이번 주차의 X-Review는 22년도 CVPR에 게재된 ‘Frame-wise Action Representations for Long Videos via Sequence Contrastive Learning’이라는 논문입니다. 우선 Self-supervised 기반의 Video Representation Learning 논문에 해당하고, 제목에서는 Long video라고 하였지만 사실은 trimmed video를 다루고 있던 논문이었습니다.
Weakly-supervised Temporal Action Localization을 잘 수행하기 위한 일종의 insight를 얻고자 논문을 찾던 중 제목에 제가 원하던 키워드들이 잔뜩 들어가 있기도 했고, WTAL은 결국 temporal annotation에 대해서는 self-, unsupervised 방식으로 학습해야하기 때문에 도움이 될 것 같아 읽게 되었습니다. 하지만 말씀드렸다시피 trimmed video를 다루었기 때문에 action과 background의 특성을 잘 활용하는 아이디어는 딱히 없었어서 참고하는 정도로만 읽어보았습니다. 추가로, 오늘 소개해드릴 논문은 Microsoft Research Asia가 저자로서 참여하였습니다.

논문으로 들어가기에 앞서 Self-supervised Video Representation Learning(SSVRL)은 아무런 label 없이 비디오의 중요한 특성을 잘 추출하는 좋은 표현력을 갖는 모델을 학습시키는 것이 task의 최종적인 목표입니다. 이미 저번 주 세미나 때 많은 석사분들께서 이에 대해 다루시며 pretext task 기반 방법론과 contrastive learning 기반 방법론으로 나눠진다고 설명해주셨는데, 본 논문은 contrastive learning 기반 방법론에 해당합니다.
그리고 좋은 표현력을 갖는 feature를 추출하게 된다는 문장에서, 좋은 표현력이라는 것은 어떠한 downstream task를 수행할 것인지에 따라 달라질 수 있습니다. 비디오는 지금 저희가 다루려는 것처럼 action들로 구성될 수도 있고, 어떠한 사건들로 구성될 수도 있고, 아니면 긴 영화들일 수도 있습니다. 이렇게 다양한 비디오의 구성 요소에 따라 어떠한 downstream task를 수행할 것인지가 결정될 것이고, 이에 따라 ‘좋은 표현력’이라는게 무엇인지가 달라지는 것입니다.
그러면 본 논문을 읽을 때에는 action으로 구성된 비디오로부터 수행할 수 있는 downstream task인 fine-grained action recognition, fine-grained frame retrieval 등을 잘 수행하기 위해 어떠한 표현력을 갖추면 좋다고 주장하는지에 집중하면 좋을 것입니다. 이러한 downstream task들과 방법론에 대한 설명은 뒤에서 다루도록 하겠습니다.
1. Introduction
I3D나 SlowFast와 같은 네트워크는 기존에 action classification task를 수행하기 위해 상대적으로 짧은 비디오(32 프레임, 64프레임)만을 입력으로 받아 사용했다고 합니다. 그리고 목표가 결국은 하나의 비디오에서 어떠한 action이 벌어지고 있는 것인지를 맞추는 것이기 때문에 출력은 프레임 별 representation이 아닌 global representation이었는데, 실질적으로 비디오를 활용할만한 수화 번역, action alignment, phase classification과 같은 task들을 수행하려면 짧은 비디오만을 입력으로 받거나 global representation을 출력으로 내뱉는 모델은 적용하기 어려울 것입니다. 다시 말해 action classification을 제외한 대다수의 실용적인 downstream task들은 상대적으로 긴 비디오를 다루되, global representation이 아닌 frame-wise representation을 필요로 한다는 이야기입니다.

이러한 흐름 속에서 좋은 frame-wise representation을 추출하기 위한 연구는 많았지만, 대부분은 fully-, weakly-supervised 기반이었습니다. 그림 1은 각 데이터셋에서 수행할 수 있는 task들을 보여줍니다. 그림 1-(b) Phase boundary detection task의 그림을 보면 해당 task는 사람이 음료를 컵에 따르는 과정 동안 (사람이 병을 만진다 – 음료를 따르기 시작 – 따르기 끝 – 병을 내려놓음)이라는 일련의 과정 속 현재 프레임이 어느 단계에 해당하는지 분류해내는 것입니다. 이를 위해 각 단계 별로 모든 프레임에 대한 temporal annotation을 붙이는 것은 굉장히 cost가 큰 일이겠죠. 그래서 저자는 self-supervised 기반의 frame-wise representation을 잘 학습할 수 있는 방법론을 제안합니다. 다른 이야기일 수 있지만 이번 캡스톤 주제를 정하고자 여러 task를 찾던 중, 해결하고자 하는 문제에 맞는 labeled dataset의 필요성과, 반대로 그러한 데이터를 얻기 힘든 경우 self-supervised 방법론들의 중요성들을 확실히 깨닫게 되었습니다.
아무튼 연구의 필요성은 잘 정당화 되었고, 이제 저자가 본 문제를 풀어나가고자 하는 방식에 대해 간략히 살펴보겠습니다. 우선 저자가 제안하는 프레임워크는 Contrastive Action Representation Learning(CARL)이고, 학습 과정 중 어떠한 라벨도 필요로 하지 않습니다. Contrastive learning을 위한 feature는 spatial, temporal 정보를 모두 잡으려는 의도에서 R50+Transformer Encoder로부터 추출하였고, 실제 contrastive learning은 SimCLR에서 제안한 NT-Xent loss를 비디오의 특성에 맞게 잘 변형시킨 Sequence Contrastive Loss(SCL)을 제안하여 사용했습니다.
본 논문의 Contribution을 정리한 뒤 본격적인 방법론을 살펴보겠습니다.
Contribution
- We propose a novel framework CARL to learn frame-wise action representations with spatio-temporal context information for long videos in a self-supervised manner.
- We introduce a Transformer-based network to efficiently encode long videos and a novel SCL for representaiton learning. Meanwhile, a series of spatio-temporal data augmentations are designed to increase the variety of training data.
- Our framework outperforms the SOTA methods by a large margin on multiple tasks across different datasets.
2. Method
저자가 제안하는 CARL에 대하여,
- Overview
- View construction and data augmentation
- Frame-level video encoder
- Sequence Contrastive Loss
순서대로 각 절에서 알아보겠습니다.
2.1 Overview
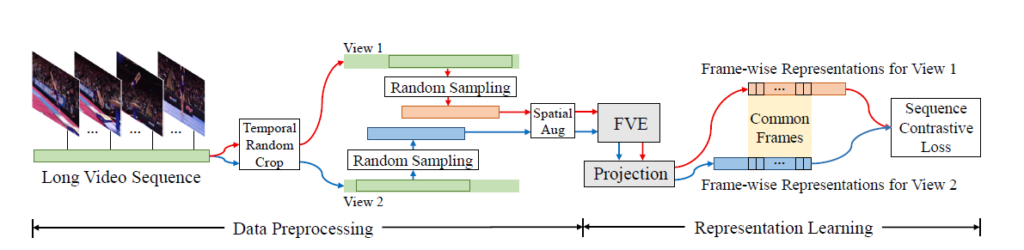
그림 2는 CARL의 전체 파이프라인을 나타내고 있습니다. 생각보다 굉장히 단순하네요. 크게 보면 Data Preprocessing 단계와 Representation Learning 단계로 나눠집니다.
먼저 Data Preprocessing 단계에서는 입력 받은 비디오로부터 Temporal Random Crop을 거쳐 두 개의 view를 만들고, random sampling을 거쳐 동일한 길이로 맞춰줍니다. 이후 하나의 view에 대해서는 일관적인 spatial augmentation을 적용해주면 뒷 단계인 Representation Learning에 사용할 feature가 준비되는 것입니다.
Representation Learning 단계에서는 앞서 받은 feature들이 FVE(R50+Transformer Encoder+…)를 거쳐 projection되고 서로 다른 view(augmentation)를 갖는 feature들의 유사도 특성을 이용한 SCL을 적용해줍니다.
이와 같은 단계들에 대해서 하나씩 자세히 살펴보겠습니다.
2.2 View Construction
2.2절이 그림 2에서 본 Data Preprocessing 단계에 해당합니다.
입력받은 비디오 V가 총 S개의 프레임으로 이루어져 있다고 할 때, 본 단계에서의 목적은 공통적으로 T개의 프레임을 갖되 서로 다른 spatio-temporal augmentation이 적용된, 즉 서로 다른 view의 두 augmented video V^{1}, V^{2}를 얻는 것입니다.
우선 입력받은 비디오 V를 [T, \alpha{}T] 사이의 길이로, 최소 \beta{}%는 겹치도록 temporal random crop을 수행합니다. 이후 서로 다른 길이의 cropped clip에 random sampling을 적용해 둘의 길이가 모두 T가 되도록 해줍니다. 각 clip을 V^{1} = \{v_{i}^{1}|1 \le{} i \le{} T\}, V^{2} = \{v_{i}^{2}|1 \le{} i \le{} T\}로 표현할 수 있고 v_{i}^{1}, v_{i}^{2}는 V^{1}, V^{2}에 속하는 i번째 프레임을 의미합니다.
실제로 저자는 T=240, \alpha{}=1.5, \beta{}=20%로 지정하여 사용했습니다.
다음으로 시간 축에 대해서는 일관된 random resize and crop, horizontal flip, random color distortions, random Gaussian blur를 V^{1}, V^{2}에 각각 적용해줍니다. 시간 축에 대해 일관되었다는 것은 spatial augmentation이 V^{1}, V^{2}끼리는 랜덤이라 서로 다르지만 V^{1}에 속하는 모든 프레임들끼리는 동일하게 적용되었다는 뜻입니다.
2.3 Frame-level Video Encoder
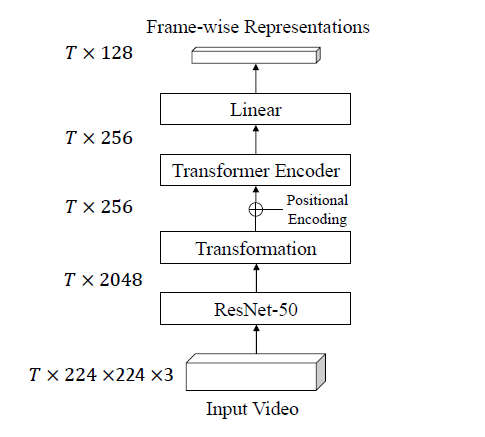
본 절에서는 앞서 얻은 두 view의 clip을 임베딩하기 위한 Frame-level Video Encoder를 소개합니다.
기존 연구에서 사용되던 3D Conv는 너무 많은 computational cost를 요구하면서 제한적인 receptive field를 갖는데, 이러한 문제를 완화하기 위해 본 방법론에서는 Resnet50과 Transformer Encoder layer를 사용합니다.
그림 3은 Frame-level Video Encoder의 구조입니다. 앞서 얻은 한 비디오에 대한 두 view 중 한 view만 예시로 고려한다고 했을 때, 아직은 sampling과 augmentation만 적용된 상태이므로 인코더에 들어오는 shape은 T \times{} 224 \times{} 224 \times{} 3일 것입니다. 이를 temporal 축에 따라 R50에 태워 spatial 정보를 추출하고 2개의 FC-BN-ReLU 블록으로 이루어진 Transformation layer를 거쳐 T \times{} 256 shape의 중간 임베딩을 얻습니다.
이후 sin-cos positional embedding을 적용하고 3 layer로 이루어진 Transformer Encoder에 태우게 됩니다. 마지막으로 FC layer를 태워 frame-wise representations H \in{} \mathbb{R}^{T \times{} 128}을 얻게됩니다. 마찬가지로 h_{i}(1 \le{} i \le{} T)는 H에 속하는 i번째 frame representation을 의미합니다.
2.4 Sequence Contrastive Loss
앞선 단계까지 완료하면 representation learning을 위한 feature가 준비된 것입니다.
저자는 representation learning을 위해 SimCLR에서 제안한 NT-Xent loss를 참조하는데, 원래의 NT-Xent loss는 자신으로부터 만들어진 augmentation을 제외하고는 모두 negative로 지정하여 멀어지도록(유사도가 낮아지도록) 학습합니다.
하지만 이미지와는 다르게 비디오는, 인접한 프레임끼리 굉장히 중복적이고 유사한 정보를 가지고 있습니다. 따라서 같은 timestamp가 아니라고 해서 모두 negative로 두었다가는 시각적으로나 의미론적으로 유사한 프레임을 negative로 두고 학습하여 오히려 representation이 망가지는 경우가 생길 수도 있습니다.
이러한 상황을 방지하고자 저자는 Sequence Contrastive Loss(SCL)를 제안합니다. SCL의 기본적인 컨셉은 다른 timestamp를 갖는 프레임을 무조건 negative로 두는 것이 아니라, 현재 보고 있는 프레임과 주변 timestamp에 해당하는 프레임들의 유사도는 Gaussian distribution을 따를 것이라고 가정하고 representation learning을 수행하는 것입니다.
자세한 내용과 수식을 바로 알아보겠습니다.
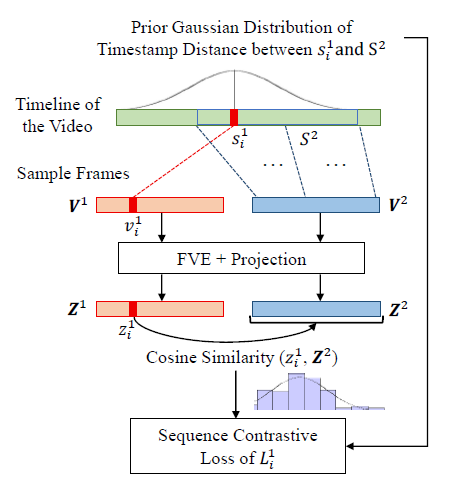
그림 4는 SCL의 과정을 보여줍니다.
우선 FVE를 거쳐 얻은 H를 SimCLR에서처럼 two-layer MLP에 태워 최종 임베딩 Z로 만들어줍니다.
SCL에 대한 수식을 먼저 보면 아래와 같습니다.
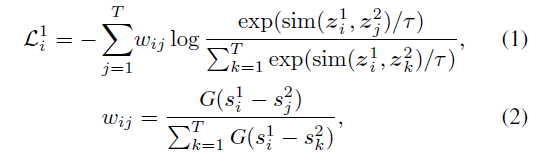
먼저 수식 (1)은 V^{1}의 i번째 프레임에 대한 SCL입니다.
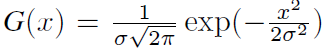
수식 (2)에서 G는 위 수식과 같고 결국은 평균이 0인 Gaussian function을 의미합니다. 그리고 s_{i}^{1}은 V^{1}의 i번째 프레임이 원본 비디오에서 갖는 timestamp를 의미합니다.
그렇다면 수식 (2)에서 s_{i}^{1}과 s_{j}^{2}가 유사할수록, 즉 원본 비디오에서 가까운 거리에 있었을수록 s_{i}^{1} - s_{j}^{2}은 0에 가까워지며 normalized Gaussian weight w_{ij}는 1에 가장 가까운, 상대적으로 큰 값을 갖게 될 것입니다.
다시 수식 (1)로 돌아가보면, 수식 (1)은 z_{i}^{1}과 z_{j}^{2}의 cos 유사도 분포가 앞서 구한 w_{ij}를 따라가도록 설계되어 있습니다. 정리하자면 저자는 비디오에서 현재 보고 있는 프레임과 다른 timestamp를 갖는 프레임들을 전부 negative로 두고 유사도가 작아지도록 학습하면 representation에 악영향을 주게 되니, 현재 보고 있는 프레임에 대해 augmentation된 다른 view의 프레임들 간의 timestamp 거리를 고려하여 거리에 따른 유사도가 Gaussian distribution을 따르도록 SCL을 설계하였다는 것입니다.
설명이 조금 난잡하였는데 그림 4의 아래 쪽 보라색 막대 그래프가 현재 보고 있는 프레임 기준 다른 view의 프레임들과의 유사도를 의미하고, 이 유사도 분포가 막대그래프 위에 그려진 Gaussian 분포를 따라가도록 representation learning을 수행한다는 것입니다.
여기까지가 z_{i}^{1}에 대한 loss였고, 이를 {V}^{1}의 모든 프레임에 대해 계산하여 평균내고, 동일한 과정을 {V}^{2}에도 거쳐 최종 loss를 얻습니다. 수식으로는 아래와 같습니다.
- \mathcal{L}^{1} = \frac{1}{T}\Sigma{}_{i=1}^{T}\mathcal{L}_{i}^{1}
- \mathcal{L}_{SCL} =\mathcal{L}^{1}+\mathcal{L}^{2}
아무래도 trimmed 비디오를 다루다보니 서로 다른 두 view에서도 인접한 프레임끼리는 representation 상의 유사도를 높이는 것이 도움된다고 볼 수 있겠지만, 다양한 background가 혼재되어 있는 untrimmed 비디오에서는 이를 어떻게 적용할 수 있을지 고민해보는 것도 중요할 것 같습니다.
방법론은 여기까지이고 이제 실험 결과에 대해 알아보겠습니다.
3. Experiments
3.1 Datasets and Metrics
총 3가지 데이터셋 PennAction, FineGym, Pouring에 대해 벤치마크를 진행하였습니다.
각 데이터셋에 대한 평가지표들은 아래와 같습니다.
- Phase Classification: 앞서 그림 1을 보며 설명드린 것과 같이, 프레임 별로 어느 단계에 해당하는지 분류를 수행한 뒤 측정한 정확도를 의미합니다.
- Phase Progression: Phase progression 값(실제 phase boundary와의 timestamp 차이)을 모든 프레임에 대해 얻고, 최종 성능은 모든 프레임에 대한 평균 r2score로 나타냅니다.
- Kendall’s Tau: 두 비디오 쌍을 뽑아 첫 번째 비디오에서 두 프레임을 추출한 뒤 두 번째 비디오에서 그 두 프레임과 가장 유사한 프레임을 retrieve 했을 때 둘의 align이 얼마나 잘 맞는지에 대한 성능 지표입니다. (NT-Xent의 \tau{}와 표기는 같지만 다른 의미를 갖습니다.)
- AP@K: Fine-grained frame retrieval 정확도로, 쿼리 프레임이 주어졌을 때 같은 단계에 속하는 프레임이 top-K개 중 몇 개인지에 대한 Average Precison을 의미합니다.
3.2 Main Results
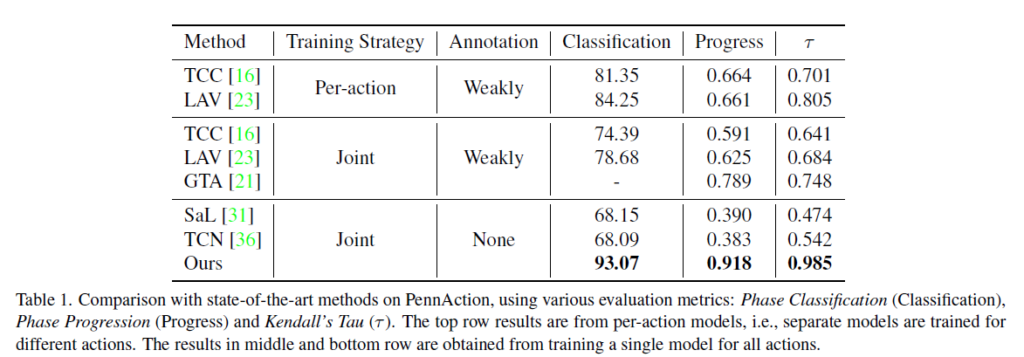
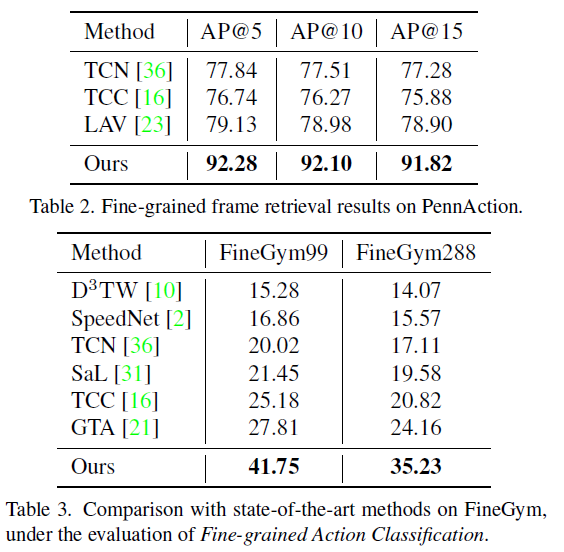
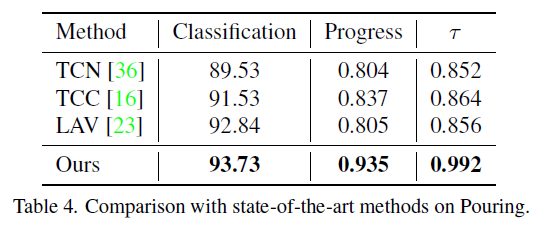
표 1, 2, 3은 각 데이터셋에서의 벤치마크 성능입니다. 표 1에서는 PennAction 데이터셋으로 측정한 4가지 평가지표를 보여주고 있습니다. Per-action은 존재하는 13개의 클래스를 각각 별도의 모델을 두어 13개의 expert model을 만드는 방식이라고 하는데, 그것을 떠나 학습 시 video-level label이 주어지는 방법론들보다도 CARL이 모든 지표에서 훨씬 압도적인 성능을 보이는 것을 알 수 있습니다. 이는 표 2, 3, 4에서도 마찬가지인 것을 볼 수 있습니다.
3.3 Ablation Study
모든 ablation study는 PennAction 데이터셋에서 수행되었습니다.
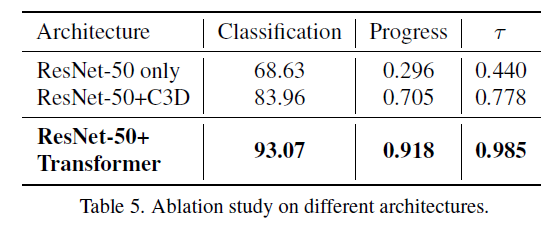
표 5는 Backbone에 따른 실험 결과입니다.
R50 only는 현재 FVE에서 Transformer Encoder layer를 아예 삭제하는 경우의 성능이고, R50+C3D는 2개의 3D Conv 거친 후 R50의 spatial embedding을 거치는 형태로 구성된 backbone을 의미합니다. 특히 이는 기존 SOTA인 TCC와 LAV와 같은 구조의 backbone이라고 하는데, 표 1과 비교해보았을 때 Self-supervised이면서도 성능이 압도적인 것으로 보아 확실히 SCL이 representation learning에 큰 역할을 수행한 것으로 해석할 수 있겠습니다. 타 방법론에 R50+Transformer를 적용한 실험은 뒤에 있으니 바로 살펴보도록 하겠습니다.
마지막으로 저자가 채택한 R50 + Transformer Encoder가 굉장히 높은 성능을 보여주고 있고, 역시나 Transformer의 long range dependency modeling 능력이 중요하게 작용했다고 볼 수 있습니다.
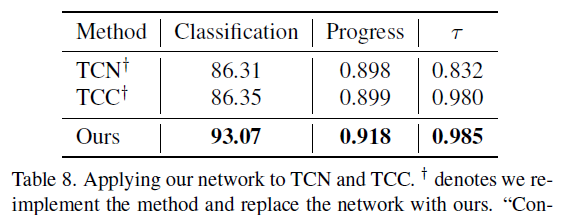
표 8은 TCN과 TCC라는 다른 방법론에 CARL의 FVE를 적용하는 경우의 성능입니다. 표 1과 비교해보았을 때 확실히 TCN과 TCC도 성능이 크게 오르는 것을 볼 수 있었는데요, 저자가 표 8을 통해 보여주고 싶었던 것은 CARL의 성능이 단순히 FVE만으로부터 온 것이 아니라 SCL이 확실히 성능 향상에 기여했다는 점인 것 같습니다.
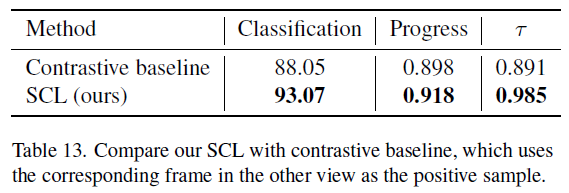
표 13은 SCL 대신 Contrastive baseline을 적용하는 경우의 성능입니다. Contrastive baseline은 timestamp 거리에 따라 Gaussian weight를 주어 학습하는 SCL과는 다르게 단순히 다른 view에서 상응하는 프레임만을 positive로 두고, 나머지는 모두 negative로 두어 학습하는 경우의 성능을 의미합니다.
베이스라인의 성능도 나쁘지는 않지만 SCL을 적용하는 경우 큰 폭으로 성능이 오른다는 점이 주목할만한 것 같습니다. 기타 하이퍼파라미터에 대한 실험과 정성적 결과도 논문에 많이 있으니 필요하신 분들은 찾아보시면 좋을 것 같습니다.
4. Conclusion
단순한 아이디어를 적용했음에도 성능이 굉장히 크게 오르는 것이 신기하였고, 다양한 데이터셋에 대해 여러 downstream task로 자신들의 방법론이 우수함을 증명한 것이 인상 깊은 논문이었습니다.
이상으로 리뷰 마치겠습니다.
안녕하세요. 김현우 연구원님.
리뷰 잘 읽었습니다! temporal 축에서 인접한 frame들의 유사도가 gaussian 분포를 따를 것이라는 추정과, 이 방법의 효과를 성능으로 입증한 것이 멋진 논문이라는 생각이 듭니다.
정리를 깔끔하게 해주셔서 비디오에 대한 사전 지식이 적음에도 큰 어려움 없이 읽을 수 있었습니다.
혹시 그림 4에서, FVE 다음에 있는 Projection이라는 것이 단순히 MLP를 한번 더 태워 V1을 Z1으로 바꿔주는 것을 의미하는 것인가요? 혹은 뭔가 특별한 연산을 수행하는 과정이 있는 것인가요?
감사합니다!!
연산 상으로는 단순히 MLP를 태우는 것이 맞지만, 이는 SimCLR의 방법론을 따온 것입니다.
FVE까지 거친 feature는 h이고, 이를 projection(=g(h))하여 z를 만드는 것인데, g(h)의 nonlinear transformation을 통해 얻은 z는 contrastive learning에만 사용되고, 실제 downstream task를 수행하기 위한 feature는 h를 사용합니다.
더 자세히 설명드리자면, h는 transformation 관련 정보를 더 많이 가지고 있어 spatial transformation에 잘 대응할 수 있기 때문에 downstream task에 바로 사용되고 , z는 이러한 h에 MLP를 태움으로써 공간적 정보들을 잃지만 오히려 그에 강인한 표현력을 가지기 때문에 contrastive learning에 사용된다고 이해하시면 좋을 것 같습니다.
좋은 리뷰 감사합니다.
해당 방법론에서 제안한 Sequence Contrastive Loss는 유사도가 가우시안 분포를 따라 가까울수록 유사도가 높고, 멀수록 작아진다는 가정을 두고 제안 된 Loss로 이해하였습니다. 따라서 이러한 가정을 뒷받침하는 근거가 있는지 궁금합니다. 그림 4에 나타난 보라색 막대 그래프를 통해 단편적으로라도 이를 확인한 것으로 보아야 할까요??
또한, 해당 논문에서 영상이 어떤 단계에 해당하는지 분류한다고 하셨는데, 이러한 과정은 영상의 경계를 구분하여 이를 순서대로 나누는 것인지 각 단계에 해당하는 라벨도 맞추는 것인지 궁금합니다.
감사합니다.
논문에서는 말씀해주신 feature 간 유사도가 실제 가우시안 분포를 따른다는 수치적인 근거를 보여주고 있지는 않습니다. 보라색 막대 그래프도 단순한 toy example에 해당하기 때문에, 어느정도 위와 같은 가정을 깔고 그것이 잘 동작하는지 확인한 결과 정량적으로 높은 성능을 보이며 해당 가정이 맞았다는 것을 증명하는 흐름이었다고 이해하시면 편하실 것 같습니다.
Phase classification task는 각 프레임을 어느 단계 중 하나로 분류한 후 라벨을 맞췄는지 틀렸는지 분류 성능을 평가하는 ‘Classification’과, 예측값 중 실제 action 간의 경계를 얼마나 잘 맞췄는지 평가하는 Phase progression, ‘Progression’ 성능을 벤치마크 테이블에서 확인하실 수 있습니다.
안녕하세요 좋은 리뷰 감사합니다.
헷갈려서 질문하는데 V1, V2에 대해서 시간 축으로 random resize, crop, horizental flip 등을 해주는 것을 spatial augmentation이라고 표현한 것이 맞으시죠?
감사합니다
맞습니다
안녕하세요 좋은 리뷰 감사합니다.
해당 논문이 trimmed video에 대한 논문이라고 하셨는데 negative를 지정할때 동일하거나 주변 timestamp를 제외하고 gaussian 분포에 따른다고 이해했습니다. trimmed video에는 하나의 주제만 있는것으로 알았는데 혹시 제 이해가 틀렸는지 궁금합니다
trimmed video에는 하나의 주제만 등장하는 것이 맞지만, 예를 들어 Pouring dataset의 경우 ‘음료를 컵에 따른다’라는 큰 주제 아래 여러 단계(다른 representation이 필요)로 나눠지게 됩니다.
이 때 특정 프레임을 기준으로 인접한 프레임부터 멀어지는 프레임까지의 유사도는 가우시안 분포를 따를 것이라는 가정 하에 가까우면 큰 유사도, 멀수록 작은 유사도를 갖도록 표현력을 학습하는 방법론입니다.