Before Review
간만에 Temporal Action Localization 관련 논문 리뷰 입니다.
NIPS에 억셉된 논문이기도 하고 논문제목에도 Optimization이라는 키워드가 있어서 뭔가 나름 ML스러운 접근으로 Action Localization을 해결한 논문인 줄 알았으나 생각보다는 평범했던 논문이라 아쉬움이 남았습니다.
리뷰 시작하도록 하겠습니다.
Introduction
Temporal Action Localization은 길이가 긴 Untrimmed Video에 대해서 비디오 내부에 존재하는 사전에 정의된 Action Category에 해당되는 Segment를 예측하는 작업을 의미합니다. Temporal Action Localization의 핵심은 Boundary를 잘 예측하는 것이 중요하기 때문에 시간 축에 대해서 민감하게 반응해야합니다. 즉, Action과 Background의 경계에 있어서는 feature가 잘 구분되어야 한다는 의미입니다.
보통의 Temporal Action Localization은 Kinetics라는 Action Classification 용도의 데이터셋으로 사전학습된 Video Encoder를 가지고 feature extraction을 해놓고 진행이 됩니다. 그런데 이 과정에서 한가지 문제가 발생합니다. 사전학습은 Action Classification으로 진행하고 Down-stream Task는 Action Localization을 한다는 것이죠.
Action Classification은 시간 축에 대해서 민감하게 반응하지 않습니다. 길이가 5초, 10초 20초 이든 같은 action class라면 동일한 output을 가지도록 학습을 하지만 Action Localization은 시간 축에 대해서 민감하게 반응하는 것이 중요합니다.
이에 저자는 Temporal Action Localization을 위한 새로운 사전학습 기법을 제안하였습니다.
저의 지난 리뷰였던 TSP라는 Temporal Action Localization을 위한 사전학습 피쳐가 있지만 이것은 Supervised 방식이라는 한계가 있습니다. Supervised 방식은 항상 Annotation이 정확히 완료된 데이터셋을 요구로 하기 때문에 다양한 상황에서 사용되기는 쉽지 않습니다. 기존에도 Temporal Action Localization을 위한 사전학습 방법론들이 있지만 모두 Supervised 기반이었습니다. 이에 저자는 처음으론 Self-Supervised 기반의 Temporal Localization 사전학습 방식을 제안합니다. 이것이 본 논문의 핵심이지요.
또한 저의 지난 리뷰였던 BSP라는 논문이 있는데 핵심은 Large-Scale의 Temporal Action Classification용 데이터셋인 Kinetics라는 데이터셋을 이용하여 Temporal Boundary를 찾는데 적합한 데이터셋으로 새롭게 만들어주는 것이 핵심입니다. BSP는 서로 다른 두 action Video를 Cut-Paste 하는 방식으로 진행이 되었는데 여기서 비디오가 어떤 action category인지 알아야 한다는 점이 있어 Classification label 정보를 알아야 한다는 한계가 있습니다.
본 논문은 TSP나 BSP 처럼 Action Localization을 위한 사전학습 방법을 제안하는 연구 입니다.
다만 여기서 위의 연구(TSP, BSP)들은 task discrepency 문제를 해결하기 위해 사전 학습 단계부터 다시 시작합니다. Localization을 위한 사전 학습을 다시 정의하는 것이죠. 이렇게 되면 사전 학습부터 다시 시작하게 되니 아무래도 시간이 오래 걸리긴 하겠네요.
저자는 일단 사전학습 자체는 Action Classification으로 진행하고 Action Localization으로 넘어가기 전에 새로운 학습을 제안합니다. 이 과정에서는 Video Encoder와 Localization Head가 같이 학습이 됩니다. 즉 End-to-End 방식으로 학습을 하겠다는 것 입니다.
End-to-End 방식으로 학습하면 무엇이 좋을까요? 바로 Classification으로 사전학습된 Video Encoder를 다시 Localization Loss를 통해서 업데이트 시키면서 task discrepency 문제를 해결할 수 있다는 점 입니다. 그런데 Localization에서 사용되는 데이터셋은 Classification을 위해 사용되는 데이터셋에 비해 비디오의 길이가 훨씬 깁니다. 따라서 End-to-End 방식으로 학습을 시키기 위해서는 상당히 많은 GPU memory를 요구한다는 것 입니다.
이에 저자는 End-to-End 방식으로 학습을 할 때는 중요한 것이 효율적으로 학습 방법을 고안하여 기존의 GPU memory만을 가지고도 충분히 학습이 가능해야 한다는 점 입니다. 이를 위해 저자는 Low-Fidelity(이하 LoFi) Optimization을 제안합니다.
LoFi의 핵심은 입력으로 들어가는 데이터의 spatial resolution이나 temporal length를 인위적으로 줄여서 GPU memory를 아끼는 것 입니다. Classification으로 사전학습이 끝나고 Localization Head를 fine tune 하기전에 LoFi 방식으로 End-to-End 방식으로 학습 시켜야 task discrepency를 해결할 수 있다는 것이죠.
서론은 이쯤으로 하고 본격적으로 저자가 어떤 방법을 제시했는지 같이 알아보도록 하겠습니다.
Method
Method가 굉장히 간단합니다. 저도 이번에 찾아보면서 알았는데 Low-Fidelity라는 의미가 “저품질”이라는 의미로 사용이 된다고 합니다. 그렇다면 무엇을 저품질로 가져갈 것이냐 인데 결국 데이터를 저품질로 가져가는 것 입니다.
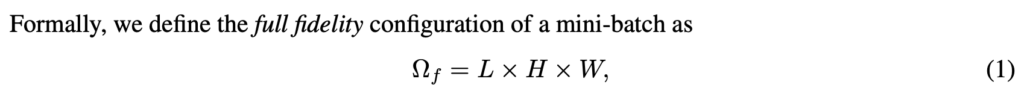
우선 full fidelity는 데이터를 온전하게 전부 사용하는 것을 의미합니다.
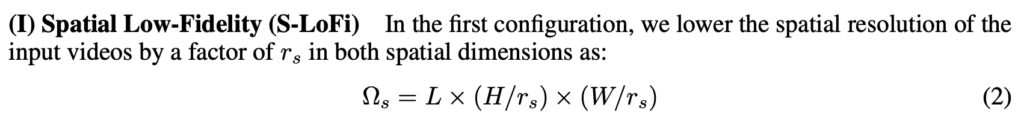
다음으로 Spatial Low-Fidelity (S-LoFi)는 입력 데이터에 대해서 Height나 Width에 대해서 scaling을 진행하여 데이터의 사이즈를 줄이고 이를 통해 memory 적으로 이득을 보겠다는 의미입니다. End-to-End 방식에서는 메모리를 줄이는 것이 중요하다고 위에서 설명했기 때문이죠.
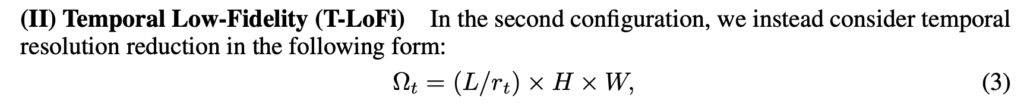
Temporal Low-Fidelity는 Temporal 축에 대해서 scaling을 진행합니다. 사실 그냥 프레임을 뽑을 때 비디오 전체를 보는게 아니라 비디오의 일부 구간만을 샘플링한다고 생각하시면 됩니다. 예를 들어 100초짜리 비디오가 있다면 그 중 5초 정도만 사용하는 것이죠. 당연히 데이터를 적게 사용하니 역시나 memory 관점에서 이득이 있습니다.
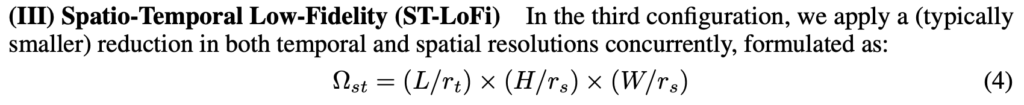
Spatial과 Temporal 차원에 대해서 모두 scaling을 진행해준 것 입니다. memory 이득은 제일 많겠네요.
이렇게 제안되는 3가지 configuration을 가지고 저자는 순환적인 구조를 제안합니다.
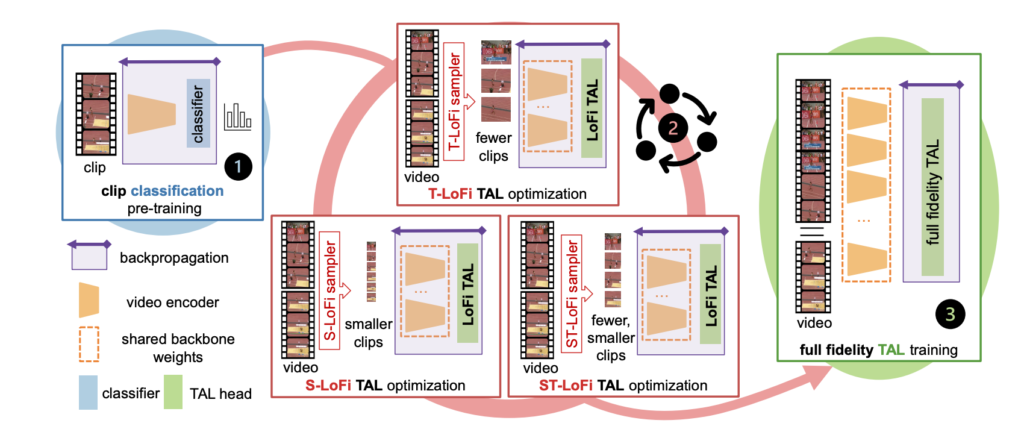
위의 그림을 보면 무슨 얘기인지 이해할 수 있습니다.
우선 LoFi 방식으로 학습하기 전에 Classification 방식으로 사전학습이 됐다고 가정하고 Low-Fidelity(LoFi) 방식으로 Optimization을 할 건데 여기서 T-LoFi, S-LoFi, ST-LoFi 골고루 한번씩 진행하면서 하고 있습니다. 예를 들면 T-S-ST-T-S-ST-T .. 이런식으로 말이죠.
T-LoFi, S-LoFi, ST-LoFi 모두 상호보완적으로 작용할 수 있기 때문에 저렇게 섞어서 해주는 것이 더 효과가 좋다고 합니다. 뭐 이 부분은 실험적인 내용이기 때문에 실험파트에서 확인하는 것으로 하고 여기서 순환과정에서도 두 가지의 셋팅이 있습니다.
Long Cycle은 scaling ratio 였던 r_{t}, r_{s}를 특정 epoch가 지날 때마다 변경을 해주는 것이고 Short Cycle은 r_{t}, r_{s}를 batch가 바뀔 때 마다 변경을 해주는 것 입니다. 즉, Long Cycle은 비교적 변화를 천천히 주는 것이고 Short Cycle은 변화를 빠르게 주는 것이라 이해하면 될 것 같네요.
이렇게 저품질의 데이터를 가지고 Localization Supervision을 활용하여 Video Encoder와 Localization Head를 End-to-End 방식으로 학습을 시키게 됩니다. 아이디어가 굉장히 간단하죠? 물론 이 당시에 Action Localization에 대한 Task discrepency를 다루는 연구가 많지 않았기 때문에 방법론이 굉장히 간단했던 것 같네요.
제안되는 방법론은 이게 다 입니다. 나머지는 Implementation Detail인데 따로 다루지는 않겠습니다.
Experiments
실험 부분 입니다. 참고로 제가 Introduction에 적은 TSP, BSP 방법론들 역시 21년도에 나온 논문들이기 때문에 실험 파트에서 비교는 다루지 않는다는 점 참고바랍니다.
Comparing TAL results of different video encoder pre-training methods
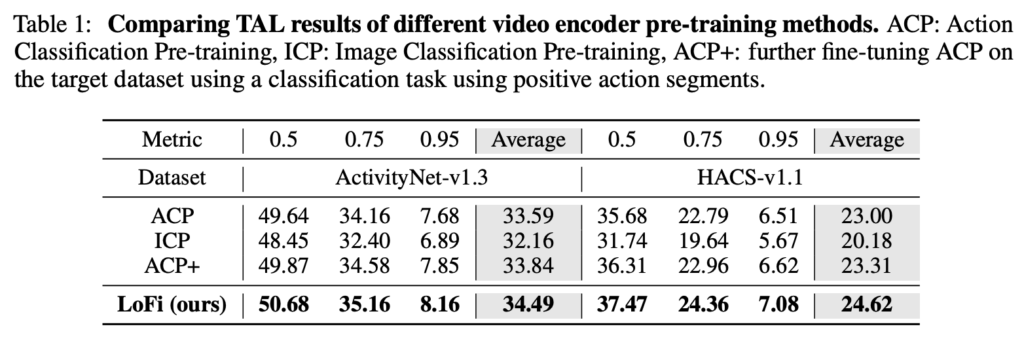
Pretraining 방법을 다르게 가져가면서 Temporal Action Localization에서의 성능입니다.
ACP는 Kinetics 데이터셋을 가지고 Action Classification 방식으로 사전학습한 방식입니다. ICP는 ImageNet으로 사전학습 된 것이구요. ACP+는 ACP를 가지고 ActivityNet의 Action Segment를 활용하여 더 추가적인 finetune을 한 방식이라고 보시면 됩니다.
직접적인 비교는 ACP+와 LoFi를 하는 것이 fair 합니다. 결국 LoFi를 학습하는 과정에서 ActivityNet을 사용했기 때문이죠.
이 실험이 얘기하는 것은 ACP+는 ActivityNet을 Classification 방식으로 학습했고 LoFi는 가벼운 Localization 방식으로 학습했을 때 우리가 제안하는 방식이 task discrepency를 해결할 수 있다라고 주장하고 있습니다.
Classification 성능이 안나온 것은 조금 아쉽습니다. 저는 TSP나 이번 방법론에서 제안된 LoFi 둘 다 target dataset인 ActivityNet을 활용하기 때문에 어느정도 overfitting된 성능이라 생각하기 때문에 Classification에서의 성능도 궁금했던 것인데 그건 나와있지 않네요.
Comparing different low-fidelity configurations
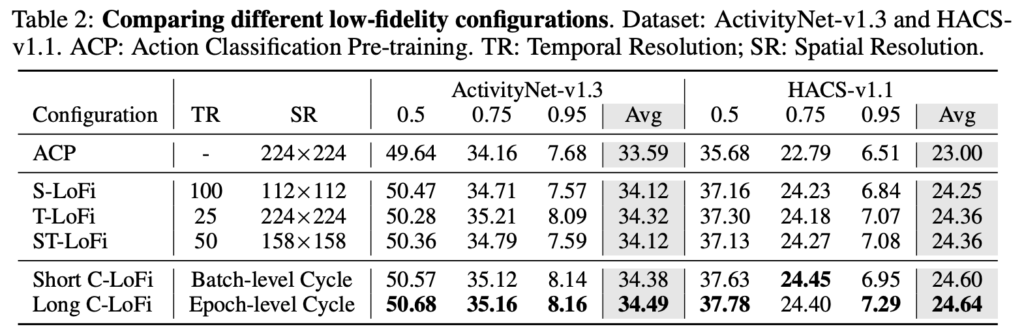
제안하는 low-fidelity configuration에 대한 ablation 입니다. S-LoFi, T-LoFi, ST-LoFi를 각각하는 것은 물론 ACP에 비해서 성능이 높아지긴 하지만 Cycle을 돌렸을 때에 비해서는 성능이 조금 낮습니다. 왜 cycle을 돌렸을 때 더 좋은 것인지에 대해서는 그냥 실험적인 요인으로 설명하고 있습니다.
제 생각에는 결국 여러 configuration을 돌아가면서 학습 과정을 진행하는 것은 augmentation 관점으로 봤을 때 더 다양한 케이스를 학습하기 때문에 더 좋은 성능을 달성한 것이 아닌가 싶네요.
Comparing TAL results with state-of-the-art methods on ActivityNet-v1.3 validation set
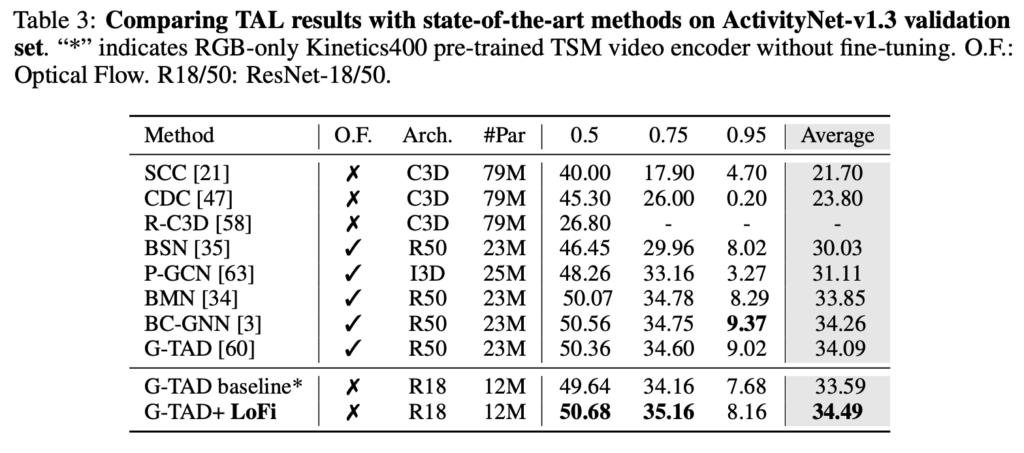
저자는 baseline으로 19년도 CVPR에 개제된 G-TAD를 Localization head로 활용하여 저자가 제안하는 LoFi의 효과를 입증하고 있습니다. G-TAD는 원래 optical flow도 같이 사용하는 방법인데 여기서 RGB만을 활용하여 다시 베이스라인을 잡고 여기에 LoFi optimization 방식을 추가하여 ActivityNet에서의 Localization 성능을 벤치마킹하고 있습니다.
flow를 사용하지 않고도 SoTA 성능을 달성한 것이 인상 깊습니다. 이러한 성능 향상은 Localization과 Classification간의 Task discrepency를 LoFi를 활용해 해결했기 때문이라고 주장합니다. 지금 와서는 당연한 말이지만 당시에는 아마 처음으로 trouble shooting이 되었기 때문에 감안하면서 읽으시면 될 것 같습니다.
Comparison to Self-Supervised Learning
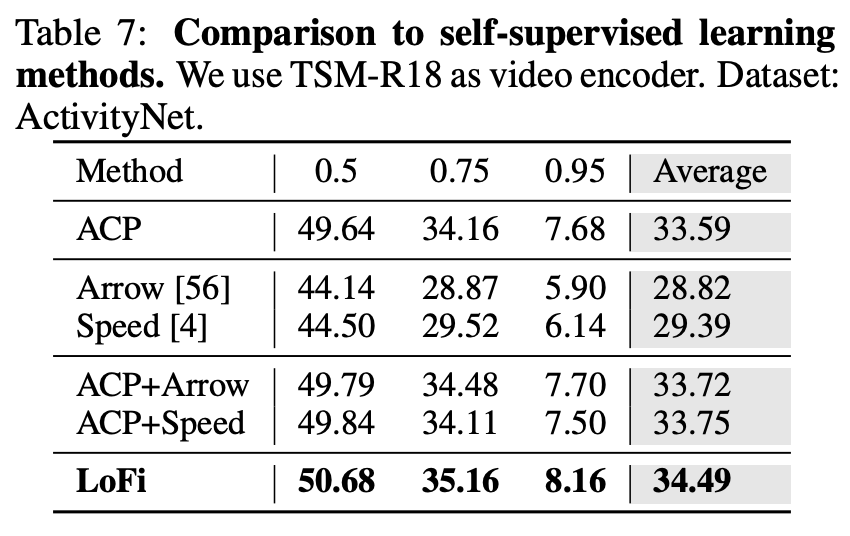
왜 이런 실험을 넣었는지는 모르겠지만 Self-Supervised 방식이랑 비교하고 있네요. 사실 LoFi는 Supervised 방식의 사전학습을 하면서도 target 데이터셋을 사용하기 때문에 fair한 비교가 절대 아니긴 한데 뭐 본인들의 방법이 SSL 방식에 비해서 훨씬 우수하다고 하고 있네요… ㅋ
Conclusion
기본적으로 Neurips 논문들은 엄밀한 증명을 거쳐서 core-ML에 대한 이론적인 연구를 많이 하는 학회인 것으로 알고 있었고 그러한 와중에 제가 관심 있어하는 연구 주제가 논문으로 공개되어 있어 기대를 가지고 봤는데 ML보다는 CV에 매우 가까운 성격의 논문이었습니다.
코드도 공개한다고 해놓고 깃허브 링크를 들어가면 비어 있는 것이 조금 아쉽습니다.
암튼 이상으로 리뷰 마치도록 하겠습니다. 감사합니다.
안녕하세요. 임근택 연구원님 리뷰 잘 읽었습니다.
모델 설명 그림을 보면 샘플러라고 끝나는데, 그 위에 설명된 수식 바탕으로 샘플링을 수행해주는 것인가요? 혹시 이게 맞다면 샘플링 자체는 학습이 필요 없는 구조인가요?
네 맞습니다. 샘플러 자체는 학습을 요구하지 않습니다. 따라서 저자가 제안하는 방식은 사실 일종의 Augmentation(?) 이라고도 볼 수 있습니다
안녕하세요 좋은 리뷰 감사합니다.
S-LoFi와 T-LoFi가 각각 spatial 축, temporal 축에 대해 sampling을 수행하고 이렇게 작거나 짧아진 clip을 task discrepency를 줄이기 위한 중간 end-to-end 학습에 활용하여 메모리 관점에서 이득을 취한 논문으로 이해하였습니다.
그림을 통해 S-LoFi는 일부를 crop하는 것이 아닌 전체 영상의 resolution을 줄여가는 것으로 확인했고 trimmed video를 대상으로 하는 것이니 어느정도 납득이 갑니다.
그렇다면 T-LoFi에서 100초를 5초로 샘플링한다고 했을 때 uniform sampling이 이루어지는 것인가요, 아니면 5초의 연속된 구간을 temporal crop해서 사용하는 것인가요?
uniform sampling이 이루어지는 것인가요?
=> 이게 맞습니다.