본 논문에서는 posed monocular or multi-view rgb images를 기반으로 하는 fully convolutional 3d object detection 방법론인 ImVoxelNet을 제안한다. 본 논문의 저자는 전에 읽어보았던 FCAF3D, TR3D 등 sun rgbd에서 sota를 달성했던 모델들의 저자의 이전 논문으로, 제안하는 ImVoxelNet은 image만을 input으로 사용한다. 또한 outdoor와 indoor모두에서 head만 바꾸어 사용할 수 있다고하여 어떤 모델인지 궁금해졌다. ImVoxelNet은 rgb image를 기반으로 하는 방법론들 중 outdoor 환경인 KITTI(monocular), nuScenes(multi-view)에서 sota를 달성하고 indoor 환경인 sun rgbd에서도 sota를 달성하였다.
Introduction
RGB image는 scene안에서 object에 대한 visual 정보를 제공하여 기존 3d object detection분야에서 활발한 연구가 진행되었다. 하지만 rgb image는 scene의 geometric한 정보를 가지지 못하고 image에서 object의 절대적인 scale을 고려하지 못하는 단점이 존재한다. 따라서 rgb기반의 3d object detection task의 성능은 좋은 결과를 보이지 못하고 있었다. monocular image를 활용한 3d object detection 방법은 data의 scale정도만 추론하는 정보를 제공해주었다. 하지만 여러 images를 사용하면 monocular rgb image보다 더 많은 정보를 얻을 수 있다. 이전 몇몇의 3d object detection 방법론들은 multi-view images를 사용했다. 해당 방법론들은 inference시에만 multi-view를 사용했는데, monocular rgb image 각각을 통해 prediction을 하고난 후 aggregation을 진행했다. 반면 본 논문에서 제안하는 방법론에서는 training과 inference과정 모두에서 multi-view input을 사용한다. input으로 받는 multi-view의 수는 임의의 view 수를 받을 수 있다. 또한 monocular benchmark에서 좋은 성능을 보였다고 한다.
rgb-based 3d object detection 방법론들은 크게 indoor와 outdoor로 나누어진다. outdoor 방법론의 경우 보통 cars를 검출하게 되는데 car는 서로 비슷한 크기를 가지고 땅에 붙어있기 때문에 하늘에서 내려보는 view형태인 Bird’s Eye View(BEV)로 2차원 형태로 projection하게되어도 서로 겹치지 않는다. 차가 위아래로 있는 경우는 없기 때문이다. BEV평면으로 projection하는 것이 cars의 3d location을 찾는데 더 효과적이라고 한다. indoor의 경우 물체들이 3d space에 random하게 분포하고 있고 서로 다양한 크기를 가지고 있다. 또한 위아래로 쌓아져서 겹쳐있는 경우도 많기 때문에 outdoor와 같은 BEV평면위로 projection하는 변형은 적절하지 않다. 전반적으로 rgb-based 3d object detection 방법론들은 data의 특성을 고려하기 때문에 domain specific한 경향을 보이는 것 같다.
multiple rgb input의 정보들을 합치기 위해 본 논문에서는 3d data를 regular한 grid공간으로 나누어 처리하는 voxel representation방식을 사용한다. indoor, outdoor에 모두 voxel 형태를 사용하여 처리하는데 indoor와 outdoor task에 변화가 있는 부분은 마지막 head부분만 바뀐다. 최종 prediction은 3d feature map을 통해 얻은 값이고 보통 point cloud based 방법론에서 사용하는(off-the-shelf) neck과 head를 사용하기 때문에 추가 변형이 필요하지 않다고 한다.
contribution은 아래와 같다.
1. 최초로 posed RGB image만을 기반으로 하는 multi-view 3d object detection 방법론들 중 end-to-end training 방법으로 구성한 task
2. moncular, multi-view input 모두에 대해 작동하는 fully convolutional 3d object detector 제안
3. indoor, outdoor상황에 따라 domain-specific한 head를 사용하여 각 benchmark에서 sota달성
Related Works
Multi-view Scene Understanding
많은 scene understanding 방법들은 mutli-view input을 사용한다. scene을 이해하기 위한 sub-task의 한 방법은 주어진 multi-view input만 사용해서 문제를 해결한다. SLAM task에서 3d scene의 geometry정보를 reconstructing하거나 sequence frame에서 camera pose를 추정할 때 사용한다. Structure-from-Motion(SfM)은 camera pose를 추정하고 Multi-View Stereo(MVS)는 SfM을 이용하여 3d point cloud를 생성한다고한다.
scene understanding sub-task의 다른 최근의 방법은 multi-view input으로부터 reformulate하는 것이다. 3D-SIS, MVPointNet,과 같은 방법론들이 존재한다.
3D Object Detection
point cloud기반 방법론은 3d convolutional network를 사용했는데, 앞선 리뷰에서도 계속 언급했던 것처럼 computation cost가 크다는 단점이 있다. 이를 해결하기 위해 outdoor에서는 2차원 평면으로 projection하는 bev plane형태로 변환하여 처리했고 일반적으로 voxel형태로 변환하여 처리하는 방식을 적용했다. indoor의 경우 object의 center를 찾는 방식이 있는데 이때 물체의 형태에 따라 object의 geometrical한 center가 해당 object에 존재하지 않는 경우도 있다. 예를 들어 table을 생각해보면 geometrical center는 4개의 다리 사이 공간에 존재하게 될 것이다. 따라서 좀 더 정확한 object center를 찾고자 각 points들이 voting방식을 적용했다.
stereo based 방법론은 multi-view 방법론과 다르다고 한다. mutli-view는 임의의 input view 수를 가지고 camera pose또한 input의 view 수에 따라 각기 임의의 값을 가진다. stereo based 방법론에는 3DOP, TLNEt Stereo R-CNN등이 존재한다. mono based 방법론은 Mono 3D, Deep3DBox, MonoGRNet 등이 존재하며 하나의 input image를 사용한다. 2d detection을 진행한 후 정보를 3d로 lift하는 방식도 사용한다. monocluar indoor 3d object detection은 연구가 많이 되지 않았고 dataset도 SUN RGBD만 존재한다. outoor 3d object detection 방법론의 경우 보통 nuScenes dataset에서 multi-view input으로 평가를 진행한다.
Proposed Method
본 논문에서 제안하는 방법론은 camera poses를 포함하는 임의의 크기의 rgb 집합을 input으로 한다. 우선 2d convolutional backbone으로 resnet50을 사용하며 image의 feature를 추출한다. 그리고 추출한 image features를 3d voxel로 projection하고 images의 각 voxel마다 features를 element-wise averaging해준다. 이후 voxel을 3d convolutional network인 3D-SIS에 통과시키고 이렇게 추출한 3d features를 indoor, outdoor에 따라 맞는 head에 입력으로 하여 bounding box features를 추출하게 된다. 전체적인 ImVoxelNet의 architecture는 아래의 Figure 1과 같고, 아래에서 하나씩 자세히 알아보자.
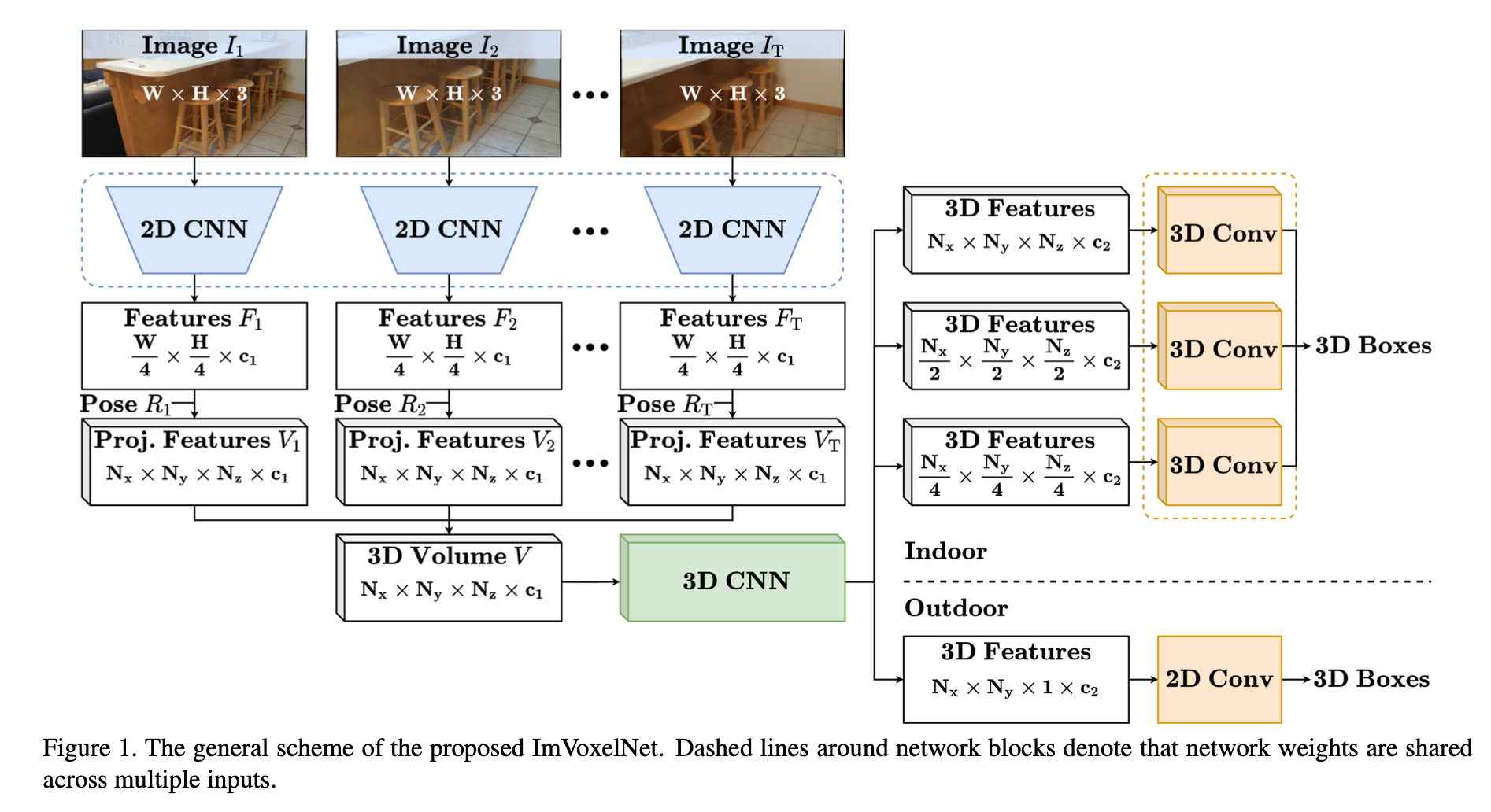
3D Volume Construction
It ∈ R^(W×H×3)는 T개의 image 집합 중 t번째 image를 의미한다. 이때 T가 1이면 single view이고 1보다 크면 multi-view이다. 그리고 2d backbone인 Resnet50으로 2d features를 추출하게된다. 추출한 2d feature의 output은 W/4 × H/4 × c0, W/8 × H/8 ×2c0, W/16 × H/16 ×4c0, and W/32 × H/32 ×8c0 이렇게 4가지로 나오는데 이 4가지 크기의 feature maps를 FPN을 통과시켜 W/4 × H/4 × c1 크기의 하나의 tensor Ft로 만들어준다. c0과 c1는 256으로 세팅해주었다.
만들어진 2d feature인 tensor Ft는 3d 형태로 만들어주기 위해 3d voxel volume인 Vt ∈ R^(Nx ×Ny ×Nz ×c1)로 projection하게 된다. voxel의 z축은 바닥면과 수직으로 설정하고 x축은 깊이 방향으로 설정하고 y축은 x,z축과 orthogonal하게 설정해준다. 또 각 축마다 axis limit을 max, min으로 정의하였다. voxel size는 xmin,xmax,ymin,ymax,zmin,zmax를 통해 Nxs = xmax −xmin, Nys = ymax − ymin, Nzs = zmax − zmin로 나타낼 수 있다.
또 아래 수식처럼 calibration을 통해 구한 parameter로 feature map Ft의 2d coordinates(u,v)를 3d voxel volume Vt의 coordinate(x,y,z) 내부에 포함되는지 mapping하여 확인한다.
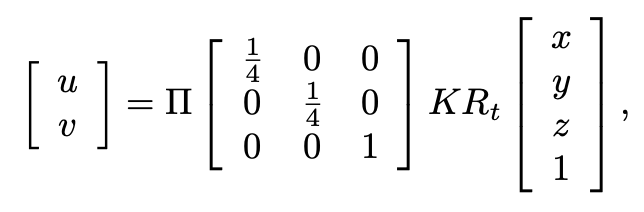
K, Rt : intrinsic, extrinsic matrices
Π : perspective mapping
3d로 projection한 feature Vt와 같은 shape의 binary mask Mt를 정의하여 각 voxel이 camera frustum안에 속하는지 여부를 나타낸다.
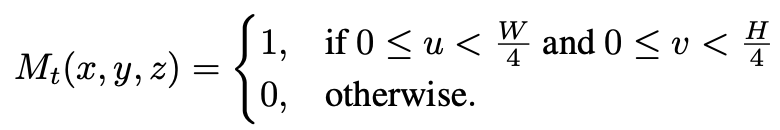
mask Mt가 1인 feature에 대해서만 3d로 projection한 feature Vt를 고려해주게 된다.
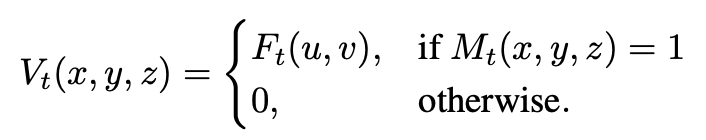
그리고 image마다 해당되는 voxel의 mask를 다 더해주고 평균을 내어 3d volume V를 얻을 수 있게된다.
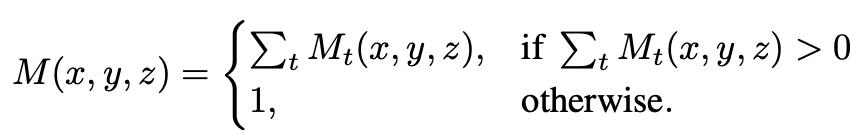
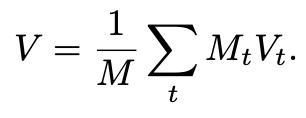
3D Feature Extraction
크게 indoor, outdoor로 나눌 수 있다. 먼저 indoor의 경우 기존 3D-SIS라는 방법론에서 사용한 방법에 따라 voxel을 3d convolutional encoder-decoder network를 통과시킨다. Figure 1에서 초록색 3D CNN 박스에 해당하는 부분이다. 하지만 기존에 48개의 3d convolutional layers를 사용한 것은 많은 computation을 필요로하여 느린 inference를 보이기 때문에 layer 수를 줄여 simplify했다. 간단하게 만든 encoder는 3개의 downsampling residual block으로 구성되며 각 block은 3개의 3d convolutional layers를 가진다. decoder의 경우 3개의 upsampling block으로 구성되며 transposed 3d convolutional layers를 가진다. decoder를 통과한 output은 Nx/4 × Ny/4× Nz/4 ×c2, Nx/2 × Ny/2 × Nz/2 ×c2, Nx ×Ny ×Nz ×c2 이렇게 3개의 feature maps를 가진다. c2는 256으로 설정했다.
outdoor의 경우 3d space를 2d bev plane으로 projection하여 2d object detection을 하게된다. 따라서 neck과 head가 2d convolutions로 구성된다. 여기서는 encoder부분만 활용하고 encoder를 통과한 tensor의 shape은 voxel V의 shape인 Nx ×Ny ×Nz ×c1에서 Nx × Ny × c2의 shape으로 출력되어진다.
Detection Head
outdoor, indoor 여부에 따라 다른 detection head를 사용한다.
먼저 outdoor의 경우 bev plane에서 2d object detection을 하는 방법으로 바뀌게 된다고 했었다. KITTI, nuScenes 데이터 셋에서 효과를 증명한 방법으로 2d anchor head를 사용하여 downstream task를 진행하게 된다. outdoor detection에서 차들은 대부분 비슷한 scale을 가지고 같은 category에 속하게 된다. detection head는 class probability를 예측하고 bounding box의 7개 parameters를 regression하는 두 개의 2d convolutional layers로 구성된다.
input은 Nx × Ny × c2 크기의 tensor이며 output은 아래의 7개 parameters와 클래스 확률 p가 된다. x,y,z는 center coordinate이고 w,l,h는 width, length, height이고 각도는 z축을 기준으로 하는 rotation angle이다. a가 붙은 것이 anchor box이다. za의 경우 bev plane위에 있기 때문에 모든 anchors에 대해 상수값이다.
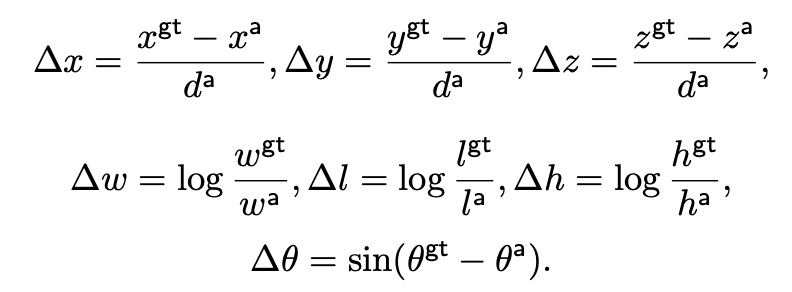
Loss는 기존 SECOND라는 방법론에서 도입한 loss를 적용하였다고 한다. Lloc, Lcls, Ldir terms로 나누어지며 Lloc는 smooth mean absolute error, Lcls는 focal loss, Ldir은 cross-entropy loss를 사용한다. Ldir은 direction loss이다.
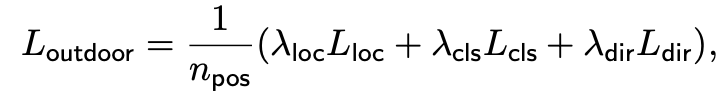
npos : number of positive anchors
λloc : 2
λcls = 1
λdir = 0.2
indoor의 경우 기존에는 voting방식을 많이 사용하였다. 본 논문에서는 dense voxel representation을 적용하였는데 기존 3d object detection에서는 dense 3d multi-scale head가 존재하지 않았다. 따라서 2d detection 방법론인 FCOS를 3d에서 사용하도록 변형하여 적용하였다. 2d convolutinal layers를 3d convolutional layers로 변경해주었다. 그리고 candidate object locations를 선택하기 위한 center sampling을 적용했다. 기존 2d에서는 3×3의 candidates를 뽑았지만 여기서는 3x3x3의 27개 candidate object locations를 선택한다. 결론적으로 head는 classification, locationm centerness 이렇게 3개의 3d convolutional layers로 구성된다.
input은 Nx/4 × Ny/4× Nz/4 ×c2, Nx/2 × Ny/2 × Nz/2 ×c2, Nx ×Ny ×Nz ×c2 이렇게 3개의 feature maps이고 output은 아래와 같은 3d bounding box parameters와 class probability p, centerness c가 된다.
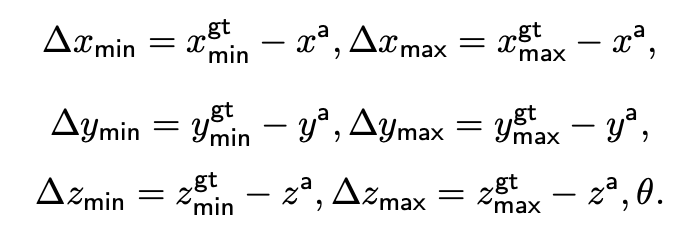
loss는 FCOS loss를 적용하였고 Lloc, Lcls, Lcntr term으로 구성된다. Lcls는 focal loss, Lcntr는 cross-entropy loss, Lloc는 IoU loss를 사용한다. npos는 positive 3d locations의 수이다.
Extra 2D Head
추가로 Indoor benchmark에서 camera rotation과 room layouts를 예측하기 위해 추가로 2d head를 제안하였다. 이 추가 head는 2개의 parallel branch로 구성되는데 하나는 두 개의 fully connected layers로 room layout을 output으로 하고 다른 하나는 camera rotation 에측값을 output으로 한다. 어떤 backbone을 통과한 output을 global average pooling하여 얻은 8c0(c0=256)크기의 single tensor를 input으로 하여 tuple형태로 pitch(β), roll(γ), 3d layout box(x, y, z, w, l, h, θ)를 output으로 한다. yaw angle은 0이 되도록 shift하였다고 한다.
loss는 rotated 3D IoU의 Llayout와 아래와 같은 Lpose의 합으로 extra loss(Lextra)를 구성한다.
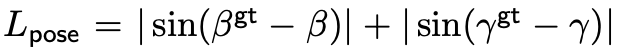
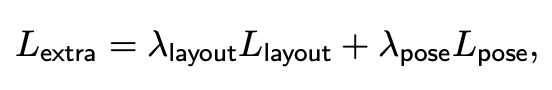
λlayout = 0.1이고 λpose = 1.0이다.
Experiments
ImVoxelNet은 4개의 datasets에서 실험을 진행했고 indoor는 ScanNet SUN RGB-D, outdoor는 KITTI, nuScenes dataset에서 진행했다. KITTI와 SUN RGBD는 monocular이고 나머지 둘은 multi-view이다.
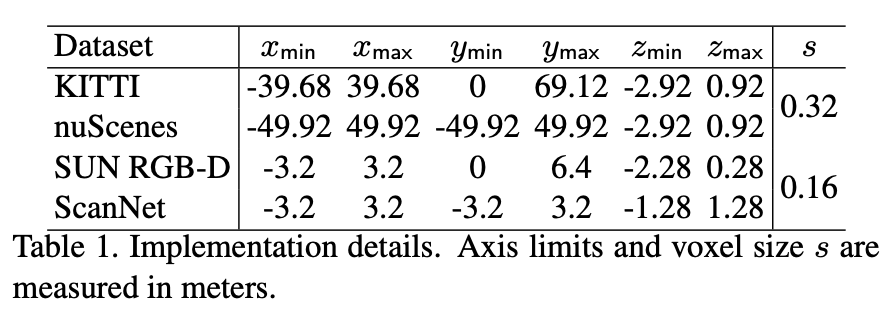
아래 Table 1에서는 각 데이터셋마다 axis limit과 voxel size s를 나타낸 것이다. outdoor에서 car class에 대한 범위를 고려해서 minimal, maximal 값을 정했다고 한다. indoor에서는 room size를 고려해서 voxel size를 설정했다고 한다.
학습 시 random하게 horizaontal flip을 적용하고 monocular input에 대해 original resolution대비 최대 25%가 넘지 않는 크기로 resize하는 augmentation을 적용했다고 한다.
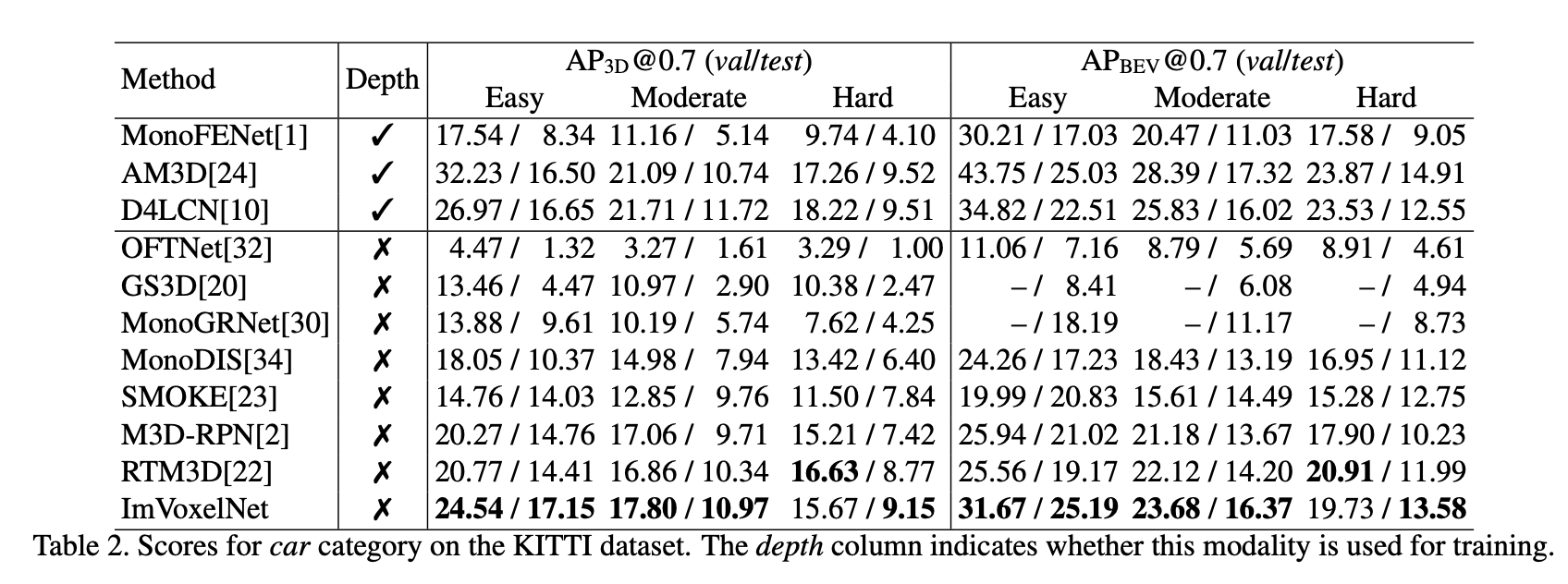
아래 Table 2와 Table 3은 각각 outdoor 데이터 셋인 KITTI, nuScenes에 대한 결과이다. Table 2의 KITTI는 monocular car detection한 결과로 ImVoxelNet이 가장 좋은 성능을 보이는 것을 확인할 수 있다. easy object에 대해 3d에서 accuracy는 최대 6%올랐고 bev에서는 4% 상승했다.
nuScenes는 multi view image를 input으로 하여 score를 측정했다. MonoDIS보다 제안하는 ImVoxelNet이 평균적으로 1%정도 좋은 성능을 보인다. 여기서 car detection을 할 때 두 boxes의 center distance가 1미터가 넘으면 iou가 0이 된다고 한다. 따라서 AP옆에 1m가 넘는 성능들은 겹치지 않는 bounding boxes들도 계산된 결과이기 때문에 0.5m일 때 성능이 가장 믿을만한 성능이다. AP뿐만 아니라 average translation error(ATE), average scale error(ASE), average orientation error(AOE)까지 reporting을 했는데 ImvoxelNet이 MonoDIS보다 0.9m 작은 ATE를 보이는 것을 알 수 있다.

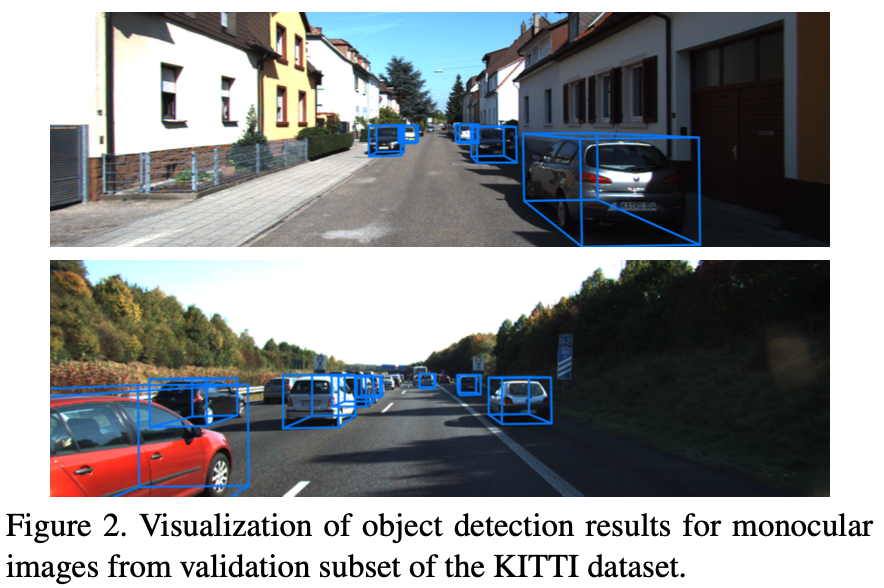
아래 그림 Figure 2와 Figure 3은 각각 KITTI와 nuScenes에서 detection 결과를 시각화 한 것이다.

아래 Table 4, 5는 각각 SUN RGB-D, ScanNet에 대한 실험 결과이다. sun rgb-d는 mono input을 기반으로 한다. 그리고 제안한 방법 마지막에 extra 2d head를 제안하였는데 sun rgbd에서 indoor loss와 extra loss를 함께 사용하여 camera pose와 layout을 함께 예측하였다. sun rgbd에서는 모든 항목에 대해 본 논문에서 제안하는 ImVoxelNet이 가장 좋은 성능을 보이는 것을 확인할 수 있다. layout과 camera pose도 가장 잘 예측했다.

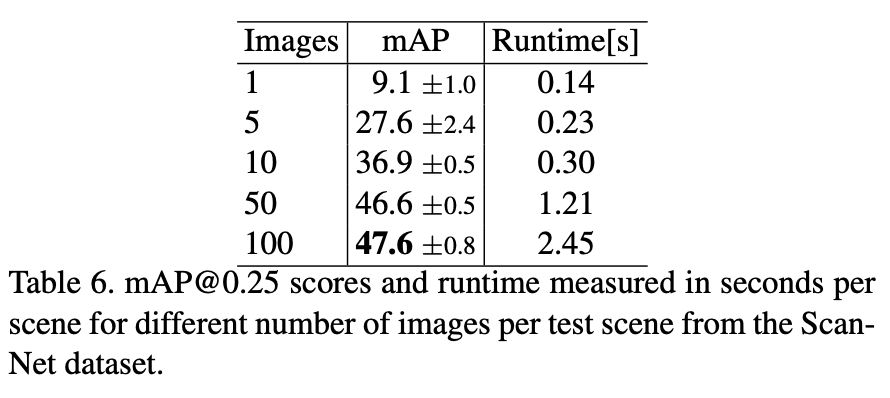
ScanNet에서는 training시 scene당 50장의 images를 사용했다. 아래 Table 6에는 각 scene마다 optimal한 test image의 수에 대한 ablation study가 나타나있다. image 수가 늘어날수록 정확도는 올라가고 runtime은 오래걸리는 상식적인 성능을 보여준다. 100장의 image를 사용한 경우 걸리는 시간에 비해 정확도 향상 폭이 크지 않은 것을 알 수 있다. ScanNet에 대한 결과는 point cloud를 사용한 H3DNet이 가장 좋은 성능을 보이지만 rgb만을 사용한 ImVoxelNet도 위의 rgb+pc를 사용하거나 다른 point cloud기반 방법론과 견줄만한 결과를 보인다. 이 결과를 통해 imvoxelnet과 다른 방법론들을 비교하는 것은 바람직하지 않다고 생각이 들지만 하나 느낄 수 있었던 것은 point cloud가 성능을 좌우하고 rgb는 point cloud의 정보를 추가로 guide해주는 느낌으로 받아들이면 좋을 것 같다고 생각했다.

아래 Figure 4와 Figure 5는 각각 SUN RGB-D와 ScanNet에 대한 결과를 시각화한 것을 보여준다.


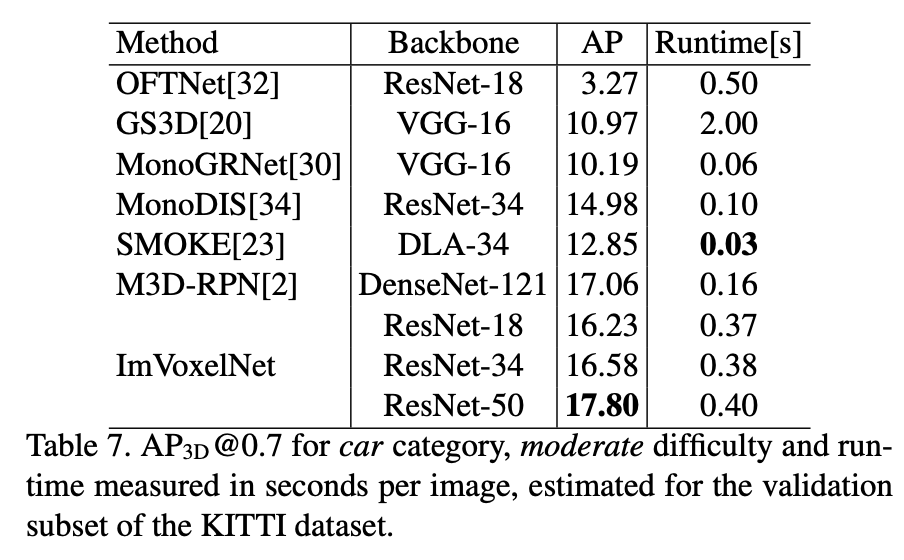
아래 Table 7에서 눈여겨 볼만한 정보는 ImVoxelNet을 backbone을 변경해가며 실험을 진행한 결과인데 backbone을 가볍게 한다고 해도 성능에 변화와 runtime시간의 차이가 미미한 것을 확인할 수 있다.
Conclusion
본 논문에서는 posed monoocular 혹은 multi-view rgb input을 기반으로하는 fully convolutional 3d object detection method인 ImVoxelNet을 제안했다. ImVoxelnet은 임의의 view 수의 multi-view input을 수용할 수 있고 monocular input에 대해서도 적용 가능하다. indoor, outdoor 환경에 따라 head를 다르게 적용하였으며 각 benchmark에서 sota를 달성할 수 있었다.
안녕하세요 좋은 리뷰 감사합니다 !
리뷰를 읽고 궁금한 점이 생겨서 질문 드립니다.
3D Feature Extraction 부분에서 나오는 3D Convolutional layer가 computation cost가 크다는 단점이 있기 때문에 다른 방법론에서는 이를 해결하기 위해 indoor에서는 object의 center를 찾는 방식을 사용하거나, 혹은 더 정확하게 center를 찾기 위해 voting 방식을 적용하였다고 말씀해주셨는데 해당 방법론에서는 원래 48개였던 3D convolutional layer의 수를 단순히 줄임으로써 computation 측면에서의 문제를 해결할 수 있었던 것인가요 ??
댓글 감사합니다.
기존 3D-SIS라는 방법론에서 보다 computational cost를 줄이기 위해 3d convolutional layer 수를 상대적으로 줄였습니다. 아무래도 2d convolution을 하는 것보다 3d convolution을 하는 것이 더 많은 연산량을 필요로 하여 time consuming한 것은 사실입니다. 이를 보완하기 위해 이후 FCAF3D와 같은 방법론들에서 sparse 3d convolutional layer를 적용하였습니다. 그리고 추가로 head부분에서 물체가 있을법한 candidata를 설정할 때, center sampling을 통해 얻은 center point를 기준으로 주변 몇 개(27개)의 candidate만 고려하여 computation cost를 줄였다고 할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
indoor, outdoor에서 다르게 처리하는 것을 인상깊게 보왔는데요. 그러면 이미지가 들어오기 전에 먼저 이 이미지가 indoor인지 outdoor인지 알아야 하는 건가요? 아니면 모델에서 이것을 파악하여 자동으로 head를 결정하여 사용하나요?
감사합니다
댓글 감사합니다.
우선 3d object detection에 많이 사용되는 benchmark dataset은 보통 indoor와 outdoor환경에 따라 나누어져있습니다. indoor는 object들이 위아래로 쌓여있고 클래스가 많거나 복잡한 scene일 확률이 높고, outdoor의 경우 detect해야하는 물체가 car, person처럼 몇 가지 되지 않고 간단하기 때문에 데이터 domain특성을 고려하여 indoor와 outdoor환경을 구분해서 서로 다른 task로 처리하는 것으로 알고 있습니다. 따라서 사전에 indoor인지 outdoor인지 파악한 후 상황에 맞는 head를 적용하는 것으로 이해하시면 될 것 같습니다.
안녕하세요 김도경 연구원님 좋은 리뷰 감사드립니다.
indoor과 outdoor모두 multiview rgb로부터 생성된 3d voxel을 사용하여 detection을 수행하는 것으로 알고 있는데, outdoor는 feature extractor와 detection head에서 다시 2d로 투영하여 detection을 진행한다는 점이 흥미로웠습니다. outdoor환경에서는 indoor처럼 3d 자체로는 detection을 수행하지 않는 것이 일반적인 경우인가요?
댓글 감사합니다.
outdoor환경에서도 3d convolution을 통해 detection할 수도 있지만, 검출해야하는 물체들이 car, pedestrican, cyclist와 같이 간단하고 클래스마다 object shape이 비슷합니다. 또한 outdoor의 경우는 indoor처럼 물건이 위아래로 쌓여(stack)있는 경우가 없기 때문에 하늘에서 새가 바라본 뷰처럼 bird’s eye view로 2d로 projection하여 detection하는 것이 더 좋은 detection 성능을 보인다고 하여 일반적으로 outdoor환경에서는 2d로 처리하는 것으로 알고있습니다.