Introduction
일반적으로 Neural Network의 크기가 커질수록 모델의 정확도는 상승합니다. 그러나 모델의 크기가 증가하면 그에 따른 메모리 사용량 그리고 연산량도 같이 증가하게 됩니다 본 논문에서는 모델을 학습시킬 때 정확도는 좀 덜 손실시키면서 메모리 사용량을 줄이고 연산 속도를 빠르게 해주는 Mixed Precision Training 이라는 기법을 제안하였습니다
딥러닝에서는 일반적으로 fp32 데이터 타입을 사용하는데 이를 fp16로 변경한 후 학습을 진행하면 메모리를 적게 사용하며 더 빠른 학습이 가능합니다. 그러나 수를 표현하는 비트 수를 줄였기 때문에 정확도 손실이 발생하게 됩니다. 논문의 저자들은 세 가지 기법을 제안하여 이러한 정확도 손실을 최소화하고 fp32와 fp16간의 성능 차를 줄임으로써 다양한 task에서 보다 적은 크기의 네트워크를 활용할 수 있음을 보였습니다. 또한 별도의 하이퍼 파라미터가 존재하지 않고 학습을 시켰을 때 최종 모델의 정확도가 fp32와 비교해도 큰 차이가 없었다고 합니다.
Mixed Precision Training
Mixed Precision Training은 우리가 딥러닝 학습에 사용하는 32-bit의 부동 소수점 단위 대신, 그 절반인 16-bit의 부동 소수점 단위를 학습에 사용하는 방법론입니다. 이를 통해 연산 속도의 상승과 메모리 절약을 이룰 수 있습니다.
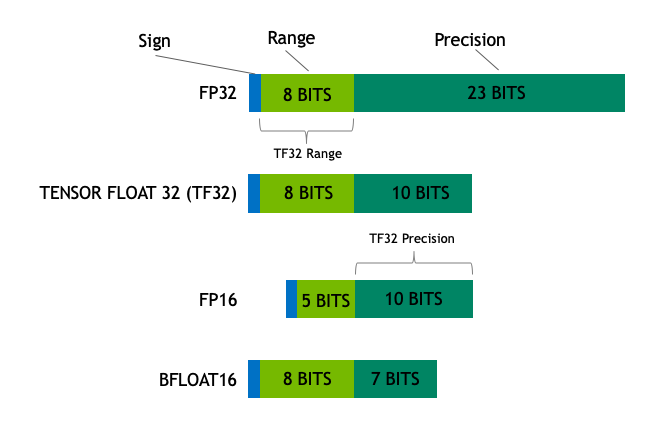
FP란 floating point로 하나의 수를 표현하는 데 어느 정도의 메모리를 사용하는 지를 나타냅니다.
일반적으로 모델의 학습에는 FP32를 사용하며, 이는 하나의 gradient, weight등을 나타내는 데 32비트의 메모리가 필요하다는 것을 의미합니다.
FP32의 정밀도로 표현되던 수가 FP16의 정밀도로 바뀌면 거의 절반에 가까운 표현력의 저하가 발생하며 이로 인해 원활한 학습이 진행되지 않을 수 있습니다. 그러나 이 논문에서는 single-precision master weights, loss-scaling, FP16 product를 FP32에 더해주는 방식을 사용하여 FP16의 정밀도를 학습 도중에 사용해도 기존 FP32의 모델 정확도와 비슷한 성능을 도출할 수 있다는 것을 보였습니다.
FP32 Master Copy of Weights
Mixed Precision Training에서, weights, activations, gradients는 FP16으로 저장됩니다. 이때, FP32의 정확도를 확보하기 위해 저자들은 Master Weight를 사용하였습니다. 이 Master Weight는 FP32로, 실제 forward, backward연산에서는 Master Weight를 FP16으로 copy하여 사용하고, 계산된 FP16의 weight gradient로 Master Gradient를 update합니다. 이 과정을 아래의 그림으로 나타낼 수 있습니다
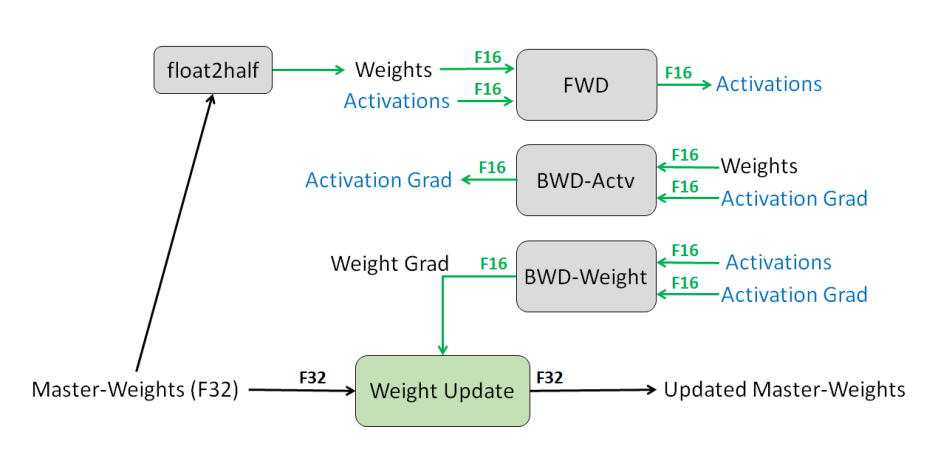
이 방법론에서 특징적인 부분은 실제 연산은 FP16으로 진행하는 것에 비해 모델의 가중치는 FP32인 점입니다. 위 그림을 보면 굳이 FP32인 가중치를 계속 유지하고 있어야 하는 지 의문이 생길 수 있습니다. FP32 Master Weight가 필요한 이유는 weight gradient에 learning rate를 곱하면 값이 매우 작아져 FP16의 표현 범위를 넘어가기 때문입니다. [그림3(b)]은 저자의 실험 중 ‘mandarin speech recognition’을 FP32로 학습시켰을 때 training gradient의 분포를 나타낸 것입니다. 이 중 2^{-24}이하의 값이 FP16으로 변환했을 때 0이 됩니다.
따라서 이러한 gradient update를 제대로 수행하기 위해 네트워크의 실제 weights를 FP32 데이터 타입으로 저장하고, FP32 연산으로 weight update를 진행합니다. 그러나 forward와 backward는 FP16 연산자를 사용하므로, FP32 master weights를 FP16 weights 변환하여 저장해놓아야 하는 단점이 있습니다. 이때 weight에 의해 50%의 추가적인 메모리 공간을 차지하게 되지만, 학습에서 weights의 크기보다 activation이 훨씬 크기에 전체 메모리 사용량은 대략적으로 50%정도라고 합니다.
Loss Scaling
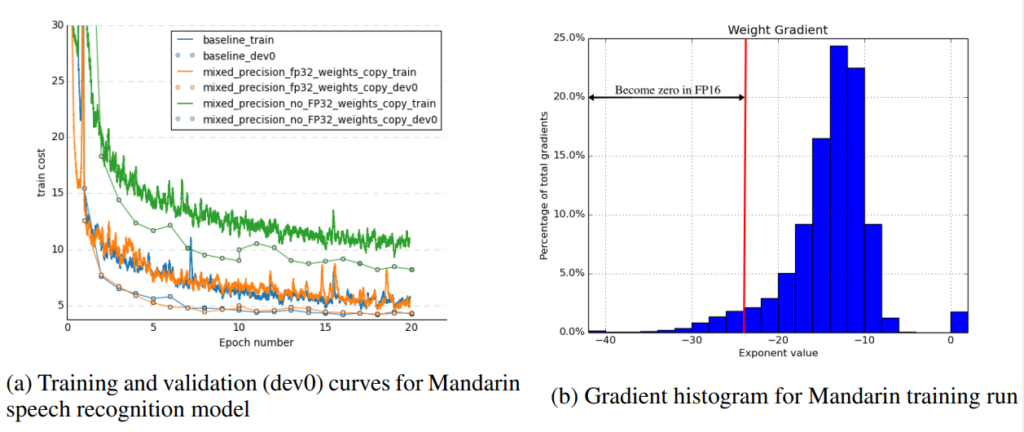
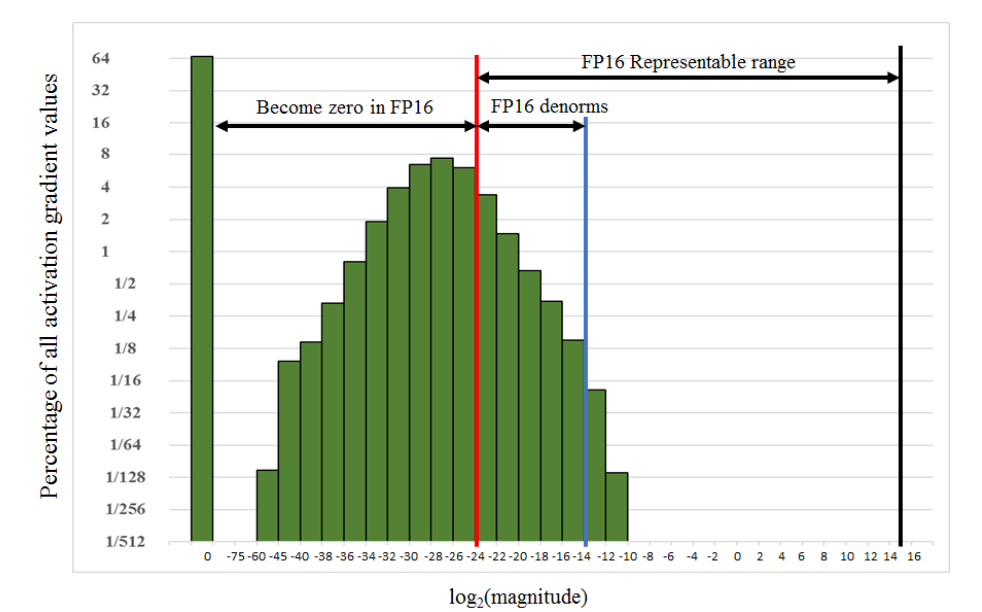
위에서 언급한 바와 같이 FP16은 많은 수의 gradient가 0으로 표현되는 문제가 발생합니다. [그림3(b)]와 [그림4]의 히스토그램 중 “Become zero in FP16″에 속한 값들은 FP16을 사용했을 때 0이 됩니다.
Loss Scaling은 이러한 문제를 해결하기 위해 gradient를 [그림4]의 “FP16 Representable range”에 들어가도록 right shift 시키는 기법입니다.
방법은 단순하게 Loss에 큰 값 α를 곱하는 것인데, Backpropagation 과정에서 loss에 곱해진 scalar α의 값만큼 모든 gradient value에 똑같은 크기 α만큼 곱해진 결과를 도출합니다. 이는 [그림 4]의 히스토그램을 오른쪽으로 log_2(α)만큼 shift만 결과와 같습니다. 따라서 적당한 α값을 선택하여 loss를 scaling하면 모든 gradient를 FP16으로 표현할 수 있습니다. 실제 weight update시에는 gradient를 FP32로 변환한 후 α으로 나눠준 값을 이용해 update합니다.
이때 α값은 실험적으로 정해지며 maximum gradient가 FP16으로 나타낼 수 있는 최대값인 65,054보다 작아지는 범위에서 선정하였습니다.
Experiments
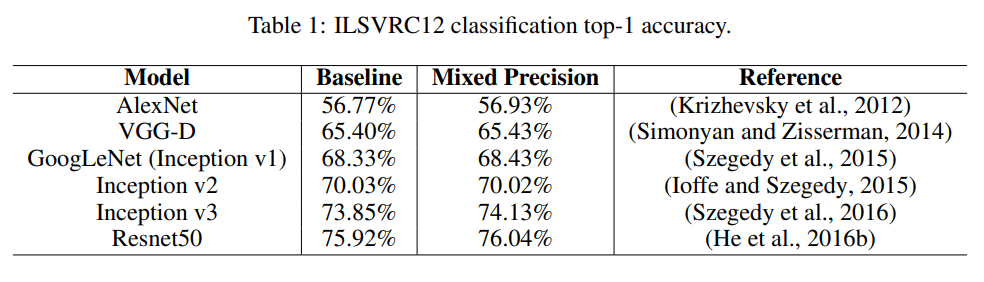
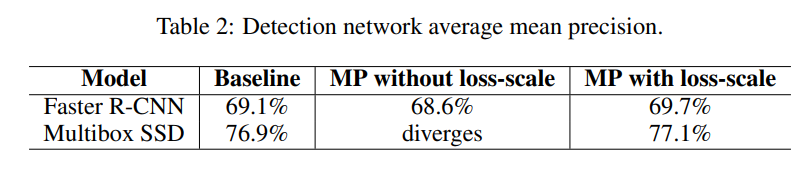
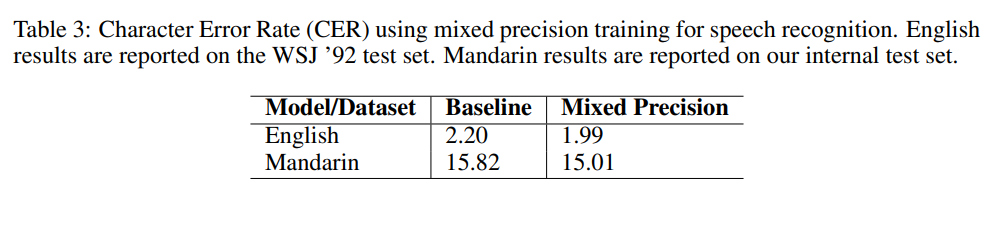
실험 부분에서는 Baseline과 Mixed Precicion의 결과를 비교하고 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
loss scaling문제를 해결하기 위해 loss에 큰 값 α를 곱함으로써 fp15에서 gradient가 0으로 표현되는 문제를 해결할 수 있다고 하셨는데, 실험 부분에서 α는 각 모델마다 다르게 설정되어 진행된 것인지 궁금합니다. α를 설정하는 기준이 논문에 언급되어 있나요 ?
또, fp32 데이터 타입 대신 fp16으로 변경해서 사용하면 메모리 사용량이 얼마나 줄었는지, 연산 속도는 몇 배 더 빨라지는지 궁금합니다.
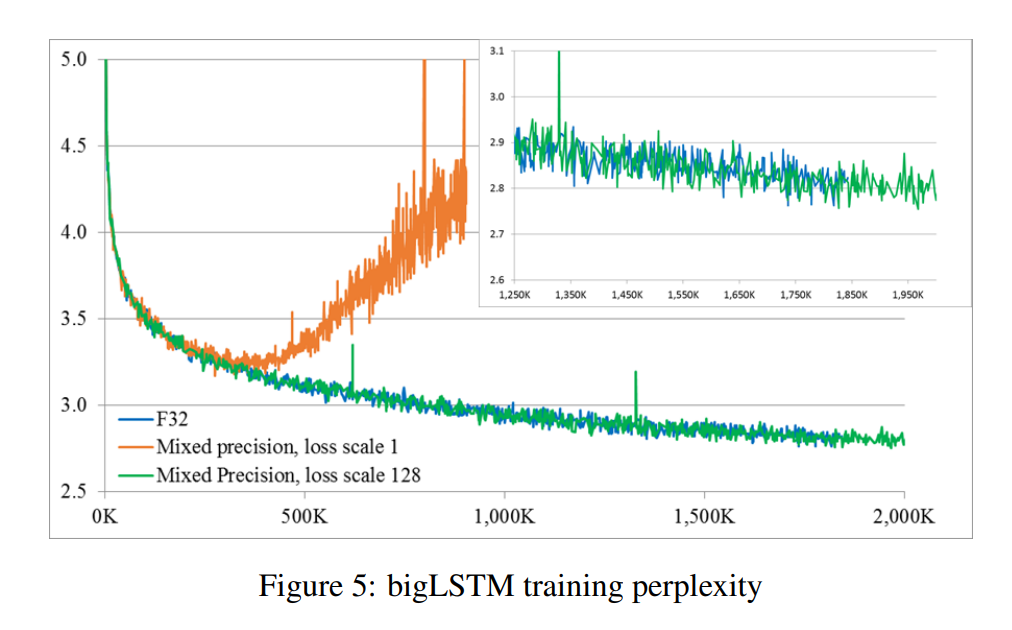
실험 파트에서 마지막 그림은 무엇을 의미하는 것인가요 ? loss scaling을 하지 않게 되면 학습이 발산한다는 것을 보여주기 위한 것일까요 ?
감사합니다 ! !
– 논문에서는 α값을 경험적으로 설정하였다고 언급하였으며 각 실험에 따라 다른 값을 사용하였습니다. 예로 Image Classification에서는 1로 설정하여 별도의 scaling 을 진행하지 않았으며 object detection은 8, speech recognition은 128을 사용했습니다. 논문에서는 언급되지 않았으나 nvidia의 공식 문서에는 큰 값의 scale factor 설정 후 학습 도중 nan값의 발생 여부나 gradient 분포에 따라 적절한 값을 튜닝한다고 되어 있습니다.
– 네 맞습니다. 실험 파트에서 마지막 그림은 loss scale여부에 따른 training loss를 비교한 그래프로 scaling factor가 1, 즉, 별도의 scaling을 진행하지 않은 경우에는 gradient 소실로 인해 발산합니다. 반면에 loss scaling을 적용하게 되면 low precision으로도 FP32와 비슷한 양상으로 학습이 진행됨을 의미합니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
논문에서 제안하는 Mixed Precision Training의 장점은 데이터 타입을 fp32에서 fp16으로 변경하였음에도 불구하고 두 모델의 정확도에 있어서 큰 차이가 없고 메모리를 적게 사용하기 때문에 더 빠른 학습이 가능하다는 점이라고 생각을 합니다. 그런데 실험을 보면 Baseline과 Mixed Pricisiond의 accuracy와 precision에 대한 성능 결과만 리포팅 되어 있네요 학습 속도에 대한 실험은 혹시 없었나요 ?
또한 classification과 detection에서의 성능은 fp32일 때와 유사하게 도출이 되는 것을 확인할 수 있었습니다. 그런데 마지막 실험은 결과가 어떤 것을 말하고자 하는지 제가 NLP 실험 결과를 분석해본 적이 없어서 혹시 추가적인 설명해주시면 감사하겠습니다 !
네. 아쉽게도 논문에는 speed에 관한 리포팅은 없습니다. Table 3의 경우에는 그림5는 언어 모델인 bigLSTM의 training loss를 나타냅니다. task자체보다는 해당 실험은 loss scale의 유무에 따른 수렴 여부를 비교하기 위해 리포팅된 것이니 가볍게 보고 넘어가셔도 좋을 것 같습니다.
안녕하세요. 리뷰 잘 읽었습니다.
저도 해당 논문을 한전 발표 자료 준비하고자 힐끗 읽어본 적이 있는데, 전체 논문은 다 읽지 못하였으나 리뷰를 통해 읽게 되었습니다.
논문의 Crucial한 Contribution으로는 FP32를 FP16으로 변경하여 Memory Used와 Inference time 측면의 향상이라고 볼 수 있겠는데, 저는 해당 논문을 읽으며 FP32를 FP16으로 변경했을 때의 현저한 표현력 저하에 대한 의문점이 들었습니다. 딥러닝에서는 Floating Point의 측면에서 중요할 수는 있으나, 네트워크의 크기 등에 따라 성능 저하량 및 경량화의 Trade-off 관계가 과연 뚜렷한지에 대한 의문이 듭니다. 논문을 읽었을 때는 괴리감없이 당연히 ‘FP16으로 바꾸면 성능은 떨어져도 연산 속도가 빨라지겠지’하는 생각이 들겠지만, 해당 측면에서의 스스로의 고찰을 말씀해주시면 감사하겠습니다.
또한 사실 수치해석을 공부한지 꽤 되어.. 부동소수점에 대한 이해가 부족한 상황에서 본 리뷰를 읽으니 어려운 감이 있는 것 같습니다. 부동소수점 연산과 딥러닝에서의 부동소수점 (Floating Point)의 측면을 고려하여 부가 설명해주신다면 감사합니다.