Introduction
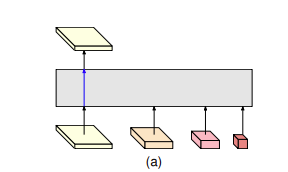
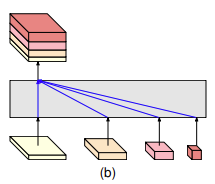
position에 민감한 task인 semantic segmentation, human pose estimation, object detection등은 feature의 high resolution representation이 중요합니다. 기존 sota 방법론에서는 high resolution representation을 얻기 위해 [그림1]과 같은 구조를 사용하여 convolution을 통해 high resolution feature를 downsampling 하고(a), downsampling된 low resolution representation을 upsampling하였습니다(b).

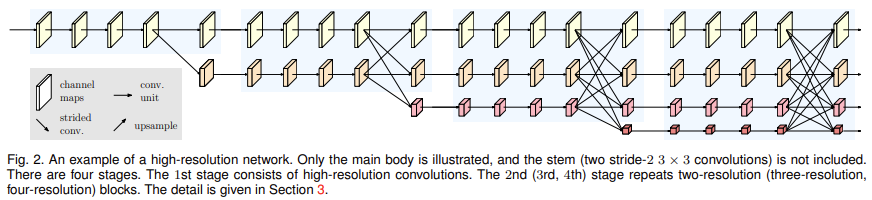
보다 high resolution representation을 유지하기 위해 저자들은 HRNet을 제안하였습니다. [그림1]에 나타난 기존 방식은 단방향으로 feature의 upsampling, downsampling이 일어납니다. 이와 달리 [그림2]의 HRNet은 각 high resolution stream에서 시작하여 downsampling된 low resolution stream이 추가되는 구조로 여러 해상도의 stream이 병렬적으로 연결되어 있습니다. 논문의 HRNet은 총 4stage로 구성되어 있으며, n번째 stage에서는 n개의 해상도를 가지는 steam이 존재합니다. 또한 한 stage에서 다음 stage로 넘어갈 때 multi-resolution fusion을 사용하여 high resolution의 위치 정보와 low resolution의 의미 정보를 충분히 가진 feature를 생성하였습니다.
High Resolution Networks
HRNet의 구조는 아래의 [그림 2]와 같습니다.
[그림2]의 가장 첫 부분에 위치하는 feature map은 입력 이미지를 두 번의 3*3 convolution연산을 통해 1\over 4 downsampling한 high resolution feature입니다. HRNet은 그림에서 볼 수 있듯 high resolution feature를 끝까지 가져가는 것을 특징으로 하고 있습니다.
HRNet은 parallel multi-resolution convolution, repeated multi-resolution fusion, representation head로 이루여져 있습니다.
parallel multi-resolution convolutions
Parallel multi-resolution convolution은 high resolution 과 low resolution의 stream을 병렬적으로 배치한 구조를 의미합니다. 입력된 feature의 해상도와 동일한 해상도를 유지하는 , downsampling된 feature를 생성하는 모습을 보실 수 있습니다. [그림2]는 4개의 stream이 병렬적으로 연결된 것을 보여주고 있습니다.
[그림2]에서 푸른색 구획으로 표시된 것을 stage라고 하며, HRNet은 총 4개의 stage로 이루어져 있습니다. N_sr이 s stage의 r 해상도를 가지는 stream 이라 한다면 parallel multi-resolution conv를 구조적으로 표현하면 다음과 같습니다.
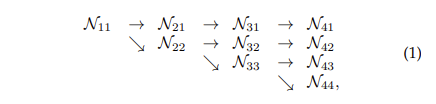
이때 첫 stream은 r=1이고 index r에 해당하는 feature map은 1\over{2^{r-1}}만큼 downsampling된 feature map을 의미합니다.
repeated multi-resolution fusions
각 stage에서 서로 다른 resolution의 feature를 fusion하는 방법은 [그림3]과 같습니다.
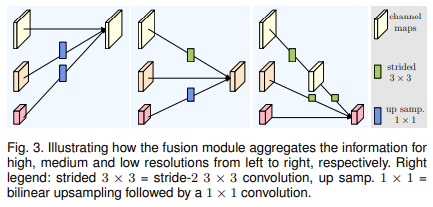
output feature를 생성하기 위해 기존 feature들의 크기를 맞추고, 더해주는 방법을 사용하였습니다. 이때 out보다 큰 feature는 strided 3\times 3conv를 통해 downsampling하고, outputq보다 작은 feature는 bilinear upsampling 하였습니다.
representation head
위의 과정을 통해 서로 다른 크기의 feature map을 얻을 수 있으며 이 feature map들은 task에 따라 representation head에서 후처리를 진행합니다.
저자들은 총 세 가지의 representation head를 제안하였습니다. 이 head들은 각각 서로 다른 task를 수행하며, 어떤 해상도의 feature를 사용하는지, 어떤 방식으로 사용하는지에 따라 HRNetV1, HRNetV2, HRNetV2p로 명명하였습니다.
HRNetV1
HRNetV1은 HRNet의 output중 high resolution의 feature만을 출력합니다. HRNetV1은 위치 정보가 중요한 human pose estimation task에 사용되었습니다.
HRNetV2
V1에서는 high resolution representation만 출력하지만, V2에서는아래의 그림과 같이 low resolution representation을 high resolution과 같은 크기로 upsampling하여 각 feature를 mix합니다. 이때 upsampling에는 bilinear upsampling기법을 사용하고, upsampling된 feature를 concat한 후 1\times 1 convolution을 사용하여 네 가지 resolution의 feature를 mix하였습니다.
high resolution과 low resolution feature를 모두 활용함으로써, V1에 비해 위치 정보와 의미론적인 정보를 모두 활용할 수 있어 semantic segmentation 사용되었습니다.
HRNetV2p
V2p는 V2의 feature downsampling하여 총 4가지의 resolution을 가진 feature를 출력합니다.
V2p는 object detection에 사용되었습니다.
Experiments
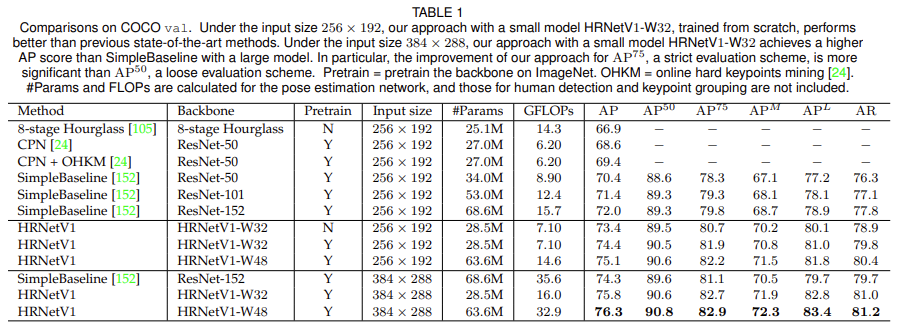
Human Pose estimation
Human pose estimation은 keypoint detection으로 입력 이미지에서 팔꿈치, 손목 등의 키포인트를 찾는 task입니다. 이 논문에서는 H\times W\times 3크기의 입력 이미지에서 k종류의 keypoint위치를 추정하는 {W\over 4} \times {H\over 4}크기의 heatmap을 예측하였습니다.
앞서 간단하게 언급하였으나 pose estimation에서 heatmap을 예측하는 모델은 HRNetV1을 representation head로 사용하였습니다.
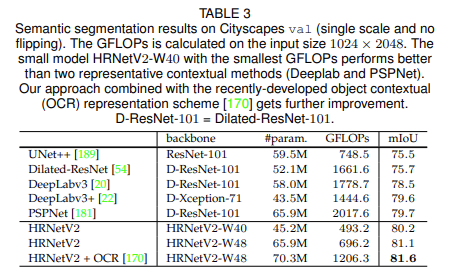
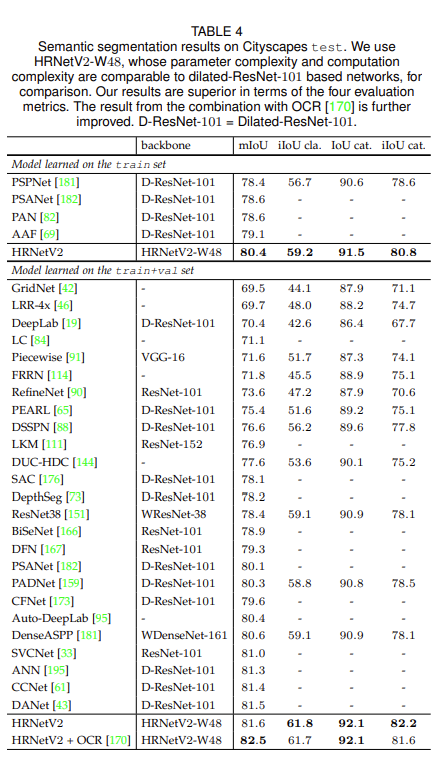
Semantic Segmentation
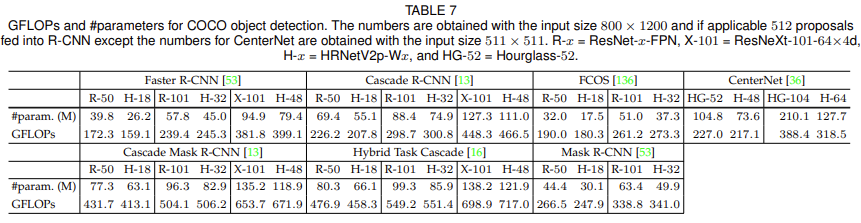
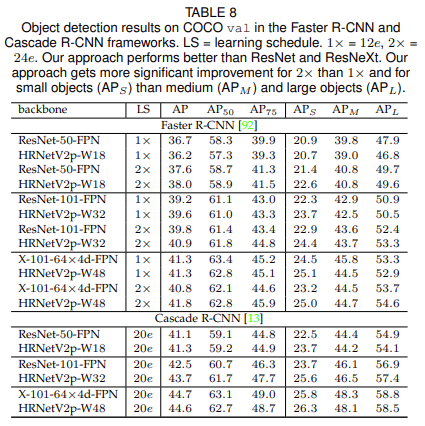
Object Detection
Ablation Study
안녕하세요 좋은 리뷰 감사합니다 !
몇 가지 궁금한 점이 있어 질문 드립니다
representation head에서 HRNetV2가 high resolution과 low resolution feature을 모두 활용함으로써 위치 정보와 의미론적인 정보를 모두 활용할 수 있다고 하셨는데 의문이 드는 점이 이 때 low resolution feature을 high resolution과 같은 크기로 upsampling을 하여 각 feature을 mix를 해준다면 low resolution feature의 sementic한 정보가 보존이 되는 지에 대한 것 입니다. bilinear upsampling 기법을 사용한다고는 하나, 과연 resolution이 upsampling에 의해 변형이 되었는데 그대로 보존이 되어 그 feature에서 추출되는 정보들이 sementic하다고 할 수 있을지에 대한 궁금증이 생겨 질문드립니다.
두번째로는 HRNetV2p와 HRNetV2는 V2p가 V2의 feature downsampling을 하여 4가지의 resolution을 가진 feature을 출력을 한다는 점이 다른 것인데, 이로 인해 사용하는 방식이 sementic segmentation에서 object detection으로 달라지는 것에 잘 이해가 가지 않아 조금 더 자세한 설명을 해주시면 감사합니다 !
질문 감사합니다.
해당 부분은 기존 연구에 해당하는 [그림1]을 먼저 이해하는 것이 우선되어야 할 것 같은데요, 전통적인 encoder-decoder방식도 어찌보면 sementic한 feature를 upsampling을 통해 변형하고, residual 등을 통해 encoder 앞부분의 정보를 더해주는 방식으로 동작합니다. low resolution의 feature를 upsampling한 feature가 sementic 정보를 포함한다는 결과를 기존의 여러 논문에서 보여주고 있으므로 이 논문에서도 마찬가지일 것이라고 생각됩니다.
좋은 리뷰 감사합니다. 쉽게 이해할 수 있었던 것 같습니다ㅎ
궁금한 점이 있어서 질문드리자면 representation head에서 HRNetV1이 위치 정보가 중요한 pose estimation에서 사용된다고 하셨는데 다른 task에 비해 특히 위치 정보가 중요한 이유가 뭔가요?
그리고 experiments에서 backbone뒤에 w 숫자가 의마하는 건 무엇인가요?
W뒤의 숫자는 the widths of the high-resolution subnetworks in last three stages를 의미하며, Fig.2에서 분홍색 Feature map의 width값입니다.
안녕하세요. 좋은 리뷰 감사합니다.
1) HRNetV2에서 언급된 bilinear unsampling이 무엇인가요?
2) Fig1을 보면 그림의 구조의 예시가 simpleBaseline이라고 적혀있는 것을 볼 수 있는데요. 이것과 비교하여서 HRNet을 보면 SimpleBaseline에 비해서 복잡한 것을 확인할 수 있습니다. 그런데 experiment에서 보면 파라미터의 수가 별로 차이가 나지 않는 것을 볼 수 있는데요. 오히려 SimpleBaseline이 더 파라미터 수가 크고 GFLOPs도 큰데 왜 이런 차이가 발생하는 건가요?? 논문에서는이런 부분에 대해서 따로 리포팅한 것은 없을까요?
upsampling 기법 중 하나인 bilinear interpolation을 의미합니다. 해당 블로그에서 보다 자세한 설명을 보실 수 있습니다.
Fig.1은 인코더-디코더 구조를 단순화한 것으로 SimpleBaseline의 경우 (a)부분에 ResNet50이 들어갑니다. 이를 Fig.2의 HRNet과 비교하여 생각해 보면 실제로 두 모델은 파라미터 수의 차이가 거의 없다는 것을 알 수 있습니다.
리뷰 잘 봤습니다.
HRNet.. 정말 유명한 백본 논문으로 알고 있습니다. 혜원님께서 모델 구조나 방법론적인 측면은 설명을 잘 해주셔서 이해도 잘 갔구요.
그런데 제 개인적인 생각으로 백본 논문은 실험 부분이 매우매우 중요하다고 생각됩니다. 본인들이 제안한 백본 모델을 여러 task에 적용해보면서 타 백본 대비 성능, 속도 등의 지표들을 비교하면서 자신들의 모델의 우수성을 강조하기 때문이죠. 그런 관점에서 백본 논문은 타 방법론 논문 대비 실험섹션이 매우 풍부하게 구성이 되어 있는데 리뷰에서는 해당 영역에 가중치가 들어있지 않아서 보완이 필요해 보입니다.
감사합니다.
댓글 감사합니다. 논문을 읽을 때 방법론이나 모델 구조에 집중하다 보니 실험 결과에 대한 분석이 부족했던 것 같습니다. 추후 실험 부분에 대한 보완을 진행하도록 하겠습니다.
안녕하세요.
좋은 리뷰 감사합니다.
논문에서는 Task에 따라 3가지의 representation head를 제안하였는데, 제가 naive하게 생각하기에, 어차피 뒤쪽에 task specific한 어떠한 신경망 구조가 추가될텐데, task가 무엇이든 해당 모델들에게 최대한 많은 정보를 줄 수 있는 HRNet V2나 V2p를 쓰면 안되나? 하는 의문이 듭니다.
특히 V1에 대해서는, 기껏 연산량을 늘려가며 multi scale의 feature map을 만들어놓고 가장 큰 것만 사용하는 것 아닌가 하는 의문이 드는데, 혹시 각 task에 다른 representation head를 쓴 실험 결과나, 그렇게 하지 앟는 이유를 알 수 있을까요?
감사합니다!
결론적으로 말씀드리자면 논문의 저자도 같은 의문을 가지고 실험을 진행했습니다. 본문 내용 중 pose estimation task에 V2가 아닌 V1모델을 사용한 이유를 언급하였는데 저자의 실험 결과 HRNetV1과 HRNetV2가 거의 같은 성능을 보여주었기 때문에 Conputation complexity가 낮은 H1모델을 선택하였다고 합니다. pose estimation의 경우 구체적인 실험 결과가 드러나지는 않았습니다.
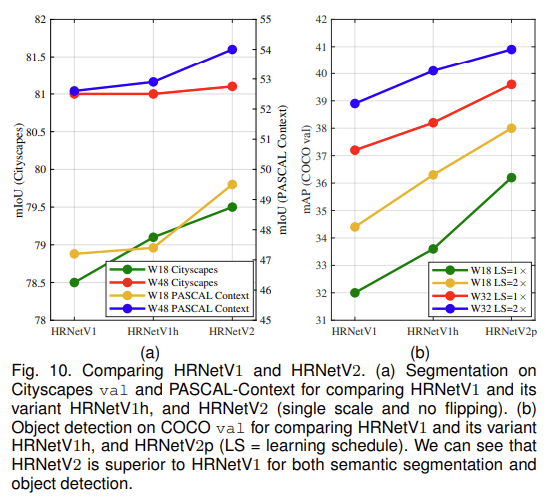
다른 task에서는 서로 다른 representation head를 사용한 실험 결과는 본문 하단 [그림 10]에 추가하였습니다. semantic segmentation에서는 V1과 V2를, object detection에서는 V1과 V2p를 비교한 ablation study 결과가 리포팅되어 있습니다. 각 task에 대해 V1을 사용한 것 보다 새로 제안한 V2와 V2p를 사용하는 것이 더 좋은 성능을 보이는 것을 확인할 수 있습니다.