Introduction
Few-shot classification 이란 이름에서 알 수 있듯 매우 적은 example이 주어진 상황에서 분류를 수행하는 것을 의미합니다. 아래의 그림을 예시로 들자면 두 가지의 class(dog, otters가 있고 각 class별로 단 4장의 training data가 주어진 상황에서 새로운 데이터가 어느 class에 속하는지 알아내는 task입니다.

기존에 사용되던 Neural Network를 사용한 학습은 few shot과 같이 매우 적은 양의 데이터를 가진 환경에서는 쓸만한 성능을 보여주지 못했습니다. 이에 연구자들은 ImageNet과 같이 많은 양의 데이터로 학습을 수행하고 few-shot data에 적응시키는 방식을 시도하였습니다.
few shot classification의 일반적인 방법론은 large dataset(base data)으로 backbone을 학습시키고, few-shot data(novel data)로 분류기를 fine-tuning하는 것이라고 합니다.
한 가지 특이한 점은 few-shot classification은 base class에 속하지 않는 새로운 training sample이 few-shot data로 주어지기 때문에 classifier를 학습시킬 때 novel class(새로 등장한 class), novel data(일반적인 관측값에서 벗어난 데이터)에 대응하는 것이 중요하다고 합니다.
이 논문에서는 기존 few-shot classification연구의 두 가지 문제점을 지적합니다. 하나는 implementation issue로 이전 연구에서 사용되던 실험 환경이 너무 제각각이라는 것입니다. 실험 세팅이 하나로 정해진 것이 없다보니 환경에 따라 성능이 다르게 나오며, 이로 인해 방법론들간의 공정한 비교가 불가능하다는 문제점입니다. 다른 하나는 평가 데이터와 학습 데이터가 동일한 문제입니다. 앞서 언급했듯이 base data와 few-shot data는 서로 다른 class를 가지고 있어 class는 novel하지만, base와 few-shot을 동일한 데이터셋에서 가져왔기 때문에 domain관점에서는 novel하지 못하다는 단점이 있다고 합니다.
이 논문에서는 기존의 few-shot classification 방법론들을 정리, 분류하고 보다 공정한 비교를 진행합니다. 또한 공정한 비교를 통해 모델이 깊을수록 방법론 간의 성능 차이에 관해 분석하였습니다.
Overview of Few-Shot Classification Algorithms
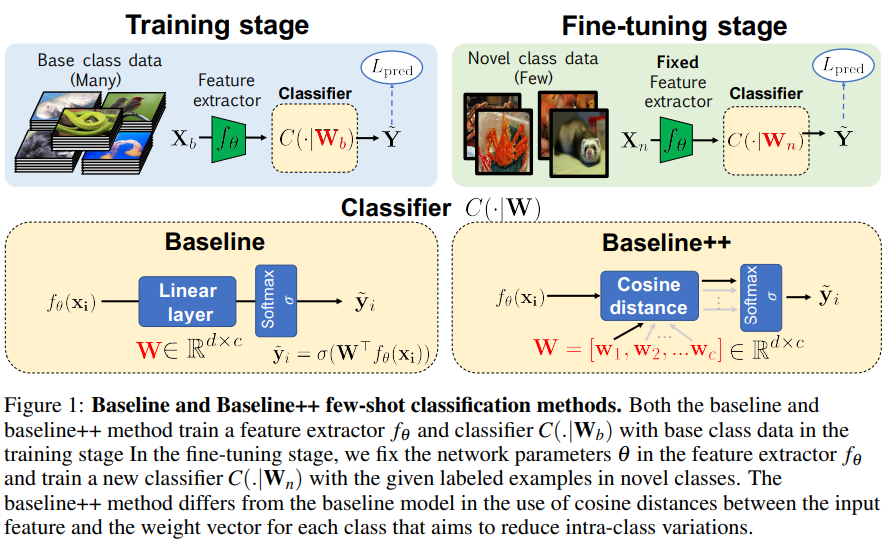
Baseline
introduction부분에서 잠깐 언급했던 것과 같이 Base class로 feature extractor f_{\theta}를 학습시키고, f_{\theta}를 고정시킨 뒤 few-shot data(그림의 Novel class data)로 classifier를 fine tuning합니다. 논문에서 baseline이라고 언급되는 네트워크는 위의 그림과 같이 FC layer + softmax로 이루어져 있습니다. loss로는 cross-entropy를 사용하였다고 합니다.
Baseline++
baseline++는 단순 분류기인 baseline구조에 similarity를 추가로 이용하는 방법론입니다.
baseline의 마지막 레이어를 이제 코사인 유사도 기반의 레이어로 변경하였습니다. W\in \R^{d\times c}가 baseline linear레이어의 파라미터를 나타낸다면, cosine distance기반의 레이어는 W를 W=[w_1, w_2, …, w_c]\in \R^{d\times c}로 표현하였습니다. w_j는 각 class를 나타내는 파라미터이며 baseline++의 classifier는 feature extractor의 출력인 f_{\theta}(x_i)와 w_1, w_2, …, w_c간의 코사인 유사도를 출력으로 합니다. 이로인해 비슷한 class끼리 가까워지고, 다른 class끼리는 멀어지도록 학습하여 intra-class vatiation을 줄인다고 합니다.
Meta-Learning Algorithms
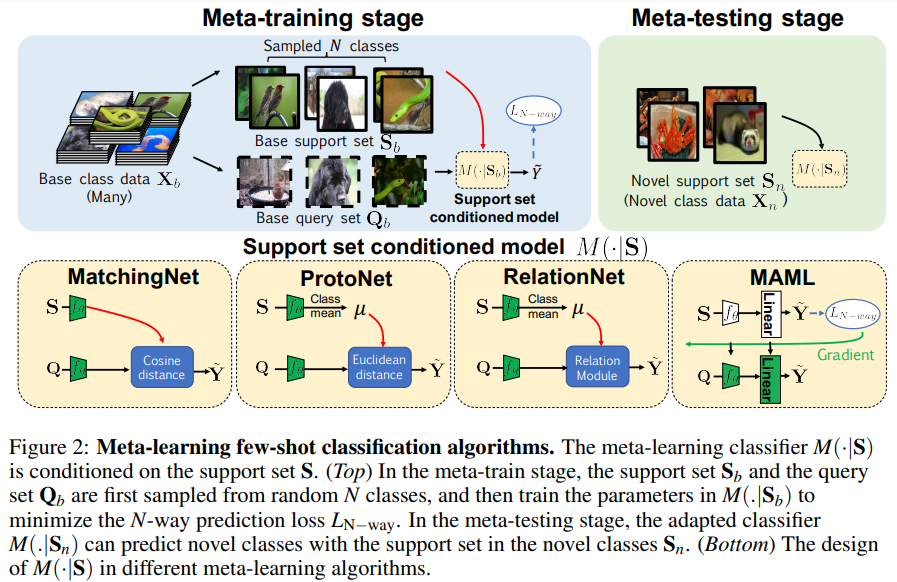
Meta-learning은 학습 데이터를 meta-training(baseline의 base data)과 meta-test(few-shot data)로 나누고, meta-training을 meta-support set, meta-querey set으로 나누어서 학습합니다. support set으로는 class의 representation을 학습하고, query는 예측할 클래스를 학습하게 됩니다.
meta learning에서는 support set과 query set을 총 네 가지의 conditioned method를 사용하여 학습을 진행하였습니다.
MatchingNet은 단순 비교 방식으로 support set의 이미지들로부터 feature를 뽑고, query 이미지의 feature와의 코사인 유사도를 통해 가장 유사한 것을 예측합니다.
ProtoNet은 MatchingNet과 비슷한 구조를 띄고 있으나 Cosine distance 대신 Euclidean distance를 사용합니다. 또한 각 support set의 class별 mean feature만을 사용하여 query와의 유사도를 계산하였다고 합니다.
RelationNet은 ProtoNet에서 Euclidian distance를 구하는 부분을 learnable한 모델로 대체한 구조입니다. S와 Q의 feature를 계산 후 s_1, s_2, …와 q의 feature간의 distance를 직접적으로 구하던 기존 방식들과 달리 S의 각 feature들과 q를 concat하여 relation network의 입력으로 사용하였다고 합니다.
MAML은 좋은 initial point를 찾기 위한 방식으로 meta test를 진행할 때 각 episode의 optimal한 point로 학습이 되도록 한다…고는 하는데 솔직히 잘 모르겠습니다… 이 부분은 추후 수정하도록 하겠습니다.
Experiments
실험에는 Mini-ImageNet과 CUB 데이터를 사용하였습니다. Mini-ImageNet은 총 100개의 class를 가지며 각 class 당 600장의 이미지가 있다고 합니다. 논문에서는 100개의 클래스 중 64개를 training에, 16개를 validation에, 나머지 20개를 test에 사용하였습니다. Backbone으로는 4개의 conv레이어를 사용하였습니다.
Evaluation Using the Standard Settings
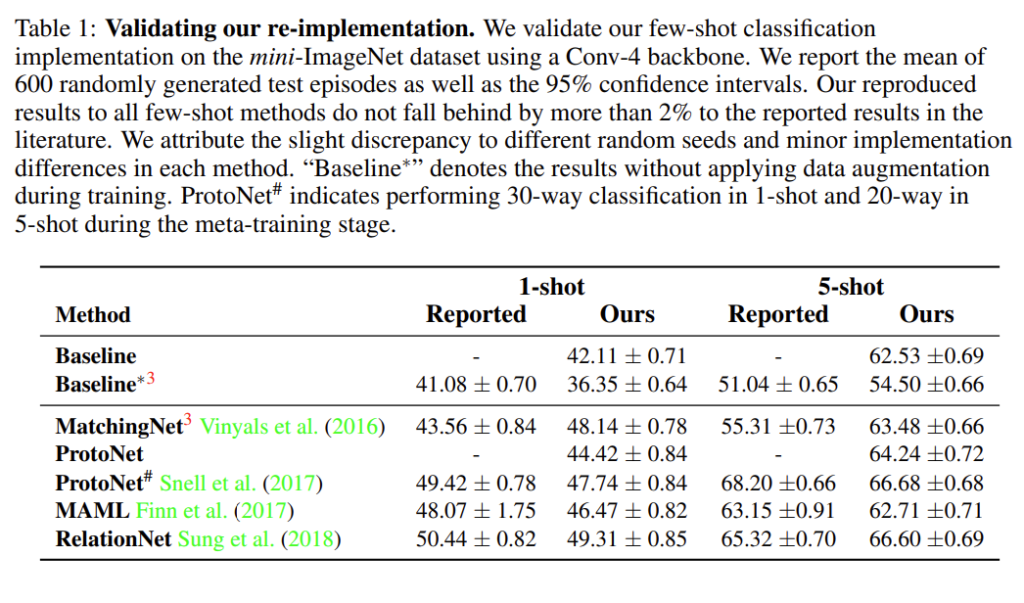
[표1]은 re-implementation 결과입니다. 저자들이 실험한 결과(ours)와 기존 논문에 리포팅된 성능(reported)을 보여주고 있으며, 두 성능의 차이가 발생하는 부분은 baseline과 동일한 세팅을 사용하여 발생하는 성능 변화라고 합니다. 논문에서는 similar re-implementation performance라고 언급하였습니다.
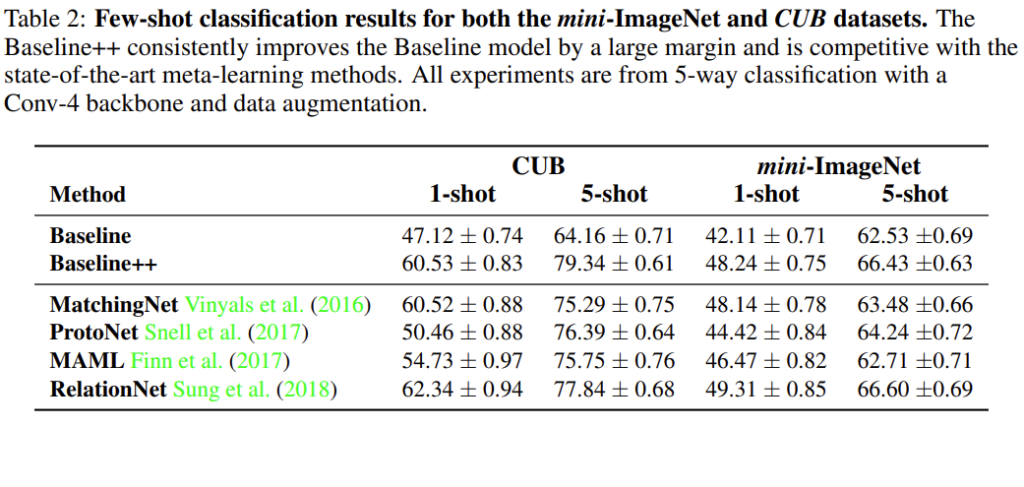
[표2]는 re-implementation된 모델들을 CUB와 mini-ImageNet으로 실험한 결과를 보여주고 있습니다. Baseline과 Baseline++의 성능 차이를 통해 intra-class의 variation을 줄이는 것이 few-shot classification성능 향상을 이루었음을 확인할 수 있습니다.
Effect of Increasing the Network Depth
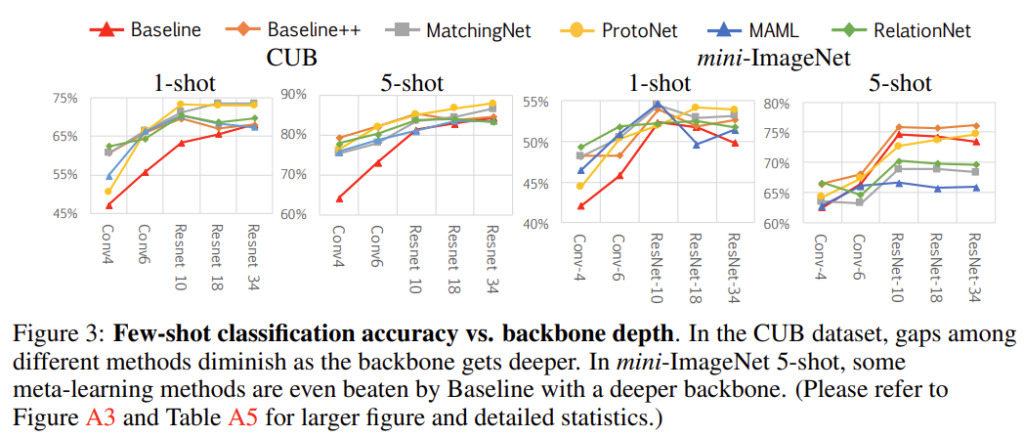
[표2]의 설험은 conv4를 backbone으로 실험하였다면[표3] backbone의 깊이에 따른 성능을 보여주고 있습니다. CUB는 backbone이 깊어질수록 방법론 간의 성능 차가 줄어들지만 mini-ImageNet은 그렇지 않은 모습을 볼 수 있습니다.
저자들은 이를 meta train과 meta test 데이터 간의 domain difference에 의한 결과로 보았습니다.
Effect of Domain Difference Between Base And Novel Classes
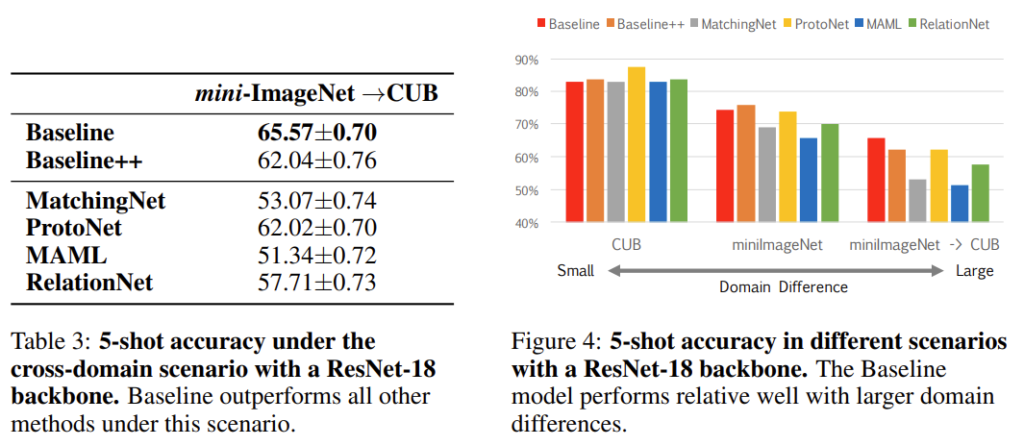
[표3]과 [그림4]는 데이터셋의 도메인에 따른 성능 차이입니다.
논문을 읽고나서 자신의 생각을 추가적으로 남겨주면 좋을 것 같습니다.
좋은 리뷰 감사합니다.
앞서 발표 하셨을 때 implementation issue에 대해 공정한 비교가 불가능하다는 문제점에 대해서 질문이 있습니다. 공정한 비교가 불가능하다는 것이 잘 와닿지가 않는데, 실험 환경이 하나로 정해져 있지 않아 성능이 상이한 문제는 few shot classification 연구에서만 해당하는 문제인 건지 궁금합니다.
감사합니다.
논문에서 알고리즘을 제안하고 이를 평가하기 위해 여러 metric을 사용합니다. 그러나 여러 논문에 등장하는 알고리즘간의 성능을 비교하기 위해서는 공통된 실험 환경을 구축하여야 합니다. 예를 들자면 Image classification task에서 Train, Test 이 별도로 존재하는 데이터셋인 ImageNet 1k의 분류 성능을 top1 acc로 평가한 결과를 여러 논문에서 리포팅하고 있어 이를 통해 알고리즘 간의 비교가 가능하게 됩니다.
논문에서는 이를 위해 1shot, 5shot 세팅을 유지하여 기존 알고리즘의 re-implementation을 진행하였습니다.
실험 환경에 의해 성능이 상이한 문제는 few-shot classification에서만 해당되는 문제는 아니고 다른 task에서도 발생하는 것으로 알고 있습니다. 다크데이터 팀에서 리뷰하는 랜덤성에 의한 성능 변화도 이러한 맥락에서 발생하는 문제점이라고 생각합니다.
좋은 리뷰 감사합니다.
실험걀과에서 1 shot과 5 shot이 의미하는 것이 새로운 noble data를 1장, 5장 줬다는 게 맞나요?
그리고 noble data는 완전히 새로운 디른 data에서 가져온 게 맞을까요? 처음에 기존 연구의 문제제기를 할 때 base와 few shot 데이터를 같은 데이터에서 가져오면 domain 관점에서 noble하지 못하다는 말 때문에 질문드립니다!
n-shot은 한 클래스 당 예측할 이미지의 수로, 실험의 1 shot과 5 shot은 예측 클래스 당 주어지는 이미지가 각각 한 장, 5장임을 의미합니다.
표1, 표2의 실험에서는 source와 target이 동일한 데이터셋의 서로 다른 클래스의 데이터를 사용하였고, 말씀하신 domain관점에서의 실험은 표3, 그림4에 해당합니다.
안녕하세요.
일반적으로 가지고 있는 데이터의 수가 적을 때는 학습을 진행하는 신경망의 크기를 작게 하는 것으로 알고 있습니다. (흔히 사용하는 전이학습에서도, 데이터가 모자랄 수록 뒤쪽 레이어만 fine-tuning하구요.)
그런데 그림 3의 차트를 보면 실제로 더 적은 계층의 모델이 더 좋은 성능을 보이기도 하고, 의외로(?) 더 깊은 모델이 더 좋은 성능을 보이기도 하는데, 이러한 차이는 모델의 구조에 의한 것일까요?
감사합니다.
말씀하신 차이가 가장 두드러지는 경우인 mini-ImageNet의 1-shot 그림에서 MAML을 예로 들자면 renet-10에서 가장 높고 resnet-18에서는 conv6보다 낮아졌다가 resnet-32에서는 다시 성능이 상승하는 것을 보입니다. 그러나 데이터셋이 CUB로 달라지면 또 다른 성능 분포를 보이는 것을 확인할 수 있는데요 이러한 차이는 모델 구조보다는 데이터의 도메인에 의해 발생하는 것이라고 이해하였습니다.
안녕하세요. 좋은 리뷰 감사합니다.
이전에 gpt를 리뷰하면서 few shot learning이라는 것에 대해서 알게 되었는데 다시 만나서 반가운 마음이 드네요. 다시 정리할 수 있어 감사합니다.
1) meta learning에서는 support set과 query set을 총 네 가지의 conditioned method를 사용하여 학습을 진행하셨다고 했는데 추후에 이 4가지 method에 대해서 언급이 없는데 자세히 설명해주시면 감사합니다.
2) figure4는 데이터셋의 도메인에 따른 성능 차이라고 하셨는데 도메인의 차이가 적다는 것과 크다는 것을 혹시 예를 들어서 설명해주시며 감사하겠습니다. 당연히 차이가 적으니 성능이 높겠다고 생각이 드는데 도메인 차이가 적다는 것이 무엇을 의미하는지 잘 이해가 되지 않습니다.
1. 4가지 method는 각각 MatchingNet, ProtoNet, RelationNet, MAML로 본문에 제시되어 있습니다.
2. 그림4 는 각각 source -> target을 CUB->CUB, miniimagenet -> miniimageNet, mini-imagenet -> CUB로 사용하였을때의 결과를 나타냅니다. 이때 도메인의 차이에 따른 성능임을 이해하기 위해서는 각 데이터셋에 관해 알아야 합니다. mini-ImageNet은 ImageNet의 일부 class를 sampling한 것으로 car, dog 등 여러 class를 가지고 있습니다. CUB는 새의 종류를 label로 가지고 있어 ‘bird’라는 공통된 속성을 가지고 있습니다. 따라서 CUB의 source와 target이 mini-imagenet의 source와 targt보다 유사한 도메인이라고 할 수 있습니다.
안녕하세요. 좋은 리뷰 감사합니다.
표1에 있는 baseline*은 baseline++인가요? 만약 아니라면 baseline*은 무엇이며, baseline++은 기존에 있던 방법론이 아닌 저자가 제안한 새로운 방법론인가요?
또 protoNet에 대한 reported 성능 부분이 비어있는 이유가 있는지 궁금합니다. 이것 또한 저자가 제안한 방법론이라 그런건지 혹은 다른 이유가 있는지 언급이 되어 있지 않는 것 같아 질문 드립니다.
마지막으로 데이터셋의 도메인에 따른 성능을 비교하는 표에서 baseline이 다른 메소드보다 가장 성능이 좋은데 이에 대한 분석을 도메인 관점에서 설명 부탁드려도 괜찮을까요 . . . ?
감사합니다.
표1의 Baseline* 은 Baseline에 augmentation을 적용하여 학습한 것으로 baseline에서 data augmentation을 유무에 따른 성능을 비교하는 것입니다. baseline++는 baseline을 기반으로 저자가 제안한 방법론입니다.
conditioned모델은 모두 기존에 다른 논문에서 제안되었던 방법론으로 reported는 기존 논문에서의 성능을 의미합니다. 공백이 존재하는 이유는 ProtoNet의 경우 mini-ImageNet의 1shot, 5shot성능이 나와있지 않기 때문입니다.
meta training에서 기존 모델들은 support data가 동일한 dataset에 있었기 때문에 새로운 데이터에 대한 적응력이 떨어지는 경향을 보입니다. 그러나 저자의 baseline은 새로운 classe를 가지는 데이터를 기반으로 classifier를 바꾸고 학습하기 때문에 새로운 class에 빠르게 적응할 수 있고 mini-imagenet에서 cub로의 도메인 이동에도 강인하다는 것이 이 논문에서 주장하는 바이며, 표3의 결과로서도 확인 할 수 있습니다.