안녕하세요. 어느덧 연구실에 들어온지 2개월이 지나 x-review를 쓰게 되었네요 .. 이참에 attention에 대해 제대로 공부해보고 싶어서 attention과 관련된 논문으로 첫번째 x-review를 쓰게 되었습니다. 그럼 리뷰 시작하겠습니다.
1. Introduction
CNN이 컴퓨터 비전 분야에서 대표적인 mechanism으로 자리잡을 수 있었던 이유는 1) 일정한 크기의 kernel을 사용한 sliding 방식으로 receptive field를 제한하여 locality를 가지고 2)weight sharing을 통해 translation equivariance 특성을 보장할 수 있다는 것 입니다. 그러나 CNN에서 kernel의 지역적인 성질은 이미지의 global한 특징을 놓칠 수 있다는 단점이 존재합니다.
반대로 self-attention은 method 파트에서 더 자세하게 설명하겠지만 입력의 요소들 간의 interaction을 모두 고려하여 어떠한 inductive bias를 가지지 않고 가중치를 부여하는 방식 입니다. 즉 convolution처럼 상대적인 위치보다도 input signal들 자체의 relation을 더 중요하게 생각한다는 것이죠. 그러나 inductive bias가 없다는 것은 self-attention은 locality와 translation equivariance 같은 특성을 보장하기 어렵다고 바꾸어 말할 수 있습니다.
그래서 논문에서는 self-attention을 사용하면서 translation equivariance 할 수 있도록 position 정보를 제공하는 relative self-attention을 제안합니다. 본래 목적은 self-attention이 완전히 convolution을 대체할 수 있고자 했지만 결론적으로는 완전히 convlution network를 배제하진 못하였고, 대신 기존 convolution 방식에 추가적으로 제안한 relative self-attension 기법을 agument한 Attention Augmented Convolutional Network를 소개하고 있습니다.
2. Related Work
Attention mechanisms in networks
Attention은 NLP와 visual task에서 convolution의 약점을 보완해주는 역할로 사용되었습니다. 몇가지 method를 예로 들면,
1.Squeeze-and-Excitation, Gather-Excite
두 방법론 모두 feature map에서 더 중요한 채널을 찾아내기 위해 가중치를 계산합니다. SE는 더 큰 영향을 주는 채널을 찾기 위해 Global Average Pooling을 수행한 후, 채널 간의 가중치를 계산합니다. GE는 feature map을 patch 단위로 나누어 patch 간의 가중치를 계산하는 방법으로 두 방식 모두 입력 feature map에서 가중치를 계산하고 self-attention mechanism을 적용합니다.
2. BAM, CBAM
BAM은 channel attention과 spatial attention이 병렬적으로 수행되고 CBAM은 두 개의 attention이 순차적으로 진행된다는 차이점이 존재하지만 입력 feature map을 channel과 spatial 두 방향으로 독립적이게 reweight한다는 특징을 가집니다.
Related Work에서는 위와 같이 이미지에 적용한 기존의 attention 방식을 언급합니다. 그러면서 논문이 제안하는 attention augmented network는 spatial과 channel 정보를 독립적이 아닌 jointly attend 할 수 있도록 relative position embedding을 통해서 공간적인 정보를 가지고, convolutional feature을 reweight 하지 않고 self-attention을 통해 추가적인 feature map을 만드는 차별점이 존재한다고 이야기합니다.
3. Methods
3.1. Self-attention over images
그럼 이미지에 대해 self-attention을 어떻게 적용해야할까요? 기본적으로 self-attention mechanism으로 Transformer 구조에서 제시한 multihead attention 구조를 따릅니다. 먼저 input으로 주어지는 tensor의 shape은 (H, W, F_{in}) 입니다. H는 activaion map의 height, W는 width, Fin은 input filter의 개수 입니다. self-attention mechanism에 input으로 넣어주기 위해서 tensor vector을 X\in\R{^{HW*F_{in}}} 으로 flatten 합니다. 이제 해당 vector을 multi head attention에 적용하면 됩니다.
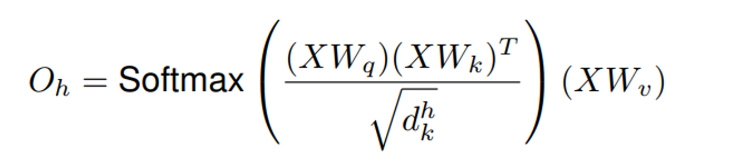
먼저 flatten한 input vector을 Query, Key, Value weight vector을 통해 queries, keys, values vector로 embedding을 합니다. 그러면 queries는 Q = XW_q keys는 K = XW_k 그리고 values는 V = XW_v가 됩니다. 이 embedding vector들을 통해서 single head의 output을 계산할 수 있는 것 입니다. Q와 K의 matmul로 일종의 점수를 매긴다고 생각하고 softmax 계산까지 통과를 시켜 모든 점수들의 합을 1로 만들면 현재 픽셀의 encoding에 있어서 다른 픽셀들이 얼마나 attend하는지를 결정할 수 있습니다. 이제 V vector를 곱하면 attend 하고 싶은 픽셀은 남겨두고, 나머지 픽셀은 작은 value가 곱해져 영향력이 사라집니다.
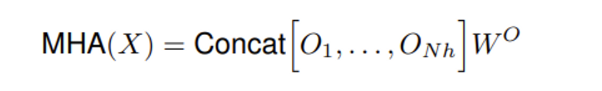
multi head attention은 간단히 N개의 head에서 구한 모든 output을 서로 concat한 후 projection 해주면 됩니다.
3.1.1. Two-dimensional Positional Embeddings
3.1. 처럼 self-attention하는 경우 문제점이 존재합니다. 바로 input의 pixel 위치가 바뀌더라도 같은 결과가 나와 permutation equivariant 하다는 것 입니다. 이는 특히 이미지와 같이 highly structured data의 경우, 결과에 좋지 않은 영향을 미치기 때문에 해당 논문 이전의 연구들에서 입력 embedding에 positional encoding을 추가했는데요, 공간 정보를 명시해줌으로써 permutation equivariant에 대한 issue를 완화해주기 위함이었습니다. 그러나 저자는 이전의 NLP 분야에서의 encoding 방식은 image classification과 object detection에 대한 실험에서 도움이 되지 않는다고 말합니다. 그 이유로 positional encoding을 통해 permutation equivariant 하진 않지만 translation equivariance를 만족하지 못하기 때문이라고 가정합니다. 따라서 입력 데이터의 각 위치에 대한 상대적인 위치 정보를 encoding 하여 translation equivariance까지 만족할 수 있도록 기존의 transformer 모델에서 사용되던 relative positional encoding에서 이미지에 대해서도 적용할 수 있도록 2차원으로 확장시킨 Two-dimensional relative positional embedding을 제안합니다.
Relative positional embeddings
기존 relative position embedding에서 relative height 정보와 relative width 정보를 추가적으로 제공함으로써 2차원으로 확장한 relative self attention을 소개합니다.
relative positional encoding이 결국 query를 기준으로 key들의 상대적인 위치를 사용하는 것이기 때문에 query에 대해 다른 pixel들이 얼마나 attend 하는지를 위치로 표현할 수 있습니다. 이때 relative width, relative height 정보를 독립적으로 더해줌으로써 한 픽셀을 기준으로 다른 픽셀이 상대적으로 얼마만큼 떨어져 있는지를 알고자 하는 것 입니다.
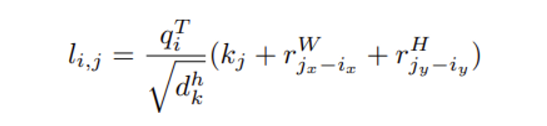
q_i가 pixel i (i = (i_x, i_y))에 대한 query vector이고, k_j가 pixel j (j = (j_x, j_y)) 의 key vector일 때,r^W_{j_x-{i_x}}, r^H_{j_y-{i_y}}이 각각 pixel j와 i의 relative width (j_x-i_x), relative height (j_y-i_y)에 해당하는 learned embedding 입니다. 수식3을 베이스로 single head의 ouput을 보면 다음과 같습니다.
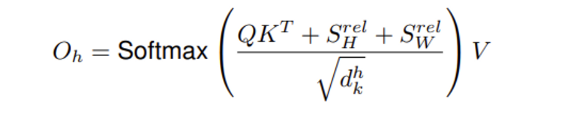
하나의 self-attention head를 통과한 output이니 수식3에서 하나의 픽셀을 기준으로 한 relative position을 보았다면 수식4를 Q, K, V로 embedding한 전체 vector 관점에서 보면 됩니다. Q의 모든 행에 대한 query vector를 차례대로 다른 K의 key vector들과 relative width, relative height을 구한 값인 S^{rel}_H, S^{rel}_W가 추가되는 것을 제외하고 3.1.의 single head output과 동일한 수식입니다. 제안한 two-dimensional positional embedding에 사용되는 relative width와 relative height는 trainable 하기 때문에 train에서 parameter의 수가 약간 늘어나게 됩니다.
3.2. Attention Augmented Convolution
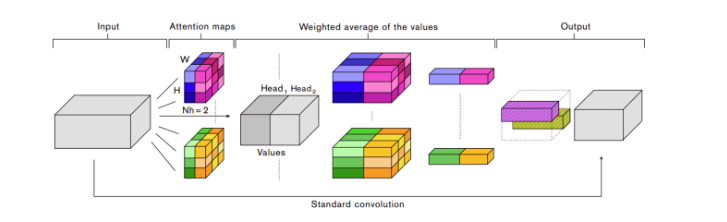
이제 논문에서 새롭게 제안하는 Attention Augmented Convolution에 대해 살펴보겠습니다. 이전의 related work에서 언급한 이미지에 대한 attention 방법론들과 다른 점으로 2가지를 이야기 합니다.
- spatial과 feature subspace를 jointly 참조할 수 있다.
relative position embedding을 통해서 공간적인 정보를 가지고 self-attention을 거쳐 spatial과 feature의 정보를 동시에 고려할 수 있습니다.
- convolutional feature를 refine하는 것이 아니라 attention을 통해서 새로운 feature map을 만들어낸다.
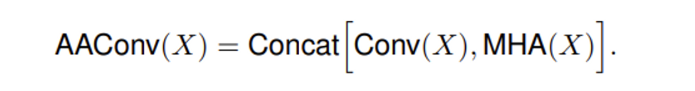
구조는 간단합니다. self-attention과 convolution을 하는 과정을 나누어 독립적으로 진행한 후에 마지막에 output을 형성할 때 두 과정의 output을 concat 하면 됩니다. 결국 3.1.1.에서 이야기 하였듯이 multi head attention layer을 친 최종 attention feature와 convolution을 거친 feature가 마지막에 concat 되는 것 입니다.
4. Experiments
Experiments에서는 image classifcation과 object detection에서 다른 Attention mechanism과 제안한 Attention Augmented method를 비교하는 실험 결과를 보여줍니다.
CIFAR-100 image classification
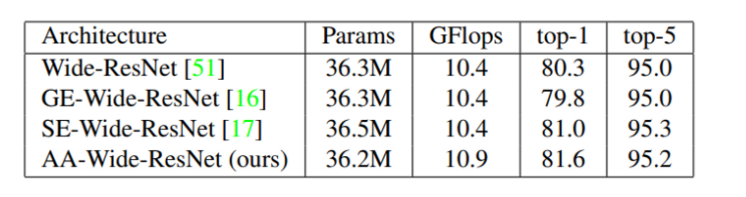
먼저 CIFAR-100 데이터셋에 대해서 다른 attention mechanism인 SEBlock및 GEBlock과의 image classification 성능을 비교한 결과 입니다. top-1 accuracy를 봤을 때 AA network가 가장 높은 accuracy를 가지는 것을 볼 수 있습니다. 하지만 성능 차이가 크지 않고 top-5까지 보았을 때는 그 차이가 더 적으며 심지어 SEBlcok과 비교하면 오히려 SEBlock이 더 높은 성능을 보이고 있습니다.
ImageNet image classification with ResNet
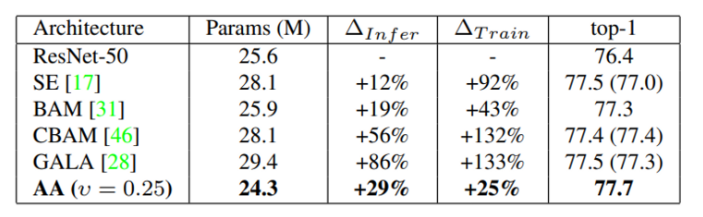
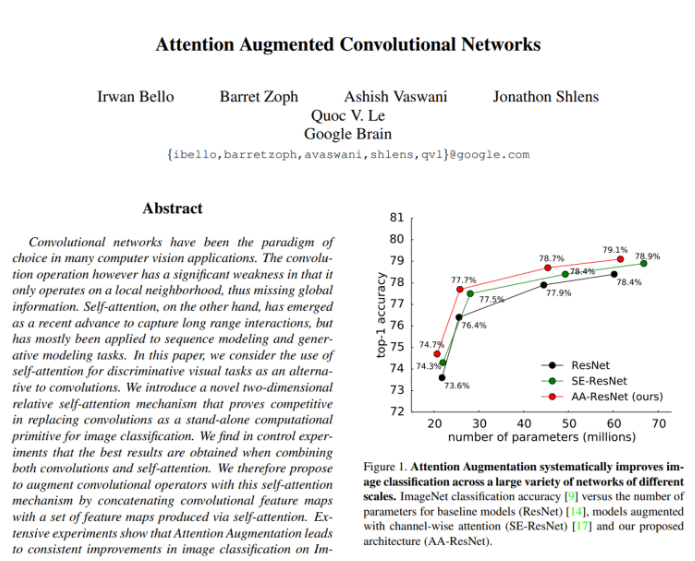
이번에는 ImageNet 데이터셋에 대한 ResNet-50을 backbone 모델로 한 image classification 결과 입니다. Attention Augmented method가 가장 적은 parameter를 가지면서 좋은 top-1 accuracy를 가집니다. Convolution을 단독으로 사용할 때보다 relative position embedding을 적용하면서 조금 더 많은 파라미터를 사용한다는 것을 여기서 실험적으로 확인할 수 있습니다. △은 ResNet50과 비교했을 때 늘어나는 latency times으로 낮을 수록 baseline과 비교했을 때 지연시간이 적다는 뜻 입니다. 베이스라인보다 많은 파라미터를 쓰는 것은 맞지만 다른 method와 비교하면 train에서 확연히 적은 지연 시간을 보여주고 있네요.
Object Detection with COCO dataset
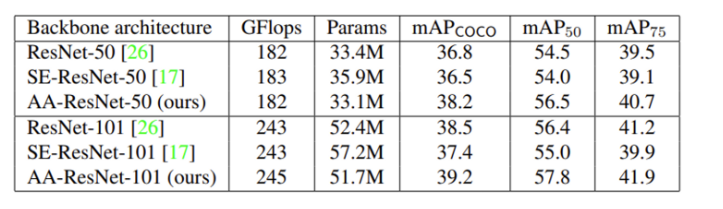
이제 COCO dataset으로 object detection을 한 성능 결과 입니다. Squeeze-and-Excitiation operators는 기본 ResNet 모델에 비해 낮은 mAP를 보이는 반면, Augmented Attention 모델은 전반적으로 1.5mAP 정도 성능이 향상되는 것을 확인할 수 있습니다. 저자들은 localization은 spatial information을 요구하는데 SEblock의 경우 spatial 정보를 없애기 때문에 self-attention으로 spatial information을 유지하는 AA method에 비해 낮은 성능을 보인다고 말합니다.
4.5. Ablation Study
Fully-attentional vision models
introduction에서 이미 언급하였듯이 원래 본 논문의 목표는 attention이 convolution을 완전히 대체할 수 있음을 증명하는 것이었습니다. 하지만 실험적으로 두 가지를 합쳤을 때 가장 높은 성능을 보였기 때문에 Attention Augmented Convolutional Network라는 방법론을 제시한 것이죠. 해당 실험은 그렇다면 relative self-attention만을 적용하여 model을 만들었을 때 어떤 결과가 나오는지를 확인하는 것 입니다.
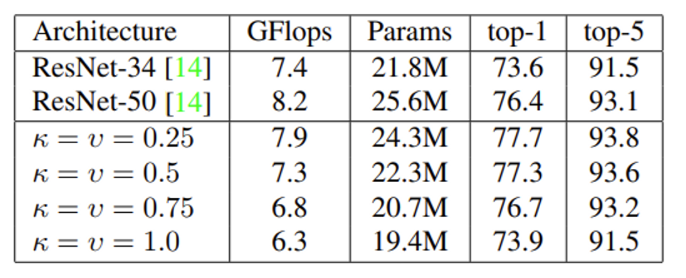
K = d_k/F_{out} , V = d_v/F_{out} 을 나타내며 k=v의 비율이 높을수록 convolution의 사용이 적은 것으로, 즉 1.0이 되었을 때가 모든 convolution을 relative self-attention으로 대체한 architecture 입니다. 비율이 높아질수록 성능 저하가 나타나는 이유로는 memory cost가 높아져 average pooling으로 downsampling을 하였기 때문입니다. 그럼에도 불구하고 accuracy가 2.5%밖에 하락하지 않은 것을 볼 수 있습니다. 비록 완전한 self-attention이 CNN의 성능을 뛰어넘지는 못하더라도 충분히 의미있는 결과라고 생각합니다.
Importance of position encodings
논문에서 사용하는 relative positional encoding이 아닌 다른 position encoding을 사용하였을 때 어떤 결과가 나오는지 확인하는 실험 입니다.
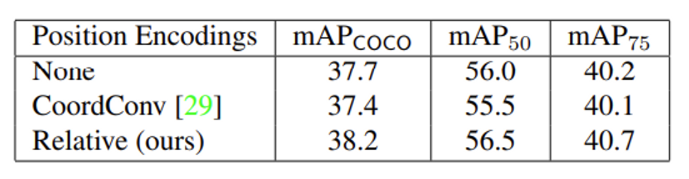
object detection에서 Position Encoding으로 이미 존재하는 방법론인 CoordConv를 사용할 경우 mAP가 사용하지 않았을 때 보다 하락하는 반면, relative position encoding을 사용하는 경우 mAP 성능이 향상합니다.
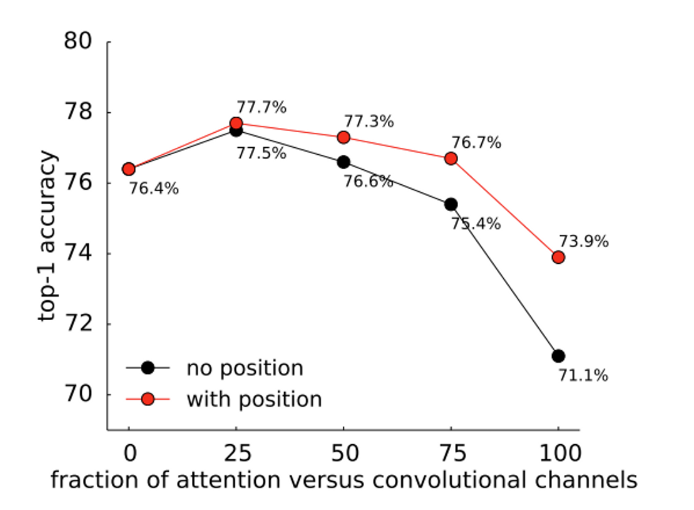
convolution channel 대비 attention mechanism을 어떤 비율로 사용하고, position encoding의 사용 여부를 종합적으로 판단했을 때 0.25%의 relative self-attention method를 사용하고 position encoding을 활용한 모델이 가장 높은 성능을 보이고 있습니다.
논문이 제 생각보다 attention 개념 뿐만 아니라 attention을 적용한 이전 방법론을 많이 가져다 써서 처음 attention을 공부하며 읽기엔 어려움이 있었던 것 같습니다 .. ? 앞으로 계속 논문을 읽으며 이런 점들을 극복 할 수 있겠죠 ? 기대되는 마음으로 첫 x-review 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽다가 궁금한 점이 생겨 질문 드립니다. 3.1.1 파트에서 “positional encoding을 통해 permutation equivariant 하진 않지만 translation equivariance를 만족하지 못한다”고 하셨는데 저는 translation equivariance를 입력의 위치가 변하면 출력도 동일하게 위치가 변한채로 나온다는 뜻으로 이해했습니다. 그러면 제가 생각한 positional encoding이 맞다면 입력의 위치가 변하면 변한대로 position이 encoding이 되는 것으로 알고 있는데 왜 translation equivariance를 만족하지 못한다고 할 수 있는 걸까요?
안녕하세요 ! 댓글 감사합니다.
Translation equivariance와 permutation equivariance는 입력 데이터가 변했을 때 출력도 입력이 변한것과 동일하게 변환되는 공통의 성질을 가지고 있긴 하지만 엄연한 다른 특성이기 때문에 이를 생각해보면 “positional encoding을 통해 permutation equivariant 하진 않지만 translation equivariance를 만족하지 못한다”의 의미를 알 수 있습니다.
Translation equivariance는 입력의 데이터가 이동하면 출력이 동일하게 이동하는 것을 의미합니다. 반면에 permutation equivariance는 입력 데이터의 순서가 바뀔 경우, 출력도 입력 데이터의 순서와 일치하는 방식으로 변환이 되는 것입니다.
즉, translation equivariance는 입력 데이터의 공간 이동에 대한 불변성을 따지는 것이고 permutation equivariance는 입력 데이터 내에서 순서에 대한 불변성을 보장하기 때문에 원래의 positional embedding은 입력 데이터에 대한 상대적인 공간 정보가 주어지지 않기 때문에 embedding된 정보로 순서만 보장할 수 있는 것이고, 본 논문에서 제안하는 relation positional embedding은 각 픽셀 사이의 상대적인 width, height 정보를 제공함으로써 translation equivariance까지 만족할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
저도 어텐션 언제 제대로 봐야지.. 하면서도 계속 미루게 되는데, 바로 어려운 응용 논문 리스펙합니다.?
논문에서 제안한 two-dimensional positional embedding이 flatten된 이미지에 위치 정보를 임베딩하고, 이걸 이용해 convolution없이도 공간적인 정보를 고려하는 어텐션 구조를 만든 것으로 이해하였는데 맞나요?
그리고 실험에서 어텐션만으로 구성한 모델이 비록 CNN을 앞서지는 못했지만 거의 근접한 성능을 보였는데, 파라미터 수가 더 적은 것을 고려하면 충분히 좋은 성능 같은데, 혹시 합성곱 계층을 어텐션으로 대체하는 후속 연구도 있는지 궁굼합니다.
감사합니다 🙂
안녕하세요 ! 댓글 감사합니다.
지오님이 이해하신 구조가 맞습니다 !
본 논문이 발표되고 나서 attention과 CNN을 비교하면서 대체하려는 시도를 한 논문은 Augmenting Convolutional networks with attention-based aggregation라는 논문이 있는데, 다른 후속 연구를 더 찾게 되면 추가적으로 알려드리겠습니다!
건화님의 첫번째 리뷰 잘 읽었습니다.
Attention Augmented Convolution 에 대한 설명에서 self-attention과 convolution이 concat되어서 합쳐질 때 더해지는것이 아니라 concat 되는 거 같은데, 그림으로는 어떻게 concat이 되는지 정확하게 잘 이해를 못하겠네요,,,(제 이해 이슈일 수 있습니다,,)
혹시 shape을 예로 들어서 조금 설명 해 주실 수 있나요?
감사합니다!
안녕하세요 ! 좋은 리뷰 감사합니다.
사실 논문에서도 단순히 relative self-attention와 convolution을 거친 output feature을 concat한다고만 서술되어 틀렸을 수도 있지만 제가 이해한 바로 설명을 해보자면 .. ..
우선 input으로 들어오는 (H, W, F_in) shape의 tensor를 self attention에 태울 input과 convolution을 할 input으로 나누어 줍니다.
그러면 self-attention input shape : (H, W, d_k) , convolution shape : (H, W, F_in – d_k)가 됩니다
각 algorithm을 지나고 나면 self-attention output shape : (H, W, d_k)이고 convoltuion output shape : (H, W, output channel)이 됩니다.
이 둘을 concat 하면 최종 output shape은 (H, W, d_k + output channel) 입니다.
shape을 적어서 설명하긴 했지만 .. 사실 그냥 나온 output 2 개의 channel을 단순히 더해주는 것에 불과하다고 보시면 될 것 같습니다 ..
안녕하세요. 첫 번째 X-Review 잘 읽었습니다.
해당 논문을 읽고자 다른 지식 (Self-attention, Inductive bias 등)에 대해서도 공부하신 것이 보이는, 전체적으로 잘 정리된 글을 읽은 느낌입니다. 첫 번째 리뷰인만큼.. 질문은 다음과 같습니다.
1. Introduction에서 Self-attention이 Inductive bias가 없다고 말씀해주셨는데, 저자의 주장에 해당하나요? Inductive bias는 단어를 처음 접했을 때, 저는 개념적으로 모호한 느낌이 들어 이해하는데에 오랜 시간이 걸렸습니다. 건화님께서 이해하신 Inductive bias에 대한 설명을 부탁드립니다. 저자의 주장에 해당하는지 물어본 이유는, Attention 메커니즘을 생각했을 때, Attention 메커니즘 그 자체의 기저된 개념만으로 Inductive bias가 있을 수 밖에 없다고 생각하는 제 생각과는 달라서 물어보게 되었습니다.
2. Related Work에서 저자의 Contribution 중 하나로 Spatial, Channel Attention을 Jointly하게 Attention하는 것을 내세운 것으로 보입니다. 이 때 의문점으로, CBAM은 Spatial Attention과 Channel Attention을 직렬적으로 수행하여 두 정보를 나름 Jointly하게 사용하는 것으로 생각되는데, 그렇다면 저자가 말한 Jointly Attend는 어떤 의미를 가지나요? BAM, CBAM과의 차이점에 대해 다시 설명해주실 수 있을까요?
3. Method에서 Self-attention의 설명이 전체적으로 잘 적혀있어 읽기 편했습니다. 마지막으로 언급한 Multi-head Attention에서 Concat 후 Projection 한다고 말씀해주셨는데, 이 때 Projection이란 어떤 의미인가요? 해당 부분에 대한 보충 설명을 해주시면 감사합니다.
4. 기존 Attention 방법론과 다른 점으로 CNN Feature를 Refine하지 않고, 새로운 Feature map을 만들어낸다는 것을 차이점으로 두었는데, 해당 방식이 갖는 장점이 어떤 것이 있나요? 새로운 Feature map은 Inductive bias가 낮아지는 측면으로 이해하면 이해가 되지만, 다른 측면에서 분명한 단점이 존재할 것도 같은데, 해당 부분이 의문점입니다. 즉, 저자가 Contribution으로 삼은 점이 명확히 파악하기 어렵네요.. 마치 Transformer의 Self-attention을 이미지에 적용하고자 했는데, Pixel-level로 진행하는 것을 보니 ViT 같으면서도, ViT보다 이후에 나온 논문이니 다른 차별점이 존재할 것도 같은데, 해당 논문은 Relative width, height 정보를 주는 것이 전부인가요?
5. Fully-Attentional Vision Model의 실험 결과에 성능 측면에서의 상,하향에 관한 이유가 잘 녹아들어 있어 이해가 쉬웠습니다. 하지만 당연히도, Self-attention을 진행한다는 측면에서 학습에 필요한 시간 및 추론 속도에는 차이가 없을까요? Inference 시에는 Freeze 하는 방식을 사용하나요?
첫 리뷰임에도, 글이 전체적으로 깔끔하고 읽기 좋았습니다. 같은 태스크를 하는 동료로서 관심 분야의 논문을 리뷰해주시다보니 일주일에 둘 이상의 논문을 효과적으로 읽는 느낌이 드는 것 같습니다. 다음 번 리뷰에서는 건화님의 고찰도 함께 담으면 더 좋은 글이 되지 않을까 생각합니다.
좋은 리뷰 잘 읽었습니다.
안녕하세요 ! 댓글 감사합니다
1. convolution은 인접한 픽셀들간의 locality가 존재한다는 것을 미리 알고 잇기 때문에 인접한 픽셀 간의 정보를 추출하기 위한 목적으로 설계가 된 것이라서 convolution의 inductive bias가 local한 영역에서 공간적인 정보를 뽑아낸다고 생각을 하는데, attention은 입력 데이터의 모든 요소간의 관계를 계산하므로 CNN보다는 Inductive Bias가 작다라고 할 수 있지 않을까 생각합니다. 없다보다는 작다라는 표현이 맞는 것 같습니다 ㅎㅎ ..
2. 저도 처음에는 related work를 읽고 CBAM 역시 spatial과 channel에 jointly 하게 접근한다고 생각을 했었습니다. 제 생각에는 저자가 말하고자 하는 jointly attend 라는 것은 CBAM 처럼 spatial attention 후에 channel attention을 거치는 과정 역시도 어떻게 보면 독립적인 attention이라고 정의하는 것 같습니다. 그에 비해 본 논문의 AA method는 relative position정보를 통해 하나의 attention mechanism으로 spatial과 channel에 대한 접근이 가능하다는 것을 표현했다고 이해했습니다.
3. W^o 값을 곱해주면서 모든 head를 concat한 값에 대한 linear projection이 가능해집니다. 그러면 원래의 spatial dimentsion에 매치할 수 있도록 attention map의 shape이 (H, W, d_v) 됩니다.
4. 음 .. CNN Feature을 refine하지 않고 새로운 feature map을 만들어내면 fully convoltuion에서 fully attention 모델까지 유연하게 attention channel을 조절할 수 있다는 장점이 존재하여 contribution으로 내세운 것이 아닐까 추측해봅니다. 사실 CNN에 attention 모델을 합쳤다는 것을 제외하고 가장 큰 차별점은 말씀하신 relative width, height 정보를 주는 것이라고 할 수 있습니다.
5. 학습에서는 positional embedding으로 인한 relative width, height 정보가 trainable하기 때문에 파라미터 수가 추가되어 학습 시간이 기존 베이스라인 모델보다 오래 걸리는 것이 아닐까 생각하지만 inference에 대한 부분은 조금 더 생각을 해봐야할 것 같습니다 .. 혹시 의견 있으시면 남겨주시면 감사하겠습니다. ?
안녕하세요. 리뷰 잘 읽었습니다.
궁금한 것이 제법 많지만 이미 지난주에 질문을 많이 받으신 것 같아서 제가 이해 못한 부분만 질문으로 남기려고 합니다.
리뷰에서는 relative positional embedding에 대해 learnable paramter라고 말씀하셨고 이 때문에 모델 학습에 사용되는 파라미터가 더 커진다고 말씀해주셨습니다. 근데 Classification실험도 그렇고 Object Detection 실험도 그렇고 baseline 모델 대비 본 논문에서 제안하는 기법을 적용한 모델의 “Params” 항목이 더 작은 것으로 보이는데 이는 왜 그런가요?
분명 리뷰에는 “Convolution을 단독으로 사용할 때보다 relative position embedding을 적용하면서 조금 더 많은 파라미터를 사용한다는 것” 이라는 말씀을 반복적으로 하시는 것 같은데 오히려 Param 값은 더 작은 것 같아서 이해가 잘 안되네요. 말씀해주신 내용대로라면 Param 값이 baseline보다 더 커야하지 않나요?
안녕하세요 ! 댓글 감사합니다.
relative width와 relative height는 trainable 하기 때문에 train에서 parameter의 수가 약간 늘어나게 되는 것은 맞습니다.
그런데 결론적으로 relative position embedding 과정에서 늘어난 파라미터는 simplicity를 위해서 무시한다고 논문에서 언급이 있었는데 제가 넣지를 않았네요 ..
제가 내용을 빠트려서 이해하시는데 혼선을 드린 것 같습니다 ..