 급의 논문은 해당 방법론과 그 실험 결과에 대한 의문증이 들 때마다 고찰을 담은 글로 해결해나가는 느낌이 들어 글쓰기 방식을 배울 수도 있는 논문이였네요. (한국인 저자라 잘 읽힌 것 같기도 합니다)
이상으로 리뷰 마치겠습니다.
안녕하세요, 좋은 리뷰 감사합니다.
tiny object에 대한 annotation을 위한 방법에 대한 논문이라 인상적입니다.
1. 해당 논문에서 다루는 Late Fusion Module과 C3 Module은 결국 각각에 대한 출력이 둘 다 heatmap인가요?
C3 Module의 출력이 무엇인지 궁금합니다.
2. indicate channel-wise concatenate 하기전에 F_LF와 F_C3에 대한 Element-wise multiplication with broadcasting 을 수행한 것으로 이해하는 게 맞을까요?
감사합니다.
안녕하세요. 좋은 질문 감사합니다.
1. 해당 논문에서 다루는 Late Fusion Module과 C3 Module의 출력에 대해 궁금증이 있으신데, Heatmap이라 함은 결국 하나의 Feature map과 동일합니다.
영상 혹은 Feature map에서 중요시되는 부분을 표현하는 방법이니, 정확히는 Heatmap이 아닌 Feature map으로 이해하심이 좋습니다.
2. Indicate channel-wise Concatenate는 Heatmap인 U_I와 F_I 사이에서 수행됩니다. 그림을 보면 오해가 있을 수 있지만, F_LF와 직접적으로 일어난다고 보기는 어렵습니다.