제가 이번에 리뷰할 논문도 retrieval을 기반으로 하는 place recognition 논문입니다.
VPR(Visual Place Recognition)은 위치를 알고자 하는 영상(쿼리 영상)과 데이터베이스의 영상들(reference 영상, GPS 정보가 태그되어있음)을 비교하여, 유사한 영상을 찾아내는 방식을 통해 쿼리 영상의 위치를 추론하는 태스크입니다. 이러한 VPR은 대규모 데이터를 이용한다는 점, 반복되는 구조 및 단기적 변화(날씨와 조명 변화, occlusion 등)와 장기적 변화(계절 변화, 공사나 식물로 인한 변화 등)로 인해 외관이 변할 경우 유사한 영상을 찾기 어렵다는 점에서 어려운 태스크 입니다.
VPR은 전통적으로 SIFT와 SURF, BOW, VLAD와 같은 hand-craft 방식을 이용하여 영상의 descriptor를 구한 뒤 유사한 영상을 찾는 방식을 이용하였습니다.
딥러닝의 발달로 CNN이 컴퓨터비전 분야에서 널리 사용되었고, 영상 분류 모델의 중간 레이어를 이용하는 것이 hand-craft 방식보다 좋은 성능을 보이는 것을 확인하자 CNN을 이용한 VPR 연구도 발달하였습니다. 이러한 CNN 기반의 VPR 연구들은 주로 NetVLAD를 활용한 방법론들로, view-point가 변해도 local한 특징은 변하지 않는다는 점을 이용하여 local feature를 통합하는 것에 중점을 두었습니다. 그러나 local한 특징은 조도 및 계절 변화에 변한다는 문제가 있었습니다.
이에 관심 영역에만 집중하는 방식(MAC, R-MAC, GeM 등)이 연구되었으나 NetVALD에 비해 성능이 저조하였다고 합니다. 그러나 최근에 GeM을 변형한 CosPlace에서 좋은 성능을 보였다고 합니다.
또한, vision Transformer를 이용하는 TransVPR(해당 논문이 궁금하시면 이전 리뷰를 참고해주세요)가 최근에 연구되었으나 TransVPR은 local feature matching에서는 좋은 결과를 보였으나, global feature는 NetVLAD와 CosPlace보다 낮은 성능을 보였다고 합니다.
해당 논문에서는 MixVPR이라는 새로운 feature 통합 방식을 제안합니다. 이는 여러 밴치마크에서 SOTA를 달성하였고, 모델의 파라미터도 크게 줄일 수 있었다고 합니다.
Method
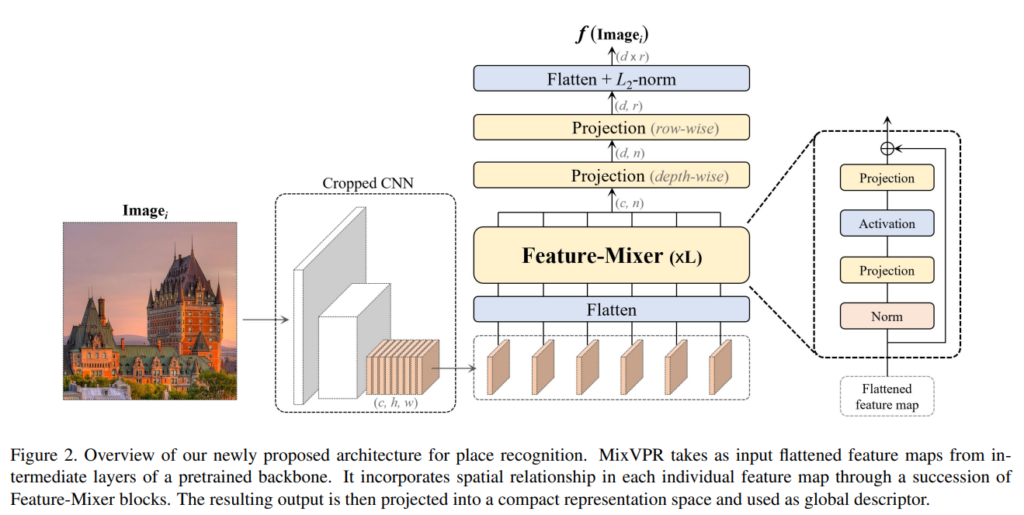
해당 논문은 컴팩트한 global feature를 생성하는 것을 목적으로 합니다. 전체적인 과정은 위의 그림2를 통해 확인할 수 있습니다. 우선 기존의 위치인식 방법론처럼 CNN 백본으로부터 feature map \mathbf{F} = CNN (\mathcal{I})= \{ X^i \}, i=\{ 1, ..., c \}을 생성합니다. 이때 3D 텐서형태의 \mathbf{F}를 저자들은 2D feature들의 집합이라 보았고, flatten 과정을 통해 X^i를 1D feature로 바꾸어줍니다. \mathbf{F}∈\mathbb{R}^{c⨉n}, n=h⨉w
이렇게 얻어진 feature는 Feature-Mixer로 정의한 L개의 MLP 블록에 입력으로 들어갑니다. Feature-Mixer는 아래의 식(2)를 통해 flatten된 feature의 global한 관계를 구합니다.
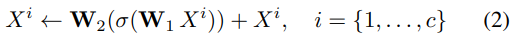
\mathbf{W}_1, \mathbf{W}_2는 FClayer이고, σ는 ReLU를 의미합니다. Figure 2에서 확인할 수 있듯이 skip connection을 통해 입력된 featuer를 결과에 합쳐줍니다. Featuer-Mixer는 local 피쳐에 집중하거나 attention 매커니즘을 이용하지 않고 FClayer를 이용하여 전체적으로 feature를 연산하는 방식입니다.(FClayer를 통해 전체 영역을 봄)
이렇게 Feature-Mixer로 생성된 결과는 두번째 Feature-Mixer 블럭에 입력으로 들어갑니다. 이렇게 L개의 블록을 통과하여 \mathbf{Z}∈\mathbb{R}^{c⨉n}를 생성합니다.
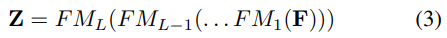
이후 차원을 줄이기 위해, depth-wise(채널축으로) layer와 row-wise layer를 통과시켜 global descriptor의 크기를 조절한다고 합니다. \mathbf{Z}'∈\mathbb{R}^{d⨉n}이 depth-wise연산을 한 결과이고, \mathbf{O}∈\mathbb{R}^{d⨉r}이 row-wise 연산을 수행한 결과라 합니다.
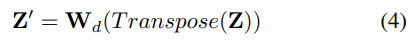
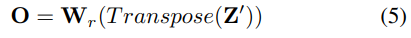
이후 L2 normalization을 수행하여 최종적으로 d⨉n 차원의 feature를 얻게 됩니다.
Connection to existing architectures
앞서 설명한 과정은 CNN 모델의 feature를 통합하여 global feature를 생성하는 과정으로, 연산이 행렬곱을 이용하며, CNN의 마지막 레이어가 아닌 중간 레이어를 이용한다는 점에서 연산량과 파라미터를 줄일 수 있었다고 합니다.
방법론에 대한 설명은 위의 내용이 전부입니다. 해당 논문의 노벨티가 방법론 측면에서 크게 있다기보다는 실험적으로 성능이 우수하며 파라미터 및 시간이 적게 든다는 점을 보였기 때문이 아닐까 합니다.
Experiments
Implementation details
우선 다른 방법론들이 CNN백본의 마지막 부분을 이용하고, MixVPR은 중간 feature를 이용하기 때문에 resolution의 차이가 생기는데, 보다 공정한 평가를 위해 모두 동일한 백본(ResNet-50)을 이용하여 실험을 진행하였다고 합니다. 또한 동일하게 ImageNet으로 사전학습된 모델을 GSV-Cities 데이터셋에 대해 학습하였다고 합니다.
평가는 Pitts250k-test과 Pitts-30k 데이터에 대해 수행하였다고 합니다. Pitts250k는 Google 거리뷰 이미지에서 수집된 8,000장의 쿼리 영상과 83,000장의 reference 영상, Pitts30k는 8,000개의 쿼리영상, 8000개의 reference 영상으로 구성됩니다. 또한, 607장의 쿼리 영상과 607장의 reference 영상으로 구성된 SPED 데이터셋, 차에서 촬영된 영상으로 구성된 MSLS 데이터셋, 극심한 변화를 포함한 Nordland 데이터셋을 이용하였다고 합니다.
Comparison to the SOTA
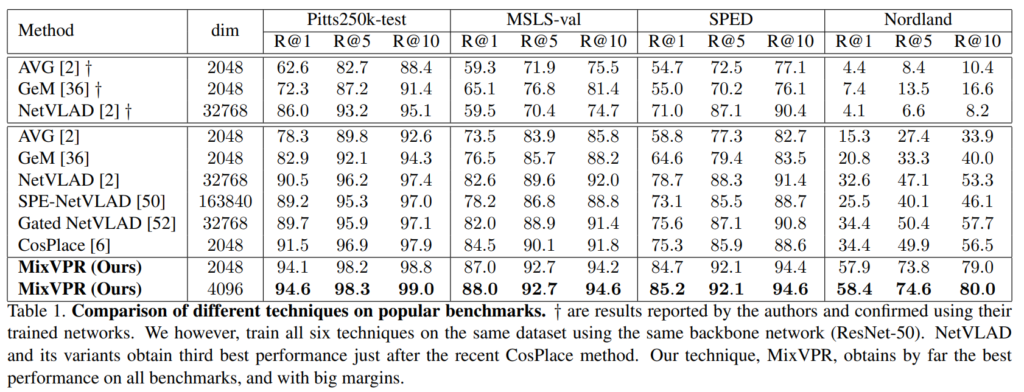
위의 Table 1은 많이 사용되는 방법론들과 SOTA방법론들, MixVPR을 리포팅한 결과로, †는 Pitts-30k의 train 데이터로 학습한 것을 나타냅니다. 결과를 통해 모든 경우에 다른 방법론들에 비해 좋은 결과를 달성하였음을 보였습니다. 외관 변화가 크게 일어나는 SPED 데이터셋에서도 가장 좋은 결과를 보여주었고, 도전적인 환경으로 구성된 Nordland 데이터셋에서도 MixVPR이 잘 작동함을 보였습니다.
Comparison against 2-stage techniques
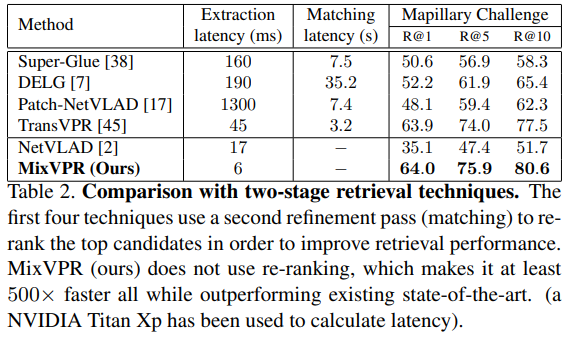
다음으로 2-stage 방법론들과 비교한 결과입니다. 2-stage 방법론들은 첫번째 단계를 통해 global representation으로 Top M개를 찾은 뒤, 두번째 단계에서 쿼리와 M개의 영상들의 local feature를 비교하여 기하학적 검증(re-ranking)을 수행하는 방법론들입니다. Table 2에 Patch-NetVLAD, DELG, SuperGLue, TransVPR의 성능을 리퐅이하였고, 결과를 통해 해당 논문에서 제안한 MixVPR이 re-ranking 과정을 거치지 않았음에도 좋은 결과를 보이는 것을 확인할 수 있습니다. 이때 2-stage 방법론들은 re-ranking 과정에 의해 오랜 시간이 걸리고, 시간상의 문제로 실제로 활용하기 어려움이 생깁니다. 그에 반해 저자들의 방법론은 빠르고 좋은 성능을 보여주었습니다.
Ablation studies
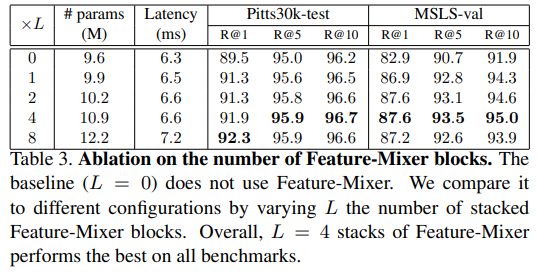
- Table 3은 레이어의 개수를 바꿔가며 실험을 한 것으로, 4개의 layer로 구성된 Featuer-Mixer가 가장 좋은 성능을 보였다고 합니다.
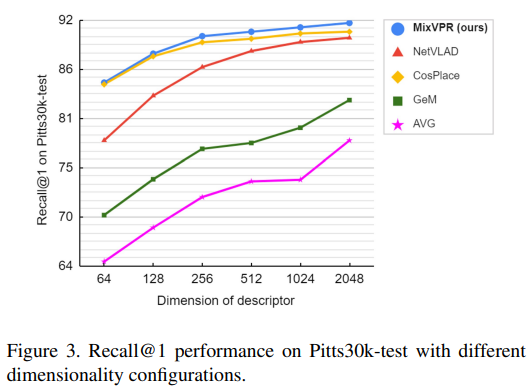
- 위의 Figure 3은 descriptor의 차원수에 따른 성능을 리포팅한 그래프로, MixVPR이 언제나 좋은 결과를 보인다는 것을 시각화하였다고 합니다.
Qualitative Results


Figure 4는 정성적으로 결과를 나타낸 것으로 반복되는 구조, 시점의 변화, 하늘이 중요한 역할을 하는 경우, 조도 변화, Occlusion에서 저자들의 방법론이 잘 작동한 경우에 대해 나타낸 것이다.
안녕하세요 좋은 리뷰 감사합니다.
1. 기존 방법론들이 훨씬 큰 차원의 feature를 사용하면서 re-ranking까지 수행함에도 불구하고 본 방법론보다 높은 성능을 내지 못한 것은 local한 영역을 보는 것에만 매몰되어 있기 때문이었던 것인가요? global 정보를 본다는 것이 cnn의 output을 나눠 FC layer에 태우는 것으로 이해하였는데, 단순하게 global이라는 키워드가 큰 성능 향상을 일으킨다는 것이 잘 이해가 안되어 혹시 모듈 별 ablation 실험이 있는 경우 첨부해주신다면 감사드리겠습니다.
아니면 resnet의 전체 layer를 이용하는 경우 원래 타 방법론들은 더 높은 성능을 보여주는데, 중간 layer로 통일한 세팅에서 본 방법론의 성능이 더 높다는 것인가요?
2. L개의 feature mixer layer를 거쳐 나온 feature에 row-wise fc layer를 태워주는데, 여기서 row-wise 연산이라는 것이 VPR을 위한 어떠한 의도를 가지거나 또는 특정 효과를 기대하고 수행하는 것인지 아니면 단순히 차원을 줄이는 역할을 하는 것인지도 궁금합니다.
댓글 감사합니다. 질문해주신 내용에 대한 답변은 다음과 같습니다.
1. 우선 기존의 방법론들이 큰 차원의 feature를 이용하였다고 하셨는데, 다시 정리하여 설명드리면 기존의 방법론들은 CNN의 뒷단 feature를 이용하기때문에 파라미터가 많다는 것이고, feature의 차원은 그림3의 그래프로 확인할 수 있듯이 일정한 차원에 대해 실험을 하였습니다. 따라서 큰차원의 feature를 이용하였으나 성능이 더 좋다고 보기는 어려운 것 같습니다. 그리고 말씀하신바와 같이 저자들의 방법론이 re-ranking을 수행한 방법론보다 좋은 성능을 보인 것은 데이터셋 때문이 아닐까 합니다. Mapillary 데이터셋은 9년동안 촬영된 영상으로, 사계절에 촬영된 영상도 포함되는 등 챌린지한 데이터셋이라 합니다. 리뷰의 앞부분에 설명드렸듯이 local한 feature는 조도 및 계절 변화에 따라 변한다는 문제가 있기 때문에 re-ranking을 수행한 방법론들에서 성능이 더 낮게 나온 것이라 생각합니다. 또한 모듈별 ablation study는 없었습니다..
2. 단순히 global descriptor의 차원을 줄이기 위해 depth-wise연산과 row-wise 연산을 수행한 것으로 이해하였습니다. cxn 차원이였던 descriptor를 dxr 차원으로 변경하기 위해 depth-wise로 c->d, row-wise로 n->r로 차원을 줄인 것으로 보시면 될 것 같습니다. 특히 저자들이 제안한 방법론이 CNN의 중간부분의 feature를 이용하는 것이라 n=wxh가 됩니다. 이는 실험 세팅을 기준으로 보면 30×30이 됩니다. 이러한 경우 차원이 너무 커서 row-wise도 수행한 것이라 생각합니다.
좋은 리뷰 감사합니다.
몇 가지 질문 던져두고 가겠습니다.
1. 해당 기법의 아웃풋은 무엇이고, 손실 함수는 어떻게 구성되나요? 위치 인식 태스크에서는 아시다시피 positive sample과 negative sample의 간극이 애매한 문제를 해결하는 것이 가장 중요하다고 생각했는데 이에 대한 제안된 내용이 없어서 질문 드립니다.
2. ‘Connection to existing architectures’ 중 ‘앞서 설명한 과정은 CNN 모델의 feature를 통합하여 global feature를 생성하는 과정으로, 연산이 행렬곱을 이용하며, CNN의 마지막 레이어가 아닌 중간 레이어를 이용한다는 점에서 연산량과 파라미터를 줄일 수 있었다고 합니다.’ 행렬곱을 이용하는 내용과 CNN의 중간 레이어를 이용한다는 말이 무슨 말인지 모르겠습니다.
혹여 Feature-Mixer에 들어가기 전 연산을 설명하는 거면;; 대부분의 vit 모델들이 사용하는 기법인데;; 흠…
댓글 감사합니다.
1. 해당 기법의 output은 d ⨉ r 차원의 descriptor 입니다. 또한 손실함수는 Multi-Similarity loss** 를 이용하였다고 합니다. 기존의 논문에 가장 좋은 성능을 보인다고 나와있어 사용한 것으로 보입니다. 해당 loss는 positive는 가까워지도록, negative는 멀어지도록(positive는 유사도가 높을수록 가중치가 낮아지는 방식, negative는 유사도가 낮을수록 가중치가 낮아지는 방식) 하는 함수입니다.
**(CVPR 2019, Multi-Similarity Loss with General Pair Weighting for Deep Metric Learning)
2. 일단 기존의 방법론들은 CNN의 뒷단을 사용했으나 저자들은 중간 feature를 이용하므로써 파라미터를 절반정도로 줄일 수 있었다고 합니다. 행렬곱을 이용하는 것은 그 뒤의 MLP Mixer를 이용하는 과정이 FC layer이기 때문에 행렬곱 연산으로 빠르게 연산이 가능하다는 것을 표현하고자 하였습니다..
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽다, 간단한 의문점이 들어 질문 남깁니다.
1. 결국 Global information을 위해 L개의 MLP를 통과한다는데, 이론적으로 이해되지만 너무 나이브하지 않나 싶어서, 제가 리뷰를 잘못이해했나 싶어 질문 남깁니다! 승현 연구원님이 생각하시는 이 논문의 핵심 Contribution에 대해 말씀해주시면 감사합니다
2. 리뷰 첫 부분을 읽다 단순히 해당 태스크에 대해 든 생각으로, 해당 태스크에서는 viewpoint에 대한 변화에 강인해야하니 Local 중 object에 대한 Feature가 더욱 중요할 것으로 보이는데, 그렇다면 CNN을 사용했을 때의 불이점도 있을까요?
좋은 리뷰 감사합니다
댓글 감사합니다.
1. 우선 해당 방법론이 너무 나이브하다고 하셨는데, 사실 저도 그렇게 생각합니다. 제가 리뷰에서 언급하지 않고 넘어가는 바람에 해당 논문의 포지션을 잘 파악하기 어려우셨던 것 같습니다. 부연설명하자면, 해당 논문은 MLP Mixer라는 연구 흐름을 활용한 방법론이라 합니다. MLP Mixer는 CNN과 ViT가 활발히 연구되고 있을 때 성능이 떨어지지 않으면서도 보다 간결하게 모델을 구성할 수 있도록 제안된 방법론입니다. 그리고 이 논문의 핵심 contribution이라하면 이러한 MLP Mixer를 VPR에 적용했으며 실험적으로 검증한 것이라고 생각합니다.
2. local한 feature도 중요한 역할을 하기는 하지만, 영상의 전체적인 부분을 이해하기에는 부족함이 있고, local feature는 국소적인 영역을 보기 때문에 영상에 변화가 생길 경우 크게 변한다는 단점이 있어 global한 정보를 더 우선시하는 것으로 이해하시면 될 것 같습니다.
안녕하세요 이승현 연구원님 좋은 리뷰 감사합니다.
질문이 한 가지 있는데요, Introduction에서는 MixVPR이 global 영역에 대한 성능이 더 좋을 것이라 생각하고 읽었는데.. 보통 VPR에서는 local 영역에 더 집중했다 혹은 global 영역에 더 집중했다를 주장하는 데 어떤 성능 지표를 사용하나요? 이를 주장하는 데에 보통 정성적인 결과만을 사용하는지 궁금합니다.
그리고 두번째는 descriptor의 차원수에 대한 질문입니다.
차원 수가 많아질 수록 성능이 좋아지는 것은 자명해보입니다만, CosPlace와 MixVPR 은 왜 NetVLAD만큼 드라마틱한 성능 향상이 없을까요? 이승현 연구원님의 생각이 궁금합니다
댓글 감사합니다.
1. 혹시 질문하시는 내용이 어떤 성능지표로 local과 global을 판단하는지 인가요?? 만일 이에 대한 질문이 맞으시다면 성능지표를 사용하는것은 아니고, 해당 descriptor가 고려하는 영역이 어떻게 되는가 입니다. 그리고 VPR 태스크는 주로 Top k개에 대한 recall 성능을 성능지표로 사용합니다.
2. 음.. 저는 차원수가 낮아도 CosPlace와 MixVPR의 성능은 어느정도 좋은 결과를 보였기 때문에 성능이 향상될 수 있는 범위가 적었던 것이라고 생각하였습니다… 질문해주신 내용에 대해서는 MixVPR에서는 다루고 있지 않아서 저도 확실하게 근거가 이렇다라고 말하기는 어려울 것 같습니다.
안녕하세요 이승현 연구원님. 좋은 리뷰 감사합니다.
리뷰를 읽고 몇 가지 질문이 있어 댓글 남깁니다.
1. 해당 논문은 global한 feature를 생성하는 방식을 제안한 논문이며, CNN에서 생성된 feature를 MLP를 통해 global한 정보를 잘 보는 feature로 통합하는 것으로 이해하였습니다. 그렇다면 단순히 FC레이어를 통과하는 것으로 global한 영역을 잘 볼 수 있게 되는 건가요?
2. “CNN의 마지막 레이어가 아닌 중간 레이어를 이용한다”라는 것은 backbone인 ResNet50의 중간 일부를 crop하여 사용한다는 의미로 해석하였는데 구체적인 모델 구조가 궁금합니다. 또한 이때 연산량과 파라미터가 적게 드는 것은 단순히 네트워크를 일부만 사용하였기 때문에 나타나는 현상인가요?
댓글 감사합니다.
1. 저자들은 FC 레이어를 통해 receptive field를 전체 영역으로 넓힐 수 있었다고 합니다. 아무래도 CNN은 커널을 통해 local한 영역만 볼 수 있었다면, FC 레이어는 처음부터 끝까지 모두 연결되어 있으므로 전체적인 관계를 고려할 수 있다. 즉, global한 정보를 추출할 수 있다고 이해하시면 될 것 같습니다.
2. 이해하신 바가 맞습니다. ImageNet으로 사전학습된 ResNet50을 모두 사용하지 않고 중간을 잘라내어 사용하기 때문에 파라미터가 절반으로 줄어들었다고 합니다.