안녕하세요. 이번 리뷰는 멀티모달 감정인식 분야가 아닌 음성 단일 모달리티 감정인식 관련 논문으로 가져와봤습니다. 성능 향상을 이루면서 제가 가장 익숙하게 건들일 수 있는 부분이 음성 파트라고 생각하였고, 실제로 음성 파트를 약간 바꾸어 실험을 진행했는데 아주 미세하지만 여태까지 한번도 오르지 않았던 성능이 약간이나마 오르게 되었습니다. 그래서 더 향상시키고자 찾아본 논문이 이 논문이 되겠네요.
이 논문을 간략하게 말씀드리자면 ‘mfcc가 많이 쓰이는데, spectrogram이랑 waveform을 동시에 같이 쓰면 더 좋지 않을까?’에서 출발하여 이 세개를 융합하여 성능 향상을 이룬 논문입니다. 저도 이 논문을 읽고 제 베이스라인에 적용하여 성능향상을 이루길 기대하면서 리뷰 시작하도록 하겠습니다.
<Introduction>
논문에서는 요즘의 연구가 acoustic information과 textual information을 결합하여 high-level context information을 사용해 감정을 예측하는 식으로 흘러간다고 합니다. 그런데 문제는 audio에 대응하는 transcription이 항상 감정 인식에 도움되지 않을 수도 있고, 음성 인식으로 생성된 text는 word recognition error를 유발할 수 있어 오히려 감정인식을 방해할 수 있다는 것입니다. 그래서 only audio signal로만 감정인식을 진행하는 것이 훨씬 더 쉽다는 것입니다. 왜냐? 오디오 신호는 훨씬 얻기 쉽기 때문에.
그럼 이 오디오 신호를 어떻게 사용해야 감정인식에 효과적일까요? 논문에서는 speech emotion recognition 문제를 multiple acoustic information을 융합함으로써 multi-level fusion 문제로 바꾸는 것이 완전히 오디오 정보를 활용하는 효과적인 방법이라고 말합니다.
그러면 앞으로는 audio에 도대체 어떤 정보들이 들어있는지 말씀드리고자 합니다. audio feature로는 가장 유명한 Mel-frequency Cepstral Coefficient(MFCC)가 있고, Constant-Q Transform (CQT) 또는 spectrogram이 있습니다. 이러한 것이 어떻게 추출되는지 자세히 알고 싶으신 분은 제가 이전에 작성한 글이 있으니 참고해주시면 감사하겠습니다. (링크 첨부)
위의 글을 읽고 왔다는 전제하에 다시 시작하도록 하겠습니다. MFCC와 spectrogram은 frequency domain에서 speech signal 정보를 반영합니다. 여기서 두 가지의 차이점은 MFCC는 human knowledge를 기반했기 때문에 low-level feature로 간주될 수 있고, Spectrogram은 deep neural network를 통해 high-level information을 얻을 수 있도록 처리되었다는 것 입니다.
MFCC, spectrogram은 직관적이고 간단하게 추출할 수 있지만 이는 온전히 frequency domain에서 추출한 feature입니다. 즉, time-domain information을 무시하고 있다고 볼 수 있습니다.
그래서 이 논문에서는, acoustic information의 다양한 level을 위한 3개의 encoder를 소개합니다.
- spectrogram을 위한 CNN
- MFCC를 위한 BiLSTM
- raw audio signals을 위한 transformer 기반 acoustic 추출 네트워크 wav2vec2
그리고 논문에서 디자인한 co-attention module으로 MFCC와 스펙트로그램 특징에서 추출한 effective information(유효한 정보)을 활용하여 각 프레임에 가중치를 부여한 후 최종 wav2vec2 임베딩(W2E)을 최적화합니다. 그런 다음 추출된 3개의 feature를 모두 concat하여 최종 감정인식을 수행합니다.
<method overview>
위에서 아주 간단하게 진행방식을 소개드렸지만 조금더 디테일하게 방법론을 설명드리고자 합니다.
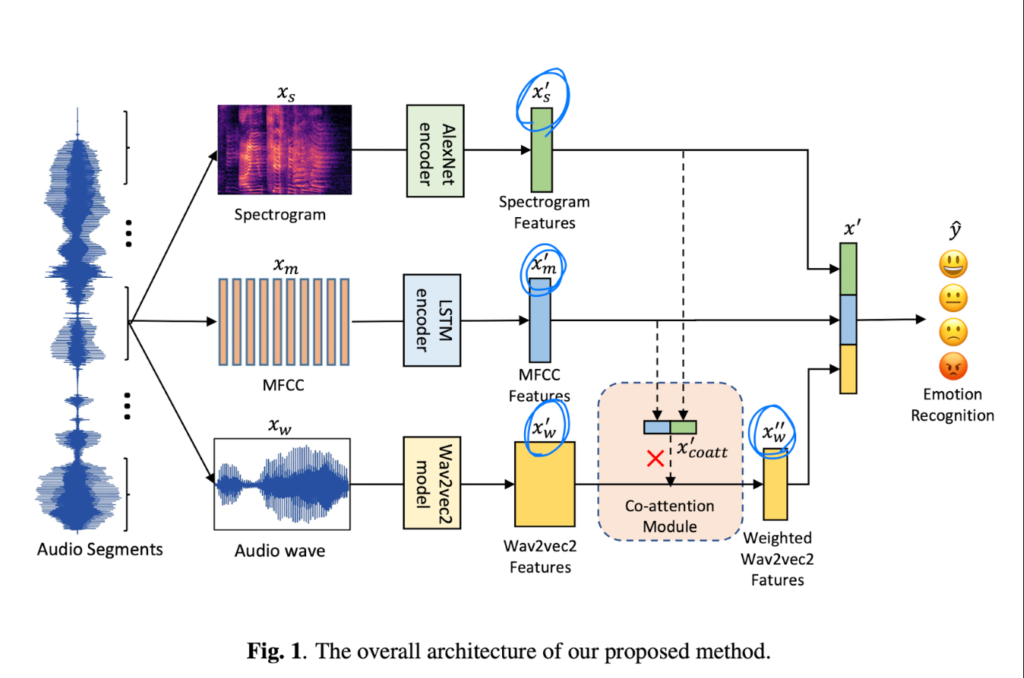
Fig 1을 보면 전체적인 구조를 파악할 수 있는데요. 그림을 보면 raw audio utterance를 몇개의 segment로 나눈 뒤에 segment에 3개의 level acoustic information (MFCC, spectrogram, W2E)를 각각의 feature encoder network에 넣은 뒤 co-attention으로 fusion하여 최종적으로 감정인식을 수행합니다.
같은 오디오 segment로부터 얻은 MFCC, spectrogtam, wav2vec2는 아래와 같이 표현됩니다.
- x_m\in{R^{T_m \times{D_m}}} : MFCC
- x_s\in{R^{T_s\times{D_s}}} : spectrogram
- x_w\in{R^{T_w\times{1}}} : spectrogram
각각의 encoder를 통해 추출된 feature는 아래와 같이 표현됩니다.
- x_m^\prime : the extracted MFCC features
- x_s^\prime : the extracted spectrogram features
- x_w^\prime : the wav2vec outputs
그리고 x_m^\prime와 x_s^\prime는 concat 되며, x_w^\prime의 각각의 다른 frame에 대한 가중치를 얻기 위해 linear layer로 변형됩니다. 이렇게 생성된 가중치를 곱한 뒤에 최종적으로 raw wav2vec outputs으로부터 W2E 벡터를 얻게 됩니다. 최종적으로 얻은 {x'’}w는 이전의 뽑아둔 feature x_m^\prime, x_s^\prime과 concat 됩니다. 이를 x\prime{coatt}라고 부르고 마지막 최종 feature combination을 x\prime이라고 표현합니다. y는 데이터의 target을 의미하고 최종적인 예측값은 y\hat이라고 표현합니다.
<learning with multi-level acoustic information>
더 자세하게 어떻게 multi-level acoustic information을 학습하는 지를 설명드리고자 합니다.
먼저 MFCC 입니다. MFCC는 0.5의 dropout을 가지는 양방향 LSTM를 이용하여 처리하였는데요. 이후에 flatten을 진행하게 되는데 이는 linear layer로 수행합니다.

[식 (1)]을 통해 수식으로 확인할 수 있습니다. 여기서 x_m^\prime \in{R^{D\prime_m}} 입니다.
다음은 spectrogram입니다. 먼저 사전 학습된 AlexNet으로 reshape을 진행해준뒤 MFCC와 동일한 연산작업에 따라 feature를 얻습니다. 수식으로 표현하면 [식 (2)]와 같습니다.
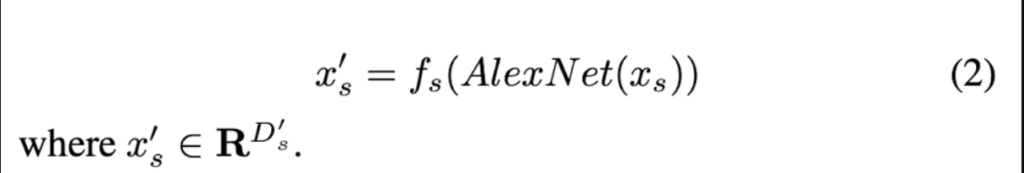
여기서 x_s^\prime \in{R^{D\prime_s}} 입니다.
다음으로는 raw audio segment입니다. raw audio segment는 바로 wav2vec2 processor와 wav2vec2 model로 보내집니다. 그렇게 해서 raw wav2vec2 output x_w\prime을 얻게 됩니다. 수식으로 표현하면 [식 (3)]과 같습니다.
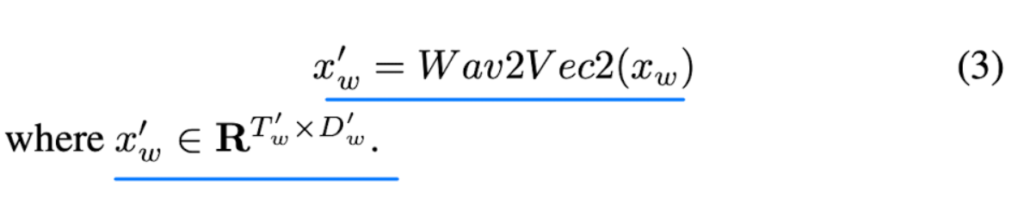
여기서 x_w^\prime \in{R^{T\prime_w}\times{D\prime_w}} 입니다.
<Co-attention-based Fusion>
세 가지 acoustic information sources가 최종 감정 예측에 비슷한 역할을 한다는 점을 고려하여서 이들 간의 상관관계를 사용하여 feature adaptation을 이루도록 유도합니다.
일반적으로 wav2vec2 output의 평균 혹은 last frame만 wav2vec2 feature를 표현하는데 사용되는데, 이는 명백히 sequence dimension 중 일부 effective information이 손실됨을 의미합니다.
논문에서는 이를 co-attention module을 통해서 해결하고자 합니다. 논문에서는 MFCC의 feature와 spectrogram feature에 의해 생성된 다양한 프레임의 W2E 가중치를 결합하는 co-attention module을 소개합니다.
처음으로, MFCC feature x_m^\prime과 spectrogram feature x_s^\prime로부터 transformation layer로 1-dimension matrix를 생성합니다. 수식으로 표현하면 [식 (4)]와 같습니다.
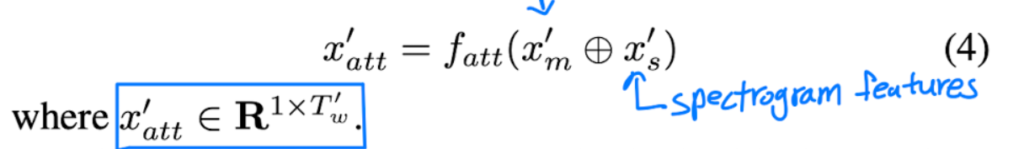
여기서 x_att\prime \in{R^{1\times{T_w\prime}}} 입니다.
최종 weighted wav2vec feature를 얻기 위해서 이전에 생성된 가중치를 wav2vec2 output과 곱합니다. 수식으로 확인하면 [식 (5)]와 같습니다.
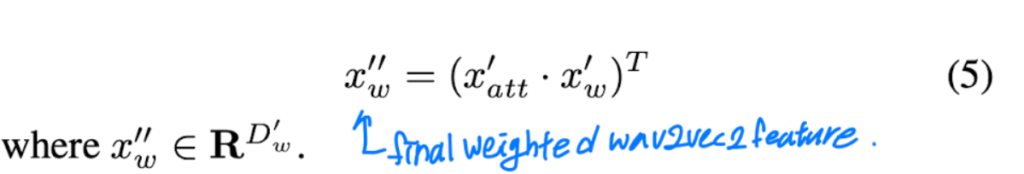
{x'’}_w\in{R^{D\prime_w}}입니다.
그래서 최종적으로 MFCC, spectrogram features, weighted W2E는 concat되어 음성 감정 예측값은 아래와 같이 표현됩니다.([식(6)])
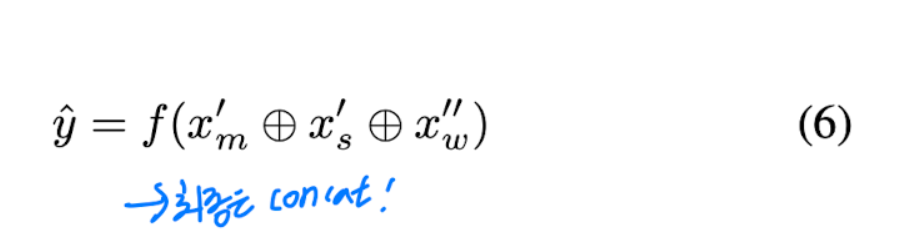
<objective>
목적 함수로는 cross-entropy loss를 사용하였습니다.
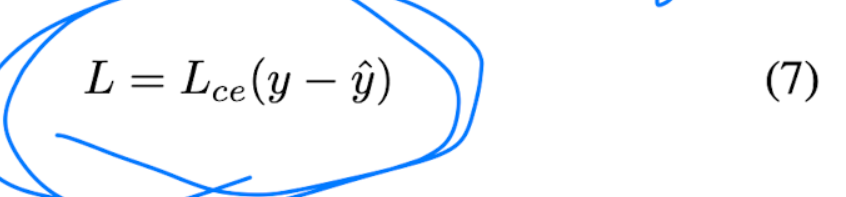
<Dataset>
이제 실험파트에 들어가게 되는데요. 이 논문에서 사용한 IEMOCAP에 대해서 간략히 설명드리고자 합니다. IEMOCAP(Interactive Emotional Dyadic Motion Capture)은 10명의 배우로부터 얻은멀티모달(오디오, 비디오, 텍스트, 모션 캡쳐) 감정 데이터셋 입니다. 멀티모달 감정인식 분야 논문을 읽게 되면 반드시 등장한다고 볼 수 있을 정도로 매우 유명한 데이터셋 입니다.
이 논문에서는 다른 논문들처럼 “happy”와 “excited”를 “happy”로 합쳤다고 합니다. 그래서 총 5531개의 sample이 있고, 4개의 감정(angry, sad, happy, neutral)으로 구성되어 있습니다.
더 정확하게 평가하기 위해서 5-fold leave-one-session-out 그리고 10-fold leave-one-speaker-out cross-validation 전략을 사용했다고 합니다. 이를 통해 화자 독립적인 결과를 생성해냅니다. 그리고 보통 사용되는 weighted accuracy (WA), unweighted accuracy (UA)를 평가 metrics로 사용하였습니다.
<Experimental Setup>
논문에서 사용된 raw audio signal은 16kHz로 sampling이 되었고, 각 audio utterance를 3초 길이의 segment로 나누었습니다. 만약 길이가 3초보다 작다면, 0으로 padding을 주어서 사용했다고 하네요. audio utterance의 마지막 예측 결과는 이 utterance로부터 모든 split된 segment에의해서 결정된다고 합니다.
MFCC를 어떻게 뽑고 했는지는 librosa 라이브러리를 이용해서 뽑았다고 하니 이 부분은 생략하겠습니다.
<Resuolts and Analysis>
<1. Results and Comparison>
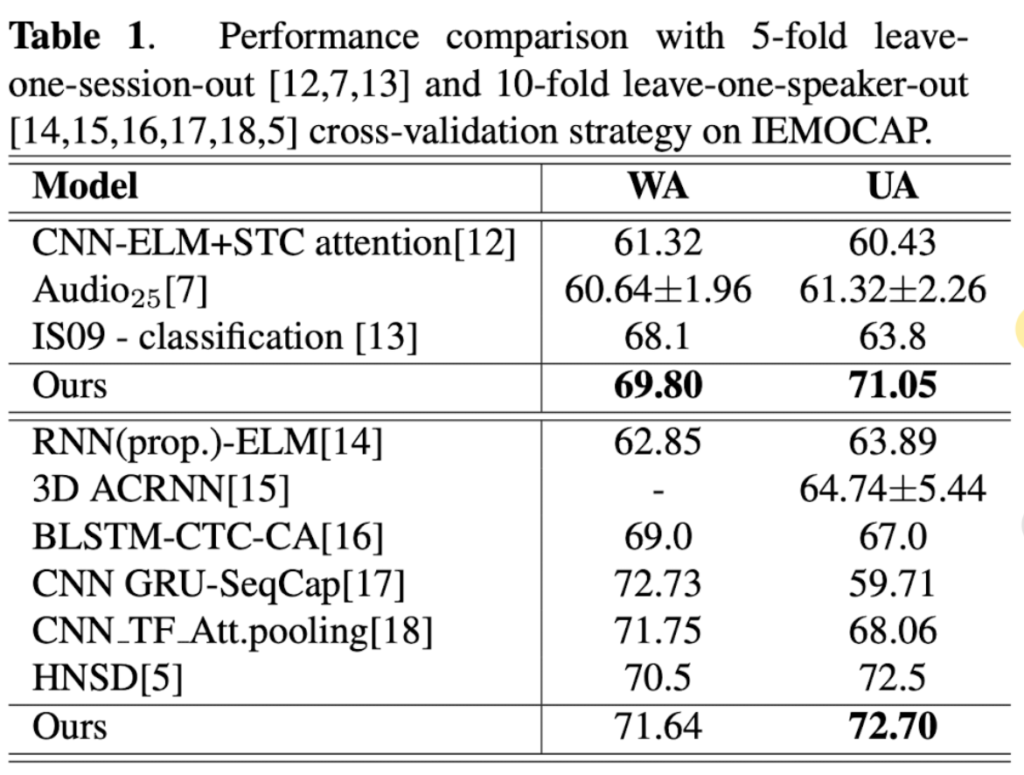
Table 1을 보시면 ours의 성능이 가장 좋은 것을 확인할 수 있는데요. leave-one-session-out validation strategy에서 UA와 WA측면에서 69.8%, 71.5%를 달성한 것을 확인할 수 있습니다.
그리고 leave-one-speaker-out-validation 전략에서 또한, UA에서 72.7%로 가장 높은 수치를 달성한 것을 확인할 수 있습니다.
<2. Ablation Study>
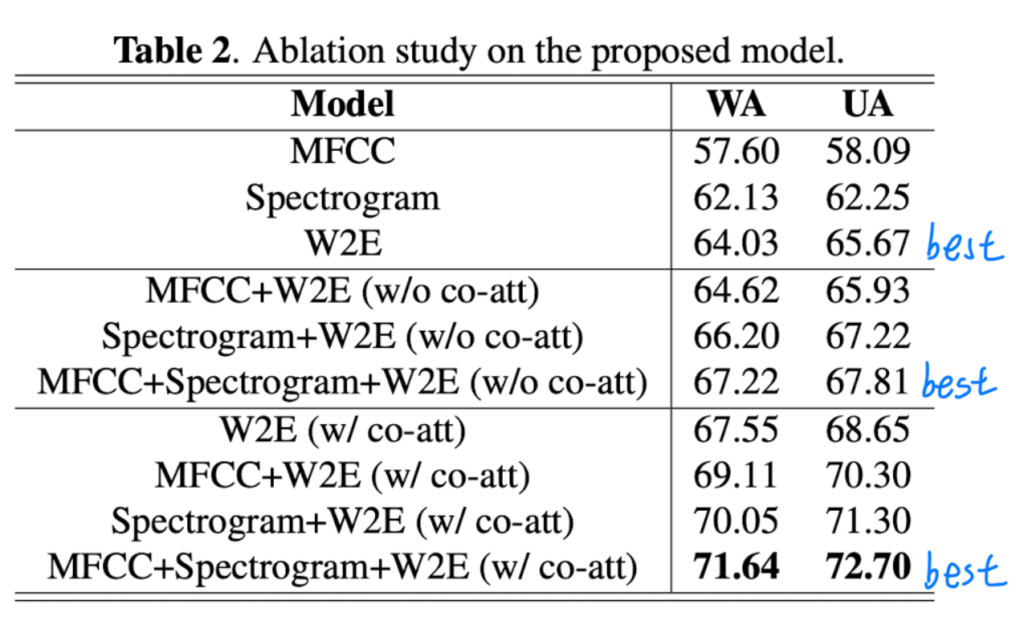
Table 2를 통해서 각자의 조합이 어느만큼 성능을 내는지 확인할 수 있습니다. 첫 3줄까지는 acoustic information의 하나 level만 사용했을 때 성능을 확인할 수 있는데, W2E가 가장 높은 성능을 내는 것을 확인할 수 있습니다. 2번째 칸은 다른 features와 W2E끼리 조합했을 때의 성능을 확인할 수 있습니다. 세번째 칸은 co-attention 후에 weighted W2E information과 다른 feature간 조합해을 때의 성능을 확인할 수 있습니다. 전체 모델의 성능에서 co-attention을 사용하여 모든 feature를 사용했을 때 성능이 가장 좋은 것을 확인할 수 있습니다.
또한 ablation study는 co-attention module의 효과 또한 확인할 수 있는데요. Table 2의 마지막 두 행에서 co-attention mechanism이 fused data를 더욱 최적화하며 direct concatenation 작업보다 WA와 UA에서 각각 4.42%, 4.89% 향상된 성능을 보입니다.
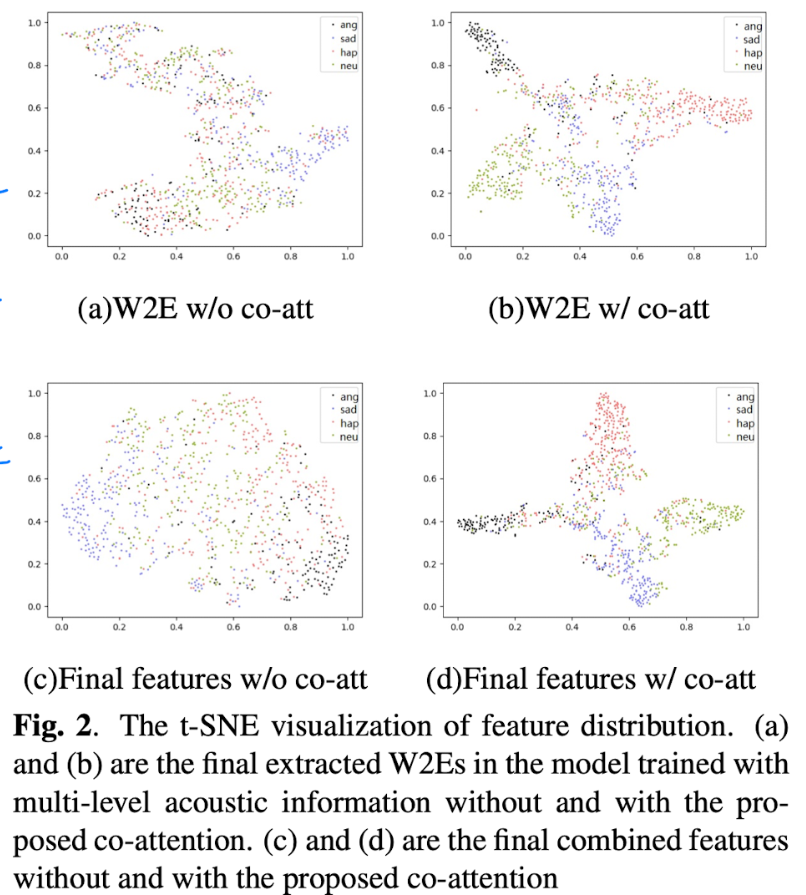
Fig 2에서 볼 수 있듯이, weighted W2E와 co-attention 후에 최종 combined된 feaure의 t-sne 시각화가 unweighted W2E와 co-attention 없이 최종 combined된 feature보다 훨씬 더 정확한 것을 확인할 수 있습니다.
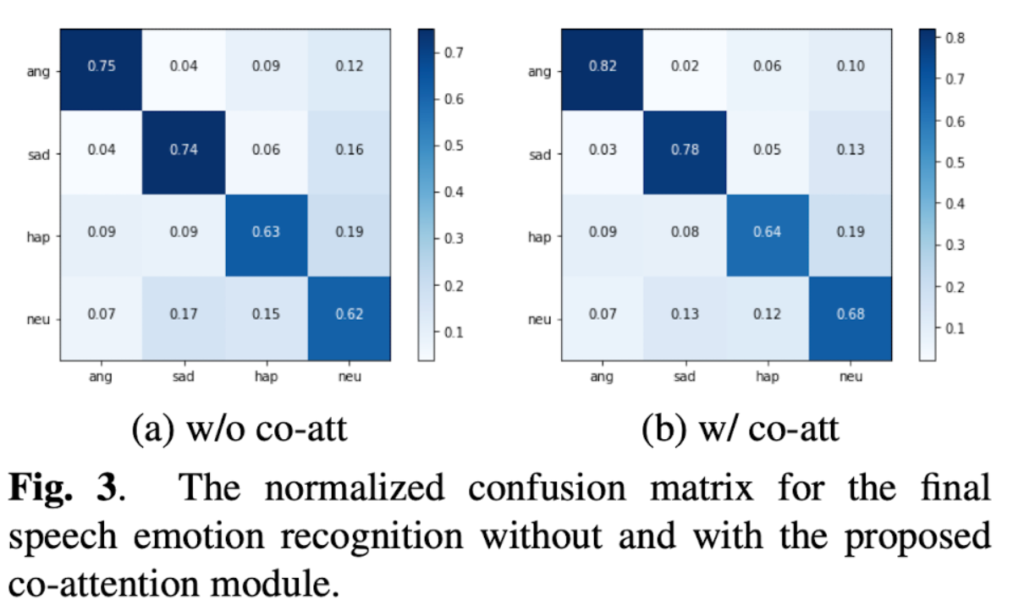
Fig 3을 통해 normalized confusion matrix를 확인할 수 있는데요. 여기서도 마찬가지로 co-attention이 적용된 모델이 co-attention이 적용되지 않은 뮤델보다 훨씬 좋다는 것을 확인할 수 있습니다.
이번 논문은 아이디어가 생각보다 간단했습니다. mfcc, spectrogram, waveform 모두를 사용하자는 것과 여기서 co-attention이라는 새로운 attention을 적용한 것이 전부인 것 같습니다. 저도 mfcc, spectrogram을 더하거나 concat하거나 해서 성능 향상을 시도해봤는데 결국 하나만 사용하는 것이 더 좋은 성능이 나왔던 기억이 납니다. 확실히 논문을 작성하려면 co-attention같은 contribution이 있어야 하는 것 같습니다. 이러한 것을 생각해내야 하다니….논문 쓰는 거는 굉장히 어려운 일인거 같네요…^^ 언젠가 저도 이러한 아이디어가 딱 떠오르기를 바라면서 리뷰 마치도록 하겠습니다. 읽어주셔서 감사합니다.
안녕하세요, 김주연 연구원님. 좋은 리뷰 감사합니다.
최대한 리뷰를 이해해보려고 이해해보았으나.. 아직 NLP쪽 기반지식이 많이 얕아 깊이 이해하기 힘드네요. 그래도 비전과는 비슷하면서도 달라서 흥미롭게 읽었습니다. 특히, (논문의 main주제와는 거리가 멀지만) 음성 신호를 spectrogram으로 변환한 뒤 CNN을 적용한 것이 저에게는 많이 신선했습니다. 막연히 CNN은 비전에만 사용하는 딥러닝 모델이라는 생각을 갖고 있었는데, 다양한 분야에 사용될 수 있음을 새롭게 알았습니다. time-domain과 frequency-domain 모두에서 활용될 수 있을 것 같네요.
리뷰를 읽다 보니 몇가지 궁금한 점이 생겨 질문 남깁니다.
1. 음성인식을 통한 NLP처리(여기서는 감정인식)의 파이프라인은, 일반적으로 음성데이터를 자연어 문장으로 바꾸고, 이를 다시 task에 맞게 적절히 처리하는 순서로 진행되나요?
2. 본 논문의 모델을 보면 총 3가지 feature를 fusion하는 것으로 보입니다. Fig1의 모델 구조에서 AlexNet encoder의 Spectrogram Features, LSTM encoder를 거친 MFCC Features, Wav2vec2를 거친 Wav2vec2 Features 이렇게 3가지 feature를 concat하는데, 3가지 서로 다른 속성의 feature들을 단순히 concat(이어붙이기) 해도 문제가 없나요? 각각의 feature vector들에 대해 concat하기 전에 별다른 처리는 하지 않는건가요?
3. 3가지 feature를 concat한 다음에는 바로 Cross-entropy를 거치게 되나요? 2번 질문의 연장인데, concat 한 이후 별다른 처리는 하지 않는 것인가요?
감사합니다.
안녕하세요. 댓글 감사합니다.
1. 네 맞습니다. 음성 데이터만 사용한다면 더 데이터를 풍부하게 가져가기 위해서 음성 + 음성을 자연어로 처리한 것 이렇게 가져가는 추세이기는 합니다.
2. 네 별다른 처리를 해주지는 않습니다. 별다른 처리가 정확히 무엇을 의미하는지는 잘 모르겠으나 (제 생각에는 normalization?) 이 세가지 정보를 concat하는 것으로 fusion을 진행합니다. 이러한 방법이 생소하게 느껴지실수도 있을 거 같은데 concat을 하여 fusion하는 방법은 많이 흔한 방법입니다.
3. concat후 바로 cross-entropy를 들어가는 것은 아닙니다. 식(6)을 보시면 concat한것을 f함수 안에서 진행하는데 저는 이 f함수를 fc layer로 이해하였습니다. 감졍 class개의 출력값을 가지는 fc layer 통과 후에 cross-entropy에 들어간다고 이해하시면 될 듯 합니다.
감사합니다
좋은 리뷰 감사합니다.
음성과 텍스트를 퓨전하는 것보다 음성 정보만 사용하는 것이 더 좋은 성능을 보일 수 있다는 점이 3d point cloud와 rgb를 퓨전하는 경우와 비슷하게 느껴져서 흥미로웠네요.
질문 드리자면 Mfcc, spectogram, waveform은 어떤 부분끼리 의미가 있는지 어떻게 파악하여 fusin하나요? 단순히 concat하는건가요?
안녕하세요. 댓글 감사합니다.
비록 중간에 co-attenton module이 있지만 최종적으로는 concat으로 fusion을 진행합니다. mfcc, spectrogram, waveform은 어떤 상관관계를 가지고 있는지 이해하기 위해서 아래처럼 생각하시면 될 듯힙니다. 음성 파일에서 아무런 가공하지 않은 waveform (low level) -> hand-crafted 방식으로 추출한 feature mfcc (low level) -> spectrogram (high-level) 이렇게 생각하시면 될듯합니다.
마지막에 concat으로 fusion하는 것에 대해서는 저는 이렇게 생각하였는데요. 각 feature에 어떤 정보를 추출하여 이것만 사용하겠다 보다는 모든 정보를 다 사용하여서 감정인식을 해보겠다라는 생각으로 concat을 진행한 것이라 생각합니다.
감사합니다.
안녕하세요 좋은 리뷰 감사합니다 !
본 논문에서 주장하는 바는 결국 frequency domain에서 추출한 feature인 MFCC, spectrogram과 time domain information인 waveform의 장점을 같이 사용하기 위해 fusion을 한 것이라고 이해해도 될까요 ?
그렇다면 생각해보았을 때 frequency와 time이라는 서로 다른 domain에서 추출된 feature인 MFCC, spectrogram, wavefrom이 가진 유효한 정보의 결이 다를 것이라고 생각을 했는데 Co-attention base fusion 부분에서 결국 세 가지 정보의 source가 최종 감정 예측에 비슷한 역할을 한다고 되어 있어서 제 예상과 달라 의아했던 것 같습니다.이 부분에 대해서 한 번 더 설명해주시면 감사합니다.
안녕하세요. 댓글 감사합니다.
네 맞습니다. 이 논문의 요지는 ‘다른 논문들은 frequency domain만 사용하는데 나는 time domain information도 사용해보겠어’가 맞습니다.
사실 건화님이 말씀하신 ‘유요한 정보의 결이 다른데 왜 최종 감정 예측에 비슷한 역할을 하는지’에 대해서 잘 이해되지 않지만 제가 이해한만큼 설명드리고자 합니다. 저는 이 논문의 컨셉이 모든 정보를 다 활용하자라고 생각하였습니다. frequency domain만 사용하지 말고 time domain도 사용하자는 것도 많지만 frequency domain에서 추출한 feature, time domain에서 추출한 feature 정보를 모~두 사용하여서 최종적인 결과물을 얻기 위해서 concat을 진행하였다고 생각하였습니다.
+ 아 작성하다보니 왜 이런 질문을 했는지 이해가 되네요. 아마 논문에서 저렇게 말한 이유는 정보의 결이 다르나 결국에는 모두 감정인식에 동일한(이 표현은 ‘동일한 정도’, ‘비슷한 기여도’라고 생각하시면 될 듯 합니다) 기여를 한다는 것이지요.
감사합니다
안녕하세요 김주연 연구윈님 좋은 리뷰 감사합니다.
멀티모달이 아닌 SER 논문은 오랜만인 것 같습니다. ㅎㅎ
네트워크의 구조 중 이해가 가지 않는 부분이 있어 질문드립니다. 그림 1을 보고, utterence를 segment로 나누고, 하나의 segment를 세 가지 인코더에 통과시켜 감정을 인식한다는 것으로 이해하였습니다. 그렇다면 각 segment에 대한 감정을 각각 인식한다는 것인데 실험에 사용되는 데이터셋은 utterence 당 하나의 감정이 매핑되어 있는 것으로 알고 있습니다. 이때 audio utterence의 최종 예측 결과는 어떤 식으로 결정되는 지 궁금합니다.
안녕하세요. 댓글 감사합니다.
정확히 이해하셨습니다. 한 segment에 대해서 감정인식을 진행한 후에 이것을 합쳐 최종 감정인식을 진행하는 것이 맞습니다. 근데 저도 의문인 것이 최종적으로 어떻게 감정인식을 진행한다는 말이 논문에서 없어서 각 segment 당 감정을 인식하여 많이 나온 감정으로 최종 감정을 정하는 것인지 혹은 segment당 감정 class 확률을 합쳐서 가장 큰 확률을 가지는 것을 최종 감정으로 정하는 것인지 헷갈렸는데 저는 후자라고 생각하고 있습니다.
감사합니다
안녕하세요, 좋은 리뷰 감사합니다.
이번에 소개해주신 논문에서는 결국 handcrafted feature를 추출한 뒤 DL 모듈에 별도로 태워 얻은 feature를 잘 활용하는 것 같습니다.
음성 도메인에 관련하여 질문이 있습니다. 보통 발화가 섞여있는 ‘음성’ 데이터의 경우에는 일반적으로 사람의 가청 주파수 대역을 고려해 sampling rate를 44100으로 지정해준다고 하셨는데, 클래식, 팝, 레게 등의 장르를 가지는 ‘음악’ 데이터의 경우에도 sampling rate를 44100로 지정하는 것이 유효할까요?
또한 spectrogram, mfcc 이외에, 굳이 성능이 높지는 않더라도 음악 데이터를 다루는 데에 적합하여 추천해주실만한 feature가 있는지도 궁금합니다.
안녕하세요. 댓글 감사합니다.
1) 저는 음악이라 할지라도 결국에는 sampling rate를 44100으로 지정해주는 것이 맞다고 생각하는데요. 음악이라는 것도 결국에는 사람이 듣는 것이기 때문에 사람의 가청 주파수를 고려한 44100으로 rate를 가져가는 것이 옳다고 생각합니다. 그리고 제가 다른 논문들을 봤을 때를 봐도 44100이상의 수로 rate를 가져가는 논문은 없었던 것 같습니다.
2) 음악 데이터는 저도 생소해서 조언을 드리기 힘들지만 이전에 VAD 서베이를 진행했을 때 음악도 detect하는 논문이 있었는데 그 논문도 spectrogram 혹은 mfcc를 feature로 사용했던 기억이 납니다. 음악일지라도 spectrogram, mfcc를 이용하는 것이 좋을 것이 두 feature 이외에 등장하는 feature는 본 기억이 없네요. (waveform을 그래도 사용하는 논문을 본 기억은 있으나 대부분 spectrogram, mfcc를 사용하는 듯 합니다)
감사합니다