Introduction
오늘도 Video representation learning에 관한 논문을 들고왔습니다. 서론은 이제 너무 많이 이야기해서 중복이니까 빼고… 본론으로 바로 넘어가겠습니다. 궁금하신 분들이 있다면 제 이전 리뷰를 참고하시면 좋을 듯 합니다.
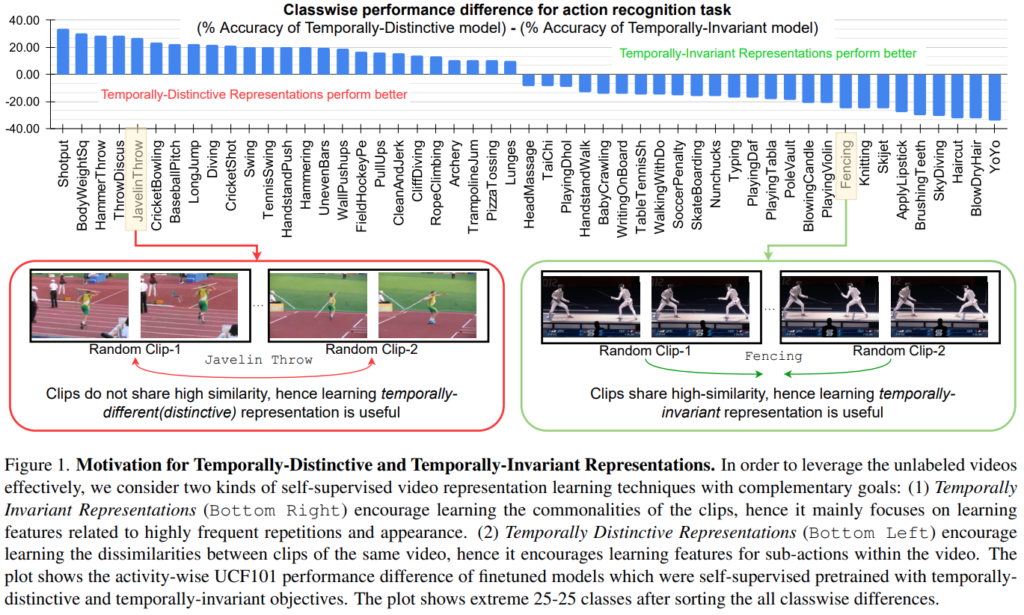
비디오에서 시간적인 정보는 매우 중요합니다. 짧은 비디오도 있지만, 긴 비디오도 있기 때문에 앞뒤 정보를 잘 활용하는 것은 매우 중요한데요. 그래서 Temporal한 Augmentation으로 해당 Task를 해결하려는 노력들이 꾸준히 있어왔습니다. 이 논문에서는 그러한 노력에 정량적인 분석을 가미했는데요. [그림 1]이 그 결과입니다.
결과를 보면, 클래스별로 평균 정확도에서 얼마나 차이나는지를 통해서 비교를 수행했는데요. 이건 비디오 내의 프레임들 끼리 시각적인 차이가 클때와, 유사할때의 경향성에 따른 분석입니다. 결과를 보면 오른쪽 절반을 차지하는 모델은 시각적인 차이가 크지 않죠? 이건 Temporally-invariant representation이 의미있는 클래스들 입니다. 반대쪽 절반은 이제 Temporally-distintive representation이 의미있는 클래스들인데요. 단순하게 이 결과만으로 이렇게 생각하는건 아니고 특정 action의 특성을 고려 했을 때, 반복이 많은 액션과 아닌 액션이 있기 때문에 이런 결과가 나왔다고 하네요.
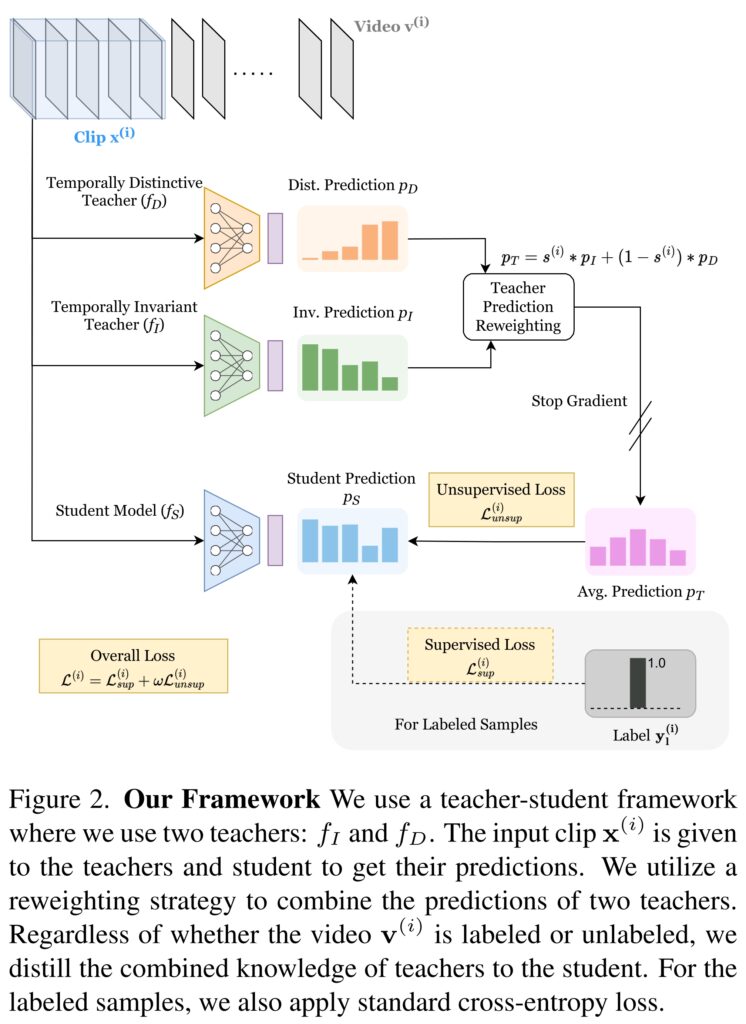
그럼 이 결과를 생각해보면 결국 Task를 크게 2가지로 분류할 수 있기 때문에, temporally-invariant한 표현력과 temporally-distintive한 표현력을 동시에 학습하는 것을 목표로 하는 모델을 만들면 되겠다는 결론을 내릴 수 있습니다. 그리고 이 결론을 달성하는게 이 논문에서 제안하는 teacher-student 기반의 semi-supervised 프레임워크입니다. Teacher 모델은 각각 temporally-invariant / temporally-distintive을 지도 학습한 모델이고, Student 모델은 비지도학습으로 구성되어, 전체적인 프레임워크는 semi-supervised가 됩니다. (자세한 학습 방식은 뒤에서 설명)
아무튼 그래서 Contribution을 정리해보면 아래와 같습니다.
- Temporally-Invariant와 Temporally-Distinctive의 표현력을 상호보완적으로 학습할 수 있는 두개의 티쳐 모델로 구성된 semi-supervised learning 프레임워크 제안
- 시간적 유사도 기반 reweighting 방법론을 통해, 라벨링 되지않은 비디오 객체들의 각각의 표현력을 재조정 할 수 있게 됨
- SOTA
Method
지도학습에서 사용할 데이터셋과 아닌 데이터셋에서 차이가 있는데요. 라벨을 가지고 학습하는지 아닌지에 따라 차이가 있어서 구분을 합니다. ↁ_l = \{(v^{(i)},y^{(i)})\}^{N}_{l}i=1 이 경우에는 지도학습에서 사용하는 라벨링 데이터셋으로 v와 y는 각각 해당 라벨의 i번째 비디오입니다. 그리고 ↁ_u = \{v^{(i)}\}^{N_u}_{i=1}의 경우에는 비지도 학습에서 쓰는 unlabeled 데이터셋입니다. 여기서 unlabeled 데이터셋의 크기가 더 커야해서 N_u \gg N_l라는 조건이 붙어있습니다.
Self-supervised pretraining of teachers
특정 비디오에서 연속되는 비디오 클립 \chi^{(i)} = \{x_t^{(i)}\}^n_{t=1}를 추출한 다음, 이 클립에 stochastic transformations (확률적인 수치로 결정해서 data augmentation 할 수 있는 것들을 뜻합니다.)을 적용합니다. 그런 다음에 각각의 teacher model f와 non-linear projection head g에 각각 해당 클립을 입력으로 태웁니다. 그런 다음 output z를 통해 Loss를 계산해 학습을 하는 방식인데요. Teacher 모델이 2개가 있어서 각각 어떤식으로 학습하는지 설명하겠습니다.
Pretraining of Temporally-Invariant Teacher
Temporally-Invariant하다는 뜻을 [그림 1]을 보면 잘 알 수 있습니다. 프레임들끼리 유사하다는 의미인데요. 그래서 Temporally-Invariant한 표현력을 학습하기 위해서는 유사한 프레임의 유사도를 높히고, 유사하지 않은 프레임의 유사도를 낮추는 방향으로 학습을 하면 됩니다.
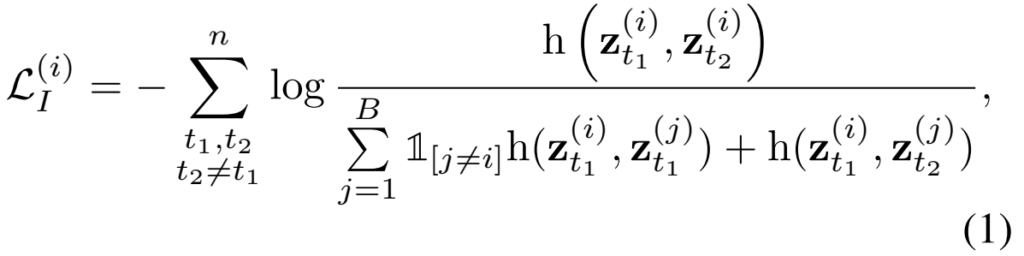
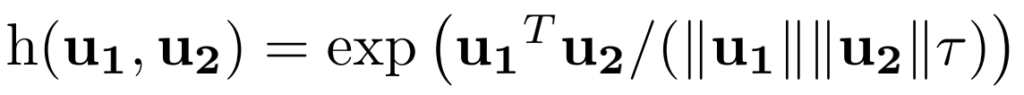
이를 위해서 같은 비디오에 해당하는 클립 (i)와 다른 비디오의 클립 (j)를 [수식 1]과 같이 Contrastive learning을 수행해주는데요. 논문에서는 agreement와 disagreement로 표현하고는 있지만 h를 보시면 아시겠지만 결국 유사도 계산이고, 수식 자체는 infoNCE Loss라서 감안해서 같이 보면 될 것 같습니다.
Pretraining of Temporally-Distinctive Teacher
Temporally-Distinctive한 표현력은 한 비디오내에서 여러 클립들의 차이를 학습하는 과정인데요. 사실 전반적인 과정이 약간 naive한 것 같은데, 최종적으로는 distintive한 클립의 표현력을 조금 더 향상시키기 위한 방향으로 학습을 진행한다고 생각하면 될 것 같습니다.
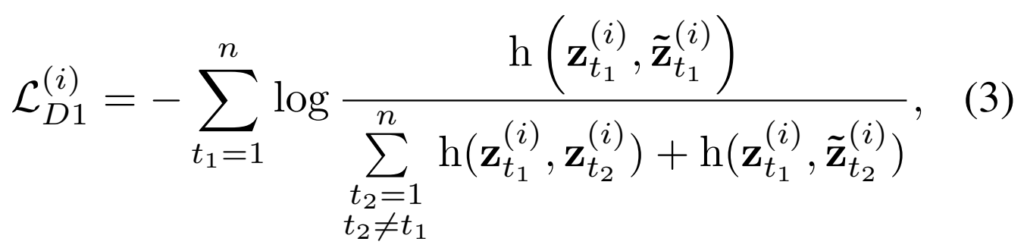
Loss는 [수식 3]과 같이 구성이 되는데요. 앞선 [수식 1]과 가장 큰 차이는 같은 비디오의 클립끼리만 학습을 수행하는 것과 어떤 시간대에서 뽑아오는지에 대한 차이점이 있고, \hat{z}로 표기된 augmentation된 클립을 사용한다는 차이점이 있습니다. 메인 페이퍼에는 빠져있는데, 사실 이렇게만 구성되는 것이 아니고 D2 Loss가 존재하는데요.
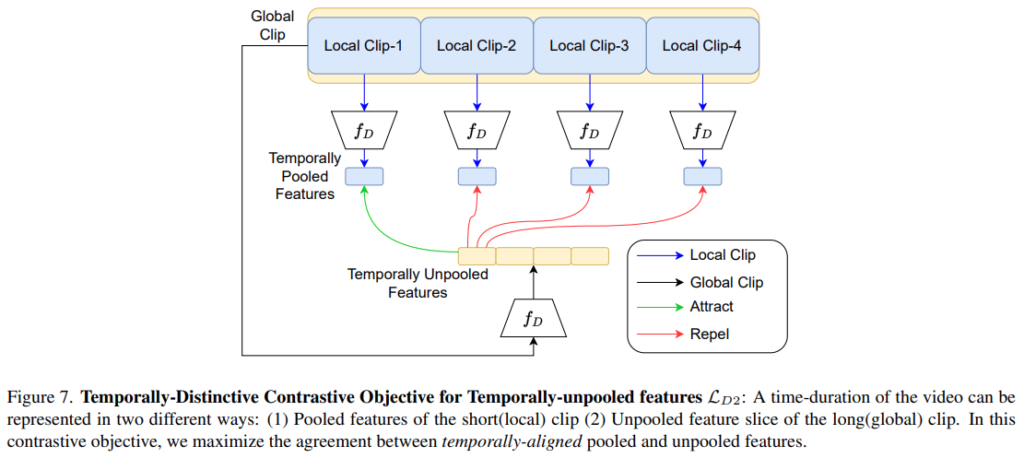
사실 이부분 처음 읽었을때는 이해가 안갔는데. 자세히 읽어보니 설명이 많이 빠졌더라고요. 기본적인 내용은 TCLR 이라는 선행연구를 따라 수행되었다고 보시면 됩니다. (물론 제가 TCLR을 안읽어서 없는 내용을 채우긴 했는데 틀릴 수 있음) 논문에서 그런 말이 없지만, [그림 7]과 TCLR 모델을 보면 MLP Layer와 Projection Layer 사이에 Temporal Pooling Layer가 있는데요. 이 Layer를 거치기 때문에 D1 Loss는 Temporally-pooled feature로 학습한 결과가 되면서 특정 구간(클립)의 정보만을 가지게 되죠. D2 Loss는 보다 더 넓은 범위(클립들)의 feature를 MLP Layer의 입력으로 사용하여 보다 global한 정보를 가지게 됩니다. 이런 방식으로 Temporal Pooling Layer 적용 유무 feature들을 모두 이용하여 Loss를 구성합니다. 정확하게는 L_D^{(i)} = L_{D1}^{(i)}+L_{D2}^{(i)}로 각각 Loss를 계산하고 더해서 최종 Loss를 만듭니다.
Semi-supervised training of student model
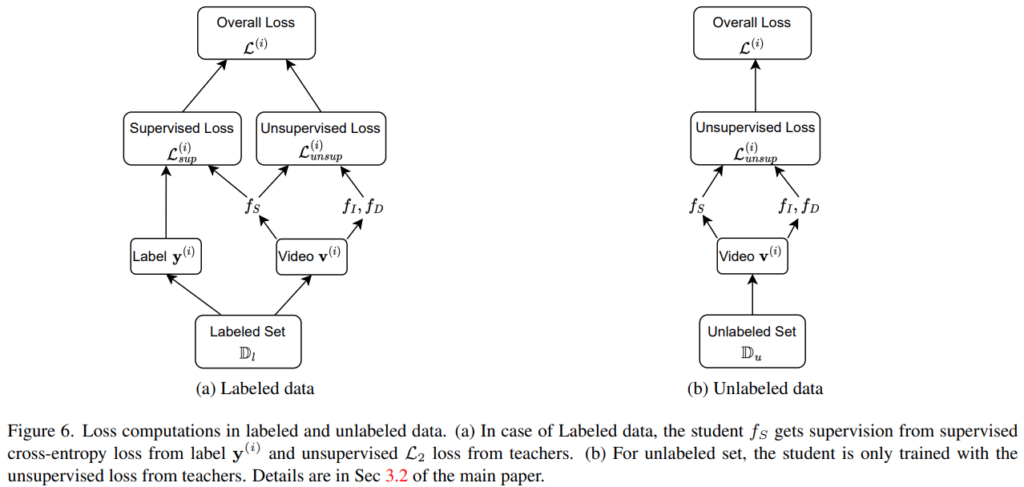
Teacher 모델이 각각 학습되는 방법에 대해서는 이제 알아보았습니다. 이제 student model을 학습시키는 방법에 대해서 알아볼텐데요. 크게 2가지 방법이 있습니다. GT가 있는 Labeled data에서 학습하는 경우에는 Supervised Loss를 쓰고, 아닌 경우에는 Unsupervised Loss만 사용하는데요.
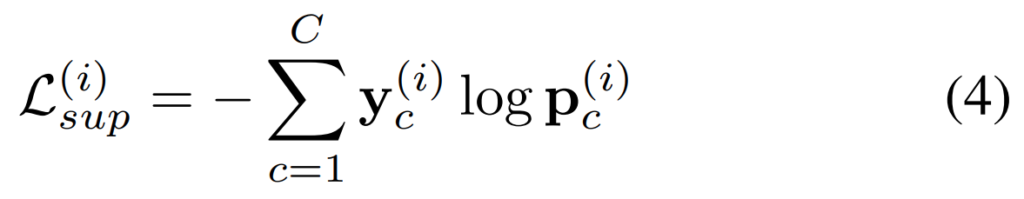
Supervised의 경우에는 [수식 4]와 같이 Cross-Entropy Loss로 구성됩니다. GT가 있으니까 그 GT랑 비교해보는 형태인거죠. 그래서 매우 간단한데, Unsupervised를 이해하려면, 이 논문에서 각 Teacher 모델의 상반된 지식을 distillation하기 위한, Temporal Similarity based Teacher Reweighting (TSTR)을 이해해야합니다.
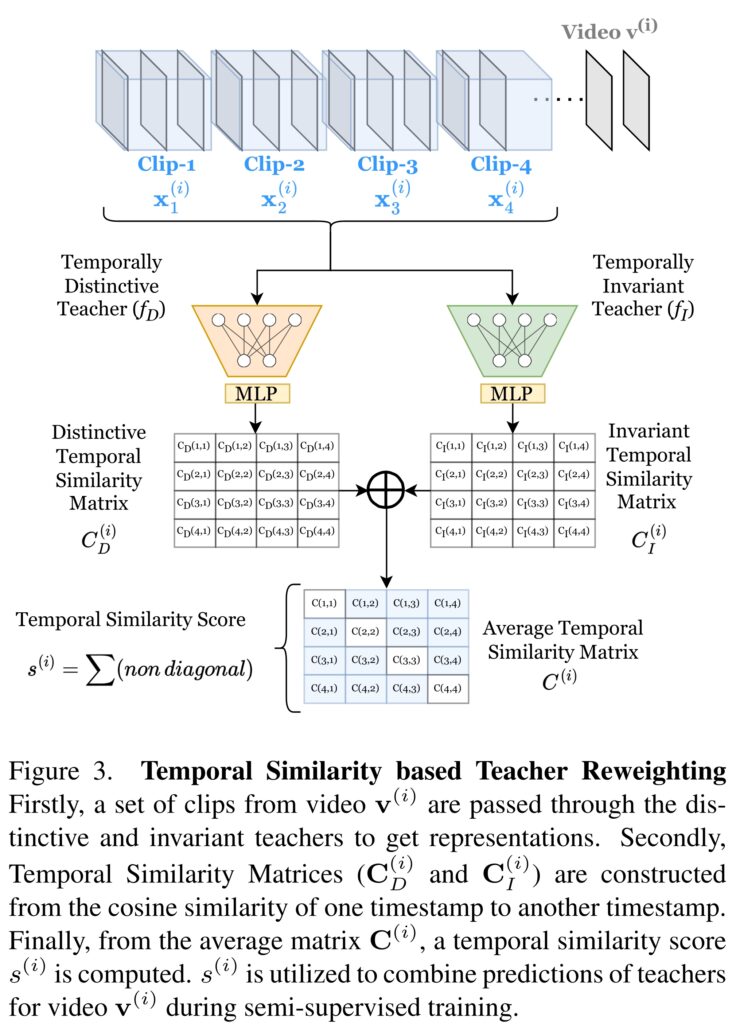
[그림 3]이 이 과정에 대해서 간략하게 설명해둔 그림인데요. 핵심은 최종적으로 만들어낼 Temporal Similarity Score를 생성하기 위한 Sim matrix를 어떻게 모델 2개로 생성할지입니다. 각각의 Teacher 모델들이 보고자 하는 표현력이 다르기 때문에 서로 다른 Sim matrix가 생성되는데요. 여기서는 이 두 matrix의 non-diagonal element들끼리의 평균값을 취해서 Average Temporal Similarity Matrix를 만드는 식으로 이 문제를 해결합니다. (대각 행렬은 자기 자신끼리의 유사도라 1이 나와서 제외)
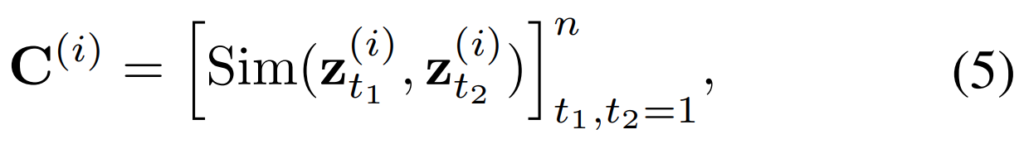
각각의 Teacher 모델에서의 Sim matrix는 [수식 5]와 같이 만들어지는데, 클립 번호에 따른 유사도 위치라서 그냥 참고하고 넘어가시면 되고요.
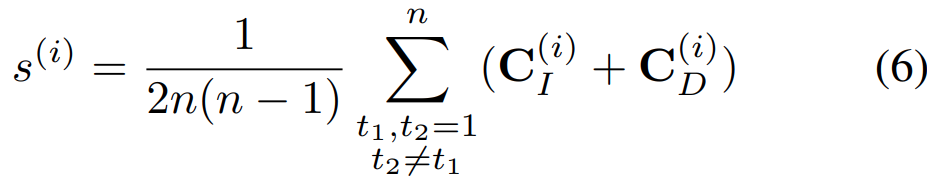
최종적으로 만들어지는 Temporal Similarity Score는 아까 말했듯이 대각행렬 제외한 평균 값으로 계산합니다. 이 결과값을 잘 생각해볼 필요가 있는데요. [그림 1]의 결론을 다시 떠올려봅시다. 관찰한 결과 이 Task에서는 결국 Temporal-Distintive하거나 Temporal-Invariant하다는 결론인데요. 이 결론에 따라 이 Score가 높을 경우에는 temporal-invariant한 teacher 모델의 예측이 정확하다는 것이고, 낮을 수록 temporal-distinctive한 teacher 모델의 예측이 정확하다는 뜻이 됩니다.
(*Temporal한 유사도를 계산했을 때, 프레임이 중복 프레임이 높은 경우에는 유사도가 높게 나오기 때문. 그래서 유사도가 높다고 나오면 결국 [그림 1]의 오른쪽과 같은 케이스가 됩니다.)
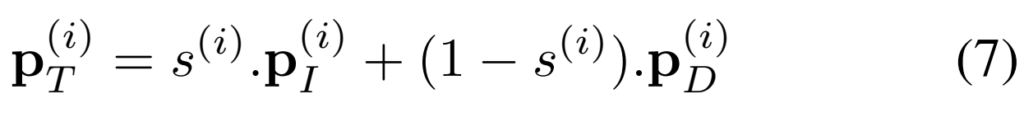
그래서 이러한 결과를 바탕으로 Teacher 모델의 예측 결과를 가변적으로 weighting해줄 수 있는 [수식 7]을 사용할 수 있습니다.
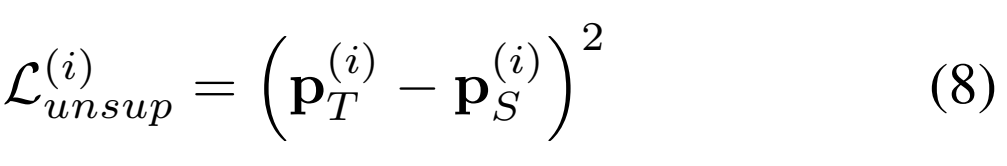
그리고 이 결과를 이용해서 unsupervised Loss를 최종적으로 유도할 수 있습니다.
Experiments
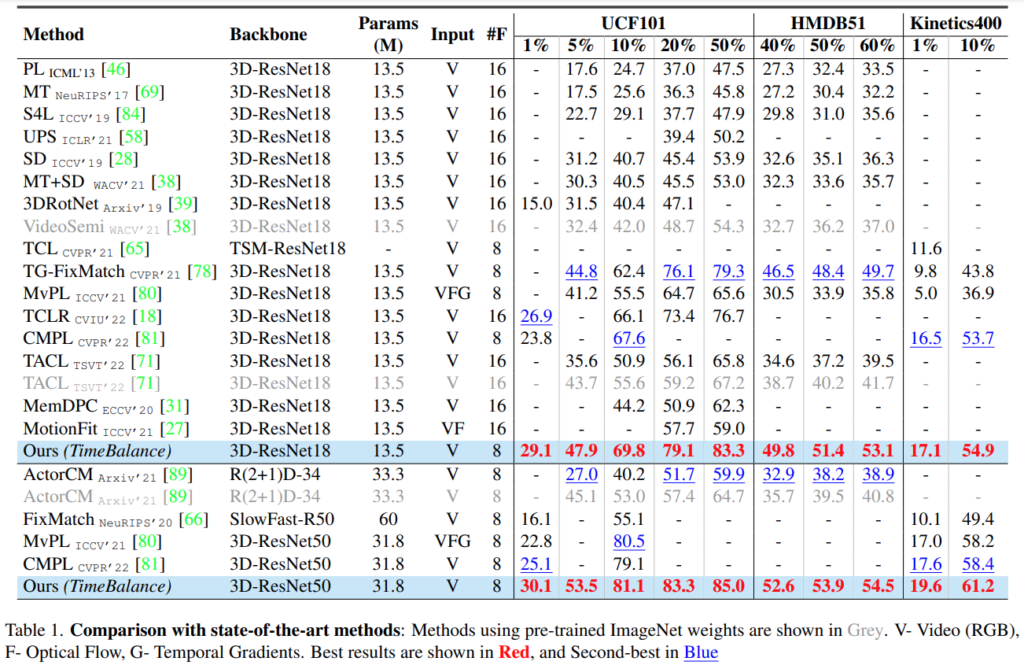
모든 경우에서 기존의 최고 성능(파란색)보다 더 높은 성능을 보입니다. 성능에서 %는 학습 데이터 비율을 뜻하고, 랜덤성 영향이 있으니 3번 돌려서 보고했다고 합니다. image-based baselines, video self-supervised baselines, semi-supervised action recognition 관련된 성능들이 각각 [표 1]에 있다고 보면 됩니다. 의문인 부분은 제가 아는 video self-supervised 방법론들의 성능보다는 낮은데… 아마 semi-supervised가 되면서 학습하는 데이터셋의 양이 줄어서 그런 것 같네요. 사실 Semi-Supervised 계열 논문을 별로 안봐서 이해를 잘 못한 것 수도 있지만 아무튼 이러한 부분을 제외하면 semi-supervised action recognition 비교군에서는 성능 향상은 확실합니다.
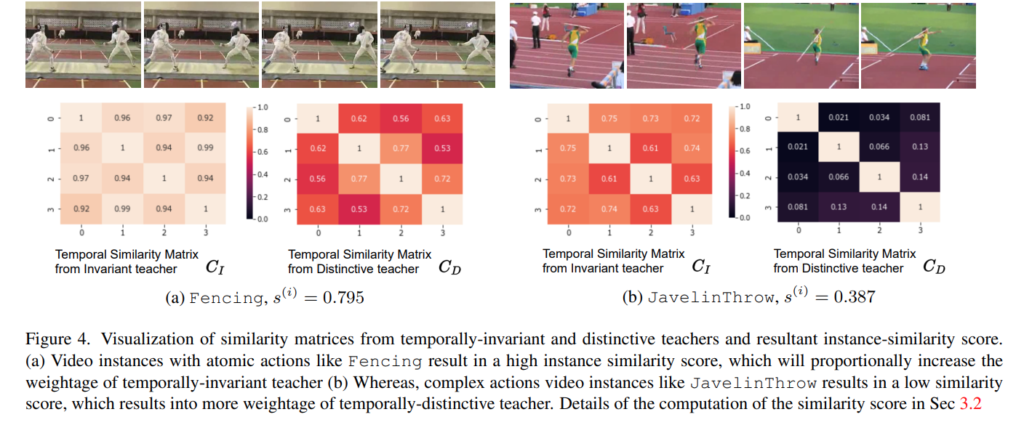
그리고 실제로 예시로 보였던 [그림 1]에서 예시로 제시되었던 클래스들의 유사도 점수를 보면 Temporal Similarity Score가 의도한대로 잘 작동하고 있음을 보입니다.
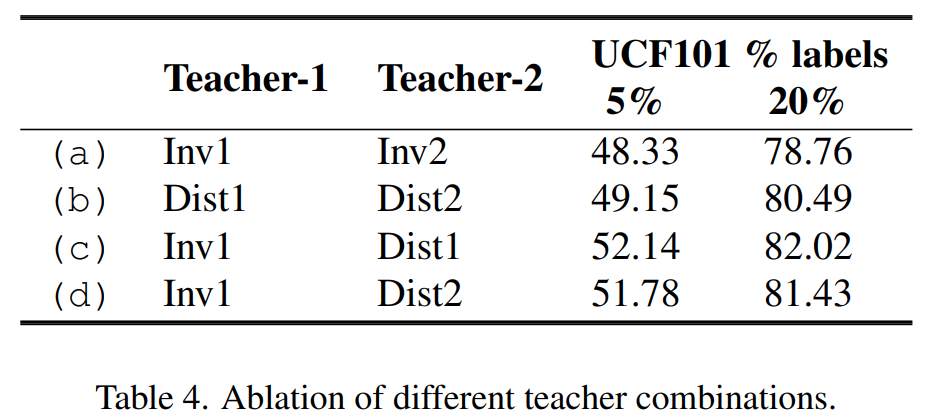
비슷한 abalation study로 각각의 Teacher 모델이 어떤 특성을 학습하느냐에 따라 성능 차이르 보게 되면, Invariant-distinctive한 특성을 각각 학습해서 distilation해야 좋은 성능을 보이는 것을 볼 수 있습니다.
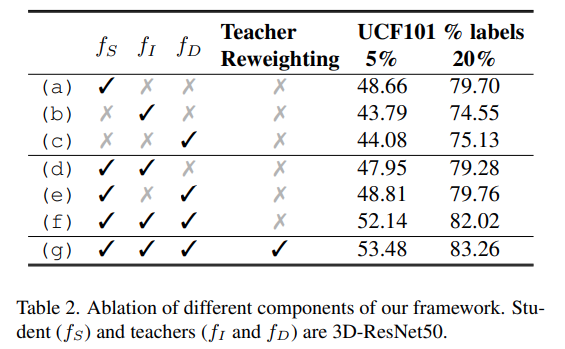
모듈 ablation에서도 동일한 경향성을 보이는데요. 의외인 점은 Student 단독 성능이 Teacher 보다 더 잘 나오는 것을 볼 수 있습니다. 그리고 양쪽 모두 붙여야 성능이 더 좋아지는데, 이건 이제 [그림 1]의 분석 결과처럼 반반으로 갈라진 Task에서 어느 한쪽 정보에 bias되서 성능 향상이 미미한 부분인 것 같네요.
Conclusion
확실한 분석 내용이 있었지만, 실험 분석은 조금 부족하지 않았나 싶습니다. 그래도 항상 중요하다고 언급되는 temporal한 정보에 대한 또다른 분석이라 좋은 논문이었습니다.
좋은 리뷰 감사합니다.
Loss와 관련하여 질문이 있습니다. 우선, Invariant Teacher를 학습하는 수식1을 통해 서로 다른 비디오클립끼리는 유사도가 작아지고, 동일 클립끼리는 유사도가 커지도록 표현력을 학습하는 것으로 이해하였습니다. 여기에 t1과 t2는 임의로 설정된 두 시간대인가요?
또한, Distictive Teacher를 학습하는 식에서는 t1=1, t2=1, t2≠t1이라는 조건이 있는 것으로 보이는데, 클립의 서로 다른 시간대를 하나만 이용하겠다는 의미로 이해하면 될까요??
t1과 t2는 서로 다른 비디오 클립이라 서로 다른 시간대가 맞습니다. 말씀하시는 조건에서 일단 t2랑 t1이 서로 같은 클립이면 학습이 안되니까 제외하는 조건이고, t1=1이 붙어있는건 클립내 프레임끼리 비교해서 학습해야해서 그렇습니다.