irregular한 3d point cloud에서 object representation을 추출하기 위해서 기존의 방법론들은 points들을 grouping하여 object로 판단되는 각 point마다 object candidate로 할당하여 object features를 추출하였다. 하지만 hand-crafted 방식으로 point를 할당할 때 부정확하게 할당되는 경우가 존재하여 성능 하락의 원인이 될 수 있다. 본 논문에서는 3d point cloud에서 간단하고 효과적인 방법으로 object를 detect하는 방법을 제안한다. local point를 grouping하여 object candidate를 할당하는 방법 대신, 모든 point cloud에 대해 object features를 계산하고 transformer의 attention 매커니즘을 적용한다. attention 방식과 더불어 서로 다른 여러 stage에서의 object features를 fusion하여 사용하여 더 정확한 object detection 결과를 보인다. 제안하는 Group-Free 3D 모델은 ScanNet V2, SUN RGB-D에서 sota를 달성하였다.
Introduction
3d object detection에서는 irregular하고 sparse한 특징을 가지는 3d point cloud 데이터를 다루기 때문에 2d object detection의 방법론을 그대로 적용하는데 어려움이 있다. 따라서 최근 3d object detection 방법론에서는 irregular input point에서 grouping과정을 거쳐 object candidate라 여겨지는 각 point에서 object features를 추출한다. 따라서 grouping을 하는 방법에 대한 다양한 방법들이 제시되었다. 하지만 이러한 hand-crafted방식의 grouping 전략은 각 point를 object candidate라고 잘못판단하는 경우 detection 성능을 크게 하락시키는 요인이 될 수 있다. 아래 Figure 1에서 voting과 roi-pooling을 보면 object candidate로 잘못 분류된 points들을 확인할 수 있다.
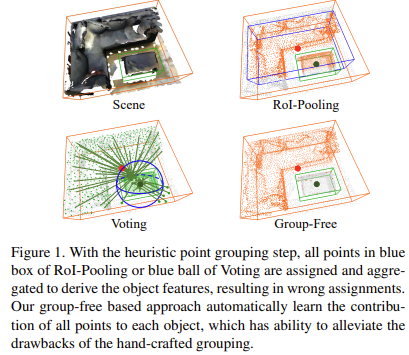
본 논문에서 제안하는 방법은 handcrafted 기반의 grouping과정을 거치지 않고 detection을 하는 방법이다. 제안하는 방식의 핵심 아이디어는 모든 point cloud에 대해 object candidate를 위한 features를 추출하여 object candidate에 기여하게되는 point가 attention module을 통해 자동적으로 학습되도록 한다. Transformer를 3d object detection에 맞게 적용한 것이다. 이러한 transformer 구조의 성능을 극대화하기 위해 2가지를 개선했다. 먼저 서로 다른 stages에서 반복적으로 object prediction을 refine하면서 object의 spatial encoding을 update하였다. 또한 inference시 마지막 stage에서의 result를 사용하지 않고, 모든 stages에서의 detection 결과를 ensemble하여 사용하였다. 이렇게 두 가지 방법을 적용하여 detection 성능을 향상시킬 수 있었다. ScanNet v2와 SUN RGB-D에서 평가를 진행했고 sota를 달성할 수 있었다. 실험적으로 본 논문에서 제안하는 모델이 효과적이고 object candidate를 효과적으로 뽑을 수 있음을 보였다고 한다. 저자는 transformer의 attention 매커니즘을 적용한것이 irregular하고 sparse한 분포를 가지는 3d point cloud 문제를 해결하는데 좋은 영향을 주었다고 판단한다.
Related Work
초반에 3d object detection 방법론들은 point cloud를 2d grid나 3d voxel 형태로 projection해서 convolution network를 적용하여 사용하였다. 보통 outdoor 자율주행 scenes의 경우 수평적으로 평면에 물체들이 분포하고 있기 때문에 하늘에서 바라보는 bird’s eye view로 projection해도 occlusion이 발생하지 않아 이러한 방법을 적용한다. 물론 front view로 projection하여 2d convolutional network를 적용하는 방법들도 존재한다. voxel-based 방법론들의 경우에는 point cloud를 voxel형태로 변환하여 3d convolution을 적용하여 features를 추출한다. 이러한 projection이나 voxelization을 하는 방법들은 데이터가 왜곡이 되는 양자화문제가 발생한다. voxel기반 방법론의 경우에는 많은 연산량을 필요로 하는 문제도 존재한다.
최근에 방법론들은 point cloud를 direct하게 사용한다. 이 방법론의 핵심 task는 irregular하고 sparse하게 분포되어있는 points에서 object features를 추출하는 것이다. 일반적으로 대부분의 방법론들이 group의 point마다 object candidates에 할당하고 각 point group마다 object features를 계산하는 방법을 사용한다. 대표적으로 pointnet이 있고 이후에 나온 frustum pointnet, point rcnn등이 존재한다. votenet의 경우 point가 object center로 투표한 points들을 group화하여 group내 point에 pointnet을 적용하여 feature를 추출한 방법론이다. 이후 point grouping방법에 대한 연구가 많이 이뤄졌다. 본 논문에서 제안하는 Group-Free3D도 point를 direct하게 사용하는 방법론이다. 다른 방법론과 차이점이 있다면 attention module을 통해 모든 points에 대해 feature를 계산한다는 점이다. 또한 attention module을 반복 적용하여 detection 결과를 refine하는 과정을 진행한다.
또한 본 논문에서 제안하는 방법론은 point features를 추출하기 위한 어떤 point cloud architecture도 backbone으로 사용할 수 있다. 여기서는 기존 방법론들과 공정한 비교를 위해 pointnet++을 backbone으로 적용하였다.
attention-based transformer는 NLP 분야에서 많이 사용되는 network architecture이다. 또한 2d image에도 사용되어 2d object detection을 할 수 있었다. 이러한 방법을 3d object detection task에 direct하게 적용하기에는 다른 3d object detection 방법론들에 비해 너무 낮은 성능을 보였다. 따라서 본 논문에서는 기존 3d object detection 방법론들의 장점을 잘 합쳐보고자 하였다. 저자는 기존 transformer model을 multi-stage에서 반복적으로 object query locations를 update해주고 각 stage에서 detection 결과를 ensemble하는 등 3d object detection task에 맞게 향상시켰다. attention을 활용한 해당 방법론이 point cloud로 object detection을 할 때 나타날 수 있는 grouping issue에 대한 대안을 시사했다고 생각한다.
Methodology
point cloud기반 3d object detection에서는 N개의 points를 가지는 point set S ∈ RN×3가 주어졌을 때 3d bounding box와 category score OS를 찾는 것이 목표이다. Group-Free3D의 전체 architecture 구조는 아래 Figure 2에 나타나있다. 크게 3가지 component로 구성되는데 point cloud 각 point에서 feature를 추출하기 위한 backbone network, object candidates를 생성하기 위한 sampling method, 모든 points로부터 object representation을 추출하고 정제하기 위한 stacked attention module로 구성된다.
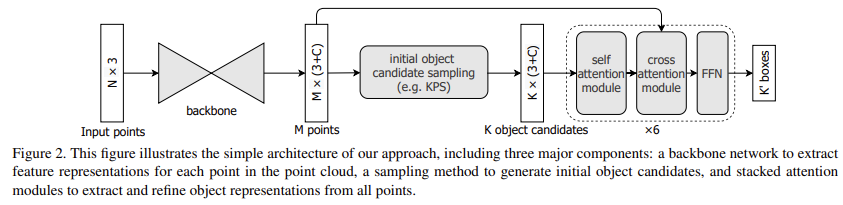
backbone은 기존 방법론들과 공정한 비교를 위해 pointnet++을 적용했다고 한다. pointnet++은 N개(2048)의 points를 input으로 하여 encoder-decoder구조를 통과하는데 8배(256 points)까지 downsample하고 다시 2배(1024 points) upsample한다. network를 통해 각 point마다 C channel vector의 representation {zi}i=1M 을 얻는다. 그리고 initial object candidate sampling module과 stacked attention modules를 통과하게된다.
Initial Object Candidate Sampling
기존 2d object detection에서는 모든 image에 대해 비슷한 크기와 aspect ratio를 가지는 data-independent한 anchor box를 사용했다. 하지만 이런 top-dowm 방식을 3d object detection에 적용하면 3d space에 존재하는 anchor box의 수가 너무 많기 때문에 실용적이지 못한 방법이 된다. 대신에 bottom-up 방식으로 point cloud의 points에서 direct하게 initial object candidiates를 sample하는 방법을 적용한다. initial object candidates를 sample하기위해 크게 3가지 방법을 고려하였다.
– Farthest Point Sampling(FPS)
FPS는 point cloud에서 object의 3d shape을 생성하거나 low resolution으로 downsampling할때 general하게 적용하는 방법이다. point cloud에서 initial candidates를 sample할 때 사용할 수 있다. 먼저 point cloud에서 random하게 하나의 point를 sampling한 후 해당 point로부터 가장 먼 점을 반복해서 선택하는 sampling방법이다. 기존에 많이 사용된 방법으로 간단하게 수행할 수 있다.
– k-Closest Points Sampling(KPS)
해당 방법은 point cloud에서 각각의 point가 실제 object candidates인지 아닌지를 분류할 때 사용한다. training 과정에서 label assignment를 할 때, 어떤 point가 gt object box안에 포함되고 object center와의 거리가 설정한 k개보다 가까우면 positive로 할당된다. inference시에는 point의 classification score에 따라 initial candidates를 할당하게된다.
– KPS with non-maximal suppression(KPS-NMS)
KPS에 nms를 추가한 방식이다. 2d nms와 동일하게 적용되며 가자아 spatially하게 가까운 object candidates를 반복적으로 update하게된다. 각 point마다 point가 속하는 object center를 예측하여 nms를 적용한다. object center로부터 일정한 거리 내 속하는 candidates를 suppress한다.
저자는 KPS가 가장 좋은 성능을 보여 default로 사용했다.
Iterative Object Feature Extraction and Box Prediction by Transformer Decoder
위에서 sampling을 통해 initial object candidates가 생성되었다. 이후 모든 point에 대해 transformer를 decoder로하여 각 candidates에 대한 object feature를 추출한다. query set{qi} 과 key set, value set으로 구성된 element set{pi} 이 주어졌을 때 각 query element마다 multi-head attention을 통과한 output feature는 attention weight에 의한 weights들을 합친 것으로 아래 식(1)과 같다. 각 key,value pair에 대해 query와 key가 매칭되는 weights를 계산하여 attention module의 output인 weighted sum을 계산하는데 사용된다.
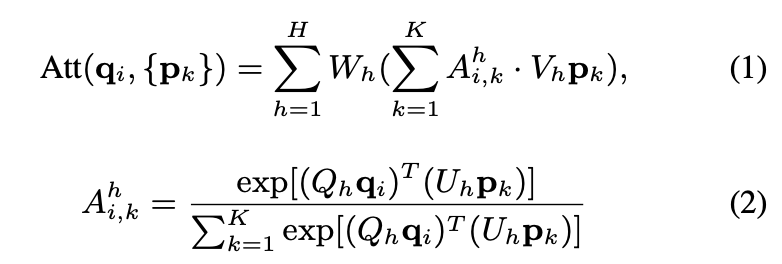
– h : attention head
– Ah : attention weight
– Qh, Vh, Uh, Wh : query projection weight, value projection weight, key projection weight, output projection weight
transformer는 여러 개의 stacked multi-head self-attention과 multi-head cross-attention mdoules로 구성되며 아래 Figure 3과 같다.
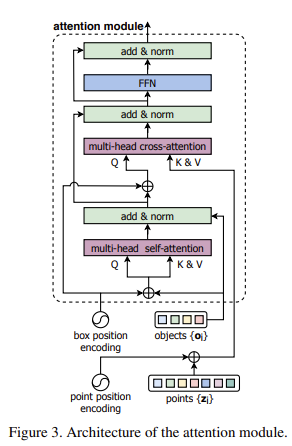
stage l 에서 input point features를 {zi(l)}i=1M, object features를 {Oi(l)}i=1K으로 나타낸다. 먼저 object features간 self-attention module을 통과시킨다.
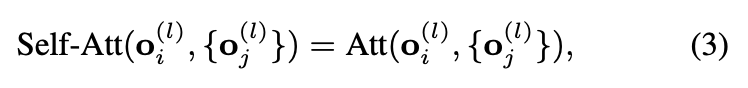
그리고 cross-attention module이 point features를 사용하여 object features를 계산한다.
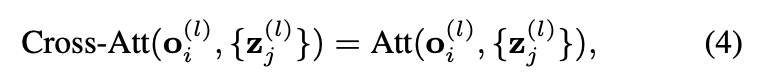
self-attention module과 cross-attention module을 통해 update된 object feature는 FFN(Feed-forward network)를 통과하여 각 object에 대한 feature를 추가로 변환해준다.
본 논문에서는 기존 original transformer의 decoder구조에서 조금 개선을 했는데, 기존 transformer는 모든 attention module에 word의 index를 명시해주는 fixed spatial encoding을 적용하였다. 본 논문에서는 stage by stage로 object candidate의 spatial encoding을 개선하는 방법을 제안한다. 각 decoder stage마다 3d box location과 categories를 예측하고, 예측된 box의 location이 해당 object의 spatial encoding을 refine하는데 사용된다. 이때 refined spatial encoding vector는 해당 decoder stage의 output feature에 더해져 다음 stage로 넘어가게된다. object와 point의 spatial encodings는 3d box(x,y,z,l,h,w)와 point(x,y,z) 각각의 parameterization을 linear layers에 통과시켜 따로 계산한다. 그리고 실험적으로 반복적으로 refinement하는 과정이 성능 향상에 영향을 주었음을 보였다.
그리고 기존에는 마지막 stage의 output을 final result로 사용했지만, 본 논문에서는 서로 다른 stages에서 예측한 결과를 ensemble하여 final detection 결과를 얻는다. 서로 다른 stage에서의 detection results를 combine하여 nms(iou 0.25)과정을 거쳐 최종적인 detection results를 생성하게된다. 이 방식을 적용하여 SUN RGB-D에서 3.8%정도 mAP를 향상시킬 수 있었다고 한다.
Heads and Loss Functions
decoder head는 5가지 prediction task로 구성된다. votenet에서 적용한 방법을 적용했다.
– Lobj : object center와의 거리에 대한 loss로 binary focal loss 사용
– Lcls : box classification. cross entropy loss 사용
– Lcenter_off : center offset prediction. smooth-L1 loss
– Lsz_cls : size classification. cross entropy loss
– Lsz_off : size offset. smooth-L1 loss
위의 5개 prediction task는 mlp를 통해 진행된다. l번째 decoder stage에서의 loss는 이 5개의 loss term의 가중합으로 구성되며 아래 수식(5)로 표현된다.
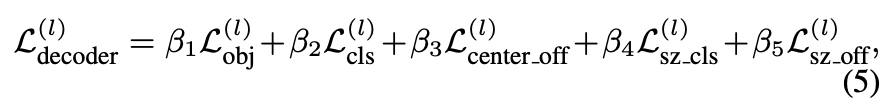
그리고 최종 loss는 모든 decoder stage에서의 loss의 평균으로 계산한다.
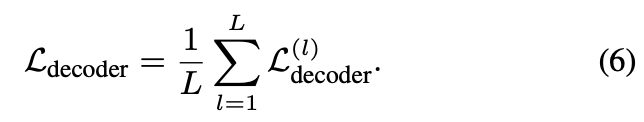
Sampling Head는 decoder head와 2가지가 다르다. box classification task를 하지 않고, objectness task는 위에서 설명한 KPS로 label assignment를 한다는 점이 다르다.
최종 loss는 decoder와 sampling head의 loss의 합으로 구성된다.
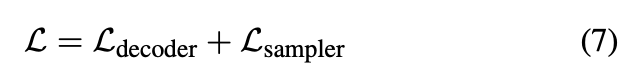
Experiments
본 논문에서는 ScanNet V2와 SUNRGBD에서 평가를 진행했다.
아래 Table 1에서는 ScanNet V2에서의 성능을 보여준다.
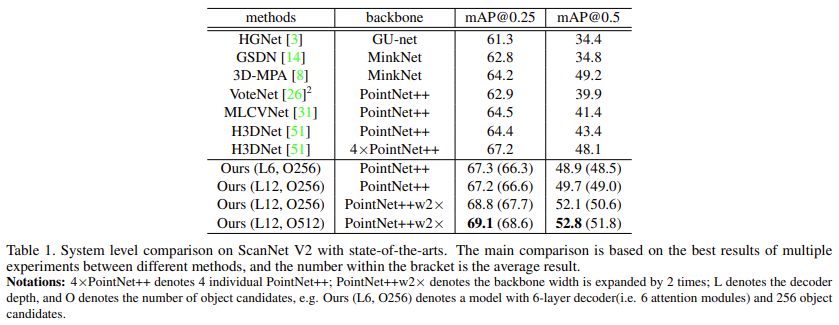
backbone을 pointnet++으로 적용했을 때 다른 pointnet++기반 방법론들보다 좋은 결과를 보이는 것을 확인할 수 있다. L은 decoder의 stage 수를 의미하고 O는 object candidate의 수를 의미한다. 6 decoder stage와 256의 object candidates로 설정한 모델이 동일한 backbone을 사용한 sota모델인 H3DNet보다 mAP 0.25와 0.5에서 각각 2.8%, 5.5%가 높은 정확도를 보이는 것을 확인할 수 있다. decoder depth를 2배 늘리고 object candidates도 512로 늘린 모델에서는 69.1, 52.8의 정확도로 다른 모델과 큰 차이를 보이고 있다.
아래 Table 2에서는 SUN RGB-D에서의 성능을 리포팅했다.
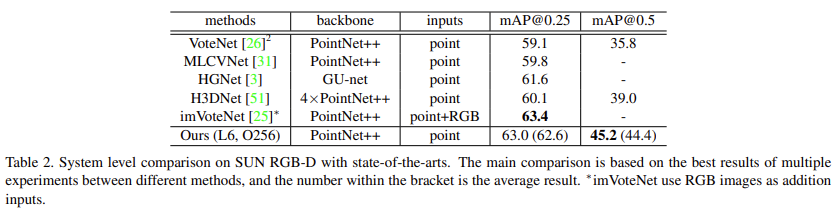
sunrgbd에서 여러 decoder layers의 예측 결과를 ensemble한 것이 큰 성능 개선을 가져왔다고 한다. 뒤에 ablation study에서 결과를 보여줄 것이다. 본 논문에서 제안하는 방법론이 다른 point cloud기반의 방법론과 비교했을 때 더 좋은 성능을 보이는 것을 알 수 있다. SUN RGBD에서는 위에 scannet v2에서처럼 decoder depth와 object candidates의 수를 바꾸어 실험한 성능이 없는 것이 의아하게 느껴진다. 아마 더 좋은 성능을 보이지 못하지 않았을까하는 추측을 해본다. imvotenet의 성능에는 못미치는 것으로 보이는데 imvotenet은 rgb image를 추가로 input으로 사용하였다. 개인적인 생각으로는 아마 transformer의 방법론을 3d object detection에 적용하였을 때 다른 방법론의 sota와 견줄만한 성능을 보였다는 것으로 가치가 있다고 판단한 것 같다.
본 논문에서는 여러가지 ablation study를 진행한 것으로 보인다.
먼저 ScanNeet V2에서 6개의 attention module과 256개의 sampled candidates로 고정하고 제안하는 iterative object prediction 방법을 적용한 모델을 설정하고 진행하였다고 한다. 아래 Table 3에서는 sampling 방법에 대한 실험을 보여준다.
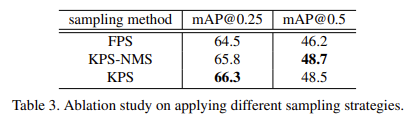
위에서 sampling 방법에 대해 설명할 때 말했던 것처럼 KPS가 가장 좋은 성능을 보이고 있다. mAP 0.5에서 nms를 추가한 방법이 조금 더 우세한 성능을 보이지만 추가적인 과정이 필요하기 때문에 시간적인 요소를 고려한다면 KPS를 적용하는 것이 이득이라고 생각된다.
아래 Table 4에서는 KPS sampling방법을 적용할 때 k값에 따른 성능을 보여준다. 다시 간단히 말하자면 KPS에서 k는 어떤 point가 positive로 할당되기 위한 범위를 설정하는 parameter이다. 성능을 보면 k가 1일때부터 6일때까지 dramatic한 성능 차이를 보이지 않는 것을 알 수 있다. 넓은 범위의 hyperparameter 차이에 대해서도 robust하다고 생각된다. sampling방법을 다른 것을 적용하여도 robust한 것 같다는 의미이다.
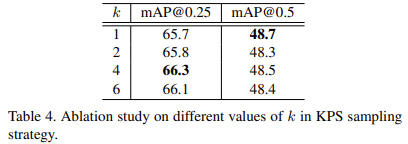
아래 Table 5에서는 iterative box prediction가 효율적인지에 대해 보여주고 있다. decoder stage에 spatial encoding을 포함하지 않는 iterative 방법에서도 64.7로 그리 나쁘지 않은 결과를 보이는데, 아마 location 정보가 이미 object feature에 포함되어 있어서 그런 것 같다. 여기에 center+size의 fixed position encoding을 추가한 것은 64.6으로 성능향상을 가져오지 못했다.
하지만 아래 line에서 stage by stage마다 box location의 encoding을 refine한 경우(iterative에 check되어있는 것) 더 좋은 성능을 보이는 것을 확인할 수 있다. 여기에 center+size의 spatial encoding을 해준 경우 box의 center만 encoding해준 경우보다 좋은 성능을 보인다.
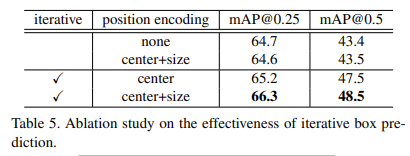
아래 Table 6에서는 서로 다른 수의 decoder stage에서의 iterative box prediction 결과를 보여준다. 당연하게 느껴지듯이 더 많은 layer를 사용할수록 조금씩 더 좋은 성능을 보여준다.
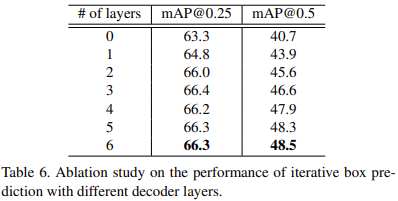
Table 7에서는 mutli-stage prediction을 ensemble한 것에 대한 효과를 보여준다. 눈여겨 볼 것은 SUN RGB-D 데이터셋에서인데, scannetv2에 비해 더 큰 폭의 정확도 향상을 이룰 수 있었다. 이것에 대해 생각해보면, sun rgbd는 scannet v2보다 더 low quality의 point cloud를 가진다. sun rgbd는 real rgb-d sensor로 생성한 point cloud로 구성되어 빈 공간이 많고 occlusion도 많다. 반면에 scannet v2는 3d mesh shape에서 point cloud를 생성한 것이기 때문에 더 complete한 데이터를 가진다. 따라서 ensemble을 적용했을 때 더 큰 폭의 성능향상이 있는 것으로 보인다.
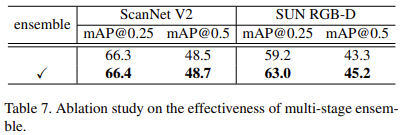
Table 8에서는 다른 것들은 다 고정하고 grouping하는 방식만 바꾸어 실험했는데, 본 논문에서 제안하는 grouping을 하지 않고 attention module을 추가한 group-free방식이 가장 좋은 결과를 보이고 있다.
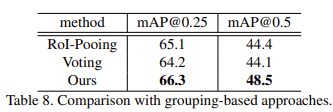
언제나오나 기다렸는데 inference time에 대한 결과가 Table 9에 reporting되어있다. 오래 걸릴 것이라 예상했지만, 예상외로 오히려 다른 pointnet++을 backbone으로 사용한 sota모델보다 더 빠른 속도를 보였고 성능도 더 좋은 것으로 보인다.
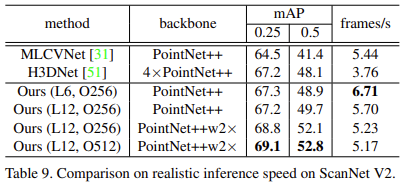
아래 Figure 4에서는 scannet v2와 sun rgbd에서의 결과를 시각화해서 보여준다. Figure 4에서 보면 layer가 깊어질수록(decoder network가 깊어질수록) 정확한 detection을 하는 것을 확인할 수 있다.
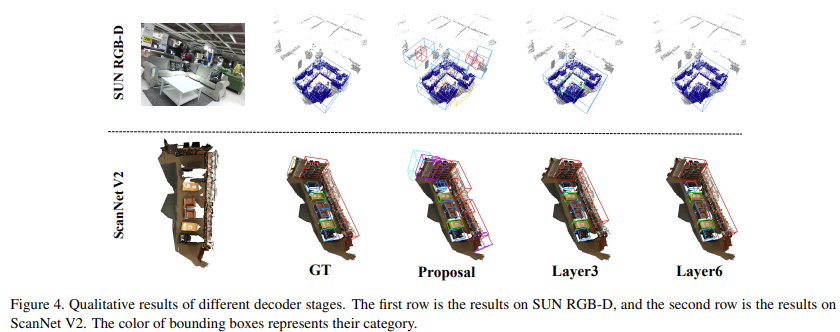
Figure 5에서는 서로 다른 decoder stage에서 cross-attention weights가 학습한 부분에 대한 시각화이다. low stage에서는 geometry정보를 고려하지 않고 주변 points에 focus하는 경향이 있고, stage가 깊어질수록 refinement를 거치면서 geometry정보에 더 집중하고 high quality의 object features를 보여주는 것을 알 수 있다.
Conclusion
본 논문에서는 transformer의 attention 매커니즘을 3d object detection에 맞게 적용한 방법을 제시했다. 기존에 grouping을 통한 방법론들의 문제점을 지적하며 이를 해결하기 위해 attention을 적용하여 group-free 방식으로 모든 points에서 object features를 계산하는 방법을 사용했다. 각 point는 attention module을 통해 자동적으로 feature에 영향을 미치는 부분을 학습하도록 했다. 결과적으로 scannetv2와 sunrgbd에서 sota를 달성할 수 있었다.
좋은 논문을 리뷰해주셔서 감사합니다.
Transformer를 3d object detection에 안정적이게 적용하기위해 bbox를 stage마다 refine하며 사용하는 점이 핵심인 것 같습니다.
근데 각 스테이지마다 refine되어 사용되는 값이 뭔지 이해가 안가네요… 그림들을 활용하여 설명 부탁 드려도 될까요?
예측된 box의 location이 해당 object의 spatial encoding을 refine하는데 사용된다. 이때 refined spatial encoding vector는 해당 decoder stage의 output feature에 더해져 다음 stage로 넘어가게된다
댓글 감사합니다.
코드를 확인해보니 간단한 구조라 그림에는 따로 표시되어있는 것 같지 않아 말로 설명해보겠습니다. refine한다는 것은 간단히 말해서 각 decoder stage에서 conv layer 2개로 구성된 mlp에 3d location을 통과시킨다는 것으로, 이렇게 얻은 position embedding vector(코드 상 position features 수는 288입니다) 를 stage마다 더해서 다음 stage로 전달하게 됩니다.