오늘의 X-Review에서 소개해드릴 논문은 21년도 CVPR에 게재된 Self-supervised Motion Learning from Static Images입니다. 논문의 제목을 통해 정적인 이미지로부터 동적인 motion을 잡아내기 위한 self-supervised 학습 방법론임을 유추할 수 있습니다. Motion에 대한 시공간 축 라벨이 없는 상황에서 action 관련 비디오 task들(Action Recognition, Action Localization 등)을 해결할 때 도움을 주는 feature를 추출하는 것에 목적이 있는 것입니다.

그러면 바로 논문의 Introduction으로 들어가보겠습니다.
1. Introduction
Video understanding 분야에는 정말 많은 task가 있지만, 그 중에서도 action recognition, action localization 또는 action detection 등 action 관련 task는 비디오의 중요한 핵심 요소와 구조를 파악하는 데에 큰 기여를 하며 발전해왔습니다. 이러한 task들은 결국 비디오 내에서 어떠한 action이 발생하는지, 더 나아가 그 action이 어느 구간에서 발생하는지 찾아야 합니다. 그렇기 때문에 당연히 비디오 내에서 발생하는 action의 특성을 잘 모델링하여 background 대비 구별력을 갖는 feature를 추출할 수 있다면 해당 task들을 해결하는 데 단단한 발판이 될 수 있겠죠.
참고로 논문에서 언급하는 motion과 action은 차이가 있습니다. Motion은 단순히 비디오나 단일 영상 내에서 발생하는 움직임을 의미하고, Action은 이러한 motion들이 모여 특정한 패턴을 만들어낼 때 그 패턴들로 구성되는 상위 레벨에서의 의미를 갖는다고 볼 수 있습니다.
연구 초반에는 Dense trajectories 또는 Optical flow와 같은 hand-crafted feature를 추출하여 motion 정보를 얻었습니다. 후에 딥러닝의 발전과 대용량 이미지, 비디오 데이터셋이 구축되며 딥러닝 쪽이 좋은 feature를 추출할 수 있게 되었다는 흐름은 다들 알고 계실 것입니다. 그러나 대용량 데이터셋으로 비디오 분야에서 사용되는 3D backbone들을 학습시켜 일반화된 성능을 얻으려면 어마어마한 양의 labeled 데이터가 필요합니다.
이러한 흐름 속에서 Self-supervised 기반의 학습 방법론들이 많이 등장하였고, 그 추세는 현재까지도 활발히 이어지고 있습니다. 이미지든 비디오든 라벨링되지 않은 대용량의 원천 데이터에는 쉽게 접근할 수 있는데, Supervised 기반의 학습 방법론을 적용하려면 사람이 직접 지정하는 라벨이 필요하기 때문에 대용량의 unlabeled 데이터가 무용지물이 되거나 큰 비용을 들여 라벨링해야 하는 상황이 발생하는 것입니다.
일전에 많은 연구원분들께서 리뷰나 세미나를 통해 설명해주셨듯, Self-supervised 방법론은 pretext task 기반 또는 contrastive learning 기반의 방법론으로 나눠지게 됩니다. 본 논문은 그 중 pretext task 기반의 방법론이라고 생각하시면 됩니다.
비디오 분야에서 기존에 제안되었던 Self-supervised pretext task 기반 방법론으로는 temporal 축에 대한 순서를 뒤바꾼 뒤 모델이 다시 순서를 맞추거나 sampling rate를 조절하여 빠르게 또는 느리게 재생되는 듯한 feature에 대해 sampling rate를 맞추는 방식 등이 있었습니다. 라벨링 되어 있지 않은 비디오의 temporal 축에 대해 변형을 가함으로써 임의의 ground truth를 만들고 이를 이용해 학습하는 것입니다. 물론 이미지 분야에서 활용되던 spatial 축에 대한 여러 augmentation들도 동시에 적용하기도 합니다.
Introduction 초반부에 저희는 action 관련 task를 해결하기 위해서는 비디오 속 motion을 잘 잡아낼 수 있는 학습 방식이 필요하다고 이야기 했었습니다. 하지만 방금 설명드렸던 기존의 pretext task들은 motion 정보를 아예 학습하지 않는다고는 할 수 없지만 명시적으로 비디오의 motion을 모델링하여 이를 맞춘다고 보기에는 어려움이 있습니다. 결국 지금까지는 action 관련 비디오 task를 해결하기 위해 가장 중요한 motion 정보를 암시적으로만 학습하고 있었고, 이를 명시적으로 학습하기 위해 저자는 MoSI(Motion from Static Images)를 제안합니다.
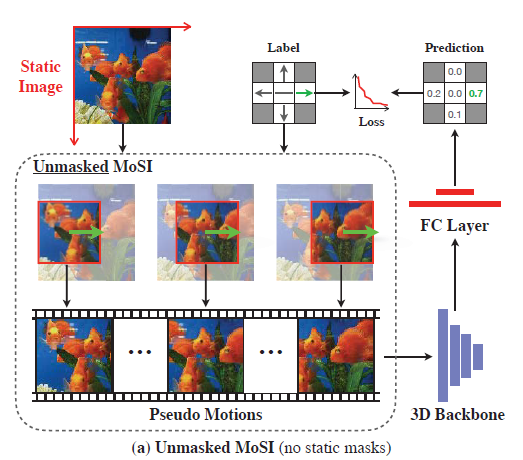
그림 1의 MoSI 설명을 보시면, 좌상단 하나의 정적인 영상에 대해 작은 window를 씌우고 옮겨가며 crop했을 때 아래 3개의 이미지와 같은 pseudo motion을 만들어내는 것을 볼 수 있습니다. Pseudo motion들을 만들어낼 때에는 window를 미리 정해진 방향과 속도만큼 옮기기 때문에 이를 마치 앞선 연구에서 “sampling rate를 얼마로 두었는지”, “원본 sequence를 어떤 순서로 뒤집었는지”와 같은 라벨링되지 않은 데이터에서 임의로 만들어낸 motion 관련 ground truth라고 두고 분류 학습을 수행하는 것입니다. 이제는 어느 정도 motion을 명시적으로 모델링하고 있다고 볼 수 있겠네요.

그림 2는 MoSI 방식으로 ImageNet을 사전학습한 모델에 HMDB51(Action recognition 데이터셋) 비디오를 입력으로 주었을 때 conv5 Grad-CAM입니다. 놀라운 점은 ImageNet으로 사전학습만 했을 뿐 HMDB51 데이터셋으로 Action Recognition에 대한 fine-tuning을 진행하지 않았음에도 불구하고 벌써 꽤나 motion에 잘 집중하고 있다는 것입니다.
그리고 MoSI에 또 다른 장점은 방금 언급하였지만 이미지 데이터셋으로 사전 학습을 수행할 수 있다는 것입니다. 방법론 자체가 정적인 하나의 이미지 또는 프레임으로부터 작은 윈도우를 옮겨가며 pseudo motion을 만들어내기 때문에 사실 상 비디오의 프레임 sequence가 불필요한 것입니다.
이에 대해 저자는, 비디오가 temporal 축을 가지고 있어 물론 더 많은 정보를 갖는 것은 맞지만 라벨이 없는 상황에서 비디오 속 motion의 특정 라벨을 만들어내어 명시적으로 학습하는 것은 굉장히 불안정하고 어렵기 때문에 비디오의 프레임 sequence를 사용하지 않는다고 이야기합니다. 라벨이 없는 raw 비디오에서 모션 정보를 알아내는 것은 사실상 hand-crafted 방식으로 추출하는 dense trajectories나 optical flow와 유사하겠죠. 이는 굉장히 큰 연산량을 수반합니다.
이렇게 MoSI의 가장 기본적인 컨셉은 파악했고, 자세한 여러 이야기들은 아래에서 이어가도록 하겠습니다.
2. Motion Learning from Static Images
MoSI의 목적은 단일 이미지나 비디오의 한 프레임으로부터 다양한 속도, 방향이 사전 지정된 pseudo motion을 만들어내고 3D backbone을 통과시켜 분류하는 것을 목표로 합니다. 이 때 pseudo motion의 속도와 방향을 올바르게 맞추기 위해서 3D backbone은 다양한 motion pattern을 학습하게 될 것입니다.
그리고 앞서 설명드리지 않은 MoSI의 또 다른 contribution은 바로 static mask입니다. 결국 이러한 MoSI의 사전 학습을 통해 해결해야 하는 것은 비디오에서의 action 관련 task인데, 실제 비디오에서의 motion은 전경과 배경에서 일관되지 않게 나타나는 경우가 일반적입니다. 그래서 이를 모방하기 위해 static mask를 씌워 pseudo motion sequence의 일부 spatial 영역은 sequence 내내 움직이지 않고, 나머지 masking 되지 않은 부분의 spatial 영역만 sequence에서 pseudo motion을 갖는(움직이는), “Static Masks” 기법도 제안하였습니다.
우선 Static Masks은 pseudo motion을 생성한 뒤 붙일 수 있는 기법이기 때문에 pseudo motion의 생성 방식부터 알아보겠습니다.
2.1 Pseudo Motions
그림 3은 그림 1과 동일합니다.
최종 목표는 좌상단에서 입력된 source 이미지로부터 하나의 motion label (x, y)를 지정한 뒤 연속된 pseudo motion image sequence \mathbf{u} \in{} \mathbb{R}^{N \times{} L \times{} L}을 얻습니다. 이해를 돕기 위해 실제 저자가 지정한 하이퍼파라미터를 기준으로 설명드리면, N=16, L=112에 해당합니다. 즉, 한 source 이미지의 하나의 motion 라벨 당 하나의 \mathbf{u}를 만들어내어 3D backbone으로 넘겨주는 것입니다.
Label pool
이를 자세히 이해하기 위해서는 우선 motion label (x, y)가 어떠한 범위 내에서 뽑히는지를 알아야 합니다. 그림 3에서 source 이미지의 좌상단을 원점으로 두고 label을 지정하는데요 화살표 방향과 같이 x축은 우측으로 갈수록 +, y축은 하단으로 갈수록 +에 해당합니다. 각 축은 총 C=2K+1개의 속도를 가질 수 있습니다. K는 motion 속도를 얼마나 잘게 나눌 것인지를 의미하고, 이에 따라 motion 속도 set \mathbb{S}는 아래와 같습니다
- \mathbb{S} = \{-K, \cdots{}, -1, 0, 1, \cdots{}, K\}
다시 정리했을 때 각 축은 총 C=2K+1개의 속도를 가질 수 있고, 저자는 두 축 중 최소 하나의 축에서의 속도 값은 0으로 지정하여 label pool을 생성합니다. 만약 두 축 모두 속도가 0이 아닌 라벨은 대각선으로의 motion을 만들어내게 될텐데, 왜인지는 밝히지 않았지만 가짓수가 너무 많아져서인지 이러한 학습 sample을 만들지 않고 있는 모습입니다.
위를 종합해보았을 때 최종 label pool \mathbb{L}은 아래와 같습니다.
- \mathbb{L} = \{i:(x, y)|x \in{} \mathbb{S}, y \in{} \mathbb{S}, xy=0\}
만약 K=2인 경우 \mathbb{S} = \{-2, -1, 0, 1, 2\}이고 이에 따라 하나의 이미지로부터 생성될 수 있는 label pool \mathbb{L} = \{(0, -2), (0, -1), (0, 0), (0, 1), (0, 2), (-2, 0), (-1, 0), (1, 0), (2, 0)\}으로 총 9개의 라벨을 만들어낼 수 있게 되는 것입니다. 그럼 이제 앞서 말씀드렸다시피 하나의 라벨로부터 생성되는 pseudo motion sequence(3D backbone의 입력) \mathbf{u} \in{} \mathbb{R}^{N \times{} L \times{} L}는 어떻게 생성되는지 알아보겠습니다.
Pseudo motion generation
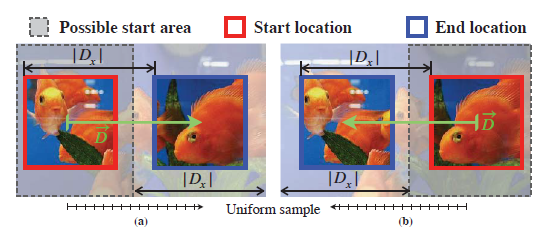
앞서 얻은 label pool \mathbb{L}에서 하나의 라벨 (x, y)를 예시로 pseudo motion의 생성 과정을 설명드리겠습니다. Source 이미지의 해상도는 H \times{} W인데, 실제로는 짧은 축으로 crop하여 정방형을 만들어 H = W = 320입니다. 해당 이미지에 대해 라벨 (x, y)를 기준으로 거리 \vec{D} = (D_{x}, D_{y})를 아래와 같이 지정해줍니다.
- D_{x} = \frac{(W-L)x}{K}, \text{if} \: x \neq{} 0 \: \text{else} \: D_{x} = 0
- D_{x} = \frac{(W-H)y}{K}, \text{if} \: y \neq{} 0 \: \text{else} \: D_{y} = 0
수식에서 L은 112로, window의 크기를 의미합니다. \vec{D}를 구한 뒤 그림에서 보시는 것과 같이 시작 위치에서 끝 위치로 갔을 때, 끝 위치가 source 이미지 밖을 벗어나지 않도록 Possible start area를 구해줍니다. 라벨 (0, 0)은 정적이기 때문에 임의로 아무 위치에서나 시작 지점을 지정해줍니다. 이후 그림 4의 빨간 박스인 시작 지점에서 파란 박스인 끝 지점으로 이동시킨 뒤, 이동한 구간을 등간격으로 나눠 총 N=16개의 sequence를 얻어낼 수 있습니다. 그러면 앞서 설명드렸듯 하나의 source 이미지의 하나의 라벨로부터 \mathbf{u} \in{} \mathbb{R}^{N \times{} L \times{} L} (16, 112, 112)를 얻었고 이를 \mathbb{L}에서 얻을 수 있는 모든 라벨에 대해 수행할 수 있습니다.
Classification
속도의 granlarity K=2인 경우 각 축의 조합을 통해 총 9개의 라벨을 얻을 수 있다고 말씀드렸었는데요, 결론적으로 하나의 source 이미지로부터 (9, 16, 112, 112) 모양의 pseudo motion sequence를 얻을 수 있고 이를 하나의 mini-batch로 두어 3D backbone과 FC layer에 태운 뒤 CrossEntropyLoss로 분류 학습을 수행합니다.
2.2 Static Masks
지금까지 설명드린 방식은 unmasked MoSI에 해당합니다. 그림 4에서 uniform sampling을 통해 얻은 \mathbf{u}는 각 프레임의 모든 spatial 영역에서 motion이 발생하고 있다고 볼 수 있는데요, 이는 실제 비디오에서 카메라가 움직이는 경우라고 생각해볼 수 있습니다. 비디오에서의 모든 spatial 영역에서 움직임이 나타나는 경우도 분명히 있지만, 일반적으로 뒷배경은 정적이고 특정 spatial 영역에서만 움직임이 발생하는 경우도 존재합니다. 이렇게 일반적인 비디오의 특성에도 대응할 수 있도록 학습하는 장치가 바로 static mask에 해당합니다.
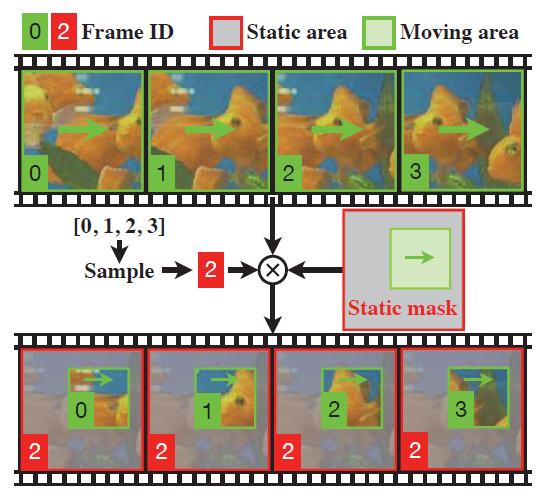
그림 6을 통해 static mask를 이해할 수 있습니다. 앞서 하나의 source 이미지로부터 총 N개의 pseudo motion을 얻을 수 있었는데요, 그림에서는 편의 상 4개의 pseudo motion을 기준으로 설명하고 있습니다. 위 초록색 0, 1, 2, 3 프레임들에서는 각 프레임의 모든 spatial 영역에서 motion이 발생하고 있는 것을 볼 수 있습니다. 이러한 sequence를 3D backbone에 넣어주는 경우 특정한 몇 픽셀만을 보고도 motion speed에 대한 예측값을 쉽게 낼 수 있게 됩니다.
이를 방지하고자 0, 1, 2, 3번 프레임 중 임의로 하나의 프레임 번호 q를 고릅니다. 그림 6에서는 2번 프레임을 임의로 선택하여 static masking을 진행한 예시입니다. 이 때 masking을 하지 않고 원 프레임의 정보를 살릴 영역과 해당 영역의 면적 L_{m} = [0.3, 0.5] \times{} 112을 임의로 지정하여 그림 6의 아래부분과 같이 masking을 진행해줍니다.
Static masking 된 \mathbf{\tilde{u}_{p}}를 구하는 수식은 아래와 같습니다.
- \mathbf{\tilde{u}_{p}} = M(\mathbf{u}_{p}, m)
- M(\mathbf{u}_{p}, m) = \mathbf{u}_{q}, \text{if} \: (a, b) \in{} \mathbf{m}
- M(\mathbf{u}_{p}, m) = \mathbf{u}_{p}, \text{if} \: (a, b) \notin{} \mathbf{m}
Masking을 진행할 임의로 선정된 영역 \mathbf{m}에 해당하면 픽셀값을 mask 값으로 대체하고, 해당하지 않으면 원본 프레임의 픽셀값을 선택하게 됩니다.
이러한 masking을 통해 모델이 단순히 몇 개의 픽셀만 보고 정답을 내뱉는 자명해에 빠지는 상황을 방지할 수 있고, 모델이 motion speed를 맞추기 위해 어느 영역에 집중해야하는지 학습할 수 있게 됩니다.
MoSI의 전체 방법론은 위와 같습니다.
이미지 데이터셋의 경우 입력받는 프레임에 MoSI 방법론을 그대로 적용해줄 수 있고, 비디오 데이터의 경우 비디오만의 특성을 살려 사용한다기보단 한 에포크 내에서 임의로 하나의 프레임을 선정해 단일 이미지처럼 취급하여 MoSI를 수행합니다. 다만 에포크마다 하나의 비디오에서 또 다른 프레임을 샘플링하여 다양성을 높인다고 하네요.
방금 말씀드린 내용 뿐만 아니라 방법론 곳곳에 임의로 정해주는 부분이 많이 들어가있는데, 저자는 이러한 랜덤성을 잘 활용하여 모델이 다양한 상황에 대한 motion 정보를 학습할 수 있도록 설계한 듯 합니다.
이제 실험 부분으로 넘어가겠습니다
3. Experiments
Datasets and backbone
MoSI 방법론을 활용한 사전학습은 UCF101, HMDB51, Kinetics, ImageNet으로 이루어졌습니다. 성능 측정은 UCF101과 HMDB51에서의 Action Recognition으로 수행되었습니다. 3D backbone으로는 기존 연구와 동일한 세팅의 R(2+1)D, R-2D3D가 사용되었습니다.
3.1 What has network learned?
해당 절에서는 backbone 네트워크가 무엇을 학습하였는지 알아보기 위해 사전 학습만 수행하고 fine-tuning은 진행하지 않은 네트워크에 대한 Grad-CAM을 보여줍니다.
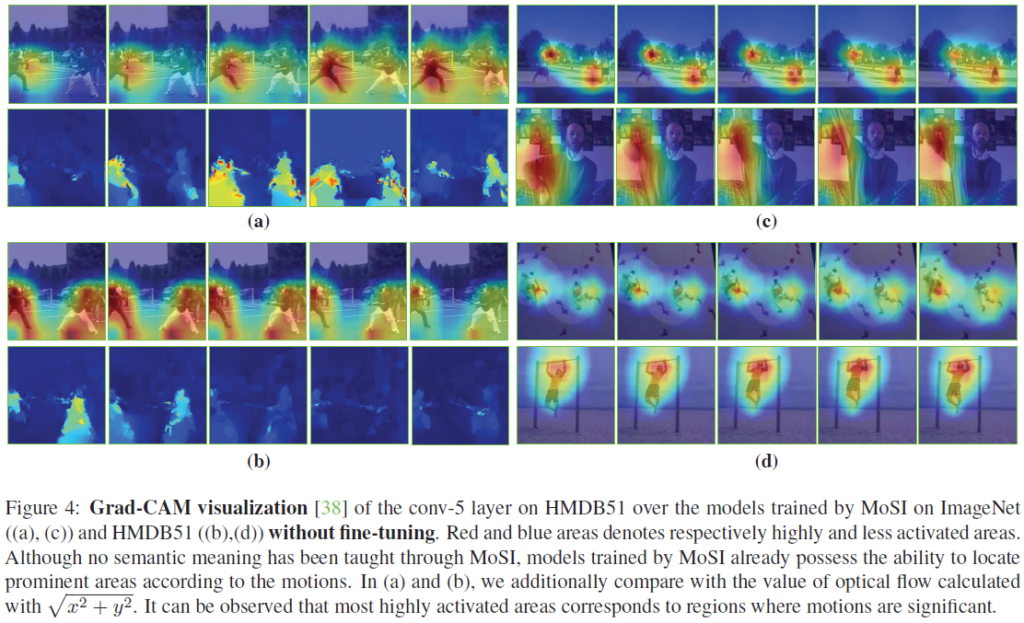
위 Grad-CAM은 모두 fine-tuning 이전에 MoSI 방법론만으로 모델이 학습한 정보를 담고 있습니다. 실제 어느 영역에서 어느 방향으로 motion이 발생했는지를 정확히 알고 비교하긴 어렵지만, 정성적으로는 프레임 간의 차이를 보았을 때 motion이 발생하는 영역에 잘 집중하고 있다는 것을 알 수 있습니다. 추가로 (a), (b) 각각의 아래 행은 optical flow 값을 나타낸 것인데, 저자가 보여주는 정성적 결과에서는 optial flow와 유사한 맥락으로 모델이 집중하는 부분이 변하는 것을 볼 수 있었습니다.
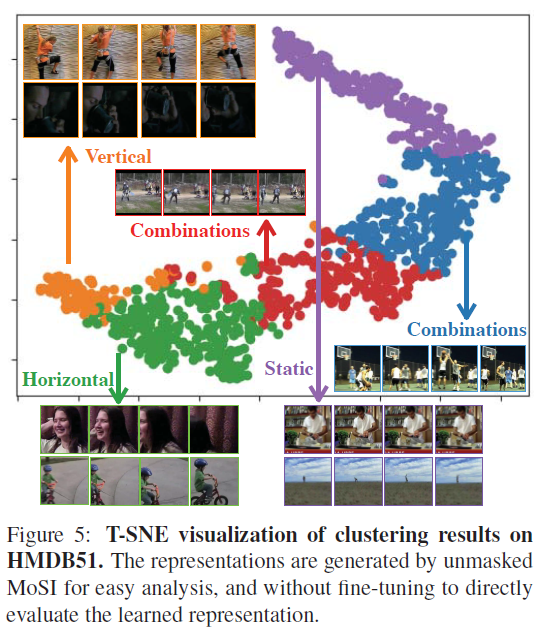
다음으로 그림 8에서는 static mask를 적용하지 않은 unmasked MoSI로부터 얻은 feature들의 t-SNE 결과입니다. 마찬가지로 fine-tuning은 진행하지 않았습니다. 구별력을 갖는 집단들을 살펴보면 MoSI가 명시적으로 학습한 Vertical, Horizontal, Static motion에 해당하는 것을 알 수 있습니다. 다만 동시에 여러 방향으로 발생하는 motion에 대해서는 명시적으로 학습하지 않았기 때문에 유사한 집단임에도 멀리 떨어져 있는 것을 볼 수 있습니다.
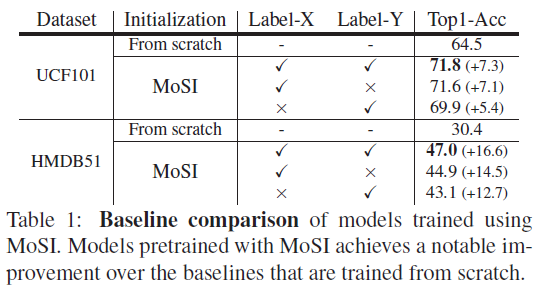
표 1은 각 데이터셋에서 fine-tuning 후 측정한 성능입니다. Label-X 성능의 경우 Y축 라벨을 0으로 두었을 때의 성능이고 Label-Y는 그 반대의 경우에 해당합니다. 당연히 두 축에 대한 motion을 모두 학습하는 경우 성능이 가장 높았고, 어떠한 경우든 scratch로 얻은 feature보다 5% 이상의 큰 정확도 차이를 보이는 것을 알 수 있었습니다.
3.2 Ablation Studies
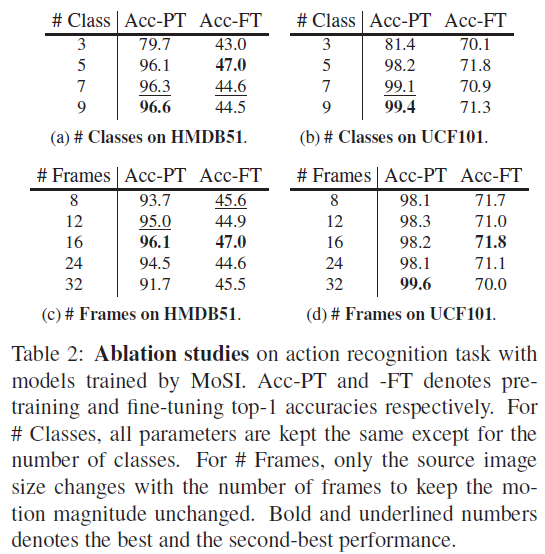
표 2는 각 데이터셋에서 Label pool의 클래스 개수, 비디오에서 선택할 프레임 개수에 따른 ablation 성능입니다. Acc-PT는 pseudo motion에 대한 예측 정확도를 의미하고, Acc-FT는 Action Recognition task에 대한 정확도를 의미합니다.
앞서 K=2인 경우 # Class = 9였는데, 이러한 경우 표에서의 성능은 가장 높았고, 저자에 따르면 # Class를 더 키운다고 해서 성능이 유의미하게 높아지진 않았다고 합니다. (c)에서 16프레임을 사용하는 경우가 성능이 가장 높았는데, fine-tuning을 수행할 때도 16프레임을 이용하기 때문에 이 때 성능이 가장 높은 것으로 추측한다고 합니다.
# Class = 3인 경우는 {-1, 0, 1}로 정적이거나 속도를 1만 갖는 라벨로 학습한 경우를 의미합니다. 이렇게 되면 모델이 다양한 속도에 대해 학습할 수 없기 때문에 확연히 성능이 떨어지는 것을 볼 수 있습니다.
이외에도 masking 영역에 대한 실험 등 다양한 ablation들이 있으니 궁금하신 분들은 논문을 참고하시면 좋을 것 같습니다.
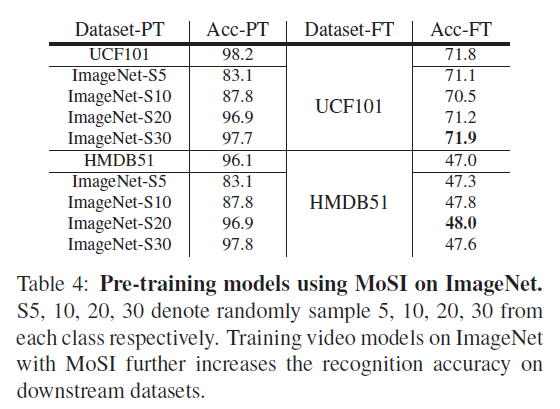
표 3은 이미지넷 데이터셋으로 pretraining, fine-tuning 하는 경우의 성능입니다. UCF101에서는 그렇지 못하지만 HMDB51 데이터셋의 경우 이미지넷에서의 pretraining 효과를 꽤나 보고 있는 것을 알 수 있었습니다. 또한 사전학습에 사용되는 데이터셋이 많을수록 효과가 늘어난다는 점도 참고할 수 있겠네요.
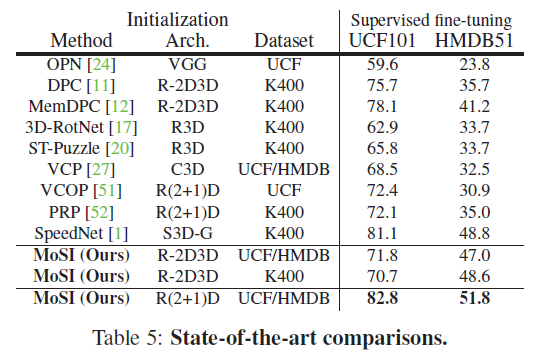
표 4는 SOTA 방법론들과의 벤치마크 표입니다. 왜 저자가 논문 상 가장 아래에 배치했는지는 모르겠지만, 우선 RGB 모달만을 사용하는 방법론들끼리의 성능을 비교하였습니다.
동일 조건으로 비교하였을 때 MoSI가 UCF101 데이터셋에서 DPC, MemDPD보다 안좋은 성능을 보이고 있는데, 실제로 같은 모델이라도 MoSI에서의 layer의 개수나 입력 해상도가 더 작고 낮아 성능이 낮다고 설명하고 있습니다. 동일한 구조로 실험한 결과가 있었으면 차이의 정도를 알 수 있었을 것 같은데 아쉽네요.
R(2+1)D backbone에서 각 데이터셋으로 pretraining 후 fine-tuning 하였을 때의 결과는 다른 방법론보다 높은 성능을 보이고 있기는 합니다만, 워낙 방법론마다 backbone 모델과 pretraining 데이터셋, 층 수나 입력 해상도가 모두 달라 쉽게 성능이 좋고 나쁨을 판단하기에는 어려움이 있을 것 같습니다.
4. Conclusion
최근의 Self-supervised video representation learning 논문들을 보면 벤치마크 테이블에서 나름 backbone 모델, layer 개수, 사용 메모리, 입력 해상도, 배치 사이즈 등 자세한 정보를 제공하여 비교하기 쉬워지긴 했지만, 21년도 논문이다보니 아직 제대로 정립이 되지 않은 듯한 느낌이 들었습니다.
아무튼 본 방법론의 장점은 video downstream task를 위해 라벨 없이 이미지 데이터 또한 활용할 수 있다는 것이라고 생각됩니다. 또한 모델이 motion을 명시적으로 학습하기 위해 pseudo motion을 만들겠다는 생각이 참신하였다고 느껴집니다.
이상으로 리뷰 마치겠습니다.
안녕하세요 김현우 연구원님. 처음 읽을때는 왜 굳이 이미지로 학습하지 싶었는데. 내용을 읽어보니 이미지 내에서 가짜 비디오를 만들어주는 셈이네요. 학습 방식은 새롭고 꽤 괜찮은 아이디어 같은 같은데요. 정작 성능은 좀 애매하네요. [표 4]의 실험 결과도 왜 UCF에서 성능이 오르지 않는지에 대한 분석이 없는데 이 부분 혹시 찾아보시고 내용 추가 가능할까요? 혹시 저자 분석이 없다면 현우님의 의견을 남겨주실 수 있나요?
사전학습을 UCF101 데이터셋으로, ImageNet 데이터셋으로 하는 경우 결국 성능은 UCF101로 fine-tuning 후 성능을 측정하기에 ImageNet으로 사전학습 한 경우 성능이 UCF 사전학습의 경우와 비슷하다는 점이 충분히 유의미하다고 생각합니다.
물론 말씀해주신대로 UCF101과 HMDB51 데이터셋에서의 fine-tuning 성능 경향이 조금 다르긴 하지만, 논문에서는 이를 ‘일반적으로 성능이 향상된다’라고 이야기하며 아예 경향성에 대한 언급을 하고 있지 않아 아쉽습니다.
리뷰 잘 읽었습니다.
뭔가 예시는 motion이 발생하는 부분만 window을 하여 해당 방법론이 꽤나 의미가 있는 것처럼 설명이 되어 있는데 개인적으로 의문이 드는 부분이
만약 예를들어 아무런 object가 없는 이미지에서도 해당 방법론은 적절한 representation을 얻을 수 있는지(아마 안될 것 같지만) 얻을 수 없다면 이러한 case를 어떻게 처리하는지 논문에 내용이 나와있는지 궁금합니다.
저도 논문을 읽는 과정에서 아무리 trimmed video에 대한 task를 수행하더라도, 확실한 콘텐츠를 포함하고 있는 이미지가 오히려 해당 방법론에 더욱 적합할 수도 있겠다는 생각을 하였습니다.
그러다보니 리뷰에 첨부한 표 3에서 이미지넷으로 사전학습하는 경우 HMDB51 데이터셋에서의 성능이 조금 더 높은 것을 확인할 수 있었습니다. 물론 한 비디오에서 하나의 프레임만 샘플링하기 때문에 데이터 개수 차이로부터 온 성능 차이일 수도 있겠지만, 비디오의 한 프레임을 샘플링했을 때 학습할만한 콘텐츠 존재 여부에 대한 불확실성을 고려한다면 어느정도 확정적으로 콘텐츠를 포함하고 있는 이미지 도메인의 데이터셋으로 사전 학습 가능하다는 점이 큰 contribution이라고 생각합니다.
논문에서 따로 프레임 내 콘텐츠를 따져 예외 처리를 해주는 경우는 언급되어있지 않습니다.