이번 논문은 text 모델로 사용하던 transformer 기반 모델을 CNN, LSTM 등으로 바꿔야 하는 상황이 와서 참고하고자 읽은 논문입니다. text 모델을 대체하는 모델을 찾아야 하는 것이기 때문에 CNN 보다는 원래 text 모델로 사용되었던 LSTM이 더 낫지 않을까 하여 서베이 하던 중에 발견한 논문입니다. 아주 대단한 BERT가 현실적으로 아카데미에서 사용하는 작은 데이터셋에도 좋은 성능을 낼까? 에서 시작한 논문인데요. arXiv이지만 인용수가 80회를 넘은 논문입니다. 그럼 시작하겠습니다.
<introduction>
논문의 시작은 NLP의 발전이 어떻게 이뤄졌는지부터 시작합니다. 아 그리고 이 논문은 2020년 논문이기 때문에 이 부분을 감안해서 읽으시는게 좋을 것 같습니다.
논문에서는 몇 년 전까지만 해도 NLP 커뮤니티 대부분이 처음부터 모델을 학습시켜왔다고 합니다. 처음부터 학습시키기 위해서는 데이터셋 모으기, 라벨링하기, 최적의 아키텍쳐 찾기, 파라미터 튜닝하기, 결과 평가하기가 요구되는데 이는 비용이 많이 드는 일입니다. 그렇기 때문에 사전 학습 모델처럼 다른 task에서 얻은 이전의 지식을 사용하는 것이 더 좋습니다. 물론 이때는 NLP에서 사전 학습이라는 것이 없을 시기이죠.
NLP의 turning point는 사전 학습된 모델로부터 전이 학습이 가능하게 되면서부터 찾아왔습니다. 논문에서는 이를 NLP의 ImageNet 모먼트라고 부르는데, ImageNet이 컴퓨터 비전 영역에서 전이 학습의 문을 열었고 딥러닝을 사용하여 새로운 최첨단 결과를 달성했기 때문입니다.
전이 학습에 더불어서 transformer는 NLP의 새로운 시대를 열었습니다. transformer는 sequential data를 다룰 수 있는 딥러닝 모델이지만 RNN과 같은 recurrent neural network와는 달리 sequentail data를 순서대로 처리할 필요가 없습니다. 그렇기 때문에 병렬 처리가 가능하며, 학습에 걸리는 시간 또한 단축할 수 있었습니다. 이 덕분에 큰 데이터셋에 대해서 학습할 수 있게 되었지요.
많은 연구를 통해서 transformer가 요약, 변역, 분류를 포함한 NLP task에서 매우 큰 성공을 이루었다는 것을 확인하였습니다. 그 중에 가장 유명한 unsupervised 방식으로 큰 데이터셋으로 학습된 BERT가 있죠. BERT 구조를 기반으로 한 다른 모델들도 GLUE benchmark에서 훌륭한 성능을 내보였습니다. 이 것에 공통점은 무엇일까요? 바로 사전학습 된 모델을 튜닝할 때에도 매우 큰 데이터 셋이 사용된다는 것입니다. 이 때문에 이 논문에서는 ‘만약 데이터셋이 작다면 어떨까’라는 다른 각도에서 문제에 접근하였습니다.
논문에서는 소규모의 task-speific한 데이터 셋이 있는 매우 일반적인 실제 사용 사례를 중심으로 연구 질문(데이터셋이 작다면 어떨까)을 공식화했습니다. 만약 데이터를 더 모으고 라벨링하는 것이 비싸다면 그리고 하드웨어를 더 이상 갖는 것이 어렵다면 여전히 BERT가 적합할까요? 논문에서는 “Should we forget about everything we knew about RNNS/LSTMs and completely switch to Transformers”라고 직접적으로 RNNs/LSTMs을 사용하지 않는 것이 좋은 것인가를 언급합니다.
<related work>
related work에서는 전이 학습이 언제 어떻게 등장하게 되었는지에 대해서 나옵니다. intoroduction에 이어서 계속 설명해보겠습니다.
전이 학습은 training data를 모으고 다시 학습하는 노력을 줄이기 위해 knowledge를 다른 task로 전이하는 task입니다. 전이 학습을 이용하면 적은 시간에 높은 정확도를 얻을 수 있기 때문에 많이 인공지능 커뮤니티에서 많이 사용되고 있습니다.
컴퓨터 비전에서는 오랫동안 기다려온 전이 학습의 순간이 ImageNet과 함께 찾아왔습니다. 반면에 NLP에서는 전이 학습의 순간이 몇 년 전까지만해도 오지 않았습니다. 2020년인 논문에서 몇 년 전이라는 말은 지금은 NLP에서 전이 학습이 등장한지 꽤 되었다는 소리군요. 어쨌든 계속 이어서 설명해보겠습니다. 전이 학습의 순간은 오지 않았지만 GloVe embedding이라고 불리는 크게 쓰이는 단어 vector representation이 제안되었습니다. GloVe embedding은 널리 사용되었죠. 그런데…. GloVe embedding은 word embedding을 만들 때 문맥을 활용하지 않습니다. 예를 들어서 ‘사과’라는 단어에 대한 임베딩은 어떤 문장에 사용되더라도 동일하게 만들어진다는 것이죠. 이러한 한계를 해결하기 위해 학습된 bidirectional LSTM을 사용하여 contextualized word-embedding을 생성하는 ELMo를 제안하기도 했습니다. ULMFiT도 마찬가지의 비슷한 모델로 제안되었죠.
이러한 모델은 모두 사전 학습 단계에서 label이 지정되지 않은 데이터를 사용할 수 있는 언어 모델링 작업을 통해 학습되었습니다. language modeling(언어 모델링)의 목표는 이전 단어를 기반으로 다음 단어를 예측하는 것을 말합니다. 그런데 BERT는 masked language modelng approach(마스킹 언어 모델링 접근 방식)을 사용한다는 점에서 ELMo, ULMFiT와 다릅니다. 기존의 방법론들은 다음 단어의 문맥만 살펴본다면 BERT는 이전 단어와 다음 단어의 문맥을 모두 고려합니다. masked language modelng approach에서는 문장의 단어가 무작위로 지워지고 특수 토큰으로 대체되며, transformer를 사용하여 주변의 마스크되지 않은 단어를 기반으로 마스크된 단어에 대한 예측을 생성합니다. 이를 통해 BERT는 GLUE benchmark에서 많은 NLP task에서 기록적인 결과를 달성합니다. 논문에 나와있는 것 외에 추가적인 것을 말씀드리자면 GLUE benchmark를 사용하는 NLP task에서 모두 1등을 달성했다고 했으니 정말 엄청난 모델인 것이죠. 이후에는 RoBERTa, DistillBERT, XLNet 등 다른 만은 transformer 아키텍쳐가 BERT의 뒤를 이어 점진적인 결과를 달성했습니다.
이 논문에서는 transformer를 이용한 BERT의 성공을 인정하며, 작은 데이터 셋에서 transformer의 성능과 기존의 bidirectional LSTM 모델과 성능을 비교합니다. GLUE benchmark와 같은 대규모 데이터 셋에서 BERT와 유사한 모델을 활용하는 것이 이미 성공적이라는 것을 보였기 때문에 이 논문에서는 task별 소규모 데이터 셋에 대한 비교를 보여줍니다.
<method>
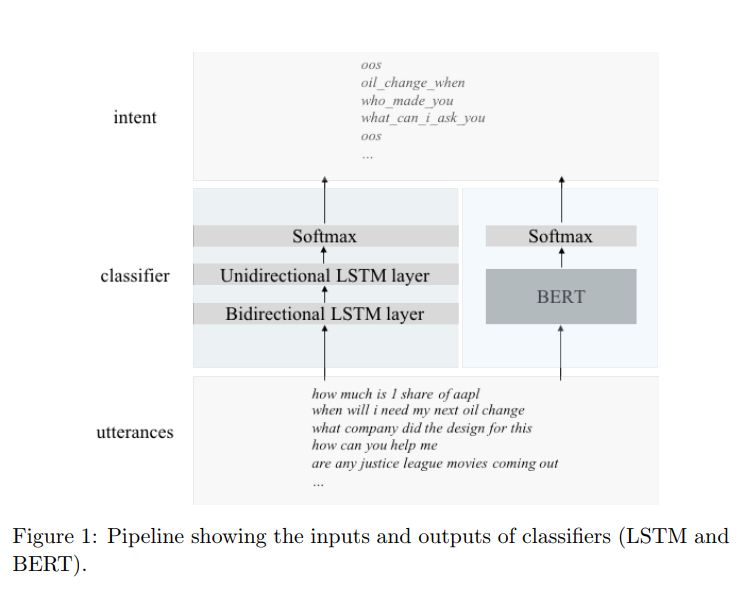
논문에서는 BERT와 LSTM을 비교하기 위해서 text classification task를 선택하였고, 동일한 training set으로 학습하고, 동일한 validation, test set으로 평가했습니다. 작은 데이터 셋에서 모델을 평가하는 것이 목적이기 때문에 데이터 셋에서 X를 {25, 40, 50, 60, 70, 80, 90}로 주어서 데이터를 랜덤하게 추출하여 사용했습니다.
Figure 1을 통해의도 분류(intent classification) task에서 LSTM과 BERT를 비교하는 파이프라인을 확인할 수 있습니다. figure에서 본 것처럼 분류기는 utterance를 text 형식으로 입력으로 받고 intent를 예측합니다. 각 발화는 intent label가 있습니다. 또한 다양한 LSTM 모델을 비교하기 위해서 LSTM layer의 뉴런 수와 양방향 layer 수를 변경하여서 총 6가지 아키텍처로 실험을 진행했는데요. 각 LSTM layer에 50개 뉴런이 있는 세가지 LSTM 모델과 각 LSTM layer에 100개의 뉴런이 있는 세 가지 LSTM 모델을 실험했습니다.
<Experiments>
<1. Corpora>
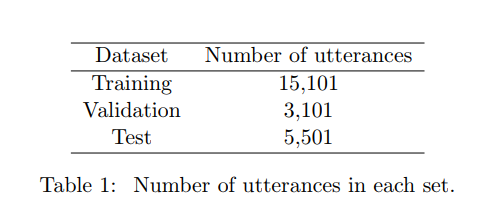
Table 1을 통해 training, validation, test set에 있는 발화의 수를 확인할 수 있습니다. 데이터 셋은 챗봇을 구축하기 위해서 수집된 발화로 구성되어 있고, 150개의 intent class가 있습니다. training set을 보면 150,001개 인데 이는 150*100개로 각 intent 당 100개의 training sample로 구성되어 있다고 보시면 되겠습니다. validation은 클래스당 20개, test는 클래스당 30개 sample이 제공된다고 합니다. 또한 150 intent class에 해당하지 않는 범위 밖의 쿼리도 있다고 하는데요. 이 데이터 셋의 목적은 dialogue modeling field가 범위를 벗어난 발화에도 초점을 맞추도록 challenge하는 것입니다. 그렇기 때문에 데이터 셋이 이렇게 구성되어 있다고 보시면 될 듯 합니다.
그런데, 데이터 셋이 매우 왜곡되어 있고, class 범위 밖 발화의 수가 class 범위 내 발화 수에 비해 매우 적습니다. 또한, 각 intent의 관찰 가능한 수보다 class 수가 많다는 것도 문제입니다. 데이터셋에서는 class 범위 밖 발화가 1200개만 존재하고, 이 중 100개는 training set에, 100개는 validation set에 나머지 1000개의 범위 외 발화는 테스트 셋에 있습니다. 논문에서는 데이터 셋 논문에서와 비교를 위해서 데이터의 순서나 분포는 변경하지 않았다고 합니다.
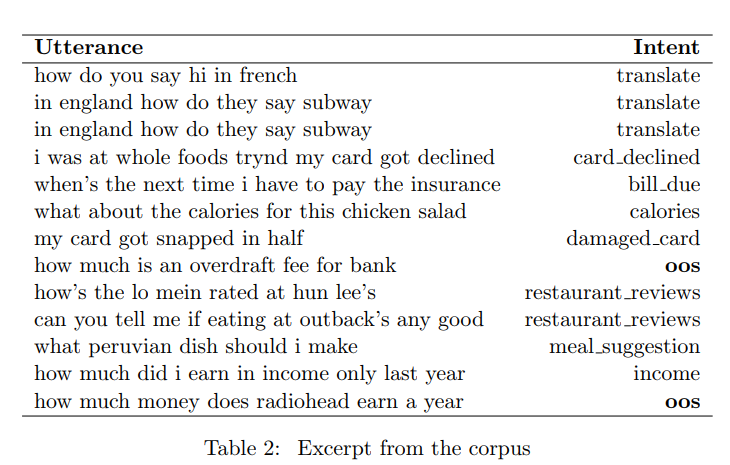
데이터 셋의 말뭉치에서 발췌한 내용은 Table 2를 통해 확인할 수 있습니다. 이 데이터 셋을 제공한 논문에서는 support vector machines, convolutional neural network, BERT만 비교하는데요. LSTM은 비교하지 않았을 뿐만 아니라 전반적인 accuracy도 공개하지 않았다고 합니다. 데이터 셋 논문에서는 범위 내 발화에 대해서만 정확도를 계산할 때 BERT의 성능이 가장 뛰어나고 범위를 벗어난 발화가 있을 때 모든 모델의 성능이 저하된다고 결론지었습니다. 그에 반면에 이 논문에서는 LSTM과 BERT를 비교하고 150개의 범위 내 발화와 범위 외 발화를 모두 포함하는 전체 accuracy metric을 제공합니다.

워드 클라우드에서 볼 수 있듯이, training set에서는 다양한 주제의 단어가 포함되어 있으며 어떤 단어의 빈도가 다른 단어보다 우세한 것은 없다는 것을 확인할 수 있는데요. 이는 모델이 특정 단어 집합을 학습하는 것만으로는 충분하지 않고, 어떤 패턴도 암기할 수 없음을 말하기 때문에 이 데이터 셋이 얼마나 어려운지 확인할 수 있습니댜.
<2. Experimental Results>

전체 정확도와 범위 내 정확도를 비교하기 위해, 그림 3음 데이터 셋의 여러 버전에 대해 나란히 표시합니다. 그림에서 볼 수 있듯이 데이터의 8개 파티션 모두에서 범위 내 정확도 결고가 전체 정확도 결과보다 높습니다. 따라서 BER와 LSTM을 비교하기 위해 전체 정확도만 보고합니다. (Figure 5 참고)

<2.1 LSTM architectures>
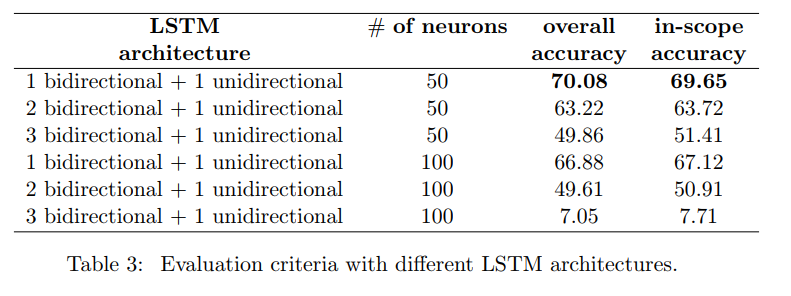
논문에서는 여러가지 LSTM 구조를 조합하여 실험을 진행하였는데요. Table 3을 통해 확인할 수 있습니다. 흥미로운 부분은 가장 심플한 LSTM 모델이 in-scope와 out-of-scope 모두 에서 성능이 높게 나왔습니다.
<2.2 Validation set>
본 논문에서는 validation set은 어떤 아키텍처가 가장 좋은지 결정하는 데에만 사용되었다고 합니다.
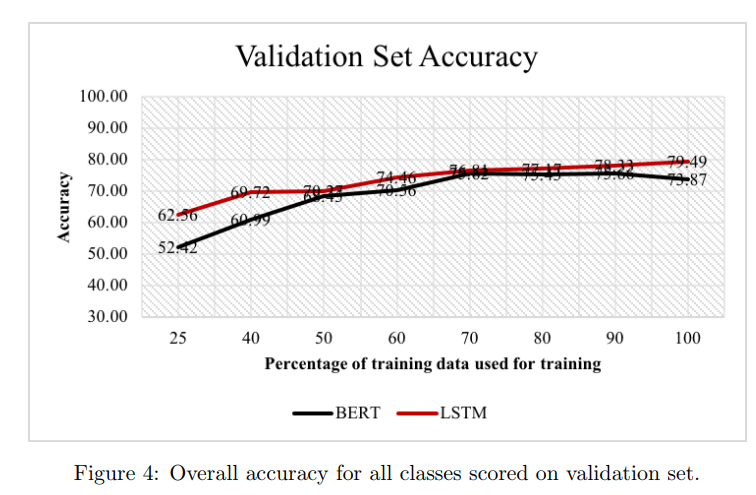
Figure 4는 다양한 데이터 셋 크기에 대해서 BERT와 가장 간단한 LSTM(위에서 언급한 양방향 layer 1개 + 단방향 layer 1개로 구성된 LSTM)의 성능을 비교한 것입니다. 모든 데이터 셋에서 LSTM이 BERT보다 성능이 높은 것을 알 수 있습니다. 여기서 그래프를 보면 흥미로운 부분이 있는데 데이터 셋이 클 때보다 작을 때 LSTM과 BERT의 정확도 차이가 훨씬 크다는 것입니다. 더 구체적으로 말하면 데이터 셋이 25%일 때 16.21% 정도 성능 차이가 발생했고, 데이터 셋이 80%로 큰 데이터 셋일 때는 2.25% 정도 성능 차이가 발생했습니다. 이러한 결과는 작은 데이터 셋인 경우에 BERT와 같은 복잡한 모델은 overfit이 될 수 있으며, LSTM과 같은 간단한 모델이 더 나은 성능을 발휘할 수 있음을 보입니다.
<2.3 Test set>
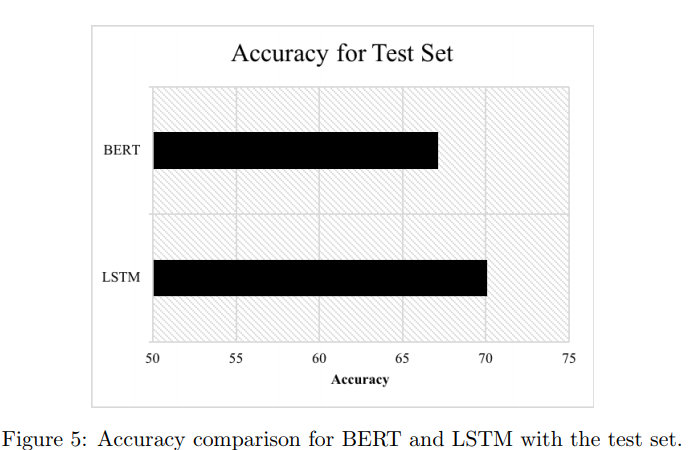
위에서 validation set 실험 분석 결과, 가장 단순한 LSTM 모델이 가장 좋은 성능을 보였습니다. 이 때문에 test set에서 가장 단순한 LSTM 모델을 선택해 BERT와 비교하였습니다. 위에서 언급했다싶이 test set에는 out-of-scope 발화가 훨씬 더 많기 때문에 정확도가 validation set보다 낮게 나올 것이라고 당연히 예측할 수 있습니다.
실시간 시스템에서 챗봇은 사용자가 시스템과 unseen out-of-scope 발화로 인해 어려움을 가집니다. 그렇기 때문에 dialogue under standing models은 이러한 발화 타입에 강해야 합니다. 이것이 test set에 더 많은 out-of-scope 발화가 있는 이유입니다. 모델이 out-of-scope에 대한 경험이 많지 않지만 실시간으로 작업할 수 있는지 확인하기 위해 test set을 이렇게 설정하였습니다.
test set에서는 LSTM의 in-score accuracy가 69.65%, overall accuarcy가 70.08%인데 반해, BERT는 67.15%의 accuracy를 달성했습니다.
Figure5를 통해 BERT와 LSTM의 비교를 확인할 수 있습니다. validation set에서와 마찬가지로 test set에서도 LSTM이 BERT보다 더 높은 accuracy를 달성했다는 것을 확인할 수 있습니다.
<Conclusion>
이 논문에서 결론 파트에서는 절대 BERT의 명성을 내리거나 하지 않습니다. BERT 덕분에 NLP 분야가 획기적인 발전을 이루었고 전이 학습을 할 수 있게 되었다고 합니다. 또한 BERT의 접근 방식은 label이 지정되지 않은 대규모 데이터 셋을 비지도 방식으로 학습하고 모델의 마지막 layer를 수정하여 특정 작업에 맞게 조정할 수 있는 문을 열어준 아주 멋진 녀석입니다. 그 후에 많은 연구자들이 매개변수를 조정하여서 다양한 데이터 셋에 대한 새로운 최첨단 결과를 얻었습니다. 이러한 연구 중 다수는 대규모 데이터 셋을 활용하였는데요. 이 논문에서는 소규모 데이터 셋에 집중하여서 다른 각도에서 모델을 제안했습니다. 서론에 나온 연구 질문은 task별 소규모 데이터 셋에 대해 LSTM과 BERT를 비교하는 것으로 공식화 했습니다. 실험을 위해서 선택한 데이터 셋은 챗봇을 구축하기 위한 데이터 셋으로 의도 분류 task를 선택했죠. 굳이 챗봇을 위한 소규모 데이터 셋을 선택했냐면 챗봇의 상호작용이 합성 데이터를 사용하기 보다는 사람이 직접 연구를 통해 수집해야 하기 때문에 데이터 셋이 작을 수 밖에 없기 때문입니다. 그래서 이 논문의 실험에 사용하기에 적합한 데이터셋인 것이죠.
다양한 아키텍쳐의 LSTM으로 실험한 결과 가장 단순한 LSTM이 이 데이터 셋에 가장 적합하다는 것을 발견하였고, BERT와 비교했을 때 LSTM은 validation set과 test set 모두에서 통계적으로 유의미하게 더 높은 정확도를 보였습니다. 또한 실험 결과, 더 작은 데이터 셋의 경우 BERT가 단순한 LSTM 보다 overfit 된다는 것을 발견하였습니다.
그래서 최종적으로 요약하자면, BERT의 성공을 폄하하는 것이 절대! 아닙니다. 하지만 소규모 데이터 셋에서 바라봤을 때 LSTM이 더 좋은 성능을 발휘했죠. 그래서 결국은 어떤 모델을 사용하기 결정하기 전에 데이터 셋과 연구/비즈니스 연구 요구 사항을 먼저 분석하는 것이 중요합니다.
이렇게 리뷰를 작성하였는데요. arXiv 논문이었지만 인용수가 80이상으로 생각보다 많은 사람이 이 논문을 보았구나 생각했습니다. 논문을 읽으면서 BERT에 대해서 절대 폄하하지 않겠다는 의지가 보일 정도로 전반적인 파트에서 BERT를 보호하는 듯한 글을 굉장히 많이 보여서 재밌게 읽었던 것 같습니다. 이 논문을 읽으면서 저는 텍스트 전처리 + LSTM을 다시 정리하게 되었는데요. 이 부분이 생각보다 많이 어려워서 많이 헤매었습니다. 나중에 다이어리로 싹 정리해서 올려보도록 하겠습니다. 읽어주셔서 감사합니다.
안녕하세요 김주연 연구원님, 좋은 리뷰 감사합니다. NLP에 대해서는 거의 아는 바가 없었는데, 저에게는 새로운 분야였기에 재밌게 읽을 수 있었습니다. 비전이랑 비슷한 부분도 있고 다른 부분도 많았기에 나름 정리하면서 읽어보려 노력했습니다. 리뷰를 읽고 제가 이해하기로는 다음과 같습니다.
1. (2020년 기준으로) 몇년 전까지만 해도 NLP 커뮤니티에서는 모델을 처음부터 학습시켰습니다. 비전 분야가 ImageNet을 기점으로 transfer learning이 가능해졌지만, NLP는 데이터셋이 구축된지 오래되지 않았기 때문입니다. NLP의 turning point는 transfer learning이 가능하게 되면서부터입니다(NLP의 imageNet moment)
2. transfer learning에 이어서 transformer는 NLP의 새로운 시대를 열었습니다. transformer는 sequential data를 다룰 수 있는 딥러닝 모델이지만 RNN처럼 데이터를 순서대로 처리할 필요가 없어서 병렬 처리가 가능합니다. 이를 바꿔 말하면 학습 시간이 단축되고, 큰 데이터셋 학습이 가능하다는 의미입니다.
3. Transformer는 요약, 번역, 분류를 포함한 NLP task에서 큰 성과를 보여주었습니다. 대표적인것이 unsupervised방식으로 큰 데이터셋으로 학습된 BERT입니다.
4. 이 논문은 큰 데이터셋으로 학습된 BERT가 작은 데이터셋에 대해서는 어떤 성능을 보이게 되는지에 대해 물음을 던집니다. BERT의 성공을 인정하며, 작은 데이터 셋에서 transformer 성능과 기존의 bidirectional 모델의 성능을 비교합니다.
5. 실험 결과 간단한 구조의 LSTM과 BERT를 비교했을 때, 전반적으로 LSTM이 우수한 성능을 보이며 데이터셋이 클 때보다 작을 때 LSTM과 BERT의 정확도 차이가 훨씬 크게 나타납니다. 데이터셋이 작으면 BERT와 같은 복잡한 모델은 overfit이 될 수 있기 때문입니다. 데이터셋에 따라 LSTM과 같은 간단한 모델이 더 나은 성능을 발휘할 수 있습니다.
NLP에서 transformer가 좋은 성능을 보여준다는것을 들어 알고는 있었지만, BERT가 얼마나 좋은 성능을 보여주는지 확인할 수 있었습니다. 하지만 작은 데이터셋에서는 LSTM에 미치지 못하는것을 보니, 역시 모든 task에 범용적으로 적용시킬 수 있는 모델을 만들기엔 갈 길이 멀어 보이네요.
리뷰를 읽다보니 몇가지 궁금한 점이 있어서 질문 남깁니다.
1. transformer는 RNN과 다르게 sequential data를 순서대로 처리하지 않는다고 되어있는데, 그럼 앞뒤 문맥을 어떻게 파악하게 되나요? 글 전체에 대한 문맥을 알아도 바로 앞뒤에 어떤 단어/문장이 있는지에 따라서 특정 문장의 문맥이 달라지게 될 것 같은데, transformer는 토큰의 순서를 무시하고 이러한 문맥을 어떻게 파악하는지 궁금합니다.
2. 리뷰를 보니 논문에서는 작은 데이터셋에서 BERT가 LSTM보다 낮은 성능을 보이는게 overfitting이 되기 쉽기 때문이라고 말하는 것 같습니다. overfitting때문에 낮은 성능을 보인다는 것을 실험으로 증명해주는지, 아니면 이는 논문 저자의 추측으로 언급하고 넘어가는지 궁금합니다.
3. 논문 내용과 직접적인 질문은 아니긴 하지만, arxiv에 올라온 논문인데 인용이 많이 되었다는 부분에서 arxiv에 올라온 논문도 정식 논문이라고 할 수 있는건지 궁금합니다. 말이 조금 이상한데.. 어떤 특정한 심사를 거친 논문이라고 볼 수 있는 것인가요? 아니면 정식 투고하기 전에 논문을 임시적으로 올려두는 성격이 강한건지 궁금합니다.
4. 본 논문에서는 자연어의 의도(intent)로 classification을 한 것으로 보이는데, NLP의 classification에 intent 이외에 다른 카테고리도 있는지 궁금합니다.
답변 주시면 감사하겠습니다!
댓글 감사합니다.
1. 이 부분에 대해서는 아직 transformer를 이해하고 있지 않아 질문이 발생한 듯 합니다. transformer는 한번에 문장을 넣는 대신에 positional encoding이라는 것을 해줍니다. 각 단어의 position을 입력해주는 과정이죠. 그래서 rnn의 경우 단어를 하나하나 넣어줌으로서 문장의 문맥을 파악하지만 transformer는 그렇지 않아도 되는 것이죠.
2. overfitting 때문에 낮은 성능을 보인다는 것은 논문의 가설이고, 이를 실험적으로 증명한 것을 conclusion에 작성한 것이라고 생각합니다.
3. 어떤 특정한 심사를 거친 논문이라고 보기는 어려울 것 같습니다. 하지만 제가 봤을 때 정식 투고하기 전에 논문 임시적으로 올려두는 성격이 강한 것 확실한 것 같습니다.
감사합니다.
좋은 리뷰 감사합니다.
간단한 질문 하나 드리자면 intent label의 값들이 의미하는게 뭔가요? Table 2에서 oos, translated와 같은 것들이 무엇을 의미하는지 궁금합니다.
댓글 감사합니다.
intent label로 정확히 무엇인지 언급하지는 않았았지만 Table 2의 oos, translated를 설명드리자면, oos는 out-of-scope로 label 범위 밖 의도를 말하는 것이고 translated는 문장의 의도가 번역이라는 말입니다.
감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
LSTM은 다음 단어의 문맥만 살펴보고, BETR은 이전 단어와 다음 단어의 문맥을 모두 고려한다는 점이 LSTM과 BETR의 가장 큰 차이점인건가요? 만약 그렇다면 이 점은 작은 데이터셋에서 LSTM이 더 성능이 좋은 이유에 영향은 없는 건가요? 단지 BETR이 작은 데이터셋에 대해 LSTM보다 overfit되기 때문에 성능이 더 낮은 것인지 궁금합니다.
감사합니다.
안녕하세요. 댓글 감사합니다.
1, 2) 이 부분에 대해서는 제가 자세히 설명드리지 않아 생긴 질문인 것 같네요. 논문에서는 양방향 lstm을 사용하였기 때문에 다음 단어의 문맥만 보는 것 뿐만 아니라 이전 단어의 문맥도 같이 봅니다. bert는 transformer 기반이기 때문에 당연히 이전 단어, 다음 단어 문맥 모두를 살펴보지요. 논문에서 강조하고 싶은 점은 LSTM은 사전학습이 되어 있지 않았다는 것이고 BERT는 사전학습이 되었다는 것입니다. 가장 큰 차이점이라고 봐도 됩니다. BERT는 굉장히 큰 데이터셋으로 이미 학습이 되어있기 때문에 작은 데이터셋에서는 overfitting이 발생할 수도 있다는 것이 논문의 요지인 것 같습니다.
3) 세 번째 질문은 논문의 내용을 한줄로 요약하면 윤서님처럼 말할 수 있을 듯 합니다. 당연히 다른 이유가 있을지도 모르지만 논문에서는 데이터셋에 대해서만 가설을 세우고 실험을 진행했기 때문에 단순히 작은 데이터셋이여서 오버피팅이 발생하여 성능이 더 낮게 나왔다고 생각할 수 있습니다.
감사합니다.