제가 이번에 리뷰할 논문도 VPR 논문입니다. 최근에 리뷰한 논문은 global search와 re-ranking을 동시에 수행하는 방식을 이용하여 연산량을 줄인 방식이었습니다. 이번 논문도 transformer를 이용한 place recognition 방법론으로, 속도와 정확도의 trade-off 관계를 더 좋은 방향이 되도록 연구를 수행한 방법론입니다.
Abstract
Visual place recognition은 이미지를 통해 위치를 인식하는 task로, reference영상과 유사한 영상을 global descriptor를 이용하여 찾아낸 후, local descritpor를 이용하여 re-ranking을 수행하는 것이 일반적입니다. re-ranking은 global descriptor에 비해 정확도를 높일 수 있으나, 높은 연산 비용이 든다는 문제가 있습니다. 저자들은 정확도와 연산량의 trade-off 관계를 개선하기 위해 global과 local한 descriptor를 함께 사용하여 한번에 상위 후보이미지들을 re-ranking하는 Efficient Transfodrmer for Re-ranking(ETR)를 제안하였습니다. 또한, self-attention을 이용하여 단일 이미지에서 local descriptor와 cross-attention을 통해 유사한 이미지들 사이의 정보를 찾아내는 방식을 제안하였습니다.
Introduction
VPR은 영상을 이용하여 위치 정보를 파악하는 태스크로, 쿼리 영상의 위치를 알아내기 위해 위치정보가 달린 reference 영상과 비교하여 유사한 영상을 찾아내는 retrieval 방식을 많이 사용합니다. 이때 유사도는 image representation을 이용하여 판단하며, image representation은 이미지 전체를 하나의 피쳐백터로 표현하는 Global descriptor와 이미지의 관심 영역에 대한 피쳐인 Local descriptor로 나뉩니다. VPR 과정은 2단계로 나뉘며, 먼저 컴팩트한 Global descriptor를 이용하여 전체 이미지에 대해 빠르게 유사한 후보 이미지를 찾아낼 수 있으며, local descriptor를 이용하여 정확도를 높이는 re-ranking이 두번째 과정이 됩니다.
SOTA 논문들이 여전히 re-ranking 과정에 Geometric verification을 이용하고 있으며, 이러한 방식은 전체 local descriptor 세트를 완전히 비교하는 방식을 이용하기 때문에 정확도를 향상시키기에는 좋은 방식이지만, 연산 코스트가 너무 많고, 시간도 오래 걸린다는 문제가 있습니다.
이러한 이유로 저자들은 이미지 쌍 간의 유사도를 바로 측정할 수 잇는 ETR(Efficient Transformer for Re-ranking)을 설계하였습니다. 아래의 그림1을 통해 확인할 수 있습니다. 사전학습된 CNN 모델로부터 추출된 local descriptor를 Transformer로 처리합니다. Transformer는 attention 방식을 사용하며, receptive field가 global하다는 장점이 있어 단일 영상 내의 복잡한 관계를 파악하기 위한 self-attention에 이용할 수 있다고 합니다.
기존의 re-ranking 방식과 다르게 쿼리와 top-k개의 후보 영상을 합쳐 한번에 입력으로 이용합니다. 기존 방식이 일일히(연속적으로) 비교하는 방식을 이용하였다면, 제안한 방법론은 한번에 입력으로 넣어 사용할 수 있어 병렬적으로 이용할 수 있다고 합니다.
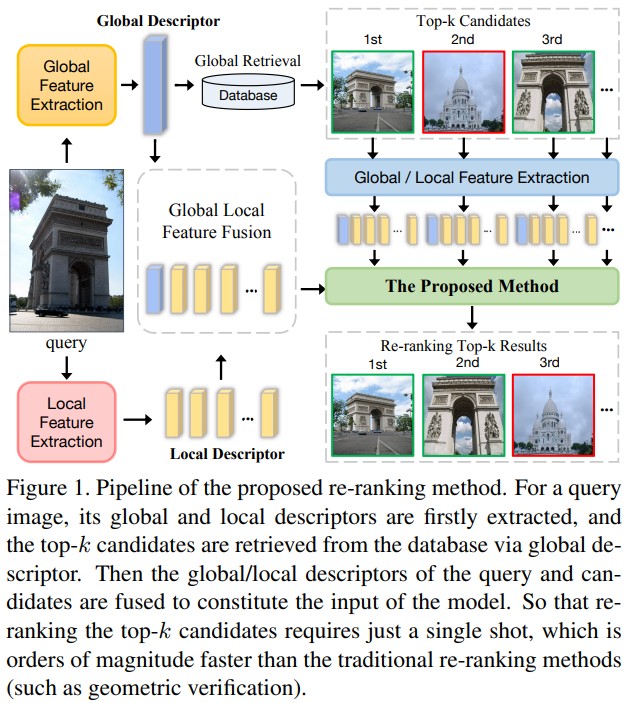
Contribution
- self/cross attention을 이용하여 이미지쌍의 유사도를 바로 예측하기 위해 Efficient Transformer for Re-ranking를 제안 → 병렬적으로 적은 연산량과 메모리로 이미지 처리가 가능
- ETR 방식이 Re-ranking에 범용적으로 활용 가능함을 보임
- 실험을 통해 VPR 밴치마크에서 SOTA를 달성
Method
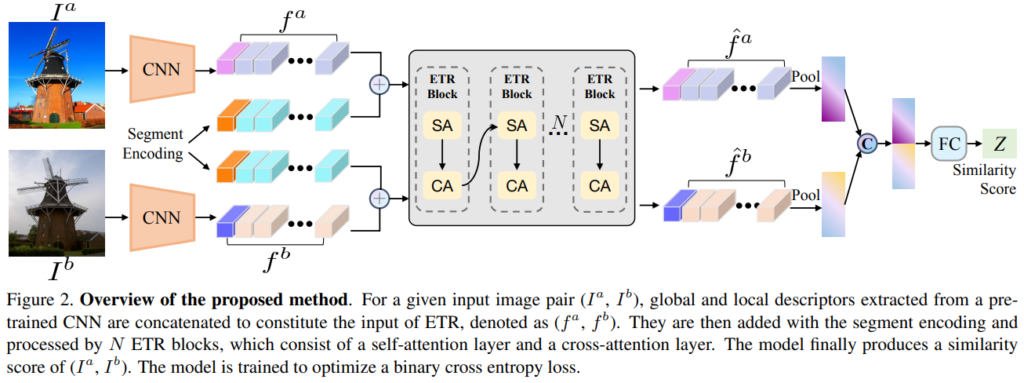
위의 그림2은 ETR로, 쿼리 이미지가 주어졌을 때 global descriptor를 이용하여 top-k개의 후보를 찾아냅니다. 그 후, 쿼리 이미지와 각 후보 이미지 셋을 입력으로 넣어 유사도를 측정하여 재정렬을 합니다.
1. Feature Extraction
ETR은 global과 local descriptors를 기반으로 re-ranknig을 수행하도록 디자인되었습니다. CNN을 통해 생성된 descriptor를 ETR의 입력으로 사용합니다. ETR은 DELG와 SuperPoint 중 무엇을 이용하여 특징을 추출하는지에 따라 local 피쳐만 입력으로 사용하는 ETR-S와 Global, local 피쳐를 모두 입력으로 사용하는 ETR-D 두가지 버전을 제안하였습니다.
** SuperPoint
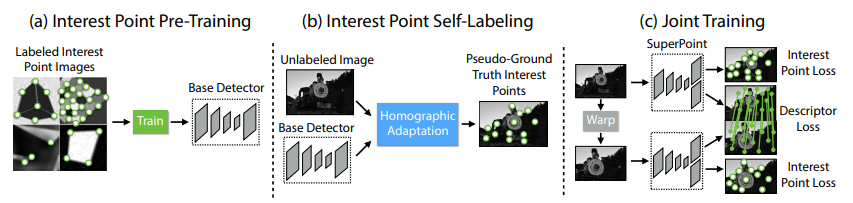
이미지 속 2D keypoint의 위치와 해당 feature의 descriptor를 추출하는 CNN 네트워크로 keypoint 위치와 descriptor 정보를 함께 계산할 수 있는 방법론입니다. local한 정보를 알아낼 수 있습니다. (더 자세한건 논문을 참고해주시기 바랍니다.)
** DELG
global과 local descriptor를 추출하기 위한 하나의 CNN 모델입니다. (자세한 건 논문을 참고해주시기 바랍니다)
2. ETR Block
ETR 블록은 Transformer를 이용하여 설계하였습니다. Transformer는 Multi-Head Self-attention(MHA)과 Feed-Forward 네트워크(FFN) 레이어로 구성이 되며, 입력된 백터는 3개의 다른 메트릭스 Q(query), K(key), V(value)로 변형되며, self-attention 레이어는 아래의 식으로 연산됩니다.

MHA는 이러한 attention 연산을 h 헤드만 수행한 것으로 아래와 같이 나타낼 수 있습니다.
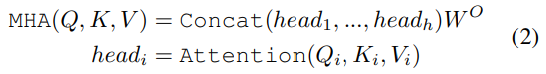
FFN은 2개의 linear transformation 레이어로 구성되며 해당 레이어를 통과한 결과는 아래와 같이 표현할 수 있습니다.
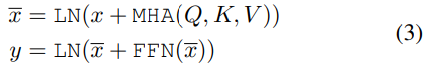
이때, FFN(X) = W_2 \sigma(W_1X)이고, LN은 layer normalization 함수를 의미합니다.
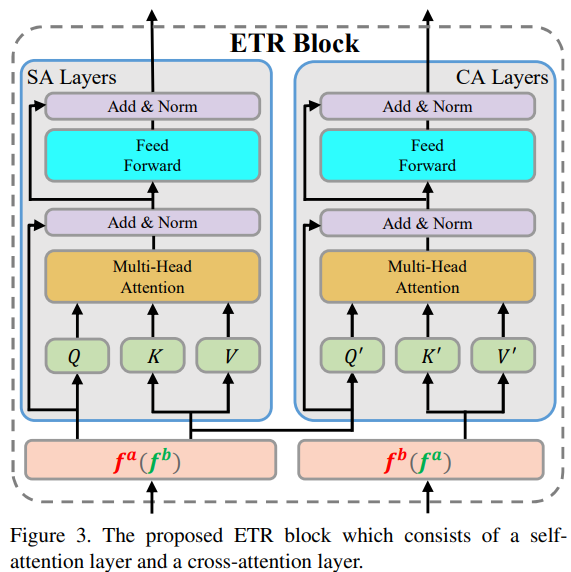
위의 그림3은 ETR block을 나타내며, ETR block은 self-attention layer(SA Layers)와 cross-attention layer(CA Layers)로 나뉩니다.
SA Layers는 f^a, f^b가 동일한 영상으로부터 나온 feature를 의미하며, 이를 통해 이미지 자체의 local descriptor 간의 관계를 파악하고 long-range dependencies(동일 이미지의 먼 거리에 있는 정보간의 관계)를 파악할 수 있도록 합니다.
CA Layers의 Q’는 K’, V’와 서로 다른 이미지에서 추출된 feature를 이용합니다. 즉, f^a에 해당하는 이미지로부터 얻은 Q’와 f^b에 해당하는 이미지로부터 얻은 K’,V’ 혹은 반대의 경우를 이용한다는 것입니다. 아래의 식(4)의 cross-attn관련 식을 보시면 더 쉽게 명확하게 이해하실 수 있습니다.
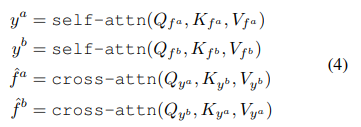
3. Model Architecture
- Model input
입력 이미지 I에 대한 global descriptor와 local descriptor는 X_g ∈\mathbb{R}^{d_g}, X_l = \{ X_{l,i} \mathbb{R}^{d_l} \} ^L _{i=1}로 표현합니다. 이때 L은 local descriptor의 개수입니다.
이미지쌍 (I^a, I^b)가 주어질 때, 이에 대응되는 global descriptor와 local descriptor는 (X*a_g, X^b_g), (X*a_l, X^b_l)가 되고, Transformer의 입력으로 들어가는 (f^a, f^b)는 아래의 식으로 구해집니다.
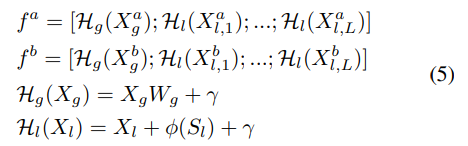
이때, W_g는 X_g를 d_l 차원으로 임베딩 시키기 위한 행렬이며, \gamma는 BERT에서 사용된 segment embedding으로, global descriptor인지 local descriptor인지를 구별해주는 부분입니다. \phi는 선형 embedding 함수로, 스케일 정보 S_{l,i}를 포함하며 ;는 concat을 의미한다고 합니다.
이렇게 ETR 블록을 N번 통과하여 (\hat{f}^a, \hat{f}^b)를 생성한 뒤, pooling(논문은 average pooling 이용)을 거쳐 output을 얻습니다.
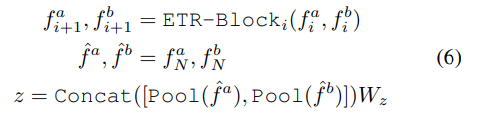
- supervision
BCE loss를 이용하며, 동일 장소인지에 따라 True, False로 GT를 제공하였다고 합니다.
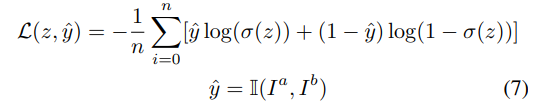
Experiments
Training Dataset
- Google Landmarks v2의 ‘v2-clean’ 집합을 이용하여 학습을 진행하였다고 합니다.(이하 GLDv2)
- 400만개 이상의 이미지를 포함하며, 각 랜드마크가 10~100장의 이미지로 구성되며, 15,000개의 랜드마크에서 랜덤하게 샘플링하여 그중 30%에 해당하는 450,508개의 이미지를 이용하였다고 합니다.
- ETR-D를 학습할 때는 공정한 비교를 위해 RRT와 동일한 train set을 이용하였다고 합니다. 여기서는 12,000개의 랜드마크에서 랜덤하게 샘플링된 322,008개의 이미지를 이용하였다고 합니다.(각 랜드마크는 최소 10장 이상의 이미지로 구성)
** 여기서 ETR-D를 별도로 언급한 것을 보면, ETR-S는 위의 방식의 셋을 이용하였다는 것인데, 이렇게 되면 공정한 비교가 될 수 있을까 하는 의문이 들었습니다.
Test Dataset
- Pitts30k
: 6,818개의 쿼리 이미지와 1000개의 갤러리 이미지 - Tokyo 24/7
: 76k개의 갤러리 이 미지와 315개의 휴대폰으로 촬영한 쿼리 이미지로 구성
갤러리는 낮 이미지만, 쿼리 이미지는 낮, 일몰, 밤 등 다양한 조건에서 촬영 - MSLS
:160만 개의 거리 레벨의 영상을 포함하는, 장기간 촬영된 데이터셋으로, 지리적/계절/시간/날짜(7년) 정보를 다양하게 포함하는 데이터셋
1.9k개의 쿼리 이미지와 57k개의 갤러리 이미지를 가진 MSLS val 셋과 MSLS challenge 셋에서 모델을 평가
Comparison with State-of-the-arts
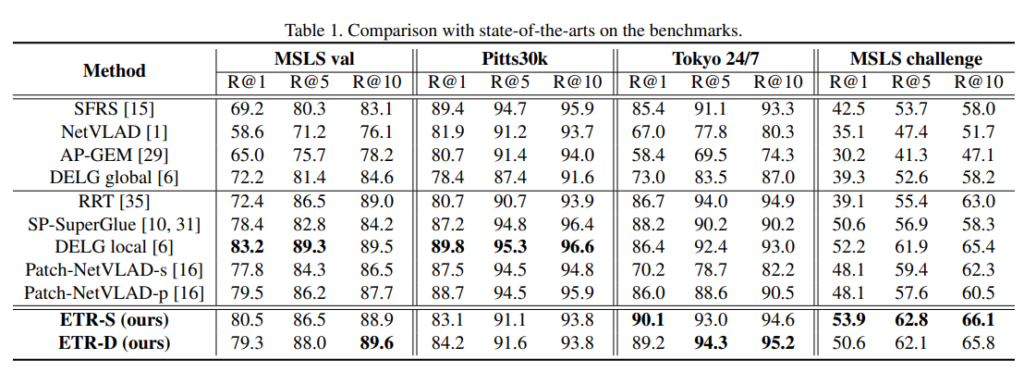
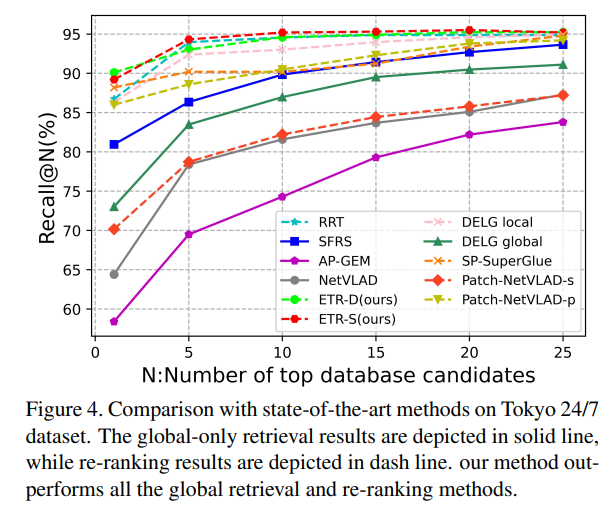
여러 SOTA 방법론들과 비교를 수행한 위치인식 결과로, 위의 4개 항목은 단순히 전체 이미지 중 유사한 것을 찾는 과정만 수행한 것(Re-rankning X)이고, 중간의 5개 항목은 top-100에 대해 re-ranking을 수행한 결과입니다.
ETR-D와 ETR-S는 모두 MSLS val, Tokyo 24/7, MSLS challange에서 re-ranking을 하지 않는 방식보다 성능이 뛰어났으며, 특히, ETR-S는 MSLS challenge에 대해 모든 경우 가장 뛰어난 성능을 보였습니다. 그러나 Pitts30k에 대해서는 SFRS가 가장 뛰어난 성능을 보였고, 저자들은 SFRS가 self-supervised를 이용하여 Pitts30k에 fine-tunning 되었기 때문이며, 자신들의 방법론은 전혀 다른 데이터으로만 학습하였기 때문이라고 합니다. (이러한 내용이 있어 성능이 조금 낮은 게 납득이 갑니다.)
또한 ETR 방식들은 2stage의 방법론들(re-ranking을 수행)과 비교했을 때 경쟁력 있는 성능을 보였습니다.
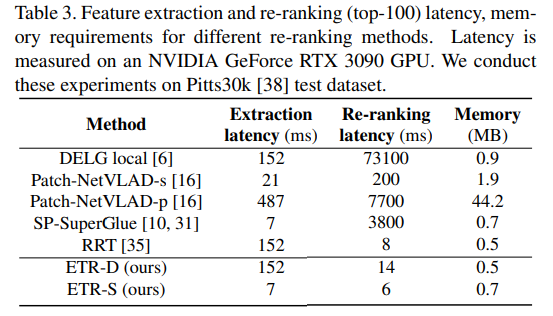
또한 표3을 통해 ETR-S는 Pitts30k에서 re-ranking 과정에 시간 측면에서 SP-SuperGlue와 DELG local보다 633배, 12,183배 빠르다는 것을 보였습니다.
RRT와 비교
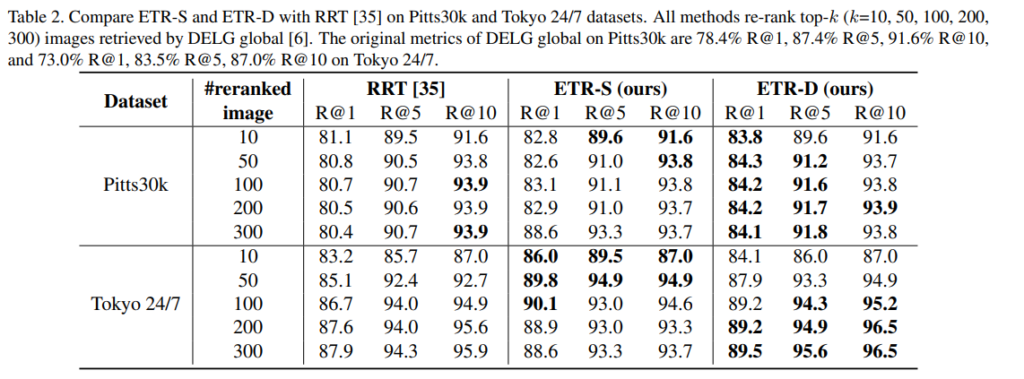
RRT 또한 Transformer 기반의 re-ranking 방법론으로, RRT를 베이스라인으로 삼았다고 합니다. 위의 표가 이에 대한 실험 결과로, 결론을 먼저 말씀드리면 ETR방식이 대체로 더 좋은 성능을 달성했다는 것을 확인하실 수 있습니다. 저자들은 ETR-S가 top-50에 대한 re-ranking을 수행할 때 RRT보다 더 좋은 성능을 보이는 것을 통해, 제안된 self/cross attention이 RRT가 사용한 원래의 Transformer 방식보다 descriptor간의 관계를 더 잘 포착할 수 있음을 보여준다고 합니다.
좋은 리뷰 감사합니다. transformer의 구조에 대해 자세히 설명이 되어있어 이해하는데 수월했습니다.
간단한 질문 드리자면 Figure 2의 cnn을 통과한 feature와 합해지는 segment encoding은 무엇이고 어떻게 얻을 수 있는건가요?
감사합니다.
식(5)의 아랫부분에 감마값이 segment embedding을 의미하는 것인데 제가 segment라는 말을 누락한 것 같습니다. 다시 추가해두었습니다. 그래서 segment encoder에 대해 말씀드리자면 global descriptor인지 local descriptor인지를 구별해주는 부분으로, feature의 종류에 따라 얻을 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽다가 궁금한 부분이 생겨 질문드립니다.
1) Figure 3에서 ETR Block에서 SA Layers의 입력으로 f^a(f^b)가 들어가고 CA Layers의 입력으로 f^b(f^a)가 들어가는데 이는 Q’가 K’,V’와 서로 다른 이미지에서 추출된 feature를 이용하기 때문인가요? 이것이 아니면 다른 이유가 있는 걸까요?
2) 논문의 방법론을 보면 전체적인 process를 ‘쿼리 이미지가 입력으로 주어짐 -> global descriptor 사용하여 top=k개 후보 찾아냄 -> 쿼리 이미지와 후보 이미지를 입력으로 넣어 유사도 측정하여 재정렬’로 이해하였습니다. 이때 유사도는 z로 볼 수 있고 z를 비교하여 re-ranking한다고 이해하였는데 맞게 이해한 것일까요?
1) 네 맞습니다. 방향에 따라 달라지기 때문에 f^b(f^a) ,f^a(f^b)라고 나타낸 것 같습니다. 자세히 보시면 SA에는 f^a(혹은 f^b)가 들어가고, CA에는 f^a일 경우에는 Q’에는 f^a(SA에서 빠져나온 선!), K’와V’에는 f^b로 구할 수 있습니다. 따라서 이러한 이유로 색을 정해둔 것 같습니다. 만약 많이 헷갈리신다면 수식(4)를 보고 이해하시는 게 더 확실하게 이해하실 수 있을 것 같습니다.
2) 일단 이해하신 바가 맞습니다. 다시 한번 설명을 드리자면, z는 similarity score로, 쿼리와 top-1, 쿼리와 top-2 … 간의 similarity score입니다. 따라서 이 similarity score를 기준으로 top-1부터 top-k까지 재정렬을 하는 것입니다.
안녕하세요 좋은 리뷰 감사합니다.
Transformer의 입력으로 들어가는 f를 계산하는 과정에서 local descriptor에 대한 스케일 정보 S_l이 연산에 포함되는 것으로 보이는데, 무엇을 의미하는 값인가요?
그리고 VPR 분야의 기존 연구에서는 cross attention 연산이 사용된 적이 없는 것인지도 궁금합니다.
S_l은 X_l이 추출되는 이미지의 크기를 의미한다고 합니다. 저자들이 베이스라인으로 삼았던 RRT 논문에서 관련 정보를 확인하였고, RRT 논문에서는 sl,i를 미리 정의된 이미지 스케일 집합을 인덱싱하는 정수로 이용하였다고 합니다.
또한 cross-attention 연산을 처음했다는 것이라기보다, 기존의 방식들이 local descriptor를 일일히 비교하여 re-ranking을 수행했다면, 저자들은 cross-attention을 이용하여 다른 이미지들과 비교를 할 수 있도록 하였다는 점이 이 논문의 contribution이라고 생각합니다.
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
특히 실험 파트를 보면서 RRT는 어떤 방법론이지, 저자가 제안하는 방법론과 비교를 하고 싶은걸? 이라고 생각했는데, 사람 생각이 다 똑같나 봅니다 ..ㅋㅋ 그 뒷부분에서 제가 궁금한 걸 다루네요.. ETR-D가 global, local을 모두 입력으로 받는 것이라고 했는데, ETR-S와 큰 차이가 나지 않는 것 같습니다. 그런데 속도 측면에서는 ETR-S가 월등이 차이가 큰데, 이러한 전체적인 맥락으로 봤을 때 ETR-D가 가지는 장점은 무엇이 있을까요?
우선 Pitts30k에서는 ETR-S보다 ETR-D가 잘 작동하고, ETR-D은 Pitts30k와 tokyo24/7 두 데이터셋에서 대체로 좋은 성능을 보입니다. 그러나 말씀하신 것 처럼 성능이 크게 좋거나 하지는 않습니다. 저자들이 제안한 ETR Block은 re-ranking을 수행하는 네트워크로, 이전 단계에서 추출된 descriptor가 local descriptor만을 추출하는 지, local과 global descriptor를 모두 추출하는 지에 따라 모두 사용할 수 있도록 하기 위해 두가지 모듈을 제안한 것으로 이해하시면 될 것 같습니다.
안녕하세요 좋은 리뷰 감사드립니다.
제가 이해한 전체적인 파이프라인이 ETR-S 혹은 ETR-D에서 discriptor를 추출하고, 이를 바탕으로 topk 후보를 탐색한 뒤 ETR block을 통해 reranking을 진행하는 것으로 이해하였습니다. 그런데 ETR-S는 local discriptor 만을 추출하는데 그렇다면 topk를 선출하는 과정에서는 superpoint가 아닌 다른 방법이 사용되는 것인가요?
그리고 표1 부분에서 사용된 평가 metric이 무엇인지 궁금합니다.
일단 ETR-S와 ETR-D는 descriptor를 추출하는 부분이 아닙니다. ETR은 re-ranking을 위한 부분으로, 앞에 CNN 네트워크에서 추출된 descriptor를 이용하여 Re-ranking을 수행하기 위한 부분입니다. 따라서 ETR-S는 superpoint로부터 출력된 입력을 사용하며, 제가 이해하기로는 다른 local descriptor를 추출하는 모델을 활용할 수도 있습니다.
또한, R은 Recall을 의미하며, R@N은 top-N개에 대한 recall 성능입니다.
안녕하세요. 좋은 리뷰 감사합니다.
이전 승현님의 리뷰 몇 편을 팔로잉하며 읽다보니 전체적인 글의 Contribution과 그 목적을 이해하는데에 수월했습니다.
하지만 하나 의문점으로 생각이 든 부분에서, Transformer 방식을 사용하는 것이 병렬적으로 처리하여 메모리 이득이라는 측면은 납득이 되지만, 그를 위하여 (아마 시간적인 측면에서의 디펜스를 하려는 것 같은데) Top-k개를 추출하는 방식에 대한 의문이 듭니다. VPR은 어찌보면 Inference Time이 꽤나 중요할 것 같은데, Experiments에서는 잘 보이지 않아 혹시 중요치 않은 지표일까요?
감사합니다.
혹시 말씀하신 inference time이 Re-ranking 과정의 inference time을 의미하시는 걸까요?? 일단 feature를 추출해내는 과정에 대한 소요시간과, re-ranking 과정에 대한 소요시간은 table3에서 확인하실 수 있습니다.