이번 주차 X-Review의 주제로 선정한 논문의 제목은은 올해 CVPR에 accept된 “Improving Weakly Supervised Temporal Action Localization by Bridging Train-Test Gap in Pseudo Labels”입니다.
아시다시피 23년도 CVPR논문이 정식으로 publish 되진 않은 상태라 arXiv에 올라온 버전으로 읽었는데, 이해하기에 조금 어려운 부분이 있어 설명이 매끄럽지 못할 수 있는 점 양해해주시면 감사하겠습니다.
참고로 본 논문은 22년도 CVPR에 게재된 “Weakly supervised temporal action localization via representative snippet knowledge propagation”(RSKP)를 베이스라인으로 삼고 있습니다. RSKP의 저자들이 본 논문에 참여하였네요.

본 논문은 제가 가장 많이 리뷰해온 Weakly-Supervised Temporal Action Localization(WTAL) task를 수행하는 방법론을 담고 있으며, 기존 방법론 대비 확연한 성능 향상을 보여주고 있습니다.
WTAL task에 대해 아직 잘 모르시는 분들이 계실 수도 있으니, task에 대해 간단히 소개한 후 논문을 살펴보도록 하겠습니다.
우선 Temporal Action Localization(TAL)이란, 수영, 창 던지기, 높이 뛰기 등을 포함하는 다양한 action이 등장하는 비디오를 입력받아 action이 발생하는 구간이 어디인지 찾고, 해당 구간에서 어떤 action이 일어나고 있는지 분류까지 수행하는 task입니다.
영상 분야의 Object Detection이 한 영상 내에서 물체에 대한 위치를 찾고 그 위치에 어떠한 물체가 포함되어 있는지 분류하듯, 이러한 프레임워크를 비디오의 temporal 축에서 수행한다고 생각하시면 이해하기 쉬우실 것 같습니다. 물론 비디오 분야에도 Spatio-Temporal Action Localization이라고 해서, 구간과 action class를 예측하는 것에서 더 나아가 구간 속 프레임 중 어느 부분에서 action이 발생하는지 박스까지 치는 task가 존재하기도 합니다.
아무튼 이러한 TAL을 수행하기 위해 학습할 때, 주어지는 라벨은 두 종류가 있습니다. Object Detection에서는 한 이미지 속 박스에 대한 좌표와 그 박스에 속하는 물체 클래스가 주어지는데요, TAL에서도 마찬가지로 action이 발생하는 구간과 그 action이 라벨로서 주어지게 됩니다.
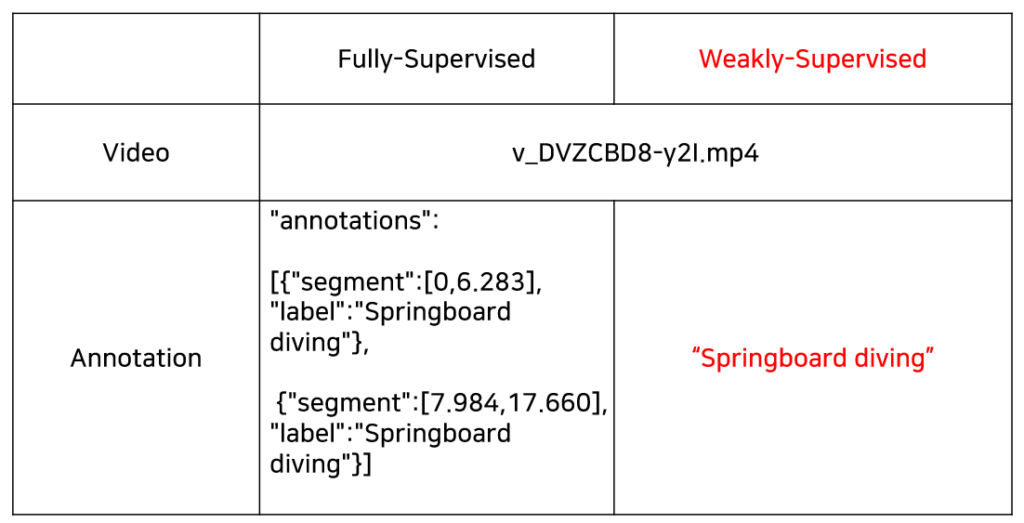
이 때 위 표에서처럼 하나의 비디오에 대해 비디오 속 action이 발생하는 구간과 그 action이 “Springboard diving”이라는 정보를 학습에 모두 사용하면 Fully-Supervised TAL에 해당하는 반면에 구간 정보 없이 이 비디오 안에는 어디인진 모르겠지만 “Springboard diving” action이 발생한다는 정보만 가지고 학습을 수행한다면 이는 WTAL이 되는 것입니다. 물론 하나의 비디오 안에는 여러 종류의 action이 포함되어 있을 수도 있습니다.
참고로 위 표의 WTAL에서 예시로 등장한 “Springboard diving”과 같은 클래스를 video-level label이라고 칭하는데, 다른 종류의 WTAL로는 video-level label 뿐만 아니라 비디오에서 해당 action의 등장 횟수나 음성 정보를 추가로 활용하는 WTAL도 있습니다. 하지만 학계에서는 video-level label만을 활용하는 WTAL이 주류를 이루고 있습니다. 또한 Unsupervised 기반으로 TAL을 수행하는 논문도 존재하긴 하는데, 잠깐 살펴보았을 때 연구가 그리 활발하게 이루어지는 것 같지는 않아보였습니다.
Task에 대한 설명은 마치고 논문의 Introduction으로 들어가보겠습니다.
1. Introduction
반복적으로 등장하는 Weak-label의 필요성 부분은 생략하고, 저자의 문제정의부터 보겠습니다.
Video-level label만을 사용하여 action의 구간을 맞추기 위해 WTAL 연구 초반에는 Class Activation Sequence(CAS) 또는 Class Activation Map(CAM)을 활용한 “Localization by Classification” 방법론이 대다수였습니다(CAS, CAM, T-CAM, T-CAS는 WTAL에서 통용되는 단어입니다). 가끔 논문의 정성적 결과를 보시면 설계한 모델이 무엇에 집중하고 있는지 보여주기 위해 GradCAM 결과를 보여주는 경우가 많은데요, 이는 모델이 분류 결과를 올바르게 예측하기 위해 영상의 어떤 부분에 집중하였는지를 의미하는 Heat map에 해당합니다.
WTAL에서는 이 방법론을 차용하여 localization을 수행합니다. 학습에 사용할 수 있는 라벨이 video-level label 밖에 없는 상황이니, 분류를 수행한 후 이 비디오가 해당 클래스로 예측되는 데에 있어 어느 구간이 가장 큰 기여를 했는가를 기준으로 localization을 수행하는 것입니다.
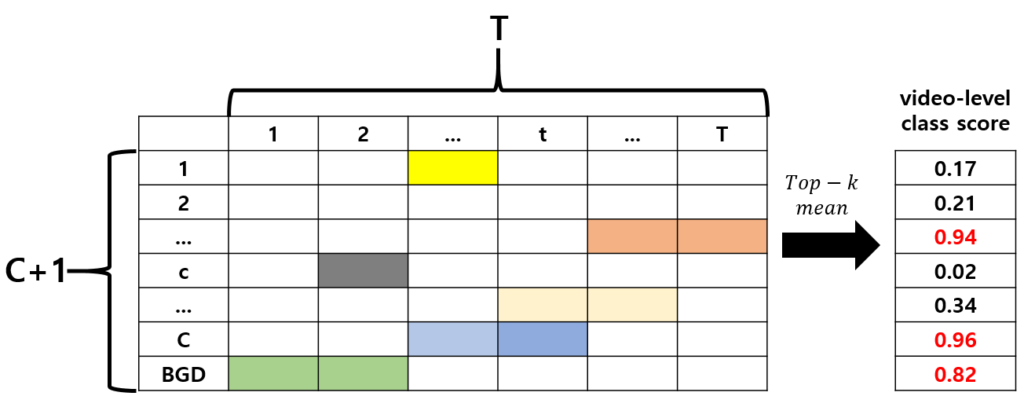
비디오를 16프레임 묶음에 해당하는 총 T개의 snippet으로 나누었을 때, 가지고 있는 video-level label로 분류 학습을 진행하며 각 snippet들이 각 클래스에 해당할 확률을 담고 있는 매트릭스를 구성할 수 있고 이것이 바로 CAM입니다.
하지만 특정 action으로 분류되는 데에 얼마나 영향을 미치는지에 대한 score를 기준으로 fine-grained 수준의 action 구간을 예측하는 것은 최적의 방식이 아닙니다. 실제로는 action이 아닌 background 구간이지만 그 구간이 담고 있는 정보가 어떠한 action으로 분류되는 데에 큰 역할을 수행했다면 FP로 잘못 들어갈 수 있는 것이고, 반대로 action이 두드러지게 발생하는 구간에만 집중하여 action이 마무리되는 부분은 모델이 제대로 알아보지 못하는 경우에는 FN이 발생할 수도 있겠죠. 이렇게 구간을 너무 넓게 또는 좁게 예측하는 것을 Action completeness가 보장되지 못하는 상황이라 칭하고, 학계에서는 이를 해결하기 위해 다양한 방법론들을 고안해냅니다.
위와 같은 문제를 해결하기 위한 여러가지 방법론들 중 최근까지 가장 좋은 성능을 보여주면서 활발히 연구되고 있는 방법론이 바로 Pseudo-label based 방법론입니다. CAS로부터 바로 localization을 수행하는 것이 아니라, 일련의 denoising 또는 enhance 과정을 거쳐 localization을 학습하기 위한 pseudo label을 만들고 이로부터 localization을 수행하는 것입니다. 물론 어떠한 방법으로 denoising 또는 enhance를 수행하는지가 각 방법론의 contribution에 해당합니다.
여기서 잠시 논문 제목의 의미를 짚고 넘어가자면, 본래 pseudo label based 방식이 train-test gap을 줄이기 위해 고안되었다고 볼 수 있습니다. 이전 방법론들은 분류 과정에서 만들어진 CAM을 기반으로 구간을 학습하지만, test 시 만들어내야 하는 구간은 분류와는 또 다른 방식으로 뽑히는게 이상적이기 때문에 둘 사이를 메워줄 pseudo label을 사용한다는 점이 train-test의 gap을 메워줄 열쇠가 될 수 있다고 볼 수 있다는 것이죠.
그럼 여기서 들 수 있는 의문점이, “pseudo label은 과연 완벽할까” 일텐데요, 기존 방법론들에 비해 해당 방식이 일반적으로 높은 성능을 보여주는 것은 맞습니다만, temporal annotation의 근원적 부재로 인해 이러한 방식에도 한계가 존재한다는 것입니다.
저자는 이러한 한계점 중 하나로 NMS를 꼽습니다. 다양한 threshold 하에서 모델이 예측한 action instance(Object Detection의 bounding box와 유사한 개념)에는 중복이 많기에 NMS를 거쳐 최종 proposal을 얻는 것이 지금까지 일반적으로 적용되던 방식입니다. 이렇게 얻은 최종 proposal 구간을 바탕으로 각 방법론들만의 pseudo label이 생성되는 것입니다.
하지만 저자는 학습 시 temporal annotation(시간 구간에 대한 label)으로부터 action의 실제 구간 정보를 본 적이 없으니, confidence score가 높다고 해서 그 구간이 실제 GT구간과 가장 적합하다고 보기 힘들고 반대로 confidence score가 낮다고해서 완전히 삭제해야하는 구간이라고 보기에도 무리가 있다고 주장합니다.
또한 pseudo label은 이렇게 NMS 과정을 마치고 나온 최종 proposal을 고려하여 전체 T개의 snippet에 대해 하나씩 할당되는데, 이 때 한 snippet에 여러 proposal이 겹치게 되면 해당 snippet에는 어떠한 pseudo label을 할당해야하는지에 대한 논의도 필요합니다. 단순히 0/1로 주는 경우, 두 개의 proposal이 극히 일부만 겹쳐도 pseudo label은 하나의 긴 proposal로 대체될 수도 있기 때문이겠죠. 이렇게 고전적 NMS 방식을 적용함으로써 발생하는 문제점들을 해결하기 위한 pseudo label 생성 방식을 제안하는 것이 본 논문의 출발점입니다.
저자는 위와 같은 문제점을 지적하며, 총 3가지 모듈을 제안합니다.
Contributions
- Gaussian Weighted Instance Fusion module: NMS를 대체하여 수행되고, 기존처럼 confidence score가 높은 instance만 살리는 것이 아니라 score가 낮은 instance도 gaussian weight를 주어 다양한 instance들을 aggregate 하는 방식을 제안합니다. 본 모듈에서는 pseudo label을 생성하기 위한 재료가 될 시작 지점, 끝 지점과 예측한 클래스, confidence score를 출력합니다.
- LinPro Pseudo Label Generation strategy: 앞서 instance 구간을 얻었다면 해당 구간을 단순 0/1로 라벨링해주는 것이 아니라 선형계획법을 활용하여 최적화 방식으로 pseudo label을 생성해냅니다.
- \Delta{} pseudo label: 학습 초반에는 만들어 내는 pseudo label이 불안정하기 때문에, 현재 pseudo label 과 이전 에포크에서의 pseudo label과의 차이를 이용해 학습합니다.
- THUMOS14, ActivityNet v1.3 데이터셋에 대해 SOTA 달성
각 모듈들이 어떻게 동작하는지는 아래에서 자세히 알아보겠습니다.
2. Related Work
Introduction에서는 WTAL 초기 방법론들의 단점 “Localization by Classification”을 극복하기 위해 pseudo label 기반 방식이 등장하였다고 말씀드렸었습니다. 이외에도 여러 접근법이 있지만, 저자는 대표적으로 4가지를 나누어 설명하고 있습니다.
- Metric learining based methods
- Erasing based methods
- Multi branch methods
- Pseudo label based methods
Metric learning based methods
Metric learning은 다들 알고 계신 용어일텐데, 이는 각 방법론들끼리 특정 의미를 갖는 feature를 추출한 뒤 해당 의미에 맞게 설계한 loss를 바탕으로 feature 간 거리를 조절하며 학습하는 방식입니다. 단순히 feature의 거리를 조절하는 방식으로 task를 수행하는 방법론들은 상대적으로 연구 초반의 논문들이기에 이 때는 앞서 이야기했듯 분류에 기대어 localization을 수행하는 경우가 많았습니다.
최근 방법론들은 대부분 metric learning이 포함되어 있기 때문에 저자는 이 부분에서 오롯이 metric learning에 의존하는 연구 초반의 방법론들을 소개하고 있습니다.
Erasing based methods
Metric learning 기반 접근법들의 문제로, Action completeness가 조금 떨어진다는 점을 보완하기 위해 등장한 접근법입니다. 먼저 일련의 과정을 거쳐 action으로 뽑아내는데, 이 때 모델은 주로 action이 현저하게 두드러지는 구간(discriminative)에 집중하여 incomplete한 예측을 만들어내어 이 구간이 incomplete하다고 가정합니다. 이후 1차적으로 뽑은 구간을 제외하고 나머지 구간에 대해 반복적으로 action을 찾아내는 과정을 거침으로써 action의 시작과 끝의 경계 부분에 있는 지점까지 잡아내 action completeness를 보완해주는 방식입니다.
해당 방법론은 action completeness를 보완하기 위해 여러 번 detection을 반복할 때, 단계에 따라 선택한 threshold에 민감하다는 것이 단점으로 꼽힙니다.
Multi branch methods
다음은 multi branch 기반 접근법입니다. 이전 방법론들보다 조금 더 발전했다고 볼 수 있습니다. 기존 방법론들은 video-level label로 학습할 때 모델이 알아서 action의 특성을 잡아내길 기대하는 느낌이 컸다면 이쪽 방법론들부터는 상대적으로 명시적인 모델링을 수행합니다. 물론 temporal annotation이 없기에 완전 명시적이라고 할 수는 없지만, 비디오 속 action의 특성을 분석해 action과 background를 구분할 때 도움이 될만한 feature들을 다양한 branch에서 추출하여 모델이 더욱 유의미한 정보들을 학습하도록 설계하였습니다.
Pseudo label based methods
모델이 localization을 위한 라벨을 만들어내고 이를 바탕으로 학습하는 방법론입니다. Expectation-maximization 프레임워크를 활용해 pseudo label을 생성하는 방법론들도 있고, action-background 관계 속에서 정의할 수 있는 uncertainty를 기준으로 조금 더 안정적인 pseudo label을 만들어내고자 한 방법론도 있습니다.
최근 등장하는 방법론들의 절반 가량은 pseudo label을 어떻게 잘 만들것인지를 고민하는 것 같은데, 저자가 언급한 접근법들 이외에 더욱 많은 방식이 있다는 점을 감안했을 때 현재는 주류를 이루는 접근법이라고 볼 수 있을 것 같습니다. 물론 pseudo label 또한 temporal annotation이 없는 상황 속에서 만들어 내야 하는 것이기 때문에 발전해야 할 부분이 많겠죠.
아래는 WTAL task에 관하여 제가 지금까지 작성한 리뷰 중 꽤 유의미했다고 생각되는 연구를 3가지 꼽아본 것이니, 관심있으신 분들은 정렬된 순서대로 읽어보시는 것도 추천드립니다.
- [AAAI 2021] Weakly-supervised Temporal Action Localization by Uncertainty Modeling
- [CVPR 2021] CoLA: Weakly-Supervised Temporal Action Localization with Snippet Contrastive Learning
- [arXiv 2022] Weakly-Supervised Temporal Action Localization by Progressive Complementary Learning
3. Method
Problem definition
N개의 학습 비디오 \{V_{i}\}_{i=1}^{N}와 학습에 사용할 video-level label \{y_{i}\}_{i=1}^{N}을 입력받습니다. y_{i}는 총 K개의 action 중 i번째 비디오에 특정 action이 존재하는지 여부가 0/1로 표시되어 있습니다.
학습 후 inference 할 때는 최종 action instances \{(c, q, s, e)\}를 만들어내는 것이 목표이고, 각각은 예측한 클래스, confidence score, 시작 지점, 끝 지점을 의미합니다.
Overview
방법론에 속하는 모듈들의 전체적인 흐름을 먼저 살펴보겠습니다.
첫 번째 모듈인 Gaussian Weighted Instance Fusion 모듈은 앞서 말씀드렸듯 NMS의 단점을 보안하기 위해 제안되었습니다. 겹치는 instance 중 낮은 score를 갖는다고 제거해버리는 것이 아니라, score가 낮으면 낮은만큼의 가중치를 주고 aggregate하여 새로운 구간을 생성하는데 활용되는 것입니다.
LinPro Pseudo Label Generation 단계에서는 앞서 얻은 구간에 pseudo label을 할당해줍니다. 이 때 하나의 snippet이 서로 confidence score가 다른 instance에 속해있다면 해당 snippet은 어떤 pseudo label을 주어야 하는지 고민해야하는 등 앞서 언급한 hard label 할당 시 문제가 있기 때문에 soft pseudo label의 설정 방식에 대한 고민이 필요합니다. 저자는 하나의 snippet이 속해있던 여러 action instance의 confidence score를 고려하면서, action instance 내 pseudo label 값이 uniform하게 분포하도록 설계합니다.
마지막으로 학습 초반에 불안정한 pseudo label을 사용하는 것은 최종적으로 학습에 안좋은 영향을 끼칠 수 있기 때문에 초반에는 \Delta{} pseudo label을 활용하여 학습합니다. 두 에포크 간 pseudo label값의 차이를 활용하는 것이고, 이 차이는 pseudo label의 신뢰성을 나타낸다고도 볼 수 있겠네요. 또한 self-correction 기회를 주어 더욱 안정적인 학습을 유도할 수도 있을 것입니다.
사실 방법론이 이제 시작되는데, 리뷰에 쉽게 접근하실 수 있도록 task에 대한 소개를 자세히 적다보니 모든 내용을 한 리뷰에 담기에는 내용이 너무 길어질 것 같아 두개의 글로 나누어 진행하도록 하겠습니다.
방법론과 실험 부분은 다음 리뷰에 마저 작성하도록 하겠습니다.
안녕하세요 ! 좋은 리뷰 감사합니다.
TAL task을 object detection에 비유하여 설명해주셔서 이해하는데 많은 도움이 되었습니다.
Δ pseudo label을 활용하는 것이 학습 초반에 불안정하게 주어지는 pseudo label을 안정시키기 위함이라고
말씀해주셨습니다. 그렇다면 두 에포크 간의 pseudo label 값이 근소한 차이를 가질 때가 pseudo label이 안정적이라고 판단한다 생각하는 것이 맞을까요? 생각을 해보았을 때 초반의 불안정한 pseudo label에서 안정적인 pseudo label로 넘어갈 때 큰 폭으로 차이가 발생하고 그 후로는 모든 epoch 유사한 pseudo label 값이 나올 거 같은데 어느 시점부터 그 epoch의 pseudo label 값을 온전히 사용할 수 있는 것인지 궁금합니다. 안정화를 위해 pseudo label의 차이를 사용하지만 그렇다면 막상 주어진 pseudo label 자체는 사용하지 않고 의미가 사라지는 것인지 의문이 들어 질문 드립니다. 아니면 두 에포크 간의 pseudo label 차이가 신뢰성을 나타낸다는 것이 어떤 가중치처럼 해당 epoch의 label에 부여되는 것일까요??
감사합니다.
안녕하세요 ! 좋은 리뷰 감사합니다 ㅎㅎ
현우님께서 이번에 비디오 논문을 한 번도 접하지 않은 사람도 이해할 수 있도록 자세히 서술했다고 꼭 보라고 하셔서 바로 읽었습니다 . . 재미있네요.
관련 지식이 전무하기에 질문하는 것인데 , , 분류 과정에서 만들어진 CAM을 기반으로 구간을 학습하지만, test시 만들어내야 하는 구간은 분류와는 또 다른 방식으로 뽑히는 것이 이상적인 이유가 무엇인가요 ?
또 본 논문에서 저자가 일반적으로 적용되왔던 NMS의 문제점을 언급하며 Gaussian Weighted Instance Fusion module을 제안했는데, 이 GWIF module이 NMS를 대체하여 수행된다고 하셨습니다. 그런데 GWIF 모듈은 confidence score가 높은 instance를 강조하고, 낮은 instance는 감소시켜 결합하는 방식으로 알고있는데 이 방식이 NMS와 같이 수행되는 것으로 이해해도 괜찮을까요? NMS를 대체하여 수행된다고 하신 말이 헷갈려서 질문 드립니다 . .
리뷰 잘 읽었습니다.
contribution을 읽고 굉장히 흥미를 가지고 읽기 시작했는데 리뷰가 끝나버렷네요.. ㅎㅎ
선형계획법을 활용하여 최적화 방식으로 pseudo label을 생성 이부분에 대한 좀 더 자세한 설명 가능하실까요?
해당 구간을 단순 0/1로 라벨링이 하지 않는 것이라 하셨는데 이를 어떻게 최적화 문제랑 연관지을 수 있는지 그 아이디어가 궁금합니다.