
본 논문은 권인소 교수님 연구실에서 작성된 논문입니다.
제가 알기론 저자분이 Depth쪽 논문을 많이 쓰시는 걸로 알고 있는데 segmentation 논문도 작성 하셨네요. 일단 그럼 리뷰 시작하겠습니다.
Introduction
RGB와 Thermal 센서 각각에 대한 필요성은 다들 아실겁니다. 이들은 각각 장단점이 존재하기 때문에 제한적인 상황에서의 안정적인 예측을 위해 기존의 많은 연구들은 두 센서의 fusion을 통해 depth, segmentation 등의 task를 진행하곤 합니다.
하지만 저자는 여기서 기존 연구들에 대한 문제 제기를 하게 됩니다. 기존 연구들이 대부분 RGB, Thermal 멀티모달 입력의 특성을 각각 고려하지 않고, 그저 fusion하는 module을 설계하기에만 급급하다는 것이지요. 이 때문에 예측이 단일 모달리티에 지나치게 의존하는 현상이 발생하여 서로의 장단점을 보완하지 못하고 의미있는 표현 또한 학습하지 못한다고 합니다.
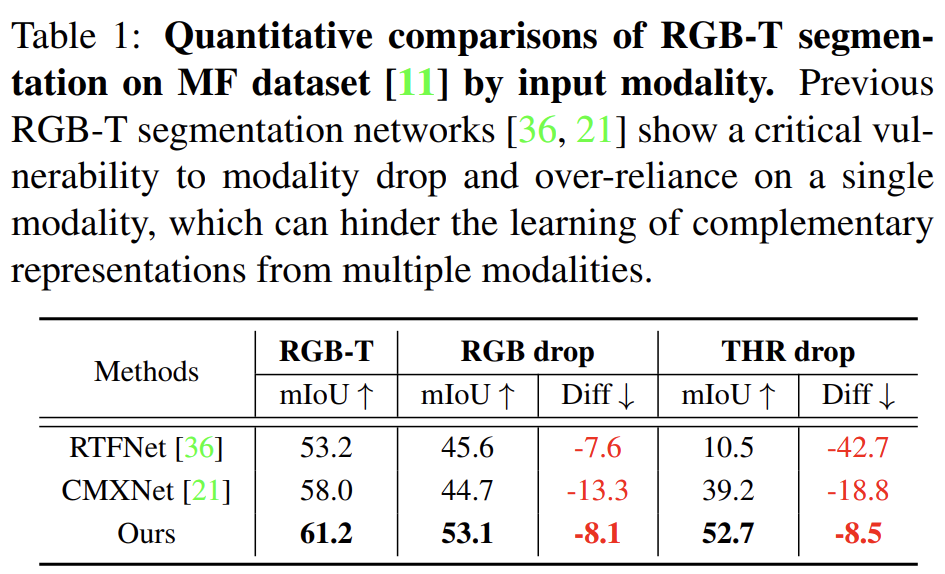
위 표에서 이를 잘 나타내어 주고 있는데요, 기존의 RTFNet와 CMXNet에서는 RGB, Thermal를 각각 drop 시켰을때 꽤나 큰 성능 하락이 있는 반면 Ours에서는 결과론적으로 8 정도의 성능 하락만이 존재하네요. 이는 본 논문에서 제안하는 방법론이 단일 모달리티에 대한 과도한 의존 문제를 해결하는 것을 시사합니다.
본 논문에서는 이를 해결하고자 2가지 기법을 제안하게 됩니다.
우선 RGB-Thermal 이미지를 무작위 마스킹(Random masking)으로 보강(augment) 하여 모델이 한 가지 모달리티에 과도하게 의존하는 것을 방지합니다. 이를 통해 단일 모달 의존성을 줄일 뿐만 아니라, 전체적인 성능을 향상시켰다고 하네요.
그리고 두번째로는 모델이 부분적으로 가려진 모달리티 또는 단일 모달리티에서도 의미 있는 표현을 추출할 수 있도록 Random masking으로 증강된 이미지와 원본 이미지의 예측 결과 간의 일관성을 강화합니다. 이를 위해 self-distillation loss를 새롭게 설계하였구요, 이를 통해 각 모달리티에서 상호 보완적이고 의미있는 표현을 추출하도록 하였습니다.
이 두가지 기법에 대한 자세한 설명은 method 부분에서 이어 나가도록 하겠습니다. 그리고 위 2가지 contribution을 그림으로 표현하면 아래와 같습니다.
다시 한번 정리하면, 본 논문에서 제안한 i) Complementary Random masking과 ii) self-distillation loss 를 통해 각 모달이 상호 보완적으로 학습을 하게되고, 이는 단일 모달로의 의존성을 낮춰주는 결과를 불러일으킵니다.

입력 모달의 의존성에 대한 정성적 실험 결과를 미리 보여드리겠습니다. 2번째 row의 RTFNet과 3번째 row의 ours를 비교해서 보시면 됩니다. 입력 이미지를 보아 하니 차량의 라이트가 반짝이는 scene이여서 RGB에서 매우 challenging할것임을 알 수 있습니다. 아니나 다를까 (f)에서 Thermal를 drop하고 RGB로만 예측하니 아무런 예측을 수행하지 못했네요. 그에 반해 (i)의 ours 에서는 어느정도의 예측은 수행한 것을 볼 수 있습니다.
본 논문은 단일 모달의 over-reliance 문제를 해결하고자 하였고, 이러한 정성적 실험결과를 통해 어느정도 효과를 증명하였네요.
Method
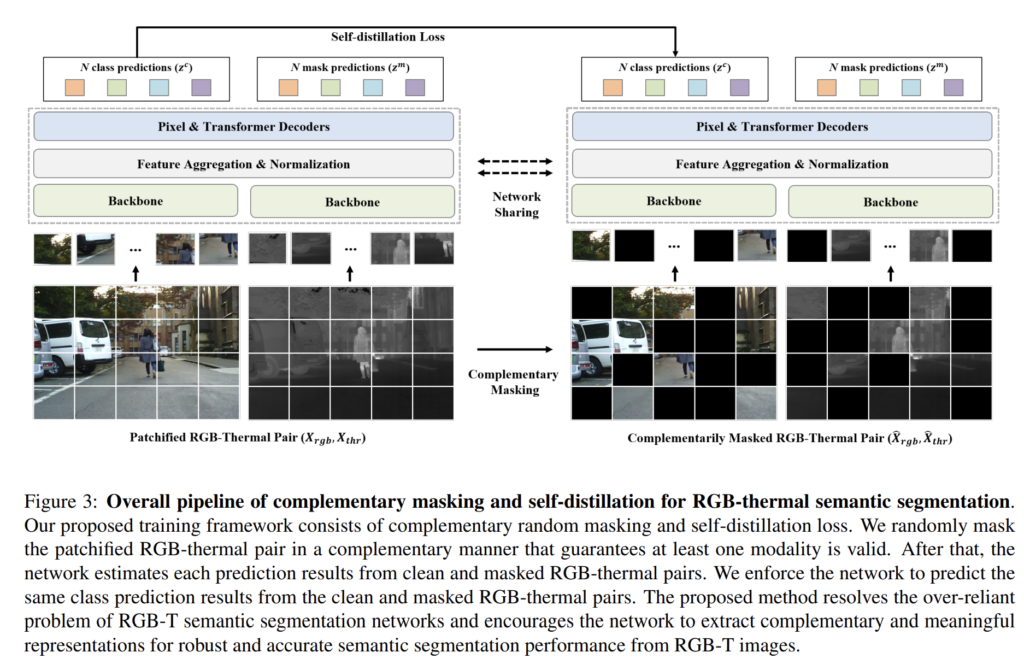
Complementary Random Masking
본 논문에서 설계한 masking 전략의 경우 최근(?) 많은 연구들에서 등장하는 MAE와 유사합니다.
다만 기존의 MAE 연구들은 downstream task를 위한 일반적인 표현 방식을 학습하기 위해 큰 규모의 backbone을 사전 학습 시키는데에 사용됩니다. 입력 도메인에 대한 general representation 학습에 초점을 두는 것이지요.
반면 본 논문에서는 이러한 masking 전략을 활용하여 RGB-Thermal 에서 각 모달의 과도한 의존성 문제를 해결하고, 각 모달에 대해 상호 보완적인 표현 학습에 초점을 두게 됩니다.
각 입력 모달 이미지는 겹치지 않는 작은 patch 집합으로 패치화된 후에 무작위로 masking 하게 되는데, 이는 아래의 식을 통해 진행됩니다.
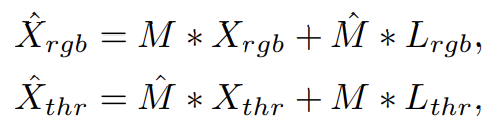
X_{rgb}, X_{thr}은 각각 토큰화된 입력 이미지이고, M은 random mask, \hat{M}은 complementary mask이며 1-M으로 단순하게 계산됩니다. 그리고 L_{rgb}, L_{thr}은 각각 rgb, thermal의 learnable token vector를 의미합니다.
한쪽 모달의 patch를 random mask M으로 마스킹하고, 마스킹된 patch인 \hat{M} 영역에 대해서는 learnable한 token vector로 대체하는 것입니다.
Self-distillation Loss
본 논문에서 제안하는 Self-distillation loss 는 크게 2가지 term으로 구성됩니다.
우선 첫번재는 L_{SDC} 입니다. 우선 식은 아래와 같습니다.
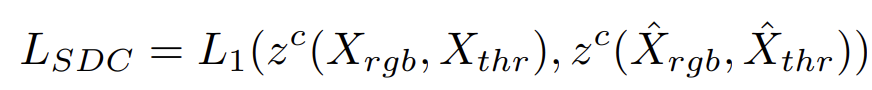
위 식에서 X_{rgb}, X_{thr} 은 위 Figure 3 모델 그림 좌측에 해당하는, 입력 이미지 원본을 토큰화한 것이고, \hat{X}_{rgb}, \hat{X}_{thr}은 모델 그림 우측에 보이는 masking 후의 의미지를 토큰화 한 것입니다. 그리고 z^c는 입력 토큰을 통해 예측한 최종 class logit 입니다. 예측값이라고 생각하시면 됩니다.
위 L_{SDC}를 통해서 Random Masking을 했을때와 안했을때 동일한 예측을 수행하도록 합니다. 사실 별 거 없고 masking의 유무에 관계없이 동일한 segmentation map을 예측하게 하는 것입니다.
두번째는 L_{SDN} 입니다. 식은 아래와 같습니다.
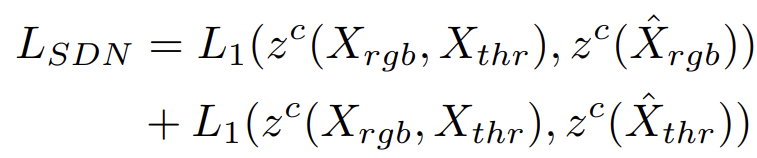
위 loss를 통해 단일 모달에서도 robust한 표현을 추출하고자 하였습니다. 식의 동작 과정은 매우 간단하기에 위 식으로도 충분히 이해하실 수 있을거라 생각됩니다. 저자는 본 loss를 통해 local feature가 아닌, non-local context를 기반으로robust한 표현력을 학습하고자 하였다네요.
또한 저자는 이 뿐만 아니라 Mask2Former에서 사용하는 loss를 사용하여 사용하였다고 합니다. 해당 논문을 읽어보지 않아 깊게는 모르겠지만 Facebook AI Reasearch 팀에서 작년 CVPR에 낸 논문이네요. 조만간 한번 읽어보고 리뷰를 작성해봐야겠습니다. 암튼 Mask2Former에서 사용하는 supervised loss는 아래와 같습니다. binary mask loss와 classification loss의 결합으로 구성되어 있네요.
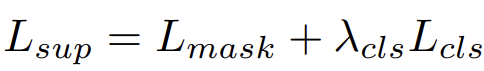
그리고 위 loss를 통해서 Modality-wise supervision이라고 하는 loss를 설계하였습니다. 입력을 3가지로 보고 (RGB, Thermal, RGB-TH pair) 이 3가지를 사용한 예측값을 gt와 비교해서 위의 L_{sup}을 계산하는 것입니다. 아래와 같습니다.
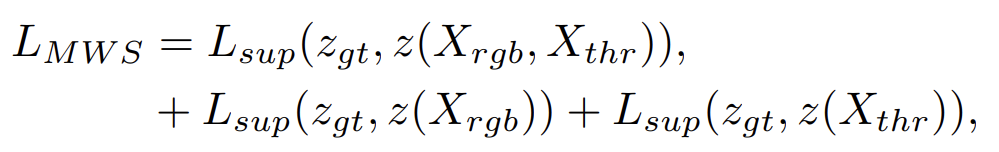
그리고 최종적으로 이때까지 나온 loss term 3개를 결합하여 최종 loss를 설계하였네요.
딱히 복잡한 설계는 없는 듯 합니다!
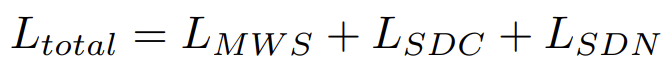
Experiment
본 논문에서는 MF Dataset, PST900 Dataset, Kaist Dataset 이렇게 3개를 사용하여 벤치마킹을 수행합니다. 모두 RGB-Thermal pair로 구성되어 있습니다. MF와 Kaist 의 경우는 Urban 환경에서 driving scene 위주로 구성되어 있고, PST900 Dataset은 동굴 및 지하 환경에서 촬영된 데이터셋이라고 합니다.
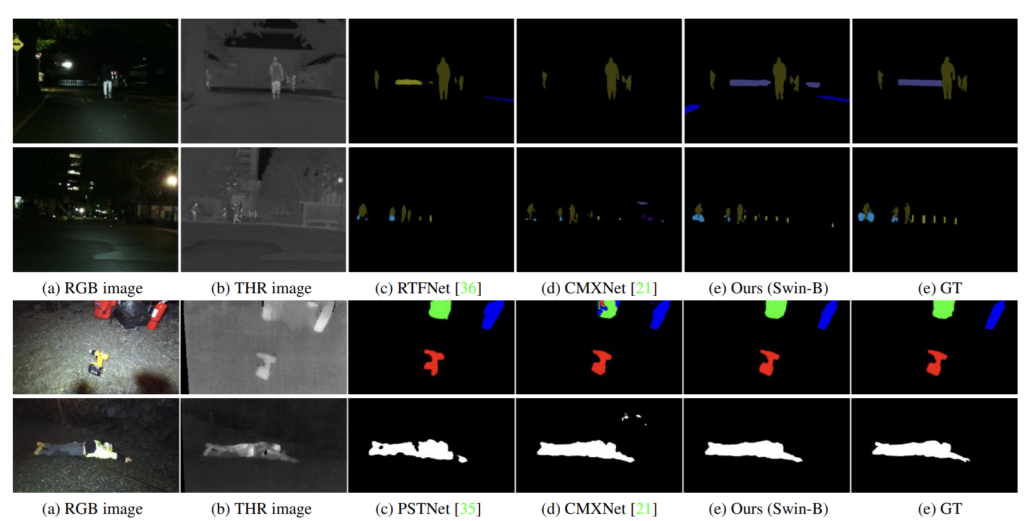
우선 MFDataset과 PST900 Dataset에 대한 정성적 결과입니다. 타 방법론에 비해 gt와 거의 유사한 예측을 수행하네요.
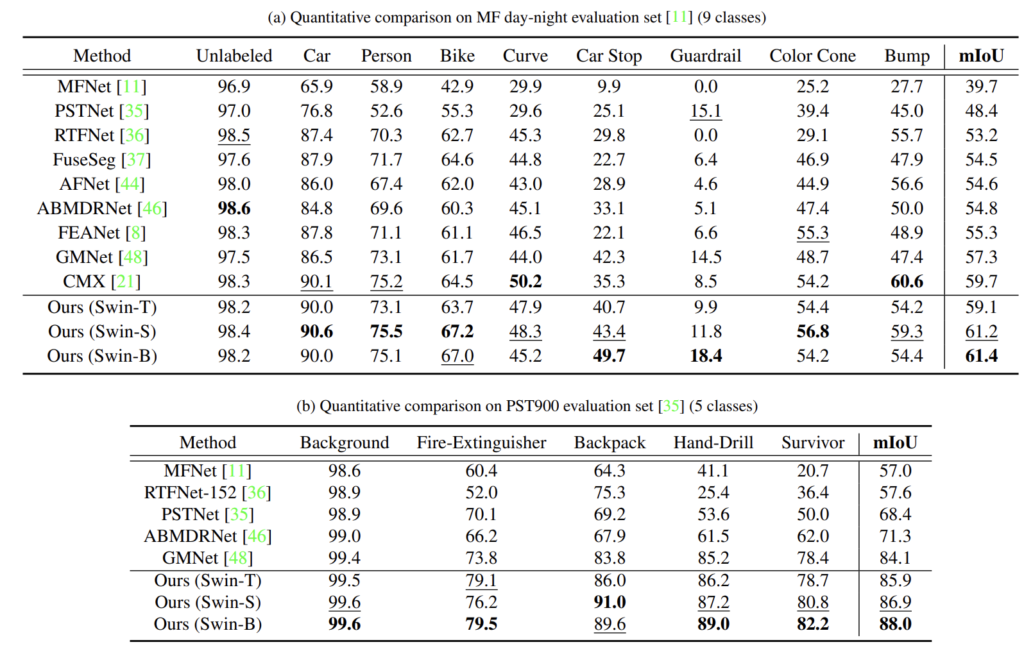
다음은 정량적 결과입니다.
MFDataset에서 Bike와 Guardrail 클래스에 대한 성능 향상폭이 꽤나 인상적이네요.
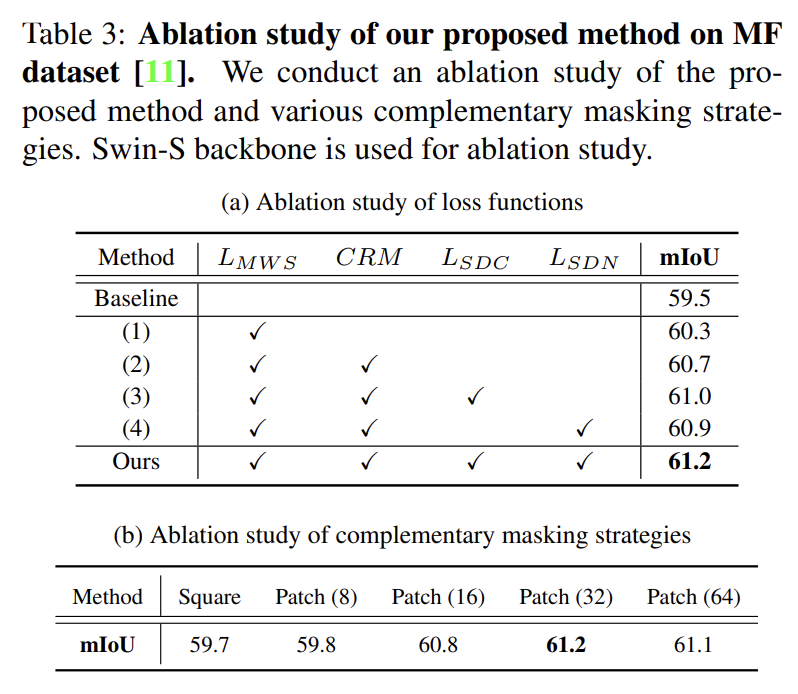

다음은 Ablation Study 입니다.
Table 3-(a)는 제안한 loss term 과 masking 전략의 추가에 따른 성능 향상을 보여줍니다. 위 표에서 CRM은 Complementary Random Masking 전략을 의미합니다.
또한 Table 3-(b) 는 masking 방식에 대한 ablation study 입니다. 일반적으로 어떤 masking을 사용할지라도 masking을 적용안한 baseline보다는 높은 성능을 보여줍니다. 그리고 32 사이즈의 patch를 사용했을 때 제일 높은 성능을 보여주네요. 부가적으로 저자는 patch 크기가 너무 작으면 각 모달에서 보완적인 정보를 학습하기가 힘들다고 하네요.
사실 주말에 조금 급하게 읽은 논문인지라 평소보다 리뷰의 퀄이 조금 떨어지는 듯 합니다. 다음 리뷰에서는 더 시간을 투자하여 꼼꼼하게 작성 해 보겠습니다. 감사합니다.
안녕하세요, 권석준 연구원님. 좋은 리뷰 감사합니다.
URP 이후 오랜만에 RGB-Thermal Multispectral을 이용하는 논문이 눈에 띄어 재밌게 리뷰를 읽을 수 있었습니다.
리뷰를 쭉 읽으면서 다음과 같이 요약해 보았습니다.
1. 논문 저자에 의하면, RGB+Thermal 센서를 같이 사용하는 연구에서, 기존 연구들은 대부분 multispectral 특성을 각각 고려하지 않고, 그저 fusion하는 module을 설계하기만 급급했다는 한계가 있습니다.
2. 이 때문에 예측이 단일 spectral에 지나치게 의존하는 현상이 발생하여 서로의 장단점을 보완하지 못하고 의미있는 표현 또한 학습하지 못한다고 합니다. 본 논문에서는 2가지 기법을 제안해서 단일 도메인에 대한 과도한 의존 문제를 완화했습니다.
3. 첫 번째 기법은 RGB-Thermal image에 complementary random masking을 가해 augment하여 모델이 특정 도메인에 과도하게 의존하는 것을 방지하는 것입니다. 이를 통해 의존성 뿐만 아니라 전체적인 성능이 향상됩니다.
4. 두 번째 기법은 self-distillation loss를 이용하는 방법입니다. 두 수식으로 구성되는데, 수식을 요약하면 토큰화한 원본 이미지, 마스킹 이미지를 모두 사용해 Loss를 구성하고, 저자는 해당 loss를 통해 (local feature가 아닌)non-local context를 기반으로 robust한 표현력을 학습하고자 하였습니다.
5. 저자는 추가적으로 Mask2Former에서 사용하는 loss를 사용하였습니다.
6. 실험에서는 RGB-Thermal pair가 있는, MF, PST900, Kaist 데이터셋을 사용하였고, 준수한 성능을 보여줍니다.
컬러 및 열영상을 함께 이용하는것은 URP 기간에 다루어서 익숙한데, multispectral model의 성능을 높이기 위해 (ssd가 예전 방법론이긴 하지만) 새로운 기법을 적용한것을 보여 요즘에는 모델 구조를 이렇게 짜는구나.. 정도로 참고하면서 읽었습니다. 읽다보니까 이해가 쉽지 않은 부분도 있었는데, 제가 아직 용어에 익숙하지 않아서 그런 것 같습니다.
1. self-distillation loss 라는 부분에서 distillation, 그리고 self-distillation이 정확히 무엇을 의미하는것인지 잘 모르겠습니다. Figure3을 보면 masking을 수행하지 않은 모델에서의 정보를 complementary random masking model에 이용하는 것 같긴 한데.. 알려주시면 감사하겠습니다.
2. complementary random masking 수식에서 L은 learnable token라고 하셨는데, 이게 무엇을 뜻하는지 잘 모르겠습니다. token vector라고 하면 무엇을 뜻하는 것인가요?
감사합니다.
1. 음, self-distillation 에서 저자가 self를 붙인 이유는 아마 Figure3 기준 좌 우 모델이 동일한 parameter를 가지는 동일 모델이기 때문에 self를 붙인 것일겁니다. distillation은 음.. knowledge distillation이라는 키워드로 공부를 해 보시면 되는데요, 간단하게 말해서 큰 규모의 성능 좋은 teacher 모델의 예측을 상대적으로 작은 규모의 student 모델에게 전이해서 학습시키는 방식입니다. student는 teacher를 보고 배우겠지요.
신정민 연구원의 ‘http://server.rcv.sejong.ac.kr:8080/2022/01/30/cvpr2018-deep-mutual-learning/’ 해당 링크 리뷰 상단에 관련된 설명이 잘 적혀있고, 구글링을 하셔도 더 많은 정보를 얻으실 수 있을겁니다.
2. 음.. masking을 한 영역에 대해 learnable token을 대체한 방식은 기존 ‘bert’나 ‘beit’ 논문에서 차용한 방식이라고 합니다. 저도 해당 논문들을 읽어보지 않아서 정확히는 잘 모르겠지만, masking을 한 영역에 학습 가능한 token을 기존 image token과 동일한 shape의 vector로 대체하는 방식으로 알고 있습니다.
안녕하세요 권석준 연구원님 리뷰 잘 읽었습니다.
리뷰에서 언급해주셨다시피 mae랑 비슷한 마스킹 기법을 사용하는 것 같은데, mae가 아니라 distillation을 적용한 이유가 있을까요?
음,, ‘mae가 아니라 distillation을 적용했다’ 라는 질문의 의미를 잘 모르겠네요.
(제가 잘 이해를 못했을수도 있습니다,,)
masking과 distillation은 저자가 제안한 서로 다른 contribution 입니다!!