기존의 vision transformer에 사용된 multiple modalities 데이터는 성능을 향상시키는데 도움이 되었지만, inner-modal의 집중해야하는 부분인 attentive weights는 충분히 고려되지 못해 최종 성능에는 좋은 영향을 주지 못했다. 본 논문에서는 transformer를 기반으로 하는 vision task를 위한 multimodal token fusion 방법론인 TokenFusion 방법론을 제안한다. tokenfusion에서는 multi modalities의 효과적인 fusion을 위해 uninformative tokens를 찾고 해당 tokens들을 다른 modality에서 projected되고 합쳐진 inter-modal features로 대체한다. 또한 Residual Positional Alignment라는 방법을 적용하여 fusion 이후에 inter-modal alignments의 명시적(explicit) 활용을 가능하도록 했다. tokenfusion은 transformer를 통해 multimodal features간 correlation을 학습하도록 했다. 서로 다른 데이터 형태를 가지는 homogeneous, heterogeneous modalities에 대해 따로 평가를 진행했고 image-to-image translation, rgb-depth semantic segmentation, 3d object detection 3가지 vision task에서 sota를 달성할 수 있었다.
Introduction
transformer는 nlp에서 활발히 연구되어 사용되었고, 이후에 vision-language task로 확장되었다. 그리고 최근에는 많은 computer vision task에도 적용되어 각종 single modal vision task에서 좋은 결과를 보이고있다. 복잡한 alignment관계를 가지는 multimodal data를 처리하려면 fusion하기 위한 model구조를 design하는데 어려움이 존재한다. 이러한 모델을 설계하기 위해 중요하게 고려해야할 점은 어떻게, 그리고 어디서 각 modality의 features를 fusion할 것인가이다. 기존에 VL-BERT, ViLT와 같은 visioin-language fusion 방법론들이 존재했는데 각 transformer layer에 들어가기 전 direct하게 concate하는 간단한 방식을 사용했다. 이러한 fusion 방식은 보통 alignment-agnostic(불가지론: 인식 불가능함)라고 하며 inter-modal alignments가 명시적으로 활용되지 못해 좋은 성능을 보이기 어렵다. 다른 multiple vision modalities에 대해 fusion하는 방식이 몇몇 존재하는데, TransFuser 방법론에서는 transformer module을 CNN backbone과 연결하는 방법을 사용했다. 이러한 기존 방법론들과는 다르게, 본 논문에서는 효과적이고 general한 방법을 통해 inter-modal alignments를 고려하여 multiple single-modal transformers를 combine하는 방법을 제안했다.
서로 다른 modality끼리 서로 상응하는 위치를 알고있는 alignment-aware fusion방식을 적용하기 위해서는, inter-modal alignment를 맞춰주기 위해 camera intrinsic/extrinsic parameter를 통해 world space의 points들을 camera plane의 해당하는 pixel에 projection해준다. 이러한 alignment-aware fusion방식은 서로 다른 modality간 alignment 관계를 명시적으로 포함하게 된다. 하지만 inter-modal projection을 transformer에 적용함으로써 alignment-aware fusion방식이 기존 모델 구조와 data flow를 변경할 수 있으며, 잠재적으로 모델 성능에 악영향을 미칠 수도 있다. 따라서 multimodal projection과 fusion에서 적합한 Layer, token, channel 등을 선택해주어야햐며 모델의 구조를 변경하거나 optimization setting을 tunning해야할 수도 있는데 이러한 어려움을 해결하고자 적응적이고 효과적으로 multiple single-modal transformer를 fusion하는 TokenFusion을 제안하였다. TokenFusion의 기본적인 아이디어는 multiple single-modal transformers를 pruning하고 이렇게 prune된 units를 multimodal fusion에 재활용하는 것이다. 각 pruned된 unit은 다른 modality로부터 projection된 alignment features로 대체된다. 이러한 fusion방식은 상대적으로 중요한 unit의 attention relations를 가지고 있기 때문에 기존 single-modal transformer에 제한적인 영향을 미칠 것이라고 저자는 주장했고 또한 multimodal transformers가 single-modal에서 pretraining된 parameter를 적용하였을때도 좋은 결과를 보였다고 한다. 평가는 multimodal image translation, rgb-depth semantic segmentation, 3d object detection에서 진행했고 3d object detection benchmark인 SUNRGBD와 ScanNetV2에서 sota를 달성하였다.
Related Work
Transformer in Computer Vision
transformer는 NLP 분야에서 고안되었으며 multi-head self-attention과 feed-forward MLP layers를 쌓아 만들어 단어들간의 long term correlation을 포착하고자 하였다. 최근에는 ViT(vision transformer)가 등장하여 large-scale image classification을 위한 transformer-based model에서 가능성을 보여주고 있다. 이후 다른 segmentation, detection과 같은 다양한 computer vision task에서도 영향력있는 결과를 보이고 있다.
Fusion for vision Transformers
multimodal data를 fusion하는 것은 서로 다른 multiple source를 활용하여 성능을 끌어올릴 수 있는 잠재력이 있기 때문에 중요한 요소로 다뤄진다. 하지만 정교한 single-modal design에 영향을 미치지 않도록 하면서 여러 개의 일반적인 multiple single transformer를 결합하는 것은 어렵다. 기존에 사용된 fusion방식들과는 다르게, 본 논문에서는 구조를 redisign하거나 optimization setting을 다시 조율하지 않고도 inter-modal alignment 관계를 명시적으로 활용하여 general하게 vision transformer를 fusion하는 pipeline을 build하고자 하였다.
Methodology
3.1에서 두 가지 multimodal fusion방법에 대해 소개하고, 3.2에서 multimodal token fusion을 제안한다. 그리고 3.4와 3.5에서 homogeneous와 heterogeneous modalities에 대해 더 정교한 fusion design을 소개한다.
Basic Fusion for Vision Transformers
M개의 modalties 중 i번째 input data를 x(i) = {xm(i) ∈ RN×C}m=1M라고 하자. N은 token의 수를 의미하고 C는 input channel 수를 의미한다. multi-layer model f(x)는 transformer-based network로 model이 총 L개의 layer를 포함하고 있다고 했을 때 l 번째(l = 1, . . . , L) layer에서의 input token feature는 el = {eml ∈ RN×C’}m=1M로 표현하고 이때 C’은 feature channel의 수를 의미한다. 첫 번째 feature인 em1은 patch단위의 xm을 vectorize하기위해 linear project(conv 태워)하여 얻은 값이다. 서로 다른 input modalities에 따라 서로 다른 transformers를 사용하고 m번째 transformer를 통과한 final prediction을 fm(x) = emL+1로 나타낸다. m번째 modality에서의 token feature eml이 주어졌을 때 l번째 layer를 통과한 feature는 아래 수식(1)과 같이 표현할 수 있다.
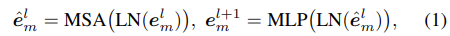
MSA, MLP, LN은 각각 Multi-head Self Attention, Multi-Layer Perception, Layer Normalize를 의미하며 e^ml은 MSA를 통과한 output feature를 의미한다.
vision task에서 multimodal fusion을 수행하려고 할 때, 서로 다른 modality간 alignment 관계는 명시적으로 존재한다. 예를 들어 image와 depth에서는 pixel 위치가 alignment 관계를 포함하고 데이터를 취득할 때 camera의 intrinsic/extrinsic이 3d point를 image로 projection할 때 중요한 alignment 관계를 내포하게 된다. 이러한 alignment 정보를 기반으로 논문에서는 크게 두 가지 방법의 transformer fusion 방법론에 대해 고려하게되었다.
Alignment-agnostic fusion
먼저 alignment-agnostic fusion방법은 agnostic(불가지론)이라는 단어에서 느낄 수 있듯이 서로 다른 modalities간 alignment 관계를 명시적으로 사용하지 않는 것이다. alignment가 많은 양의 dataset으로부터 내포적으로 학습된다는 이유에서이다. intro에서 설명한 것처럼 alignment-agnostic fusion방법의 일반적인 방식은 multimodal input tokens를 단순히 concat하는 것이다. l번째 layer에서의 input feature el이 서로 다른 modalities에 대해 token-wise로 concat될 수도 있다. alignment-agnostic fusion방법은 기존 transformer model을 크게 수정하지 않아도 되기 때문에 간단하지만, 이미 알고있는 multimodal alignment relations를 고려하지 못하는 단점이 존재한다.
Alignment-aware fusion
alignment-aware fusion방법은 서로 다른 modality간 상응하는 위치를 알 수 있기 때문에 inter-modal alignments를 명시적으로 활용하게 된다. 해당 방식은 위에서 언급했던 것처럼 alignment가 같은 pixel이나 3d coordinate에 해당하는 tokens를 찾아 선택하는 방법이다. m번째 modality input xm의 n번째 token이 xm[n]으로 표현된다고 했을 때, m번째 modality에서 m’번째 modality로 token projection을 것을 아래 수식(2)처럼 정의했다.
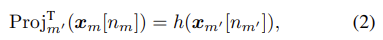
h는 서로 다른 modality에서 같은 위치의 값을 projection하는 identity function이다. 그리고 모든 N개의 tokens에 대해 projection을 하여 concatenation하여 modality projection이라는 것으로 아래 수식(3)처럼 정의하였다.
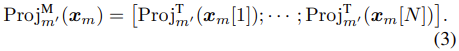
수식(3)은 input단에서 fusion하는 방식인데 다른 위치에서도 fusion을 할 수 있다. transformer 기반의 모델에서는 높은 복잡도를 보이기 때문에 최적의 fusion하는 전략과 위치를 잘 선택해야한다.
Multimodal Token Fusion
논문 처음에 소개했던 것처럼 TokenFusion에서는 single-modal transformer를 prune하고 pruned된 unit을 fusion을 위해 재활용한다. 이 방식은 single-modal transformer의 informative한 units이 대부분 보존되며 성능 향상을 위해 multimodal fusion을 적용하는 것이라 생각할 수 있다. 이전 vision transformer의 token은 hierarchical하게 prune되었다. 비슷하게 여기서에도 scoring function을 적용하여 덜 informative한 token을 선택하게 되는데, m번째 modality의 l번째 layer에서 token의 중요도를 dynamical하게 예측하기위한 scoring function은 sl(el) = MLP(el) ∈ [0, 1]N 로 표현한다. sl(el)이 backpropagation이 가능하게 하기 위해 위의 수식(1)을 아래 수식(4)와 같이 MSA output e^ml 을 재구성한다.
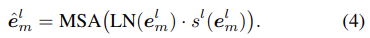
m번째 modality에 대한 loss는 Lm으로 나타내고, uninformative token을 prone하기 위해 sl(eml)에 대한 token-wise pruning loss(l1-loss)를 추가해준다.

이렇게 feature eml ∈ RN×C’에서 token-wise pruning을 통해 모든 N개의 tokens 중에 중요하지 않은 tokens를 dynamic하게 찾아낸다. 제안하는 multimodal transformer에서의 token fusion 방식은 찾아낸 uninformative한 tokens를 다른 modality로부터 projection한 token으로 대체하는 방식을 제안한다. 이 과정은 각 transformer layer이전에 수행되며 l번째 layer의 input feature eml은 아래 수식(6)과 같이 reformulate된다.

수식에 대문자 I로 보이는 것은 mask tensor ∈ {0, 1}N을 output으로 하는 indicator이고 θ는 10^-2의 threshold이며 operator ⊙는 element-wise multiplication을 의미한다. 만약 2개 이상의 modalities를 가지는 경우라고 하면 tokens를 M-1개로 pre-allocate해놓고, allocated된 부분은 자신과 다른 modaltiy 중 하나와 결합된다. pre-allocation에 대한 더 자세한 내용은 뒤에서 다루도록 한다.
Residual Positional Alignment
만약 uninformative한 tokens를 direct하게 대체하면 원래의 positional 정보가 손상될 위험이 있어 모델이 다른 modality로부터 projected된 features의 alignment를 이해하지 못할 수도 있다고한다. 따라서 이러한 문제를 완화하기 위해 Residual Positional Alignment(RPA)를 적용하여 multimodal alignment의 Positional Embeddings(PEs)을 활용하고자한다. RPA의 핵심 아이디어는 후속 layers에 equivalent한 PEs를 주입한다는 것이다. PEs의 backpropagation은 첫 번째 layer 이후에 멈추는데, 이는 train시 첫 번째 layer의 PE의 gradient만 유지되고 나머지 layers는 freeze한다는 의미이다. 이러한 방식으로 PEs는 원래 token을 다른 modality의 token으로 대체했음에도 불구하고 multimodal token을 정렬하도록 수행된다. 정리하자면 token이 대체되더라도 다른 modality에서 projection된 feature에 추가되는 original PEs는 보존된다는 뜻이다.
Homogeneous Modalities
homogeneous vision modaltiy x1, x2, · · · , xM들은 rgb나 depth에서 같은 위치에 있는 pixel에 대해 같은 label을 공유하게된다. 이러한 특성이 transformer 기반 모델이 joint learning을 할 때 도움이 된다고 주장한다. 따라서 서로 다른 modality에 대해 MSA와 MLP layer 모두에서 parameters를 share한다. 이때 서로 다른 modality는 통계적으로 평균과 분산의 분포가 크게 다를 수 있기 때문에 modality-specific layer normalization 과정을 분리해서 적용한다. 이 경우에는 수식(6)에 h를 identity function으로 적용하고, 항상 pruned된 token을 같은 position을 sharing하는 token으로 대체할 수 있도록 두 모달리티의 token 수를 같도록(nm’ = nm) 설정해준다. homogeneous modalities의 fusion을 위한 TokenFusion의 구조는 Figure 1에서 확인할 수 있다.
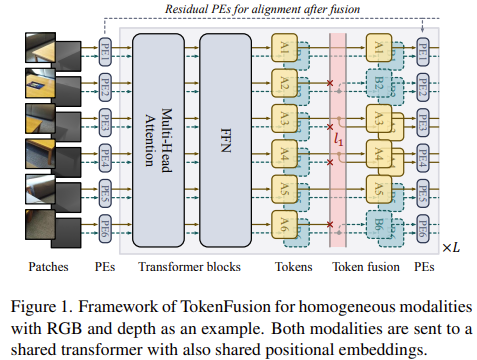
두 개의 input modalities에 대해 bi-directional projection을 적용하고 각각 modality에 token-wise pruning을 적용한다. 그리고 uninformative한 token을 대체하는 token substitution과정은 위의 수식(6)에 따라 진행된다. 위에서 설명했던 것처럼 2개 이상의 modality를 적용하는 경우 수식(6)에 따라 m modality 중 m’을 뽑아 pre-allocation strategy를 통해 모든 modality의 token-wise pruning을 적용한다. 좀 더 자세히 설명하자면, m번째 modality에서 N개의 token을 같은 크기를 가지는 M-1 group에 random하게 사전할당한다. 이 pre-allocation과정은 training과정 전에 수행되어 training 시 group은 고정되어 사용된다. am’(m) ∈ {0, 1}N으로 group allocation을 나타내며, am’(m)[n]이 1이라는 것은 m번째 modality의 n번째 token이 pruned되었다는 것을 나타낸다. 이 경우에는 상응하는 m’번째 modality의 token으로 대체된다. 지금까지 내용을 수식으로 한 번에 표현한 것이 아래 수식(7)이다.
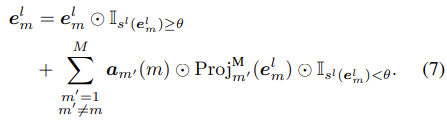
Heterogeneous Modalities
여기서는 input modalities가 서로 다른 data format을 가지거나 구조적인 차이를 가지는 heterogeneous modaltiy를 다루는 법에 대해 알아보자(transformer의 구조에서 layer수가 다르다거나 embedding dimension이 다르다거나 등). 대표적인 예로 3d object detection과 2d object detection을 서로 다른 transformer로 동시에 학습하는 task가 될 수 있겠다. heterogeneous modalties에 대해 fusion하는 TokenFusion의 구조는 아래 Figure 2에서 확인할 수 있다.
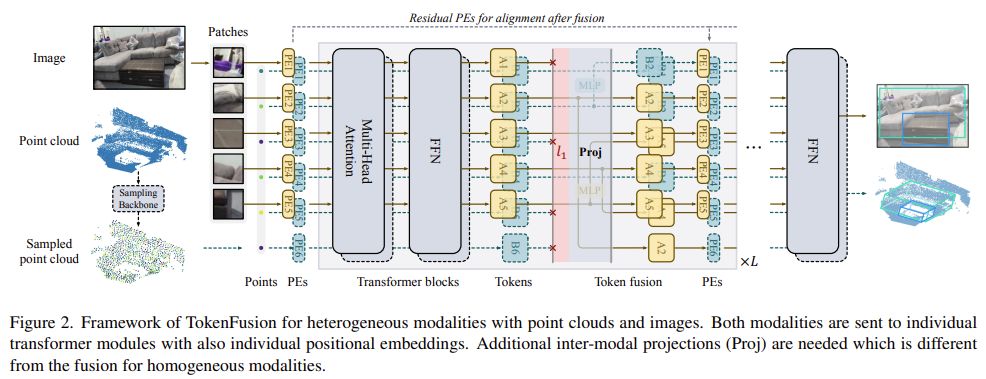
homogeneous경우와는 다르게 MLP를 통해 수식(2)의 token projection function h를 근사한다. 기존에 3d object detection에서 camera intrinsic/extrinsic을 이용해 3d point를 상응하는 2d로 project하는 것처럼, 3d object label을 image에 projection하여 상응하는 2d object label을 얻는다. 그리고 두 개의 unshared parameter를 가지는 transformer를 end-to-end로 학습한다. point cloud를 input으로 하는 3d object detection의 경우 Group-Free의 구조를 따르고, image를 input으로 하는 2d object detection의 경우 YOLOS의 구조를 따른다고한다. inter-modality projection은 seed point를 image patch에 mapping한다(Npoint-to-Nimg mapping). 이때 seed point tokens(Npoint)에 token-wise pruning이 적용된다. 그럼 특정 token의 경우 low important score를 가질 것이고 이 token의 3d coordinate를 image input에 해당하는 2d pixel에 projection하게된다. 이 과정을 수식(2)에서 m과 m’을 각각 “point”와 “img”로 바꿔서 표현할 수 있다.
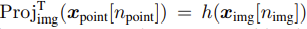
token projection을 통해 얻은 npoint와 nimg사이의 관계는 아래 수식을 만족한다.
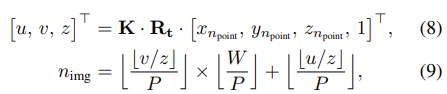
K와 Rt는 각각 camera intrinsic과 extrinsic matrices를 나타내며 [xnpoint , ynpoint , znpoint , 1]은 npoint번째 point의 3d coordinate를 의미한다. u, v, z는 [u/z], [v/z]가 실제 image pixel로 projection된 좌표이다. P는 vision transformer의 patch size, W는 image width를 나타낸다.
Experiments
평가는 homogeneous와 heterogeneous modalities에 대해 여러 sota 방법론들과 비교하였다. 3d object detection에 대한 결과에 좀 더 집중해서 보도록하자.
multimodal image-to-image translation
먼저 multimodal image-to-image translation task를 보면, multimodal image-to-image translation이란 예를들어 normal과 depth정보를 합쳐 rgb image를 생성하는 것 처럼 서로 다른 modality를 input으로 하여 target modality를 생성하는 방식이라고 한다. 여기서는 Taskonomy dataset을 사용했다고 하며 이 dataset은 large-scale의 indoor scene dataset이라고 한다. 실험에서는 generator와 discriminator 두개의 transformer를 각각 사용했으며 10 layer를 가진 tiny version(Ti)과 20 layers를 가진 small version(S)의 architecture를 사용했다. 아래 Table 1에서 성능을 확인할 수 있다.
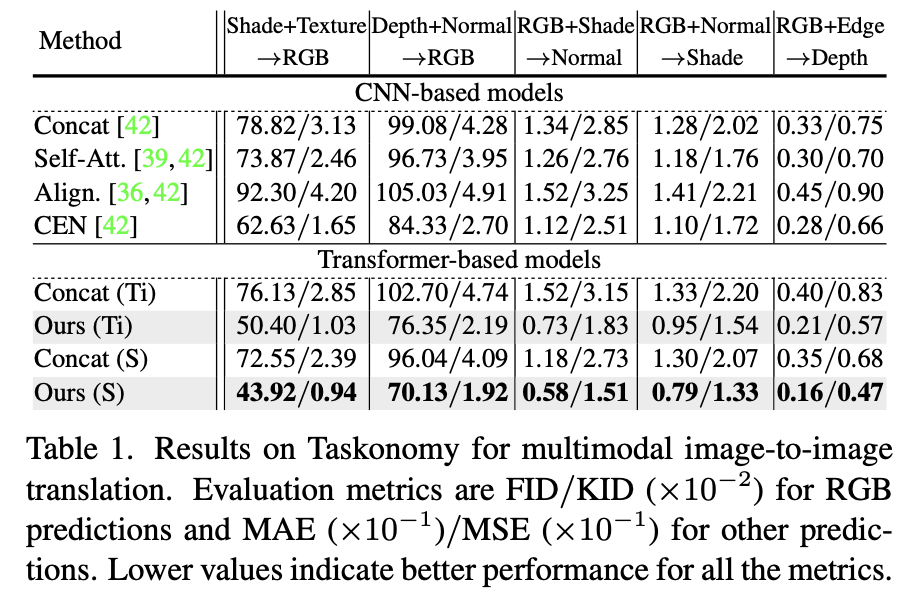
기존의 모델들이 대부분 cnn based model이어서 cnn-based와 transformer-based 두 가지의 baseline을 제공하였다. 제시되어있는 성능은 MAE/MSE 값으로 작을수록 좋은 성능이라고 이해할 수 있다. 결론적으로 본 논문에서 제안하는 TokenFusion 방법이 큰 폭으로 가장 좋은 성능을 보이는 것을 알 수 있다. 아래는 시각화한 자료이다.

오른쪽 끝에서 두 번째의 TokenFusion을 사용한 방법이 가장 색상도 풍부하고 detail한 요소들도 잘 생성한 것을 직관적으로 확인할 수 있다.
rgb-depth semantic segmentation
또 다른 homogeneous한 modality에 대해 평가를 진행했는데 rgb-depth semantic segmentation이다. 데이터셋은 NYUDv2와 SUN RGB-D를 사용했다. 여기서도 위의 image translation task에서와 마찬가지로 tiny와 small 모델 구조를 사용하였다. 결과는 아래 Table 2에서 확인할 수 있다.
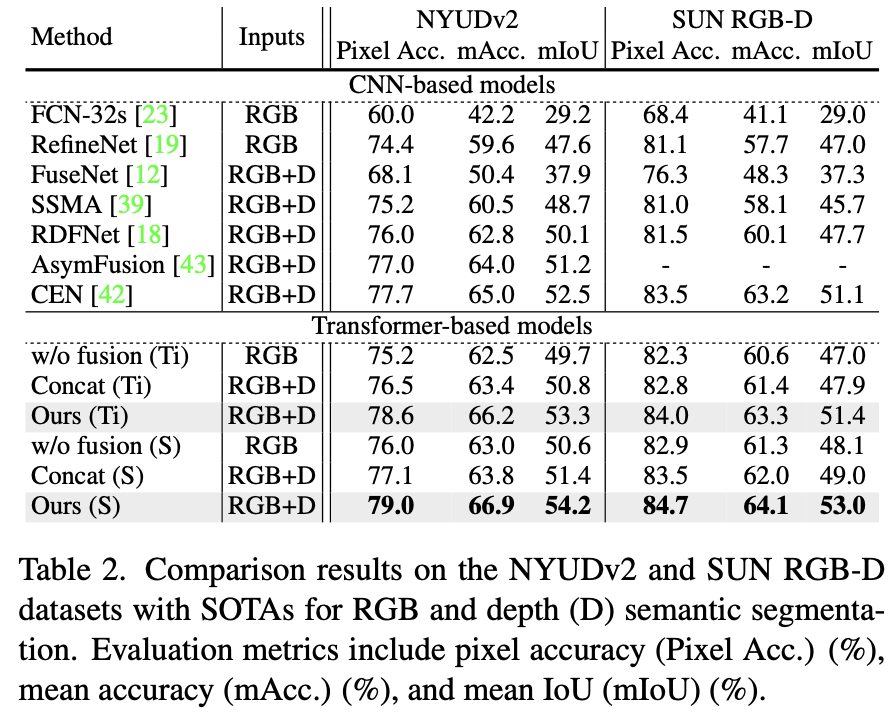
전반적으로 보았을 때 tokenfusion을 사용한 transformer기반 방법론들의 성능이 대체로 cnn기반의 방법론들보다 높은 것을 알 수 있다. 여기서는 light한 backbone을 사용했다고 하는데 더 큰 backbone을 사용하면 성능이 더 향상될 가능성이 있다고 주장한다. 논문에서 table에 대한 설명이 없어 아쉬운 것 같다.
vision and point cloud 3d object detection
heterogeneous modalties를 fusion하는 3d object detection task에 TokenFusion을 적용하였다. 여기서는 3d point cloud와 2d images에 대해 각각 3d, 2d detection을 동시에 진행했다. 3d와 2d detection은 각각 GroupFree와 YOLOS(you only look at one sequence)라는 모델 구조를 사용하였고 groupfree와 YOLOS의 tiny, small version을 각각 combine하여 사용하였다. 아래 Table 3과 Table 4에서 성능을 확인할 수 있다.
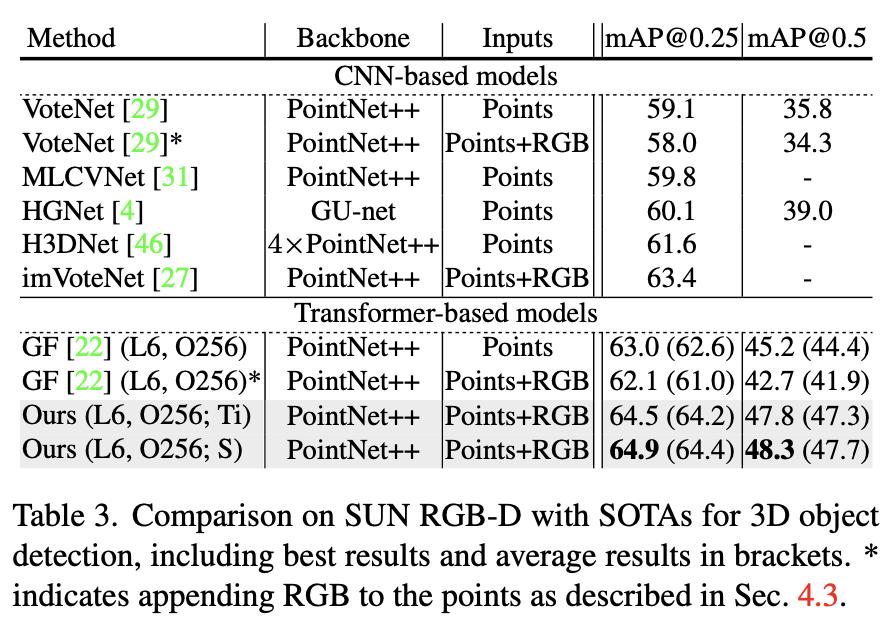

먼저 Table 3은 SUN RGB-D에서의 성능이고 Table 4는 ScanNetV2에서 성능이다. *이 붙은 것은 pointnet++을 통과한 sampling된 points의 3 channel의 rgb vector를 append했다는 표시이다. 수치적으로 확인할 수 있듯이 *이 붙어있는 rgb vector를 단순히 append하여 사용한 것이 오히려 성능을 drop시키는 것을 알 수 있다. 이것이 heterogeneous fusion task의 어려움을 잘 보여주고 있고 기존에 fusion방식이 왜 point cloud만을 사용하는 것보다 좋은 결과를 얻지 못했는지 설명해준다고 생각한다. 본 논문에서 제안하는 TokenFusion의 경우 cnn기반 방법론뿐만아니라 다른 transformer기반 fusion방법보다 좋은 결과를 보이는 것을 확인할 수 있다. 아래 Figure 5에서 visualize결과를 확인해보자.

시각적으로 보았을 때 TokenFusion방식이 확실히 3d prediction에서 눈에 띄는 효과를 보인다고 생각한다. 두 번째 행을 보면, 특히 파란색 박스를 보면 tokenfusion을 하여 3d prediction을 할 때 확실히 sparse하고 missing data가 많은 부분에서도 object의 위치를 잘 찾아낸 것을 알 수 있다. 또한 첫 번째 행에서처럼 occlsuion이 존재하는 경우에 tokenfusion이 또 잘 찾아내는 것을 알 수 있다.
Ablation Study
Table 5에서는 l1-norm과 tokenfusion의 효과를 보이고있다.
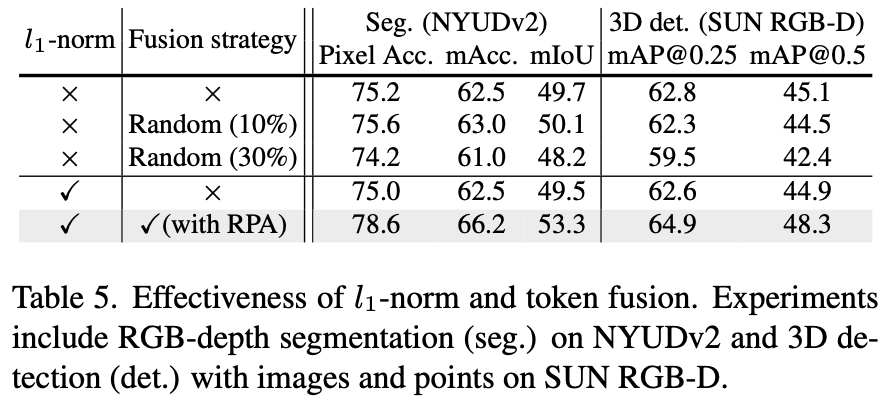
l1-norm을 fusion과 같이 적용하지 않았을 때는 오히려 성능이 조금 떨어졌는데, fusion과 함께 사용하였을 때 그 효과가 드러나는 것을 확인할 수 있다. 또 random하게 fusion하는 것보다 본 논문에서 제안하는 것처럼 score에 따라 uninformative한 patch를 다른 modalty로 활용하는 fusion방식(+ RPA로 positional embedding 보존)이 더 좋은 효과를 보인다.
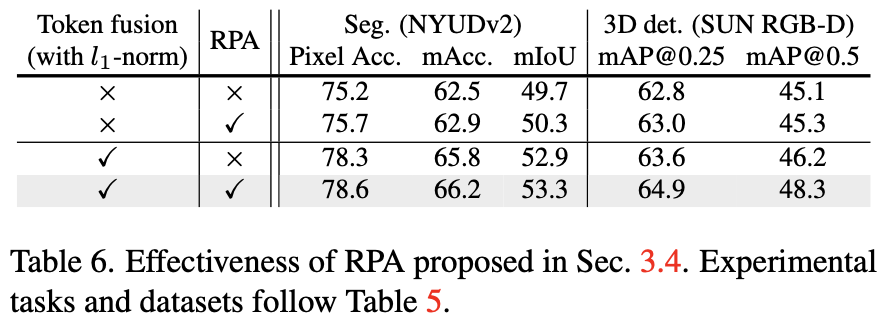
Table 6에서는 RPA(Residual Positional Alignment)의 효과를 보이고있다. 3d task에서 RPA가 token fusion방식과 함께 사용되지 않을때 성능에 미치는 영향보다 token fusion과 함께 사용되었을 때 더 큰 성능 향상을 보이는 것을 알 수 있다.
Conclusion
본 논문에서는 homogeneous, heterogeneous modality를 가지고 vision transformer를 fusion하는 TokenFusion을 제안하였다. TokenFusion은 uniformative한 tokens를 추출하고 이 tokens들을 다른 multimodal의 informative한 token과 interaction을 강화하기 위해 재사용하였다. 서로 다른 modality간 alignment relation은 residual positional alignment와 inter-modal projection을 통해 명시적으로 활용되었다. 기존에 fusion기반 방법론이 좋은 성능을 보이지 못했지만 transformer를 사용하여 fusion기반 방법론으로도 좋은 성능을 보일 수 있다는 것을 증명하는 논문이라고 생각된다. 참고로 SUN RGBD에서 vision transformer를 기반으로 하는 방법론들 주에는 아직 가장 좋은 성능을 보이는 것으로 알고있다. 논문을 처음에 읽을 때 이해가 어려웠는데 여러 번 수식을 이해하려고 하니 더 잘 이해할 수 있었던 거 같아 수식을 기반으로 이해하면 그리 어렵지 않을 것이라 생각한다.
안녕하세요 ! 좋은 리뷰 감사합니다.
리뷰를 읽고 궁금증이 생겨 질문 드립니다.
Multimodal Token Fusion이 single model transformer에서 scoring fnction을 적용하여 상대적으로 덜 informative한 token을 다른 modality에서 projection한 token으로 대체하는 방식이라고 얘기해주셨습니다. 제가 이해하기로는 대체되는 token은 다른 modality에서 같은 위치의 값을 projection한 값이라고 생각을 하는데, 그렇다면 논문에서 언급된 원래의 positional 정보가 손상되는 위험이 있기 때문에 다른 modality에서 projection한 token의 alignment를 이해하지 못할 수도 있다는 문제점 외에도 대체된 token이 본래의 token보다 informative하다는 보장을 어떻게 할 수 있는 것인지 궁금합니다. 혹시 수식 10^-2의 threshold라고 언급되는 세타가 그런 역할을 하는 것일까요?
댓글 감사합니다.
질문주신 내용은 fusion을 하는 이유에 대한 내용이 될 것 같기도 한데요, 보통 fusion을 하는 이유가 서로 다른 modality에서 각 modality가 가지는 장단점을 보완하기 위해 사용한다고 생각합니다. 예를 들어 3d point cloud의 sparsity를 보완하기 위해 rgb 2d image를 사용하는 것처럼 본 논문에서는 h함수를 통해 각 modality에서 informative한지에 대한 score를 구하고 말씀하신 threshold를 기준으로하여 활용할만한 정보가 있는지 부족한지를 판단하게 됩니다.
좋은 리뷰 감사합니다.
Mulitmodal Token Fusion 부분에 대해 궁금한 것이 있습니다. multimodla token fusion은 정보력이 낮은 영역을 다른 모달리티로 대체해주는 것으로 이해하였는데 맞나요?? 또한, m모달리티에 대한 loss L_m은 무엇과 예측 score를 비교하는 것인지 설명 부탁드립니다.
처음 실험(표1과 그림3이 해당하는)은 특정 모달리티의 정보들을 결합하여 온전한 RGB영상을 만들어내는 것으로 보이는데 Shade 정보가 어떤 것인지 설명해주실 수 있나요?
댓글 감사합니다.
네. 특정 modality의 score가 낮은, 즉 정보력이 낮은 token을 다른 modality의 token으로 대체합니다. loss는 task의 맞는 loss가 적용되며 objectness loss, box loss, sementic classification loss 등이 적용될 수 있습니다.
shade정보는 이미지의 밝고 어두운 부분을 나타내는 음영이미지입니다.
안녕하세요. 좋은 리뷰 감사합니다.
tokenfusion의 기본적인 아이디어를 여러개의 single-modal transformer -> prunning -> 여러개의 prune된 units -> multimodal fusion으로 이해했습니다.
또한 이 논문의 contribution이 구조를 다시 디자인하거나 optimization을 setting읗 다시 조율하지 않고도 general하게 vision transformer를 fusion하는 것으로 이해하였습니다.
리뷰를 읽고 궁금한 부분이 생겨 질문 드립니다.
1) multimodal token fusion에서 scoring function을 적용하여 덜 informative한 token을 선택한다고 하였는데 왜 덜 informative한 token을 선택하나요??? 앞에서 single-modal transformer의 informative한 units이 대부분 보존된다고 하였는데 이와 비슷하게 진행하기 위해서는 더 infromative한 token을 선택해야 하는거 아닌가 궁금합니다.
2) token fusion 방식을 통해 찾아낸 uniformative한 tokens를 다른 modality로 projection한 token으로 대체한다고 하였는데 이는 다른 modality로 projection한 token이 더 informative하기 때문인가요?
댓글 감사합니다.
1) 2번에서 질문하신 것처럼 덜 informative한 token을 선택하여 상응하는 다른 modality의 token으로 대체하기 위함입니다. 더 informative한 token을 보존하기 위함이죠
2) scoring function을 통해 얻은 score값이 threshold보다 낮은 token을 다른 모달리티에서 threshold보다 높은 token으로 대체하기 때문에 상대적으로 더 informative한 정보를 포함하는 token으로 대체한다고 생각합니다.