요약:
검출기(detector)의 확신도(confidence)에 기반한 다양한 능동 학습(Active Learning)이 많다. 이들 방법론은 한가지 문제점을 내포하고 있는데, 예측이 잘 작동하는 이른바 high-performing classes를 위해 설계된 것이 일반적이며 데이터셋에 대한 좋은 표현력(representation)을 보장할 수 없는 상황에서는 능동 학습 기법의 효과를 볼 수 없다는 점이다.
본 논문에서, 그들은 능동학습을 위해 검출기를 통해 데이터의 uncertainty와 robustenss를 고려하는 통합된 프레임워크(unified framework)를 제시해 학습이 잘 되지 않은 카테고리에 대해서도 정상 작동을 보장할 수 있는 능동학습 기법을 소개한다. 이 방법론을 통해 얻을 수 있는 추가적인 이점은 자동 레이블링(auto-labeling)을 통해 발생할 수 있는 데이터의 분포변화(distribution drift)를 막을 수 있다는 것이다.
실험을 통한 검증은 PASCAL VOC07+12와 MS-COCO를 통해 진행되었으며, 기존 SOTA 대비 7.7%의 향상을 보여 82% 의 mAP에 도달했다. 저자들은 TUM, NVIDIA, CALTECH 소속이다.
방법론:
“데이터의 uncertainty와 robustenss를 고려하는 통합된 능동 학습 프레임워크“
방법론 한 줄 소개
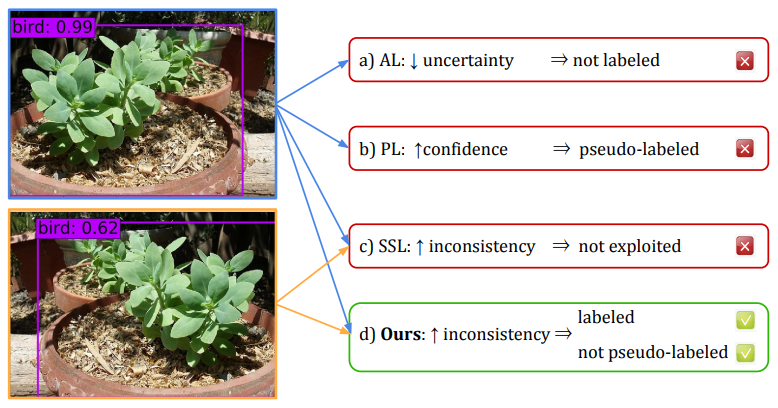
Uncertainty: 본 논문에서 uncertainty란 일반적인 능동 학습에서 사용되는 의미와 동일하다. 이는 인공지능 모델이 해당 데이터에 대한 이해도를 의미하며, 일반적으로 “이해도가 낮은”, “어려운”, “확신도(certainty)가 낮은”, “불확실성(uncertainty)이 높은”, “학습이 잘 되지 않은”, “추가적 학습을 필요로 하는”이 동치관계라 볼 수 있다. 또한 일반적인 능동학습 방법론은 “불확실성이 높은 데이터”를 “고가치 데이터”로 하여 쿼리(사람 작업자에게 오라클 라벨을 요청하는 행위) 하고, 다음 주기의 학습 데이터 풀(Pool)에 추가한다.
Robustness: 본 논문은 robustness라는 특징을 능동학습에 처음 도입하였는데, 이는 self-learning에서 consistent regulation을 위해 많이 사용되는 개념이다. 아마 이전 X-review의 FixMatch 논문이 있다면 확인할 수 있는 내용인데, “학습하는 인공지능 모델이 데이터 A에 대해 예측의 일관성을 유지 할 수 있는가”를 의미한다. 예를 들어 인공지능 모델이 검은색 가방이 촬영된 이미지 A에 대해 가방으로 잘 예측했다고 하자. 해당 모델에 색변환을 통해 빨간색 가방으로 이미지 변환된 A’을 입력했을때 여전히 가방으로 예측(90% 확률로 가방)한다면 robustness가 높은 모델이며, 앵무새(90% 확률로 앵무새)로 잘못 예측한다면 robustness가 낮은 모델이다. 예측이 틀릴 경우에도 모델의 확신도(certainty)는 높을 수 있다. 따라서 Uncertainty와 Robustness는 서로 상호보완적 관계를 갖는 지표로 볼 수 있다.
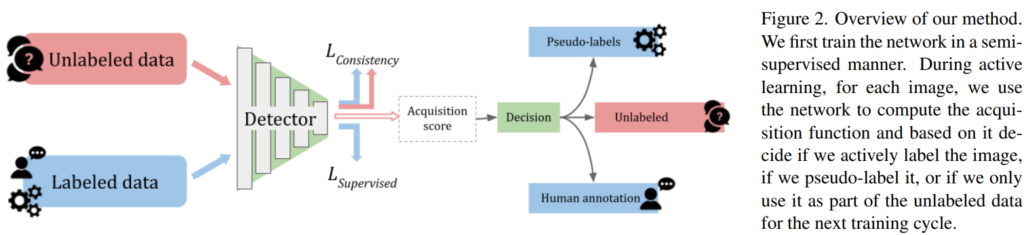
Frameworks: 위 Figure2는 본 논문의 방법론이다. 검출기(Detector) 학습에 Unlabeled data를 이용하기 위해 unlabeled data를 통해 학습하는 consistency loss와 지도학습을 위한 multibox loss, localization task를 위한 L1 loss로 구성된다.
multibox loss 는 아래 수식과 같으며 y^p는 해당 데이터에 대한 학습 여부를 의미한다. unlabeled data 중 pseudo label의 예측 확신도가 threshold 이하인 경우 y^p 값을 0으로 하여 학습에 사용하지 않는다. c는 데이터에 대한 모델의 클래스 예측 분포이다. Pos는 positive bounding box로 물체를 포함한 bounding box를 의미한다. Pos에 대해 label이 존재하는 데이터는(labeled, pseudo labeled) 아래의 방식으로 학습하며 label이 없는 데이터의 경우 예측의 robustenss를 이용해 학습한다.
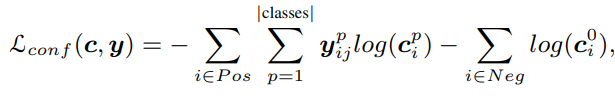
다음으로 consistency loss는 다음과 같이 카테고리와 bounding box의 위치에 대한 예측의 robustenss를 이용하도록 설계하는데, augmented된 데이터에 대한 예측 일관성을 이용한다.
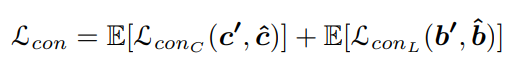
L1 loss는 검출기 모델의 일반적인 지도학습 방법을 이용한다.
위 방법론을 통해 robustenss가 높은 데이터는 pseudo labeling을 통한 지도학습에 사용되고 unlabeled data 또한 consistecy loss를 통해 unsupervised learning 방식으로 사용된다. 또한 카테고리에 대한 예측 consistency가 높고 (높은 robusteness) 동시에 uncertainty가 높은 데이터를 계산하여 수식을 통해 정렬한다(acquisition score). 이때 acquistion score가 높은 순으로 미리 설정한 labeling cost만큼 선별한다.
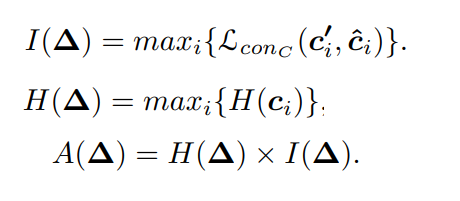
실험:
실험은 VOC07+12 데이터와 MS-COCO 데이터로 진행되었으며, 검출기로는 SSD 모델을 사용해 mAP 성능을 리포팅 하였다. uncertainty만 이용하거나 pseudo labeling만을 이용한 방법론에 비해 높은 학습 효율을 보임을 알 수 있다
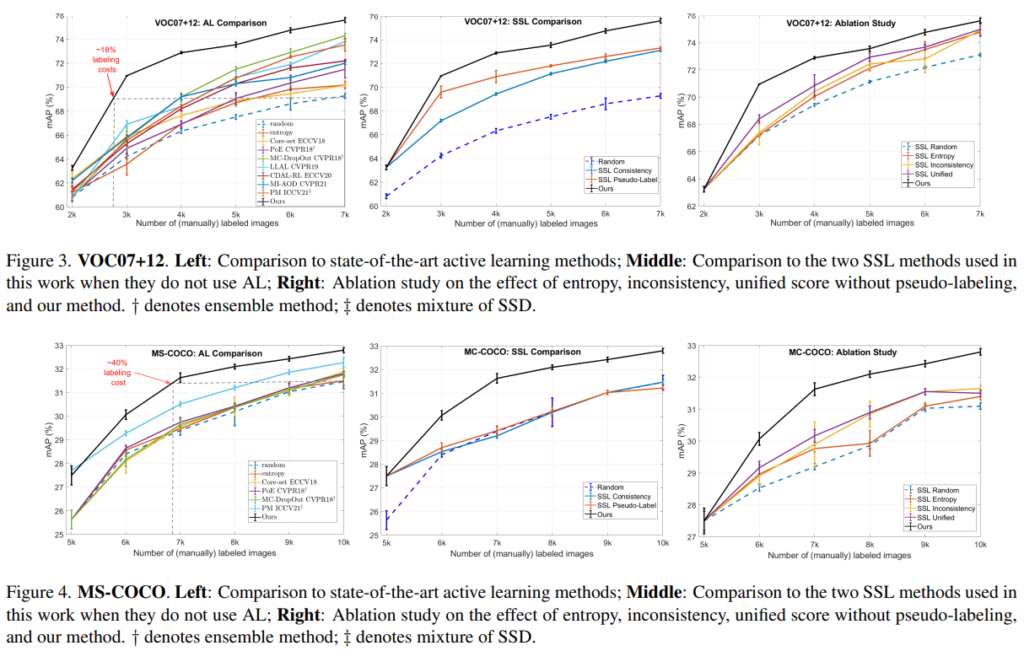
또한 단순 Active Learning 방법론보다 효과적으로 object detection task에 잘 접목할 수 있음을 아래 비교실험을 통해 확인하였다
안녕하세요 ! 좋은 리뷰 감사합니다.
방법론에서 설명해주신 acquistion score라는 것은 해당 score가 높은 순으로 데이터를 선별하여 어떤 방식으로 학습할지를 결정하기 위함인 것일까요 ? 그렇다면 언급된 unlabeld data 중 pseudo label의 예측 확신도가 threshold 이하인 경우에 학습에 사용하지 않는 것은 이미 acquistion score로 데이터를 선별하고 이후에 한번 더 threshold로 사용할 데이터를 선별해주는 과정을 거치는 것인지 궁금합니다.
acquistion score는 Active Learning에서 고가치 데이터를 선별하기 위한 “선별함수”를 위해 정의됩니다.
acquistion score가 높은 데이터 부터 예산에 맞게 labeling을 요청하기 위한 데이터로 선별 합니다.
acquistion score와 pseudo labeling가 사용되는 프로세스는 서로 다른데요
전체 학습이 아래와 같은 단계로 이루어진다고 합시다.
1. 모델 학습
2. 데이터 가치 판단을 통한 고가치 데이터 선별 및 Labeled pool 구축
3. 모델 학습 (1의 반복)
이때, acquistion score는 2 에서, pseudo labeling는 1, 3과 같은 단계에서 사용됩니다.
안녕하세요. 좋은 리뷰 감사합니다.
Robustness 설명해주신 부분에서 예측이 틀린 경우에도 모델의 centainty는 높을 수 있다고 하였는데, 그 이유가 무엇인가요 ? 이 경우에는 모델이 학습한 데이터와 유사하지 않은 데이터에 대해 예측하는 경우인 건가요 ? . . . …
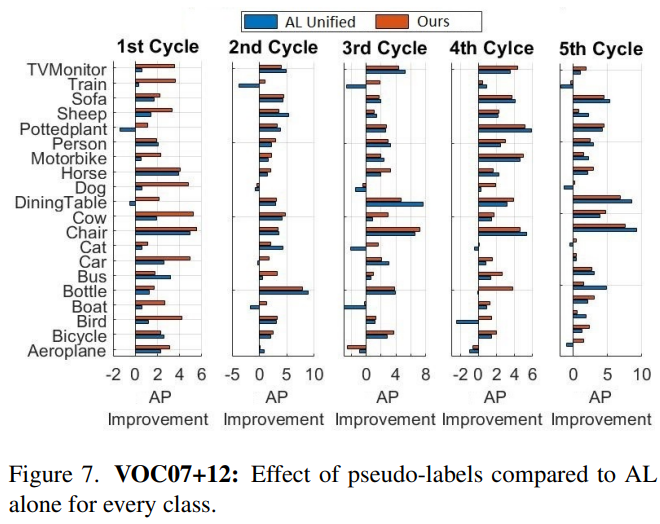
또 단순 Active learning 방법론과 비교실험을 한 부분에서 Cycle은 실험을 진행한 횟수인가요 ? 만약 그렇다면, 5번째 cycle이 더 성능이 좋아야 할 것 같은데 그렇지 않아보여 의문이 듭니다. . 마지막으로, AP가 음수로 나오는 경우는 어떤 경우인가요 ?
Robustness는 모델 예측이 데이터 변환에도 일정할 수 있는지에 관한 지표이고
Centainty는 모델이 자신의 예측에 확신이 있는지에 관한 지표로
두 지표는 서로 다릅니다.
예를들어 Image Classification 문제에서 강아지 이미지 X와 augmented 된 이미지 X’에 대한 예측을 진행한다고 합시다.
X에 대해 강아지일 확률이 90%, X’에 대해서도 강아지일 확률이 91%라면 해당 모델은 데이터에 대한 robustness가 높은 모델입니다.
그러나 X에 대해 강아지일 확률이 90%, X’에 대해서도 강아지일 확률이 21%로 크게 하락한다면 해당 데이터에 대한 모델의 robustness는 낮습니다.
반면 X에 대해 강아지일 확률이 90%, 고양이일 확률이 10%라면 해당 데이터에 대한 모델의 확신도(Centainty)는 높은것입니다. 그러나 강아지일 확률이 55%, 고양이일 확률이 45%라면 해당 데이터에 대한 모델의 예측 확신도(Centainty)는 낮은 것 입니다.
다음으로 Active Learning은 보통 n 회 반복 실험을 하며 5번째 cycle은 5번 누적된 성능입니다. 전반적인 카테고리에서 robustness를 보완한 지표로 selection 했을 때 성능 향상이 있는 것으로 보아 해당 지표가 robustness와 상호보완적 요소를 지닌 지표임을 알 수 있습니다.
안녕하세요 황유진 연구원님 좋은 리뷰 감사합니다.
설명해주신 것에 의하면 robustness는 결국 consistency 를 의미하는 것 같습니다. 따라서 Active Learning 에 consistency loss를 접목한 것은 self-supervised learning 모델을 결합한 것이 아닌 방법론에서는 처음인 듯 한데, 굉장히 신박하네요!
1. 그런데 궁금한 건 왜 이 기법을 Object Detection에 적용한 것인지에 대한 의문입니다. 말씀하신 것처럼 이 방법론은 Semi-supervised learning 에서 많이 사용하는 기법으로 Object Detection 보다는 가장 간단한 Classification에 대한 적용이 익숙한데요, Object Detection에서의 어떤 문제가 있었기에 이 방법이 도입이 된 것인지 궁금합니다.
2. 추가로 AL을 Object Detection으로 확장했을 때의 발생하는 문제점이 따로 있을까요?
맞습니다. robustness 지표를 측정하기 위해 consistency를 이용한 것이지요.
1. Object Detection의 labeling cost는 물체의 카테고리 뿐 만 아니라 위치까지도 고려해야하기 때문에 labeling cost가 더 높은 편입니다. 따라서 object detection을 위한 active learning연구를 진행했다고 논문은 소개합니다
2. Image classification을 위한 AL 방법론을 Object Detection으로 확장했을때 문제점은 하나의 이미지에서 고려해야할 요소(인스턴스)가 여러개라는 점이지요. 이를 해결하기 위해 본 논문은 하나의 이미지에서 예측된 물체를 통해 계산된 스코어 중 가장 높은 스코어를 그 이미지의 대표 스코어로 지정했습니다.
안녕하세요. 좋은 리뷰 감사드립니다.
불변성이 높으면 psudo labeling, consistency와 불확실성이 둘다 높은 데이터를 선별해서 labeling을 진행한다고 이해하였습니다. 리뷰를 읽고 한 가지 의문이 있는데요, 먼저 ‘데이터셋에 대한 좋은 표현력을 보장할 수 없는 상황’은 어떤 것인지 잘 모르겠습니다.
데이터셋에 대한 좋은 표현력을 보장할 수 없는 상황이란, 학습이 충분히 진행되지 않아 분류기의 성능이 낮고, 데이터에 대한 표현력이 좋지 않은 상태입니다.
이런 상황에서는 모델이 생성한 pseudo label에 대한 신뢰도는 떨어지며, 따라서 Self-training 학습을 진행하기 어렵습니다.