제안서를 쓰고 돌아오니 CVPR 2023 accepted paper 리스트가 공개되었더라고요. 또 시즌이 되었습니다. 재밌는 논문이 뭐가 있을까 찾아보다가 하나 잡아서 들고온 논문인데요. MAE인데 비디오라서 하나 들고와봤습니다.
Introduction
계속해서 Self-Supervised Video Representation Learning 관련 논문을 리뷰하고 있어서 다들 이제는 익숙해 지셨을 것 같은데요. 왜 중요한지는 다들 아실테고… 학습 자체의 어려움으로는 두가지를 꼽습니다. 첫째로는 비디오의 특성 때문에 비싼 라벨링 비용으로 데이터셋 자체를 만들기 어렵다는 것이고, 두번째로는 spatial-temporal한 콘텐츠가 대용량 데이터셋에서는 한번에 표현되기가 어렵다는 점입니다.
이러한 어려움을 해결하기 위해서 되게 많은 해결책이 도전되어왔습니다. Transformer는 당연하고, VAE도 적용되어져왔고, Mask를 이용하는 방식도 당연히 시도되어왔습니다. 하지만 이러한 시도들도 당연히 (이 논문이 나왔을테니까) 한계는 있었는데요.
첫번째로는 기존의 MAE를 잘 생각해보면 됩니다. 신정민 연구원님이 MAE 관련된 리뷰를 몇개 쓰셨는데 그걸 읽어보셨다면 딱 이해가 갈텐데요. 이미지 MAE에서는 마스킹 비율이 매우 높아도(대략 85%) 매우 잘 복원된다는 것을 생각하면 됩니다. 이러한 특성이 비디오와 결합되면, 모델이 프레임간의 temporal한 정보를 고려하지 않아도 없으면 없는대로 프레임(이미지) 내의 정보만으로 복원을 합니다. 그래서 temporal한 정보가 중요한 비디오의 특성 하나를 학습하지 않게 됩니다.
두번째로는 프레임들이 고정된 크기의 stride를 가지고 너무 sparse하게 샘플링 된다는 점입니다. 이 경우에는 fine-grained한 모션 디테일을 학습할 수 없어 액션을 구분하는데 문제가 생긴다고 하네요.
*문제가 생기는 이유 : 데이터셋을 잘 보면 같은 공을 던지는 액션인데 크리켓/야구 정도로 구분될 정도로 비슷한 액션이 있기 때문
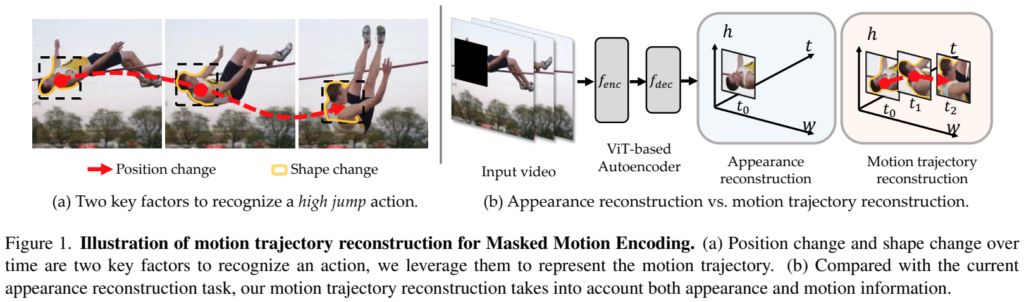
그래서 본 논문에서는 새로운 mask-and-predict 이론을 디자인해서 이 문제를 해결하는데요. [그림 1]은 이 문제의 새로운 해결 방향을 보여줍니다. (a)를 보면 “Position change”와 “Shape change”를 표현하는 것을 볼 수 있는데요. 이 논문에서는 이렇게 액션을 모델링 할 때 중요한 키 포인트로 이 두 변화를 잘 학습하면 된다고 판단했습니다.
이러한 관측에 따라, mask-and-predict task를 위해 곧 임박한 position and shape 변화를 나타내는 motion trajectory(움직임 궤적)을 예측하는 것을 제안했습니다. 특정 포인트를 dense grid를 이용해서 샘플링하고, 이 포인트를 optical-flow를 이용해서 트래킹합니다. (그림에서 Shape change라고 되어있는 영역을 트래킹하는데, 이 부분이 액션을 구분하는데 핵심 영역이 된다고 이해하면 됩니다.) 그럼 이 영역은 상대적인 움직임을 표현하는 position feature와 궤적에 따라 변화한 모양 변화를 표현하는 shape feature를 모두 표현하는 영역이 됩니다.
결론적으로 이 논문에서 제안하는 것은 motion trajectory를 학습하기 위한 MME(Masked Motion Encoding)을 제안하는데요. 이 인코딩은 마스킹된 영역이 무엇인지도 학습하고, 프레임간의 상관관계도 학습해서 움직임도 추정할 수 있는 모델입니다. 추가적으로 모델이 좀 더 fine-grained한 모션 디테일을 학습할 수 있도록 motion trajectory를 interploate하는 것도 제안합니다.
그래서 요약하면 아래와 같은 것을 제안하는데요.
- 기존의 방식들이 Temporal한 정보를 학습하기 어렵지만, MME(Masked Motion Encoding)는 할 수 있다!
- Motion interpolation을 통해서, 보다 더 세분화된 움직임을 학습할 수 있다!
라고 하고, 벤치마크 결과에서도 좋은 성능을 보였다고 합니다.
Proposed Method
Rethinking Masked Video Modeling
비디오로부터 샘플링된 클립이 입력으로 주어졌을 때, f_{enc}(\cdot)은 비디오를 최대한 잘 설명할 수 있는 feature를 학습하는 것을 목표로 합니다. 기존의 masked video modeling은 겹치지 않는 3D 패치들로 클립들을 분할하고, 이 패치들에서 랜덤으로 마스킹을 취해서, 남은 부분들을 encoder에 넣고 decoder f_{dec}(\cdot)는 이걸 복원하기를 기대합니다. 문제는 서론에서도 언급했다시피, MAE에서 85%를 마스킹해도 복원을 잘 해버린다는 문제가 있습니다. 이러한 문제로 이렇게 마스킹을 해도 프레임 내의 콘텐츠 만으로 복원하도록 모델이 학습됩니다. 오히려 temporal 정보를 활용하는 것을 방해하는 것이죠.
General Scheme of MME
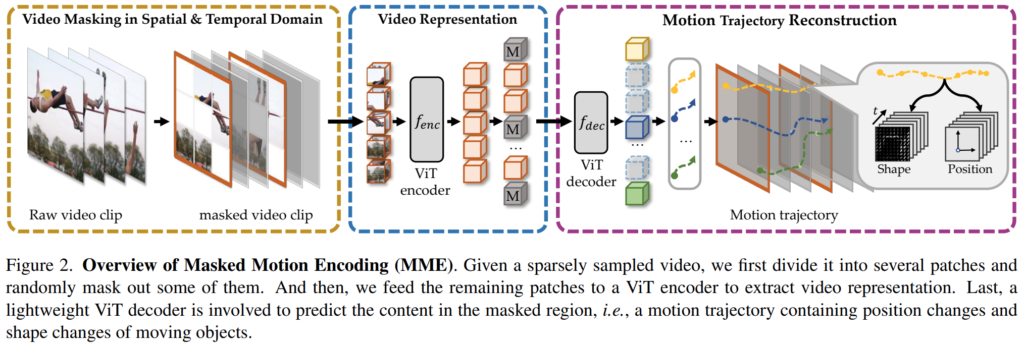
그래서 서론에서 언급했던 것 처럼 motion trajectory를 학습할 수 있는 모델 구조를 설계하였는데요. [그림 2]를 보면 전반적인 MME의 구조를 볼 수 있습니다. 먼저, 비디오에서 샘플링된 클립으로부터 겹치지 않는 3D 패치(t\times h\times w)를 만듭니다. 마스킹 전략은 tube masking strategy를 사용하는데요. 이 전략은 모든 프레임 내에서 동일한 마스킹 맵을 유지하는 방법입니다. 그리고 계산 효율성을 위해 모델의 입력에는 마스킹 되지 않은 패치들과 위치 정보만을 encoder의 입력으로 넣습니다. 인코더의 output은 마스킹된 패치들의 motion trajectory z를 복원하기 위해 디코더에 입력으로 들어갑니다.
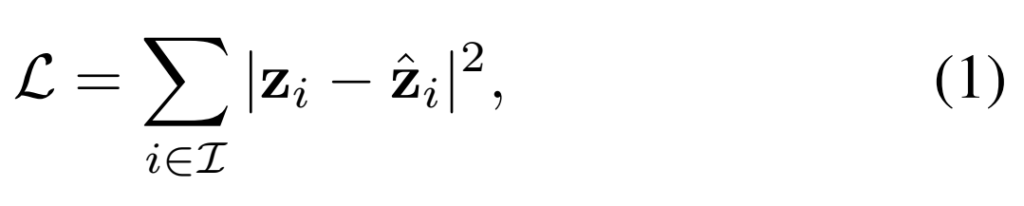
학습 Loss는 위의 그림과 같이 모든 마스킹된 패치의 인덱스(I)와 예측된 motion trajectory \hat{z}의 차이를 계산하는 식으로 구성됩니다.
결국은 인간이 액션을 인식할 때의 방식에서 영감을 받아, position change와 shape change라는 정보를 motion trajectory라는 이름으로 활용합니다. 이를 통해서 모델은 temporal clue를 활용할 수 있게 되는데요. 이 다음으로는 이제 fine-grained한 모션 정보를 담고있는 motion trajectory에 대한 자세한 이야기를 해봅시다.
Motion Trajectory for MME
움직임을 표현하는 방식은 매우 다양합니다. 비디오 연구에서 자주 쓰이는 optical flow도 대표적인 예시죠. 하지만 이러한 방식들은 매우 짧은 구간의 움직임 정보만을 표현합니다. (Optical flow가 결국은 지금 프레임과 이전 프레임의 차이를 계산하는 것이죠? 이런 맥락에서 이렇게 표현하는 것 같네요.) 그래서 본 논문에서는 좀 더 긴 모션 정보를 표현하는 방법이, 비디오 표현에 더 좋지 않을까라는 생각으로 새로운 움직임 표현 방식을 씁니다.
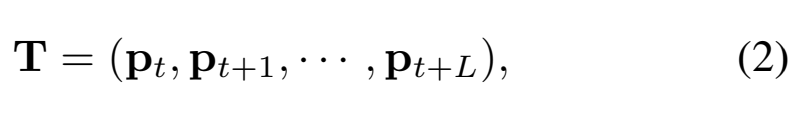
사실 기본적인 방법은 DT라는 2013년에 나온 방법론을 따르는데요. 자세한건 뒤에서 설명하고 여기서 필요한 수식은 [수식 2]를 보면 되는데요 L개의 프레임을 커버하는 탄도or궤적(trajectory) T를 만드는데요. T를 만들기 위해서 p_t를 L개만큼 모읍니다. 이 p_t는 이제 (x_t, y_t)로 좌표이고, 이 좌표들을 모으는건데요.

이러한 궤적 정보들에서 position feature z^p와 shape feature z^s를 만들고, 이 feature들을 모아서 [수식 3]과 같은 motion trajectory z를 만드는 것이 목표입니다. position feature는 이제 이전 프레임으로부터의 상대적인 움직임 변화를 나타내고, shape feature는 트래킹 중인 물체(여기서는 [그림 1]의 사람 박스라고 보면 됩니다)의 HOG descriptor로 생성합니다. T에서 z로 가는 부분이 좀 연결성이 없게 느껴지는데, T는 이제 프레임 끼리에서 물체를 트래킹한 정보들을 모은거고. z는 T에서 얻어진 정보를 이용해서 이 모델에서 사용할 두 feature를 계산했다고 정리하면 될 것 같네요.
Tracking objects using spatially and temporally dense trajectories
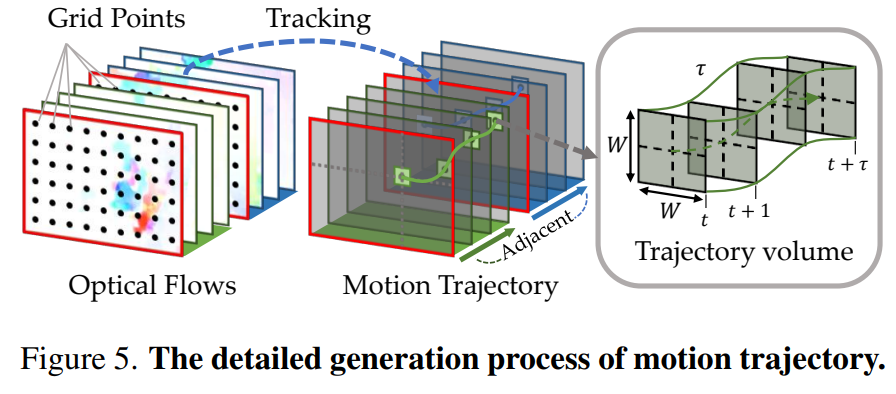
이 논문에서 DT를 베이스라인으로 삼았는데요. DT는 프레임 내에서 그리드 포인트들이 고정되어 있고, 이 포인트에 feature들이 존재하는데 이 정보로 트래킹을 하는 방법론입니다. 이해가 어려울 것 같아서 supplemenatry에 있는 [그림 5]를 가져왔으니 보시면 대충 어떤 느낌인지 이해가 가시리라 믿는데요. 이 방법을 쓰는 이유는 결국은 트래킹 성능이 더 좋다고 합니다. [그림 5]를 보면 빨간색 프레임이 표시된 것인데, 이 프레임들이 샘플링된 프레임이고 그 사이에 보간된 모션 정보를 모델이 예측하도록 학습을 수행해서 보다 세밀한 움직임 정보를 학습에 이용할 수 있도록 했다고 합니다.

당연히 이 방식으로 추적하는게 완벽하지는 않다고 합니다. [그림 6]이 예시인데, 논문 저자가 대부분의 비디오를 분석해본 결과, 추적 해야하는 물체가 카메라 시야각 밖에서 움직이는 경우가 많았다고 합니다. 이 경우에는 당연히 부정확한 결과 값이 나오게 되는데요. 학습 과정에서 이러한 결과를 배제할 수 있는 Mask를 하나 만들어서 BCE Loss를 하나 추가로 설계해서 붙여서 학습했다고 합니다.
Representing position features
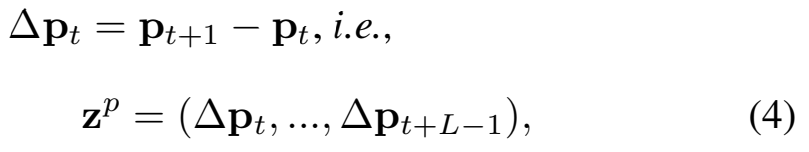
궤적 정보 T가 주어졌을 때, position feature는 이 궤적 정보 안의 포인트들의 상대적인 움직임으로 계산합니다. [그림 4]와 같이 \Delta p_t는 이제 앞뒤 포인트의 차이를 통해 계산하고, position feature z^p는 \Delta p_t를 concat하면 됩니다. 좌표 형태기 때문에 결국 z^p는 L \times 2의 shape를 가집니다.
Representing shape features
Shape feature는 HOG feature를 사용합니다. HOG는 저희 연구실 사람들이라면 다들 아시겠죠? ㅎㅎ;; 기존 연구들에서는 각 프레임의 HOG를 재구성하는 방식을 사용했지만, 여기서는 trajectory-aligned HOG라는 것을 사용합니다. 이건 이제 궤적안의 포인트들이 있는데 그 포인트들의 HOG를 모은 것이라고 보면 됩니다.
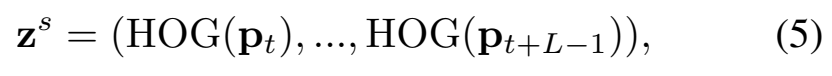
수식으로는 [수식 5]와 같이 계산하는데요. 이러면 1개의 패치가 K개의 궤적을 가지는 상태에서 trajectory-aligned HOG를 모두 concat 해줘서 shape feature z^s를 만듭니다.
Experiments
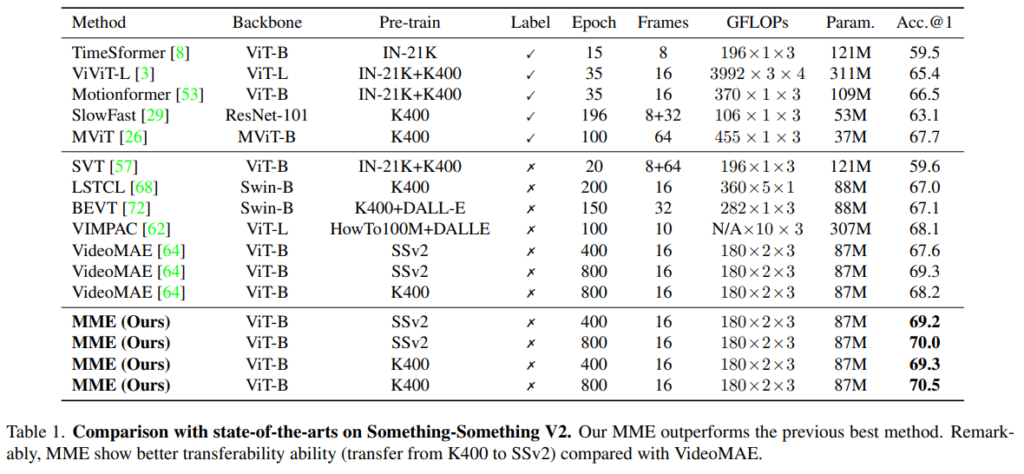
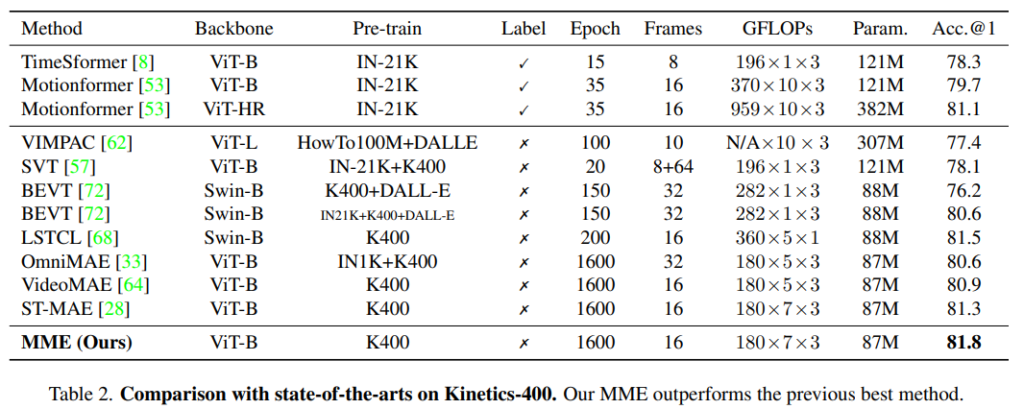
대표적인 두가지 데이터셋에서의 벤치마크 성능을 먼저 보겠습니다. 같은 데이터셋끼리 비교를 하면 되는데요. 요즘 한창 인기인 MAE의 대표적인 비디오 방법론인 VideoMAE와 비교해도, 동일한 학습 세팅을 유지해도 정확도가 2%~1%나 상승했습니다. [표 1]에서 K400으로 학습하고 SSv2로 평가하면 더 성능이 좋은 것을 볼 수 있는데요. 이건 논문이 텍스쳐 정보를 학습하는 대신에, 시간적인 정보를 주로 학습해서 일반화 성능이 더 좋아졌다고 보면 될 것 같습니다. 학습도 3090 16장에서 한걸 보니 생각보다 어마어마하진 않네요.

UCF랑 HMDB는 너무 쉬운 데이터셋이라 넘어가고… SSv2가 뭔가를 하는 행동을 촬영한 데이터셋이라 motion 정보에 매우 의존적입니다. 이런 상황에서 기존의 방법론보다 훨씬 더 높은 성능을 보이는 것을 [표 4]를 통해 확인할 수 있는데요. 논문에서 제안하는 MME가 시간에 따른 움직임 정보를 더 잘 학습했다는 것을 보여줍니다.
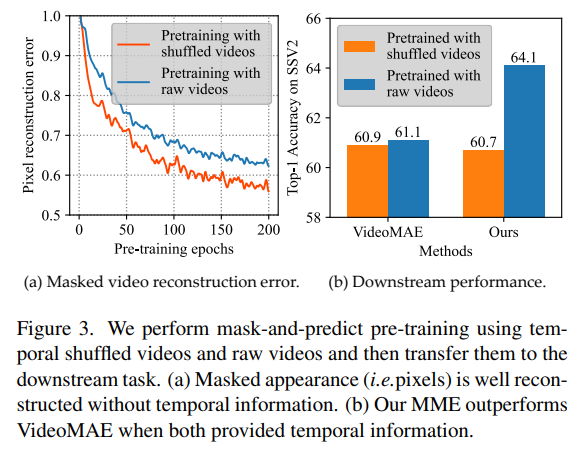
[그림 3]은 증명 실험인데요. 입력 영상의 프레임을 셔플해서 학습시켜본 결과입니다. 서론에서 MAE 방식대로 학습하면 복원이 단일 프레임 내의 정보만을 이용해서 학습된다고 설명했었는데요. 만약 셔플을 통해서 시간 정보가 깨지면…? 그럼 제안하는 방법론에서는 학습이 잘 안되고 기존 방법론에서는 큰 차이가 없어야겠죠? 이에 대한 결과를 잘 보여주는 실험입니다. 기존 방법론(VideoMAE)에서는 역시 큰 차이가 없지만, 제안하는 방법론에서는 성능 차이가 크게 발생합니다.
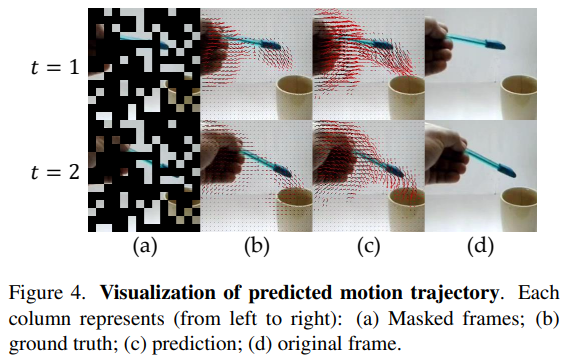
Abalation에 대한 내용도 많은데, 너무 많아서 관심 없으실 것 같아서 넘어가고 Visualization 결과 마지막으로 올리고 리뷰 마무리 하겠습니다. 한창 연구중인 분야라서 그런지 방법론이 쉬워서 리뷰 자체는 짧은데. 역시 아이디어 싸움 같습니다. 기존에 증명되었던 정보(시간적인 정보는 비디오에서 중요하다)를 잘 적용해서 새 분야에서 성능을 올린 논문 같은데, 연구할 때 항상 잘 생각해야겠습니다.
좋은 리뷰 감사합니다.
쉽게 풀어서 설명해주시니 이해하는데 큰 도움이 되네요.
간단한 질문하자면, intro 부분에서 MAE의 문제를 지적할 때 frame들이 고정된 크기의 stride를 가지고 sparse하게 샘플링된다고 하셨는데 고정된 stride를 가지는 것이 어떻게 sparse하다고 여겨지는 것인지 조금 더 설명 가능하실까요? shape change도 grid형태로 샘플링하는 것 같은데 어떤 차이가 있는지 궁금합니다!1
감사합니다.
비디오라서 sparse 하다는 뜻은 프레임을 sparse하게 사용한다는 뜻입니다. 일반적으로는 초당 1프레임씩만 쓰는데, 아무리 프레임끼리 중복이 있다고 해도 모든 프레임을 쓰는게 성능이 더 잘나오긴 하거든요. Shape change가 grid(네모) 형태인건, MAE에서 마스킹할 영역을 액션과 연관있는 핵심 영역으로 한정짓기 위한 방법이라고 보면 됩니다.