안녕하세요, 로보틱스 팀 신입 연구원 양희진이라고 합니다.
이번에 로보틱스 팀에서 제안서 작업을 진행을 했었는데 제가 할당받은 task는 경량화 모델(light-weight model)에 대해 서베이 및 작성에 대해 진행을 했었습니다. 작년 딥러닝 시스템 과목을 수강했을 때, 프로젝트를 진행하면서 ROS2에서 detection을 수행하기 위해 제공되었던 코드에 MobileNetV2를 사용하는 것을 본 적이 있습니다. 그때는 사용 이유를 잘 몰랐지만 이번에 서베이를 하는 기회 덕분에 자세하게 알아보는 계기가 되었습니다. MobileNetV1부터 작성을 하려고 하였으나 이전에 김태주 연구원님께서 작성을 해놓으셔서 이후 개선된 MobileNet v2를 리뷰를 해보았습니다.
기존의 MobileNetV1 을 간단하게 살펴보면 경량화 된 모델이 모바일 기기에서 동작하는 것이 목표였고, 이러한 모델이 성능이 크게 감소되지 않게 하면서 복잡도는 떨어지도록 설계를 한 모델입니다.
그럼 MobileNetV2가 기존의 V1 모델에서 개선된 점은 다음과 같습니다.
- Inverted residual block 도입
- Linear Bottleneck 도입
shortcut connection이 thin bottleneck layer 사이에 존재하는 inverted residual 구조에 기반한 V2 모델을 제안을 하였습니다. 또한, 모델의 representational power 를 보존하기 위해 narrow layer 안에서는 비선형성(non-linear)을 제거하는 것이 낫다는 것을 발견하였습니다. 해당 논문의 접근법은 expressiveness of the transformation으로부터 입출력의 도메인을 분리하는 것이라고 합니다. 그렇게 만들어진 모델은 ImageNet, COCO object detection, 등등 으로 성능을 측정하였고, 작은 모델로도 충분히 높은 성능을 달성했다고 합니다. 각 내용의 자세한 내용은 3장에서 알아보도록 하겠습니다.
1. Introduction
현재 딥러닝은 많은 분야에서 문제를 해결하기 위해 사용되고 있습니다. 하지만 이러한 딥러닝의 성능을 올리기 위해서는 연산량도 함께 증가하게 되는 문제가 있습니다. 이러한 문제점은 모바일 임베디드 보드에는 올리기에는 무리가 있습니다. 이와 같은 문제점을 해결하기 위해서 경량화 모델을 만드는 연구가 활발히 이루어지고 있습니다.
이번 논문에서는 inverted residual with lienar bottleneck이라는 구조를 제안하여 저차원(low-dimensinal)의 압축된 representation을 다시 고차원(high-dimensional)으로 확장한 다음, lightweight depthwise convolution 으로 필터링 작업을 거치게 됩니다. 이러한 과정을 통해 feature는 저차원의 representation으로 투영(projection)됩니다. 이 과정들은 standard opration이므로 효율적으로 구현이 가능할 뿐만 아니라 어떤 모델에도 사용할 수 있다는 장점이 있습니다. 또한 large scale의 tensor를 사용하는 것이 아니기 때문에 메모리 사용량 또한 줄일 수 있는 장점이 있다고 합니다. 이러한 이유로 임베디드 보드나 작은 디바이스를 포함한 환경에서도 효율적으로 사용이 가능함을 의미하게 됩니다.
저자는 이러한 문제를 해결하기 위해 다음과 같은 contribution을 했다고 합니다
- inverted residual block을 도입하여 파라미터 수를 줄였다.
- linear bottleneck block을 사용하여 모델의 복잡도를 줄이고, 연산량과 메모리 사용량을 최소화하도록 설계하였다.
2. Related Work
모델의 최적의 아키텍처를 만드는 것은 accuracy와 latency사이의 밸런스를 맞추는 것입니다. 그 당시 성능이 드라마틱하게 향상된 대표적인 모델인 AlexNet, VGGNet, GoogLeNet, ResNet 등이 있습니다. 하지만, 해당 모델들은 너무 복잡하다는 단점이 있기 때문에 덜 복잡하면서 성능은 어느정도 비슷하게 나오는 모델을 만드는 방법에 대한 방향을 제시합니다.
3. Prelininaries, discussion and intuition
3.1. Depthwise Separable Convolutions
해당 section은 MobileNetV1에서 사용하였던 방법론을 가져다 사용합니다.
간단히 살펴보면, 기존의 convolution 연산은 입력 데이터의 모든 채널에 대해 동일한 필터를 사용합니다. 하지만, Depthwise Separable Convolution은 두 개의 단계로 나뉘어 집니다.
- Depthwise Convolution
- 입력 데이터의 각 채널마다 독립적인 필터를 사용하여 채널별로 컨볼루션 연산을 수행하는 Depthwise Convolution입니다. 이때, 필터의 개수는 입력 데이터의 채널 수와 같습니다. 채널마다 독립적으로 처리되기 때문에 일반적인 컨볼루션에 비해 계산 비용을 크게 줄일 수 있습니다.
- Pointwise Convolution
- Depthwise Convolution을 거친 결과를 다양한 채널로 합치기 위해 Pointwise Convolution을 수행합니다. Pointwise Convolution은 컨볼루션 필터의 크기가 1×1인 것으로, 입력 데이터의 모든 채널을 동시에 처리합니다. 이를 통해 채널 간 정보를 합칠 수 있습니다.
3.2. Linear Bottlenecks
MobileNetV1이 개선된 점 중 하나인 Linear Bottleneck에 대해 알아보겠습니다.
딥러닝 모델에 대한 네트워크의 구조를 한 번 생각해보겠습니다. n개의 층을 가지는 L_i 로 구성된 신경망이 있습니다. 입력으로 이미지가 들어왔을 때 각 activation tensor들은 h_i \times w_i \times d_i차원을 가지는 것을 알 수 있습니다. 이를 픽셀에 대해 생각했을 때, d_i 차원을 갖는 h_i \times w_i 개의 픽셀이 있다고 얘기할 수 있습니다. 그럼 대략적으로 입력 이미지에 대해서 layer activation 들은 manifold of interest*를 형성한다고 생각할 수 있다고 저자는 말합니다. 지금까지의 연구들에서는 신경망에서의 manifold of interest는 저차원의 부분공간(subspace)로 embeddable 하다고 가정해왔습니다. 저자는 이러한 intuition을 가지고 개선 전 모델인 MobileNetV1에서는 저차원의 부분공간으로 보냈다가 다시 복구를 시켜주는 bottleneck layer를 적용함으로써 activation space의 차원을 효과적으로 줄일 수 있었습니다.

해당 그림을 참고하면서 설명을 하면 결국 manifold of interest의 정보는 결국 비선형 activation function인 ReLU와 같은 것(ReLU의 식을 생각해보면 0이 아닌 양수 값을 가진다면 linear transformation 연산과 같음)이기 때문에 일부 소실될 수 있다고 얘기합니다. 만약 이러한 ReLU가 채널에 대한 정보를 붕괴시킨다면 해당 채널에서 정보가 손실되는 것은 피할 수 없게 됩니다. 하지만, 채널이 위 그림처럼 충분히 많다면 정보가 다른 채널에서는 어느정도 살아있을 수 있다는 것을 나타내는 그림입니다.
즉, 저차원으로 매핑하는 bottleneck 아키텍처를 만들 때, linear transformation 역할을 하는 linear bottleneck layer를 만들어서 차원은 줄이지만, manifold 상의 중요한 정보는 그대로 유지하는 것이 목표입니다.
ReLU와 같은 비선형 activation 이 없는 layer를 하나 더 추가하면 linear bottleneck의 역할을 할 수 있게 됩니다.
- manifold
- 고차원의 데이터가 저차원으로 압축되면서 특징 정보들이 저차원의 어떤 영역으로 매핑하는 것을 의미
- manifold of interest*
- 입력 이미지에서 가장 중요한 정보가 담긴 공간을 의미합니다. 즉, 입력 이미지의 대부분의 정보는 일부 특정한 공간 안에 포함되어 있고, 이 공간 내에서 이미지를 표현하는 것이 가장 효율적이라는 의미를 가지고 있습니다.
위 내용들을 요약 하면 다음과 같습니다.
- ReLU 이후, manifold of interest가 0이 아닌 크기로 유지된다면, linear transformation에 해당
- ReLU가 입력 이미지에 대해 manifold of interest의 완전한 정보를 보존하는 경우는 입력 manifold가 입력 공간의 저차원 subspace 공간에 있는 경우에만 가능
3.3. Inverted Residuals
MobileNetV1이 개선된 점 중 하나인 inverted residual에 대해 알아보겠습니다.
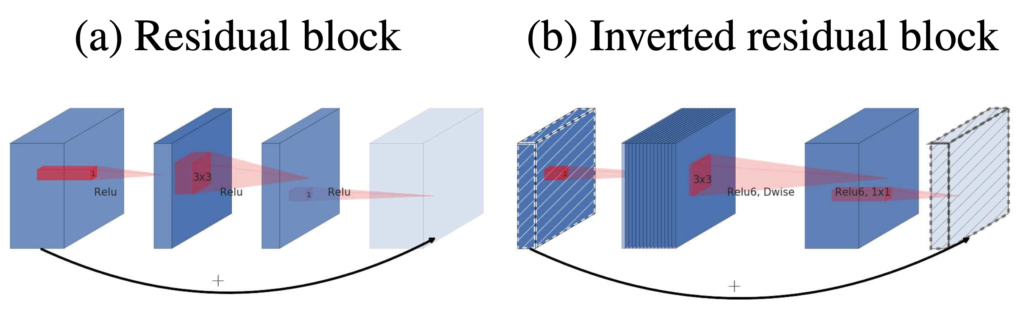
일반적인 residual block의 반대인 구조를 가집니다.
(a)기존의 residual block은 wide → narrow → wide 구조로 layer가 있고 wide layer끼리 연결을 추가한 방식을 사용합니다. 이때 narrow layer가 bottleneck 구조를 만들어줍니다. 즉 처음 입력은 채널이 많은 wide 한 상태이고 1×1 convolution 연산을 통해 채널을 줄이고 다음 layer에서 bottleneck을 만드는 구조입니다. bottleneck에서는 3×3 convolution 연산을 사용하여 skip connection으로 합쳐지면서 원래의 사이즈로 복원되게 됩니다.
(b)inverted residual block의 구조를 보면 narrow → wide → narrow layer 구조로 있고 narrow layer끼리 연결이 되어있는 것을 볼 수 있습니다. 이런 구조를 가지는 이유는 저차원의 layer에서는 필요한 정보만 압축된 채로 저장이 되어 있다고 가정하기 때문입니다. 즉, 필요한 정보는 narrow layer에 이미 있기 때문에 skip connection으로 사용해도 정보를 더 깊은 layer까지 전달할 수 있습니다. 또한 이렇게 압축된 narrow layer를 skip connection 으로 이용하면 메모리 사용량 또한 줄이는 이득까지 얻을 수 있습니다.
3.4. Information flow interpretation
expressiveness of the transformation으로부터 입출력의 도메인을 분리하는 것에 대해 알아보도록 하겠습니다. 아키텍처의 한 가지 흥미로운 특성은 bottleneck layer의 입력과 출력에 대한 도메인과 계층 변환 간의 자연스러운 분리를 제공한다는 것입니다. 즉, 입력을 출력으로 변환하는 비선형 함수입니다. 내부 레이어의 깊이가 0인 경우, underlying convolution은 shortcut connection 덕분에 identity function이 됩니다. expansion ratio가 1보다 작을 때, 해당 경우는 residual block입니다. 하지만 저자들이 제안한 목적을 위해선 1보다 큰 expansion ratio 비율이 가장 유용하다는 것을 보여줍니다. 이러한 interpretation을 통해서 네트워크의 expressiveness를 capacity와 별도로 연구할 수 있으며, 네트워크 속성에 대한 더 나은 이해를 제공하기 위해 입출력의 도메인을 분리하는 것에 대한 추가적인 탐구가 보장된다고 믿는다고 합니다.
4. Model Architecture

위 표는 아키텍처를 나타낸 표입니다. k는 bottleneck residual block을 통해 k → k' 채널로 변하게 됩니다. s는 stride를 나타내고, t는 expansion factor에 해당합니다.
MobileNetV2 는 처음에는 Fully convolution layer 이후, 19개의 residual bottleneck을 이루고 있습니다. 해당 저자들은 activation function으로 ReLU6를 사용했다고 하는데 이는 비선형성을 가지고 있기 때문입니다.
이러한 비선형성은 low-precision에 대한 연산에 사용하면 robustness하기 때문이라고 합니다. 해당 아키텍처는 무조건 커널 크기는 3×3의 구조를 이루고 있다고 합니다. 학습시에는 dropout과 BN을 적용했다고 합니다.
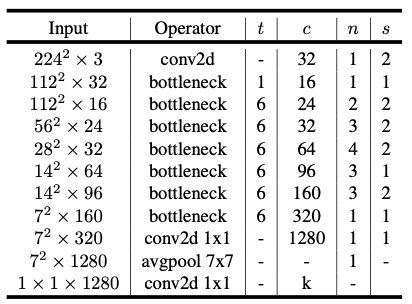
위 그림을 보시면, 첫 번째 레이어는 기본적인 convolution 이므로 제외하고, 그 다음 bottleneck으로 부터 expansion rate를 조절하면서 실험을 했는데, 이때 5~10 사이를 적용했다고 합니다. 최종적으로 실험을 통해 expansion factor를 6으로 적용했다고 합니다.
Trade-off hyper parameters
다양한 성능에 대한 performance points에 맞게 조정을 합니다. 입력 이미지의 해상도와 너비에 대해 multiplier 를 조정 가능한 하이퍼 파라미터로 사용하여 원하는 정확도 및 성능의 trade-off 관계를 고려하여 조정할 수 있습니다.
primary network(multiplier=1, resolution=(224, 224)는 computational cost가 300MMAdds이고 340만개의 파라미터를 사용합니다.
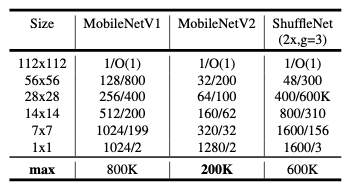
저자는 성능에 대한 trade-off 를 고려하여 입력 영상의 해상도를 96에서 224로, 너비 multiplier를 0.35에서 1.4로 실험을 했습니다. 해당 네트워크의 computational cost의 범위는 7MMAdds ~ 585MMAdds 였다고 합니다. 반면에 모델의 크기는 1.7M과 6.9M개 사이의 파라미터로 다양했다고 합니다.
5. Implementation Notes
5.1. Memory efficient inference
경량화 모델은 모델이 작아진 만큼 computational cost가 줄었기 때문에 inference time이 줄 것에 대한 기대 또한 할 수 있습니다. 그런 부분에서 생각해봤을 때, inverted residual bottleneck layers는 실제로 메모리 측면에서 효율적입니다. 이는 모바일 어플리케이션에서 매우 중요한 부분입니다.
6. Experiments
6.1. ImageNet Classification
Training setup
학습은 TensorFlow를 사용하였고, Optimizer는 RMSProp(decay=0.9, momentum=0.9)를 사용했다고 합니다. 또한 Batch Normalization을 모든 층에 적용시켰고, standard weight decay를 4*e-5로 설정을 하였습니다.
Results
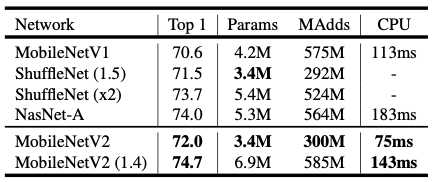
위 표는 이전 버전의 모델인 MobileNetV1과 다른 경량화 모델인 ShuffleNet, NASNet-A 모델과 비교를 한 표입니다.
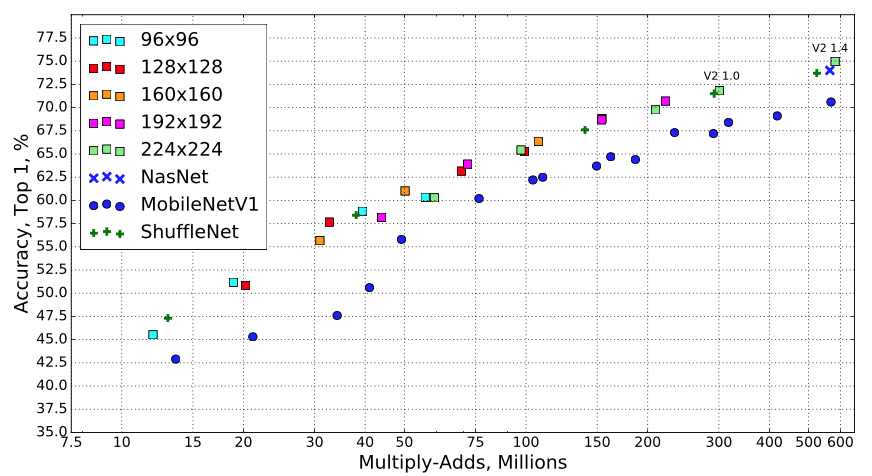
위 그림은 각 MobileNetV2와 다른 경량화 모델에 대한 비교를 MMadds에 따른 정확도로 나타낸 그래프 입니다. 이때 MobileNetV2 의 모든 해상도에 대해서는 multiplier를 [0.35, 0.5, 0.75, 1.0]로 사용하였고, 224의 해상도에 대해서는 1.4를 추가로 사용했다고 합니다. 연산량과 정확도에 대한 trade-off가 두드러지게 나타나는 것을 알 수 있습니다.
6.2. Object Detection
저자는 mobile 및 real-time 의 성능을 비교하기 위해 2-Stage의 모델에 대해서는 비교하지 않고 1-Stage Detection 모델인 SSD을 작게 만든 SSDLite와 YOLOv2에 대해 성능비교를 하였습니다.
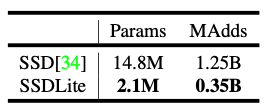
- 해당 표는 기존의 SSD와 SSDLite 모델에 대한 파라미터 수와 computational cost를 비교한 표입니다. 파라미터의 수는 7배 정도, cost는 3.5배 정도 차이가 나네요.
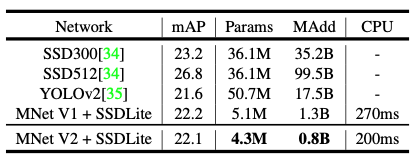
- SSDLite에 MobileNetV1을 적용한 것과 V2를 적용한 것에 대한 성능 분석을 위한 표입니다. mAP는 0.1떨어지지만 파라미터의 수도 줄이고 MAdd 또한 줄였으며 inference time 또한 줄인 것을 볼 수 있습니다.
6.4. Ablation study
Inverted residual connections
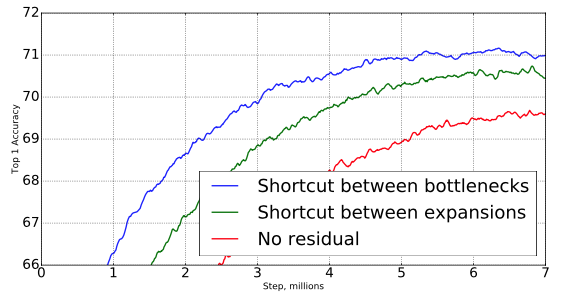
residual connection의 중요성은 광범위 하게 연구되어 왔습니다. 이 논문에서 reporting된 새로운 결과는 shortcut connecting bottleneck이 shortcut connecting the expanded layers 보다 성능이 더 좋은 것을 알 수 있다는 것입니다.
Importance of linear bottlenecks
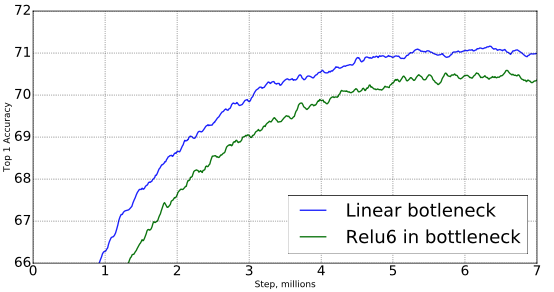
Linear bottleneck 모델은 non-linear을 가진 모델보다 절대로 강력할 수 없습니다. Activation function은 항상 bias와 scaling에 적절한 변형을 가하면서 선형적인 체제(linear regime)에 동작하도록 하기 때문입니다. 하지만 해당 논문에서의 실험은 linear bottleneck이 성능을 향상시키는 것을 보여주었고, non-linearity가 저차원 공간의 정보를 파괴한다는 것을 나타냅니다.
7. Conclusions and future work
저자는 매우 적인 모바일 모델의 제품군을 구축할 수 있는 매우 간단한 네트워크 아키텍처를 설명하였습니다. 기본적인 builing unit은 특히 모바일 어플리케이션에 적합한 몇 가지 특성을 가지고 있습니다. 매우 효율적인 메모리 연산에 대한 inference를 사용하고 모든 신경망에는 standard operation을 사용했습니다.
ImageNet 데이터셋에서 해당 MobileNet은 SOTA를 달성하였고 Object detection에서도 real-time에 대한 SOTA를 달성하였습니다. 특히, MobileNetV2와 SSDLite와 조합했을 때 YOLOv2 보다 파라미터의 개수가 10배, computational cost가 20배 정도 차이가 났습니다.
이론적 측면에서 제안된 convolution 블록은 네트워크의 expressiveness와 capacity를 분리할 수 있는 고유한 특성을 가지고 있습니다. 이에 대한 연구를 하는 것은 향후 연구를 위한 중요한 방향이라고 제시합니다.
좋은 리뷰 감사합니다.
리뷰를 읽고 질문이 있습니다. Information flow interpretation 부분에서 질문이 있는데, 도메인과 계층 변환 간의 자연스러운 분리를 제공한다는 것의 의미가 잘 와닿지 않습니다.
해당 부분은 bottleneck layer의 관한 설명으로 bottleneck의 내부를 외부보다 더 크게 함으로써 입력/출력 시 압축된 특징을 전달하는 것으로 이해하였습니다. 그렇다면 activation을 사용하지 않음으로써 손실되는 정보를 줄인다는 의미인가요?
혜원님, 안녕하세요.
리뷰 읽어주셔서 감사합니다.
해당 질문에 대해 답변을 드리면 bottleneck을 통과할 때 입력/출력에 대한 도메인이 달라져 자연스러운 분리가 된다라고 표현을 한 것 같습니다. 자세히 말하자면, bottleneck layer의 입력/출력 도메인과 입력을 출력으로 변환하는 non-linear function인 계층 변환 간의 자연스러운 분리를 제공한다는 의미입니다. 좀 더 자세하게 얘기해보면 모델이 입력 데이터의 특성을 이해하고 변환할 수 있으며, 도메인 간의 변환을 통해 다양한 입력 형식에 대해 유연하게 작동할 수 있다는 것을 의미하게 됩니다.
감사합니다.
안녕하세요 양희진 연구원님. 첫 X-Review 잘 읽었습니다.
MobileNet V1은 예전에 읽은 적이 있지만.. MobileNet V2가 있는 것은 알고 있었지만 리뷰를 통해 알게 되었습니다. 우선 MobileNet V2에 대한 설명을 위해서는 MobileNet V1의 핵심 Contribution을 짚고 넘어가는 것이 중요하겠으며, 해당 부분에 대해 Point-wise, Depth-wise Convolution을 설명해주셨지만 해당 설명만으로는 이해가 쉽지 않습니다. 모델의 경량화 측면, 즉 Embedded, Mobile Platfform을 위한 모델을 위해 고안한 네트워크인 본 네트워크가 성능 혹은 실제 Memory Used 측면에서 강점이 뚜렷한지를 실험단에서 잘 읽었습니다만, Trade-off 관계가 강하지 않고, 즉 성능의 저하는 큰 차이 없는데 (SSD에서는 1%의 mAP 저하에 반해) Params는 9배나 줄일 수 있었던, 그 이유에 대한 희진님의 고찰이 궁금합니다.
그렇다면 해당 방법에서 성능의 저하를 조금 더 가져가더라도, Params나 MAdds (MAdds는 어떤 것인가요?) 를 더 큰 폭으로 줄일 수 있을지도 궁금합니다.
리뷰에서 Maniford-of-Interest를 보존하는 방법론으로 Linear Bottleneck을 말씀해주셨는데, Linear Bottleneck은 정확히 어떤 것인가요? 해당 Bottleneck 레이어가 왜 필요한지에 대해서는 이해됩니다만.. 해당 레이어 또한 태스크의 목적인 Params를 늘리는 데에 기여하지 않나요..?
Inverted Residual Block은 그 핵심 개념을 잘 말씀해주셔서 이해가 쉬웠습니다. 그렇다면, 중간 단의 Wide한 레이어를 연결한 것에 대한 실험이 있을까요? 저자는 Narrow layer가 Maniford-of-Interest를 주로 갖고 있기에 이들만을 연결하면 성능은 큰 변동이 없으며 동시에 params를 줄일 수 있다고 주장하는 것으로 보이나.. Wide를 연결했을 떄의 성능 변동이 궁금하며 또한 희진님의 Narrow layer가 Maniford-of-Interest를 가지고 있다는 사실에 대한 고찰은 어떨까요? (Wide한 것이 Narrow한 것보다 더 많은 정보를 가지고 있지 않나요..? 그렇다면 Wide layer는 왜 필요한가요..?)
좋은 리뷰 잘 읽었습니다. 감사합니다.
상인님, 안녕하세요.
리뷰 읽어주셔서 감사합니다.
1. Point-wise, Depth-wise Convolution을 설명해주셨지만 해당 설명만으로는 이해가 쉽지 않습니다. 모델의 경량화 측면, 즉 Embedded, Mobile Platfform을 위한 모델을 위해 고안한 네트워크인 본 네트워크가 성능 혹은 실제 Memory Used 측면에서 강점이 뚜렷한지를 실험단에서 잘 읽었습니다만, Trade-off 관계가 강하지 않고, 즉 성능의 저하는 큰 차이 없는데 (SSD에서는 1%의 mAP 저하에 반해) Params는 9배나 줄일 수 있었던, 그 이유에 대한 희진님의 고찰이 궁금합니다.
– https://gaussian37.github.io/dl-concept-dwsconv/ 를 참고하여 작성하였습니다
– 기존의 convolution은 입력된 필터에 대한 동일한 필터를 사용하지만, 메모리 측면에서 효율성을 보여주는 부분은 Depthwise convolution 입니다. 채널마다 독립적인 convolution 연산을 통해 메모리 연산량에 대한 효율적인 가능합니다.
– 일반적인 convolution 연산량을 살펴보면 곱연산에 대해 NxMxD_G^2xD_K^2 의 computational cost가 발생합니다. 하지만 Depthwise separable convolution 과정에서는 MxD_G^2(D_K^2+N) 의 computational cost이 발생하게 됩니다.
– 여기서 D는 width, height , D_K는 필터 D_G는 output의 width, height 크기를 의미합니다.
– 이때, 연산량이 어느정도로 줄었는지에 대한 비율을 확인하기 위해 ratio를 분자에 Depthwise seperable convolution 에 대한 연산량 분모에 standard convolution로 두면 구할 수 있습니다, 예를 들어 N=1024, K=3 으로했을 때 0.9정도의 연산량이 줄어든 것을 확인 할 수 있습니다.
2. 해당 방법에서 성능의 저하를 조금 더 가져가더라도, Params나 MAdds (MAdds는 어떤 것인가요?) 를 더 큰 폭으로 줄일 수 있을지도 궁금합니다.
– MAdds는 Multiply-adds 로 conputational cost를 의미합니다.
– 성능과 computational cost는 서로 trade-off 관계이므로 말씀하신대로 파라미터 수와 연산량 측면에서는 좋은 결과를 가져올 수 있지만 성능에 대한 기대는 하기어려울 것 같습니다.
3. Bottleneck은 정확히 어떤 것인가요? 해당 Bottleneck 레이어가 왜 필요한지에 대해서는 이해됩니다만.. 해당 레이어 또한 태스크의 목적인 Params를 늘리는 데에 기여하지 않나요..?
– 해당 연산이 추가되어 파라미터 수가 늘었다기 보다는 저차원의 feature map을 생성하고 해당 feature map을 고차원으로 확장하는 것은 computational cost를 줄이는 효과가 있기 때문에 bottleneck layer를 ResNet에서도 사용한 것으로 알고 있습니다.
4. Inverted Residual Block은 그 핵심 개념을 잘 말씀해주셔서 이해가 쉬웠습니다. 그렇다면, 중간 단의 Wide한 레이어를 연결한 것에 대한 실험이 있을까요? 저자는 Narrow layer가 Maniford-of-Interest를 주로 갖고 있기에 이들만을 연결하면 성능은 큰 변동이 없으며 동시에 params를 줄일 수 있다고 주장하는 것으로 보이나.. Wide를 연결했을 떄의 성능 변동이 궁금하며 또한 희진님의 Narrow layer가 Maniford-of-Interest를 가지고 있다는 사실에 대한 고찰은 어떨까요? (Wide한 것이 Narrow한 것보다 더 많은 정보를 가지고 있지 않나요..? 그렇다면 Wide layer는 왜 필요한가요..?)
– 다른 실험 결과는 없고, 저러한 구조를 가진 block을 구성하여 실험을 진행한 것으로 알고 있습니다. 상인님의 말씀대로 wide layer에서 manifold of interest에 대한 정보를 더 많이 가지고 있는게 맞습니다. 하지만, 해당 논문에서 narrow를 사용한 이유는 narrow에서도 충분한 정보들이 이미 저장이 되어있기 때문에 skip connection으로 사용한 것입니다.
– wide를 연결하면 안되는지에 대한 질문 내용이 narrow → wide → wide에 대한 질문이라면 skip connection 을 사용할 때 입력이 narrow에 대한 정보를 그대로 전달하기 위해 입력에 맞춰서 연결을 해줘야 하는 것으로 알고 있습니다. 그러므로 inverted 형태이므로 narrow는 narrow에 맞게 전달을 한 것으로 보입니다.
– expansion layer를 사용하는 이유는 저차원의 feature map을 고차원의 feature map을 생성하여 모델의 representation power를 향상시킬 수 있기 때문입니다.
안녕하세요. 리뷰 잘 읽었습니다.
MobileNetV2에서 가장 중요한 점은 앞서 설명해주신 mainfold of interest 부분이 아닐까 항상 생각은 하고 있습니다만 그 개념을 linear bottleneck과 연결하기는 어렵더라구요. 그래서 궁금한 것이 리뷰 내용에서 “결국 manifold of interest의 정보는 결국 비선형 activation function인 ReLU와 같은 것(ReLU의 식을 생각해보면 0이 아닌 양수 값을 가진다면 linear transformation 연산과 같음)이기 때문에 일부 소실될 수 있다고 얘기합니다. 만약 이러한 ReLU가 채널에 대한 정보를 붕괴시킨다면 해당 채널에서 정보가 손실되는 것은 피할 수 없게 됩니다. 하지만, 채널이 위 그림처럼 충분히 많다면 정보가 다른 채널에서는 어느정도 살아있을 수 있다는 것을 나타내는 그림입니다.” << 라는 내용이 있습니다. 제가 이해한 바로는 정보 손실이 최소화된 manifold of interest가 존재하는 embedding space를 찾기 위해서 ReLU 같은 activation 연산 없이 곧바로 차원을 줄이는 Linear bottleneck block을 통과시킨 것으로 이해하였습니다. 근데 또 해당 글에서는 manifold of interest는 결국 중요한 정보만을 남기고 손실이 된 것이기 때문에 ReLU activation을 적용한 것과 유사하다고 볼 수 있다라는 식으로도 말씀하셨습니다. 그렇다면 그냥 ReLU 함수 쓰면 되는 것 아닌가요? 왜 ReLU 대신에 Linear bottleneck block을 활용해야만 하나요? MobileNet의 근본적인 목표인 연산량을 줄이기 위해 차원을 직접적으로 줄이는 layer 연산이 필요해서 인가요? 그렇다면 ReLU와 Bottleneck block을 동시에 사용하면 안되나요? 그렇게 되면 ReLU로 인한 정보 손실 + 차원 축소로 인한 정보 손실 합쳐서 정보 손실이 심해지기에 또 문제가 될까요? 무언가 리뷰에 작성해주신 설명만을 보면, ReLU와 Linear bottlneck block이 서로 비슷한 역할을 수행한다는 것처럼 말씀해주셨는데 결국 저자가 ReLU 대신 Linear bottlneck block을 활용할 수 밖에 없었던 이유가 딱히 없는 것 같아서 서로의 차별점을 좀 더 설명해주시면 좋겠습니다.
사이트 오류? 때문인지 문장 사이 문단을 띄었는데도 한 문단처럼 딱 붙어서 보이네요. 관리자 사이트에서는 제대로 보이는 듯 하니 가독성 좋게 보시려면 그쪽에서 확인하면 좋을 듯 합니다.
안녕하세요, 정민님. 리뷰 읽어주셔서 감사합니다.
먼저 ReLU 대신 Linear Bottleneck layer를 사용한 이유는 1×1 pointwise convolution을 통해 선형 변환을 수행하게 되는데, 이렇게 하는 이유는 차원의 축소의 효과 및 계산의 효율성을 위한 방법입니다. 다음 계층으로 넘겨줄 때 이루어지는 연산량을 줄이고 계산 효율성을 향상시키기 때문입니다. 즉, ReLU를 사용할 경우, 복잡한 representation에 대해 모델이 학습하기 때문에 computational cost가 크기 때문에 linear bottleneck layer 한 것 같습니다.
경량화 모델은 임베딩 디바이스 환경을 고려하여 모델의 계산 비용을 줄이고 파라미터 수를 감소시키면서도 효율성과 성능을 유지하는 데 초점을 맞추었기 때문에 ReLU 대신 Linear Bottleneck Block을 활용했다고 생각합니다.
감사합니다.