첫 X-review입니다 . . 원래는 다른 논문을 읽고 있었는데, 익명의 누군가가 깜!짝 놀라며 바꾸라고 조언하였기도 하고 처음이기도 해서 X-review 맛보기로 좀 쉽고 가벼운 논문으로 들고 왔습니다. 본 논문은 18년도 CVPR에 게재된 An Analysis of Scale Incariance in Object Detection입니다. 그럼 바로 시작하겠습니다 ㅎㅎ

Introduction
논문에서는 AlexNet이 등장하면서 ImageNet Classification에서 top-5 error가 15%에서 2%로 떨어지게 되었지만, 그에 비하여 Object Detection은 보다 낮은 오직 62%의 mAP를 보인다며 아래와 같은 질문을 던지고 있습니다.
Why is object detection so much harder than image classification?
무엇 때문에 Object detection이 Image Classification보다 더 어렵냐는 것인데요, 이에 대한 이유로 데이터셋의 차이를 언급합니다. Image Classification에서 자주 사용하는 데이터셋인 ImageNet과 Object detection에서 자주 사용하는 데이터셋인 MSCOCO의 비교 그래프는 다음과 같습니다.
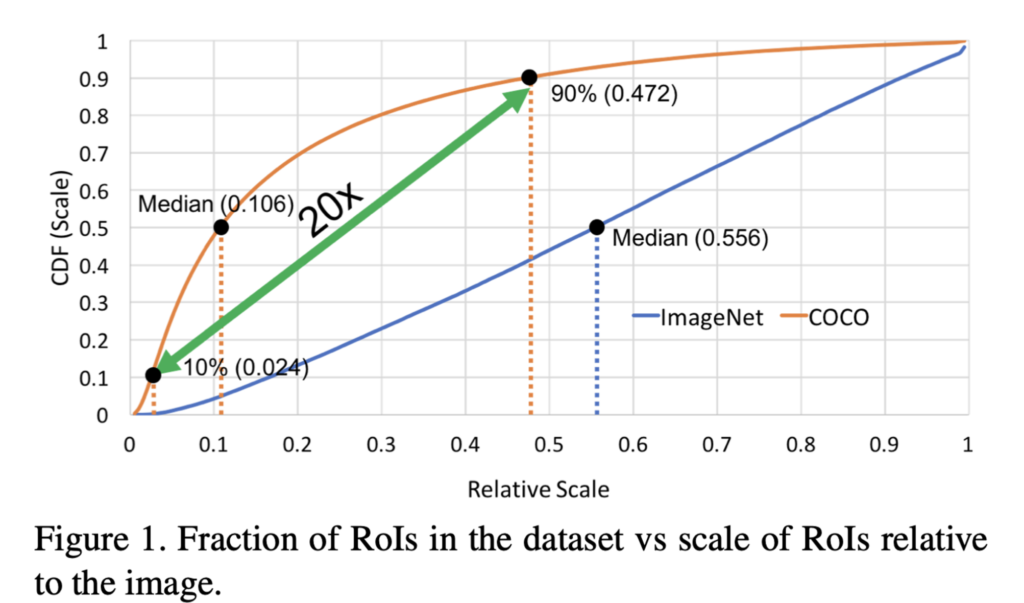
x축은 Object의 상대적인 Scale을 나타냅니다. (이미지 안에서 객체가 크면 1, 작으면 0에 가까움)
그래프를 보시면 COCO dataset(주황색)의 전반적인 Object가 small Object라는 것과(Median이 0.106), object간의 scale variation이 20배 정도로 굉장히 크다는 것을 볼 수 있습니다. 또한 두 dataset의 scale에 있어서 large domain-shift가 존재합니다. 두 데이터간 domain shift가 문제가 되는 이유는 보통 detection model에서는 ImageNet으로 pre-trained된 model을 backbone으로 사용하는 경우가 많기에, 이때 ImageNet과 MSCOCO 사이의 domain shift로 인하여 성능에 영향을 미칠 수 있기 때문입니다.
위에 언급한 scale variation과 small object에 대한 문제를 해결하기 위하여 많은 solution들이 제안되어왔는데, 논문에서 언급한 예로는 small object를 detect하기 위해 input과 가까이 있는 layer(shallow layer)를 deep layer랑 combined 시킨다던가, 서로 다른 resolution을 가지는 각 layer에서 prediction하는 방법, image pyramid, dilated/deformable convolution등이 언급되었습니다.
하지만 이런 방법들은 object detection에서 성능을 개선하는데 도움이 되었지만 몇몇 문제가 있었는데, 예를 들어 FPN, Mask-RCNN, RetinaNet 등의 방법은 shallow layer의 feature와 deep layer의 feature를 결합하여 pyramidal representation을 사용하므로 higher level의 semantic한 정보에 접근할 수 있지만 object의 크기가 25×25 pixel인 경우에는 train과정에서 2배로 upsampling해도 object를 최대 50×50 pixel로만 확대할 수 있다며 feature pyramid network에서 생성된 high level semantic feature은 small object를 분류하는데 적합하지 않다고 합니다. (high resolution image에서의 large object에서도 이와 같음)
Image Classification at Multiple Scales
그렇기에 일반적으로 object detection을 학습시키는 방법을 보면 COCO dataset 같은 경우 image size는 일반적으로 640×480인데, 이 이미지를 그대로 넣으면 small object에 대한 검출이 어렵기에 보통 up-scaling하여 학습을 시킵니다. 이 시점에서 저자는 또 한가지 질문을 던집니다.
Is it critical to upsample image for obtaining good performance for object detection?
CNN은 과연 up-sampling에 robust 하는가? 라는 질문인데요. 논문에서 이에 대한 해답을 얻기 위해 다음과 같은 실험을 하였습니다.
Naive Multi-Scale Inference

위의 그림과 같이 원본 이미지(224×224)를 48×48, 64×64, 80×80, 96×96, 128×128로 down-sampling하고 이를 다시 224×224로 up-sampling합니다. 이렇게 up-sampling된 이미지는 224×224의 원본 이미지로 학습된 CNN 모델에 input으로 집어넣어 accuracy를 확인해보고자 합니다.
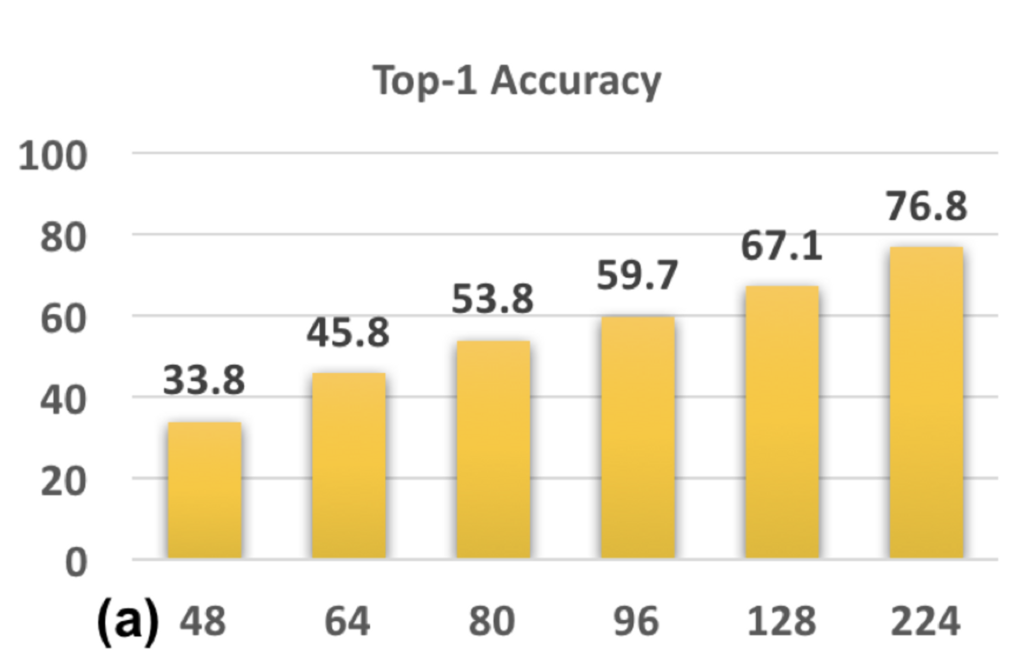
결과를 보면 training image와 testing image간의 scale 차이가 증가할수록 성능이 하락하는 것을 볼 수 있습니다. (x축이 down sampling된 scale) 따라서 CNN은 up-sampling에 robust하지 않다는 결론을 낼 수 있습니다. small object를 잘 잡기 위해 train time에 보지 못했던 scale을 넣어준 것 자체가 optimal한 방법은 아니라는 것입니다.
Resolution Specific Classifier
이에 대한 대안으로 다음 실험을 진행했는데, 다양한 scale의 image가 존재한다면, 다양한 network를 각각 만들어서 학습시키면 되지 않을까 하는 생각에 resolution specific model을 만들어 실험합니다.
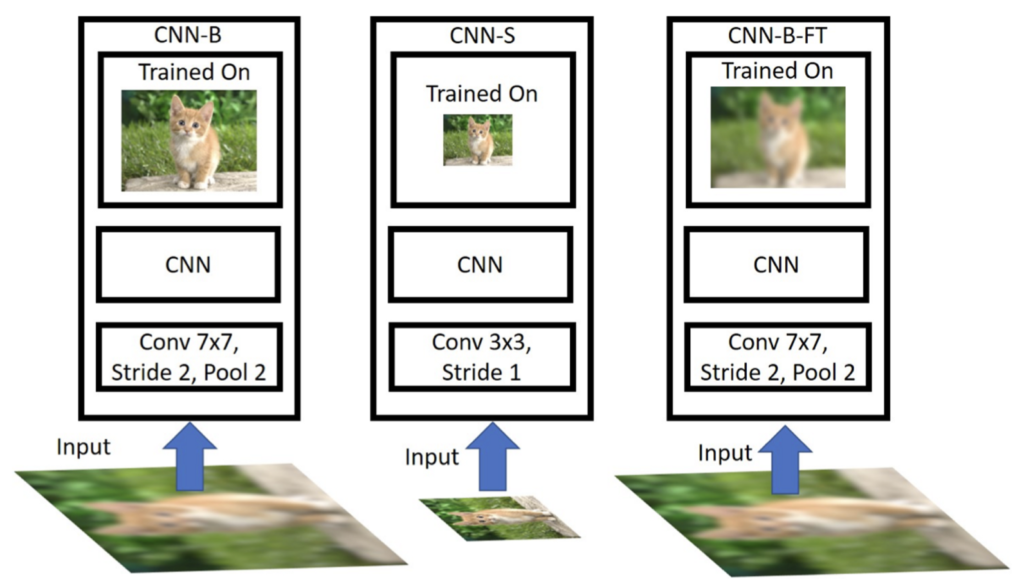
왼쪽 CNN-B가 앞서 실험한 원본 이미지로 학습한 것이고, 가운데 CNN-S는 downscailing된 이미지로 학습을 시키는 것입니다. (scale specific model) CNN-B의 경우는 원본 해상도로만 학습을 했기에 testing image의 resolution은 본 적 없는 모델이며, CNN-S의 경우에는 작은 해상도로 학습을 하는 것이 차이점입니다. CNN-S의 경우 down scailing된 이미지가 들어가기에 Model 디자인도 조금 바꿔 실험을 진행했습니다. (Conv 7×7, stride 2, Pool2 → Conv 3×3, stride 1)
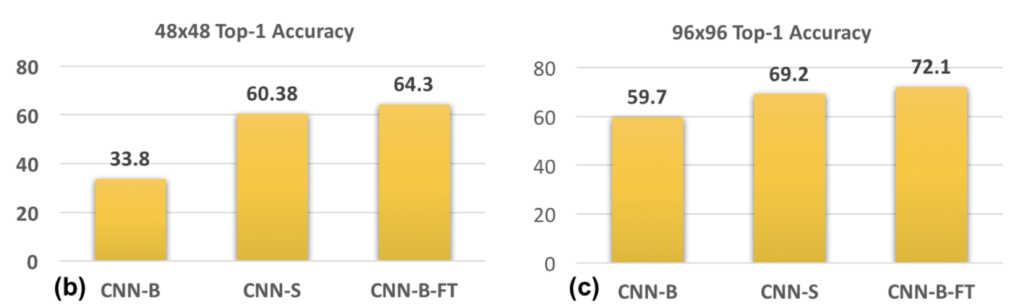
결과를 보면 CNN-S가 CNN-B보다 성능이 더 좋은 것을 볼 수 있습니다.
Fine-tuning High-Resolution Classifiers
마지막으로 한 실험은, 앞써 CNN-B의 성능이 잘 나오지 않았던 이유는 한번도 보지 못했던 scale 때문이라면, CNN-B를 다시 fine tuning하면 어떨까? 하여 진행한 실험입니다. 이는 그림에서 CNN-B-FT에 해당합니다. 위의 그래프에서 결과를 보면, CNN-B FT가 CNN-S보다 성능이 더 높다는 것을 볼 수 있습니다. 결과적으로 high resolution object에서 뽑은 feature들이 low resolution object를 detect하는데 도움이 된다는 것입니다.
Data Variation or Correct Scale?
직전 실험으로 training과 testing image간 resolution차이가 명확한 성능 하락을 보이는 것을 확인하였습니다. 이후 진행하는 실험은 Data variation과 scale variation에 관한 실험인데요, appearance와 pose를 최대한 많이, 다양하게 학습을 시키는 것이 좋으며(Maximize data variation), 앞서 확인한 것처럼 CNN이 scale 변화에 robust하지 않으니 scale 변화를 최대한으로 줄여보자(Minimize scale variation)는 것에 기반한 실험입니다.


Training at different resolutions
첫번째로는 맨 좌측 사진과 같이 train time에는 800×1200으로 학습을 시키고, test time에는 1400×2000으로 test한 경우입니다. 이 경우는 train time, test time사이에 scale 변화가 존재하는 경우라고 볼 수 있습니다. 이때는 19.6% mAP의 성능을 보입니다.
두번째로는 첫 번째 실험(800all)과 동일한 환경에서 train time에 들어가는 image가 1400×2000인 점만 다릅니다. 이는 train time과 test time에 동일한 resolution의 이미지가 들어가는 경우(scale 변화 X)이며, 19.9% mAP의 성능을 보입니다. 이렇게 scale 차이가 없음에도 첫 번째 실험의 성능과 별로 차이가 나지 않는 이유는 image의 scale을 키워 학습하게 되면 small object는 더 잘 학습시킬 수 있을지는 몰라도 의도치 않게 large object가 너무 커지기 때문에 CNN의 receptive field의 한계로 잘 학습되지 않는다고 저자가 주장하고 있습니다.
Scale specific detectors
이 문제를 해결하기 위해 80 Pixel 이상인 object는 배제한 채로 1400×2000 resolution으로 동일한 실험(1400<80px)을 진행하였지만, 16.4% mAP로 더 낮은 성능을 보였습니다. 이는 medium-to-large object(전체의 약 30%)를 무시함으로써 appearance와 pose에 대한 variation을 잃었기 때문입니다.
Multi-Scale Training (MST)
마지막으로 세 번째 사진처럼 multiple resolution으로 image를 random sampling한 scale-invariant detetor를 학습시킨 결과 성능은 19.5% mAP(800all 과 비슷한 성능)가 나왔는데, 그 이유로는 object가 너무 작아질수도, 너무 커질수도 있기 때문에 성능 저하에 영향을 미친다고 하였습니다.
이러한 실험들의 결론으로 논문에서는 object 간에 가능한 한 많은 variation을 가져가면서 그와 동시에 적절한 scale로 training하는 것이 중요하다고 판단하며 Scale Normalization for Image Pyramids(SNIP) 방법론(5.4)을 제안합니다.
Scale Normalization for Image Pyramids(SNIP)
결국 앞단의 실험을 통해 이 논문이 제안하는 것은 scale variation을 줄이기 위해 image pyramid 상에서 scale normalization을 하자는 것인데, 간단히 말하자면 작은 이미지에서는 large object를, 중간 크기의 이미지에서는 medium object, 큰 이미지에서는 small object를 학습시키는 것입니다. 이에 대한 성능으로는 위의 표를 보시면 21.4%로 이전의 실험들의 성능을 능가합니다.
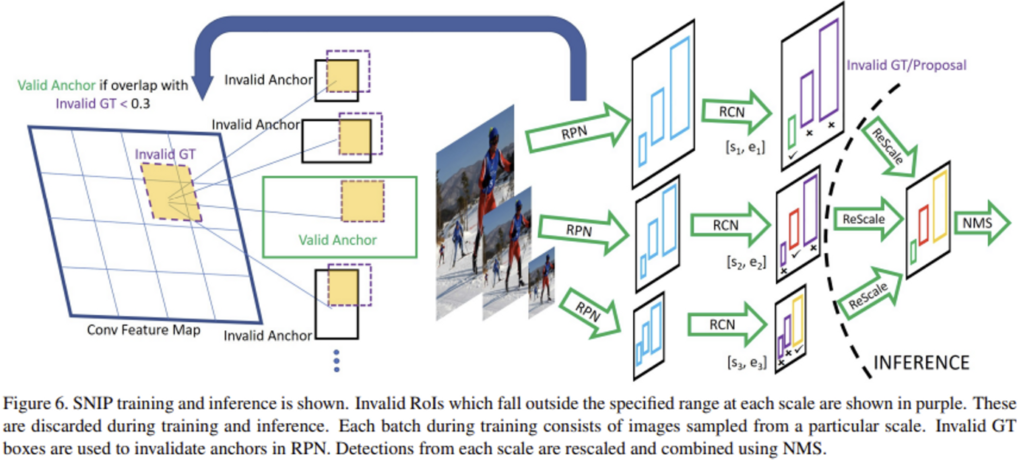
SNIP의 학습 과정을 살펴보면, 위 그림과 같이 Image Pyramid를 만들어놓고 RPN을 통해 서로 다른 resolution을 가진 이미지(1400×1200, 800×1200, 480×800)에서 각각의 Region Proposal을 뽑아냅니다. 그리고 뽑아낸 region proposal의 면적이 미리 설정해둔 특정 range안에 들어가는 것만 유효한 region proposal로 골라냅니다. (1400×1200에서는 [0, 80], 800×1200에서는 [40, 160], 480×800에서는 [120, ∞]) Backpropagation 과정에서도 이렇게 유효한 범위 내에서 뽑힌 것들로만 사용하여 학습을 진행하며, test 할 때는 마찬가지로 각 resolution에서 RPN을 사용하여 proposal을 생성하고, 범위 안에 해당하는 proposal들만 rescale하여 soft-NMS를 사용하여 detect하게 됩니다.
다양한 scale의 object proposal을 생성하는 RPN은 gound truth box와 anchor box 간의 overlap을 계산하고, 일정 threshold(0.3) 이상인 anchor box를 positive anchor로 분류하며, image에 포함되지 않는 크기의 anchor box나 이미지와 겹치지 않는 anchor box는 negative anchor로 분류하여 positive anchor만으로 학습을 진행합니다.
결론적으로 small object도 잘 검출하면서 scale variance를 줄이기 위해 scale normalization을 해주자는 것이 이 논문의 핵심인데, scale normalization에서 normalization의 기준은 기존 pre-trained된 모델의 Dataset입니다. 이렇게 함으로써 글의 앞단에서 언급한 문제인 domain-shift 문제를 해결해줄 수 있게 됩니다.
Experiments
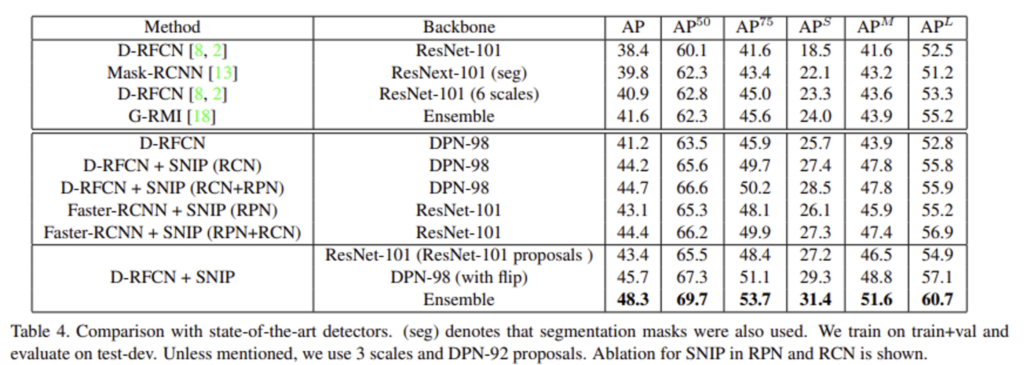
논문에서는 D-RFCN과 Faster-RCNN을 이용하여 실험을 진행하였고, SNIP를 사용한 것이 성능이 가장 높은 것을 볼 수 있습니다. 하지만, D-RFCN 방법론에 Backbone으로 DPN-98을 사용하여 실험한 부분을 보면 논문에서 전반적으로 small object에 대한 성능을 올리고자 SNIP방법론을 제시하였다고 서술한 것에 비하여 AP_{s}가 크게 증가한 것 같지 않습니다 . . . 또, SNIP을 사용하면 training time이 두 배 정도 늘어난다는 단점이 있다고 하네요 . . .
이 저자들이 SNIP의 후속작으로 SNIPER 논문을 냈는데요, 본 논문을 읽다가 코드도 같이 보고 싶어 공개된 깃허브에 들어갔지만 , , , 제가 찾지 못한건지는 몰라도 SNIPER 코드밖에 없더라구요 . . 아쉬운 마음 안고 글 마무리 하도록 하겠습니다. ?
안녕하세요. 논문도 재밌고 깔끔하게 정리가 되어 있어 읽기 편한 리뷰였던 것 같습니다.
URP 때 small object 잡으려고 고생한 추억이 떠오르네요…
리뷰를 읽고 한가지 의문이 생겼는데, 마지막 부분에 scale normalization을 pre-trained 모델의 dataset을 기준으로 한다고 하였는데, 이는 scale normalization의 기준이 되는 object scale의 범위를 pre-trained 모델의 dataset으로 한다는 것인가요? 아니면, scale normalization 과정을 pre-trained model의 dataset으로 하고 fine tuning은 다른 데이터셋으로 하는 것인가요?
전자라면 결국 pre-trained 모델은 다른 domain에서 학습된 것은 그대로인데, 어떻게 domain shift 문제가 해결되는지 궁굼합니당.
감사합니다. 🙂
후자가 맞습니다. pre-trained model 기준으로 object instance를 선택하여 학습을 진행하며, 이후 fine tuning은 다른 데이터셋을 이용합니다. !
윤서님의 첫 리뷰 잘 봤습니다.
실험적 분석이 꽤나 흥미로운 논문이군요.
우선 성능적인 비교 말고 모델 추론 속도나 파라미터 수에 대한 분석이 있는지 궁금합니다. 또한 해당 논문을 읽게 된 계기도 궁금하네요 ㅎㅎ
감사합니다.
본 글 마지막 단에도 적어뒀듯이 SNIP을 적용하게 되면 에포크당 traing time이 2배로 늘어나게 되며, 파라미터 수에 대한 분석은 언급이 되어 있지는 않네요 . .
해당 논문을 읽게 된 계기는 . . 맨 앞단에 적어두었는데 small object에 대한 성능 개선에 관심이 있었기 보다는 ,, 첫 X-review기념 조금 읽고 쓰기 조금 가벼운 논문을 찾다보니 읽게 되었습니다. . ㅎ,,ㅎ
안녕하세요 좋은 리뷰 감사합니다.
feature의 resolution에 따라 서로 다른 크기의 object를 찾음으로써 object의 scale normalization을 진행할 수 있다는 점이 흥미로웠습니다. 실험 부분에서 간단한 의문이 있는데 D-RFCN+SNIP(RCN)과 D-RFCN+SNIP (with flip)의 차이가 무엇인가요? 같은 backbone에 SNIP을 적용한 것은 동일한데 전체적인 성능이 약 2%정도 상승한 것이 신기합니다.
D-RFCN+SNIP(RCN)과 D-RFCN+SNIP (with flip)의 차이는 논문에 딱히 언급되어 있지 않습니다. 아마 예상하건데, 전체 모델 구조는 동일하며 flip augmentation 적용 여부 차이만 있는 것 같습니다.