오랜만에 x-review를 쓰는 것 같네요. 벌써 CVPR 2023 accepted list 가 공개되었더군요. (다만 CVPR에는 Active Learning 과 관련된 연구가 많이 붙지는 않아 안타까웠습니다…) 그렇다고 Active Learning 연구가 아예 없는 것은 아니었습니다. Active Learning 이 한 방울 묻어있는 연구가 하나 있었습니다. 이는 제가 기존에 리뷰하던 Self-supervised learning 과 Active learning 을 결합한 방식에 대한 논문입니다. 바로 리뷰 시작해보도록 하겠습니다.
Active Finetuning: Exploiting Annotation Budget in the Pretraining-Finetuning Paradigm

- Paper: CVPR 2023 [ Arxiv PDF ]
- Author Video: None
- Code: GitHub #### Coming soon (아직 공개하지 않음)
Introduction
이번에 공개된 CVPR 리스트를 봐도, self-supervised learning 에 대한 관심이 얼마나 뜨거운 지 알 수 있을 겁니다. 이 부분에 대해서는 많은 분들이 공감하시지 않을까 싶습니다. 그런데 self-supervised learning를 사용하기 위해서는 downstream task 에 대해 일부 데이터셋을 사용하여 지도학습 방식으로 다시 fine-tuning 해야합니다. 저자가 주목한 점이 바로 이겁니다. 아무리 라벨을 사용하지 않고 학습하는 self-supervised learning 이 성공적이라고 할지라도, 결국 donwstream task를 위해서 지도학습 방식으로 재학습을 필요로 한다는 점입니다.
그리고 여기에는 Active Learning 관점에서 또 하나의 가정이 기저에 깔려있습니다. 바로 ‘어떤 데이터셋이 유용한지 그리고 라벨이 있어야 하는지에 대해 안다’ 라는 가정이죠. Fine-tuning 할 때 일부 데이터셋 (가령 전체 데이터셋의 10%)을 사용하는데, 우리는 당연하게 해당 데이터셋의 라벨을 가지고 있다고 생각합니다. 또한 이 때 사용하는 일부 데이터셋이 유용하다라는 가정까지 합니다. 결국 저자는 self-supervised learning을 Downstream task에서 더욱 효과적으로 사용하기 위해서는, Fine-tuning 시에 사용하는 데이터셋을 잘 골라야 한다는 결론을 내리게 됩니다. 그리고 이를 위해 Active Learning 기법을 도입하게 됩니다. 왜냐, Active Learning 이라는 연구가 바로 어떤 데이터셋이 모델에 유용한 지를 연구하는 분야이기 때문입니다.
Active Learning 에서는 batch-selection strategy라는 기법을 사용합니다. 이는 전형적인 AL에서 사용하는 학습법으로, [ 데이터 선택 – 라벨링 – 재학습 ] 을 하나의 주기로 여러번 반복하는 학습 기법을 저자는 batch-selection strategy 라고 하였습니다. 이 Active Learning 을 Self-supervised learning 과 단순하게 결합하는 방식은 이미 이전 연구에서도 선보인 바 있었습니다. 똑같은 10% 데이터셋을 사용하더라도, Active Learning은 여러번 반복하는 학습 과정을 통해 10% 데이터셋을 유용하게 선택하겠다는 것이었죠. 그러나 결과는 성공적이지 않았습니다. Fine-tuning에 사용하는 데이터셋의 크기가 굉장히 작을 경우, 데이터를 오히려 편향적으로 선택하여 성능이 충분하지 않다는 결론을 내렸기 때문이죠.
결국 저자는 Active Learning의 batch-selection strategy 방식이 아닌 유용한 데이터 선별 방법에 대해 집중하기로 결론을 내렸습니다. 즉, Self-supervised learning 학습 이후 Downstream으로 내릴 때 (fine-tuning 할 때) 사용하는 데이터를 선택하는 방법을 학습을 통해 알아내자 라는 것이죠. 아래 [그림 1]이 바로 저자가 제안하는 ActiveFT의 개요입니다. Finetuning하는 데이터를 Active Learning 기법을 살짝 묻혀서 선택하겠다는 것이죠!
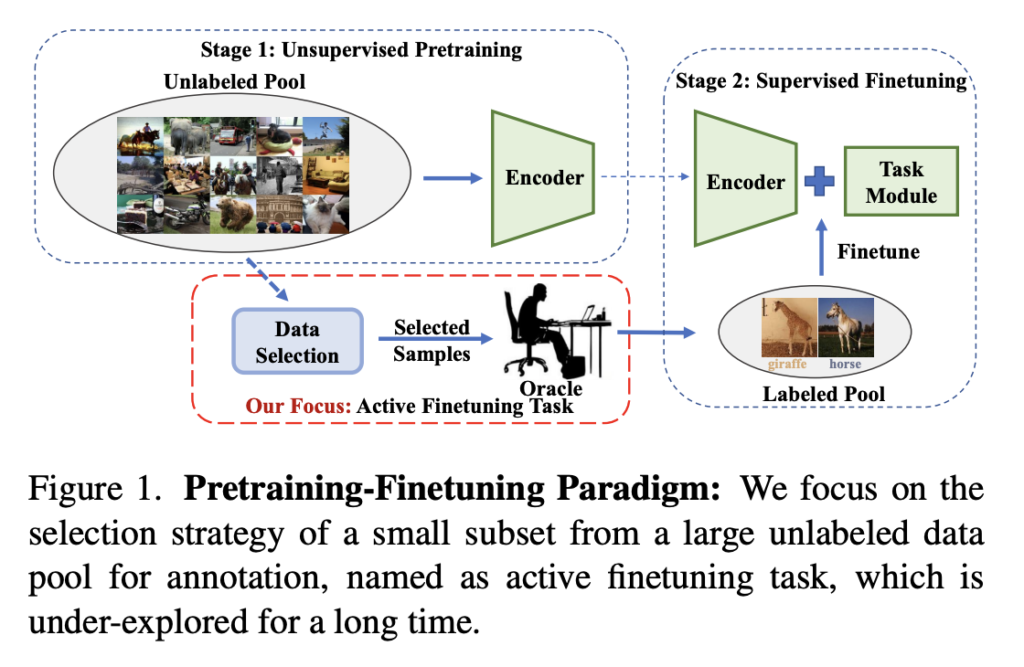
Method
1) Formulation of AL
Active Learning 은 유용한 데이터를 선별하기 위한 연구입니다. 이 때, 유용하다의 기준이 (1) Uncertainty (불확실성) 이 되기도 하고, (2) Diversity (다양성) 이 되곤 합니다. 전자의 경우 모델의 예측에 대한 신뢰도가 낮은 ‘불확실한’ 데이터를 선택하는데, 이렇게 불확실한 데이터는 대개 결정 경계 근처에 잇기 때문에 성능 향상에 탁월하다는 가정이 있습니다. (2) Diversity는 성능을 올리는 데에 데이터 전체를 커버할 수 있는 대표적인 데이터를 선택하는 것이 유용하다는 입장입니다.
양 쪽 진영이 엎치락 뒤치락 하며 성능 향상을 위해 연구가 되고 있지만, 이 연구들은 모두 데이터를 선별하는 Sampling Metric이 사전에 정의되어 있습니다. 이게 무슨 소리냐? 불확실하다의 대표적인 기준으로 Entropy 를 예시로 들면 이해가 쉬우실 것 같습니다. ‘Entropy 가 높은 것이 유용한 데이터이니 이 데이터를 선별하자’ 라고 Sampling Metric을 사전에 정의를 해둔다음, 대부분의 연구는 어떤 Feature를 생성해내는지 네트워크를 집중적으로 연구를 하곤 합니다. 아니면 Feature를 생성해둔 다음 Sampling Metric으로 어떤 수식을 사용하는 것이 효과적인지를 실험해보곤 합니다. 중요한 것은 Sampling Metric은 고정된 수식이라는 점입니다. Sampling Metirc을 새롭게 제안하는 연구는 항상 있었으나, 이것을 학습을 통해 알아내는 것이 아니었습니다. 각자 제안하는 Feature를 가장 잘 표현해낼 수 있는 Sampling Metric을 정의하였죠.
그런데 저자는 기존에 시도하지 않은 Sampling Metric S를 구하는 방식을 제안하였습니다. Self-supervised learning 이후 Downstream 에서 튜닝하는 데 사용할 수 있는 데이터셋을 구하는 것이 목적이기 때문입니다. 아래 수식이 바로 Sampling Metric S를 의미하며, B는 Budget으로 선택할 데이터 개수를 의미합니다.
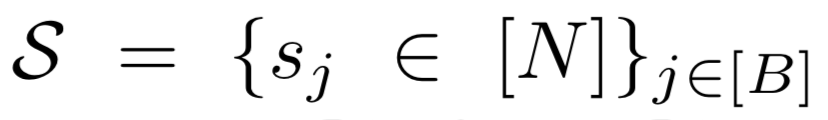
데이터를 선택하는 데에는 Supervised learnign으로 학습된 모델 f를 사용합니다. 기존의 Unlabeled pool 전체 데이터셋을 학습하는 Self-supervised learning 모델 f는 전체 데이터셋의 분포를 잘 표현해낼 수 있기 때문이죠. 따라서 이 모델을 사용해서 S_{opt}을 구하고자 하엿습니다. 이 S_{opt}는 하단[수식 1]과 같이 모델의 오차 error(f(x;w_S),y)를 최소화하는 것으로 정의됩니다.
2) Data Selection with Parametric Model
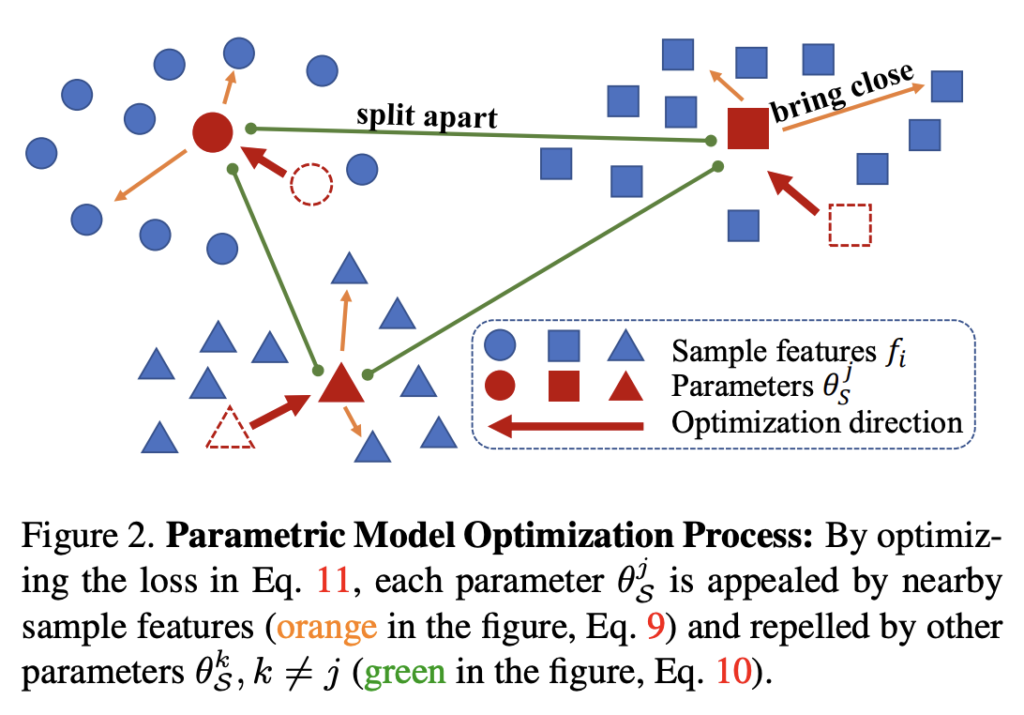
우선 저자가 생각하는 데이터 선택의 기준은 다음 2가지의 직관이 반영되어 있습니다: 1) 선택된 데이터셋 P^u_S의 분포는 전체 데이터셋 P_S의 분포와 비슷해야 한다. 2) 이 때, 선택된 데이터셋 P^u_S는 다양성을 유지해야 한다.
전자의 경우 선택된 데이터로 튜닝될 경우, 전체 데이터셋에서 학습된 모델과 유사한 성능을 발휘할 수 있도록 보장하고, 후자는 전체 데이터셋의 코너 케이스를 커버할 수 있기 때문입니다. 이것이 반영된게 상단 [그림 2] 입니다. 이런 기준으로 데이터를 선택하는 것이 효과적이다는 게 저자의 주장이죠.
앞서 학습이 완료된 self-supervised 모델 f를 사용한다고 하였는데, 저자는 데이터 스페이스가 아닌 데이터를 이 모델에 넣어서 발생한 feature로 데이터를 선별하고자 하였습니다. 따라서 저자의 직관이 반영된 샘플링 방식은 다음 [수식 2]와 같이 정의될 수 있습니다.
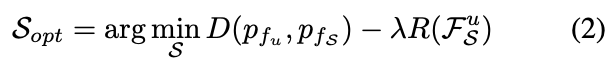
D는 분포 사이의 거리를 나타내는 메트릭이고, R은 데이터셋의 다양성을 측정하며 \gamma는 이 두 항의 균형을 맞추는 가중치입니다. 첫번째 항인 D(p_{f_u}, p_{f_S})가 저자의 직관 1)에 해당하고, R(F^u_S) 가 직관 2)에 해당합니다.
그런데 그동안의 딥러닝 메트릭은 연속적인 공간에서 정의되어 있습니다. 그래야 미분을 통해 최적화를 할 수 있기 때문이죠. 그런데 S는 이산공간에서 정의되어 있습니다. (S는 유한 개의 데이터 중에서 유의미한 데이터 일부를 선택하는 수식이기 때문인 것 같은데..) 이런 이산 sampling method를 직접적으로 최적화하는 것은 미분이 불가능하다는 점에서 어렵기 때문에 저자는 수식을 다음과 같이 변경하였습니다. \theta_S는 연속 파라미터이고, B는 Budget 인 p_{\theta_S}로 p_{f_S}를 모델링하는 것이죠. 따라서 S를 결정하기 위해서는 최적화 이후 각 \theta^j_S에 가장 가까운 f^j_S를 찾는 문제로 변경될 수 있다고 합니다.
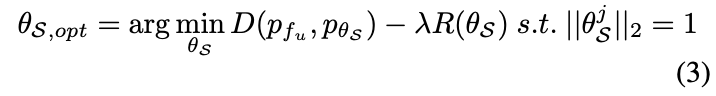
추출된 샘플 feature F^u_S와 정의한 파라미터 \theta_S의 차이점은 전자의 경우 데이터셋의 각 샘플에 해당하는 불연속적인 feature인 반면, 후자는 특징 공간에서 연속적이다 라는 점입니다.
요약하면, 이산 공간에서 존재하는 S를 최적화 하고자 continuous한 파라미터로 근사 혹은 설계하여, 최적화를 할 수 있도록 새롭게 설계하였다 정도로 볼 수 있을 것 같습니다.
3) Parametric Model Optimization
여기서부터는 수식적으로 저자가 정의한 연속 공간에서의 파라미터를 업데이트할 수 있는 Loss function에 대해 설명합니다.
앞서 설계한 파라메트릭 모델 p_{\theta_S}에서 분포느 B개의 파라미터로 표현됩니다. (B개의 데이터를 선택해야하기 때문이죠)
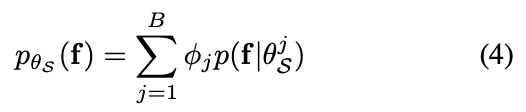
f와 θ^j_S는 모두 피처 공간에 놓여 있으므로, 각 구성 요소는 다음 [수식 5]와 같이 유사성에 따라 정의할 수 있습니다.
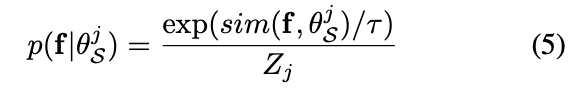
해당 수식은 다음과 같이 경험적으로 근사화하여 다음과 같이 정의할 수 있습니다. (이 과정에 대해서는 추후 그림을 통해 다시 한번 업데이트 하겠습니다;; 너무 어렵네요..ㅎ….)
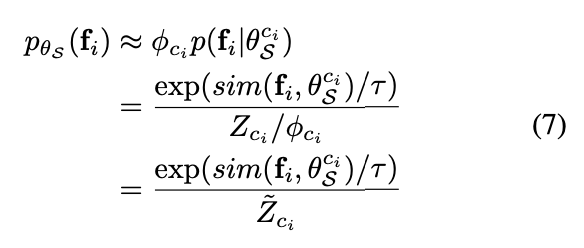
이제 두 분포 pfu , pθS는 KL-분산을 최소화 하는 과정을 통해 가까워지도록 업데이트를 할 수 있습니다. 이 과정이 다음 [수식 8] 과 같이 정의합니다.
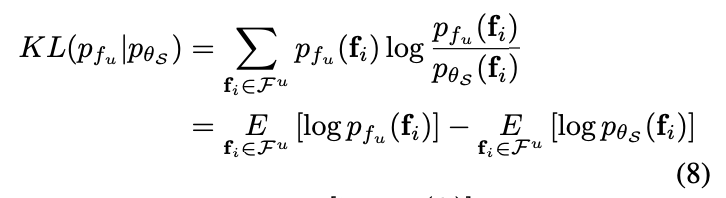
여기서 첫번째 항은 매개변수 \theta_S가 없는 상수입니다. 그러면 KL-분산을 최소화하는 것은 두번째항을 최대화하는 것과 같기 때문에 최종적으로 식 3의 첫번째 D 에 대한 항은 다음과 같이 도출 될 수 있습니다.
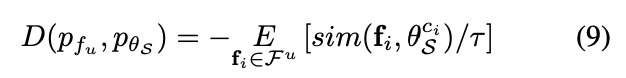
그런데 이 D만 정의된 채로 최적화를 수행하면, 데이터 내부의 다양성을 잃을 수 있습니다. 이는 저자가 생각하는 샘플링 조건 (2)에 해당하는 것이죠. 즉, 선택셋의 다양성을 보장하기 위해 추가 정규화 함수를 도입하였습니다. 이 정규화는 선택셋 사이의 유사성을 최소화하는 방식으로 구현되었다고 합니다. (코너 케이스까지 커버할 수 있는 연산을 정규화라고 표현했다고 볼 수 있겠지요)
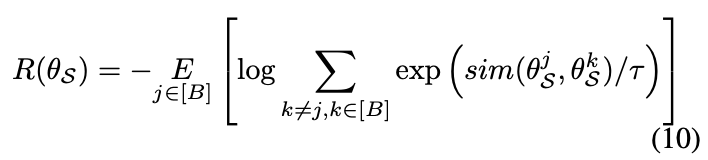
자 이제 멀고 멀었던 Loss function을 최종적으로 정의할 수 있게 되었습니다. 아래 [수식 11]이 바로 최적의 S를 구할 수 있는 Loss fucntion입니다. 이를 바탕으로 경사 하강을 통해 직접적으로 최적화 할 수 있는 모델을 설계하였습니다.
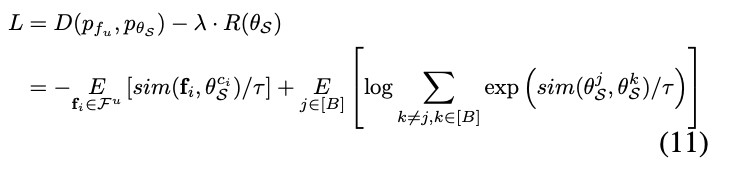
이제 최적화가 완료되면 \theta^j_S와 가장 유사도가 높은 feature f_{s_j}를 찾는 것으로 문제가 최종적으로 정의되었습니다. [수식 12]
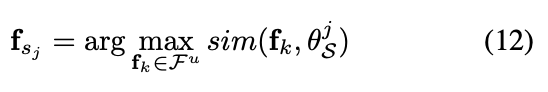
최종적으로 데이터 샘플 [x_{s_j}]_{j∈[B]}는 샘플링 메트릭 S = [s_j]_{j∈[B]}를 사용하여 선택됩니다.
결론적으로 저자가 제안하는 ActiveFT를 요약한 수도코드는 다음과 같이 정리할 수 있습니다.

Experiment
Image Classification
데이터셋으로는 CIFAR10, CIFAR100, ImageNet-1k을 사용하였으며, 평가 메트릭으로는 Top-1 Accuracy를 사용합니다.
비교를 위해 사용한 방법론은 총 8가지 입니다. Random 은 임의로 데이터를 선별하는 방식이며, FDS는 대표적인 Greedy K-Center 알고리즘이고, K-means 까지 고전적인 세가지 방법론을 사용하였습니다. 그리고 Coreset, VAAL, LearnLoss, TA-VAAL, ALFA-Mix까지 최신 방법론 5가지를 비교 실험을 위해 사용하였습니다.
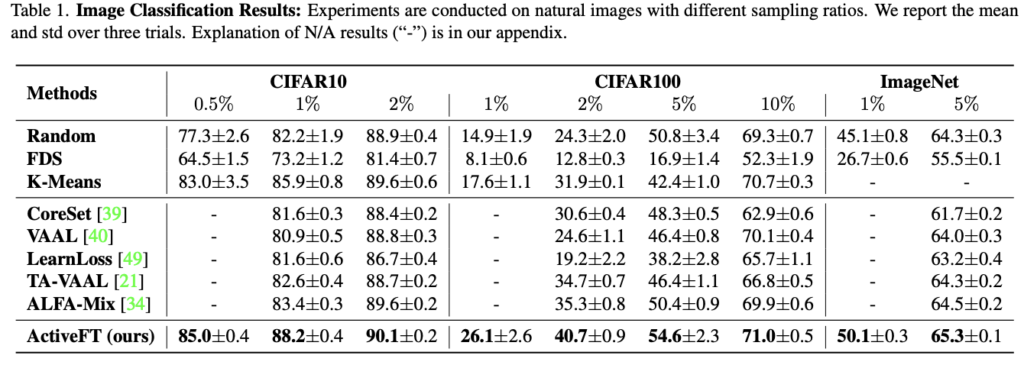
상단 테이블이 바로 비교실험을 수행한 결과입니다. ActiveFT는 샘플링 비율이 다른 세 가지 데이터 세트 모두에서 다른 방법보다 우수한 성능을 보였습니다. 특히 각 데이터 세트에서 샘플링 비율이 낮을 때 성능 향상이 두드러지는데, 이를 통해 저자의 방법이 가장 대표적인 샘플을 선택할 수 있기 때문이라고 주장하였습니다. 또한 Fine-tuning을 위해 선택한 샘플 수는 일반적으로 라벨링 코스트를 절약할 수 잇을 만큼 전체 풀의 크기보다 훨씬 작다는 점도 주목할 만한 결과인 것 같습니다.
Semantic Segmentation
데이터셋으로는 ADE20k 을 사용하였으며, 평가 메트릭으로는 mIoU을 사용하였습니다.
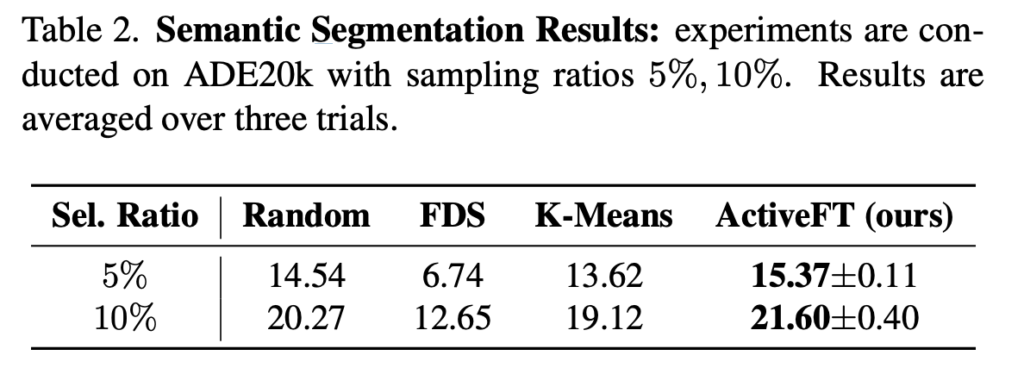
상단 [테이블 2]가 바로 Fine-tuning을 위한 5%, 10%의 데이터를 선택했을 때 ActiveFT 와 고전적인 메트릭 3가지와 비교 실험한 결과입니다. (기존 AL 방법들은 이미지 분류에도 탁월한 성능을 보이지 않앗기 때문에 세그멘테이션으로 확장하진 않았다고 합니다.)
데이터 선택 방법의 성능 향상은 Classification 만큼 크지 않습니다. 저자는 이에 대해 Segmentation이 아주 미묘한 로컬 패턴에 초점을 맞춰야하는 작업이기 때문에 그럴 수 있다고 하네요. 게다가 이 경우 글로벌 피처가 장면의 모든 디테일을 표현하기는 어렵습니다. 그러나 이러한 어려움에도 불구하고 다른 방법론과 비교했을 때 여전히 눈에 띄는 성능을 보여주며, 이는 태스크 확장에 있어 저자의 ActiveFT에 대한 범용성을 확인할 수 있다고 합니다.
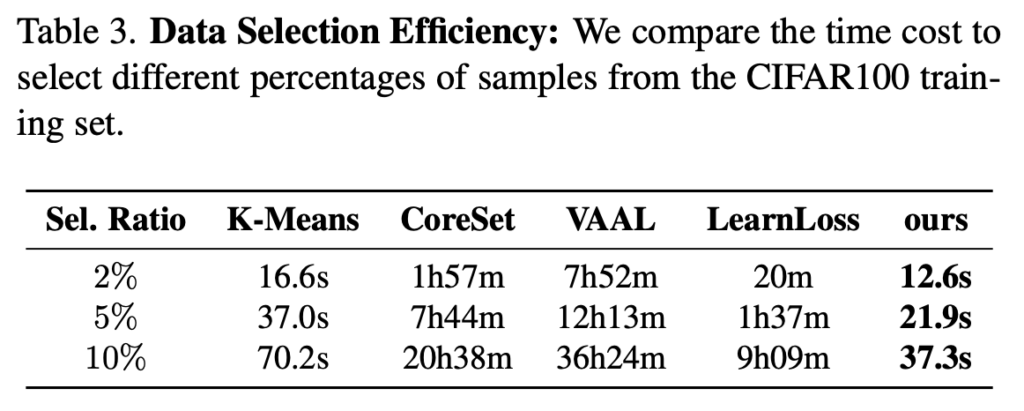
Data Selection Efficiency
저자는 특히 시간적 효율성에도 집중하였는데요, 이에 대해 ‘Data Selection Metric은 가능한 한 랜덤 선택에 가깝도록 시간 효율적인 방식으로 진행되어야 한다’ 라고 주장하였습니다. 특히 [Table 3]에서는 CIFAR100를 다양한 비율의 샘플을 선택하는 데 필요한 시간을 비교하였습니다. (여기서 FDS는 성능 좋지 않아서 비교 대상에서는 제거하였다고 합니다.)
기존의 AL의 경우, Introduction에서 언급한 반복적인 모델 학습과 데이터 샘플링을 모두 실행 시간에 포함해야하는 데다, 모델을 재학습 과정이 시간을 많이 차지합니다. 반면, ActiveFT는 모든 샘플을 한 번에 선택하기 때문에 선택 과정에서 모델을 다시 훈련할 필요가 없습니다. 따라서 기존의 AL 방식보다 속도가 월등히 빠르다는 장점이 있다고 합니다.
Visualization of Selected Samples
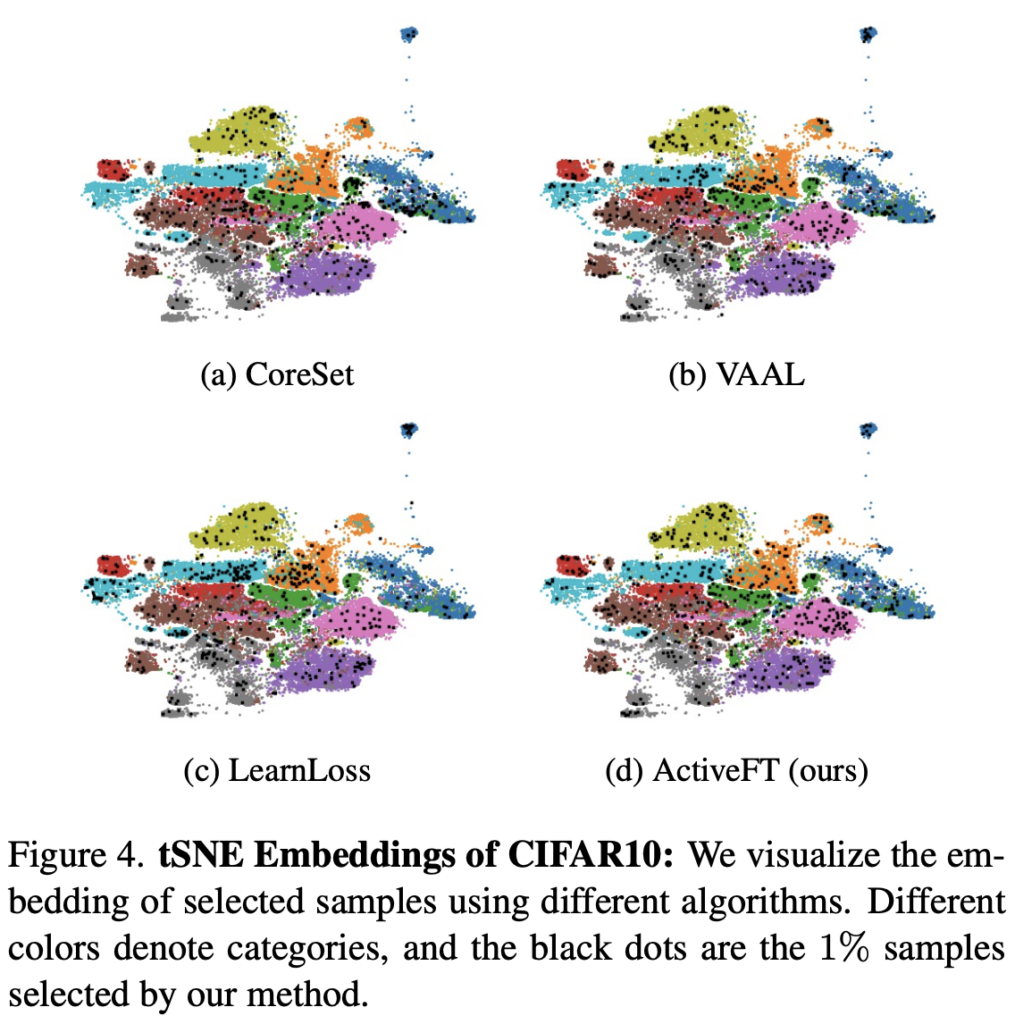
다음으로 CIFAR-10에 대한 피처 시각화 결과를 상단 [그림 4]에서 확인할 수 있습니다. 검은색 점이 바로 각각 다른 방법으로 선택된 1% 샘플인데요. 그 결과는 ActiveFT에서 선택한 샘플이 다른 샘플보다 피처 스페이스에서 전체 풀과 더 유사하게 분포한다는 것을 정성적으로 확인할 수 있었습니다. 이를 통해 저자가 제안하는 최적화 기법이 전체 풀을 반영하는 데에 효과적일 수 있었다 라고 합니다.
지금까지 CVPR 2023에 게재된 ActiveFT라는 방법론에 대해 알아보았습니다. Sampling Metric을 학습해서 알아내자 라는 방법론을 제안한 건 제가 알기론 처음이었습니다. 점차 Active Learning 에 대해 방법론에 대한 고도화 보다는, 기존에 집중하지 않은 문제를 알아내고 해결하려는 시도가 계속 등장하는 것 같습니다.
안녕하세요, 홍주영 연구원님, 좋은 리뷰 감사합니다. 오랜만에 보는 AL 관련 리뷰라 읽어보려고 했는데.. 솔직히 이해하기 쉽지 않았습니다. 특히 중간 수식 부분은 아예 이해를 못했습니다. 그래도 제가 나름 이해한 내용에 대해 정리해보자면 다음과 같습니다.
1. 라벨을 사용하지 않고 학습하는 self-supervised learning을 사용하기 위해서는 downstream task에 대해 일부 데이터셋을 사용하여 ‘지도학습 방식으로 다시 fine-tuning’을 해야 합니다(재학습 필요)
2. self-supervised learning을 downstream task에서 더욱 효과적으로 사용하기 위해서는 ‘fine-tuning’시에 사용하는 데이터셋을 잘 선택해야 합니다. -> 어떤 데이터셋이 모델에 유용할지 연구하는 active learning 기법 도입
3. Active learning에서는 [데이터 선택 – 라벨링 – 재학습]을 하나의 주기로 여러번 학습하는 batch-selection strategy 라는 기법을 사용합니다. Active learning을 self-supervised learning과 단순 결합하는 방식은 이전 연구에서도 선보인 바 있지만, 결과는 성공적이지 않았습니다. fine-tuning에 사용하는 데이터셋의 크기가 굉장히 작을 경우, 데이터를 오히려 편향적으로 선택해 성능이 충분하지 않았기 때문입니다.
4. 이에 저자는 active learning의 batch-selection strategy 방식이 아닌 유용한 데이터 선별 방법에 집중합니다. -> Self-supervised learning 학습 이후 Downstream으로 내릴 때 (fine-tuning 할 때) ‘사용하는 데이터를 선택하는 방법을 학습을 통해 알아내자’
5. AL에서 유용한 데이터를 선별하기 위해 연구가 진행되는데, uncertainty와 diversity를 기준으로 유용성을 판단하는 방법은 데이터를 선별하는 sampling metric이 사전에 정의되어 있습니다. 저자는 기존에 시도하지 않는, Sampling Metric S를 구하는 방식을 제안하였습니다.(self-supervised learning 이후 downstream에서 튜닝하는 데 사용할 수 있는 데이터셋을 구하는 것이 목적이기 때문)
6. 실험 결과 해당 방법론이 수많은 dataset에서 sampling 비율이 다른 방법보다 우수했습니다.
이해가 쉽지 않아서 질문이 몇 있습니다. 대부분 기본 용어에 관한 질문입니다.
1. 초반에 나오는 ‘’downstream’과 이 때 수행하는 ‘fine tuning’이 무엇인지 잘 모르겠습니다. self-supervised learning을 수행할 때 필수적으로 들어가는 과정인것 같긴 한데.. 설명해주시면 감사하겠습니다.
2. 중간 실험 부분에서 semantic segmentation 부분이 나오는데, 여기서 semantic segmentation이 무엇을 뜻하는건지 궁금합니다. 이미지 데이터를 선택하는 Task이기 때문에 vision에서 다루는 semantic segmentation과 완전히 동일한 의미로 사용된건지, 만약 그렇다면 어떤 segmentation의 어떤 점을 개선한건지 궁금합니다
3. 데이터를 선별하는 sampling metric이 구제적으로 무엇인지 궁금합니다. 리뷰를 읽어보면 미리 정의되어 있기도 하고 (제안된 방법론에서는)데이터에 따라 바뀌기도 하는 것 같은데, 데이터를 선별하는 수식이라는 것 이외에는 이해가 쉽지 않습니다.
4. ‘데이터셋의 코너 케이스’ 라고 코너 케이스가 언급되는데, 데이터 선별에서 코너 케이스로는 어떤 것이 있을 수 있는지 궁금합니다.
제가 배경지식이 부족해 질문이 좀 많습니다.. 답변 남겨주시면 감사하겠습니다
1. Self-supervised learning 은 라벨이 없이 학습을 수행합니다. 이를 위해, 라벨을 자체적으로 만들어낸다고 하여 Self 라는 이름이 붙혀진 것인데요. 예를 들어, 최근 가장 핫한 MAE는 스스로 이미지에 구멍을 뚫고 그 구멍을 다시 원래 이미지로 복원하는 방식으로 학습을 수행합니다. 자체적으로 구멍을 뚫었기 때문에, 모델은 원본 이미지에 접근할 수 있어 지도학습 방식으로 학습할 수 잇습니다. 또 다른 예시로 제가 매번 예시로 드는 회전각 맞추기 문제도 있죠. 학습 과정에서 원본 이미지를 90/180/270/360 단위로 회전시킨 다음그 회전 각을 맞추는 문제 역시 모델은 각 회전 각도를 알 수 있겠죠. 그러므로 지도학습 방식으로 학습할 수도 있습니다. 이 방식으로 우선 모델을 학습합니다.
그런데 이렇게 학습한 모델은 앞서 정의한 문제만 풀 수 잇는 모델이겠죠?! MAE 로 정의했다면 이 모델은 이미지를 복원하는 식으로밖에 문제를 풀 수 없습니다. 따라서 object detection 혹은 classification 등 다른 태스크를 수행하려면, 그 문제를 풀 수 있게 모델에 변형을 가하고 학습을 또 진행해야 합니다. 그런데 Self-supervised 기법으로 학습한 경우, 모델은 충분히 학습한 데이터의 표현력을 가지고 있기 때문에, 학습한 모델의 마지막 레이어만 해당 문제를 풀 수 있게 변형하는 식으로 모델을 변경합니다. 그럼 이제 object Detection 혹은 classification 등 다양한 문제를 풀 수 있도록 재학습을 시킵니다.
즉, Self-supervised leanring 은 보통 정의한 문제로 사전학습 한 다음, 원하는 태스크로 미세 조정을 시키는 2단계를 거칩니다. 여기서 Classification, Object Detection 등 원하는문제를 Downstream task 라고 하고 재학습및 미세조정을 Fine-tuning이라고 합니다.
2. Segmantation은 Classification, Object Detection, Depth Estimation 등과 같은 컴퓨터 비전 안에 존재하는 연구 분야 중 하나로, 모든 픽셀에 대해 Classification을 진행하는 Task로 이해하시면 될 것 같습니다. 누끼따는 것(?) 과 비슷하다고 보면 될 것 같은데요. 그 중 Semantic Segmentation은 구분한 Class 사이의 instance를 구분하지 않는데요. 가령 사람 2명 강아지 2마리가 있는 이미지가 있다고 가정해봅시다. Semantic Segmantation에서는 사람 클래스를 가지는 object가 2개, 강아지 클래스를 가지는 object가 2개 있다는 출력을 내겠지만, Instance Segmantation은 사람 1, 사람 2, 강아지 1, 강아지 2 라는 출력을 발생하게 됩니다. 즉, Semantic Segmentation은 Segmantation 분야의 일종으로 그 픽셀이 어떤 클래스에 속하는 지에 집중하는 태스크입니다. 보통 Active Learning 혹은 Self-supervised learning 과 같은 Classification 만 수행하는 연구는 Segmentation을 수행하는 실험을 추가로 보여줌으로써 확장 가능성을 어필하곤 합니다. Backbone 모델 처럼 말이죠.
3. 우선 예전에 재연님이 댓글 남겨주신 내용을 아래 링크를 첨부합니다.
http://server.rcv.sejong.ac.kr:8080/2021/11/15/iclr-2018-active-learning-for-convolutional-neural-networks-a-core-set-approach-part-1/#comments
해당 리뷰에서는 1~5까지 고전적인 Sampling Method 에 대해 다뤘습니다. 만일 Least Confidence (LC) 를 Sampling Method로 설정한다면 ‘모델이 예측한 각 클래스의 확률 중 Top 1 의 확률이 가장 낮은 데이터가 성능을 올리는데 유용한 데이터일 것이다’ 라는 가정이 기저에 깔리게 되겠죠. (Least Confidence 동작 원리는 링크 참고 부탁드립니다! 아마 테이블을 통해 보는게 이해가 잘 될 것 같습니다)
Active Learning 은 라벨이 없는 데이터 중에서 모델의 성능을 가장 향상시킬 수 잇는 데이터를 찾아내는 연구라고 할 수 있을 것 같은데요. 똑같은 개수의 100개의 데이터를 사용하더라도, 성능을 더 올릴 수 있는 데이터를 선택하는 것이 목적입니다. Active Learning 과정을 통해 데이터의 가치를 판단하는 모델은 모든 라벨이 없는 데이터에 대해 가치를 예측하게 되는데요. 그 가치는 보통 해석이 어려운 벡터로 구성이 됩니다. 따라서 이 벡터에 대해 특정한 수식을 통해 가치를 나열할 수 있습니다. 만일 데이터의 가치를 Entropy 로 반환하는 모델이라고 한다면, ‘Entropy 가 높은 것이 유용한 데이터다’ 라고 하는 것이 여기서는 Sampling Method가 됩니다.
4. 강아지 이미지에 대해 예시를 들어봅시다. 우리의 모델은 리트리버, 푸들 이미지를 골고루 커버해야하는데, 리트리버의 데이터가 워낙 많다보니 푸들이라는 데이터는 커버할 수 없게 되었습니다. 이렇게 데이터 개수가 적은 경우에도 코너 케이스가 될 수 있을 것 같습니다. 물론 코너 케이스의 상황은 무수히 많지만요! Outlier라는 키워드로 이해하시면 좋을 것 같습니다.
글 만으로는 이해가 어려울 수 있을 것 같은데요. 이해가 안되는게 있다면 언제든지 불려주세요 ㅎㅎ 이해될때까지 설명드리겠습니다 ㅎㅎ
친절한 답변 감사드립니다. 덕분에 의문의 많은 부분이 해소되었습니다. 홍주영 연구원님의 답변으로 제가 이해한 바에 따르면
self-supervised learning으로 학습했을 때, 원하는 task에 맞게 모델을 변형하기 위해서는 학습된 모델의 마지막 Layer만 바꾸면 되고, 일부 데이터셋으로 재학습해야합니다. 이 때 원하는 task를 Downstream task라고 하고, 재학습&미세 조정을 fine-tuning 이라고 합니다.
fine-tuning시에 사용하는 데이터셋을 잘 선별해야 하기 때문에, 여기에 active learning을 도입합니다.
sampling method는 고가치 데이터를 선별하는 수식이므로 무엇을 기준으로 고가치 데이터를 선별하느냐에 따라 sampling method는 달라질 수 있습니다.
하지만 아직도 의문인 부분이 남아 있습니다. segmantation task에 대해서는 픽셀별로 classification 하는 것으로 이해했는데, 위 도표에서 active learning으로 segmantation의 무엇을 측정해서 report한건지 아직 이해가 잘 되지 않습니다. 이는 조만간 제가 찾아가서 질문 드리겠습니다.
자세한 답변 정말 감사드립니다.
네 추가 답변을 드리자면 아래와 같습니다.
“원하는 task에 맞게 모델을 변형하기 위해서는 학습된 모델의 마지막 Layer만 바꾸면 되고”
-> 마지막 Layer 만 바꾸는건 한 가지 예시일 뿐 모든 Self-supervised Learning 에서 적용되는 것은 아닙니다! 아키텍처를 바꾸기도 하며 다양하게 적용되고 연구되고 있습니다. 특히 Downsteam task에 맞춰서 다양한 변형이 존재하죠!
“fine-tuning시에 사용하는 데이터셋을 잘 선별해야 하기 때문에, 여기에 active learning을 도입합니다”
-> 네, 맞습니다! 저자가 Active Learning 을 도입하게된 메인 아이디어가 바로 재연님이 말씀해주신 거라고 할 수 있습니다.
“sampling method는 고가치 데이터를 선별하는 수식이므로 무엇을 기준으로 고가치 데이터를 선별하느냐에 따라 sampling method는 달라질 수 있습니다.”
-> 네, 특히 기존에는 고정된 Sampling method 를 사용했다면, 본 논문의 저자는 최적화 과정을 통해 이 Sampling method를 알아내는 시도를 했다는 Contribution이 있다는 것이죠
“위 도표에서 active learning으로 segmantation의 무엇을 측정해서 report한건지 아직 이해가 잘 되지 않습니다.”
-> Segmentation에서는 mIoU라는 지표로 성능을 평가합니다. Classification에서 Accuracy를 사용해서 성능 평가 하는 것과 같죠.
해당 테이블에서는 저자가 제안하는 sampling method에 의해 선택된 데이터를 사용해서 Semantic Segmentation을 Downstream task로 fine-tuning 합니다. 즉, 기존에는 Classification으로 Fine-tuning했다면 모델의 확장 가능성을 파악하기 위해 Segmentation을 Downstream task로 Fine-tuning을 진행한 것이죠. 그리고 Segmentation 성능 평가를 위해 mIoU 이라는 메트릭을 사용해서 측정해보니, 본인들이 제안하는 데이터로 모델을 학습한 것이 성능이 더 좋다는 것을 리포팅한 부분입니다. IoU 라는 지표는 아마 URP 과정 중 SSD를 통해 들어보셨을 것이라 생각이 됩니다. mIoU는 클래스 별 IoU 계산 결과를 평균을 낸 것으로 Segmentation에서 얼마나 좋은 성능을 내는지 확인할 수 있는 지표로 많이 사용됩니다~!
이해될 때까지 답변 드리겠습니다!! ㅎㅎ 또 질문이 있다면 언제든지 남겨주세요!