안녕하세요. 이번 논문은 멀티모달 감정인식에도 사전학습 모델이 나올 수 있구나를 볼 수 있는 논문이여서 신박하여서 가져와봤는데요. 이름에서 알 수 있듯이 bert 기법이 많이 적용된 논문입니다. 그럼 리뷰 시작하겠습니다.
<prompt-based learning>
우선 prompt-based learning이 뭐지? 싶은 분들이 있을거 같아 introduction에 들어가기 전에 프롬프트가 무엇인지 설명드리고자 합니다.

위의 사진은 “Pretrain, prompt and predict”라는 논문에 나와있는 재밌는 그림이 있어 가져와봤는데요. prompt 옷을 입고 있는 여성이 Bert, Bart, Ernie라는 언어 모델에게 prompt를 줍니다. JDK는 누구에 의해서 개발되었냐는 질문에 Oracle이라고 잘 답변하는 것을 확인할 수 있습니다. 이를 통해 확인할 수 있는 것은 수행해야 할 작업을 지정하는 ‘프롬프트’를 제공하여 사전 학습된 모델이 특정 예측을 하도록 유도한다는 것입니다. 이것이 프롬프트의 역할이라고 생각하시면 됩니다. 그러면 프롬프트는 어떻게 등장하게 되었을까요? 프롬프트의 시작은 gpt로부터 시작되었다고 볼 수 있습니다. (프롬프트라는 개념은 gpt전에 등장했을 지 몰라도 gpt는 프롬프트 기법을 사용하면서 유명해졌습니다.)

위의 그림이 바로 gpt3의 모델 그림을 간략하게 가져온 것입니다. 여기서 주목할 점은 parameter 수 인데요. gpt3이전의 언어 모델들이 모두 모델의 크기를 엄청나게 키우면서 gpt3 역시 모델의 크기를 무지막지하게 키워 아주 높은 성능을 달성했는데요. parameter 수를 보면 175B로 어마무시한 수를 기록한 것을 확인할 수 있습니다. 그러면 여기서 질문이 나올 수 있죠. 과연 이 엄청난 수의 파라미터를 파인-튜닝 할 수 있을까요? 분명 쉽지 않을 것입니다. 그래서 few-shot learning이 등장하면서 prompt라는 것이 등장하였습니다.

위의 그림을 통해 few-shot learning이 대략적으로 이런거구나 확인할 수 있는데요. few-shot learning이라는 것은 task의 설명을 주고 examples를 몇 개 주었을 때 prompt로 task를 수행할 수 있도록 유도하는 것입니다. 여기서 example을 하나도 주지 않고 설명만 준다면 zero-shot, example을 하나만 준다면 one-shot이라고 부를 수 있습니다. 이게 가능한 이유는 in-context learning 덕분인데요. 여기까지 들어가면 너무 딥하게 들어가는 것이기 때문에 제가 이전에 작성한 gpt3 리뷰를 확인해주시면 감사하겠습니다.
그럼 이제 introduction 시작입니다.
<introduction>
멀티모달 감정 인식 연구는 높은 주석 비용과 라벨 모호성으로 인해 규모와 다양성 측면에서 라벨링된 말뭉치가 부족하여 어려움을 겪고 있습니다. 본 논문에서는 멀티모달 감정 인식을 위한 멀티모달 사전 학습 모델 MEmoBERT를 제안하여, 자체적으로 수집한 방대한 양의 라벨이 없는 대규모 비디오 데이터로부터 자기 지도 학습을 통해 multimodal joint representaion을 학습합니다. 또한 기존의 ‘선 훈련 후 미세 조정’ 패러다임과 달리, 다운스트림 감정 분류 작업을 masked text prediction으로 재구성하여 다운스트림 작업을 사전 훈련에 가깝게 만드는 프롬프트 기반 방법을 제안합니다.
<method>
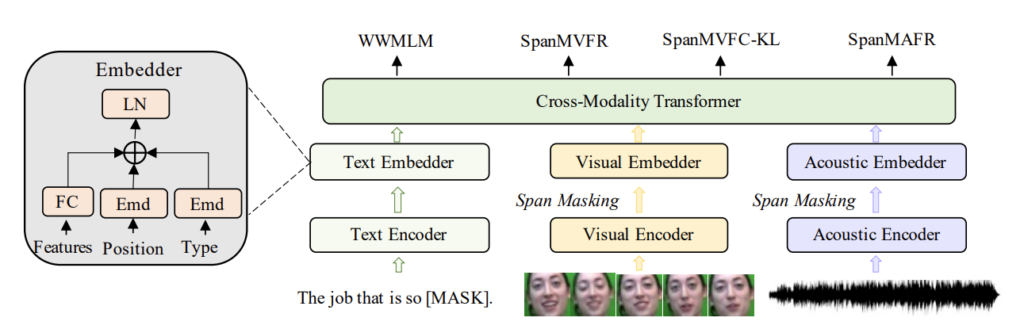
MEmoBERT는 텍스트, 시각 및 음향 모달리티에 대한 모달리티별 토큰/프레임 수준의 raw feature을 생성하는 3개의 독립 modality encoder와 각 모달리티의 해당 raw feature, position 및 type을 기반으로 각각 임베딩을 생성하는 3개의 임베더로 구성됩니다.
특히, Text Encoder는 bert의 embedding layer를 사용하였고, Visual Encoder는 화자의 얼굴을 기반한 얼굴 expression feature를 만들 수 있는 사전학습된 facial expression model을 사용하였는데요. DenseFace로 DenseNet 구조를 가졌다고 합니다.

DenseNet의 구조에 대해서 처음 들어봐서 사진으로 이해하고자 위의 그림을 가져와봤는데요. 위의 그림처럼 된 구조가 DenseNet 구조구나 하고 넘어가시면 될 것 같습니다.

Accoustic Encoder는 audio waveform을 기반으로 acoustic feature를 생성하는 사전학습된 음성 모델을 사용하였는데요. 음성 분야에서는 유명한 wav2vec2 모델 입니다. bert는 그래도 VIT 등에서 많이 나와서 잘 아실거 같은데 wav2vec2는 음성 분야에서만 유명한 모델이라 이해를 돕기 위해 사진을 가져와봤습니다. 역시나 이런 구조의 모델이구나 생각하시고 넘어가시면 될 듯 합니다.
이렇게 encoder를 정의했다면 각 모달리티에 대한 최종 임베딩은 raw feature, position emedding, type embedding을 합산한 다음 Layer Norm을 통해 정규화하여 최종 임베딩을 얻게 됩니다.
그런 다음 MEmoBERT의 cross-modality transformer는 는 서로 다른 모달리티의 임베딩을 기반으로 corss-modality contextualized representaion을 학습합니다.
논문의 저자는 사전 학습 단계에서 emotional multimodal joint representation을 학습하기 위해 4가지 효율적인 사전 훈련 작업을 설계하여 MEmoBERT를 최적화합니다. 모델이 잘 사전 학습되면 프롬프트 기반 또는 미세 조정 기반 방법을 채택하여 다운스트림 작업에 맞게 조정합니다.
<mehod>
<1. Cross Modality Transformer>
cross-modality transformer는 BERT 아키텍쳐를 사용하여서 multi-modal pretraining을 위해 3가지 modality(text, visual, audio)로 확장합니다. 사전 학습 중에 modality별 embedding이 multi-layer transformer에 공급되어서 서로 다른 modality에 걸쳐 high-level cross-modality contextualized representation을 학습합니다.
<2. Pre-training Tasks>
논문의 저자는 text, visual, audio modality 관련 task를 포함한 4가지 사전 학습 task를 설계하여 modality 간 상호 작용을 향상시키고 multimodal joint emotional representation을 학습합니다. conditional masking strategy를 사용하는데 하나의 modality만 마스킹하고 다른 modality는 그대로 유지하는 전략을 말합니다. 이를 통해서 model은 더 좋은 latent alignment를 학습할 수 있으며 더 좋은 multimodal joint representation을 학습할 수 있습니다.



위의 3개의 그림을 통해서 conditional masking이 어떻게 되는지 파악할 수 있습니다. 예를 들어서 “cool”이라는 단어를 마스킹 했다면 다른 모델은 마스킹하지 않는 식으로 들어갑니다. 오디오를 마스킹 했다면 다른 모달리티를 마스킹하지 않는 식으로 하나의 모달리티만 마스킹 하는 식으로 마스킹 합니다.
만약 여러개의 웃는 얼굴이 마스킹 되었다면 주변 표정, “멋지다”라는 단어, 음성 톤을 기반으로 마스킹된 얼굴 프레임의 표정 특징/감정 분포를 추론할 수 있어야 합니다.
<2.1 Whole Word Mask Language Modeling (WWMLM)>
Whole Word Mask Language Modeling (WWMLM)은 visual, acoustic modality가 주어진 상태에서 마스킹된 전체 단어를 예측하도록 학습됩니다. WWMLM은 Word Piece보다 더 정확한 semantics를 capture할 수 있는데요. 예를 들어 설명하도록 하겠습니다. Word Piece는 단어의 부분적인 토큰을 마스킹하는데 특히 접수다(예: “un-“, “im-“, “op-“)와 접미사(예: “-less”)가 포함된 단어의 경우 전체 단어의 감정적 의미가 완전히 반대될 수 있습니다. WWMLM은 접두사, 접미사를 모두 포함하여 마스킹하기 때문에 이러한 상황을 방지할 수 있습니다.
<2.2 Span Masked Acoustic Frame Regression (SpanMAFR)>
Span Masked Acoustic Frame Regression (SpanMAFR)은 text 및 acoustic modality가 주어졌을 때 마스킹 된 audio frame의 acoustic encoder에서 추출한 acoustic feature를 reconstruct하는 방법으로 학습합니다. 또한 연속된 프레임을 마스킹하는 span maksing strategy를 채택하여 사용한다고 하는데요. 이에 대해서 논문에서 더 언급된 설명이 없어 직접 찾아봤습니다.

위의 그림과 같은 방법으로 연속된 프레임을 마스킹 한다고 하는데요. 이러한 방법을 사용하면 global emotional expression을 더 잘 capture하고 모델이 acoustic frame의 local smoothness를 이용하는 것을 피하도록 도와준다고 합니다. objective function으로는 L2 regression을 사용했습니다.
<2.3 Span Masked Visual Frame Regresstion (SpanMVFR)
Span Masked Visual Frame Regression (Span MVFR)은 text, acoustic modality가 주어진 상황에서 마스킹된 visual frame을 입력으로한 visual encoder로부터 추출된 facial expression feature를 reconstrut하도록 학습합니다. 연속된 visual frame의 similarity 때문에 위의 사진에 보였던 audio에서 사용한 마스킹 전략을 그대로 사용하고요. 마찬가지로 objective fuction으로 L2 regression을 사용합니다.
<4.Span Masked Visual Frame Classification with KL-divergence (SpanMVFC-KL)
Span Masked Visual Frame Classification with KLdivergence(SpanMVFC-KL)는 text, acousitc modality가 주어진 상황에서 masking된 visual frame에 대한 감정 범주(예: 행복, 슬픔, 분노)의 분포를 예측하는 방법을 학습합니다. 마스킹된 frame의 transformer output을 fc layer에 fed하여 k개의 facial expression classes의 emotion distribution을 학습합니다. 마지막으로 KL-divergence를 objective fucntion으로 사용하니다.
저는 이 논문에서 처음으로 KL-divergence를 접했는데요. 그래서 제가 이해한 것을 조금 더 설명드리고자 합니다.

위의 사진을 통해 KL-divergence를 확인할 수 있는데요. 어렵게 생각하지 않아도 됩니다. 여기서 H(p,q)는 cross-entropy를 의미하는데요. p, q는 확률 분포를 의미합니다. 이러한 지식을 가지고 위의 식을 보면 KL-divergence가 두 확률분포의 차이를 계산하는 데에 사용되는 것을 알 수 있습니다.
<3. Prompt-based Emotion Classification>
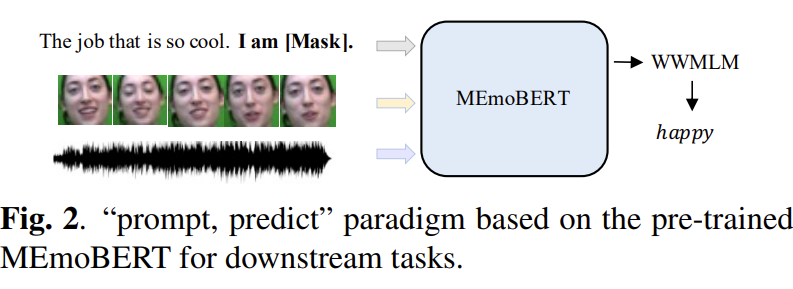
Fig 2를 통해 “prompt, prdict” 패러다임을 확인할 수 있습니다. 프롬프트 기반 멀티모달 입력 “[X] 나는 [MASK] 입니다. [V] [A]”에서 [X], [V], [A]는 각각 비디오의 text, visual, acoustic 입력을 의미합니다. 따라서 분류 문제는 “나는 [MASK] 입니다.”라는 text prompt의 도움으로 [MASK]를 감정 범주 단어(예: 행복, 슬픔, 분노)로 예측하도록 refomulated됩니다. 이는 언어 모델 task와 굉장히 유사하죠.
<Experiment>
<Result>
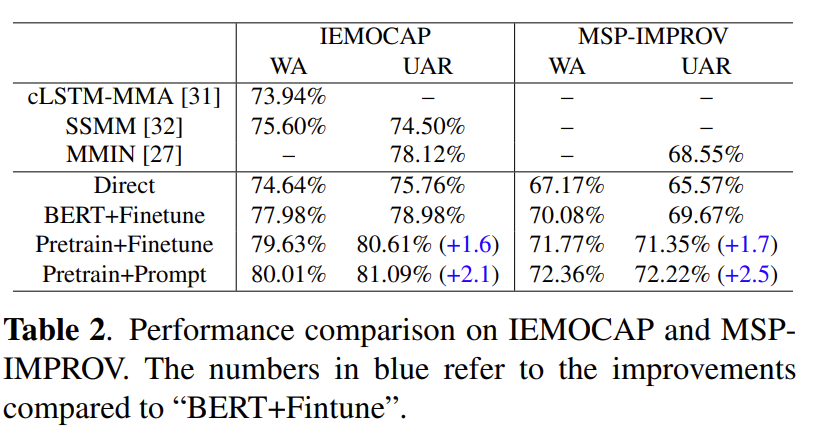
Table 2에서 실험 결과를 확인할 수 있습니다. WA는 weighted accuarcy를 의미하고, UAR는 Unweighted Average Recall을 의미합니다. Direct, BERT+Finetune, Pretrain+Finetune, Pretrain+Prompt는 아래와 같이 의미합니다.
- Direct : directly train the MEmoBER
- BERT+Finetune : finetune the MEmoBERT followed by a classifier for downstream task
- Pretrain+Finetune : finetune the pre-trained MEmoBERT followed by a classifier for downstream tasks
- Pretrain+Prompt : the prompt-based learning method based on the pretrained MEmoBERT without introducing any additional parameters for downstream tasks.
실험 결과를 확인하면 논문에서 제안한 방법인 사전학습 + prompt를 이용했을 때 가장 성능이 높은 것을 확인할 수 있습니다.
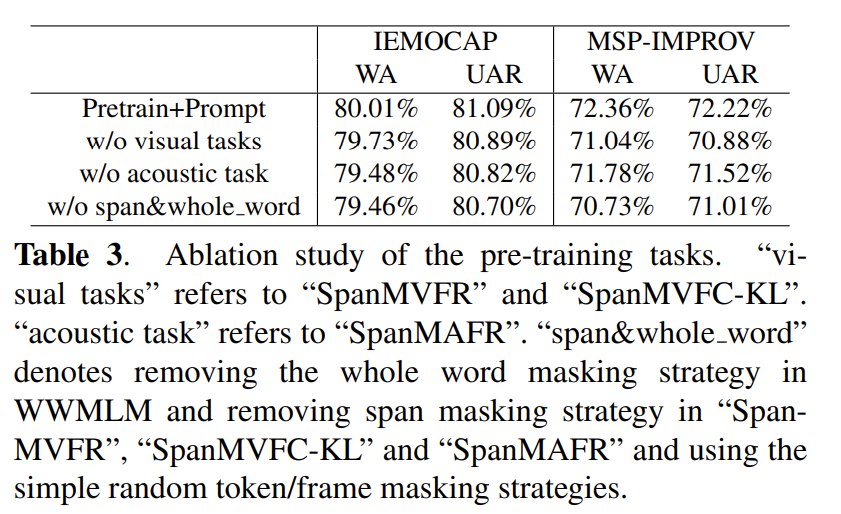
Table 3에서는 논문의 저자가 제안한 pretraining task의 ablation study를 표로 정리하였는데요. 역시나 모두다 적용한 것이 가장 성능이 높고 모든 기법이 사전학습 방식에 도움이 되었다는 것을 확인할 수 있습니다.
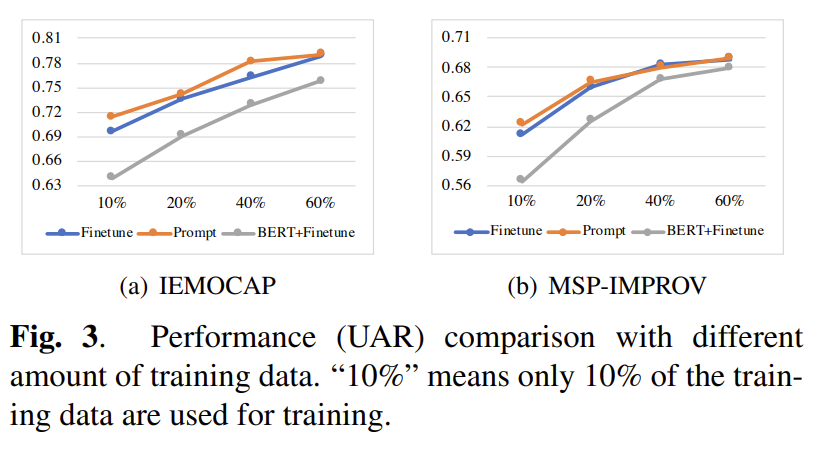
Fig 3에서 training data의 양에 따른 ablation 실험 결과를 확인할 수 있는데요. 여타 다른 사전학습 모델과 마찬가지로 training dataset이 클 수록 성능 또한 상승한다는 것을 확인할 수 있습니다.
이렇게 리뷰를 진행해봤는데요. 사전학습 모델이다 보니 논문에서 설명하지 않는 기법이 많아 읽는데 시간이 오래걸린 논문입니다. bert의 위대함을 다시 느낀 논문이기도 한데요. 이쪽 분야 논문을 읽어보면 bert를 굉장히 많이 사용하는게 보여서 bert에 대해서 다시 정리할 필요성이 느껴지기도 합니다. 이상 읽어주셔서 감사합니다.
좋은 리뷰 감사합니다.
prompt라는 개념이 방대한 양의 데이터로 학습하는 대신, 한정된 데이터로 학습하는 과정 이후 fine-tunning하는 과정의 일부라고 이해했는데 experiment에서 finetune과 prompt가 다르게 표현되어있어 차이에 대해 간단히 설명해주실 수 있을까요? 또 finetune과 prompt를 함께 진행하는 것은 안되는건가요?
감사합니다.
댓글 감사합니다.
gpt에서 finetuning vs few-shot learning에 대해서 말씀드리자면, finetuning은 모델을 학습시키기위한 데이터셋이 별도로 필요하며 파라미터가 업데이트 된다는 단점이 있는데 few-shot learning을 통한 prompt 방법론은 별도의 데이터셋이 필요없다는 장점이 있습니다. (example 몇개만 주기 때문이죠)
finetuning과 prompt를 동시에 사용한다는 것은 생각하지 못했는데 흠…..그렇게 쓰면 안되는 것은 아닌데 제 생각에 둘은 다른 줄기라고 생각되어 동시에 사용하는 것은 보지 못했습니다.
Prompt라는 개념이 결국 SSL의 pretext task랑 일치하는 것 같네요. SpanMVFR를 학습하는 것에 질문이 있습니다. pretext task로 가상의 GT를 만들 수 있는 task를 생성하는 것으로 알고 있는데요. 해당 Task에서는 감정 범주에 분포를 예측하는 학습을 하는데, GT가 없는 데이터로 학습을 하는데 4가지 감정에 대한 분포를 어떻게 계산해서 학습을 수행하나요?
댓글 감사합니다.
아 이 부분은 라벨링 되어 있지 않은 데이터셋이 아닌 IEMOCAP 같은 감정 라벨링이 되어 있는 데이터셋을 사용했기 때문에 가능한 일인 것 같습니다.
감사합니다
좋은 리뷰 감사합니다.
audio encoder 부분에서 각 모달리티에 대한 최종 임베딩이 raw feature, position emedding, type embedding을 합산하여 계산한다고 하셨는데 이는 오디오 뿐 아니라 텍스트와 이미지 모달리티에도 해당되는 건가요? 오디오나 텍스트의 경우 raw feature가 1d, 이미지는 2d로 표현되는데 multi-layer transformer에 입력되는 임베딩의 형태가 각각 어떻게 이루어지는지도 궁금합니다.
댓글 감사합니다.
저도 이 부분이 궁금하지만 정확하게 임베딩 차원에 대해서 논문에서 공개한 것이 없어 알 수 없습니다. 하지만 추측하자면, raw feature, position, type embedding을 모두 sum한다고 하였으니 동일한 차원이라 유추합니다.
감사합니다.