4월 한달 일정이 너무 바쁘다보니 오랜만에 x리뷰를 작성해보네요. 이번에 가져온 논문은 Style Transfer 관련 논문으로 내용이 상당히 재밌어보여서 가져와보았습니다. Style Transfer에 대한 지식이 없으신 분들은 제 예전 style transfer 논문 리뷰들을 참고하면 좋을 것 같습니다. 추천드리는 style transfer 리뷰로는 AdaIN을 보시면 좋을 것 같네요.
Intro
일단 Style Transfer의 task를 간략하게 소개드리면 해당 분야에서는 Image를 Style과 Content라는 개념으로 나누어 부릅니다. Style이라고 하는 부분은 영상의 전반적인 texture, color와 같은 색상에 해당하는 부분들을 의미하며, Content라는 개념은 영상 속 물체나 장면의 structure, shape 등 구조적 성분들을 의미하는 것이죠.
결국 해당 task는 Style Image와 Content Image가 각각 존재한다고 하였을 때, Content Image의 Content를 가지고 Style Imaeg에서 추출한 Style 정보를 자연스럽게 적용하고 싶은 것이 해당 논문의 목적입니다. 그리고 이러한 Style Transfer는 주로 ImageNet pre-trained VGG19를 활용해서 영상의 Style과 Content 정보를 추출 및 적용시키게 됩니다.
보통 Style Transfer 분야에서는 이러한 pre-trained VGG를 main objective function으로 사용하는 흐름이 2015년부터 지금까지 쭉 이어져왔었지만 사실 VGG는 상당히 오래된 CNN 모델 중 하나입니다. VGG network를 활용한 Perceptual loss가 2016년 나왔을 때 당시에만 해도 VGG가 상당히 정확하고 최신 백본 중 하나였기에 사용했던 것이지만, 현재 VGG보다 훨씬 더 좋은 백본들이 쏟아져 나온 상황에서도 Style Transfer 논문에서는 Style과 Content를 추출하는 모델로 VGG를 활용하고 있습니다.
무언가 이상하지 않나요? 보다 더 사실적이고 정교한 Style Transfer Image를 만들기 위해서는 영상에서 Style 성분과 Content 성분을 더 잘 표현하는 것이 중요할 것이며, 이러한 관점에서 VGG보다 더 좋은 backbone network를 활용하면 더 좋은 Style 및 Content 성분을 추출한다고 생각하는 것은 당연한 생각일텐데 말이죠.
사실 해당 분야를 연구하는 연구자들이 VGG 대신 다른 backbone을 통해 Perceptual Loss를 계산하지 않았던 것은 아닙니다. 일반적으로 VGG보다 더 좋은 classification 성능을 보여주는 backbone들 (예를들면 ResNet, InceptionNet, DenseNet 등등)을 VGG 대신 활용하여 Style Transfer Network를 학습하게 되면 예상과 달리 좋지 못한 결과가 생성됩니다.

그림1을 살펴보시면 ImageNet으로 사전학습된 VGG를 활용하는 것이 ImageNet으로 사전학습된 ResNet보다 더 Style Image의 특징들을 잘 반영하여 영상을 생성한 것을 확인하실 수 있습니다. 더욱 재밌는 점은 사전학습을 시키지 않고 random weight을 가진 모델에 대해서도 VGG는 더 그럴듯한 Style Transfer를 수행한 것을 정성적으로 확인가능합니다.
즉 위에 실험은 VGG가 ResNet보다 정교한 style transfer가 가능한 이유에 대해서 weight와 관계없이 두 모델 간에 네트워크 구조 차이로 인한 유의미한 성능 차이가 존재한다고 저자는 주장합니다. 저자는 이러한 모델 구조의 차이로 인한 style transfer 성능의 차이를 밝혀내기 위에 몇가지 실험을 진행하는데, 이 중 한가지는 ResNet 모델의 deep layer에서 추출된 feature map의 확률분포가 large peak을 가진다는 사실입니다.(즉 확률분포 값이 small entropy를 가지는 상황)
이러한 관측 결과가 의미하는 바는, 매우 소수의 feature channel이 전체 feature map의 분포를 지배하는 상황이 연출된다는 것이며 이는 곧 생성되는 영상이 Style Image의 대중적인 Style을 보는 것이 아니라 일부 스타일에 편향되는 현상이 발생한다는 것입니다. 즉 ResNet의 경우 Deep layer 단에 있는 style이 제대로 추출되지 못하며 이는 곧 테두리와 같은 high-level style pattern을 영상 합성시에 잘 반영하지 못한다는 것을 의미합니다.
반면에 VGG와 같은 backbone의 경우 모든 레이어에서 feature map의 채널들이 모두 일정한 확률 분포 값을 가지고 있었으며, 이는 곧 스타일의 다양성을 훨씬 더 많이 포착 가능하다는 것을 의미합니다. 저자는 이러한 관측을 기반으로 ResNet에서 peak가 발생하는 원인에 대해 분석하였으며 결과적으로 Skip Connection으로 인한 현상이라는 것으로 결론을 지었습니다.
Skip Connection은 ResNet 뿐만 아니라 VGG 이후에 많은 백본 연구들이 활용하는 구조적 특징 중 하나이기 때문에 Style Transfer에는 VGG를 제외한 대부분의 최신 백본들이 모두 비슷한 경향성을 보였던 것입니다. 결국 논문에서는 Residual Connection이라는 연산 방식이 Style Transfer에는 부적합한 방식이라는 결론을 내렸으며, 이러한 Residual Connection 연산이 있더라도 feature map의 분포가 peak되는 현상을 줄이기 위해 Stylization With Activation smmothinG(SWAG)라는 기법을 새롭게 제안합니다.
Preliminaries
그럼 구체적인 방법론에 대한 내용에 들어가기 앞서서 해당 논문에서 사용하는 수식 및 기본적인 Style Transfer의 흐름에 대해 가볍게 다루고 넘어가겠습니다.
어떠한 컬러 영상 x_{0}가 있다고 할 때 x_{0}를 어떤 CNN에 입력으로 넣어 추출된 특징은 [F^{l}(x_{0})]^{L}_{l=1}라고 부르겠습니다. 여기서 F^{l}(x_{0})은 W_{l} \times H_{l} \times D_{l} 를 가지지만 gram-matrix를 계산하기 위해서 차원 축 D는 유지한체 W와 M을 합치는 D_{l} \times M_{l} 꼴로 reshape이 가능합니다.(여기서 M은 WxM이겠죠)
그럼 이제 수식1과 같이 M 축끼리 서로 내적을 수행함으로써 Gram matrix를 계산하게 됩니다.
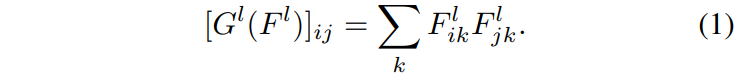
즉 요약하면 x_{0} 에 대해 CNN을 태워서 Feature map F_{l} 를 추출하고 이 Feature map에 대해서 Dimension 축과 Spaital 축(Width&Height) 으로 나누어 reshape을 한 뒤 Spatial 축끼리 서로 내적을 수행하여 최종적으로 Dimension 축 간에 Correlation을 계산한 D\times D 꼴의 행렬을 만든 것이 바로 gram matrix 입니다.
Gram matrix에 대해 조금 자세히 설명드린 이유는 이러한 gram matrix가 영상의 반복되는 패턴(즉 style 성분)을 표현한다고 하여 Style loss를 부과할 때 많이 사용되기 때문입니다. 결과적으로 Style Transfer 모델에는 Content에 관한 loss와 Style에 관한 loss로 나뉘어집니다.
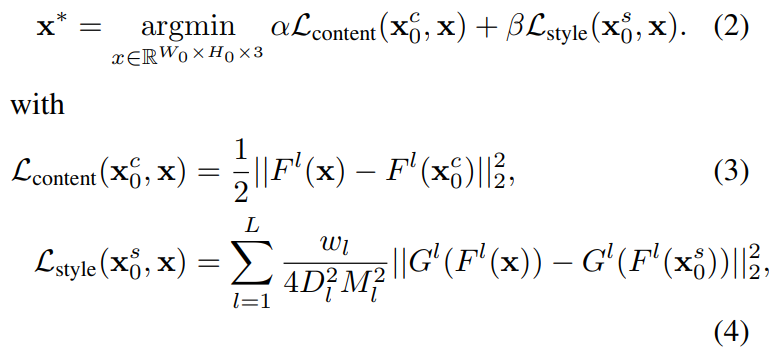
여기서 x^{c}_{0}, x^{s}_{0} 는 각각 Content Image와 Style Image를 나타냅니다.
Method
Importance of residual connection
먼저 논문에서는 VGG와 ResNet의 구조적 차이에서 비롯된 Style Transfer 결과를 분석하기 위해 VGG19와 ResNet50을 base-model로 활용하였으며, 각각 ImageNet으로 사전학습된 weight과 단순히 pytorch에서 모델을 선언했을 때 초기화되는 Random Init에 대한 실험들을 진행하였다고 합니다.(각각의 표기는 p-VGG, p-ResNet, r-VGG, r-ResNet으로 결정됩니다.)

먼저 그림2에서 p-VGG와 p-ResNet을 비교해보면 ResNet의 경우 매우 low level 수준의 color pattern만을 반영하여 영상을 생성한 것을 확인하실 수 있습니다. 이러한 차이는 pretrained model이 아닌 random weight인 경우 더 두드러지게 발생하는데, r-ResNet의 경우 Style transfer가 전혀 안되었다고 봐도 무방한 이미지를 생성하는 반면, r-VGG는 random weight임에도 불구하고 그럴듯한 수준의 stylization을 한 모습입니다.
저자는 이러한 원인을 찾기 위해서 많은 네트워크 구성 요소들(residual connection 사용 여부, 1×1~7×7까지의 kernel size 종류, 네트워크 깊이, batch norm 여부, maxpooling과 conv with stride2, 레이어 당 채널 수 등등)을 절제하여 실험하였으며 그 결과 Residual Connection이 이러한 현상을 만들어내는 주범이라는 것을 실험적으로 확인했습니다.

이러한 저자의 실험은 위에 그림3에서도 훨씬 더 잘 나타나게 됩니다. 먼저 용어 정리부터 들어가면 NoResNet은 ResNet 모델에 Residual Connection 연산을 모두 제거한 것을 의미하며, pseudo-VGG는 ResNet에 Residual 연산 외에도 VGG와 매우 유사하게 모델에 수정을 가한 버전(즉 maxpooling을 통한 사이즈 줄이기, bottleneck layer를 basicblock으로, 7×7 conv layer를 3×3으로 변경하기 등)을 의미합니다. 또한 pseudo-ResVGG는 pseudo-VGG에다가 다시 Residual Connection을 적용한 결과이며, 마지막으로 ResNet*은 논문에서 제안하는 기법(SWAG)를 적용한 결과를 의미합니다.
일단 재밌는 점은 ResNet에 Residual Connection을 제거하게 되니 그림-2 r-VGG와 유사하게 영상의 Style을 잘 녹인 것을 확인할 수 있었습니다. 또한 VGG 모델과 매우 유사하게 세부적인 구조 디테일도 변경한 pseudo-VGG의 경우 더더욱 r-VGG와 유사한 결과를 생성할 수 있게 됩니다. 하지만 Residual Connection의 유무에 따른 결과와 비교하였을 때는 마이너한 변화로 볼 수 있습니다.
이것에 대해서 보다 명확하게 판단하기 위해 저자는 pseudo-VGG에서 다시 Residual Connection 연산을 추가한 결과를 보였으며(pseudo-ResVGG) 보시면 아시다시피 style이 전혀 반영되지 않고 content image와 거의 유사한 결과를 가지고 있음을 확인할 수 있습니다. 이러한 결과를 토대로 VGG와 ResNet에 수많은 구조적 차이 중 Residual Connection의 유무가 상당히 큰 영향력을 준다고 저자는 주장합니다.
Why do residual connection degrade performance?
그렇다면 Residual Connection 연산이 추가될 때 왜 Style Trasfer가 잘 되지 않을까요? 저자는 이러한 원인을 분석하기 위해서 Feature map과 gram matrix에 대한 통계학적 요소들을 확인하고자 하였습니다. 보다 구체적으로는 10장의 이미지를 입력으로 넣어 네트워크의 stage 맨 마지막 layer에서 추출한 feature map과 gram matrix에 대하여 최대값과 normalized entropy의 평균 값을 계산하였으며 그 결과는 아래와 같습니다.
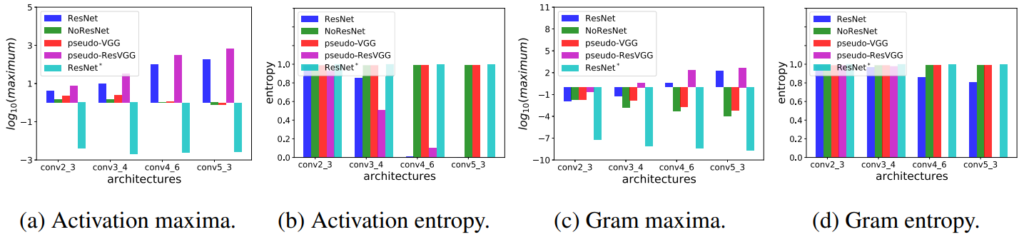
아직 각 그래프에 대해 설명을 드리지는 않았지만 한눈에 봐도 경향성이 크게 달라지는 것을 확인하실 수 있을 것 같습니다. 먼저 maxima 부분에 대해서 살펴보면 early stage에 대해서는 모든 네트워크 구조들이 2미만에 값을 지니지만, 레이어가 점점 깊어질수록 ResNet과 pseudo-ResVGG(i.e., Residual Connection이 존재하는 모델)의 max 값이 매우 큰 폭으로 커지는 것을 볼 수 있습니다. 반면 Residual Connection 연산이 없는 NoResNet과 pseudo-VGG의 경우에는 0에 가까운 값을 지니고 있구요.
이러한 현상은 gram matrix에도 마찬가지입니다. layer가 점점 깊어질수록 ResNet과 pseudo-ResVGG는 더 큰 값을 가지게 되지만, 그 외에 다른 모델들은 음수에 해당하는 작은 값들을 지니게 됩니다. 이러한 maxima 값이 커지는 것은 모델들의 경우 entropy 값의 경우 거의 0에 해당하는 것을 볼 수 있습니다. 이는 10장의 영상에 대해서 모두 특정 채널의 값만이 peak인 확률 분포를 지니고 있기 때문에 entropy 값 역시 0에 가까운 것을 의미합니다.
반면에 Residual Connection이 없는 모델들의 경우 모든 채널에서 비슷비슷한 확률 분포 값을 가지고 있기 때문에, 엔트로피 값이 크게 나타나게 됩니다. 이러한 entropy 값이 중요한 이유가 무엇이냐면, 결국 gram matrix는 자기 자신의 feature에 대해서 채널축에 대한 내적 계산을 통해 correlation을 계산하게 됩니다.
이 때 특정 번째의 채널 값이 과도한 값을 가지게 된다면 gram matrix 안에도 특정 채널번째 값이 큰 값을 가지게 될 것이며, 수식(4)에서 reference style imaeg와 stylized imaeg에 대한 gram matrix가 서로 같아지도록 하는 계산하는 l2 loss 관점에서 저러한 큰 값을 지니는 outlier에 상당히 편향되도록 학습이 될 수 밖에 없습니다. 또한 보통 gram matrix에서 발생하는 peak 값은 i채널과 j채널이 서로 다른 상황이 아닌 서로 같은 상황(i==j)일 때가 대부분이기에 모델은 스타일 correlation을 배우는 것이 아닌 자기 자신의 스타일을 닮도록 편향되는 것이죠.
결국 요약하자면 특정 채널이 과도하게 값이 커지고, peak에 달성하는 현상들은 모델이 특정 채널과 correlation pattern에 과도하게 지배되거나 편향되는 결과값을 유발할 수 있게 됩니다.
Why are residual network activations and Gram matrices peaky?
그렇다면 Residual Connection이 왜 Feature map과 Gram matrix를 peaky peaky하게 만들까요? 이에 관해 알기 위해서는 먼저 Residual Connection이 어떤식으로 구현되는지를 확인해볼 필요가 있습니다.
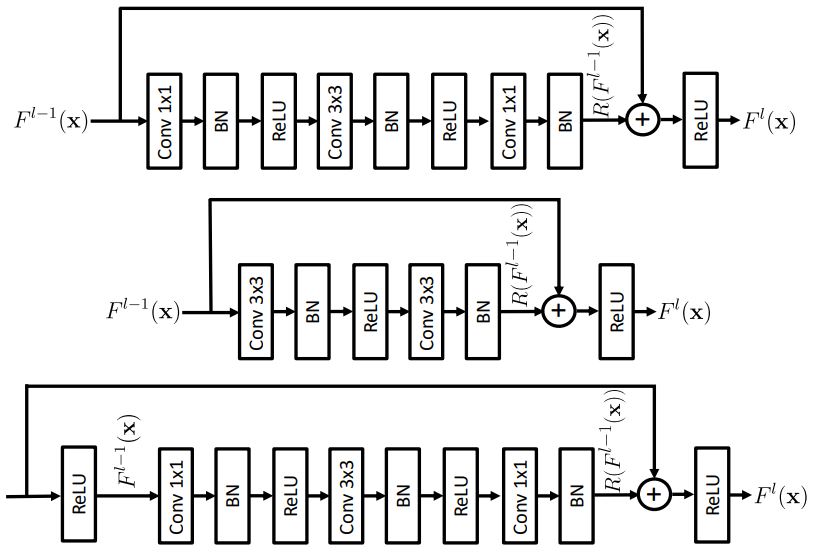
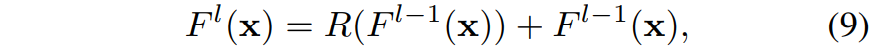
일반적으로 Residual Connection은 그림 5와 수식 9처럼 볼 수 있듯이, 어떠한 컨볼루션-batch norm-ReLU 의 조합으로 구성된 block을 타고 나온 결과 값과 해당 블록의 입력 값 끼리 element-wise로 더해주는 방식으로 구현됩니다. (참고로 여기서 R은 Conv-BN-ReLU의 나열을 의미합니다.)
보다 구체적으로는 수식 10과 같이 Batch Norm과 ReLU 사이에서 Residual Connection 연산이 적용되게 되는데 이 부분이 peaky한 결과값을 내도록 하는 원인이라고 저자는 주장합니다.
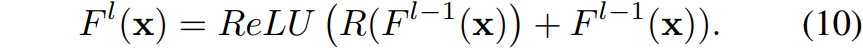
만약 F^{l-1}(x) 가 ReLU를 타고 나온 결과값이라면, 해당 값은 0 이상의 positive value 값만을 지니고 있으며, R(F^{l-1}(x))의 경우는 실수 값을 가지게 될 것 입니다. 여기서 이제 저자는 F^{l}(x) 값이 peaky한 상황이 발생하는 방향을 2가지로 가정하는데, 첫째는 R(F^{l-1}(x))의 값이 peaky한 결과를 생성하는 경우이며 2번째는 이미 F^{l-1}(x) 가 peaky한 결과값을 가졌다는 가정입니다.
결국 peaky한 상황을 제거하기 위해서는 element-wise 연산 시에 positive value에 negative value가 더해짐으로써 상쇄해주는 역할을 수행해야만 하지만, ReLU operation으로 인하여 peak를 상쇄할만한 negative value들은 모두 0 혹은 0에 가까운 값들을 지니기 때문에 layer가 점점 깊어질수록 peaky한 현상이 더 심해진다는 것입니다.
그래서 저자는 이러한 현상을 구조적으로 막기 위해서는 그림 5의 맨 마지막 케이스처럼 Residual 연산에 활용할 F^{l-1}(x) 가 ReLU를 타기 이전 값을 활용하는 방법이 있다고 합니다. 이는 ReLU를 적용하기 전이므로 negative와 positive를 모두 담고 있는 실수 값을 지니기 때문에 R(F^{l-1}(x))와 함께 더할 때 peak한 채널들을 상쇄시킬 수 있다고 합니다.
하지만 이러한 모델 구조는 Image classification 관점에서 매우 부적합하다는 것을 실험적으로 확인했습니다. 모델 구조를 변경하여 CIFAR100에 대한 학습을 돌려보았더니 기존 ResNet이 77% 정확도를 달성한 반면 변경된 구조의 ResNet은 65%의 성능을 달성하였다고 합니다. 게다가 설령 이러한 구조 변화가 Style Transfer에 좋은 영향을 준다고 하더라도, classification과는 다른 모델에서 비롯된 결과이기 때문에 결과적으로 논문의 원래 목적(Classification에서는 잘 동작하는 진보된 모델이 왜 Style Transfer 분야에서는 잘 동작하지 못할까?)과는 동떨어진 해결책이게 됩니다.
그래서 저자는 모델의 구조 변경 없이 stylization을 성공적으로 수행할 수 있는 방법에 대해서 탐구합니다.
Stylization With Activation Smoothing(SWAG)
본 논문에서 제안하는 방식은 상당히 간단합니다. 바로 softmax 기반의 smoothing transformation을 통해서 low entropy를 발생시키는 peaky activation을 완화시키겠다는 것이죠.
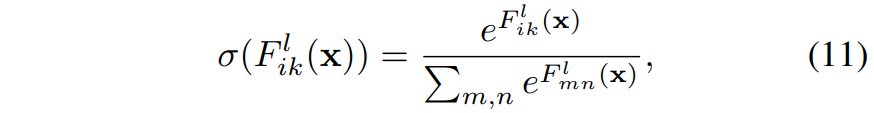
참고로 저자는 Softmax layer를 네트워크 구조 안에 삽입하자는 주장을 하는 것이 아닙니다. 그렇게 되면 모델의 구조를 바꾸게 되는 것이니 그런 방식이 아닌 수식(2)을 통해 content와 style에 대한 loss를 계산하기 위하여 모델에서 추출된 feature map에 softmax 연산을 적용하자는 것입니다.
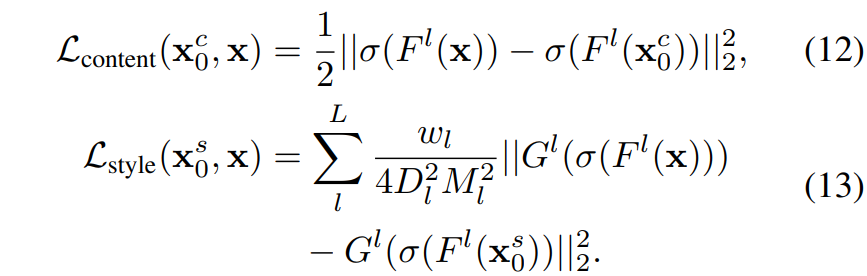
Softmax 연산은 Large peak value는 감소시키고, small value에 대해서는 increase 해줌으로써 보다 분포가 획일적으로 해주는 성질이 있습니다. 저자는 단순히 수식12,13과 같이 softmax 연산을 붙이는 행위 자체를 Stylization With Activation smmothinG(SWAG)라는 거창한 명칭?을 붙여서 얘기합니다.
이러한 SWAG 기법을 적용하였을 때 생성된 결과는 그림3에서 확인하실 수 있습니다. 분명 ResNet의 경우 Stylization이 잘 되지 않았는데 loss function 계산 시에 정규화를 해준 것만으로도 상당히 큰 변화를 보여주는 것을 확인할 수 있습니다.
Experiments
사실 style transfer 쪽 논문은 실험 결과라고 해봤자 정성적 결과를 보여주는 것 말고는 크게 증명할 부분이 없을 것 같습니다. 게다가 본 논문은 method의 과정 자체에서 다양한 ablation 실험을 했기 때문에 본 논문에서 제안하는 contribution에 대한 ablation 역시 크게 다룰 부분이 없구요. 따라서 다양한 백본 모델에 대해 기존 버전과 SWAG를 적용한 것에 대한 정성적 결과를 끝으로 리뷰 마무리 짓도록 하겠습니다.

위에 그림은 ResNet, Wide-ResNet(W), InceptionNet(GoogleNet)에 대한 결과를 나타낸 것입니다. 보시면 ResNet과 Wide ResNet의 경우 low-level의 style을 잘 입히지만 조금 더 넓은 의미에 style을 잘 입히지 못하지만, SWAG을 적용시키게 될 경우 조금 더 semantic하고 high-level에서의 style을 잘 반영하는 모습입니다. 근데 사실 이게 너무 주관적이어서 크게 와닿지 않을 수도 있겠네요.
결론
문제 정의, 이를 해결하기 위한 접근 방식, 그리고 제안하는 방법의 단순함이 이 논문의 큰 장점이 아닌가 싶네요. 하지만 절제 실험할 때에서는 마치 ResNet을 통해 Stylization을 하면 전혀 안되는 것처럼 묘사하더니 맨 마지막 정성적 결과에서는 어느정도 Style이 잘 변환된 것을 보니 조금 cherry pick이 있는 것이 아닌가.. 문제 정의할 때 해당 문제에 대해 너무 과하게 해석한 것이 아닐지 생각이 좀 듭니다.
안녕하세요, 신정민 연구원님, 좋은 리뷰 감사합니다. 요즘 생성AI에 대해 다룬 뉴스를 보면서 style transfer에 대해 접하게 되었는데, 마침 이와 관련된 리뷰가 있어서 관심있게 읽어보게 되었습니다. 리뷰를 다음과 같이 요약해 보았는데, 올바르게 요약한 것인지는 잘 모르겠습니다..
1. Style transfer는 Image를 content와 style로 나누어 보는 관점에서, 각 영상(content)과 style을 입력하면 영상이 스타일에 맞게 변형되는 것입니다.
2. 초반에야 VGG backbone model이 최신 모델이어서 VGG를 사용했지만. 더 우수한 backbone이 많이 나온 최근에도 style transfer에는 VGG를 사용합니다. 이는 예상과 달리 최신 모델들이 그리 좋은 성능을 보여주지 못했기 때문입니다.
3. 저자의 주장에 따르면, 이는 VGG가 모든 layer의 feature map의 채널들이 모두 일정한 확률분포를 갖고 있어 전체적인 스타일을 모두 포착할 수 있기 때문입니다. ResNet은 deep layer의 feature map distribution이 large peak를 가지기 때문에 스타일을 전체적으로 보지 못하고 편향적으로 반영합니다. 저자는 Peak의 원인으로 skip connection을 지목합니다. skip connection은 VGG이후 많은 모델의 공통 구조적 특징이기 때문에 이들 모델에서 동일한 문제를 야기합니다.
4. 저자는 실험적으로 문제의 원인이 residual connection 이라는것을 확인합니다.
5. 그 다음으로 residual connection 연산이 추가될 때 왜 style transfer가 잘 되지 않는지 분석합니다. 특정 채널이 과도하게 값이 커지고, peak에 달성하는 현상들은 모델이 특정 채널과 correlation pattern에 과도하게 지배되거나 편향되는 결과값을 유발할 수 있게 됩니다. 이는 ReLU operation으로 element-wise 연산 시 peaky한 상황을 제거해 줄 negative value가 사라지기 때문입니다. 모델 구조를 변경하는것은 좋지 못하기 때문에 저자는 다른 방법을 탐구합니다.
6. 본 논문에서는 softmax 기반의 smoothing transformation을 통해 low entropy를 발생시키는 간단한 방법을 제안합니다. 네트워크 구조 안에 softmax를 삽입해서 구조를 바꾸는 것이 아닌, content&style에 대한 Loss를 계산하기 위해 모델에서 추출된 feature map에 softmax를 적용하는 것입니다. 정성적으로 개선 결과를 확인 할 수 있습니다.
style transfer에도 정량적으로 성능을 확인할 수 있는 지표가 제시 되었다면 개선 사항을 더 객관적으로 확인할 수 있었을 텐데, 정성적으로만 확인할 수 있어서 아쉬웠습니다. 리뷰를 읽다보니 궁금한 점이 생겨 질문 남깁니다.
1. style transfer에는 content와 style에 대해 나눠서 loss를 계산하는 것으로 보이는데, 어떻게 한 이미지 안에서 content와 style을 추출하는건지 궁금합니다. 각 task에 알맞은 Filter를 별개로 사용하는 것인가요?
2. style transfer에서는 그럼 content와 style에 따른 수많은 input image가 따로 필요한건지 궁금합니다.
3. 논문 내용과 직접적인 질문은 아니지만 마지막에 말씀하신 cherry pick이 무슨 의미인지 궁금합니다.
4. 뉴스에서 스타일 전이를 생성AI와 함께 소개하는 것을 본 적이 있는데, 생성모델과 스타일 전이에 관계가 있는 것인가요?
감사합니다.
제 리뷰에 많은 관심 가져주셔서 감사합니다. 최대한 문답 형식으로 답글을 달아보았으니 쭉 읽어보시면 좋을 듯 합니다.
1. Style transfer는 Image를 content와 style로 나누어 보는 관점에서, 각 영상(content)과 style을 입력하면 영상이 스타일에 맞게 변형되는 것입니다.
–> 좋습니다.
2. 초반에야 VGG backbone model이 최신 모델이어서 VGG를 사용했지만. 더 우수한 backbone이 많이 나온 최근에도 style transfer에는 VGG를 사용합니다. 이는 예상과 달리 최신 모델들이 그리 좋은 성능을 보여주지 못했기 때문입니다.
–> 네네 보다 구체적으로는 Classification과 같은 인식 분야에서는 좋은 성능을 보여주는 최신 백본들이 Style Transfer에는 좋은 성능을 보여주지 못했다고 보시면 됩니다.
3. 저자의 주장에 따르면, 이는 VGG가 모든 layer의 feature map의 채널들이 모두 일정한 확률분포를 갖고 있어 전체적인 스타일을 모두 포착할 수 있기 때문입니다. ResNet은 deep layer의 feature map distribution이 large peak를 가지기 때문에 스타일을 전체적으로 보지 못하고 편향적으로 반영합니다. 저자는 Peak의 원인으로 skip connection을 지목합니다. skip connection은 VGG이후 많은 모델의 공통 구조적 특징이기 때문에 이들 모델에서 동일한 문제를 야기합니다.
–> 무언가 ChatGPT가 요약해준 듯한 느낌이 들정도로 요약을 잘 하셨군요:)
4. 저자는 실험적으로 문제의 원인이 residual connection 이라는것을 확인합니다.
5. 그 다음으로 residual connection 연산이 추가될 때 왜 style transfer가 잘 되지 않는지 분석합니다. 특정 채널이 과도하게 값이 커지고, peak에 달성하는 현상들은 모델이 특정 채널과 correlation pattern에 과도하게 지배되거나 편향되는 결과값을 유발할 수 있게 됩니다. 이는 ReLU operation으로 element-wise 연산 시 peaky한 상황을 제거해 줄 negative value가 사라지기 때문입니다. 모델 구조를 변경하는것은 좋지 못하기 때문에 저자는 다른 방법을 탐구합니다.
–> 네네 모델 구조를 변경하는 것은 Style Transfer에는 좋은 성능을 보여주지만 인식 등 다른 분야에서는 좋지 못한 성능을 보여주기에 활용도가 떨어지기도 하고, 본 논문에서 원하는 해결 방식이 아닙니다.(인식 분야에서 잘 동작하는 최신 모델이 Style Transfer에 잘 모두 잘 동작하도록 하는 것)
6. 본 논문에서는 softmax 기반의 smoothing transformation을 통해 low entropy를 발생시키는 간단한 방법을 제안합니다. 네트워크 구조 안에 softmax를 삽입해서 구조를 바꾸는 것이 아닌, content&style에 대한 Loss를 계산하기 위해 모델에서 추출된 feature map에 softmax를 적용하는 것입니다. 정성적으로 개선 결과를 확인 할 수 있습니다.
–> 정정해줄 부분이 있다면 smoothing transformation을 통해서 low entropy를 발생시키는 것이 아닌 high entropy를 발생시키게 됩니다. entropy가 더 큰 것이 확률분포 상으로는 uniform한 상황을 의미하기 때문입니다. 그림4에서 Resnet*의 entropy 부분을 살펴보시면 값이 1에 가까운 것을 확인하실 수 있을 겁니다.
style transfer에도 정량적으로 성능을 확인할 수 있는 지표가 제시 되었다면 개선 사항을 더 객관적으로 확인할 수 있었을 텐데, 정성적으로만 확인할 수 있어서 아쉬웠습니다. 리뷰를 읽다보니 궁금한 점이 생겨 질문 남깁니다.
–> 그 부분은 저도 동감합니다만 아쉽게도 style transfer 분야 자체가 세상에는 존재하지 않는 영상을 만든 것이기 때문에 GT라는 개념이 존재하지 않게 됩니다. 그럼에도 불구하고 정량적 수치를 나타내는 방식이 일부 존재하는 것으로 알고는 있으나 사실 그리 신뢰할만한 지표는 아니기 때문에 해당 분야에 대한 결과를 살펴보실 때는 비판적으로 보시는 편이 좋긴 합니다.
1. style transfer에는 content와 style에 대해 나눠서 loss를 계산하는 것으로 보이는데, 어떻게 한 이미지 안에서 content와 style을 추출하는건지 궁금합니다. 각 task에 알맞은 Filter를 별개로 사용하는 것인가요?
–> content와 style은 각각 수식 3번과 4번을 보시면 알 수 있을 듯 합니다. ImageNet으로 사전 학습된 모델 혹은 random weight으로 초기화된 CNN 어떤 것이든 상관없이 RGB 영상을 입력으로 넣어서 Feature map을 추출하였다면, 이 추출된 HxWxD의 Feature map 자체를 content, 해당 Feature map에 대한 Gram matrix를 계산하면 이를 Style로 보게 됩니다. 혹시나 하는 마음에 보다 자세한 설명을 드리면, 이 논문에서 말하는 VGG, ResNet 등의 백본들은 Image를 생성하기 위해 사용하는 Encoder가 아닙니다. 영상을 변환시키는 Encoder-Decoder 형식의 Generator는 따로 있고 모델 학습을 위해 계산하는 loss 값을 구하는 과정에서 VGG로 추출한 Feature map을 쓸지, ResNet으로 추출한 Feature map을 쓰는지에 따라서 성능 차이가 발생하고 이를 해결하려고 하는 논문입니다. 해당 질문이 나온 배경이 혹시나 이 논문에서 집중하는 VGG와 ResNet의 차이를 영상 변환에 활용되는 encoder backbone에 대한 실험으로 착각하셨을까봐 추가로 더 설명드립니다.
2. style transfer에서는 그럼 content와 style에 따른 수많은 input image가 따로 필요한건지 궁금합니다.
–> Style Transfer는 2가지 학습 방식이 있습니다. 하나는 입력 Image 자체를 학습시키는 방법, 다른 하나는 Style Transfer Network 자체를 학습시키는 방법으로 말이죠. 후자는 일반적으로 저희가 생각하는 CNN 모델을 학습시키는 방법이기 때문에 직관적으로 이해하실 수 있으나, 전자의 영상을 학습하는 방식은 상당히 낯설게 느껴지실 겁니다. 쉽게 생각하면 Content Image 한장과 Style Image 한장이 있다면 두 영상의 각각의 content, style 성분을 뽑아서 융합되는 새로운 영상 자체를 학습하는 것입니다. 이는 최종 생성 영상 그 자체를 어떤 미분 가능한 2D feature map이라고 생각하면 조금 더 쉽게 이해하실 수 있을 것 같습니다. 결과적으로 영상을 학습하는 방식은 style과 content 각각 한장에 대해서 가능하며 네트워크를 학습시키는 방식은 수 많은 content와 style image가 필요로 할 것입니다. 이에 대한 추가적인 설명은 제 리뷰 맨 위에 ADAIN 리뷰의 앞부분 참고 부탁드립니다.
3. 논문 내용과 직접적인 질문은 아니지만 마지막에 말씀하신 cherry pick이 무슨 의미인지 궁금합니다.
–> 말 그대로 자기한테 유리한, 필요한 것들만 선별하는 행위를 의미합니다. 논문의 장점을 어필하기 위해 남들은 잘 못만들었지만 자신이 제안하는 방법은 더 강인하고 그럴듯하게 만든 상황들을 선택해서 논문에 정성적으로 보였다는 것이죠. 마치 본인의 방법론이 매우 대단한 방법론인 것처럼 보이도록 말이에요.
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=gud0415&logNo=221211432153
4. 뉴스에서 스타일 전이를 생성AI와 함께 소개하는 것을 본 적이 있는데, 생성모델과 스타일 전이에 관계가 있는 것인가요?
–> 비슷하면서 다릅니다. 생성 모델은 예전에 유행하던 GAN 기반 방식, 혹은 요새 유행하는 Diffusion 방식 등등 여러가지가 있지만, Style Transfer는 학습하는 loss function 자체도 다르고, 학습에 사용되는 input도 content와 style 2가지의 reference image가 필요하다는 점에서 차이가 존재합니다.(GAN이나 diffusion 방식등은 conditional image라고 해서 한장의 content image만을 넣거나 혹은 영상 + text 단위로 조합해서 영상을 생성하죠)
답변을 천천히 읽어 보니 많은 공부가 되었습니다 상세한 답변 감사합니다!
안녕하세요. 좋은 리뷰 감사합니다.
우선.. 레퍼런스로 링크주신 이전 리뷰도 읽고 본 논문의 리뷰도 읽었는데, ‘이 부분이 뭐지..?’ 싶은 것을 미리 디펜스 하듯 아래에 모든 설명이 있어 사실 논문을 다 읽고 나니 본 논문에 대한 질문이 없어져버렸습니다.
따라서.. 본 논문과 Style Transfer라는 Task를 연결지어 하나 궁금한 점으로, 그렇다면 본 태스크에서는 Correlation을 계산하는 방식이 Channel 축 간의 Correlation 계산 방법밖에 존재하지 않나요?
사실 질문거리가 많았다가.. 리뷰를 읽으며 잘 이해되어버렸습니다. 감사합니다.
네네 정확히는 correlation을 계산하고 싶다기 보다는 영상에서 스타일이라는 정보를 어떻게 추출할 수 있는가?에 집중하시면 될 것 같습니다.
영상에서 컨텐츠 정보라는 것은 전반적인 scene structure, object shape 등을 의미하지만 style이라고 하는 것은 어떻게 표현할 수 있을지 사실 좀 모호한 부분이 많거든요.
그래도 일단 style이라고 하는 것은 영상 속에 반복되는 패턴이나 질감 등을 나타낸다고 생각한다면 채널축에 대한 correlation을 계산하여 공간적 정보는 모두 날려버리고 채널들간에 상관관계 계산을 통해 나타나는 경향성, 확률 분포 등이 style 분포일 것이다 라고 생각하시면 될 것 같습니다.