본 논문에서는 FCAF3D라는 모델을 제안한다. FCAF3D는 Fully Convolutional Anchor-Free indoor 3D object detection의 줄임말로 3d object detection방법론 중 처음으로 anchor-free를 적용한 방식이다. point cloud를 입력으로 하여 voxel representation 형태로 사용하고 sparse convolutions에 통과시킨다. FCAF3D는 하나의 fully convolutional network의 feed-forward pass를 통해 짧은 runtime시간동안 넓은 범위의 scenes에 대해 다룰 수 있다고 주장한다. 그리고 기존 3D object detection 방법론들의 경우 prior bounding box 등을 활용하여 object의 geometry정보에 의존해서 priors를 추정했는데, 이것이 일반화 능력을 해칠 수 있다고 주장한다. 일반화 능력을 제한하는 prior assumptions를 없애고자 본 논문에서 저자는 이름에서 보이는 것처럼 anchor-free 방식으로 oriented bounding boxes의 새로운 parametrization(매개화)를 제안하여 더 순수하게 data-driven한 방법을 적용하고자 하였다. 제안된 FCAF3D 방법론은 다양한 dataset의 3D object detection 결과에서 sota를 달성할 수 있었다.
Introduction
point cloud를 기반으로 하는 3d object detection task는 autonomous driving, robotics, AR 등과 같은 분야에서 여러 가지 3d scene을 이해하는데 core기술로 다뤄지고 있다.
이미지는 각각의 픽셀값을 가지기 때문에 2d methods의 경우에는 dense한 fixed size의 kernel을 사용하였다. 하지만 3d methods의 경우 우선 3D data가 irregular하고 unstructed한 임의의 volume형태로 3d space에 분포하고 있기 때문에 2d methods의 data processing 방법을 3d methods에 direct하게 적용하는 것은 어렵다. 따라서 3d data를 processing하는데 다른 방법을 적용하였다. 3d data는 2d에서의 convolution과 다르게 하나의 차원을 더 가지기 때문에 3d convolution kernel을 사용하여 깊이 차원에 대해 더 훑어보는 형태를 적용하였다. 아래 그림을 통해 쉽게 이해할 수 있을 것이다.

하지만 이러한 convolutional 3D object detection 방법에도 문제가 있는데 scalability issue가 존재한다. large-scale scenes의 경우 많은 computational resource를 필요로 하고 따라서 process하는데 시간이 오래 걸리게된다. 3d convolution이 연산량이 많아진다는 것은 직관적으로 이해할 수 있을것이다. 이로 인해 본 논문에서 제안하는 방법론은 2d image에서의 pixel과 비슷한 구조를 형상화 하기 위해 3d space의 뿌려져있는 point를 일정한 크기의 voxel grid로 나누어 regular한 공간으로 제한하는 voxel representation방식을 취하고, 해당 방식은 아래 그림처럼 sparse한 형태를 보이기 때문에 sparse convolutions를 적용하였다.
하지만 이 방법은 detection accuracy의 성능 하락이 있다. 다르게 말해서 아직 accuracy와 scales를 모두 고려한 3d object detection method가 제안되지 않았다는 의미이다.
accuracy와 scale의 두 마리 토끼를 모두 잡기 위한 이상적인 3d object detection method는 임의의 shape과 size를 가지는 object에 대해 추가적인 hand-tuned hyperparameter없이 다룰 수 있어야한다고 주장한다. 저자는 3D bounding box의 aspect ratios나 sizes와 같은 prior assumption이 일반화 능력을 제한하고 학습해야 할 parameters 수를 늘린다고 주장한다.
따라서 본 논문에서는 bounding box의 shape이나 size와 같은 prior assumptions에 의존하지 않고 anchor-free method를 사용하여 data-driven한 방식을 취했다. 또한 parameters 수를 줄이기 위한 방법으로 새로운 oriented bounding box(OBB) parametrization을 도입하였다. 그리고 SUN RGB-D에서 실험적으로 OBB parameterization이 효과적이라는 것을 입증하였다.
본 논문에서는 point cloud를 기반으로 하는 3d object detection model인 FCAF3D를 제안한다. 다양한 3d data에서 실험적으로 효과를 입증하였고 sota를 달성하였다. 제안하는 contribution은 아래와 같다.
1. first-in-class fully convolutional anchor-free 3D object detection method for in door scenes. (first-in-class란 의약품 분야에서 전에 나온적 없는 신약 개발을 의미한다고 한다. ‘최초’라는 의미로 받아들이면 된다.)
2. present a novel OBB(Oriented Bounding Box) parametrization and prove it to boost the accuracy.
3. 다양한 large-scale indoor dataset에서 sota달성. mAP와 빠른 inference time 보임.
Related Work
최근 3D object detection 방법론들은 indoor와 outdoor상황에 따라 다르게 design되었다. indoor, outdoor에 따른 methods는 독립적으로 발전되어왔는데, 각각 domain-specific한 data processing을 적용하였다.
우선 outdoor인 경우, 많은 methods들은 3D points를 bird-eye-view plane에 projection하였다. 말 그대로 새가 보는 view, 위에서 내려다 보는 view로 projection하여 3d object detection task를 2d object detection task로 차원을 줄여 해결하는 것이다.
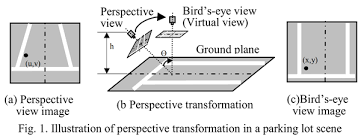

해당 접근방식은 2d object detection과 3d outdoor object detection 모두에서 효과적인 것으로 입증되었지만, occlusion이 많고 보다 많은 computation cost와 memory를 필요로 하는 indoor 상황에서는 실용적으로 적용하기 어렵다. 위와 같은 문제를 보완하기 위해 다른 3D data processing 방법들이 제시되었다. 3D object detection에서 크게 3가지 접근법이 dominant하게 사용되는데 voting-based, transformer-based, 3D convolutional이 해당하는 data processing 방법이다.
우선 voting-based method의 경우 VoteNet이 point voting을 적용한 최초의 3d object detection 방법론이다. votenet은 pointnet을 통과시킨 3d points 중 object candidates를 grouping하고 각 group의 center point를 voting하는 방법이다. votenet을 기반으로 하는 방법론들은 voting방식과 grouping방식을 개선하는 방향으로 제안되고 있다. BRNet, MLCVNet, H3DNet, VENet 등이 voting based 방법론이다.
voting based 방법론들은 scalability에 안 좋은 모습을 보이는데, 모델의 성능이 input data의 영향을 많이 받기 때문에 large scenes가 input으로 주어지면 속도가 느려진다고 한다. 또한 voting과 grouping이 custum한 layer를 통해 진행되기 때문에 debugging이 어렵고 mobile device에 porting하기 어렵다고 한다.
그리고 최근에는 end-to-end learning방식의 transformer-based methods가 등장하고 있다. Votenet의 head를 transformer module로 바꾼 GroupFree가 대표적이고 3DETR은 최초의 end-to-end 구조로 학습하는 3D object detection 방법론이다. 하지만 transformer-based methods도 여전히 scalability issue가 존재한다고 한다.
voxel representation은 3차원 공간에서 증가하는 sparse한 3d data를 효율적으로 처리할 수 있다. voxel 기반의 3d object detection 방법론에서는 points를 regular grid인 voxel로 변환하여 3d convolutional network를 통해 처리한다. 하지만 dense한 voxel 부분에서는 많은 메모리를 필요로 하고 3d convolution은 많은 연산량을 요구한다. 전반적으로 large scenes를 처리하기 위해서는 많은 resource가 필요하고 sigle pass로 처리하기 어려움이 있다. GSDN 방법론에서는 sparse 3d convolution을 통해 성능을 향상시켰다. 해당 방법론에서는 3d convolutional blocks이 존재하는데 encoder-decoder 구조로 되어있다. voting based, transformer based 방법론들과 비교했을 때, GSDN은 memory측면에서 더 효율적이고 large scenes에 대해서까지 확장할 수 있다.
GSDN의 주요 단점은 accuracy인데 sota 모델들에 비해 현저히 떨어진다고 한다. GSDN에서는 3d object bounding boxes의 anchor로 15개의 aspect ratios를 사용했는데, anchor-free로 학습한 경우 12%의 성능 하락을 보였다고 한다. 따라서 본 논문에서는 GSDN과 다르게 sparse 3d convolution을 활용함과 동시에 anchor-free방식으로 구성하였다.
rgb기반 2d object detection에서 anchor-free 방법론들은 anchor기반 이전 방법론들보다 좋은 개선들을 보였다. FCOS가 2d object detection에서의 anchor-free방식을 적용하였고 3d object detection에서도 FCOS를 조금 변형하여 사용한 FCOS3D, ImVoxelNet등이 존재한다. 본 논문에서도 위의 모델들에서 적용된 anchor free방식을 사용하여 sparse하고 irregular한 3d data를 처리하려고 하였다.
Proposed Method
FCAF3D는 Npts개의 RGB-color points을 입력으로 하여 3D object bounding boxes를 output으로 출력한다. FCAF3D의 architecture는 아래 Fig 2와 같이 backbone, neck, head로 구성된다.
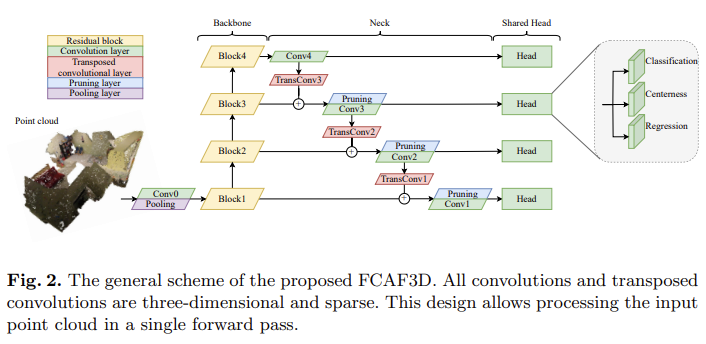
FCAF3D의 architecture를 design할 때 저자는 위에서 문제점으로 지적했던 scalability를 목표로 하기 때문에 GSDN과 같은 sparse convolutional network를 사용하였다. 그리고 더 나은 일반화를 위해 수동으로 조절해야하는 hyperparameters의 수를 줄였다. 특히 neck부분에서 sparse pruning을 단순화했다고 한다. 또한 multi-level location assignment를 가진 anchor-free head를 도입하였다. 마지막으로 기존 3D bounding box parametrizations의 한계를 극복하기 위한 새로운 parametrization을 제안하여 accuracy와 generalization ability를 높였다.
Sparse Neural Network
Backbone
FCAF3D의 backbone은 ResNet을 조금 변형하여 사용하는데, 모든 2D convolutions를 sparse 3D convolutions로 바꿔준다. 이렇게 바꿔준 backbone을 저자는 HDResNet으로 부르기로 한다. 여기서 sparse 3D convolution이 무엇인지 간단하게 설명하자면 0이 아닌 값을 가지는 data에 대해서만 convolution을 진행하는 방법이다. 0이 아닌 값을 가지는 부분이 output에 영향을 얼마나 미치는지 rule을 파악해서 해당 부분만 연산하는 방식이다.
Neck
Neck부분은 GSDN decoder를 단순화한 version을 사용한다. 아래 그림이 GSDN의 architecture이고 neck부분은 위의 Fig 2에 표현되어있다.
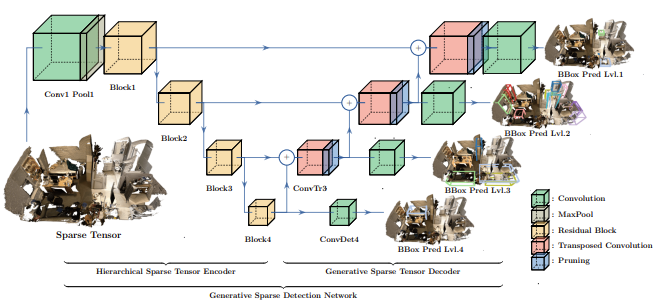
각 level에서의 features는 하나의 sparse transposed 3D convolution과 sparse 3D convolution을 통해 처리된다. transposed convolution에 대해서도 간단하게 설명하자면 padding, stride를 통해 정의되며 output에 대한 input을 만들어내기 위한 upsampling과정이라 생각하면 될 것 같다. 이게 무슨 뜻이냐면 일반적인 convolution과는 반대로 원본 input값을 되돌리는 것이 아니라 원본 차원만을 되돌려주는 것이다. 아래 그림을 보면 output에 대해 stride, padding에 따라 같은 차원의 input을 만들어내는 것이다. 예를 들어 output에 동일한 stride와 padding을 적용하면 input과 동일한 차원을 만들어 낼 것이다.
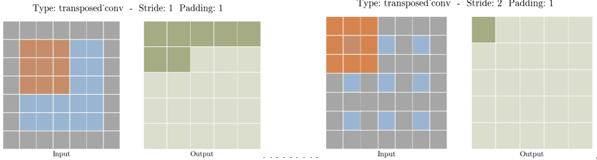
각각의 transposed 3D convolution의 kernel size가 2라고 하면 cubic한 구조를 가지기 때문에 한 번 연산을 통해 0이 아닌 값이 2^3=8배 증가할 수 있다. 이렇게 빠르게 증가하는 memory를 방지하기 위해 GSDN에서는 pruning layer를 사용하여 masking을 통해 input값을 filtering한다.
GSDN에서 feature level-wise 확률값은 추가적인 convolutional scoring layer를 통해 계산된다. 본 논문에서 제안하는 FCAF3D에서는 단순화를 위해 해당 scoring layer를 제거하고 대신에 뒤의 head에서 classification layer를 통해 얻은 확률값을 score로 사용한다. 기존에 GSDN에서는 voxel마다 confidence threshold를 이용해 sparsity pruning threshold보다 낮은 voxel을 제거했지만 본 논문에서는 sparsity pruning threshold를 조절하지 않고 input points(Npts)와 같은 갯수의 voxel 수(Nvox)를 유지한다.
Head
anchor가 없는 FCAF3D의 head는 feature level에서 sharing되는 weights를 가진 3개의 parallel한 sparse convolutional layer로 구성된다. 각 위치(x^, y^, z^)에서 classification probabilities(p^), bounding box regression parameters(δ), centerness(c^)를 각각 출력한다. 이러한 design은 FCOS모델의 head와 유사하다고 한다.
Multi-level location assignment
training 시 FCAF3D는 서로 다른 feauture levels마다 locations {(x^,y^,z^)}를 출력하며 gt boxes {b}에 assign된다. 본 논문에서는 dataset별로 hyperparameters를 tuning할 필요가 없는 sparse data에 대한 간단한 방식을 제안하였다. 각 bounding box마다 해당 bounding box가 최소 Nloc개의 locations를 포함하게되는 feature level을 선택한다. 만약 이 경우를 만족하는 feature level이 없으면 첫 번째 feature level을 선택한다. 또한 bounding box의 center 부근의 points들만 gt와 positive한 matching으로 간주하는 center sampling방식을 통해 location을 filtering하게된다. 이러한 과정을 통해 어떤 locations {(x^,y^,z^)}은 gt bounding boxes bx^,y^,z^와 matching될 것이다.
inference의 경우 classification score(p^)는 NMS 직전에 3d centerness(c^)과 곱해지게 된다.
Loss function
전체 loss function은 아래와 같다.

Npos : matching locations의 수 (∑x^,y^,zˆ 1{x^,y^,zˆ≠0})
Lcls : classification loss
Lreg : regression loss
Lcntr : centerness loss
loss function 수식은 간단하다. classification loss, regression loss, centerness loss를 합쳐 matching된 locations 수로 나누어준다. 수식에서 1{x^,y^,zˆ≠0}는 해당 location이 matching이 되었을 때 1, matching이 되지 않았을 때 0이 되는 값으로 matching된 location에 대해서만 bounding box regression loss와 centerness loss를 포함하여 계산하겠다는 뜻이다. YOLO에서 responsible에 해당하는 개념과 동일하다. classification loss는 focal loss를 사용하고 regression loss는 IoU를 사용하고 centerness loss는 binary cross-entropy loss를 사용한다. 참고로 hat(^)이 붙은 notation이 예측한 값들이다.
Bounding Box Parametrization
3d object bounding boxes는 axis-aligned(AABB)나 oriented(OBB)로 표현할 수 있다. AABB는 bAABB = (x, y, z, w, l, h)로 표현되며 OBB는 여기에 heading angle(θ)이 추가된 bOBB = (x, y, z, w, l, h, θ)형태로 표현된다. 두 수식의 parameters에서 x,y,z는 bounding box의 center 좌표값을 의미하고 w,l,h는 각각 width, length, height를 의미한다. 아래 그림은 순서대로 AABB, OBB이다.


AABB parametrization
gt AABB(x, y, z, w, l, h)와 location(x^,y^,z^)을 이용해 bounding box regression parameters(δ)는 아래와 같이 6개의 값을 가지는 tuple로 표현될 수 있다.
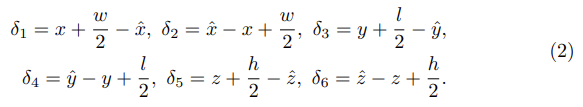
x에 대해 예시를 들어보면 아래 그림과 같이 표현되는 것이다.
예측되는 AABB인 b^는 δ로부터 얻을 수 있다.
Heading angle estimation
point cloud 기반의 모든 3d object detection sota 모델은 classification후에 regression을 통해 heading angle estimation을 하게된다. 이때 heading angle은 여러 bins로 classified되고 해당 bin 안에서 정확한 heading angle을 regression하게 된다.
먼저 indoor scenes의 경우 0에서 2π범위를 12개의 동일한 크기의 bins로 나눈다. outdoor scenes의 경우에는 보통 딱 2개의 bins만을 사용한다. 이때 2가지 bins는 road에 parallel한 경우와 수직하는 경우이다.
heading angle bin이 선택되면 heading angle value값은 regression을 통해 추정되는데 outdoor scenes의 경우 삼각법 등을 이용하여 추정하게 된다. 한편 indoor scenes의 경우에는 좀 더 복잡한데 object의 heading angle이 모호하다. outdoor의 경우 heading방향이 간단하고 명확하지만 아래 Fig 3에서 보면 indoor에 존재하는 사각형의 책상과 원형 테이블 같은 경우에는 어떤 방향이 heading angle이라고 명확히 말하기 어렵다.

이러한 경우에는 gt angle annotation이 random하게 설정되기 때문에 heading angle bin classification을 하는 것이 의미가 없다. 따라서 heading angle을 잘 예측했지만 gt와 일치하지 않는 경우 잘못 예측했다고 판단하는 경우가 존재할 수 있다. 이러한 경우를 방지하기 위해 본 논문에서는모든 heading angle에 대해 동일한 값을 가지는 rotated IoU loss를 사용한다.
그리고 본 논문에서는 rotation ambiguity를 고려한 새로운 OBB parametrization을 제안한다.
Proposed Mobius OBB parametrization
OBB parametrization은 rotation ambiguity를 고려한 매개화 방법이다. OBB parameters는 (x, y, z, w, l, h, θ)의 값을 가지는데 이때 q = w/l로 w와l의 비율로 정의한다. 그리고 x, y, z, w+l이 fixed한 값이라고 할 때 아래 4개는 같은 bounding box를 표현한다.

w+l이 고정된 크기이기 때문에 θ(0~2π)와 q(양의 값)에 관계없이 4개 표현은 같은 위상을 가지고 계속 같은 위상을 가진다는 의미를 Mobius strip(뫼비우스의 띠)에서 topologically equivalent하다고 표현하고 있다. Mobius strip을 생각해보면 시작점을 따라 쭉 진행하다보면 다시 시작점에 도달했을 때 반대 방향에 있을텐데 이처럼 반복하여 계속 같은 위상을 나타낸다는 것을 말하고 싶은 것 같다. 아래 수식 (4)는 수식 (3)의 4개 표현과 같은 points를 2차원 euclidean 공간의 Mobius strip으로 표현할 수 있다고 한다. 표현이 어렵게 되어있는 거 같은데 q와 θ에 관계없이 같은 위상을 가지는 관계를 만족하는 points를 찾는 task다 라고 이해하고 넘어갔다.

수식 (3)에서 4개의 표현이 결국 모두 같은 point를 다른 표현으로 사용한 것으로 결국 euclidean space에서 하나의 같은 point로 mapping된다는 것을 아래 식을 통해 알 수 있다.

그리고 실험적으로 수식 (4)에서 4개의 표현 성분을 모두 사용한 것보다 앞의 두 성분 값만 사용한 것이 더 좋은 성능을 보였다고 하여 두 값을 새로운 OBB parameter로 사용한다.
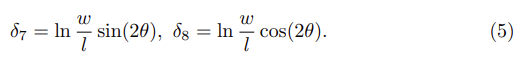
위의 수식 (2)를 통해 예측된 b^를 구할 수 있다고 했었고 w, l, θ는 아래와 같이 구할 수 있다.
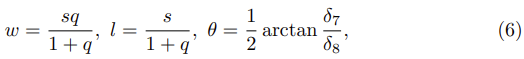
이때 ratio q(w/l) = e((δ7)2 + (δ8)2)1/2, size인 s = δ1 + δ2 + δ3 + δ4로 표현할 수 있다.
이러한 bounding box 매개화 방법은 anchor-free방식을 적용하기 위해 사용되었다.
Experiments
Dataset
본 논문에서는 ScanNet V2, SUN RGB-D, S3DIS 3개 dataset에 대해 실험을 진행하였다.
ScanNet V2는 18개 categories에 대해 1513개 object를 포함하는 3d indoor scan dataset이다. annotation은 모두 같은 방향을 나타내어 heading angle이 없는 AABB형태이다.
SUN RGB-D는 indoor rgb-d image로 구성되며 monocular 3d scene dataset이다. annotation은 heading angle을 포함하는 OBB형태이다. 총 37개 categories가 존재하지만 본 논문에서 실험을 할 때는 10개 categories에 대해서만 진행했다.
S3DIS는 Stanford Large-Scale 3D Indoor Spaces dataset의 줄임말로 6개 건물에서 272개 rooms에 대한 3d scan dataset이다. 본 논문에서는 5개의 furniture categories에 대해서만 평가를 진행했다. annotation은 heading angle을 포함하지 않는 AABB형태이다.
Hyperparameters
classification layer의 output size를 dataset마다 사용하는 class 갯수(18, 10, 5)로 변경하였다. 그리고 backbone은 위에서 언급했던 것 처럼 ResNet34를 sparse 3d로 수정한 HDResNet34라고 부르는 모델을 사용하였다. 그리고 voxel size는 0.01m로 했고 point 수(Npts)는 100,000개로 설정하였다. 따라서 voxel 갯수(Nvox)도 100,000로 동일하다.
Training
epoch가 8, 11일 때 learning rate decrease를 했고 initial learning rate는 0.001, weight decay는 0.0001로 하였다. batch size는 8로 학습하였다.
Evaluation
input point 수(Npts) 100,000개는 random하게 sampling하였고 학습과 실험은 각 모델에 대해 5번씩 진행했다.
Results
Comparison with State-of-the-art Methods
아래 Table 1에서는 본 논문에서 제안하는 FCAF3D 모델을 기존 3가지 3d indoor benchmark(scannet v2, sun rgb-d, s3dis)의 sota모델들과 비교해보았다.
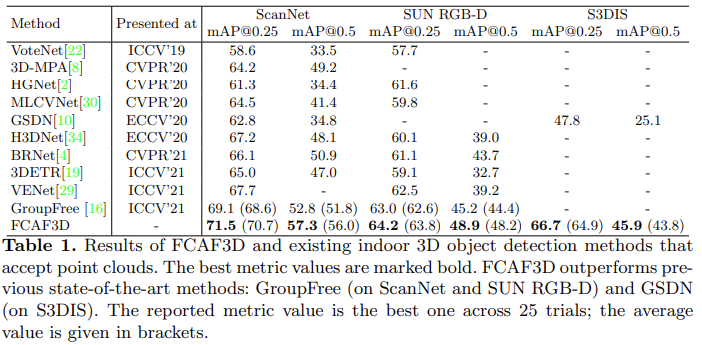
bold한 부분이 가장 좋은 성능인데 FCAF3D 모델이 다른 sota모델보다 모두 높은 성능을 보이는 것을 알 수 있다. 실험은 5번씩 진행하였는데 그 중 가장 좋은 성능을 표기하였고 brace안 값은 평균값을 의미한다. 각각의 dataset에서 예측한 bounding box를 아래 그림에서 ScanNet, SUN RGB-D, S3DIS 순으로 시각화해서 gt와 함께 보여주고 있다.

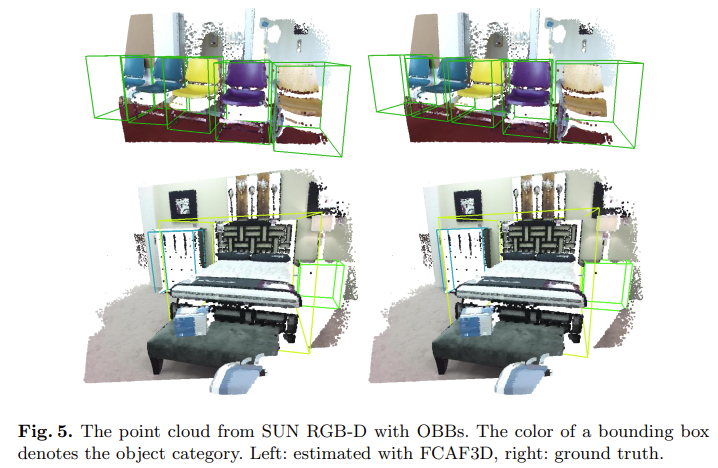

Fig 4,6은 bounding box가 AABB로 표현되는 형태이기 때문에 heading angle이 없어 bounding box가 모두 같은 방향을 가지는 것을 확인할 수 있다. 한편 Fig 5의 경우에는 bounding box가 OBB로 표현되기 때문에 bounding box의 heading 방향이 다른 것을 확인할 수 있다.
아래 Table 2에서는 VoteNet, ImVoteNet, ImVoxelNet에서 기존 parametrization을 바꿔 실험한 결과이다.

sin-cos param은 3d outdoor환경에서 3d object detection하는 모델인 SMOKE에서 사용한 parameterization방법이고 Mobius param이 본 논문에서 제안하는 OBB parametrization방법이다. IoU loss로 표시된 것은 본 논문에서 적용한 rotated IoU loss를 의미한다. 본 논문에서 제안하는 Mobius parametrization 형태가 가장 좋은 성능을 보이는 것을 알 수 있다. ImVoxelNet의 경우 rotated IoU loss가 적용되어 있어 따로 실험하지 않았다고 한다.
아래 Table 3에서는 3d convolution 방법론이자 FCAF3D의 neck부분에서 사용된 GSDN모델과 본 논문에서 제안하는 FCAF3D와의 비교 결과를 보여준다. 첫 행을 보면 두 모델이 서로 동일한 환경에서 실험한 결과인데 FCAF3D가 더 높은 정확도를 보이는 것을 확인할 수 있다.
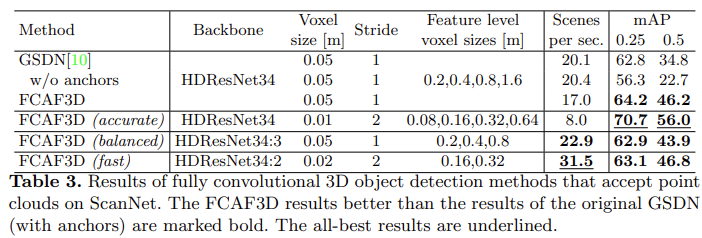
FCAF3D옆에 brace에 accurate, balanced, fast가 붙은 모델들이 있는데 직관적으로 받아들이면 된다. accurate는 성능이 가장 잘 나오도록 한 모델로 table에서 볼 수 있듯이 voxel size를 0.01로 줄이고 feature level voxel size도 작은 크기로 바꾸었다. 따라서 속도는 다른 모델에 비해 낮은 것을 확인할 수 있다. balanced의 경우에는 backbone에서 3개의 feature levels를 사용한 경량화 된 모델로 GSDN에 비해 속도와 정확도에서 모두 좋은 성능을 보인다. fast의 경우에는 feature levels를 2개로 줄여 속도를 빠르게 할 수 있었다. 한가지 눈여겨볼 점은 정확도도 balanced 모델보다 좋아졌다는 점이다.
아래 Table 4는 voxel size, point 수, centerness, center sampling에 대한 ablation study이다.
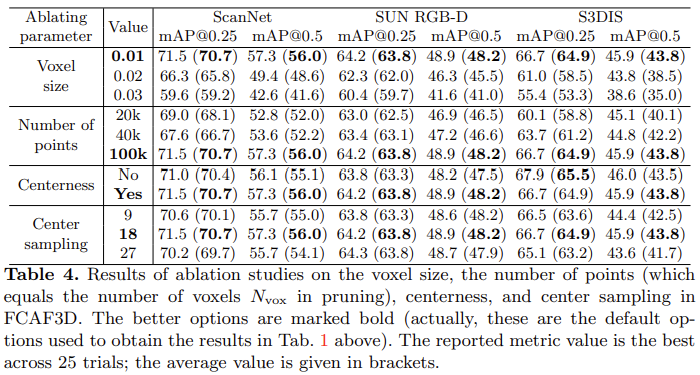
간단하게 살펴보자면 voxel size는 예상하는 것처럼 크기가 커질수록 accuracy가 줄어드는 것을 확인할 수 있다. 그렇지만 너무 작은 voxel size를 설정하면 inference 시간이 오래걸린다는 단점이 있다. points 수는 역시 마찬가지로 적어질수록 성능이 낮아지는 것을 확인할 수 있다. 이것은 2d image에서 비교하자면 subsampling과 같이 resolution이 작아지는 것과 비슷하다고 생각하면 이해가 쉬울 것이다. bounding box의 중심값을 나타내는 centerness도 함께 사용했을때 작지만 성능이 향상된 것을 확인할 수 있다. center sampling은 위에서 설명했던 것처럼 bounding box center로부터 몇 개의 주변 locations를 positive로 matching할 지 sampling하는 것인데 18개의 locations로 설정했을 때 가장 좋은 결과를 보인다.
아래 Fig 1에서는 inference time과 accuracy를 비교한 결과이다.

Conclusion
본 논문에서 제안하는 FCAF3D모델은 indoor환경에서의 fully convolutional anchor-free 3d object detection 방법론이다. ScanNet, SUN RGB-D, S3DIS에서 sota를 달성하였고 mAP와 inference time모두 좋은 성능을 보여주었다. 본 논문에서는 새로운 bounding box 매개화 방법 OBB를 제안하였고 성능 향상을 보임과 동시에 anchor-free방식으로 prior assumption을 하지 않아 hyperparameters의 수도 줄이는 효과를 가져왔다. 해당 모델은 point cloud를 기반으로 하며 3d object detection에 다양하게 적용될 수 있을 것 같다. SUN RGB-D에서 detect한 bounding box 결과를 끝으로 리뷰를 마치겠다.

좋은 리뷰 감사합니다.
몇 가지 이해가 안가는 부분이 있어 질문 드리고자 합니다.
1. Transpose 3d convolution이 deconvolution과 다르게 원래 차원으로만 되돌려 놓는다고 하셨습니다. 근데 deconvolution도 원본 input 값으로 되돌려 놓는 연산은 아니며, 또다른 명칭이 transpose convolution라고 불리우는 것처럼 차원만 원본으로 되돌려 놓는 연산이기도 합니다. 제가 알고 있는 지식과는 다른 의미에서의 연산을 수행하는지 궁금합니다.
2. AABB parametrization
해당 기법이 익숙하지가 않아서 조금더 자세한 설명이 있으면 좋겠습니다.
2-1. 각 축에 대한 높낮이를 더하는 것이 무슨 의미가 있는지 모르겠습니다.
2-2. 예측값과 GT 값 간의 비율을 보는 것 같은데 무엇을 위해 수행하는지 궁금합니다. 수식 2에서 hat이 붙은 값들이 예측값 같은데 이미 예측값을 추론하고나서 나서 비율을 구하는 이유가 뭘까요??
3. [minor] pruning layer는 처음 들어봐서 뭔지 궁금하네요…
댓글 감사합니다.
1. 우선 다시 확인해보니 convolution이라고 적는다는 걸 deconvolution이라고 잘못 적은 것 같습니다. transpose convolution이 여러 표현으로 사용되어 새로운 방식이라고 생각하실 수도 있어서 convolution의 반대과정인 deconvolution이라고 한다는 것을 생각하다가 잘못 적었네요…ㅎ하 수정했습니다.
2. 저도 anchor based방법에 익숙했고 AABB 표현은 처음 접해서 조금 더 찾아보았습니다.
2-1. 우선 해당 parametrization은 ImVoxelNet, FCOS에서 사용한 매개화 방식을 사용한 것으로 center point로 부터 anchor box의 edge까지 거리를 표현합니다. 보통 anchor box로부터 4개(x,y,w,h)의 offset에 대해 regression하는 방식인데 AABB는 point로부터 거리(distance)를 regression하는 방식이라고 합니다. 표현법의 차이이고 “Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection”이라는 논문에서는 두 방법을 사용했을 때 성능에 본질적인 차이는 없다고 합니다.
2-2. 음… 본 논문에서 해당 내용에 대한 언급은 없고, 다른 reference의 anchor-free방식 논문에도 자세히 설명한 내용은 못찾았네요. 아마 예측한 후 AABB방식으로의 변환을 위해 box regression parameter δ로 표현하기 위함이라고 생각했습니다.
3. pruning layer는 FCAF3d의 neck부분에 사용된 GSDN에서 사용된 layer로 transpose conv를 통과한 각 voxel마다 일정 pruning confiendce threshold보다 낮은 voxel에 masking을 하여 pruning하는 것 입니다.
좋은 리뷰 감사합니다.
3D object detection에서 scalability 문제란 무엇인가요?? 데이터 특성상 연산량이 너무 커서 넓은 범위를 보기 어렵다는 문제로 이해하였는데 제대로 이해한 것이 맞나요??
또한, transposed convolution이 잘 이해가 가지 않는 데 다시 설명해주실 수 있나요?? 입력을 복원하는 것이 아닌, 동일한 크기의 output을 만들어내는 것이 목표라고 이해하였는데, 그렇다면 해당 부분에 나와있는 그림은 어떻게 이해하면 되나요?? output의 진한 부분은 input 레이어에서 어떻게 작동하여 얻어진 것인지 설명해주시면 감사겠습니다..
랜덤하게 설정된 gt angle에 의해 발생하는 문제를 해결하고자 heading angle에는 동일한 값을 가지는 IoU를 사용한다고 하셨는데, IoU를 angle의 오차를 계산하는 방식이라 상당히 좋은 아이디어인 것 같습니다. 그러나 IoU자체가 방향에 관여하는 오차 정보를 주기는 어렵지 않을까 하는 생각도 드는데, 이에 대해 어떻게 생각하시나요??
또한, 전체적인 리뷰를 통해 AABB에 비해 OBB방식이 객체를 더 잘 이해하는 방식이라 생각하였습니다. 그런데 IoU를 이용하는 방식은 방향에 대한 정보를 주는 것이 아니라 OBB에 마이너스의 영향을 주지는 않을까 하는 생각이 듭니다. 이에 대한 실험 결과나 보완 방법은 없었는지 궁금합니다.
댓글 감사합니다.
scalability란 말씀하신 내용이 맞습니다. 3d convolution 연산을 보면 연산량이 클 수 밖에 없을 것입니다.
transposed convolution에 대해서 위에서 말씀드린 것과 같이 제가 convolution이라고 해야하는 것을deconvolution이라고 해서 오해가 있었네요. convolution의 반대 과정인 upsampling하는 과정으로 이해하시면 될 것 같습니다. convolution과 동일하게 padding과 stride로 정의되며 input에 대해 stride와 padding을 적용하여 연산하게 됩니다. 오른쪽의 경우 stride가 2이므로 input 간격을 2로 하고 padding을 1로 하여 원하는 output의 크기를 얻어낼 수 있습니다.
heading angle을 고려한 rotated IoU의 경우 논문과 코드를 확인했을 때 작동원리를 보면 이해할 수 있습니다. gt box와 anchor box가 있을 때 z축으로만 각도 변화를 추정하고 x,y에 대한 iou를 구한 후, 두 박스의 합집합 영역에 대한 교집합 영역으로 angle의 정도를 추정합니다. 따라서 align이 맞지 않는 경우 괜찮은 오차 정보를 제공할 수 있다고 생각합니다.
AABB와 OBB의 bbox 매개화 표현 방식은 angle을 포함하는지 여부에 따라 달라집니다. Table 2에서 iou를 포함한 결과가 더 좋은 결과를 보이고 있습니다. heading angle에 따라 object의 방향의 align을 맞춰주는 방향으로 loss가 감소되기 때문에 이러한 결과를 보인 것 같습니다. 추가 보완 방법에 대한 reporting은 없습니다.