
안녕하세요. 열 번째 X-Review입니다. 지난 4월 간의 일정을 마친 후 5월에 들어서며 오랜만에 작성하는 X-Review입니다. 다음 주부터 현재 주 관심 분야인 Small-object detection과 관련된 실험을 이어나가기 이전에, 예전 페이스북 Pytorch KR에서 지나치며 본 후 관심이 생겨 나중에 읽어봐야지 했던 논문을 리뷰하도록 하겠습니다.
우선 해당 논문을 한 줄로 요약하자면, “딥러닝에 역전파 (Backpropagation)를 고안한 제프리 힌튼 교수님의 논문으로, 실제 대뇌 피질의 학습 방법에 역전파 과정이 있을까에 대한 의구심에서 시작한 순전파만으로 학습하는 딥러닝 방식입니다. 아래의 리뷰를 읽다보면 저와 같은 느낌을 받으실 수도 있겠지만, 해당 논문에서 제안하는 방식이 Backpropagation은 허상이였다! 이제 그렇게는 딥러닝을 학습하지 말자!는 말이 아닌, 앞으로 Forward-Forward Algorithm (앞으로는 FF 알고리즘이라 명하겠습니다)이 딥러닝의 새로운 학습 토템으로 자리 잡을 수 있지 않을까 하는 하나의 견해이니, 이 점 참고하시면서 리뷰 읽어주시면 감사하겠습니다. 힌튼의 논문은 처음 읽는 것 같네요. 리뷰 시작하겠습니다.
1 What is wrong with backpropagation
딥러닝의 발전 속 2 번의 겨울이 도래했었으며, 그 중 첫 번째 겨울은 XOR 문제와 결부되어 있다는 사실은 모두들 알고 있을 것입니다. 이를 해결한 것이 Backpropagation, 역전파이며 이를 고안해 낸 사람이 바로 이번 논문의 저자, Geoffrey Hinton 교수님입니다. 물론 이전 Paul Werbos가 Backpropagation을 제안했지만, 주목을 받지 못했으며 현재 우리가 알고 있는 Backpropagation은 제프리 힌튼 교수님이 고안해 낸 방법입니다. 논문의 시작은 지난 몇 십년 간의 딥러닝의 발달과 성공의 뒤에는 방대한 데이터의 파라미터를 조절하여 Gradient를 조절하는 방식 (SGD)이 있으며, Gradient는 주로 Backpropagation을 사용하여 계산되어 왔습니다. Backpropagation 등장 이후, 학자들은 뇌의 작동 방식에 관심을 갖기 보다 Backpropagation을 사용하여 인공 지능의 성능을 높이는 것에 관심을 가져왔습니다. 누구든 알고 있을 지식인데 이 문단을 가져온 이유는, 해당 문장을 읽다보니 하나의 생각이 들었기 때문입니다. 인공지능은 결국 컴퓨터가 사람의 지각, 사고 방식을 모사하는 일련의 과정인데, 정작 현재는 그 본질을 생각지 않은 채 성능을 올리는 방법만 고민하는 것은 아닐까 생각이 들었습니다.
힌튼이 문제로 삼은 점은 다음과 같습니다. 대뇌 피질의 학습 과정에서 실제로 Backpropagation 방법이 사용되는가? 즉, 실제로 우리 뇌는 오차를 역으로 전파하여 오차를 수정하는 과정이 있는지 미심쩍다고 하며, 역전파가 있다면 이전의 신경 활동 값을 모두 저장해야하나, 실제로 그런지에 대해서도 의구심이 든다고 말합니다.
우리는 이를 이해하기 위해 인간이 정보를 학습하는 메커니즘에 대해 담은 피아제의 인지 발달 이론을 들고와서 설명할 필요가 있습니다. 이번 리뷰에서 해당 논문을 자세히 알아보고자 함은 아니라, 인간이 실제로 물체를 지각하고 인지하는 과정에 대해 훑기 위함이며 다음의 링크에서는 자세한 내용을 읽을 수 있습니다. 인지 발달 이론에서 핵심은 인간이 본인이 모르거나 새로 알게된 사실을 받아들이는 과정에서 본인의 인식 (뉴런의 Weight로 이해하면 됩니다)이 잘못된 결과에 대해 오차를 통해 다시 적용하는 과정이 명시적으로 존재하지 않으며, 정보 제공자를 통해 지식 체계가 강화되고 이전의 지식과 동화됩니다. 힌튼은 이에 그치지 않고 피질의 학습 과정에 대해 다시끔 살펴보며, 아래의 그림을 통해 다시 살펴보겠습니다.

마치 Nature의 논문 리뷰 같습니다만.. 시각 정보를 처리하는 피질 (Visual Cortex)의 연결된 구조는 Top-down (Forwardpropagation)으로 구성되어 있으며, 만약 Backpropagation에 해당하는 Bottom-up 과정이 존재한다면 피질로 부터 시각 정보를 받아들이는 망막 이전 시신경까지 오차가 전파되는 과정이 있어야하는데, 실제로는 그렇지 않다는 것 입니다. 시각 정보는 마치 일종의 동영상을 전달받는 것과 같이 연속적인 프레임으로, 오차 전파를 위한 추가적인 Time-out이 존재하지는 않는다고 합니다. 피아제의 인지 발달 이론으로 설명하면 우리가 이미지를 보고 있다면, 시각 피질은 이미지에 대한 정보를 수정하는 것으로 보입니다. 즉, 이미지를 보면서 해당 지점에서 일종의 Loop를 통해 정보 체계를 수정하는 것과 같은 의미입니다.

또한 힌튼은 만약 Backpropagation이 존재한다면 윗 문단에서 말한 것과 같이 인식체계에 주기적인 Time-out이 존재해야한다고 주장합니다. 역전파가 일어나는 동안, 파이프라인 뒷쪽의 정보가 앞쪽으로 전해져야하는데, 인식은 연속적이기 때문에 이를 위한 Time-out이 존재하지 않습니다. 마치 Online-learning처럼, 이미지가 인식될때마다 학습된다는 의미입니다.
또한 힌튼이 의심한, 그렇다면 Backpropagation이 일어나기 위해 필수적인, 뇌가 이전의 정보를 기억하고 있는가에 대해 Unknown Blackbox Block이 존재하는 경우엔 설명이 안된다는 점입니다. 또한 역전파 계산을 위해서는 뉴런의 모든 지점이 마치 미분 가능한, 도함수의 형태를 가지고 있어야하는데 이러한 부분도 불명확하다는 점입니다.

위의 그림을 통해 다시 살펴보면, Blackbox에 대해 FF 알고리즘은 적용할 수 있지만, Backpropagation에 대해서는 완벽한 정보를 가지고 있지 않기 때문에 연산이 불가능합니다. 힌튼은 이 점에 대해 강화학습이 해결할 수 있지 않겠냐는 반론에 대해 미리 준비한 듯 강화학습과, 그에 대한 단점을 언급합니다.
강화학습에 대한 지식이 없어 해당 부분에 대해 명확한 설명을 드리기는 어려우나, 강화학습은 뉴런의 활동에 대해 weight의 일부에 랜덤한 변화를 주어, 변화에 따라 바뀌는 결과에 대한 보상을 해주는 방식이라고 합니다. 강화학습에서 에이전트는 보상을 최대화하는 방식으로 학습합니다. 예를 들어 게임에서 이긴 경우 양의 보상을, 진 경우 음의 보상을 통해 보상을 최대화하려는 방향으로 행동을 선택하고 보상이 높은 전략을 취하게 하는게 강화학습의 전략입니다. 따라서 강화학습은 Blackbox에 상관없이 Forwardpropagation이 가능하다고 볼 수 있습니다.
하지만 힌튼은 강화학습 방식에 대해, 해당 방식은 Variance, 즉 경우의 수가 굉장히 높기 때문에 각 Parameter의 변화가 output에 미치는 영향을 확인하기 어렵다고 합니다. 이를 위해 Parameter의 수에 반비례하게 learning rate를 설정하는 방식도 존재하지만, Parameter의 수가 늘어날 수록 학습 속도가 느려져 이점이 사라집니다.
힌튼은 FF (Forward-Forward) 알고리즘의 장점으로 ReLU와 같은 비선형성을 포함하지 않는 네트워크도 학습할 수 있으며 (Backpropagation의 부재에서 오는 이점으로 보입니다) 연속적인 데이터에 대해 학습의 Pipeline이 지속된다는 장점이 있다고 주장합니다. 하지만 어떤 때는 (특히 대용량 데이터에 대해) Backpropagation보다 느리며 아직은 Generalized 되지 않아 전력 문제가 되지 않는 한 (Backpropagation을 통한 딥러닝 모델의 학습은 많은 GPU와 전력을 필요로 하기에) 아직은 Backpropagation 알고리즘을 통한 학습 방법을 능가하긴 어려울 것으로 보인다고 말합니다. 즉, FF 알고리즘은 그 자체로 Backpropagation을 이길만큼 성능면에서 혁신적이라고 볼 수는 없으나, 딥러닝 학습의 새로운 지평선을 열어준 것으로 보입니다. 그럼, 이제 FF 알고리즘에 대해 알아보겠습니다. 사실 그 아이디어는 굉장히 간단합니다.
2 The Forward-Forward Algorithm
기본적으로 딥러닝 모델, MLP 구조에서 각 레이어는 입력 정보가 상이하기 때문에 출력 Feature 또한 상이하다는 것이 전제되어 있습니다. 즉, 데이터의 분포가 다르므로 레이어에서의 Representation이 다릅니다. 이를 다른 시각으로 보면 각 레이어에서의 독립적인 Task를 구하는 과정, 즉 Greedy 알고리즘으로 생각할 수 있습니다. 그러므로 FF 알고리즘은 모든 레이어를 독립적으로 학습한다고 가정합니다.
해당 가정을 토대로, FF 알고리즘은 서로 반대되는 Object function을 갖는 두 데이터가 각각 Forward 되면서 역전파를 대체할 수 있는데, 이 때 두 Forward Pass를 Positive Pass와 Negative Pass라고 명합니다. Possitive Pass는 Real (Positive) 데이터에 적용되며, 각 레이어의 Weight이 goodness를 증가하는 방향으로 작용합니다. 이 때 말하는 goodness는 한국어로 번역이 꽤 어려운데, 쉽게는 최적의 선택을 한다고 생각하면 될 것 같습니다. 반대로 Negative Pass는 Negative 데이터에 적용되어 각 레이어의 Weight이 goodness를 감소하는 방향으로 작용합니다.
위의 작동 과정을 풀어 설명하자면, 마치 Contrastive learning과 같이 Positive Pass는 Positive 데이터에 가까워지며 동시에 Negative Pass와는 멀어지게끔, 반대로 Negative Pass는 Negative 데이터에 가까워지며 (실제로는 Positive 데이터에 멀어진다고만 해석하는 것이 더 옳은 것 같습니다만) Positive 데이터에 멀어지는 방향으로 작용한다고 볼 수 있습니다. 그렇다면 이 때 말하는 goodness는 어떻게 구해질까요? 힌튼은 단순히 Squared Sum을 통해 구합니다. 힌튼은 이에 대해 각주로 미분이 쉬움과 동시에 Layer normalization이 goodness의 과정에서 제거되기 때문이라고 합니다. 뒤의 이야기에 대해서는 정확한 설명은 없지만, 뒤의 Layer normalization이 나올 때 다시 추정해보겠습니다.
이제 아래의 그림을 통해 살펴보겠습니다. 아래 그림에서 왼쪽은 Real (Positive)데이터로, 우리는 이 때 goodness를 증가시키는 방향으로 작용해야합니다. 따라서 레이어의 신경망 활동을 통한 Output인 a_j^l 들의 Squared Sum이 되며, 반대로 오른쪽의 Negative Pass는 Negative 데이터에 대해 goodness를 감소시키는 방향으로 작용하니 a_j^l의 Negative Squared Sum으로 goodness를 감소시킵니다.

사실 본 논문은 해당 아이디어가 전부입니다. 물론 아래에서 디테일한 부분에 대해 조금 더 짚겠지만, 핵심적으로 알아야할 점은 Forward Pass에서 일종의 Loop를 돌며 마치 contrastive learning과 같이 Positive / Negative Pass가 goodness를 각각 증가시키는, 감소시키는 방향으로 작용하며 인지과정을 통한다는 점입니다. 디테일한 부분은 아래 논문의 수식을 통해 다시 살펴보겠습니다.
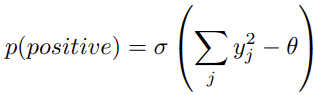
위의 수식은 특정 레이어 노드의 인덱스 j에 대해 Positive sample일 확률을 구하는 수식으로, p(negative)는 해당 수식의 음의 부호를 붙인 것과 같습니다. 이 점을 유념한 채 위의 수식을 살펴보면, 각 레이어는 Positive / Negative Pass에 따라 Positive input에 대해서 Negative input을 기준으로 특정 Threshold만큼 높이는 것을 목적으로 합니다. 이 말이 조금 어렵게 다가올 수 있는데, Threshold는 Positive와 Negative를 구별해낼 수 있도록 만드는 일종의 기준선과 같이 쓰이며, Positive 데이터는 Threshold 보다 높게, Negative 데이터는 Threshold 보다 낮게 goodness가 형성됩니다. 물론 아직도 이해가 어려울 수 있으나, 더욱 중점적으로 고민할 수 있는 부분은 역전파는 Output에서만 Objective function을 가지고 이를 통해 Weight을 조절해나갔는데, FF 알고리즘은 각 레이어마다 Objective function을 가지는 것을 알 수 있습니다.
사실 본 논문을 읽을 때 1장과 2장에서만 반나절을 투자할만큼 개념이 어려웠는데, 이해가 되었다 생각이 들었을 때 작성했는데도 말로 풀다보니 다시 어려운 것 같네요.. 후에 준비가 된다면 세미나 시간에서 다시 살펴보도록 하겠습니다.
2.1 Learning multiple layers of representation with a simple layer-wise goodness function
결국 우리는 단일 레이어에 대해 각 데이터에 대한 goodness, 최적의 선택을 구하는 방식을 알게 되었습니다. 다만, 첫 번째 레이어의 Output이 그대로 두 번째 레이어의 Input으로 전해진다면, 하나의 문제점이 있을 수 있습니다. 이는 우리가 하나의 레이어에서 이미 Squared Sum을 통해 goodness로 Positive / Negative 데이터를 구별할 수 있게끔 학습했기 때문에, 두 레이어의 Output vector의 크기만으로 구별될 수 있다는 점입니다. 이는 코드 상으로 살펴봐야될 것 같긴 합니다만, 어쨋든 두 Output vector의 크기가 다르다면 두 번째 레이어부터는 새로운 Representation을 가질 수 없게 됩니다. 이는 자명합니다. 두 번째 레이어에서부터 새로운 Representation을 기대하기 위해선 Output Feature Vector의 크기를 다음 레이어의 Input으로 사용하기 이전에 Normalize해주면 됩니다. 방향 정보만 전달해주려는 목적이죠. 이렇게하면 첫 번째 레이어에서 goodness를 계산하기 위해 사용했던 정보들이 제거되는 것 처럼 보이지만, Orientation, 즉 방향은 전달하기 때문에 Relative activity, 연관성 있는 활동은 이어나갈 수 있다고 합니다. 이 때의 Normalization은 이전 레이어의 Mean을 빼지 않은 채 진행하였습니다.
3 Some experimnets with FF
이전 문단에서 대뇌 피질의 학습 과정부터 FF 알고리즘의 소개까지 꽤나 긴 시간을 보냈는데, 역시 실험이 중요한 것처럼 보입니다. 비지도학습과 지도학습에 대해 진행하며 실험이 이어지다 뒷편의 6절부터는 볼츠만 머신과의 차이부터 GAN과의 연관성, Contrastive learning과의 관계 등 꽤나 많은 부분에 대해 언급하지만, 이번 리뷰에서는 MNIST 데이터 셋을 토대로하는 비지도학습과 지도학습에 대한 실험을 살펴보고 리뷰를 마치겠습니다. 후에 기회가 된다면 2편으로 다른 내용에 대해 다루고 싶지만, 볼츠만 머신 등의 다른 부분에서 제가 아직 이름만 들어봤던 방법 혹은 알고리즘이라.. 리뷰에 풀기에는 오히려 혼선을 줄 것 같아 지양하겠습니다.
힌튼은 MNIST 데이터 셋이 FF 알고리즘의 Feasibility를 보이는 좋은 예시라고 보인다고합니다. CNN은 MNIST 데이터 셋에 대해 0.5-0.6%의 오차를 보이며 MLP는 약 1.4%의 오차를 보입니다.
실험 이전에, 힌튼은 FF 알고리즘의 두 의문점에 대해 설명합니다. 우선, Negative 데이터를 학습하는 goodness가 어떠한 효과를 가져오는지, 두 번째로는 Negative data를 어떻게 만들어내는지입니다. 힌튼은 해당 의문점에 대해 설명하고자 Hand-crafted Negative data를 생성합니다. Self-supervised learning 의 주된 학습 방법인 Contrastive learning (위에서 계속 해당 FF 알고리즘이 마치 Contrastive learning과 같다고 설명했습니다)를 Supervised learning에 활용할 때는 입력 Input vector를 Representation vector로 바꾸어 이를 label에 대한 Confidence score (Probability)를 구하는 Linear transformation으로 학습하는 구조를 활용합니다. 이러한 과정은 Hidden layer가 없이 학습되므로 Backpropagation이 따로 필요하지 않으며, FF 또한 이러한 관점에서 Positive Sample과 Negative Sample을 활용한 Representation learning을 진행합니다.
이 때 FF 알고리즘이 이미지의 전반적인 부분 (long-range correlation)을 학습하기 위해서는 Negative dataset이 Positive dataset과 이미지가 전반적으로는 다르나, 부분적으로는 유사하게 구성하는 것이 중요합니다. 이렇게 해야만 각 레이어가 이미지의 전반적인 부분에 집중하기 때문입니다. 이는 당연하게도, 레이어는 Short-range correlation에 대해서는 Positive/Negative를 구별하기엔 굉장히 어렵기 때문입니다. 이를 위해 힌튼은 1/0으로 구성된 마스크를 넓게 구성한 다음, Real 데이터를 마스크와 마스크의 1/0을 반대로 뒤집은 마스크를 적용하여 합한 데이터를 테이터 셋으로 구성합니다. 아래 그림을 살펴보면 좋을 것 같습니다.

이제 Negative Sample을 생성한 채, 4개의 레이어를 갖는 MLP를 학습한 결과 1.37%의 오차를 보였다고 합니다. 실제로 Label을 예측할 때는 뒷단의 세 레이어의 Normalized Output Vector를 사용했다고 합니다.
다음은 Supervised learning입니다. FF 알고리즘은 오차를 역전파하는 과정이 없기 때문에, Supervised learning을 위해서는 Input에 Label을 추가하는 방식으로 구현합니다. 이번에는 Label이 옳다면 Positive, 틀리다면 Negative 데이터가 됩니다. 이 때 중요한 점은 Positive / Negative를 구별짓는 것이 오직 label이므로, FF 알고리즘에서 Negative 데이터로 판명된 Representation (Feature)은 Prediction 시 모두 무시하게끔 학습해야한다는 점 입니다. 힌튼은 앞선 Unsupervised learning에서와 동일한 MLP 구조를 학습시켰을 때, 1.36%의 오차가 나타났다고 합니다.

결국 두 방법 모두 현재 Backpropagation을 사용한 CNN 구조보다 오차가 높다는 점은 존재하지만, 힌튼이 말하고 싶은 점은 특정 Label과 이미지만을 입력으로 넣은 후, 각 레이어의 Activation 결과로 축적된 goodness를 통해 가장 높은 goodness를 갖는 Label을 예측값으로 두면 되는, 간단하면서도 직관적인 구조이며 이것이 정말로 뇌가 이미지를 인지하고 학습하는 과정임을 시사합니다. 현재는 Positive Pass와 Negative Pass가 Squared Sum으로 단순히 구현되어 있는데, 이를 발전시키면 더 좋은 결과를 보이지 않을까하는 사견이 듭니다.
리뷰를 마치려 했으나 그래도 실험 테이블 하나쯤 가져오고자, CIFAR-10 데이터셋에서의 실험을 보겠습니다. 현재 CIFAR-10은 50,000 장 분량의 32x32 크기의 RGB 이미지로 구성되어 있으며, Object와 Background 등 정보가 다양하므로 앞선 MNIST 때와 같은 방법으로는 학습이 진행기 힘들 것으로 보입니다. FF 알고리즘에서 가장 중요한 점은 CNN과 달리 레이어 간의 Weight가 공유되지 않는다는 점으로, 따라서 힌튼은 2-3개의 Hidden Layer를 가질 때 한 레이어에서 3072 개의 노드를 갖도록 구성했습니다. 3072라함은 결국 32 x 32 x 3이므로, 각 Hidden layer에서 Output으로 나오는 텐서의 차원을 모두 곱한 값에 해당합니다. 이 때 연산이 되는 Hidden unit은 11x11의 Receptive Field를 갖고, 각 노드에서 Input의 크기는 11 x 11 x 3입니다. 이 부분이 굉장히 직관적이면서.. 이해하기에 쉽지 않았네요. 아래 표를 살펴보겠습니다.
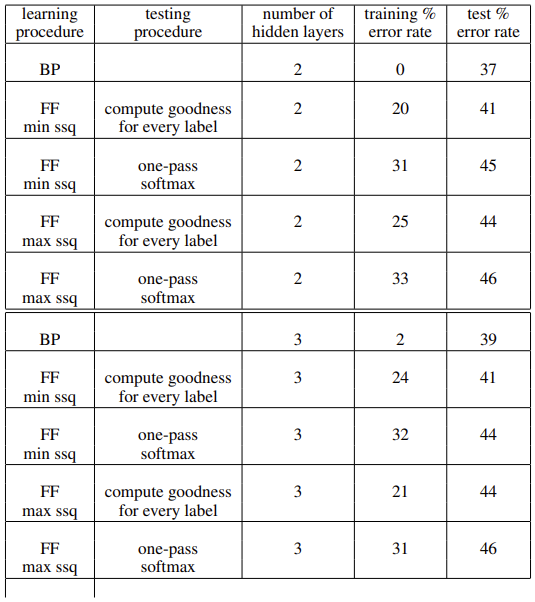
학습 구조를 동일하게 한 채 Backpropagation (BP)와 FF 알고리즘에서의 에러를 비교한 결과입니다. 실험에서 살펴볼만한 점으로는 FF가 BP 방식에 대해 크게 뒤쳐지지는 않으면서도, BP가 traning error를 보면 모델이 Fitting되는 속도가 더욱 빠른 것을 알 수 있습니다. 실험 방식에 대해 Compute goodness for every label은 위의 MNIST 실험에서 살펴본 것이며, one-pass softmax는 최종 Output layer에서의 goodness를 사용한 것으로 보입니다.
이번 논문은 사실 한 주에 걸쳐 쓰기에는 쉽지 않았던 것 같습니다. 무엇보다 딥러닝 전반적인 지식을 가지고 있는 채로 작성해야만 수월하게 설명하고 다양한 관점에서 이야기를 풀어나갈 수 있었을 것 같은데, 그러지 못한 상태에서 읽다보니 초반부에 많이 어려웠던 것 같습니다. 추후 연구가 더욱 진행된다면, 해당 논문이 센세이션을 불러올 수 있지 않을까하며 지금은 방법론에 대해 간단히 이해하고 넘어가려고 합니다. 이상으로 리뷰 마치겠습니다.
좋은 리뷰 감사합니다.
‘FF (Forward-Forward) 알고리즘의 장점으로 ReLU와 같은 비선형성을 포함하지 않는 네트워크도 학습할 수 있으며’ 라고 되어있는 문장에 대해 질문이 있습니다. activation function인 ReLU는 gradient의 saturate가 되는 현상이 발생되는 것을 막기 위해 사용하는 함수로 알고 있는데, FF 알고리즘은 saturate현상이 발생하지 않는 게 맞는지 궁금합니다.
감사합니다.
안녕하세요 이상인 연구원님. 어려운 논문 읽으셨네요. Forward pass랑 Negative pass는 같은 Forward Pass를 공유하는데 입력 데이터에서의 차이만 존재하는 거죠? 설명을 읽어보면 linear 레이어 forward 하는거랑 동일한 것 같은데요. convolution에서도 작동하는건가요 linear에서만 작동하나요? 내용이 쉽지는 않네요 세미나 기대하겠습니다.
리뷰 잘 읽었습니다. 언젠간 읽어보겠다고 다짐한 논문이었는데 자세한 리뷰 덕분에 읽지 않아도 될 것 같네요.
일단 해당 논문은 NIPS2022에 개제가 된 논문은 아닌걸로 알고 있어서 그 부분은 수정하는게 좋아보입니다.
궁금한게 Goodness가 감소했다라는 것은 결국 우리가 몰랐던 정보를 받아 들였다라고 생각하면 되나요?
안녕하세요. 좋은 리뷰 감사합니다.
순전파만을 가지고 contrastive learning과 유사하게 학습을 진행한다는 점이 신기한 것 같습니다.
그런데, 결과를 이용한 역전파를 수행하지 않고 positive sample에 대해서는 goodness를 상승시키고, negative에 대해서는 하락 시키기 위해 입력 데이터에 라벨을 삽입한 것으로 보이는데, 여기에서 두 가지 의문이 있어 질문드립니다.
1) 각 계층의 학습이 진행될 때, 입력 데이터가 positive인지 negative인지에 따라 학습의 방향이 달라질 텐데, 그렇다면 이 여부는 입력 데이터의 라벨을 보고 순전파 과정에서 판단하는 건가요?
2) 너무 역전파 기반의 지도학습 방법론에 매몰된 생각인가 싶기도 하지만, 입력 데이터에 라벨을 포함하면 결국 모델이 잘못된 feature를 학습할 수 있지 않나요?
감사합니다.
리뷰 잘 보았습니다.
궁금한 점이 있는데 먼저 positive에 대한 goodness는 높이고 negative에 대한 goodness는 줄이는 방향으로 학습을 한다고 했습니다. 그리고 그 goodness를 계산하는 방식은 레이어의 출력값의 squared sum으로 계산된다고 이해했습니다.
근데 여기서 goodness의 정의를 왜 출력값의 합으로 정했을까요? 리뷰에서는 미분이 편하다는 이점 등을 말씀해주시긴 했는데 사실 저 goodness라는 개념 자체가 너무 모호하다보니 해당 값이 커지거나 작아지는 방향으로의 학습이 너무 와닿지않네요..(그냥 goodness는 오차의 반대 의미 아닌지?)
게다가 미분이 쉽다라는 얘기가 나와서 하는 말인데 그럼 FF도 미분을 통해서 weight을 조정하는 방식인건가요? 다만 레이어 각각에 대해서 미분을 통해 weight을 조정하는 차이정도인걸까요? 각 레이어마다 objective function을 두고 backpropagation 하는 방식이 FF라면 이 학습 방식은 레이어 두세개 정도로 구성된 mlp말고도 vit large 수준의 네트워크를 학습시킬 수는 있는 것인가요?
(리뷰에서는 매우 간단한 모델 구조에서만 실험한 것 같아서 혹시 복잡한 모델에 대해서도 학습하는지 궁금하네요)
리뷰에서는 결국 학습의 목적, 방향성에 대해서는 설명하는
것 같은데 실질적으로 weight이 어떻게 조정되는지에 대한 설명이 부족한 것 같아서 궁금증도 많아지고 FF의 이점 및 차별성에 대해서도 의문이 생기는 것 같아요. positive sample에 대해서 goodness가 커지는 방향으로 weight이 조정된다는 방향성을 토대로 실제 backpropagation과 달리 FF는 어떤 방식으로 가중치를 조정하는지 그리고 해당 방식의 장점을 한번만 더 요약해줄래요?
좋은 리뷰 감사합니다.
어려운 내용인 것 같은데 리뷰를 최대한 이해를 돕기위해 풀어 써주셔서 감사합니다ㅎㅎ
질문 하나 드리자면 “Positive 데이터는 Threshold 보다 높게, Negative 데이터는 Threshold 보다 낮게 goodness가 형성됩니다.” 이 부분이 학습을 통해 goodness를 데이터에 부여하는게 맞나요?
그렇다면 positive로 판단되었을때와 negative로 판단되었을 때 모두 같은 network를 통해 학습이 진행되는건가요?
안녕하세요 좋은 리뷰 감사합니다.
방법론을 설명해주실 때 positive인지 negative인지를 goodness를 통해 파악한 뒤 상응하는 pass들이 goodness를 pos 또는 neg 방향으로 향하도록 작용한다고 해주셨는데요, 이 때 작용이라는 것이 어떠한 연산을 포함하는 것인가요? 단순히 goodness를 계산한 뒤 normalization 후 뒷 층으로 넘겨주는 형태로 이해하였는데 어느 부분에서 goodness가 원하는 방향으로 가도록 작용하는지를 잘 이해하지 못하였습니다.
그리고 positive 데이터가 real과 같은 의미라고 하셨는데 supervised 상황에선 같은 클래스를 의미하고 unsupervised 상황에서는 마스킹을 통해 만들어진 것이 아닌 실제 데이터를 의미하는게 맞나요?
안녕하세요. 리뷰 작성자 이상인 연구원입니다.
올해 초 해당 논문 이후 다양한 경로 (페이스북 생활코딩, PytorchKR, NeurIPS Session)를 통해 해당 논문의 제목을 접하며, 제프리 힌튼의 새로운 고찰을 담은 논문에 많은 관심을 가져 제 리뷰를 읽어주셨으리라 생각합니다.
저 또한 논문을 처음 읽기 전 Backpropagation에 대한 회의를 Backpropagation을 만든 힌튼이 언급하니 흥미로울 수 밖에 없었는데, 그만큼 뇌과학부터 딥러닝 전반에 걸친 방법론과의 비교를 담은 논문으로 많이 어려웠습니다. 실제로 리뷰에서 언급했듯이 제가 잘 알지 못하는 분야 (강화학습, 볼츠만 머신, GAN 등)과 관련한 부분에서는 설명이 미약하거나 마저 담지 못하였습니다.
어찌보면 여러 편에 걸쳐 작성해도 부족할 만큼 내용이 어려우면서 고찰이 깊기도 했는데, 저는 그 중 뇌과학과 FF 알고리즘의 과정과 실험 내용만을 집중적으로 리뷰하고자 노력했습니다.
해당 댓글은 다름이 아니라 논문에 대한 관심과 질문이 많아, 전체적으로 핵심 내용에 대한 리뷰를 코드를 통해 다시 언급하며 질문들을 모아 다른 분들의 질문 내용도 한번에 확인할 수 있도록 하고자 함 입니다. 우선 전체적으로 질문 내용들을 모으면 아래와 같습니다.
참고로 오피셜 코드는 공개되지 않았지만, 몇몇 깃허브를 보니 다음의 깃허브에서 파이토치로 구현한 FF 알고리즘이 이해가 쉽게 작성되었다고 생각이 들어, 해당 코드를 토대로 설명하겠습니다. https://github.com/carloalbertobarbano/forward-forward-pytorch
모든 질문에 대한 답변 중 논문에서 명시적으로 언급되어 있지 않은 질문에 대한 답변은 저의 이해를 바탕으로 한 사견이기 때문에, 틀릴 수도 있습니다.. 후에 다른 연구원분께서 다른 시각과 설명에서 본 논문의 리뷰를 작성해주셨으면 합니다.
Q-1] 리뷰 중 “FF 알고리즘은 ReLU 등의 비선형 활성화 함수를 포함하지 않아도 학습할 수 있다”는 문장을 읽은 후, FF 알고리즘의 Gradient Saturation (Vanishing Gradient) 문제를 피할 수 있는지에 대한 질문 [양희진 연구원]
A] 해당 질문에 대한 답변을 위해선, 알고 있으신 내용이지만 Vanishing Gradient 문제가 생기는 이유에 대해 짚으면 금방 의문점을 해결할 수 있을 것이라 생각합니다.
Vanishing Gradient는 Backpropagation 과정 중 오차로부터 입력 레이어로 오며 1보다 작은 Gradient의 지속된 곱셈으로 인해 Gradient가 0이 되는 과정입니다. 핵심은 Gradient가 곱해져야한다는 점 입니다.
Backpropagation에서는 Chain Rule에 의해 입력단의 레이어는 모든 레이어에서의 Gradient 곱을 가지고 있습니다. 하지만 FF 알고리즘은 그렇지 않습니다. 예를 들어 히든 레이어의 노드들이 각각 활성화 함수를 통과해 Output을 뱉으면, 해당 레이어에서 Loss를 계산한 다음 바로 학습을 이어나갑니다.
여기서 다시, Loss를 계산한 다음 학습을 이어나간다는 말이 Backpropagation이랑 다를 것이 무엇이냐고 생각할 수 있습니다. 왜냐하면 실제로 코드를 확인한다면, 코드 내에서도 loss.backward()로 구현되어 있기 때문입니다. 하지만 이 backward()는 실제로 역전파 과정이 아닌, 단순히 미분을 계산하는 과정의 코드입니다.
물론 그럼에도 여전히 헷갈릴 수 있습니다. 하지만 Backpropagation은 명확히 전 레이어를 통과한 후 오차에 대해 전파하는 과정이라면, 현재는 레이어마다 리뷰에서 언급한 일종의 루프를 통해 해당 레이어의 Gradient를 갱신하고 있기 때문에, Gradient Saturation과는 상관이 없다고 생각됩니다.
Q-2] Forward Pass와 Negative Pass는 같은 Forward Pass를 공유하는데 입력 데이터에서의 차이만 존재하는지, 그렇다면 입력 데이터의 라벨을 보고 순전파 과정에서 판단하는지, 그렇다면 모델이 잘못된 Feature를 학습하지는 않는지, 또한 Convolution에서도 작동하는지에 대한 질문 [이광진 연구원, 백지오 연구원, 김현우 연구원]
A] 질문해주신 바가 맞습니다. Forward Pass와 Negative Pass를 설명하기 위해 각각의 Pass를 분리하여 설명하였지만, 정확히는 입력 데이터에서만 차이가 존재하며 하나의 Pass인 해당 레이어에서 일어납니다. 이를 위해 MNIST 예시를 다시 들고와서 설명하면 좋을 것이라 생각하며, 뒤의 Convolution에서도 작동하는지에 대한 답변이 될 것으로 보입니다.
우선, Supervised learning의 MNIST 예시에서 저자의 실험을 모사한 코드를 확인하면, Linear Layer의 입력으로 넣는 784개의 픽셀 (28 x 28)에 대해, 앞 10개를 0으로 만든 다음, 라벨에 해당하는 인덱스에 특정 값 (코드에서는 784개의 픽셀의 최댓값을 넣었습니다. 이는 One-Hot Encoding과 연산 과정에서 Impulse를 주기 위함으로 사료됩니다)을 넣습니다.
모든 데이터에 이와 동일하게 구성하기 때문에, 또한 모델의 입력 데이터에 라벨만큼의 데이터를 0 / Input의 최댓값으로 넣기 때문에 잘못된 Feature를 학습한다고 생각할 수도 있지만, 우선적으로 모든 레이어에 동일하게 적용되는 부분이며 아마 그 점으로 인해 One-Hot Encoding에 단순 1 / 0이 아닌 Max를 넣지 않았을까 생각합니다.
그러므로 우선적으로 입력 데이터의 라벨을 통해 순전파 과정에서 학습하는 과정이 존재한다고는 볼 수 있으나, 정확히는 라벨을 매번 레이어의 입력으로 넣어 최종 Output에 대한 Loss를 역전파하는 과정을 배제하고자 이와 같이 구성했다고 보는 것이 더 옳지 않을까 판단됩니다.
라벨에 해당되는 인덱스에 특정 값을 넣었다는 말은 곧 해당 데이터는 논문의 Positive data에 해당합니다. 하지만 Negative data에 대해서는 랜덤 인덱스에 대해 값을 부여하여 데이터의 변형을 줍니다. 이 때 Negative data는 Supervised learning에서는 단순히 라벨을 잘못 부여하는 방식으로, Unsupervised learning에서는 이미지에 변형을 줘 Representation을 변형하는 식으로 구성합니다. 이렇게 변형을 준 것은 Negative로, 실제 데이터는 아닙니다. 실제 데이터는 원본 데이터입니다.
그렇다면 Unsupervised learning에서 Contrastive learning과 같이 학습할 수 있다는 부분과 이어지게 됩니다. 결국 하고자하는 말은 이처럼 라벨에 변형을 주어 Positive / Negative data의 차이를 만든 후, 하나의 Pass인 레이어를 통과하는 것 입니다.
두 번째로, Convolution에서도 작동하는지에 대한 질문입니다. 이는 FF 알고리즘이 Weight를 공유하는지와 연관지어 답변드릴 수 있을 것 같습니다. 우선 논문 중, FF는 네트워크가 Weight-sharing이 가능하지 않도록 의도했다고 합니다. 이는 어찌보면 당연합니다. Weight가 공유되는 순간, Backpropagation이 의도되는 것과 같기 때문입니다.
따라서 FF 알고리즘은 Weight를 공유하지 않으며, 그러므로 Backpropagation Net 중 하나인 CNN과 비교될 수 있습니다. CNN은 단일 Convolution 레이어에서의 Parameter는 Feature map의 모든 Receptive Field에 동일하게 적용되지만, FF 알고리즘은 불가능합니다.
그러므로 Convolution에서는 작동하지 않는다고 볼 수 있다고 생각할 수 있습니다. 하지만 Convolution 연산의 Receptive Field 측면만 연관 짓는다면, 11 x 11 크기로 한정된 Receptive Field를 갖도록 연산하는 과정은 존재합니다. Fully-Connected는 되어 있지 않은 MLP 구조인 것입니다.
또한 추가적인 사실로, Input / Output Resolution을 유지하고자 CNN에서는 Padding을 사용하나, FF 알고리즘에서는 Edge 부분의 Hidden 레이어 노드에 대해서는 Input에 맞게 Truncate하여 사용합니다. 이것이 마치 CNN 같은 모습을 보이며, 실제로 CIFAR-10에서 꽤나 좋은 성능을 보인 이유가 아닐까 생각됩니다.
Goodness에 대한 질문이 전체적으로 많은 것 같습니다. 접해보지 못한 개념이라, 저 또한 완벽한 이해가 되었을까 하는 생각이 들긴 했습니다만, 질문을 정리해보고 다시 설명드리도록 하겠습니다.
Q-3] Goodness의 감소는 곧 모르던 정보를 받아들이는 것과 같은 의미인지? Goodness의 정의에 대한 질문 및 학습 데이터와 Goodness의 관련성 [임근택 연구원, 신정민 연구원, 김도경 연구원]
A] Goodness의 증가와 감소는 Positive / Negative 데이터를 이진 분류하는 것과 같다고 보는 것이 맞는 것 같습니다. 이를 위해 MNIST 예시가 적절하다고 보여지는데, MNIST 데이터를 분류하고자 예측하는 코드를 살펴보면,
0-9의 입력 라벨을 넣어 각 입력 라벨에 해당하는 레이어의 Goodness를 뽑아냅니다. 최종적으로는 Goodness의 총합이 가장 높은 것을 예측 값으로 활용하게 됩니다. 그렇게 볼 때 Goodness는 곧 Positive / Negative 데이터를 분류하기 위한 역할을 수행한다고 볼 수 있습니다.
하지만 Goodness의 감소라는 것이 곧 해당 데이터를 Real data로 인지하지 못하는 것이다보니, 모르는 정보를 받아들이는 것과도 같다고 봐도 무방한 것으로 생각됩니다. Real data가 아닌 data, 곧 Negative data를 받아들이는 일종이라고 봐도.. 무방하지 않을까 생각합니다.
우선적으로 Goodness가 왜 단순히 출력값의 합, Squared Sum으로 구성했는지에 대해서는 논문에 다음과 같이 나와있습니다. “There are two main reasons for using the squared length of the activity vector as the goodness function. First, it has very simple derivatives. Second, layer normalization removes all trace of the goodness”
흠.. 힌튼은 분명 후반부에 squared sum이 아닌 다른 형태로 Goodness를 구성할 수 있다고 언급하며, 저는 이 부분이 앞으로의 FF 알고리즘의 연구의 시발점이 되지 않을까 생각합니다. 우선 두 번째 이유에 대해서는 생각해봐도 잘 모르겠네요.. 힌튼은 아마 Contribution으로 새로운 학습 방법을 제시하며 그에 걸맞게 Goodness 함수를 변경시키는 다양한 실험은 진행하지 않아서일까요?
단지 새로운 인사이트를 제공하고자 했을 때, 구현의 단순성을 위함이라고 생각했지만, 두 번째 이유가 핵심일 것으로 보이는데, Squared Sum으로 구성해도 어짜피 Layer normalization에서 길이의 정보는 Normalize되니 상관 없다(?)는 생각으로 이렇게 작성했을까하는 생각도 드네요.. 정확한 답변을 드리지 못해 죄송합니다.
FF 알고리즘도 미분을 통해 Weight을 조정하는 방식입니다. 코드에서는 아직 ReLU를 사용하지만, 이것이 레이어 별로 구성됩니다. vit-L 수준의 네트워크를 학습시킬 수 있는지에 대한 여부는, 불가능한 것은 아닙니다. 위의 CNN 예시가 그를 입증하는 것 처럼 보이죠. 하지만 논문의 실험 부분은 MNIST, CIFAR-10 등의 미니 데이터 셋에 대해 진행하며, 힌튼이 말하듯 큰 데이터 셋에서는 아직 Backpropatation의 성능이 훨씬 좋다고 말하듯이,
알고리즘의 성능을 Saturation하여 발표한 것이 아닌 작은 데이터 셋에서 그 실용성만을 보기만을 원하는 것이 논문의 소개 및 실험 파트에서 자명하게 나타나는 것 처럼 보입니다. 복잡한 모델에 대해서도 학습하는지는 모델의 구성에 따라 다르겠지만, 우선적으로 논문의 FF 알고리즘은 Task 별로 판을 다시 짜야합니다. 레이어를 데이터에 맞게 구성하고, Supervised 경우 라벨 수에 맞게 라벨을 입력으로 넣으면서도, 이미지의 Representation을 해치지 않게 새로운 알고리즘의 도입 또한 필요하리라 생각됩니다.
따라서 현재 알려진 복잡한 모델에 일종의 Loop를 통해 레이어 별 학습하는 것은 논문에서는 나와있지 않습니다. (물론, 어떤 문장에서 이에 대한 견해가 소개되었을 수도 있지만 제가 놓쳤을 수도 있습니다.)
Weight 조정과 같은 과정은 현재의 Backpropataion을 레이어 하나에 대입하여 그대로 생각하면 됩니다. 하지만 이 작업이 레이어 별로 Output이 나오며 전체적으로 조정되지 않는다는 점이죠.
Positive data가 입력으로 들어왔을 때 Goodness가 커지는 방향은 해당 레이어에서 Loss를 1/n(\sigma{1+exp(-g_pos + \theta} + exp(g_neg – \theta)), \theta = Threshold로 구성했을때, g_pos가 Threshold 보다 커지도록 학습하게 될 것이므로 해당 레이어의 Weight이 증가하는 방향으로 움직일 것으로 보입니다. (이는 코드를 통한 해석입니다)
해당 방식의 장점은 서두에서 말씀드린 바와 같이 학습의 새로운 지평선을 열어준 것으로 보는 것이 맞는 것 같습니다. 혹은 CNN과 같이 GPU를 많이 사용하지 않고도 MLP 몇몇으로도 비슷한 성능을 내어 학습 및 추론 단계에서 Computing Power를 많이 필요로하지 않는 것을 장점으로 볼 수도 있지만, 무엇보다 가장 핵심은 Backpropagation이 실제 뇌의 학습 과정에 해당하지 않는 것으로 보여, 실제 뇌의 학습 방법을 모사한 알고리즘을 구상한 것이 핵심 Contribution이 아닐까하는 생각이 듭니다.
리뷰에 대한 답글을 쓰다 보니, 또 다시 해당 논문의 내용이 헷갈립니다. 아직 본 논문에 대해 완벽한 이해가 이루어지지 못한 것이 아쉬우나, 현재의 제 이해력에서는 시간을 들인 것에 대해 아쉬운 것도 같습니다. 추후에 다른 연구원분께서 혹여 논문 리뷰를 해주신다면, 감사하겠습니다.
노력추 드립니다 bb
노력추 드립니다 bbb