제가 이번에 리뷰할 논문은 Retrieval기반의 위치 인식 논문입니다. 제가 리뷰했던 TransVLAD(논문, 리뷰)를 인용한 논문이라 관심이 생겨 리뷰를 하게 되었습니다. 아직 arxiv에 있지만 찾아보니 CVPR 2023에 Accept된 논문이라 합니다.
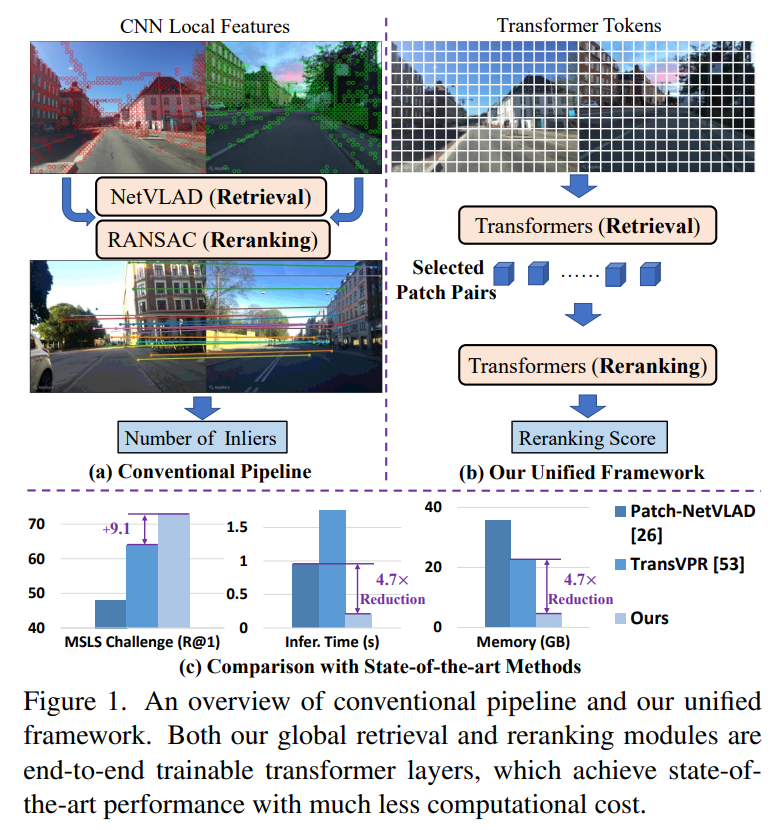
VPR(Visual Place Recognition, 위치인식)은 쿼리 영상의 위치를 파악하기 위해 위치정보가 있는 레퍼런스 영상과 비교하여 유사한 레퍼런스 영상을 찾아 위치인식을 수행하는 테스크입니다. 일반적으로 위치인식은 전체적으로 유사도를 측정하는 과정(=Global Retrieval)과 후보 영상들에 대해 다시 확실하게 순위를 매기는 과정(=Reranking), 2stage 방식으로 봅니다. 이때 기존 방법론들은 주로 Global Retrieval은 CNN featurer를 모아 이용하고, Reranking은 RANSAC기반의 기하학적 특징을 이용합니다. 그러나 RANSAC방식은 기하학적 정보만을 이용하므로 유의미한 정보(local feature간의 관계나 attention value 등 데이터로부터 얻을 수 있는, task에 특화된 정보)는 고려하지 못한다는 한계가 있습니다. 또한, Reranking 과정은 inference 시간이 길어지고 더 많은 메모리 필요하여 실제로 적용하기 어렵다는 문제가 있습니다.
따라서 저자들은 transformer 모델을 이용하여 Retrieval과 Reranking 과정을 통합한 하나의 위치 인식 프레임워크인 R^2Former를 제안하였습니다.
R^2Former의 reranking 모듈은 feature correlation과 attention value, xy 좌표를 입력으로 하여 이미지 쌍을 매칭하는 방식으로, (1)end-to-end학습이 가능하며, (2)reranking 모듈을 다른 네트워크에 적용할 수 있다는 장점이 있습니다. 해당 방법론은 VPR의 여러 주요 데이터셋에서 SOTA를 달성하였으며, MSLS 챌린지에서 SOTA를 달성하였다고합니다.
해당 논문의 contribution을 정리하면 다음과 같습니다.
- Retrieval과 Reranking 과정을 통합한 하나의 위치인식 프레임워크로, vision transformer 토큰을 통해 CNN feature와 유사하거나 더 좋은 Reranking 혹은 local matching을 수행함
- transformer 기반의 Reranking 모듈 제안하여 local feature쌍 사이의 상관관계를 고려한 학습 가능하게 함. 또한 해당 모듈을 다른 CNN이나 transformer 백본과 결합 가능
- 확장실험을 통해 다양한 데이터셋에서 SOTA 달성 및 기존의 Reranking을 활용하는 방식에 비해 inference 시간과 메모리 소비량을 줄임
Method
위의 그림은 R^2Former 파이프라인을 나타낸 것으로 2stage(Retrieval과 Reranking) 방법론입니다. 이제 제안된 방법론에 대해 자세히 다뤄보겠습니다.
1. Problem Formulation and Training Objective
- 쿼리 이미지 Set: \{ I_q \}
- 레퍼런스 이미지 Set: \{ I_r \}
- Global Retrieval: I_q 에 대응되는 positive I_r 의 embedding feature는 가까워지도록, negative는 멀어지도록 학습 (positive는 10m 이내의 이미지, negative는 25m 이외의 이미지로 설정)
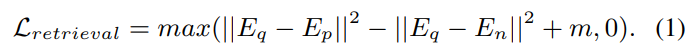
- Reranking: local feature를 입력으로 받아 쿼리-레퍼런스 쌍에 대한 이진 분류(True,False)로 학습 진행.
Reranking을 위해 Global Retrieval 부분은 freeze하고 상위 k개의 샘플에 대해 Reranking 모듈 학습
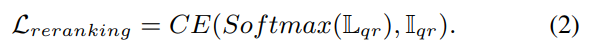
2. Global Retrieval Module
그림 2에서 확인하실 수 있듯이 쿼리와 레퍼런스 이미지는 동일한 Encoder를 공유하며, Global Retrieval을 위해 transformer만을 이용하여 feature와 추가적인 데이터를 추출합니다.
ViT for Place Recognition
이미지를 pxp 패치(p=16을 디폴트로 설정)로 나누어 T∈\mathbb{R}^{n⨉d}개의 토큰으로 변환합니다.위치 정보를 주기 위해 ViT에서 위치정보를 학습할 수 있도록 제안된 position embedding PE∈\mathbb{R}^{(n+1)⨉d} 적용합니다. 여기에 PE에 2D interpolation을 적용하여 입력 해상도가 달라져도 대응할 수 있도록 하였습니다.(해당 논문에서는 640×480로 설정)
Global Attention
본 논문에서는 ViT를 이용하여 Global 상관관계를 모델링합니다. 그림2에서 Transformer의 구조를 확인할 수 있으며(기존의 Transformer 방식과 동일), 수식으로 나타내면 softmax(QK^T/d)V가 됩니다. (Q,K,V는 각각 query, key, value를 나타냄)
Dimension Reduction
마지막 Transformer 레이어의 출력 Class Token을 Linear 레이어를 통과시켜 256 차원의 Global Feature를 생성합니다. (그림2의 파란색에 해당) 또한, output 토큰에 Linear head를 적용하여 128차원으로 줄여 Local Feature를 생성합니다.(그림2의 초록색에 해당) global/local feature는 차원 축소 후 L2 normalization을 적용합니다. 이 과정을 통해 기존 Reranking 기반 방법론들보다 훨씬 작은 차원을 가지게 됩니다.
3. Reranking Transformer Module
다음은 Reranking 과정에 대한 설명입니다.
Attention-based Selection
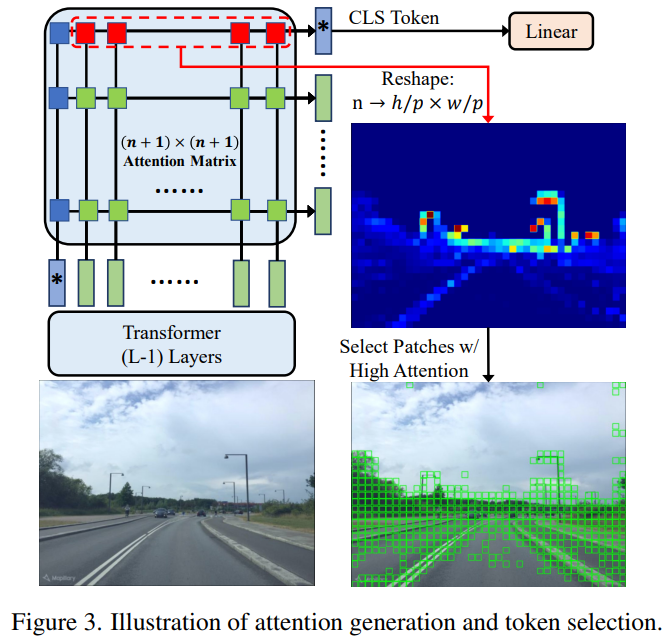
대량의 시나리오에서 local-feature매칭을 수행하기 위해서는 많은 메모리가 필요합니다. 기존 방법론들은 주로 640×480 해상도의 이미지로부터 1200패치 토큰을 만들어 사용하였다고 합니다. 그러나 저자들은 실제로 유의미한 부분은 빌딩이나 나무, 도로와 같이 영상의 일부분이라고 주장합니다. 또한, 기존 방법론들도 여러 크기의 local feature를 이용하거나 추가적인 모듈을 통해 attention을 만들어냈지만 저자들은 앞선 Transformer에서 만들어진 attention map을 그대로 활용하여 약 500여개의 유의미한 local feature만을 사용하여 매모리를 줄이고 파이프라인을 단순화하였습니다.
그림2의 attention map은 입력 토큰에서 출력 토큰에 대해 얼마나 영향을 주었는지 나타낸 것으로, output class(CLS) 토큰은 각 입력 패치가 global feature에 영향을 준 정도를 나타낸다고 합니다.
따라서, token selection은 n차원의 백터를 h/p ⨉ w/p 의 attention map으로 재구성하여 모든 토큰을 정렬하고, 그 중 정보량이 높을 것으로 판단되는 상위 500개의 토큰을 선택합니다. 이렇게 하여, 500개의 토큰에 대해, 131차원(local feature(128) + attention 값과 x,y 좌표(3) = 131)의 feature를 얻게 됩니다.
Correlation-based Reranking
저자들은 보다 정확한 위치인식을 위해서는 local feature의 매칭 정확도를 높여야 하며, 기존의 RANSAC기반의 기하학적 검증 방식은 local feature만을 고려하여 다른 유의미한 정보를 고려하지 못했다고 주장합니다. 따라서 상관관계와 attention, 위치 정보도 포함한 7차원의 정보를 생성합니다.
- (x,y,A,x',y',A',S)
- x,y,x’,y’: 쿼리와 래퍼런스 패치 사이의 위치정보
- A, A’: 쿼리와 래퍼런스 패치 사이의 attention values
- S: 쿼리와 래퍼런스로부터 추출한 128차원의 local feature들 사이의 cosine similarity
즉, 500개의 토큰을 선택햇으므로, 500x500x7의 correlation matrix를 생성합니다.
여기에 연산량을 줄이기 위해 각 토큰에 대해 5개의 최근접 토큰만을 선택하여 500x5x7의 행렬로 변경합니다. 이후 Linear layer를 통과하여 두 행렬을 1000x5x32의 행렬로 변환합니다. 이후 global한 상관관계를 모델링하고자 2개의 Transformer 블록을 통과합니다. 각 블록의 역할은 다음과 같습니다.
- Transformer Block-1: 상위 5개 쌍에서 중요한 정보를 하나의 class token으로 추출
- Transformer Block-2: 1000개의 토큰 정보를 32차원의 벡터로 종합
최종적으로 classification linear head를 이용해 2채널의 값으로 변환합니다.
Experiment
Datasets and Evaluation Metrics
- MSLS Dataset
- Mapillary Street-Level Sequences
- 해당 데이터으로 모델 학습
- 다양한 도시, 시점의 변화, 낮/밤, 계절 변화를 모두 포함한 데이터 셋
- Pitts30k를 이용하여 finetuning을 수행할 경우 도시에서의 성능을 더 향상시킬 수 있음
- Evaluation
- 평가 데이터셋: MSLS의 Val & Challenge set, Pitts30k, Tokyo 24/7, R-SF, St Lucia
- MSLS Challenge는 GT가 제공되지 않는 데이터 셋(리더보드 제출을 통해 성능만 확인 가능)
- 상위 K개에 대한 Recall 성능을 측정(25m를 기준을 정답 판단)
Comparison with State-of-the-art
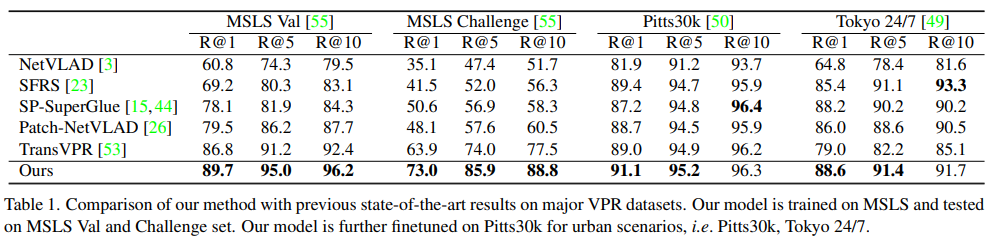
표1을 통해 대부분의 SOTA 방법론들과 비교했을 때 좋은 결과를 얻었음을 확인할 수 있습니다. Top-1과 Top-5에 대해서는 모두 가장 좋은 성능을 달성하였습니다. 저자들이 분석하기로는 Pitts30k와 Tokyo24/7 데이터는 소규모 데이터라 Reranking을 학습하기에는 적절하지 않았고 대규모 데이터셋으로 학습하여 inference하는 것이 더 좋았다고 합니다. (이는 supplementary를 참고하라 하였으나 아직 공개 전이라 그런지 자료를 찾지 못하였습니다. CVPR 논문이 공개되면 추후 업데이트하도록하겠습니다)
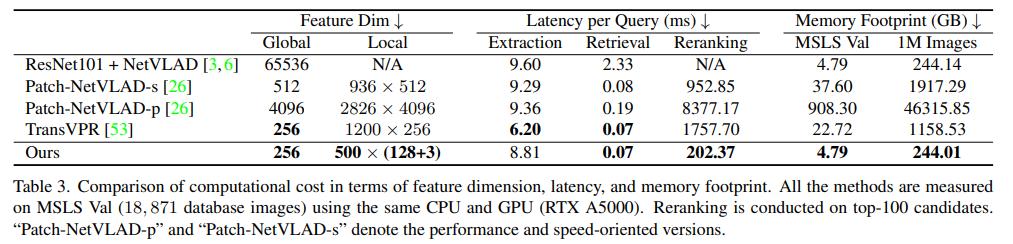
위의 표3은 연산량을 비교한 것으로, 기존의 방법론들과 비교했을 때, 차원수도 줄었고, inference time도 대체로 감소하였으며 메모리 사용량도 크게 감소하였다고 합니다.(메모리의 경우, NetVLAD는 reranking 과정이 없다는 점을 감안하여 표를 확인해주시기 바랍니다.)
Ablation Study
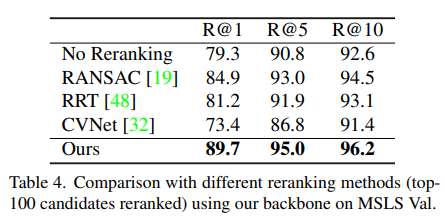
표4는 저자들의 방법론에서 Reranking을 다양하게 바꾸어 실험한 결과로, 기존 방법론들 중에서는 RANSAC이 가장 좋은 효과를 보였으며, 저자들이 제안한 방법론을 적용할 경우 상당한 성능 향상이 가능함을 실험적으로 증명하였습니다.
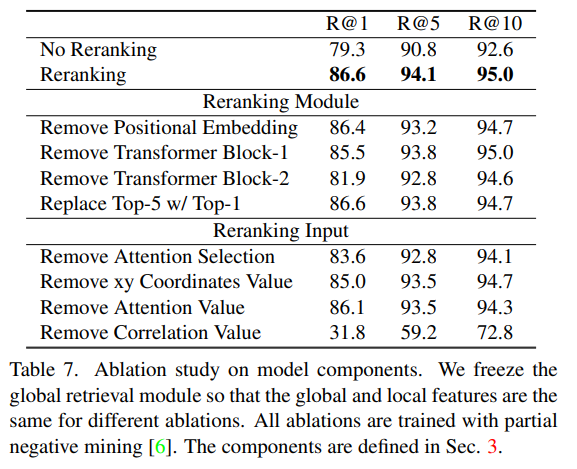
표7은 각 구성요소에 대한 ablation stuyd로 global retrieval 부분은 freeze하고, reranking 모듈 부분에 대해서 다야한 변화를 주어 실험을 진행한 것입니다.
Visualization
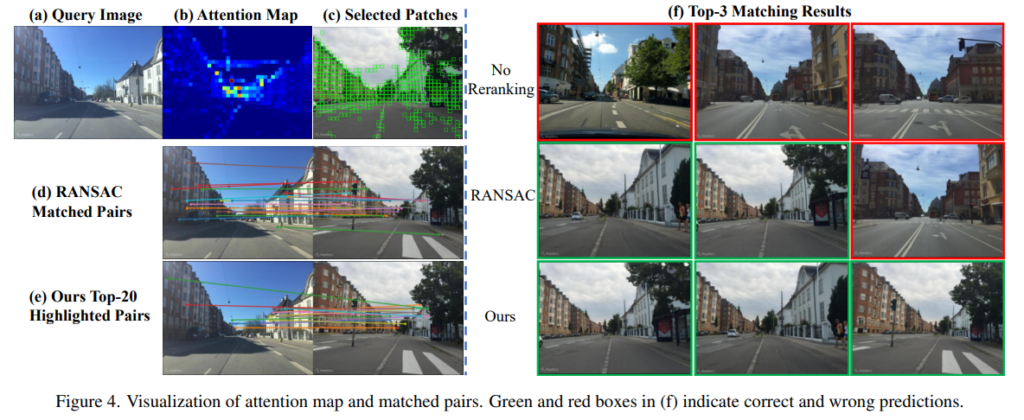
위의 그림은 결과를 시각화한 것으로, (f)에 해당하는 이미지들은 상위 3개 이미지에 대한 결과로, RANSAC에 비해 저자들이 제안한 방식이 더 강인하게 잘 작동하였다는 것을 확인할 수 있습니다. 또한, (d)와 (e)를 통해 매칭쌍을 시각화한 것인데, 저자들이 이야기하기로는 ours 방식이 덜 타이트해보이지만, RANSAC과는 다른 정보를 이용하여 매칭을 진행하였다고 합니다. Reranking 과정의 Transformer Block들에 대한 시각화가 있었다면 더 좋았을 것 같다는 생각이 들었습니다.
Top-500 토큰 뽑아서 쓰는건 정성적인 결과로 찾아낸 것 같은데, 데이터셋마다 그 수치가 달라질 것 같습니다. (유의미한 영역이 나오는 분포가 달라지므로) 이 방식에 대한 ablation study는 따로 없나요? 그리고 정보량이 높다는 것은 attention map에서 값이 높은 영역을 말하는 것인가요? 추가적으로 비교 실험에서 Feature 크기 차이가 꽤 나는것 같은데… Retrieval에서 이 크기 때문에 속도 차이가 꽤 발생할 것 같은데요. 혹시 이에 대한 추가 분석은 없나요?
토큰의 개수에 대한 ablation study는 따로 없었습니다. 말씀하신 대로, 데이터의 분포에 따라 선택될 토큰의 개수를 변경하는 것이 좋아보이지만, 해당 논문의 경우에는 모든 데이터에 대해 500으로 고정하여 실험한 것으로 보입니다. 추후 supplementary를 보고 해당 내용이 있을 경우 업데이트 하도록 하겠습니다.
또한 정보량이 높을 것으로 예측된다는 것은 attention map에서 높은 값을 지는 영역으로, global feature에 영향을 많이 준 영역을 정보량이 높을 것으로 판단한 것으로 이해하였습니다.
마지막으로, 해당 실험 결과는 속도를 줄이기 위해 중요한 local feature만을 저장하였다는 것을 보이고자 한 것으로 이해하였습니다. 의미하신 추가 분석 내용은 아니지만, 저자들은 자신들이 제안한 방법론이 여러 Reranking 방식(RANSAC 등)과 비교했을 때, 시간도 짧고, straightforward방식이므로 실제로 적용을 한다면 병렬적으로 GPU를 이용하여 지연시간을 크게 단축할 수 있을 것이라는 주장이 있었습니다.
안녕하세요. 좋은 리뷰 감사합니다.
기존의 retrieval과 reranking을 융합하여 새로운 방법론을 제안했다는 것에서 대단함이 느껴지는 논문이네요. 질문이 있는데,
1) 2.Global Retriveval Module 파트에서 쿼리와 레퍼런스 이미지가 동일한 encoder를 공유한다는 것이 동일한 구조의 encoder를 사용한다는 걸까요 아님 encoder의 파라미터도 공유한다는 의미일까요?
2) attention map을 활용하여 유의미한 local feature를 사용했다는 것은 attention map에서 값이 높은 것을 의미하는 건가요?
3) 데이터셋 마다 이미지의 크기가 다를 것이고 그것에 따라서 attention map 사이즈도 다를 것 같은데요. 그러면 어떤 데이터셋에서는 local feature 500개 만으로는 유의미한 정보를 뽑아내지 못할 수도 있을 거 같은데 논문에서 이것과 관련하여 언급한 것은 없을까요?
감사합니다.
1) 네 맞습니다. 동일한 모델로 레퍼런스와 쿼리 영상의 feature를 추출하는 것이므로 동일 파라미터를 공유한다는 의미로 이해하였습니다.
2) 넵 맞습니다. global feature에 영향을 많이 준 영역을 정보량이 높을 것으로 판단한 것으로 보입니다.
3) 논문에서는 500개를 이용한 것에 대해 아래와 같이 단순하게만 언급하였습니다. 말씀하신대로 데이터셋에 따라(retrieval 테스크에 따라) 선택하는 local feature의 개수를 실험적으로 선택하는 것이 좋을 것 같습니다.
“On the contrary, we leverage the natural attention map within our transformer module and only save a fixed number of local features (e.g. 500) with top attention values, resulting in a much lower memory cost and simpler extraction pipeline.”
좋은 논문 리뷰 감사합니다.
이해하기 쉽게 설명해주셔서 큰 어려움 없이 읽었습니다. 간단한 질문드리자면 위치인식 task에서 본 논문이 global retrieval과 reranking을 end-to-end로 하는 최초의 모델인가요? 그리고 local features를 500말고 다른 갯수로 실험한 ablation은 없나요?
감사합니다.
우선 해당 논문이 처음으로 global retrieval과 re-ranking을 end-to-end로 한 것은 아니며, 해당 논문의 방법론도 안정적으로 모델을 학습하기 위해 초반에는 global retrieval과 re-ranking 을 각자 학습한 뒤, 일정한 수준을 달성한 뒤, end-to-end로 성능을 향상시켰다고 합니다.
참고로 TransVPR도 end-to-end로 학습된 방법론입니다.(TransVPR 리뷰를 참고해주세요. ) 또한, 해당 논문에서는 TransVPR과의 차이점에 대해서 TransVPR은 feature extractor가 CNN으로 구성되지만, 저자들은 Transformer만을 이용하였다는 점을 제시하였습니다.
또한, local feature의 개수에 대한 ablation study는 논문에서 확인할 수 없었습니다. supplementary가 공개될 경우 확인해보고 있다면 알려드리도록 하겠습니다.
좋은 논문 리뷰 감사합니다.
reranking을 한번에 수행하는 방법론이 SOTA 달성할만하지 않은가 했는데
Transformer랑 결합되어 나왔네요.
전반적인 부분에 대해서는 이해가 가는데 reranking 학습 부분에서 의문점이 드는 부분이 있습니다.
local 측면에서 matching 여부에 대한 GT를 어떻게 제공해주고 있나요?
이야기하신 내용이 re-ranking loss의 Crossentropy loss를 의미하시는 게 맞을까요?
matching 여부는 Re-ranking을 수행하는 이미지들이 실제로 positive일 경우와 실제 negative일 경우가 GT로 들어갑니다.