기존 3d object detection 방법론들에서는 object의 foreground surface geometric 정보를 충분히 사용하지 못했다. 본 논문에서는 voting방식을 기반으로 하는 RBGNet을 제안한다. 이름에서 알 수 있듯이 ray를 생성하여 feature grouping하는 module을 제안하고 foreground biased sampling strategy를 통해 object 표면의 foreground points를 이용하여 더 의미있는 정보를 얻고자하였다. 그리고 ScanNet V2와 SUN RGB-D에서 sota 성능을 달성하였다.
Introduction
3d object detection은 autonomous driving , AR, robot과 같은 다양한 분야에 적용되고 있다. 기존의 많이 발전해온 2d image에서 regluar한 input data를 통한 문제와는 다르게, 3d scenes는 unordered하고 sparse하며 irregular한 형태의 3d point cloud로 구성되어있다. 기존 3d object detection 방법론은 크게 data 표현 방법에 따라 grid-based와 point-based 두 가지로 나눠진다. grid-based 방법론은 irregular한 3d point를 regular한 형태의 3d voxel로 변환하거나 2d bird’s eye view map으로 변환하여 사용하는 방법이다. point-based 방법론은 point를 다른 처리를 거치지 않고 그대로 사용하는 방법으로 대표적으로 pointnet이 있다. point-based 방법론에서는 point-wise features를 추출하여 grouping을 하게되는데, 이 grouping하는 방식에서 surface geometic 정보를 얻는 방법에 대한 연구가 아직 부족하다고 저자는 주장한다. 저자는 feature grouping module이 point-based 3d detectors에서 중요한 역할은 한다고 주장하며 더 나은 3d bounding box 예측을 할 수 있다고 한다.
본 논문에서는 one-stage 3d detector인 RBGNet을 제안하며 raw point cloud를 입력으로 한다. votenet을 기반으로 하며, foreground object features를 학습하여 성능을 향상시키기 위해 두 가지 새로운 전략을 제안한다.
먼저 ray-based feature grouping을 제안하여 foreground object의 더 나은 기하학적 표면 정보 feature를 학습할 수 있도록 한다. 이때 rays는 아래 Figure 1처럼 cluster center로 부터 일정한 각도를 간격으로 uniform하게 방출된다.
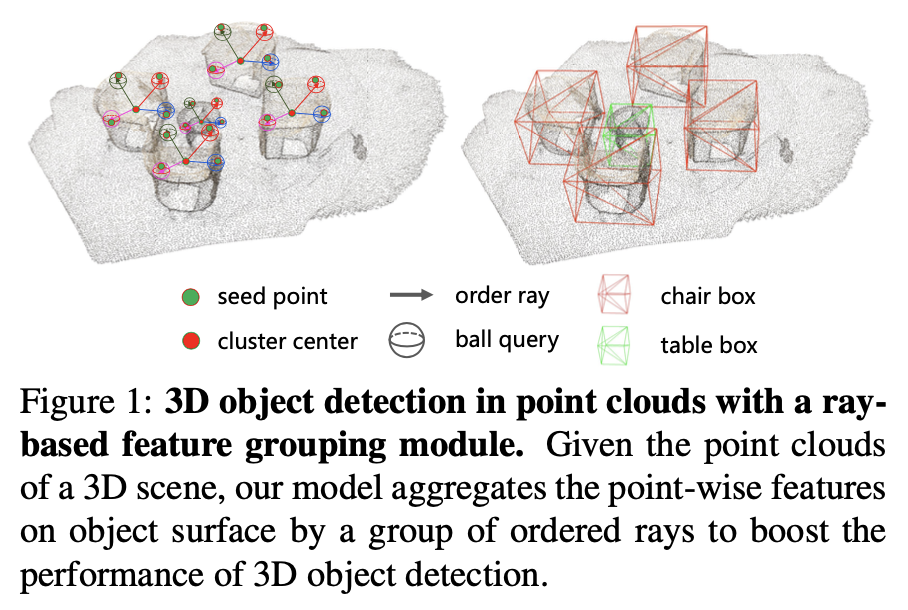
ray의 경계는 검출하고자 하는 object scale에 따라 정해지며 각 rays에서 anchor points가 sampling된다. 또한 coarse-to-fine strategy를 제안하여 영역에 따라 서로 다른 density의 point를 가질 때 서로 다른 anchor points를 generate하도록 했다.
그리고 foreground biased sampling strategy를 제안하여 3d box를 예측할 때 더 많은 foreground object points를 할당하고자 하였다. 저자는 farthest point sampling을 foreground points들에만 적용했을 때 성능이 약 10% 가량 향상된 것을 근거로 3d bounding box를 예측할 때 object surface에 존재하는 points들이 background points들보다 유용하다고 주장한다. 따라서 간단하면서 전체 scene의 범위를 포괄할 수 있는 효과적인 object surface point biased sampling을 제안한다. 특히 farthest point sampling을 하기 전에 segmentation head를 추가함으로써 각각 points가 foreground point인지 여부를 판단하는 confidence score를 구하게 된다. 이 score에 따라 foreground set과 background set 두 가지로 나누어진다. 이 두 가지 sets에 각각 farthest point sampling이 적용되며 논문에서는 87.5%의 foreground set과 12.5%의 background set을 포함시켜 전체 scene을 cover할 수 있도록 했다.
본 논문에서의 contribution은 아래와 같다.
1. 새로운 ray-based feature grouping module을 제안하여 ray에서 object surface point를 encode
2. foreground biased sampling module을 통해 foreground surface points에서의 feature에 focus
3. ScanNet V2, SUN RGB-D에서 sota 달성
Related Work
3d object detection은 3d point의 irregular, sparse하며 순서가 없이 입력되는 특징때문에 challenge한 요소가 많다. 따라서 존재하는 방법론들은 크게 grid-based와 point-based로 나누어서 문제를 해결한다. 앞에서 말했던 것처럼 grid-based는 regular한 voxel형태로 변환하여 처리하는 방식이고, point-based는 raw point cloud를 그대로 사용하는 방식이다. 본 논문에서 제안하는 RBGNet도 raw point cloud를 입력으로 하는 point-based 방법론이고 feature grouping을 할 때 사전에 정의된 ray에서 object shape 분포를 학습하여 3d detection의 성능을 높히기위해 사용한다.
point cloud sampling을 하는 이유는 너무나 많은 original point cloud를 sparse하게 만들기 위해서이며 detection 성능의 중요한 역할을 한다고 할 수 있다. 기존에는 pooling과 비슷한 역할로 Farthest point sampling(FPS)가 널리 사용되었다. FPS는 가장 먼 points들은 unidorm한 분포로 sampling하는 방식이다. 하지만 FPS는 object를 구성하는 중요한 역할을 하는 points들이 sampling되지 않는 경우가 있기 때문에 downstream task를 할 때 좋은 결과를 내는데 한계가 있다고 한다. 본 논문에서는 foreground biased sampling(FBS)를 통해 object surface에 있는 points들에 집중하여 sampling하는 방식을 적용하였다.
Methodology
RBGNet은 one-stage 3d object detection framework로 irregular한 point cloud로부터 더 정확한 bounding box를 예측하기 위해 고안된 모델이다. RGBNet은 크게 3가지 components로 나눌 수 있다. 1)backbone network with foreground biased sampling을 통해 point cloud에서 feature를 추출하고 2)ray-based feature grouping module을 통해 object surface의 points를 포착하여 shape distribution을 학습하고 3)proposal and classification module을 통해 downstream task를 할 수 있다. 본 논문에서는 sampling과 grouping하는 module에 focus를 맞추었고 box proposal과 classification하는 방법은 votenet과 동일한 방법을 적용하였다.
RBGNet의 전체적인 architecture는 아래 Figure 2와 같다.
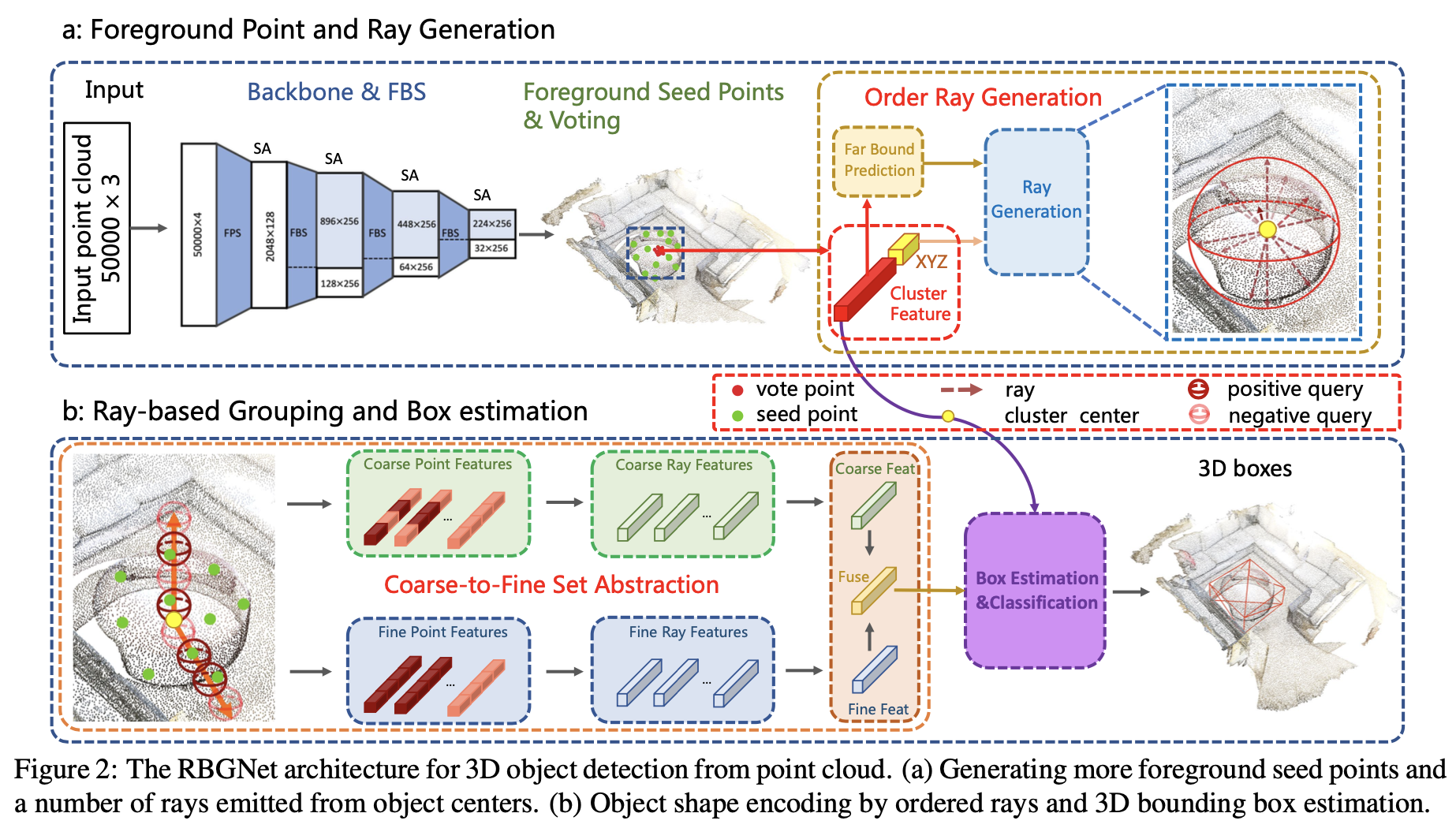
Ray-based Feature Grouping
votenet은 3d object detection에서 좋은 결과를 보였다. pointnet++ backbone을 통과한 seed points들이 voting방식으로 object가 있을만한 candidates의 center를 투표하여 grouping하게된다. 이렇게 합쳐진 features들이 3d bounding box를 예측하는데 사용된다. 이때 grouping하는 방법이 detection 성능에 중요한 역할을 한다고 한다. 따라서 본 논문에서는 ray-based feature grouping module을 제안하여 object shape의 분포를 효과적으로 encoding하고 더 나은 object feature를 학습하여 detection 성능을 향상시켰다.
Ray Point Representation
우선 rays들을 사전에 지정해준다. votenet에서 vote sampling과 grouping을 통해 나온 vote cluster centers {ci}i=1M(ci = [vi , fi], vi: vote center, fi: features, M: N of vote clusters)를 얻을 수 있다. 그리고 각 vote cluster마다 N개의 rays가 cluster center로부터 정해진 angle과 간격을 두고 uniform하게 나오게된다. 아래 Figure 3에서 spherical coordinate system에 기반한 ray generate 방법을 알 수 있다. 간단히 말해서 구 위에서 어떤 규칙을 가지고 ray를 생성하는 것이다.
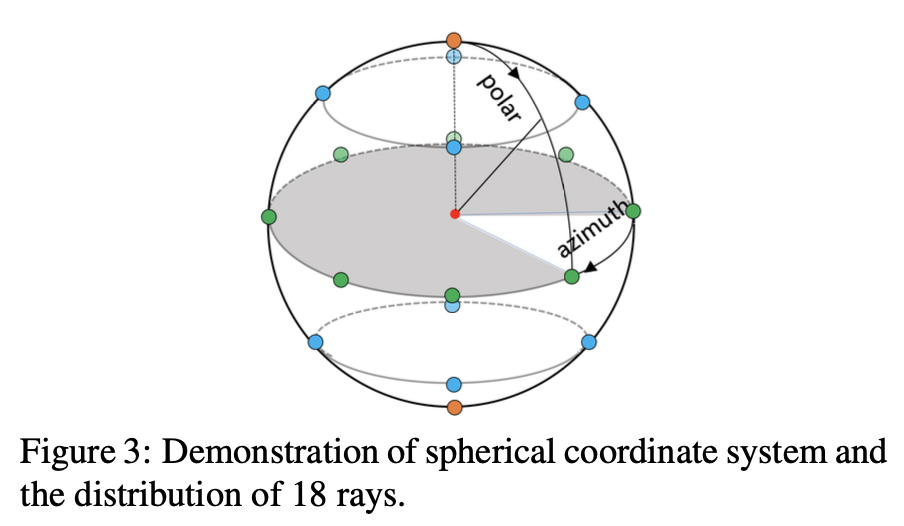
아래 수식 (1)을 보면 z축으로부터 떨어진 각도를 의미하는 polar angle은 P개의 bins로 나뉘어 z축과 수직하는 구와 만나는 표면으로 나눌 수 있다. 위의 Figure 3에서는 bin이 5개인 것을 확인할 수 있다.
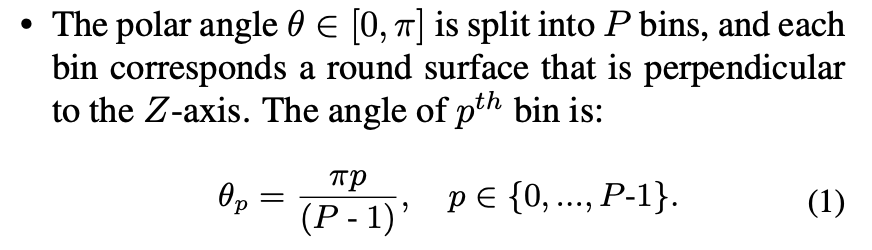
그리고 각 p번째 bin(구의 z축과 수직하는 평면)마다 생성되는 rays의 수(Ap)는 아래 수식(2)와 같다. 4의 배수로 나타나며 구의 지름을 포함하는 평면에 대해 대칭인 갯수를 가지게된다.
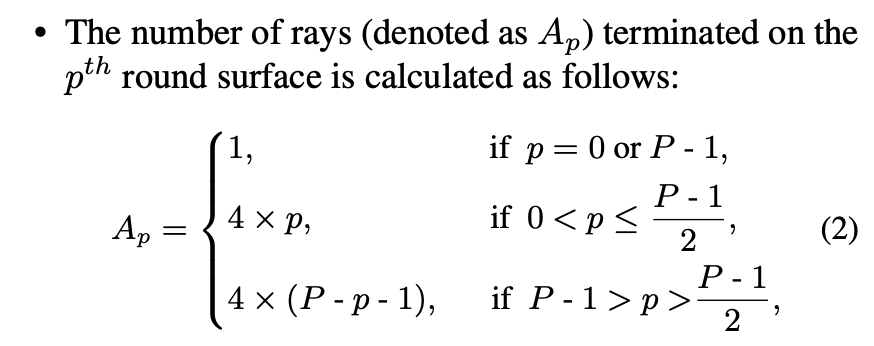
이렇게 ray의 수 Ap와 각도 θp를 통해 azimuth angle ψp,a ∈ [0, 2π]을 아래 수식(3)과 같이 나타낼 수 있다.
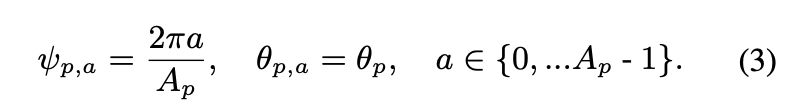
위의 전략을 통해 더 uniform하게 분포되도록 ray를 생성하여 전체 scene 영역을 cover 할 수 있다. 전체 rays의 수는 Ap를 모두 더한 수가 될 것이다.
각 cluster의 ray 거리의 범위에 대해, 모든 rays들은 cluster feature인 fi를 기반으로 하여 예측되는 object scale인 li와 같은 길이를 가진다. 아래 수식 (4)의 loss를 통해 object scale(li)를 regression하게된다.
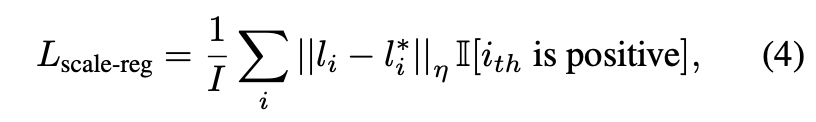
– li∗ : gt box의 대각선 크기
– I[ith is positive] : vote center(ci)가 gt object center와 일정한 범위(반지름 0.3)안에 존재하는지 나타내는 indicator function
– I : positive vote centers의 수
– η : smooth-l1 norm
위에서의 과정을 통해 determined rays를 generate한 후, RBGNet은 각 ray에서 anchor points를 sampling하게 된다. 이때 중요하지 않은 points들이 샘플링되거나 dense하게 points가 몰려있는 영역에서 단지 일정 구 안의 있는 points들만 고려하는 ball query방식은 놓치는 points들이 존재할 수 있기 때문에 한계가 있다. 따라서 저자는 coarse-to-fine anchor point generation strategy방식을 통해 이 문제를 해결하고자 하였다. coarse-to-fine 방식은 간단히 말해 dense areas에서 sampling을 더 많이 하는 방식이다. ‘coarse’와 ‘fine’의 두 가지 sampling 전략을 모두 사용하는 hybrid sampling 전략을 적용한 것이다. 먼저 pointnet++의 첫 번째 SA layers에서 trilinear interpolation을 통해 2048개의 points들로 upsampling을 하여 더 의미있는 points들을 얻고자하였고 cluster center와 cluster features(f)에 coarse-to-fine anchor point generation을 적용하였다.
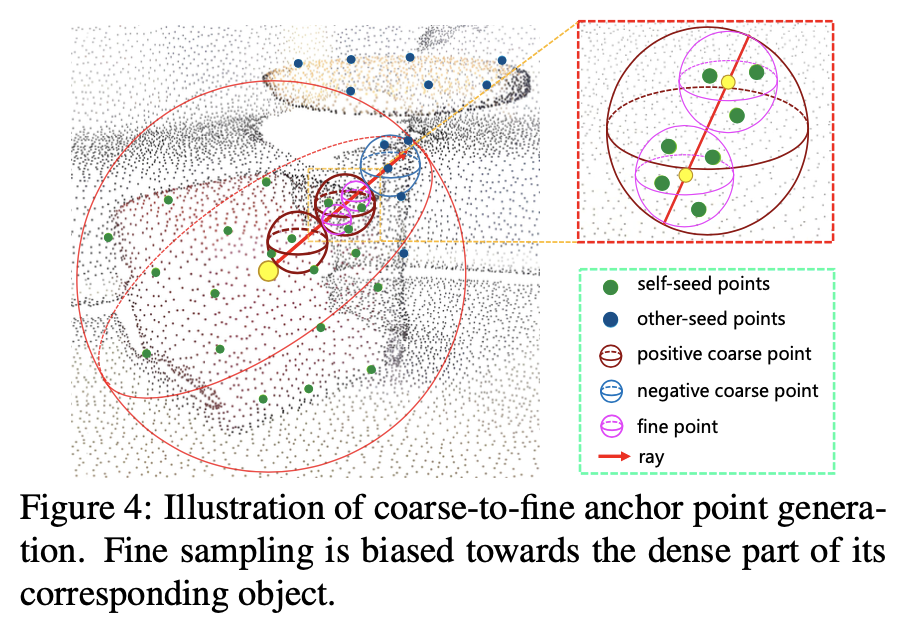
먼저 coarse stage를 보면, n번째 ray에서 anchor point 집합을 아래 수식(5)와 같이 sampling할 수 있다.
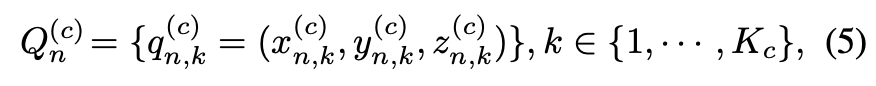
– Kc : 각 ray에서 sampling한 anchor points 수
그리고 각 anchor point에서 local feature를 추출하기 위해 pointnet++에서 set abstraction block을 적용하여 각 anchor point 주변의 seed points의 features를 aggregate하게된다. 이렇게 추출된 aggregated local features는 ρ(c)n,k로 나타낸다. 그리고 binary classification module을 추가하여 point와 cluster feature(f)로 positive mask(m(c)n,k)를 예측하도록 하는 수식이 아래 수식(6)으로 표현된다.
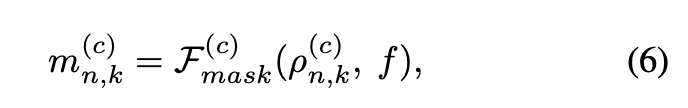
positive mask의 gt는 pointnet++의 ball query 과정을 각 anchor point에 적용하여 계산할 수 있다. 이렇게 어떤 surface point가 gt object와 ball query 영역 안에 포함되면 positive label을 부여하고 아니면 negative label을 부여한다. 이 point mask module을 통해 anchor point가 해당하는 object에 포함이 되는지 아닌지를 판별할 수 있게된다.
그리고 fine stage는 anchor point가 해당되는 object의 dense part에 bias되어 진행된다. 이를 위해 각 ray의 postive region에서 inverse transform sampling을 통해 uniform하게 Kf anchor points set(Qn = {qn,k}k=1)을 생성한다. 그리고 coarse stage에서 적용했던 것처럼 local features를 추출하고 positive mask를 예측하게된다.
모든 rays에 대해 coarse-to-fine방식을 반복해서 적용하고 얻는 각각의 coarse, fine feature는 P(c) = {ρ(c)n,k}k=1,n=1Kc,N , P(f) = {ρ(f)n,k}k=1,n=1Kf,N로 mask는 M(c) = {m(c)n,k}k=1,n=1Kc,N, M(f) = {m(f)n,k}k=1,n=1Kf,N 으로 표현한다.
Feature Enhancement by Determined Rays
위에서 언급했던 것처럼 foreground objects의 fine-grained surface geometry가 정확한 object proposal을 하는데 중요한 역할을 한다고 한다. 바로 위에서 설명한 coarse-to-fine anchor point generation 전략을 통해 이러한 surface geometry features를 encode할 수 있었다. 그리고 여기서는 이러한 feature information을 합쳐 cluster features의 quality를 향상시키고자한다.
각 anchor point에서 local features P(c), P(f)와 point masks M(c), M(f)가 주어졌을 때, negative anchor point의 feature는 0으로 masking되었을텐데 이것을 P^(f)라고 표기한다. 이 features를 합치기 위해 미리 설정했던 predefined rays와 fusion을 하게된다. 이 과정도 coarse와 fine branch에서 각각 독립적으로 진행된다. fusion 방식은 concat을 하는 것이고 아래 수식(7)처럼 표현한다.
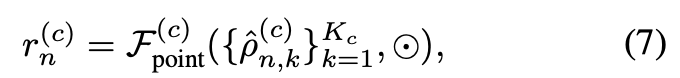
– ⊙ : concatenation
– F : cluster features
– rn(c) : ray feature
그리고 아래 수식(8)처럼 모든 rays에 대해 concate을 하고 MLP를 태워 128차원의 coarse feature를 추출하게 된다.
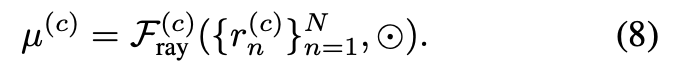
fine branch의 경우에도 coarse branch와 동일한 과정을 거치고, 구해진 coarse와 fine feature는 fusion된다.
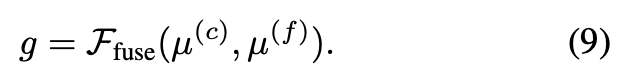
– g : fused feature
이렇게 coarse feature와 fine feature를 구해 fusion하는 방식을 통해 object surface geometry정보와 object size와 위치에 대한 정보를 얻어 3d bounding box를 예측하는데 효과를 볼 수 있다.
Foreground Biased Sampling
흔히 사용되는 farthest point sampling방식은 background points를 많이 sampling하는 경우도 있기 때문에 downstream task를 할 때 안좋은 성능을 보일 수도 있다. 따라서 본 논문에서는 간단하면서도 효율적인 전략인 foreground biased sampling방식을 제안하여 object surface의 foreground에 존재하는 points들에 집중해서 sampling하도록 한다. pointnet++의 set abstraction layer를 통과하여 encode된 point-wise features 각각이 주어졌을 때 각 segmentation head를 추가하여 각 points들마다 confidence score를 계산한다. 자세히 살펴보면, 첫 번째 SA layer를 통과한 후 xyz(ρj)와 128차원 features(νj)를 포함하는 downsample된 point set D = {dj}j=12048을 얻을 수 있다. 그리고 각 point에서 segmentation head를 통해 얻은 score를 얻게된다.
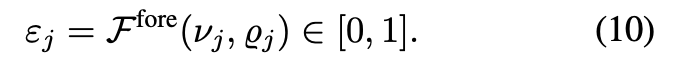
구한 confidence score를 sort하여 top k개의 점을 뽑아 foreground set D(f) = {dj(f)}j=1κ으로, 나머지는 background set D(b) = {dj(b)}j=12048-κ 으로 정의한다. 이때 score가 높은 point에만 집중하다보니 foreground point의 recall과 전체 scene을 cover할 수 있기 위한 sampling과 서로 trade off 관계에 있으므로, foreground와 background 각가에 farthest point sampling을 적용하여 이후 두 sample을 합치는 방식을 적용하였다. 따라서 최종 sampling된 point set은 아래 수식(11)과 같다.

– D(f^) = {dj(f^)}j=1α : sampled된 foreground set
– D(b^) = {dj(b^)}j=1β : sampled된 background set
– α : foreground set의 sample 수
– β : background set의 sample 수
– S : 최종 sampled points 수
본 논문에서는 87.5%의 foreground points, 12.5%의 background points를 sampling하여 전체 scene을 cover하면서도 dense area의 foreground object points를 sampling하도록 했다.
Learning Objective
loss function은 foreground biased sampling(Lfbs), voting regression(Lvote-reg), ray-based feature grouping(Lrbfg), objectness(Lobj-cls), bounding box estimation(Lbox), semantic classification(Lsem-cls)의 합으로 구성된다.
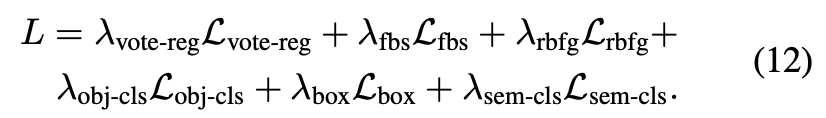
Lvote-reg, Lobj-cls, Lbox는 votenet과 동일하게 적용하였고, Lsem-cls와 Lfbs는 cross entropy loss를 적용하였다. Lrbfg는 ray-based feature grouping module의 loss를 합하여 아래 수식(13)과 같이 적용하였다.
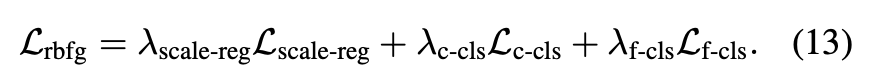
Lscale-reg은 smooth l1 loss를 사용하여 object scale을 supervise하고자 하였고 Lc-cls와 Lf-cls는 cross entropy loss를 사용하였다.
Experiments
dataset은 SUN RGB-D와 ScanNet V2를 사용하여 평가했다. SUN RGB-D는 single-view RGB-D dataset으로 10개 categories를 포함하는 OBB로 표현된 bounding box를 가진 rgb-d training image를 포함한다. camera parameters를 이용하여 depth image를 point cloud로 변환하였다. ScanNet V2는 1513개 training samples를 가지며 AABB로 표현된 bounding box를 포함한다. SUN RGB-D보다 크고 많은 objects들을 포함한다. 18개의 object categories label을 사용한다.
각 scene마다 50,000개의 points를 subsample했고, 2~4번째 SA layers에서 FPS를 본 논문에서 제안하는 FBS(Foreground Biased Sampling)으로 대체해서 사용하였다.
아래 Table 2에서는 ScanNet V2에서의 결과를 보여준다. 제안하는 RBGNet이 가장 좋은 성능을 보이는 것을 확인할 수 있다. R66은 66개의 rays를 사용했다는 것이고, O256은 256개의 object candidates를 사용했다는 것을 의미한다. w2x는 channel을 2배 늘린 backbone을 사용한 것인데, 동일하게 더 강한 backbone을 적용한 Group-Free와 비교해도 더 좋은 결과를 보인다.
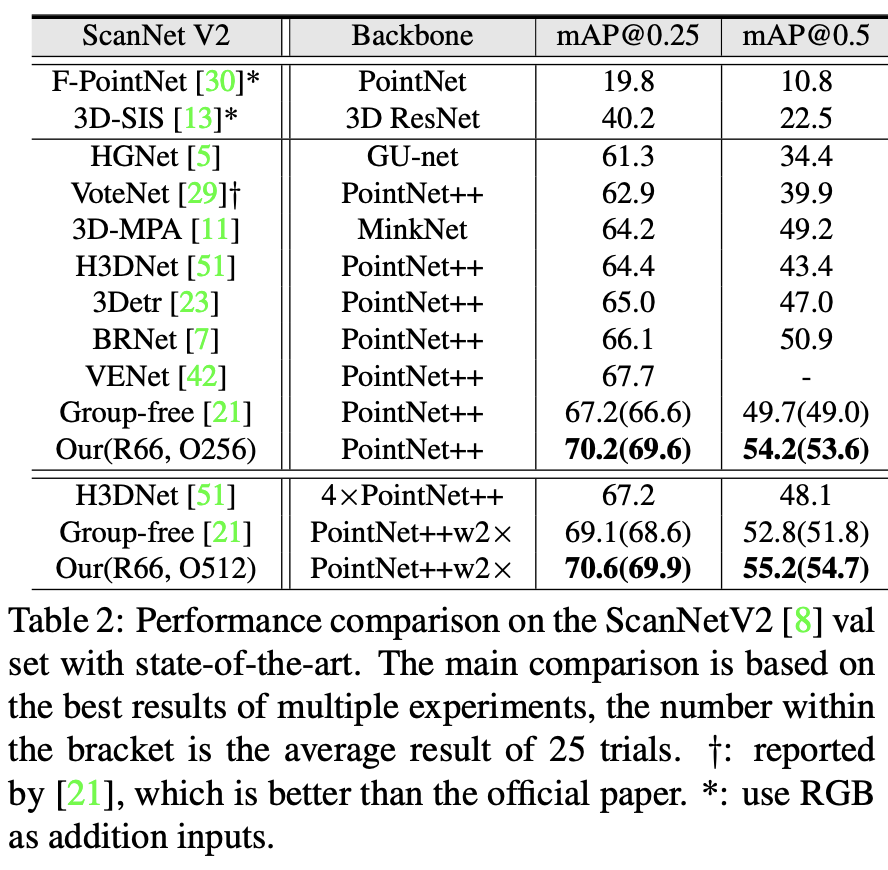
아래 Table 3은 SUN RGB-D에서의 결과이다. pointnet++을 backbone으로 하는 기존의 다른 point cloud based 방법론이나 rgb based 방법론과 비교해보아도 가장 좋은 결과를 보이는 것을 알 수 있다.
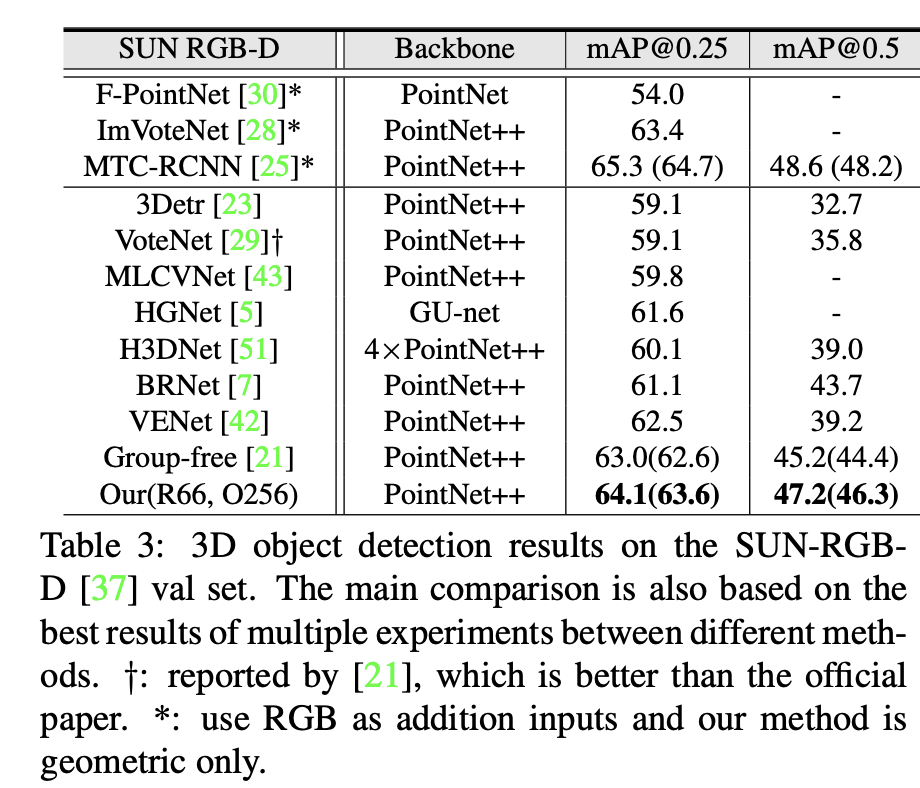
아래 Table 4,5,6은 ablation study 결과이다.
우선 Table 4에서 ray based feature를 적용했을 때 더 큰 성능 향상을 불러온만큼, ray-based feature grouping이 성능향상에 효과가 있다는 것을 알 수 있다.

Table 5에서는 ray의 수에 따른 성능을 reporting하였다. 상식적으로 예상할 수 있는 것처럼 더 많은 rays를 사용할수록 surface points를 더 정확하게 capture할 수 있다는 것을 objp recall을 통해 알 수 있으며, 또한 더 좋은 성능을 보이는 것을 알 수 있다. 본 논문에서는 inference time과 accuracy의 trade off관계를 고려하여 ray의 수를 66으로 설정하였다.
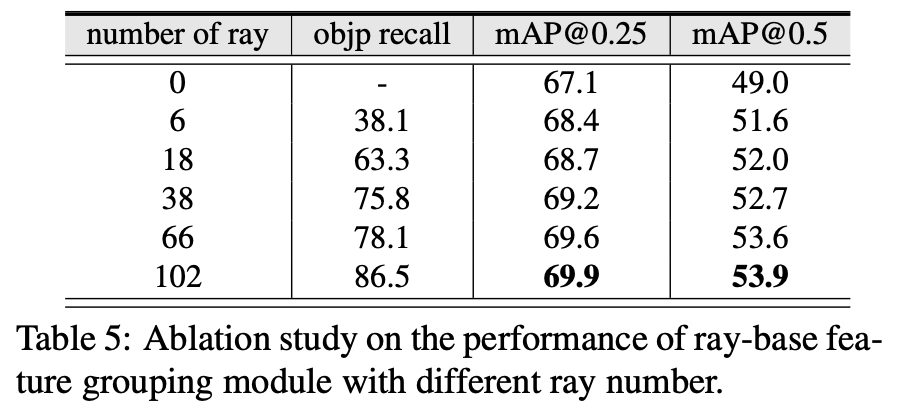
아래 Table 6에서는 ray-based feature grouping module의 효용성을 검증하고자 다른 방법들은 모두 고정하고 feature aggregation하는 방식만 바꿔서 실험한 결과인데, 다른 방법론들에 비해 ray-based grouping방식이 가장 효과가 있는 것으로 보인다.
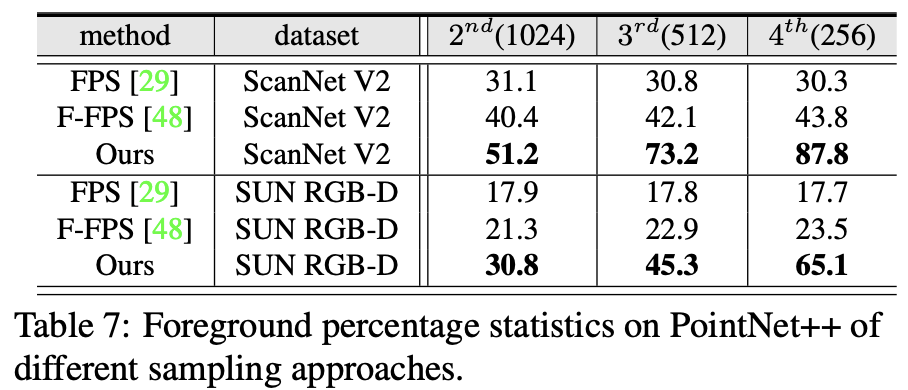
위의 Table 4에서 foreground biased sampling strategy(FBS)의 효과를 보여주고 있는데 이를 통해 3d object detection task에서 foreground point sampling이 중요하다는 것을 시사한다. 아래 Table 7에서는 2~4번째 SA layers에서 여러 subsampling 방법론들을 통해 foreground points recall을 비교한 결과이다. 결과가 눈에 띄는 차이를 보이는 것으로 보아 FBS가 효과적이라는 것을 다시 한 번 확인할 수 있다. foreground의 points를 sampling하는 것이 성능 향상에 큰 영향을 미친다는 뜻이다.
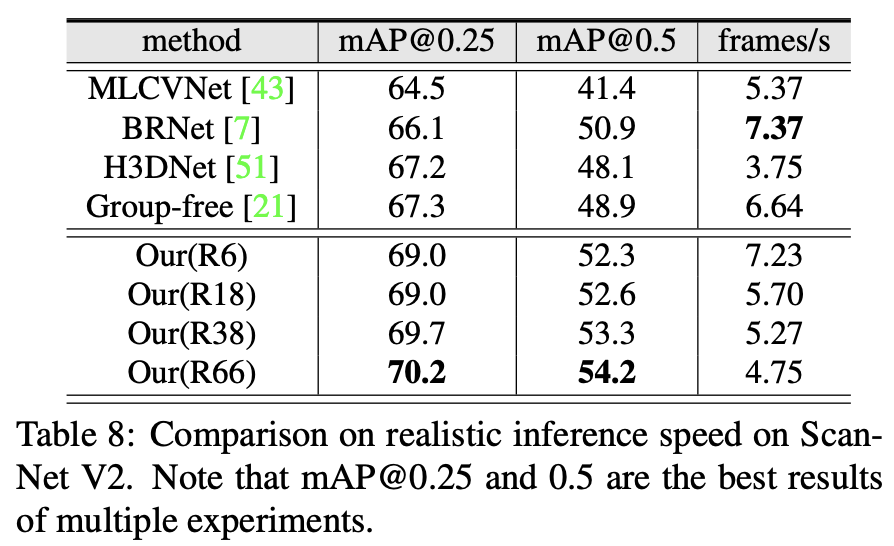
아래 Table 8은 inference speed에 대한 결과를 보여준다. 다른 모델들과 비교했을 때 속도에서 큰 차이를 보이지 않지만 더 좋은 성능을 보이는 것을 확인할 수 있다.
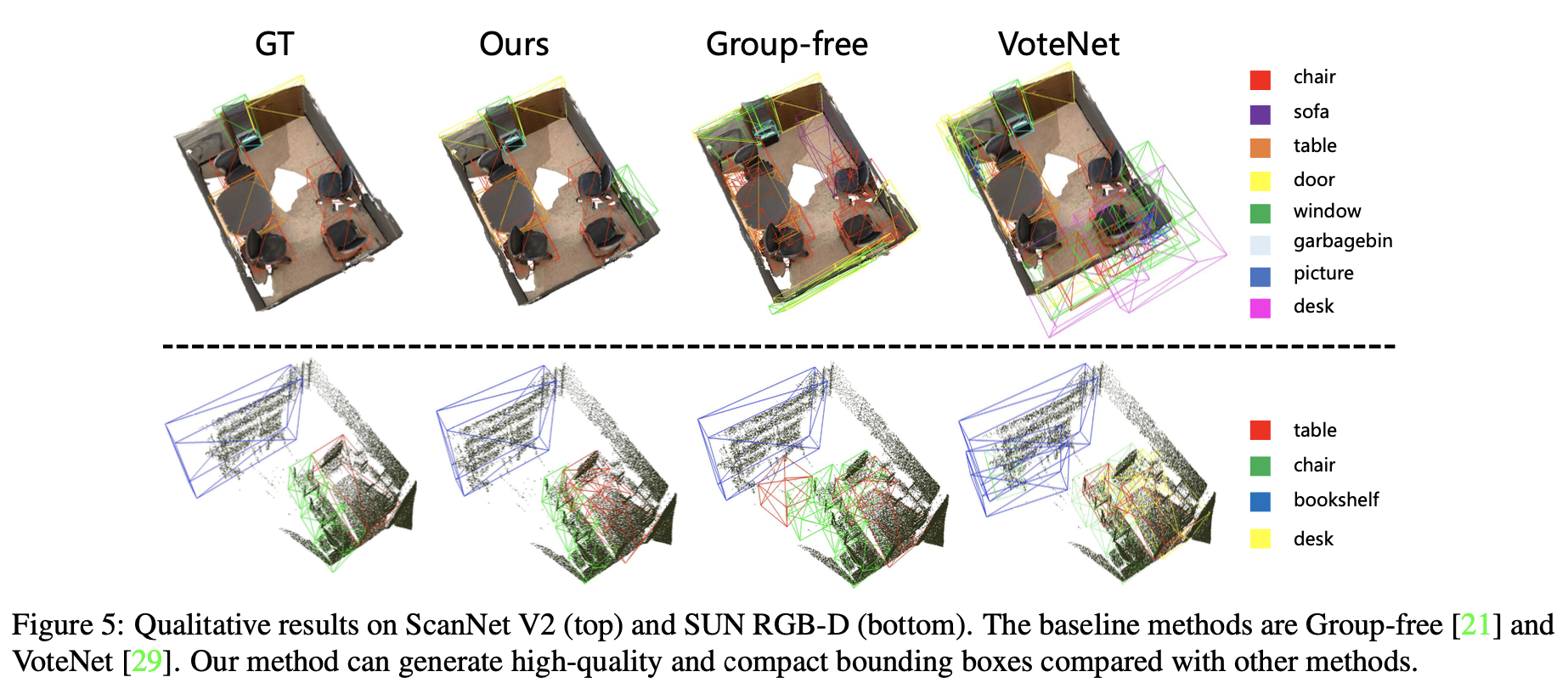
마지막으로 ScanNet V2(위)와 SUN RGB-D(아래)에서의 시각화 결과를 Figure 5에서 확인할 수 있다.
Conclusion
본 논문에서는 raw point cloud를 기반으로 하는 새로운 3d object detection framework인 RBGNet을 제안하였다. RBGNet에서는 ray-based feature grouping module을 통해 object surface geometry정보를 학습하여 3d detection 성능 향상에 도움을 주었다. 또한 foreground biased sampling을 통해 전체적인 scene을 cover하면서도 object surface에 존재하는 points들을 더 많이 sampling하여 object를 더 잘 찾을 수 있도록 하였다. 결과적으로 대표적인 3d indoor dataset인 ScanNet V2와 SUN RGB-D에서 sota를 달성할 수 있었다.
안녕하세요. 좋은 리뷰 감사합니다.
1) 리뷰를 읽다보니 궁금한 것이 이 논문에서 최초로 ray라는 것을 언급하고 이를 정의한 것인가요? ray자체를 처음으로 사용한 것이 contribution인지, ray를 이용하여 feature groping module을 제안한 것이 contribution인지 궁금합니다. (근데 작성해보니 둘이 같은 의미인거 같기는 하네요ㅎㅎ;;)
2) ray point representation 파트에서 rays들을 사전에 지정해준다고 하는데 이는 Figure3에 나온 점 들 중에 하나로 위치가 지정되는 걸까요? 그러면 궁금한것이 사전에 지정해둔 위치에 따라 성능도 달라질 것 같은데 이 부분에 대해서는 리포팅 된 것이 없나요?
감사합니다.
1) ray를 처음으로 언급하고 사용한 것은 아니고, 2d를 3d로 변환할 때 frustum구조로 사영해서 3d point를 구하는 방식이 ray와 유사합니다. 또 segmentation task에서는 ray방식을 사용한 방법론들이 있는것으로 알고있습니다. ray를 통해 object의 의미있는 points들을 grouping하는 방식이 contribution이라 생각합니다.
2) 사전에 지정해준다는 뜻이 Figure3에서 점들 중 하나를 선택하는 것이 아니라, Figure 3에 보이는 것처럼 여러 bins로 나누어 설정해준다는 뜻입니다. 이때 bin을 몇 개로 나눌지를 사전에 지정해준다는 뜻이었습니다. 그래서 ray의 수에 따른 성능은 Table5에서 보여주고 있습니다.
감사합니다.