안녕하세요. 아홉 번째 X-Review입니다. 지난 2-3주에 걸쳐 DETR과 Deformable DETR을 리뷰하고, 이번에는 Small object detection을 위한 방법론을 들고 왔습니다. 아마 한전 3차년도 정량적 결과를 위한 주된 방법론으로 사용될 것으로 보입니다. 이미 김태주 연구원께서 해당 논문을 리뷰하신적이 있는데, 이해가 안되는 부분에 대해서는 김태주 연구원의 리뷰도 같이 참고해주시면 좋을 것 같습니다. 그럼 시작하겠습니다.
Introduction
서두에서 Small object detction을 위한 방법론이라고 말을 했는데, 그렇다면 기존의 방법론들은 어떠한 방식으로 해당 문제를 해결하고자 했는지를 먼저 살펴보겠습니다. 가장 잘 알려진 방법으로는 High-resolution Feature map을 사용하는 것입니다. 대표적으로 FPN이 있으며, 다들 잘 아시듯이 FPN은 Small object를 위해 고차원의, Semantic한 정보를 갖는 Row-resolution Feature map을 High-resolution Feature map에 더해주는 방식으로 Feature map Resolution과 해당 Feature map이 갖는 Semantic Features 간의 Trade-off 관계를 보정해주는 역할을 합니다. 하지만 해당 방법론들은 연산량이 Image size에 비례하도록 커지는 문제점이 있으며, Computational cost가 높아 Inference 시에도 좋은 FPS를 보이지 못합니다.
또 다른 방법 중 하나는 단순히 Input image size를 늘리는 것으로, SSD를 생각해보면 SSD320보다 SSD500의 성능이 더 좋은 것은, Multi-scale Feature map을 뽑는 Conv4_3, Conv_5 등등에서 Feature map의 Resolution이 320보다 크기에 기인했다고도 볼 수 있습니다. 당연한 말들이였지만, 여태는 어쩔 수 없는 부분이다, 혹은 둘 사이의 적절한 조합으로 최저고하 시켜보자는 몇몇의 노력에 그쳤습니다. 따라서 QuerydDet은 이러한 문제점을 해결하고자 CSA(Cascade Sparse Query)라는 방식을 가져오게 됩니다. 어떠한 방식인지는.. 아래에서 다시 살펴보겠습니다.
우선, 우리는 현재까지의 Detection에서의 SOTA 모델 중 하나인 RetinaNet을 살펴볼 필요가 있습니다. QueryDet이 RetinaNet을 베이스로 하기 때문인데, RetinaNet은 COCO 데이터 셋에서 AP_M 과 AP_L 에서는 각각 44.1과 51.2의 mAP를 보이는 반면, AP_S 에서는 24.1로, 굉장히 낮은 수치를 보입니다. 저자는 이러한 이유에 대해 다음과 같이 분석합니다.
- 앞서 말씀드린 것 처럼, Backbone으로 사용되는 CNN이 진행됨에 따라, down-sampling으로 인하여 small object는 좋은 Weight을 얻지 못합니다. 좋은 Weight을 얻지 못한다는 것은 Object가 아닌 Background로 분류된다고 봐주시면 됩니다. 그 이유로는 쉽게 우리가 생각했을 때 down-sampling을 거친 이후 CNN 마지막 레이어에서 어느 한 지점을 찍은 이후 그 지점의 Receptive field를 고려하여 이미지에서 생각해보면, Receptive field가 넓어 Object가 있는 부분보다 배경이 더 많은 부분을 차지하게 됩니다. 저자는 이를 배경에 의해 object가 오염된다고 표현합니다.
- IoU의 함정이라고 볼 수 있는데, Small object는 predict bbox가 조금만 벗어나더라도, IoU의 차이가 굉장히 심해집니다. 사실 이러한 부분도 큰 문제라고 볼 수 있죠. 큰 물체는 꽤 많이 달라보여도 IoU > 0.5를 만족시키는 것에 비해서, 작은 물체는 조금만 달라져도 IoU가 크게 낮아지기 때문입니다. 이러한 문제는.. GIoU, DIoU 등 다양한 관점에서 분석되고 있긴 하지만, 아직은 Saturation 되지는 않은 것으로 보입니다. (사실 해당 점이 문제점이라는 것이지, 해당 논문에서는 이를 고치겠다! 하지는 않습니다.)
그러면 앞서 말한 FPN 방식을 사용한다면.. 당연히 성능적인 측면에서는 개선이 일어납니다. 하지만 앞서 말씀드린 것과 같인 Computation cost가 문제가 됩니다. 그래도 단순히 Image size를 늘려 Feature map의 Resolution을 확보하는 것 보다 FPN 방식은 Feature map 간의 up-down-sampling을 통해 High-resolution Feature map에서 Row-resolution Feature map의 정보를 보완하는 방식을 사용한다고는 하지만, 예를 들어 RetinaNet에서 Pyramid 레벨 2, P_2 를 Detection head에 추가할 경우, FLOPs 및 Memory cost가 이전 대비 300% 증가한다고 합니다. Small object detection 성능과 Computational cost 간의 Trade-off는 어쩔 수 없는 것 처럼 보입니다. Computational cost의 증가로 인하여, 13.6 FPS에서 4.85 FPS로 속도 측면에서 굉장히 느려지기도 하네요..
따라서 저자는 이러한 문제점을 해결하고자, 즉 Small obejct detection의 성능을 개선함과 동시에 Computational cost를 최대한 줄이고자 QueryDet이라는 방법을 제안합니다. QueryDet은 아래의 두 가지 핵심 동기를 통해 소개됩니다.
- Low-level Feature에 대한 연산은 상당히 중복적입니다. Small object에 대한 Spatial distribution, 즉 Feature map 내에서 공간적으로 차지하는 부분이 크지 않고 희소하기 때문에, High-resolution Feature map에서는 차지하는 부분이 더욱이 작습니다. 이를 다시 말하자면, High-resolution Feature map, 즉 Low-level feature에서의 연산량은 많은데, Small object는 이 때의 연산에서 차지하는 비중이 적을 수 밖에 없습니다. Low-level과 Low-resolution은 상반되는 용어이니, 헷갈리지 않으면 이해가 쉽게 될 것으로 생각됩니다.
- FPN은 고도화된 구조를 가지고 있습니다. Highly structured라고 표현되어 있는데, 이는 다른 말로 High-level Feature map인 Low-level Feature map에서 Small object의 정확한 위치를 찾을 수는 없지만, 이 쯤에 있지 않을까?하는 대략적인 위치에 대해서는 꽤나 높은 신뢰도를 가지고 있습니다. 즉, 예를들어 원래 Feature map이 고도화되며 13×13 Feature map에서 256×256 Feature map에서의 Small object에 대한 위치를 알 수 없는 것이 원래는 맞습니다. Receptive Field는 넓은데, 해당 Grid 내 정확한 위치는 알 수 없지만, FPN에서는 High-level feature map과 Low-level feature map을 더하는 연산을 하기 때문에 어느 정도 위치를 대략 짐작할 수는 있다는 말이겠죠.
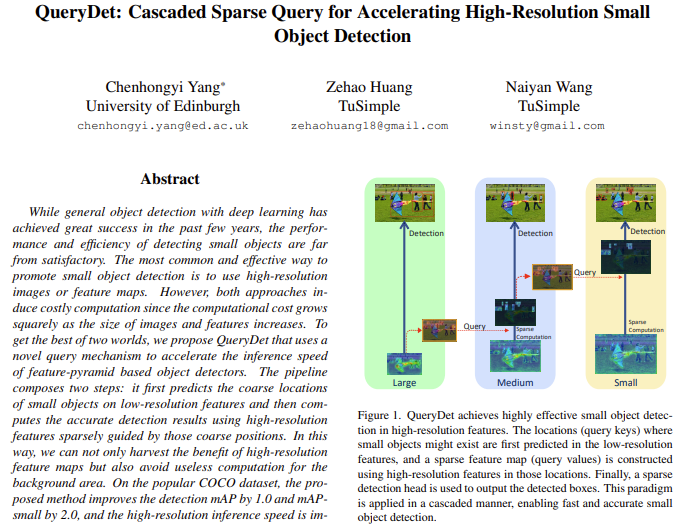
그렇다면 먼저 QueryDet의 핵심 아이디어에 대해 말해보겠습니다. 저자는 Figure 1.에서와 같이 Query를 토대로 Sparse Computation을 하는 새로운 하나의 Head를 만듭니다. Head라는 것은 Detection Head 에서의 Head와 같은 의미로, Small object에 대한 대략적인 위치를 Low-resolution Feature map (High-level Features)에서 재귀적으로 예측합니다. 예측하는 Head를 통해 High-resolution Feature map에서는 Small object에 대한 효율적인 연산 및 Attention을 할 수 있습니다. 이러한 방식이 결국 계단식이라고 표현하며 Cascade라는 단어를 사용합니다. 추가적으로 저자는 계산의 효율성을 위해 Sparse convolution을 도입합니다. 이러한 이유는 당연히도, Query(여기서는 Small object를 Query로 표현합니다)는 전체 Feature map에서 차지하는 부분이 상당히 작기 때문에, 해당 Query에 대해서만 연산을 진행하는 것이 연산량 측면에서 이득이라고 할 수 있습니다.
Methods
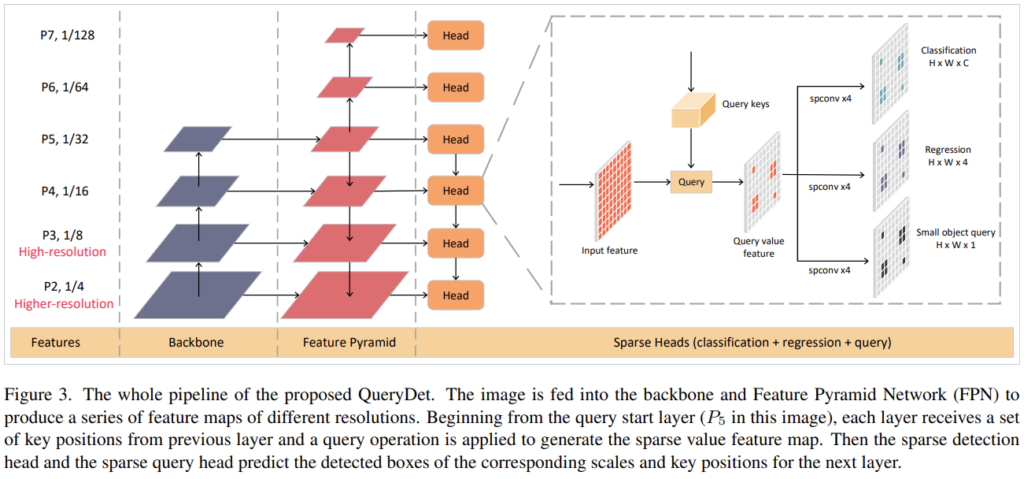
QueryDet은 하나의 아이디어를 기반으로 하기에, 실제로는 1-stage, 2-stage, End-to-End Detector (DETR 기반 방법론)에 상관없이 적용할 수 있습니다. 이 중 논문에서는 당시 SOTA 모델 중 하나였던 RetinaNet을 기반으로 설명합니다.
Related Work에 대해서는 따로 언급을 안했는데, 그 이유 중 하나는 RetinaNet에 대한 설명이 주를 이루기 때문입니다. RetinaNet에서 하나만 다시 살펴보자면, Figure 3의 P_1, P_2, ..., P_7 을 Feature Pyramid의 각 Feature map이라고 할 때, P_2 는 P_3 에 비해 더 높은 Resolution (Higher-resolution)의 Feature map에 해당합니다. 이러한 CNN Backbone에서 FPN 구조로 P_5 에서 Down sampling을 통해 Detection Head로 이어지게 됩니다. 각 Head에서는 원본 Resolution Feature map에서 Low-resolution, High-level Feature map의 정보들이 더해집니다. 이 때 오른쪽에서 Input Feature에서 Query Keys들이 보일텐데, 이것이 바로 QueryDet에서 제안하는 Small object에 대한 정보를 갖는 하나의 Feature map입니다. Query가 더해진 Query value features에서 Spaital Convolution을 통과한 이후 각각 Classification, Regression, Small object query로 이어져 분류, bbox 회귀, small object에 대한 분류를 진행합니다. 전체적인 파이프라인은 이와 같습니다.
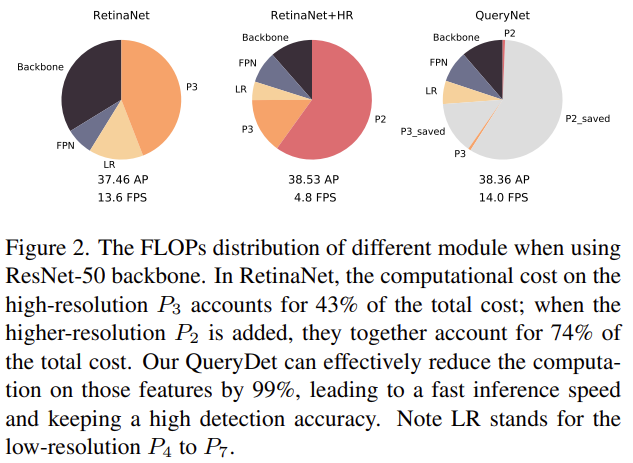
이를 설명한 이유는. RetinaNet에서 P_2 Feature map을 그대로 Detection Head로 사용한다면, Small object에 대한 성능은 높아지겠지만 Computational cost는 증가합니다. 계속해서 Computation cost가 높아진다고는 하는데, 어느 정도로 높아질까요? 실제로 P_4 에서 P_7 까지의 Computation cost는 다 더해도 전체의 15%에 해당하지만, P_3 에 해당하는 Computation cost는 그 하나만으로 전체의 75%를 차지합니다. 그렇다면, P_2 까지 추가한다면? FLOPs가 엄청나겠죠.. 이는 아래의 Figure 2.에서 확인할 수 있습니다.
위에서 QueryDet의 간략적인 구조를 말씀드렸는데, 실제로도 이것이 끝입니다. 그렇다면 어떻게 작은 객체를 정의할까?에 대한 의문이 들 수 있습니다. 그 이유는, 우리가 Input image에서 정의한 Small object와 실제 Feature map에서 정의하는 small object는 같은 크기로 정의할 수는 없습니다. 300×300 크기의 input image에서 30×30 크기의 object는 충분히 작다고 말할 수 있지만, 30×30 Feature map에서 30×30 크기는 전체에 해당하기 때문입니다. 그렇다면 우선적으로 Query head가 어떻게 구성되는지, input과 output은 어떠한지, 그리고 작은 객체는 어떻게 정의하는지를 살펴보겠습니다.
P_l 을 input feature map으로 받는 Query head는 heatmap인 V_l 을 내뱉습니다. V_l 의 사이즈는 H^{'} \cdot W^{'} 로 정의됩니다. heatmap이라는 단어에서 힌트를 얻을 수도 있었겠는데, 정확히는 어떠한 하나의 (i,j)로 이루어진 Grid 내 Small object가 있을 확률에 대한 heatmap입니다.
이제는 Feature map 내 Small object에 대해 정의해야할텐데, 저자는 단순함을 위해 P_l 에서의 가장 작은 Anchor box에 해당하는 s_l 의 크기를 Threshold로 잡고, 이보다 작은 object를 small object로 정의합니다. 즉, 각 Pyramid의 단계에 따라 small object가 정의되야하는 크기가 다르므로, 저자는 이를 단순히 적용하고자 했다고 볼 수 있겠습니다. 추가적으로 위에서 말한 것 처럼, Ahcor-free detector, 즉 DETR 등의 방법에서는 minimum regression, 즉 예측 bbox의 최소 회귀 크기 (DETR을 떠올려보면, object query가 갖는 regression 범위를 의미한다고 볼 수 있겠습니다. 정확한 것은.. 코드를 봐야 이해할 것 같습니다. 어떠한 Direct set prediction에서 QueryDet 모듈이 어디에 사용되냐에 따라 해석할 수 있는 의미가 더 있을 것 같긴 합니다.
또한, Feature map 내 각 Point는 object의 center location (x_0, y_0) 과의 거리값을 통해 1과 0으로 인코딩됩니다. 거리가 사전에 정의한 s_l 보다 작다면 1, 즉 small object가 있는 위치일 것이며, 아니면 0으로 인코딩됩니다. 다시 설명하자면, 하나의 object가 small object query로 사용되려면 s_l 보다 작은 크기여야하며, Feature map 내에서 해당 지점을 찾고서 인코딩해서 “이 지점은 Small object가 있을만한 지점이야!”라고 알려주기 위해서 Small object와의 center location과의 거리를 계산하여 Query value feature를 구성합니다.
Inference 시, predicted socre가 threshold 값보다 큰 경우에만 query로 사용하며, 해당 지점을 Small object가 있는 지점으로 선택합니다. 그럼 이제, 위에서 인코딩한 정보는 다시 상위 Feature map, 예를 들어 P_l 에서 인코딩한 정보는 P_{l-1} 로 전달되어야 할 것이며, 두 Feature map 사이의 Resolution 차이를 고려하여 아래의 수식으로 four nearsed neighbors를 예측하여 전달합니다.
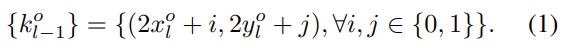
수식 (1)을 살펴보면 네 지점을 구하게 되는데, 이를 Key position이라고 정의합니다. 각 object에 대하여 key position을 계산한 k_{l-1} 을 다음 Feature map 레벨 ( P_{l-2} )과의 연산 (논문에서는 연산으로만 나와서, 뭔가 싶었는데.. 태주님의 리뷰에서 요소곱임을 알 수 있었습니다)을 통해 Small object에 대한 정보만을 가진 Query value feature map을 생성합니다. 이렇게 수학적으로만 보면 또 어려우니, 작은 예시를 들어 설명하자면 한 레벨의 Feature map에서 인코딩된 위치 정보에 따라, 다음 Feature map으로 전해질 때는 Resolution이 다르니 예측되는 지점을 Y 좌표 0, 1을 더하여 계산하고, 다음 Feature map에서의 정보와 요소곱하여 해당 Feature map에서는 이전 Feature map에서 Small object라고 판정된 위치에 대해서만 다시 1,0 값을 갖게 됩니다.
이렇게 설명해보니 왜 요소곱인지 당연시되는 것 같습니다. 정확치는 않아도 예시로 [1, 2, 3, 4 / 5, 6, 7, 8]의 Feature map이 있고 다음 Feature map 레벨에서 [1, 0]으로 인코딩되었다면, 요소곱 이후에는 [1, 2, 3, 4 / 0, 0, 0, 0]으로 인코딩 될 것이고 1에 해당하는 위치는 1, 2, 3, 4, 그리고 해당 지점이 Small object가 있을 위치로 인코딩되어 다시 이전 Feature map 레벨에 전달되게 합니다. 이러한 계단식 구조를 통해 High-level information을 Low-resolution Feature map에 전달할 수 있고, 그러한 Small object query를 통해 이제 Feature map은 Small object의 위치에 대해 잘 학습할 수 있게 될 것 입니다.
우리는 인코딩되어 1, 0으로만 정보를 가지고 있으니, 굳이 0이 있는 모든 위치를 계산할 필요가 없습니다. 그렇기에 우리는 Sparse Convolution을 통해 1로 인코딩된 정보에 대해서만 계산하면 됩니다. 이는 Computation cost를 줄이며, 다시 돌아가면 이러한 작업을 할 수 있는 이유는 인코딩의 도움 덕분이라고 볼 수 있습니다. 저자는 이러한 패러다임을 계단식의, Sparse Convolution을 사용한다고 해서 Cascade Sparse Query, CSQ라고 명합니다.
이제 학습에 대해 알아보겠습니다. Base model로는 RetinaNet을 썻으며, Query head에서 인코딩된 Query map에 Focal Loss를 적용합니다. Focal Loss를 적용하는 이유는, 짐작하건데 인코딩된 Feature point는 Sparse하기 때문에, Small object의 특성을 생각했을떄는 Class imbalance 문제가 있을 수 있고, 따라서 Focal Loss로 성능 향상을 보고자하지 않았나 하는 생각이 듭니다. 우선 아래의 수식은 Small object의 GT center location과 GT Query map을 인코딩하는 과정에 해당합니다. Threshold s_l 을 생각하면, 어렵지 않게 이해할 수 있을 것으로 생각됩니다.
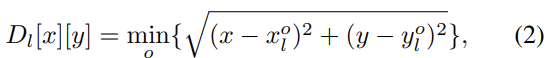
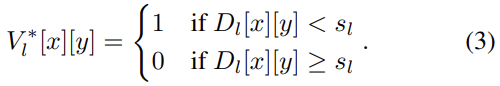
이제, Feature map F_l에 대한 Loss입니다. L_{FL} 은 Focal Loss를, L_r 은 bbox에 대한 regression을 의미합니다. U^{*}_{l}, R^{*}_{l}, V^{*}_{l} 는 각각 GT 클래스 분류값, bbox 위치 회귀 값, Query score 결과를 의미합니다. Query output score만 잘 생각해보면 Loss도 어렵지 않게 넘어갈 수 있습니다.
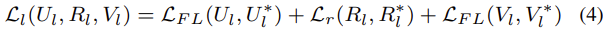
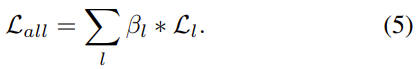
B_l 로 전체 Loss를 조절합니다. 이는 우리가 SSD를 생각해보면 쉽게 알 수 있는데, SSD에서 Conv4_3의 Loss를 L2 norm 해줍니다. 그 이유는 무엇이었을까요? Conv4_3은 그만큼 High-resolution이고, 그렇다면 데이터의 분포가 다른 Feature map에 비해 차지하는 비율이 클 것이니, Conv4_3이 전체 데이터의 지배적인 분포를 가져버리기 때문입니다. 그렇게 된다면 Detection head에서 Loss를 더하게 되면 Conv4_3에 의해 좌지우지되게 되어버리죠. 마찬가지입니다. 상위 Feature map, 즉 Low-level, High-resolution Feature map에 의해 Loss가 크게 변하는 것을 방지하고자 조절하는 하나의 계수를 놓아 전체 Loss를 조정합니다. 충분히 어렵지 않게 이해할 수 있을 것이라 예상합니다. 다음 장은 기존의 RetinaNet과의 비교이니, 이제 실험 단계로 넘어가겠습니다.
Experiments
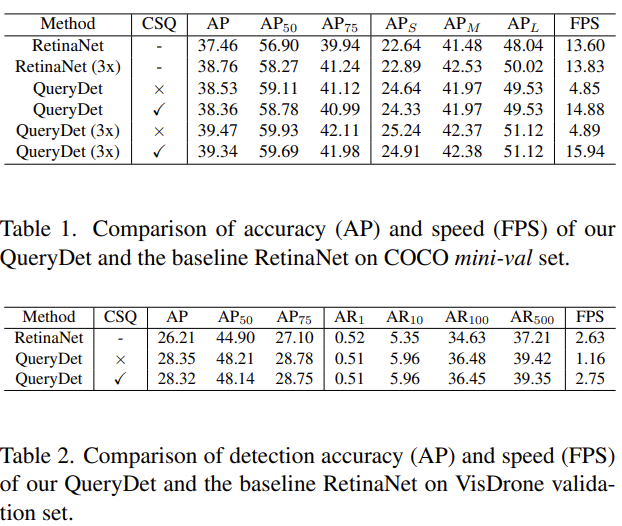
우선, RetinaNet에서 QueryDet을 적용했을 때의 결과입니다. 전체 AP도 1% 가량 향상했으며, 무엇보다 Small obejct에 대한 성능을 살펴보면 AP_S 가 2%가량, 꽤나 많이 향상한 모습을 볼 수 있습니다. 여기서, CSQ가 없는 QueryDet이란 베이스 방법론인 RetinaNet에서 Query head만 추가한 방법입니다. 계단식으로 구성되는 추정 과정이 빠져있스니다. 그렇게 했을 때는 FPS 측면에서 느리나 성능의 향상 폭은 굉장히 좁은 것을 알 수 있습니다. 해당 실험에서는 우리가 중점적으로 살펴볼 점은 CSQ를 통해 인코딩하는 정보를 전달하며 FPS는 굉장히 빠르게 만드는 동시에 성능적인 측면도 괜찮게 가져갈 수 있다는 점입니다. CSQ가 없을 때의 성능이 조금 더 높은 이유는, 아마 Sparse Convolution에서 오는 부정확함 혹은 인코딩하지 않고 모든 지점을 살펴봤을 때의 이점이라고 볼 수 있습니다.
COCO mini-val set이 아닌 VisDrone 데이터 셋도 사용을 하는데, VisDrone은 드론 사진 촬영 데이터셋으로 많은 양의 작은 물체가 포함되어 있는 데이터 셋으로, Small object detection 논문에서 몇 번 본적이 있는데 성능 향상도 꽤나 많이 일어난 것을 알 수 있습니다.
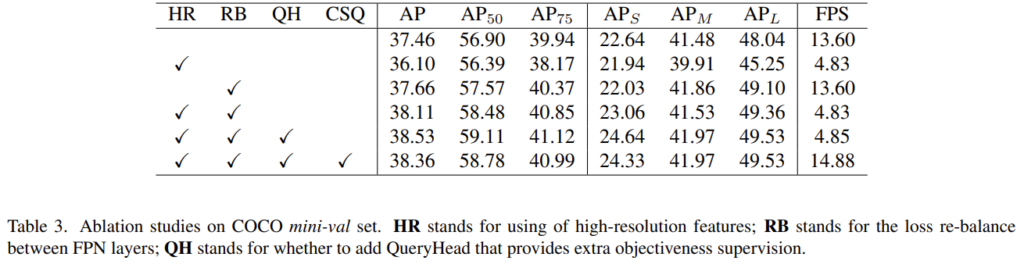
해당 실험은 High-resolution Feature map (HR)과 Re-balance Loss (RB), QH (Query head), CSQ에 대한 Ablation study입니다. 참.. 모든 것이 좋으면 좋겠지만 당연히 그런 일은 있을 수 없습니다. AP와 FPS는 아직 Trade-off 관계이며, 이 둘을 모두 충족하기는 다른 획기적인 방법이 필요한 것일까요? RB에 대한 성능 개선을 살펴보자면, HR + RB를 사용했을 때, 기존에 비해 성능 개선이 많이 일어난 모습을 볼 수 있습니다. 조금 의아한점은 HR을 추가했을 때는 오히려 AP가 하락한 점인데.. 이 부분에 대해서는 큰 언급이 없었던 것으로 봤습니다. 우리가 아는 지식과는 조금 동 떨어져있는 결과인데, 왜 저자가 말을 안했는지, 리뷰 쓰고서 다시 한번 살펴봐야겠네요.
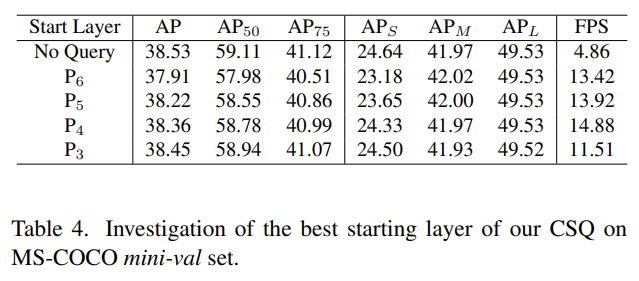
다음은 Query 예측을 시작하는 지점에 따른 성능 차이를 보여주는 Ablation study입니다. 사실 이번 실험은 명확히도 당연한 사실 중 하나였지만, 들고온 이유 중 하나는 Start Layer에 따른 FPS의 변화입니다. 증가하는 듯 하다가.. 갑자기 떨어지는 것을 보아 앞서 언급한 P_3 이 전체의 75%에 해당하는 Computation cost, 즉 그만큼 Resolution이 커서 그렇지 않았을까라고 짐작하고 있습니다. 저자는 No Query, 즉 CSQ 방법을 사용하지 않은 성능을 계속 리포팅하는데, FPS를 말하고 싶어서 그랬을 것으로 보입니다. 표를 보다 흠칫흠칫 놀라고는 합니다. 정말 많은 실험을 한 것으로 느껴집니다.

다음은 정성적 결과입니다. Query heatmap이 Small object에 대해 활성화되어 있는 것을 알 수 있는데, Mid-size나 Large-size의 object에 대해서는 활성화되어 있지 않은 것으로 보아, Small object를 정의하는 과정과 그 과정에서 전해지는 정보를 우리가 시각적으로 정말 그렇구나하고 생각할 수 있는 지점으로 보여 들고 왔습니다. 이외에도 Ablation study는 특히나 많은데, 제가 보기에는 다음의 Anchor-Free Detectors에 대한 성능 분석을 가져오고 싶어서 해당 분석을 보고 마치도록 하겠습니다.
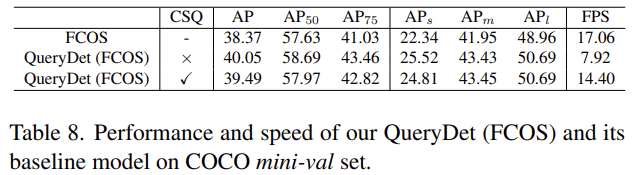
FCOS에서의 Query det 결과입니다. FCOS는 Anchor-free 방법론 중 하나로, 이전에도 다른 연구원분들이 리뷰한 이력이 있으니 살펴보시면 좋을 것 같습니다. 성능 면에서도 미세하지만 확실한 성능 향상을 보입니다. 저는 Deformable DETR에서 Deformable Convolution에서의 Query를 QueryDet으로 적용하는 방법을 이번 과제에서 구상하고 있습니다.
이상으로 리뷰 마치도록 하겠습니다. 읽어주셔서 감사합니다.
리뷰 감사합니다.
간단한 질문 드리겠습니다. total loss에서 beta로 전체 loss weight을 조절하는 부분이 있는데 SSD를 빗대어 설명해주셔서 이해가 잘 되었습니다:) 혹시 이 weight를 설정하는 기준이나 feature level마다 어떤 값으로 설정하는지에 대한 설명이 있나요?
그리고 CSQ를 적용하지 않은 것이 속도는 3배 가량 빠른데 accuracy는 큰 차이를 보이지 않는 것 같습니다. 혹시 추후에 deformable DETR의 deformable conv의 query를 Query로 적용하시나면 어떤 method를 선택하실건가요?
감사합니다.
네. 우선 첫 번째 질문은 loss weight을 조절하는 beta에 대한 질문으로 이해했습니다. 해당 부분은 Implementation Details에서 확인할 수 있으며, beta는 [latex] P_2 [/latex]에서 [latex] P_7 [/latex]까지, Minimum 1, Maximum 3을 잡고 Linear하게 늘어난다고 합니다. 이를 통해 P_2의 영향력을 줄이고자 함을 알 수 있습니다. 하지만 신기한 점으로, beta는 Dataset에 따라 달리 설정되었습니다. 위에서 말한 1~3의 간격으로 Linear하게 늘어나는 것은 COCO Dataset으로, 리뷰에서 말씀드린 VisDrone Dataset에서는 1-2.6의 간격 사이에서 Linear하게 늘어난다고 합니다. 이는 제 예상에, VisDrone Dataset은 COCO Dataset에 비해 Small object의 비율이 훨씬 많으며, 그렇기 때문에 High-resolution인 [latex] P_2 [/latex]의 영향력을 조금 더 주려하지 않았나 생각듭니다.
CSQ를 적용하지 않은 것이 속도가 3배 빠른데, Accuracy가 크게 차이나지 않는 점이 굉장한 핵심점이라고 볼 수 있는데, CSQ를 적용했다는 것은 Small object에 대한 Keypoints만 다음 Resolution으로, 계단식으로 전달해지는 반면 CSQ를 적용하지 않는다는 것은 마치 FPN처럼 연산되어, 정확도 측면에서는 조금 높을지 몰라도 FPS가 느려지게 됩니다. 그렇기 때문에 CSQ를 적용하고서, 속도를 확 높이고 정확도를 비슷하게 가져갈 수 있는 것이 핵심 Contribution입니다.
물론 구상 중에 있으며, Deformable DETR의 Query point, 즉 DCN을 통해 학습되는 offset에 QueryDet을 통해 Feature map의 Resolution이 변화함에 따라 offset이 Small object에 더더욱 집중될 수 있도록하는 그림을 구상 중에 있습니다.
리뷰 읽어주셔서 감사합니다.
리뷰 잘 읽었습니다.
small object 검출을 위한 기존의 FPN 방식은 cost가 많이 들어서 이를 문제삼아 새로운 방식을 제안한 논문이군요. 문제정의가 매우 훌륭한 거 같습니다.
한전 과제에 적용해보겠다고 하셨는데, 한전 2차년도 baseline 모델이 small한 경우를 잘 검출해내지 못해서 해당 방법론을 적용해보려고 하시는건가요?
네. 한전 2차년도 Baseline 모델이 3차년도 정량적 기준 (30×30 pixel, 10.36 MR)에 미치지 못하였기 때문입니다. 30×30 pixel 정도면 영상 내에서는 정말 작은 객체에 속한다고 볼 수 있으니, QueryDet의 아이디어가 유용할 것으로 생각됩니다.