Introduction
기존에 사용되던 Convolution 기반 object detection모델은 anchor-based인 경우가 많았으며, 그 예로는 R-CNN. SSD, YOLO있었다고 합니다. anchor-based 방법론은 물체가 있을 법하거나, 물체의 형태를 나타내는 다양한 형태의 박스인 anchor box를 사용합니다. 그러나 저자는 이러한 앵커 박스에 두 가지 단점이 존재함을 주장하였습니다.
- large set의 box가 필요함
detector의 학습은 잘 아시다시피 anchor box와 GT와 얼마나 겹치는지 IoU를 통해 판단하고, GT와 겹치는 box들을 positive sample로 하여 학습에 사용합니다. 이때 모든 GT에 대응하는 충분한 개수의 sample을 확보하기 위해 영상 전체에 많은 수의 box를 뿌리게 됩니다. 이로인해 positive, negative sample의 불균형이 발생하고 학습이 느려진다는 단점도 있습니다. - 많은 hyperparameter와 design choice
박스의 개수, scale, aspect ratio등 box에 관한 하이퍼파라미터를 사용자가 사전에 설정해 줘야 합니다. 만일 이를 multiscale architecture에서 사용하는 경우, 각 scale에 따라 설정해줘야 하는 값이 발생합니다. SSD를 예로 들자면 각 feature map에서 몇 개의 박스를 뽑을 지 결정하는 추가적인 변수가 존재한다는 것을 생각하시면 될 것 같습니다. 이렇듯 하이퍼파라미터가 많아지므로 모델의 설계가 복잡해진다는 단점이 있습니다.
이러한 배경에서, 저자들은 CornerNet을 제안하였습니다. CornerNet은 anchor-free방식의 one-stage detector로, [그림1]의 오른쪽 이미지와 같이 물채의 좌상단과 우하단 모서리를 한 쌍으로 검출하여 detection을 수행합니다.
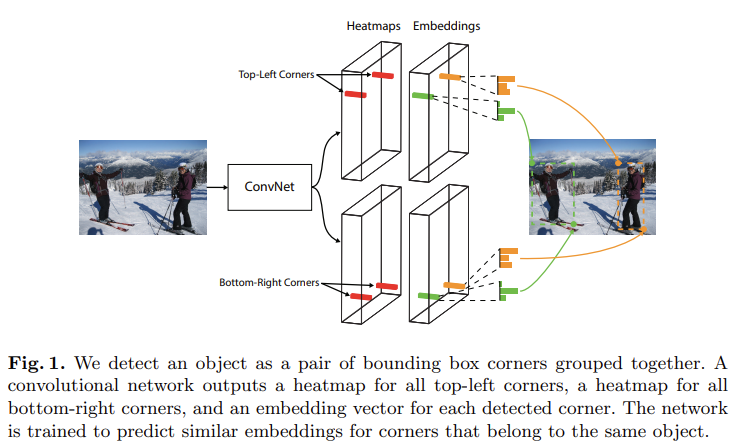
CornerNet은 단일 CNN을 사용하여 좌상단과 우하단의 corner를 검출하는 heatmap을 각각 예측하고, 동일한 object를 나타내는 corner들을 grouping하는 embedding을 진행하여 물채를 검출합니다. 이러한 방식은 default box를 사용하지 않아 위의 단점이 드러나지 않는다고 합니다.

CornerNet에서는 두 keypoint를 검출하는데, [그림2]와 같이 object 외부에 존재하는 point는 local feature로는 검출하기 여럽습니다. 이를 위해 저자들은 corner pooling이라는 방법을 제안하였는데 자세한 설명은 아래에서 하도록 하겠습니다.
CornetNet
Overview
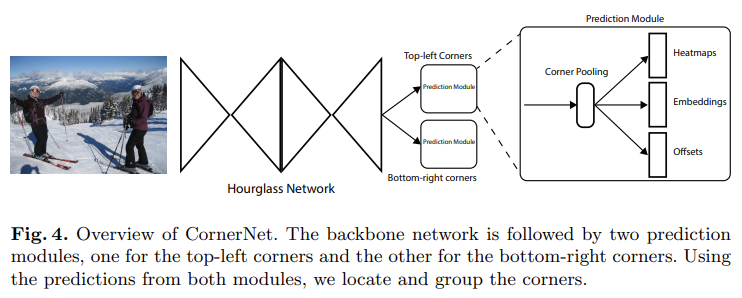
[그림 4]는 CornerNet의 개요를 나타내며 보시는 바와 같이 Hourglass Network를 backbone으로 사용하였고, 그 뒤로는 각 corner를 예측하는 두 개의 prediction module을 사용하였습니다. 각 prediction module에서는 corner pooling을 사용하여 heatmap, embedding, offset을 예측합니다.
Detecting Corners
CornerNet은 left-top과 right-bottom을 의미하는 heatmap 두 세트를 예측합니다. 이때 각 heatmap은 H\times W\times C의 크기를 가지며 채널 수인 C는 category의 개수를 의미합니다. 각 채널은 해당 클래스의 코너 위치를 나타내는 binary mask를 의미합니다. 또한 각 corner 는 GT에 해당하는 하나의 positive location을 가지고, 다른 모든 location은 negative로 취급합니다.
p_{cij}를 prediction heatmap 클래스 c에 대한 위치 (i,j)의 점수이고, y_{cij}가 Gaussian으로 조정된 GT의 heatmap일 때, 저자가 사용한 focal loss는 [식1]과 같습니다.
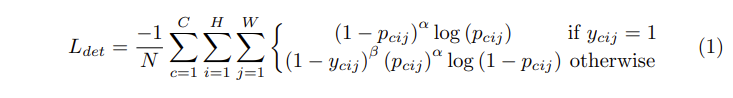
이때 N은 한 이미지에 존재하는 object 수, \alpha와 \beta는 각 점의 기여를 제어하는 하이퍼파라미터입니다. 이후에 진행하는 모든 실험에서는 \alpha를 2로, \beta를 4로 설정하였습니다. Gaussian bump가 y_{cij}로 인코딩된 경우 (1-y_{cij})를 통해 GT 주변의 패널티를 줄였다고 합니다.
예측에 사용되는 heatmap은 conv의 출력값으로 입력 이미지를 downsampling하여 생성됩니다. 이후에 heatmap에서 input image scale로 위치를 매핑할 때, 소실되는 정보로 인해 정확한 위치를 찾을 수 없고 이로 인해 GT와 bounding box간의 IoU에 영향을 미칠 수 있습니다. 이러한 문제를 해결하기 위해 저자들은 [식2]와 같은 location offset을 예측하였습니다.
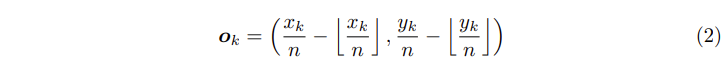
[식2]에서 o_k는 offset, x_k와 y_k는 corner k에 대한 x와 y 좌표입니다.
학습 시, 예측된 offset o_k 와 gt location \hat o_k 사이의 offset loss로는 smooth L1 loss를 사용하였습니다.

Grouping Corners
한 이미지에 여러 물체가 있는 경우, 여러 개의 corner가 검출될 수 있습니다. 이때 검출된 top-left와 right-bottom corner가 동일한 box에 속하도록 해야 합니다. 이에 저자들은 pose estimation에서 사용하는 Associative Embedding을 통해 각 corner의 embedding vector를 생성하고 같은 박스에 속하는 경우 벡터 간의 거리가 작아지도록 학습하였습니다.
e_{t_k}가 object k의 좌상단 corner에 대한 embedding, e_{b_k}가 우하단의 corner에 대한 embedding일 때, 같은 box에 속하도록 두 corner를 가까워지게 하는 pull Loss와 두 corner를 멀어지게 하는 push Loss를 사용하였습니다. 식으로 나타내면 아래의 [식 4, 5]와 같습니다.
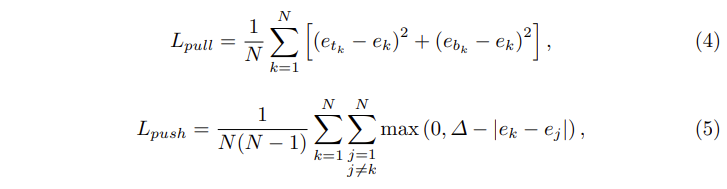
e_k는 e_{t_k}와 e_{b_k}의 평균이고 Δ는 모든 실험에서 1로 설정하였다고 합니다.
Corner Pooling
[그림2]를 다시 가져와봤는데요, 위의 그림과 같이 corner와 물체가 멀리 떨어져 있는 경우 corner를 찾을 local visual evidence가 부족하게 됩니다. 쉽게 말하자면 해당 점을 keypoint로 검출하기 위한 local feature가 부족하다는 의미로, 이러한 문제를 해결하기 위해 저자들은 corner pooling이라는 방법을 사용하였습니다.
Corner Pooling은 corner에서 수직, 수평 방향으로의 연장선이 object와 만나는 지점을 확인하는 방식으로 진행됩니다.
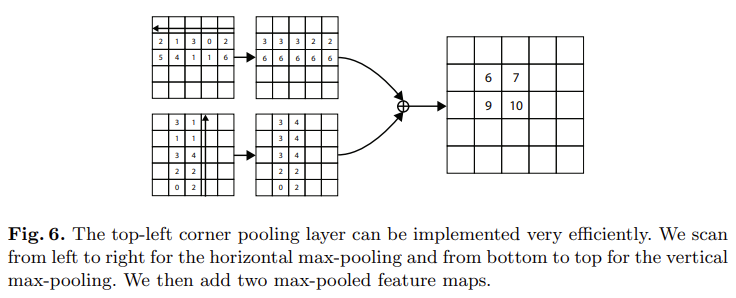
[그림6]은 corner pooling을 나타내고 있는데, 위의 그림은 수평 방향으로, 아래의 그림은 수직 방향으로 corner pooling을 진행하는 것을 나타내고 있습니다. input feature의 (i,j)픽셀에서corner pooling을 수행하는 과정은 다음과 같습니다. f_t와 f_l을 pooling layer의 입력된 feature map이라 하고, f_{t_{ij}와 f_{l_{ij}을 각각 f_t와 f_l의 위치 (i,j)를 나타냅니다. H\times W 크기의 feature map을 사용하였을 때, f_t에서 (i,j)와 (i,H) 사이의 모든 feature를 특징 벡터 t_{ij}에 max pooling하고 f_l에서 (i,j)와 (W,j) 사이의 모든 feature를 l_{ij}에 pooling합니다. 마지막으로 t_{ij}와 l_{ij}결과값인 t와 l을 elementwise 연산해주면 하나의 corner pooling 연산이 완료됩니다.
top 방향, left방향으로의 연산을 식으로 나타내면 [식 6, 7]과 같이 나타낼 수 있습니다. Right-bottom의 경우 right, bottom 방향으로 동일하게 진행해 주면 됩니다.
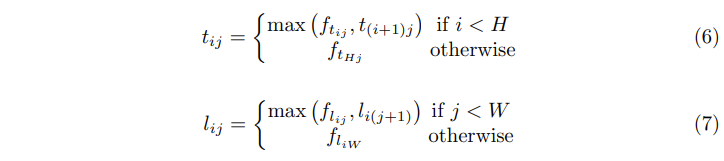
Experiments
Ablation Study
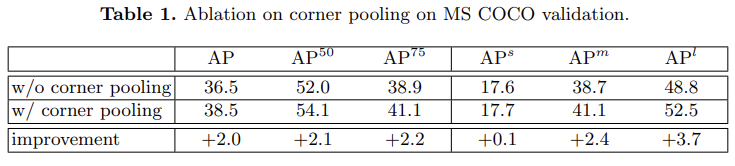
corner pooling의 유뮤에 따른 성능은 [표1]과 같이 나타납니다. 전체적으로 성능이 향상된 것을 볼 수 있는데 특히 large object에서의 성능 향상이 이루어졌습니다. small에 비해 Large object에서 bounding box의 corner가 물체와 멀리 떨어진 경우가 많기 때문일 것으로 생각됩니다.
Comparisons with state-of-the-art detectors
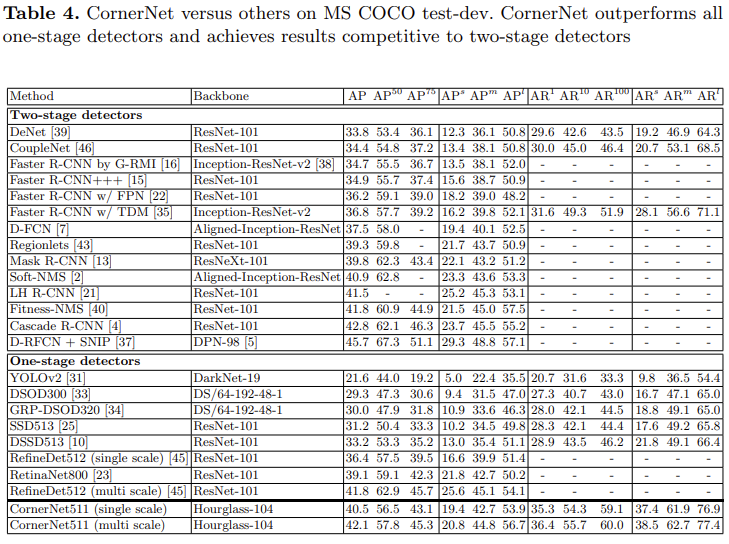
기존 sota 모델들과의 성능을 비교한 결과입니다. 1-stage detector와 비교했을 때 CornerNet이 비교적 좋은 성능을 내는 것을 확인할 수는 있으나, 1-stage의 이점인 속도 면에서의 비교가 없어 아쉽습니다.

좋은 리뷰 감사합니다.
Corner grouping 과정에서 corner들이 같은 박스에 속한다면 해당 corner의 임베딩끼리 가까워지도록 학습한다고 하셨는데, 한 이미지에 찍힌 여러 개의 corner 쌍 중 어떤 corner 쌍이 같은 박스에 속하는지는 어떻게 판단하나요?
그리고 해당 임베딩은 Associative Embedding 기법을 따라 생성된다고 하셨는데, 이것이 어떤 과정을 의미하는지, corner에 대한 어떤 정보를 담은 feature로 임베딩 되는 것인지도 궁금합니다.
댓글 감사합니다.
두 질문에 대한 답변을 드리기 전에 우선 Associative Embedding이 무엇인지부터 설명해야 할 것 같은데요, Associative Embedding은 human pose estimation의 keypoint detection에 사용되는 기법입니다. 간단하게 이야기하자면 embedding은 하나의 keypoint당 하나의 값으로 나타나며, 동일한 human의 keypoint는 동일한 값을 갖습니다. 자세한 설명은 해당 링크를 참고하시면 될 것 같습니다.
이때 GT로 주어진 bbox의 tl, br를 한 박스의 gt라고 한다면 예측된 keypoint 중 gt와 매칭된 두 keypoint의 임베딩 값이 동일해지도록 학습을 진행해줍니다.
리뷰 감사합니다.
우선적으로, 물어보고 싶은 점이 있어 글을 읽으며 댓글을 달게 되었습니다.
1. 리뷰 중 Anchor-based 방법론의 단점으로 “이때 모든 GT에 대응하는 충분한 개수의 sample을 확보하기 위해 영상 전체에 많은 수의 box를 뿌리게 됩니다.”라고 말씀해주셨는데, 이는 저자의 견해였나요?
왜냐하면, 영상 전체에 많은 수의 box를 뿌린다는 것은 사실 우리는 Object가 어디있는지 모른채, GT에 대응하는 bbox를 놓치지 않고 하나라도 맞춰보고자하기 위해서라고 생각했는데, 해당 내용은 GT가 하나 있을 때, 그 GT에 대응하는 Sample이 많을 수록 좋다는 의견처럼 들려서, 그렇다면 NMS를 하는 과정과는 상충되지 않나?라고 생각이 들었습니다. 그렇기에 해당 내용에 대해 다시 설명해주신다면 감사합니다.
2. 두번째는 Corner Pooling이 이해가 되질 않아 질문드리게 되었습니다. Max pooling이 어떻게 구성되는지, 왜냐하면 Fig. 6을 살펴보면 가로축 방향으로는 모두 같은 값으로 되는 반면, 세로축 방향으로 진행 시에는 밑에 2 2 | 0 2로 남아있어서.. 해당 리뷰를 읽으며 혜원 연구원님이 말씀해주신 것과 같이 그리고 저자의 견해처럼 Corner는 Local Feature로써 사용될 Confidence가 낮을텐데, 즉 Feature로 쓰이기에는 정보가 부족할텐데 Corner를 어떻게 찾지?하고 보다 보니 Corner Pooling에서 Max pooling을 통해 object 위치에 해당하는 Corner 점들은 Object를 포함함과 동시에 Background가 있을테니, 세로축 한번, 가로축 한번 하면 교집합 지점을 찾을 수 있곘구나했는데, 해당 내용도 비슷한 것 같긴 한데 정확히는 Max pooling 과정에 이해가 가질 않아 설명해주시면 감사하겠습니다.
3. 사실 해당 방법론은 그렇다면 이미지 내 Object가 단일이 아닌 여러 Object가 있는 경우, 예를 들면 COCO Dataset에서의 성능이 리포팅되어있긴한데 저자의 다른 견해가 있을까요? Corner Pooling 과정에서 조금 더 생각해보면 물체가 여러 개 있을때는 Max pooling이 오히려 방해가 될 것 같은데.. 이에 대해 저자의 다른 견해가 있는지 등등이 궁금합니다.
1. 제가 표현을 조금 애매하게 쓴 듯 하네요 원 글의 의미는 상인님께서 말씀하신 것 처럼 GT에 대응하는 박스가 없는 경우가 없도록 하기 위해, 즉 object의 위치를 모르므로 box를 gt에 대응시키기 위해 많은 박스를 사용하였다는 의미입니다.
2. 그림 6에 나타난 top-left prediction module의 corner pooling 과정을 예로 들어 설명 드리겠습니다. 이제 아래에서 top 방향으로 진행하면서 max 값을 전이하는 것으로 처음에 0값과 그 위에 있는 2를 비교하여 0은 위로 전이되지 않고, 그 다음 단계에서 2와 3을 비교합니다. 이 경우에도 3이 더 크므로 전이가 일어나지 않습니다. 다음으로는 3과 1을 비교하는데 이 경우에는 3이 이전에 나온 값 중 최대값에 해당하므로 해당 위치(원래 1이 있던 자리)의 값을 3으로 변형합니다. [그림2]의 두 번째 피자 그림과 연관지어 다시 설명드리자면 아래에서 위로 진행하다가 물체(피자의 도우 부분의 feature)를 만났을 때 그 값이 위쪽으로 계속 전이되는 것입니다.
3. 일단 이론적으로는 한 이미지의 동일한 객체가 여러 개 존재해도 detection이 가능하긴 합니다만… 해당 논문의 discussion에서 occlusion문제가 앞으로 저자가 해결해야 할 문제임을 언급하고 있습니다.
좋은 리뷰 감사합니다.
table 4에 평가지표 AR은 무엇을 의미하는 건가요? 또한 AR^10일 때와 AR^100일 때 ConerNet이 다른 모델에 비해서 성능이 압도적으로 높은 듯 한데 왜 높은지 혜원님께서 어떻게 생각하시는지 궁금합니다.
감사합니다.
AR은 Average Recall을 의미합니다.
AR 1/10/100 confidence가 높은 것을 기준으로 내림차순 정렬했을때 가장 score가 높은 1개/10개/100개의 bounding box를 이용해서 측정한 Average Recall 값을 의미합니다.
좋은 리뷰 감사합니다.
Coner Pooling 설명을 시작하는 부분에서 “쉽게 말하자면 해당 점을 keypoint로 검출하기 위한 local feature가 부족하다는 의미로~ “ 라고 해주셨는데, 해당 내용을 convolution 을 통한 feature extraction 과정 중에 대한 문제점으로 인해 corner pooling 방법을 사용했다고 이해해도 되는지 궁금합니다.
감사합니다.
‘convolution을 통한 feature extraction 과정 중에 대한 문제점’이라는 표현이 잘 와닫지 않지만 해당 내용을 ‘convolution을 통해 feature extraction을 진행했을 때, local한 정보에 비해 global한 정보를 고려하지 못한다는 문제점’으로 생각한다면 global pooling의 사용 이유로 생각할 수 있을 것 같습니다.
좋은 리뷰 감사합니다.
혹시 corner를 grouping할 때 어떤 left top과 right bottom corner가 매치되는지 어떻게 확인하나요? 그리고 occlusion이 있는 경우 해당 corner가 어떤 object의 corner인지는 어떻게 고려해주나요?