
오늘 리뷰할 논문은 고려대학교 김승룡 교수님 연구실에서 작성된 논문입니다.
Mutual Learning, Uncertainty map과 관련된 리뷰로 저번 리뷰처럼 masking 관련된 내용들이 흥미로워서 찾아보다가 citation을 타고타고 읽어보게 되었습니다.
제가 진행중인 실험은 Semantic Segmentation task인데 리뷰는 또 어쩌다 보니 Depth 논문이네요. 언젠간 다시 Depth 관련 연구를 진행해보고 싶다는 생각을 하면서,, 리뷰 시작하도록 하겠습니다.
(++ 해당 리뷰 의 전반부 내용을 참고하시면 depth estimation의 전반적인 흐름과 틀에 대해 이해하실 수 있으니, 신입 연구원분들이나 depth task에 대해 처음 접해보시는 분들은 참고한 뒤 리뷰를 읽어 보시면 더 도움이 될 듯 합니다.)
Introduction
Depth Estimation, Semantic Segmentation 등 CV와 Robotics 분야에서 Semi, Self Supervised 방식으로 문제를 해결하는 논문들의 Introduction 서술 흐름은 대부분 유사합니다.
pixel-level의 annotation 비용이 비싸기 때문에 large한 labeled dataset이 부족한 실정이며, supervised 방식으로 해결하려고 하면 이런 부족한 labeled dataset에 의존하게 되어버린다는거죠. 그렇기 때문에 semi-supervised나 self-supervised 방식으로 Depth Estimation 문제를 해결하고자 하는 연구들이 많이 등장하게 됩니다.
monocular depth estimation을 수행하는 연구들 중 stereo의 예측을 pseudo label 삼아 mono network를 학습시키는 연구들이 많이 수행되었습니다. 아무래도 1장으로 예측하는 mono보다는 2장을 함께 사용해서 예측하는 stereo의 성능이 더 높으니 이러한 방식을 사용하게 됩니다.
물론 stereo가 mono에 비해 예측을 잘 수행하기는 하지만, stereo가 예측한 pseudo label에도 부정확한 예측이 존재할것입니다. 그래서 pseudo label의 이러한 부정확한 영역을 걸러주고 정제해주기 위한 confidence(신뢰도) 를 예측하는 방식들이 앞서 제안되었구요. 하지만 저자는 이러한 앞선 방식들이 2가지의 문제가 있다고 주장합니다.
i) pseudo label 을 예측하기 위한 stereo network가 필요하다.
ii) pseudo label의 confidence를 추정하기 위한 추가적인 module이 필요하다.
i)번과 ii)번의 문제 모두 추가적인 network가 필요하기 때문에 이들의 적용성(applicability)에 한계가 있을 수 밖에 없다고 설명하며 아래와 같은 구조를 제안합니다.
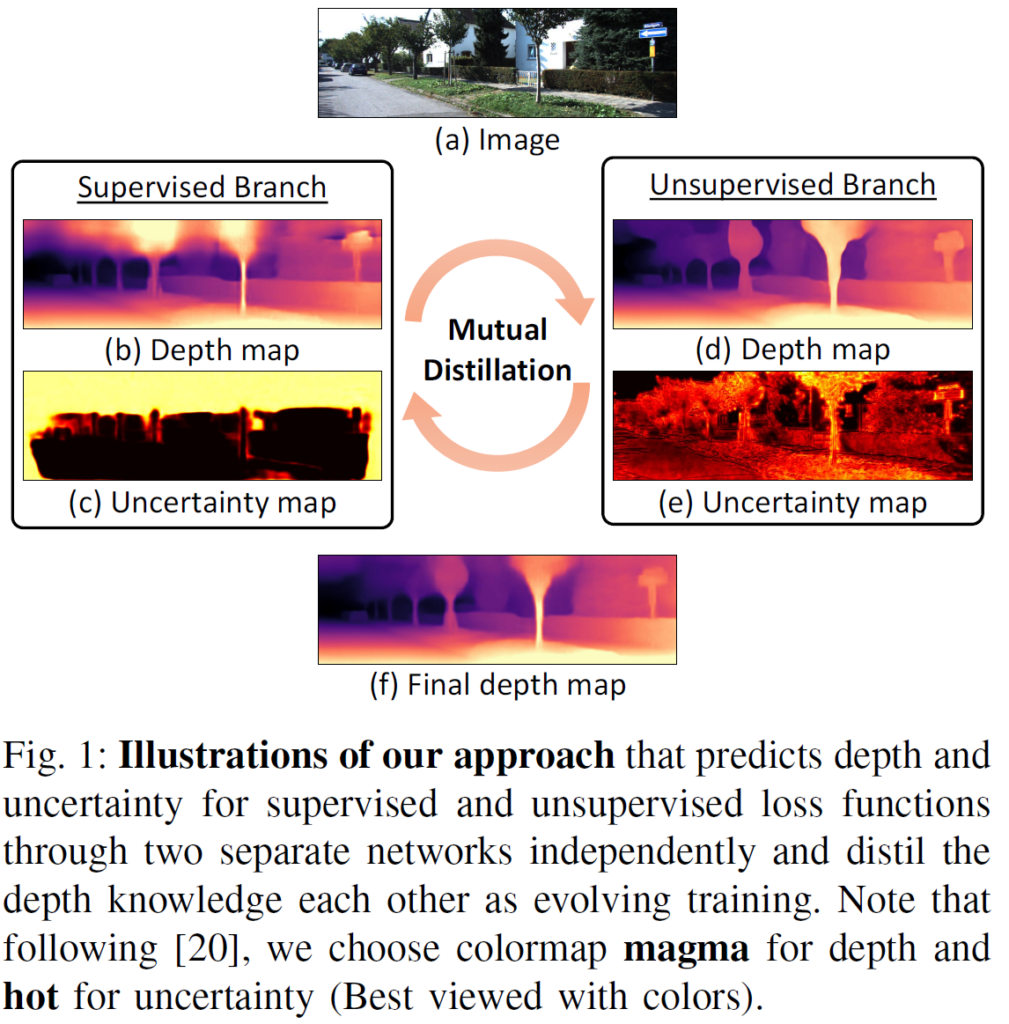
입력 이미지에 대해 좌측의 Supervised Branch와 우측의 Unsupervised Branch가 함께 Mutual Distillation을 통해 학습을 진행하는 방식입니다. 두 Branch의 모델 모두 1장의 이미지로 학습과 예측을 수행하는 mono model을 사용하였구요.
그런데 여기서 Mutual Learning을 진행하는데 왜 두 Branch를 Supervised와 Unsupervised로 나누었을까?? 라는 의문이 들 수 있습니다. 이왕 gt를 사용할꺼면 두 Branch 모두 사용하는게 낫지않을까 라는 당연한 의문점이죠.
저자는 Supervised와 Unsupervised loss가 서로의 장,단점이 존재하기 때문에 두 Branch를 나눈것이고, Mutual Distillation을 통해 서로의 이점을 보고 배우며 단점을 보완하는 방식으로 학습이 진행되길 기대한것이지요. 사실 무조건 gt 사용하는 것이 좋을것이라 생각이 들긴 하는데 흠,,,
그렇다면 여기서 저자가 말하는 Supervised loss와 Unsupervised loss의 각각 장단점은 무엇일까요??
unsupervised loss는 object boundary 영역에서 blurry한 결과가 나타난다는 문제점이 있습니다. 사실 해당 문제점은 앞선 많은 연구들에서 다뤄왔던 문제점이고, 이를 해결하고자 많은 기법들도 제안이 되었죠.
간단하게만 설명드리자면, blurry한 결과는 occluded pixel때문에 발생하게 됩니다. 가령 이미지 A,B가 입력으로 들어왔다고 생각해 봅시다. A에서 특정 점이 B에서의 특정 점과 매칭이 되어야 disparity를 구할 수 있을텐데, B에서 그 점이 가려진(occluded) 상태라면 어떻게 될까요? 해당 점에 대해서는 disparity 계산이 불가능하고, 이 때문에 blurry한 깊이 결과가 생성이 되게 됩니다.
그리고 supervised loss의 경우는 sparse 하다는 문제점을 가진다고 합니다. gt depth는 LIDAR를 통해서 구해진 값일텐데, LIDAR의 특성 상 gt depth와 이를 통해 계산되는 supervised loss가 sparse 하다는것이죠.
아, 해당 문제점도 앞선 연구들에서 풀어야 하는 문제로 언급이 많이 되었습니다.
저자는 위처럼 unsupervised와 supervised loss가 각각의 장단점이 있기 때문에 이들을 서로 다른 Branch의 모델로 구성하고 Mutual Distillation을 통해 서로의 장점을 배우는 방향으로 학습을 진행하기를 기대하였습니다.
추가적으로 위에서 언급드린 supervised loss의 문제점을 해결하고자 unprojected point filtering loss 라는 loss를 통해 gt depth가 존재하지 않는 sparse 영역을 보완하고자 하였습니다. 이는 뒤에서 자세히 설명 드리겠습니다.
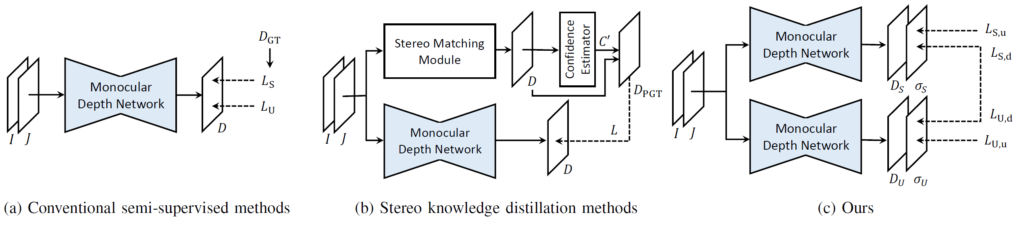
그리고 위 그림은 semi-supervised mono depth를 수행하는 이전 연구들의 구조와, 본 논문에서 제안하는 방법론의 구조를 직관적으로 나타낸 그림입니다.
(a) supervised loss와 unsupervised loss가 각 장,단점이 존재하기 때문에 이 둘을 함께 사용해서 sum하는 방식들의 연구가 진행이 되었습니다. 하지만 이렇게 단순히 두 loss를 합쳐버리면, 각 loss에서 발생하는 오류들을 처리할 수 없다는 점에서 supervised loss와 unsupervised loss의 단점을 해결 못한 채 모두 가져버리게 됩니다.
(b) 가장 일반적인 flow를 가지는 방식입니다. Stereo의 예측을 pseudo label 삼아 mono에게 전달해주는데, 이때 stereo의 부정확한 depth 예측을 정제하기 위해 ‘confidence estimator’라는 추가적인 모듈을 통해 confidence map까지 구하는 방식이죠. 하지만 제가 위에서 설명드렸다시피 이는 2가지 문제점이 존재하고, 그리하여 저자는 (c)라는 구조를 제안합니다.
(c) 2개의 Mono 모델이 서로 Mutual Learning을 진행하는 과정에서 한 쪽은 Supervised로, 반대쪽은 Unsupervised 방식으로 학습을 진행하는 구조입니다. 위에서 언급드렸다시피 이러한 구조를 통해 Supervised loss와 Unsupervised 예측의 단점을 완화하고 장점을 배우는 방식으로 학습이 가능하다고 하네요.
2. Method
2.1. Preliminary
입력 image와, monocular depth network가 예측한 depth를 각각 I, D 라고 칭하겠습니다. 그리고 supervised loss 계산에 사용이 될 gt depth 는 D_{GT} 라고 하겠습니다. 아래 loss 식을 통해 supervised network의 학습이 진행됩니다. 그냥 예측 depth와 gt depth의 L1 loss 입니다.
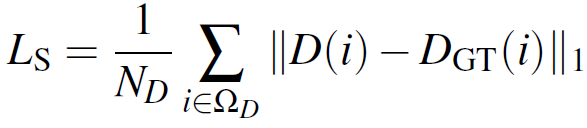
\Omega_D는 gt depth가 존재하는 pixel들의 집합을 의미합니다. 그리고 N_D는 해당 pixel들의 전체 개수를 의미하지요.
위에서 언급드렸다시피 large scale의 dense한 gt depth를 얻는것은 매우매우 expensive하다고 합니다. 그래서 보통은 LIDAR를 통해 얻은 sparse한 gt depth를 사용한다고 합니다. depth 벤치마킹이 가장 활발하게 이루어지는 KITTI dataset의 경우 3% 정도의 density를 가지고 있다고 하네요.
그렇기 때문에 위 식을 통해 예측 Depth map을 sparse gt depth map으로 수렴시키는 과정이 dense한 depth map을 예측하는 것을 보장하지는 못한다고 합니다. gt가 sparse하기 때문이죠.
특히 하늘 영역이나, 투명한 물체 영역은 LIDAR 가 포착하지 못하기 때문에 gt depth 가 존재하지 않고, 이러한 영역에서는 위 loss를 통해 효과적인 학습을 진행할 수 없습니다.
반면 gt depth 없이 unsupervised (or self-supervised) 방식으로 학습을 진행하는 방식에서는 photometric reprojection error를 최소화 하는 방향으로의 학습을 진행하게 됩니다. I와 J라는 이미지가 주어졌을 때 두 이미지의 matching을 통해 disparity와 pose 변화를 예측하고, J 이미지를 I 방향으로 warping(=reprojection)한 I’ 이라는 이미지를 생성하는 것입니다. 그리고 아래 식을 통해 I와 I’ 에서 각 pixel 별로의 photometric error (= pe) 를 구하는 것이죠.
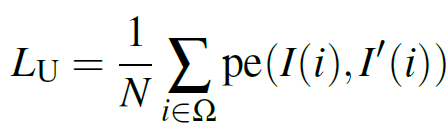
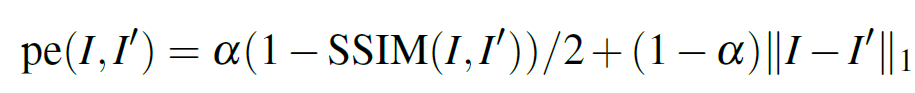
photometric error 의 경우 두 이미지의 L1 loss 뿐만 아니라, 두 이미지의 유사도를 계산하는 SSIM loss를 함께 사용하곤 합니다. 이러한 unsupervised loss는 supervised loss에서 나타나는 sparse의 문제점은 없지만, 위에서 언급드렸다시피 근본적인 정확성에 문제가 있습니다. object boundary와 occluded pixel에 대해 disparity 계산이 어려워서 blurry 한 depth 결과를 도출해낸다는 점이죠.
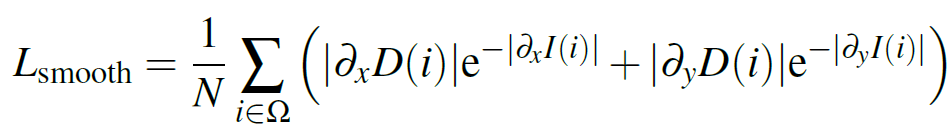
그리고 위의 smooth loss 는 monodepth1에서 제안되었으며, 제가 알기론 수많은 depth 논문에서 당연하다시피 사용하곤 합니다. Disparity의 경계 영역에서 끊어짐 등이 발생하지 않도록 gradient x, gradient y를 측정하는 loss 인데 disparity map에서 x, y축 각각에 대해 편미분을 수행하여 축 별로 gradient를 계산하고, 경계영역에서는 gradient의 차이가 급격하기 때문에 exp 로 가중치를 줘서 scale을 줄인것입니다. 이에 대한 자세한 설명은 여러 mono depth1 리뷰나 글을 보시면 될 거 같습니다.
2.2. Overall Framework
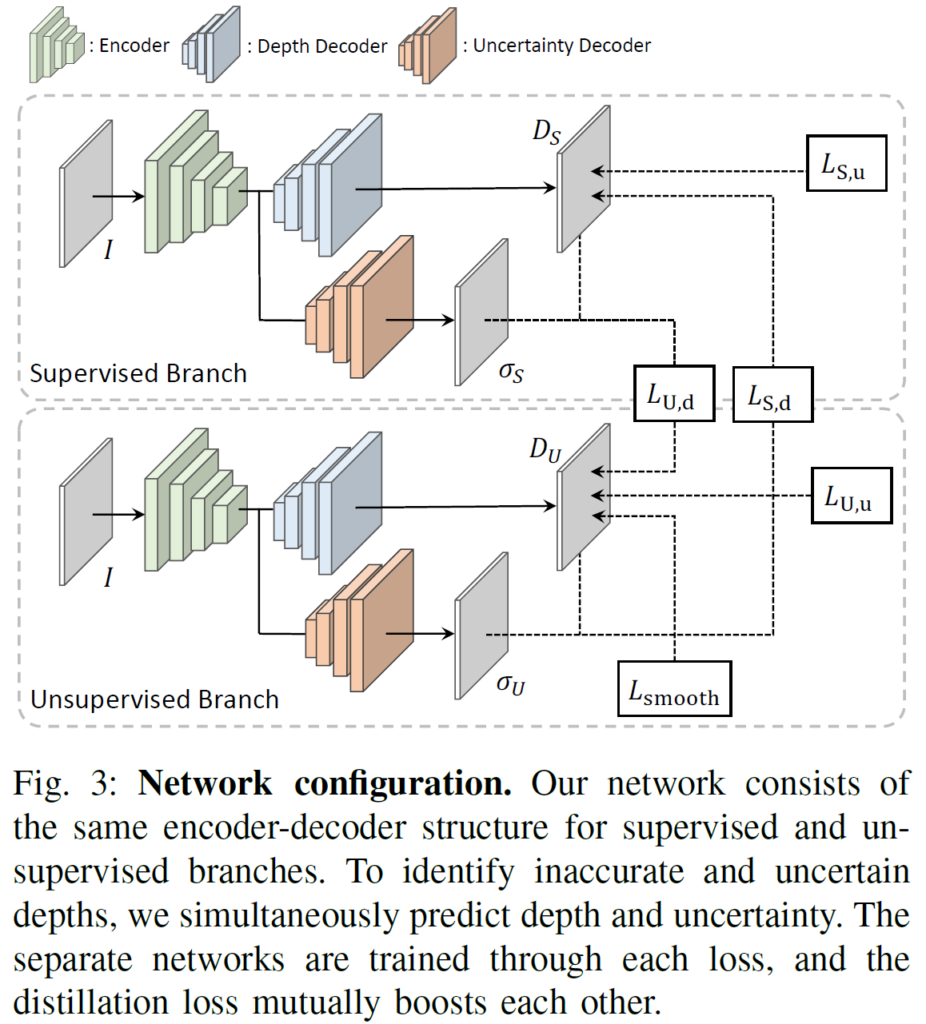
본 논문에서 제안하는 전체적인 구조입니다.
Supervised Branch와 Unsupervised Branch가 각각의 loss를 통해 독립적으로 학습되고, 추가적으로 Mutual Distillation을 통해 서로 장점을 배우고 단점을 완화하게 됩니다.
그리고 각 Branch에서 신뢰도 높은 depth를 예측하기 위해, uncertainty map을 예측하는 decoder를 추가적으로 설계하게 됩니다. 이러한 uncertainty map는 각 Branch의 예측을 반대편 Branch로 distillation할 때 depth map의 신뢰도(=reliability)를 조정해주는 역할을 합니다.
또한 두 branch에 서로 다른 data augmentation을 적용한다고 하네요.
Learning Depth and Uncertainty
각 Branch는 depth 뿐만 아니라 uncertainty map도 예측을 하게 됩니다. 이를 위해 negative log-likelihood minimization 방식을 활용해서 depth와 uncertainty를 함께 예측하게 됩니다. 이 방식은 CVPR 2020에 투고된 ‘On the uncertainty of self-supervised monocular depth estimation’ 이라는 논문에서 제안한 방식을 그대로 사용하였다고 하네요. uncertainty에 대한 깊은 이해를 위해선 해당 논문을 읽어봐야겠네요.
(기회가 된다면 조만간 리뷰를 진행하겠습니다)
아무튼 negative log-likelihood minimization 방식은 아래의 loss를 통해 출력 D의 분포를 Laplacian likelihood 형태로 모델링 한다고 하네요.
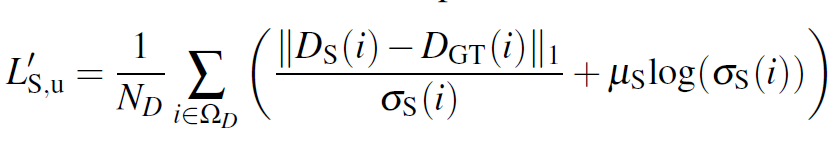
D_S 와 \sigma_S 는 각각 예측한 depth map과 uncertainty map을 나타냅니다. 그리고 앞쪽 term만으로 loss를 구성하게 되면 loss를 줄이기 위해 \sigma_S 를 무한대로 발산시키기 때문에 이를 방지하기 위한 log term을 추가한 것을 볼 수 있습니다.
하지만, gt depth map의 경우 위에서 설명 드린 것처럼 sparse 하기 때문에, 위의 loss를 성공적으로 minimization 한다고 해도 이미지 내의 모든 영역을 고려할 수는 없게 됩니다. 가령 LIDAR의 view를 벗어난 이미지 상부 영역이나, 투명한 영역 등이 되겠지요.
즉 gt depth가 cover하지 못하는 이미지 상부 영역의 경우는 아무래도 부정확한 depth를 예측 할 확률이 높은데, 해당 영역의 uncertainty가 신뢰도가 높게 측정이 되면 부정확한 depth인데도 불구하고 반대쪽 Branch로 distillation이 진행되는 문제가 존재합니다.
그래서 gt depth가 sparse한, unreliable한 영역을 처리하기 위해 위의 loss 식에다가 unprojected point filtering loss 라고 불리는 추가적인 term을 설계하게 됩니다. 아래의 loss로 Supervised Branch를 학습하게 되는것이죠.
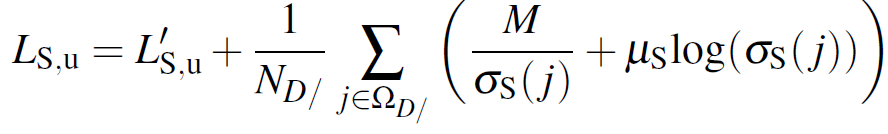
\Omega_D/ 는 \Omega_D가 보지 못하는, 즉 LIDAR의 view 를 벗어나서 gt depth가 계산이 안된 영역의 pixel을 모아놓은 집합입니다. 그리고 M은 hyper parameter 이구요.
음… 사실 본 논문에서 추가한 unprojected point filtering loss term이 어떤 식으로 동작하게 되는지 직관적으로는 잘 와 닿지 않네요. \Omega_D/ 에 속한 pixel의 uncertainty가 너무 낮아지지 않도록 제약을 거는 느낌? 으로 이해하였습니다.
아래 그림은 본 논문이 추가적으로 설계한 unprojected point filtering loss 의 효과를 시각화 한 결과입니다.

(b)의 gt depth를 잘 보시면, 이미지 상단 영역은 LIDAR가 포착하지 못한 것을 볼 수 있습니다. unprojected point filtering loss의 적용 유무에 따라 상단 영역의 변화에 집중해서 살펴보면 되겠네요.
(c),(d)가 unprojected point filtering loss 를 적용하지 않은 경우이고, (e),(f)가 적용한 경우입니다.
(c)와 (e)의 이미지 중간 상단영역 가로등을 보시면 (e)에서 가로등을 훨씬 더 잘 포착한 것을 볼 수 있습니다.
두번째인 Unsupervised Branch의 경우 아래와 같은 직관적인 loss term을 사용하였습니다. Unsupervised 에서는 sparse gt 를 사용하지 않기 때문에 unprojected point filtering loss 를 적용하지는 않은 것을 볼 수 있네요.
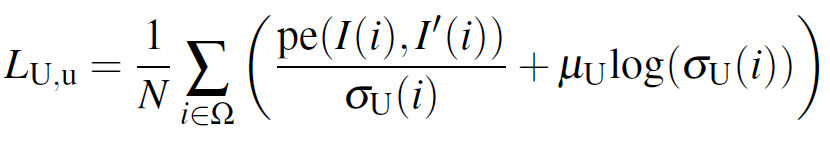
Distillation of Depth with Uncertainty
자, 위의 단락에서 L_{S,u} 를 통해 Supervised Branch를, L_{U,u}를 통해 Unsupervised Branch를 개별적으로 학습 시켰습니다. 각각의 Branch는 depth map과 uncertainty map을 예측하게 되구요.
그럼 이제 이러한 정보들을 가지고 Mutual Distillation을 수행해야 합니다. 아래 loss를 통해 uncertainty를 고려한 depth map을 반대편 Branch로 전달해서 loss를 계산하게 됩니다.
Supervised Branch를 학습시킬 때는 Unsupervised Branch의 uncertainty map이 적용된 것을 볼 수 있네요.
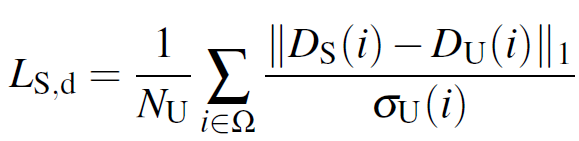
N_U 는 1/( uncertainty map의 모든 값의 합) 입니다. 아래 식을 통해 이해하시는게 더 낫겠네요.
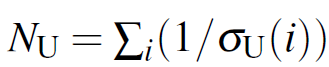
그리고 Unsupervised Branch를 학습시킬 때에도 위와 유사한 방식으로 loss를 계산합니다.
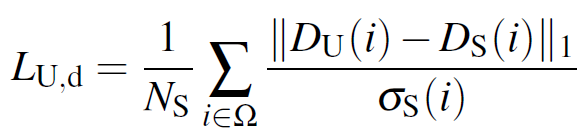
Total Loss
위에서 설명드린 loss를 조합해서 최종적인 loss를 설계하였습니다.
순서대로 Supervised branch와 Unsupervised branch에 대한 식이 따로 구성되어 있는데, 학습은 당연히 end-to-end 로 한꺼번에 진행됩니다.
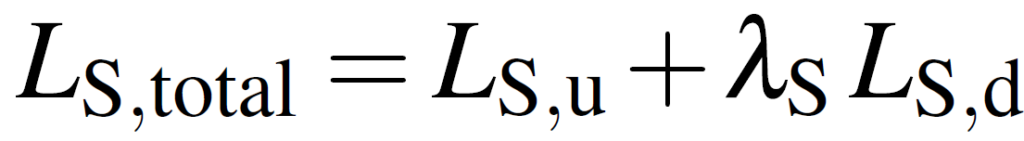
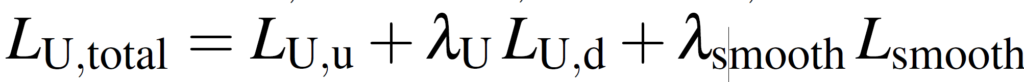
Unsupervised loss의 경우 위 Preliminary에서 설명드린 smooth loss가 추가적으로 더해져 있는 것을 볼 수 있습니다.
+ Noising the Networks : Data Augmentation
앞선 많은 Semi-supervised 방식에서 Data augmentation의 중요성을 강조하였습니다.
두 network가 있다고 가정할 때, 두 network에 서로 다른 Data augmentation을 부여하고 최종적으로 추출되는 feature를 align함으로써 더 robust한 feature를 학습하고자 하였고, 많은 연구들이 이러한 방식의 효과를 입증했습니다.
본 논문에서는 이러한 앞선 연구들의 흐름을 수용하여, 두 Branch를 robust하게 학습하기 위해 object instance를 제외한 다른 이미지 영역에 photometric noise를 부여하였습니다.
object는 유지하고, background 영역에 photometric noise를 부여함으로써, background context의 bias나 background의 structure와 같은 background의 기하학적인 구조에 의존한 depth 예측을 피하고, object 그 자체에 초점을 맞춘 depth 예측을 수행하고자 하였습니다.
실험 섹션에서도 해당 noise의 효과를 입증 하였습니다.
3. Experiment
모델의 각 branch는 feature를 추출하는 하나의 shared encoder, depth map과 uncertainty map을 예측하는 두개의 개별적인 decoder로 구성되어 있습니다. Monodepth2와 유사한 Unet 구조를 기반으로 설계하였다고 하네요.
그리고 실험에서는 KITTI dataset에서 정적 frame을 제거한 KITTI zhou split과 Cityscape dataset을 사용하여 학습과 평가를 진행합니다.
depth 평가 metric의 경우 해당 블로그 에서 자세히 설명해 주고 있으니 생략하겠습니다.
(원래 제가 디테일하게 설명드려야 하지만, 타 블로그로 대체한 점 죄송합니다 ,,,)
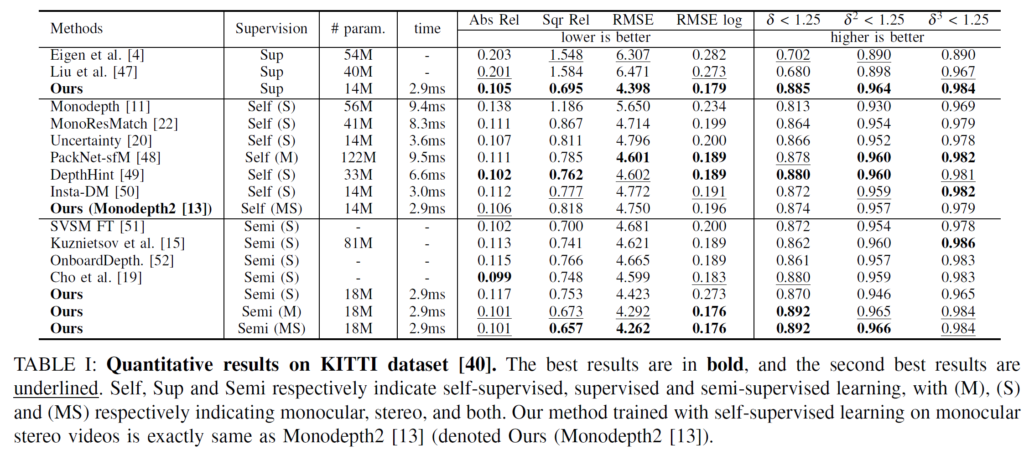
우선 KITTI dataset에서의 전체 평가 결과입니다.
본 논문에서 제안한 방식의 # param이 매우 인상적이네요. 타 방법론들에 비해 훨씬 더 가벼운 모델인데도 불구하고 거의 SOTA에 가까운 성능을 보였습니다. inference time또한 매우 빠르네요.
추가적으로 봤을때 개인적으로 좀 신기했던 점이 Ours의 (S)와 (M)에 대한 성능 차이입니다. (S)는 stereo이고 (M)은 mono를 의미하는데, mono의 경우가 성능이 훨씬 더 높은것을 볼 수 있습니다. 흠… 이에 대한 분석적인 내용은 없네요…

그리고 타 방법론과 비교했을때 KITTI dataset 에서의 정성적인 결과입니다.
Ours의 결과가 object의 shapeㅇ르 정확히 유지하면서 depth 예측을 해내는 것을 볼 수 있네요.
그리고 세번째 image에서 특히 이미지 상단 부분의 표지판에서 좀 더 선명한 것을 볼 수 있습니다.
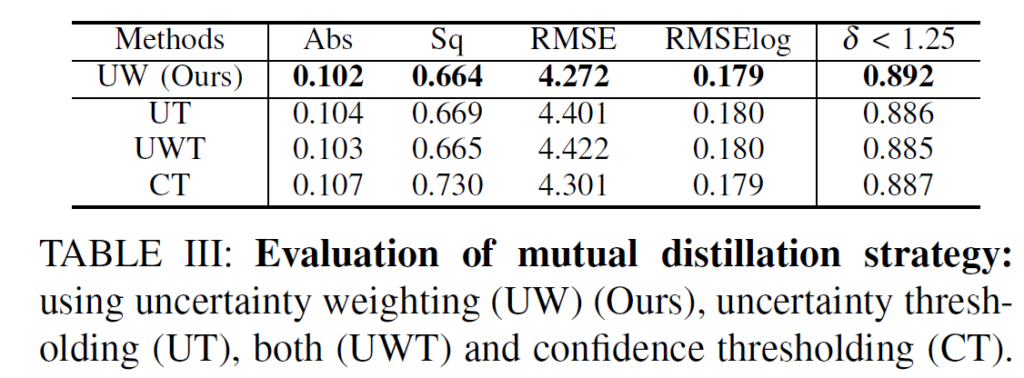
그리고 위 결과는 본 논문의 uncertainty를 활용한 distillation 방식과 관련된 ablation 결과입니다.
본 논문의 UW 는 구해진 uncertainty map을 그대로 적용하는 것을 의미하며, UT는 uncertainty map을 thersholding 기법으로 사용한 방식을, 그리고 UWT는 이 둘을 모두 사용한 것입니다. 마지막으로 CT는 특정 threshold 값을 사용하는 방식이죠.
전체적으로 보면 우선 threshold 방식 보다는 uncertainty 방식이 성능이 더 좋네요. 그리고 uncertainty map을 단순하게 weight 방식으로 적용하는 본 논문의 방식이 제일 효과적인 것을 볼 수 있습니다.
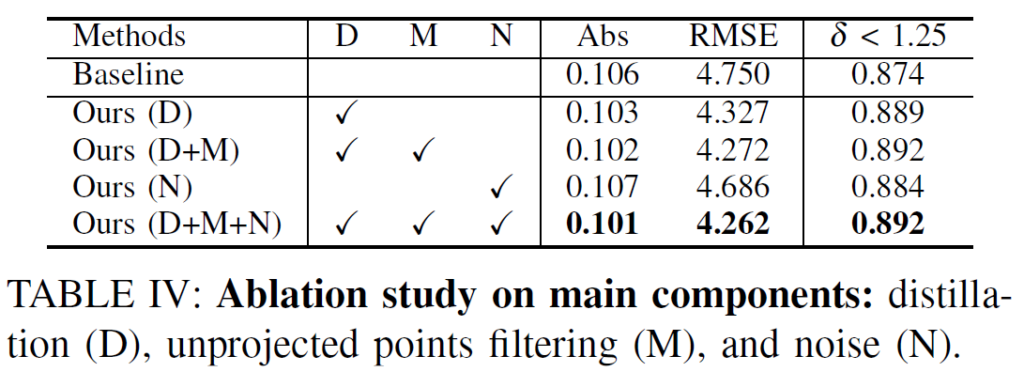
그리고 마지막으로 본 논문에서 제안한 여러 모듈(?)들에 대한 ablation study 입니다.
photometric noise (N)만 적용했을 때에는 baseline 대비 Abs 성능이 하락하는데, (D)와 (M)을 함께 적용했을 때에는 photometric noise (N)의 효과를 보고 있네요.
Conclusion
최근 mutual learning 에서의 masking, uncertainty, threshold에 대한 논문들을 리뷰하고 있습니다.
본 논문이 제안한 방식은 꽤나 직관적이고 간단한데 효과적인 성능과 inference speed를 달성하였네요.
그런데 좀 의아한 점이 있긴 합니다. 본 논문에서 문제 정의를 할 때에 Supervised loss와 Unsupervised loss의 장,단점이 존재하기 때문에 이들을 보완하기 위한 방식으로 두 Branch를 각각 Sup, Unsup 으로 구성하였습니다. 제 생각에 이 효과를 입증하기 위해서는
i) Sup-Sup
ii) Unsup-Unsup
이렇게 두 가지 방식의 성능을 함께 리포팅해야 한다고 생각합니다. 해당 성능을 보여야 이를 통해 Sup-Unsup 사이에서의 Mutual Distillation의 효과에 대해 입증할 수 있기 때문이죠. 왜 리포팅 하지 않았을까요,,,? 성능이 더 좋지 못했을까요? 본 논문의 문제 정의와 정확하게 반대의 실험적 결과여서 리포팅하지 않았을 수도 있겠다는 매우 비판적인 상상을 하면서 오늘의 리뷰를 마치도록 하겠습니다.
(생각하면 생각할수록 좀 치명적이긴 하네요,, 무조건 해당 결과를 함께 리포팅 해야 논리적으로 증명할 수 있는건데,,)
쩝, 아무튼 다음 리뷰는 어떤 논문을 들고오게 될 지는 아직 모르지만, 더 좋은 논문으로 찾아 뵙도록 하겠습니다.
읽어 주셔서 감사합니다.
좋은 리뷰 감사합니다. 자세히 설명해주셔서 이해하기 수월했습니다:)
3d point cloud의 sparse한 특징으로 인해 gt depth를 만들기 위한 방식을 함께 적용하는군요. 만약 classification같은 task라면 모든 3d points들을 사용하지 않고도 sparse한 point를 활용할 수 있을 것 같은데 segmentation의 경우 per point gt가 있어야하기 때문에 이런 방식의 depth estimation이 필요할 수 있겠네요.
처음에 제안하는 방법론의 구조를 두 개의 mono branch로 한 것을 보고 왜 stereo로 해도 좋지 않을까?라는 의문을 가지고 읽었는데 뒤에 실험부분에서 실험적으로 사용한 것으로 받아들여지네요. depth를 추정할 때 mono가 stereo보다 정확한 깊이를 추정하기 어렵다는 생각이 드는데 혹시 mono를 사용한 방법이 더 좋은 성능을 보인 것에 대해 어떤 이유가 있을지 권석준 연구원님의 의견이 궁금합니다!
도경님께서 질문하신 부분도 제가 실험섹션을 읽으며 의아했던 부분이기도 합니다. 심지어 성능갭 또한 꽤나 크구요.
질문에 대한 답변은,,, 사실 저도 잘 모르겠습니다. 제가 평소에 depth 논문들을 자주 읽어왔던게 아니라 더더욱 잘 모르겠네요..ㅎ 명쾌한 답변을 드리지 못해서 죄송합니다. ㅠ
안녕하세요.
좋은 리뷰 감사합니다.
상세하게 설명을 잘 해주셔서, 읽다가 생긴 의문들이 대부분 읽다보니 사라지고 말았습니다…
그럼에도 남은 질문을 드리자면, Lidar로 얻어진 depth map이 RGB image에 비해 sparse하기 때문에 RGB image의 각 픽셀과 Lidar depth map의 픽셀들을 1대1로 매칭하지 못할 것 같은데, 그러면 손실함수 계산시에는 가장 가까운 Depth map과 매칭하여 계산을 수행하는 것인가요?
또한, 마지막 부분에 Sup-Sup / Unsup-Unsup 의 결과가 있어야 한다는 것이, Sup-Unsup 조합을 통해 성능을 향상한 것인지, 혹은 단순히 모델 두 개를 가지고 Mutual learning 했더니 성능이 오른 것인지 확실하지 않기 때문이라 이해하였는데 이게 맞나요?
감사합니다.
1. 음.. 사실 이때까지 gt랑 loss를 계산하는 부분을 그러려니~ 했던 거 같습니다. 제가 좀 더 알아보고 답글 다시 달아드리겠습니다..ㅎㅎ
2. 음, Sup-Unsup 의 조합 vs Mutual learning 중 어떤 것 때문에 성능이 오른 것인지 확실하지 않아서 이를 확인하고자 생각된 의문은 아닙니다. 본 논문에서 핵심으로 가지는 아이디어가 Sup-Unsup의 조합을 통해 Supervised loss와 Unsupervised loss 의 각 단점을 보완하여 해결하는 것이기 때문에 이를 뒷받침하기 위해 Sup-Sup의 조합과, Unsup-Unsup과의 비교를 해야된다고 생각했던겁니다!