Abstract
Active Learning(AL)이란 무엇인가요? 능동 학습으로 직역되는 AL은 사람이 모델에게 학습할 데이터셋인 training set을 구축하는 것 처럼 학습의 주체인 모델이 능동적으로 training set을 구축하여 학습을 진행하는 방식입니다. 따라서 AL은 unlabeled instances들에서 학습의 성능을 좋게할 데이터를 선별하는 것이 풀어야할 문제인데요, 본 논문에서는 모델의 표현에 대한 일관성을 근거로 unlabeled instances를 선별하는 방법론, ALFA-Mix를 제안했습니다. 제안하는 방법은 비교된 최근의 AL 방법론을 이기는 성능을 보였다고 하네요. 특히 low-data regimes(초기 labeled 데이터의 갯수가 적은 상황)와 self-trained vision transformers와 잘 작동한다고 합니다. 방법론을 살펴봅시다.
Related works
다양한 AL의 기존 접근법에 대해 알아봅시다. 크게 2 가지 방법론이 있는데요
- uncertainty based:특정 unlabeled instance가 얼마나 가치있는지(informative) 측정하는 방법
- distribution-based: 어떤 training set의 분포가 얼마나 다양한지 확인하는 방법
위의 두가지 관점으로 많이 연구되고 있습니다. 그러나 deep neural networks에 AL을 적용하려는 노력들은 high-dimensional data, low-data regime 문제들로 고통을 겪고 있습니다. 그 중에서도 모델 초기화시 하용하는 labeled data가 적어서 발생하는 low-data regime 문제를 다루기 위해 본 논문은 이용가능한 training data의 정보를 최대한 활용할 수 있는 방법을 제안합니다. 기존의 방법론처럼 model의 output만을 고려하는것이 아니라 feature mixing을 이용합니다. 이는 model output과 gradient를 사용하여 데이터의 가치를 판단하는 BADGE[1]에서 영감을 받았는데 gradient 를 직접 사용하여 연산량을 높이는 [1]과 다르게 feature를 mixing하는 방식으로 연산량을 줄였다고 합니다.
Concept
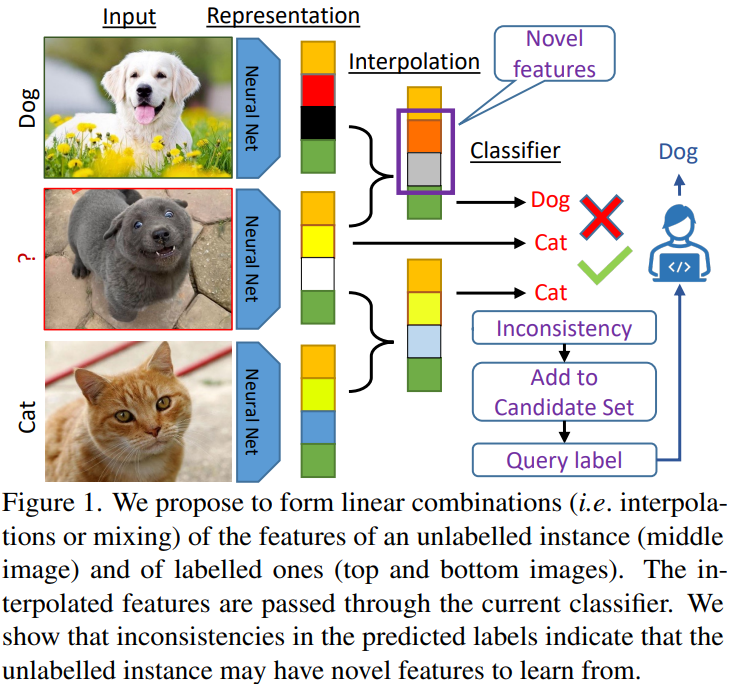
본 논문에서는 새롭고 효율적인 AL 방법론, Active Learning by FeAture Mixing (ALFA-Mix)를 제안합니다. 해당 방법은 unlabeled instances의 정보량(informative)을 측정하기 위해 교란된(변형을 가한, perturbed) 버전의 입력에 대한 예측 변동성을 이용합니다. 즉, 특정 unlabeled instances에 다양한 변형이 가해지더라도 같은 값으로 예측할 만큼 해당 데이터에 대한 확신(uncertainty)이 있는지에 대해 측정하는 uncertianty-based methods의 한 갈래와 유사합니다.
그렇다면 이 교란(perturbed)은 어떻게 가하게 될까요? 이미지를 직접 변형하는게 아닌, 논문의 제목에 들어나있듯이 feature mixing을 통해 perturbed를 진행합니다. 조금 더 자세하게 말씀드리겠습니다. Figure 1을 참고해주세요.
본 방법론은 perturbed versions의 feature(Figure1의 Novel features에 해당합니다)를 만들기 위해 labeled 와 unlabeled instances을 convex combinations 합니다. convex combinations이란 interpolation으로도 불리는 feature mixing방법으로 기존 연구에서도 종종 사용되었다고 합니다. (이에 대한 자세한 방법은 method에서 확인해봅시다.)
Methods
- Notation
a deep neural network: f = f_c(classifier) + f_e(encoder)
networks parameters: θ = {θ_e, θ_c}
f_e: X → R_D
f_c: R_D → R_K (K is the number of classes)
z=f_e(x) / y=f_c(z)
- Feature Mixing
앞서 new feature, perturbed versions features를 만들기 위해 feature mixing을 제안했으며, 이는 labeled instances와 unlabeled instances의 feature를 convex 결합한 것이라고 간단하게 소개했습니다. new feature를 이용해 모델의 확신도를 측정하고자하는 시도는 결국 모델의 잘못된 예측의 원인이 인식하기 어려운 새로운 feature 때문이라는 가정을 기반합니다. 매우 직관적이죠.
보간의 식은 다음과 같습니다. 0~1 스케일을 갖는 가중치 α를 이용해 unlabeled feature(z_u)와 labeled feature(z_*)를 합하는 단순한 방법입니다.
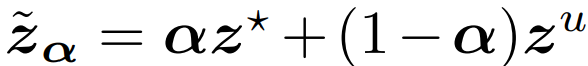
이때 labeled instances를 anchor로 하며 unlabeled instances들은 모든 anchors들을 이용해 unlabeled instances를 interpolatings(=feature mixing)합니다. 이렇게 생성된 new features에 대해 pseudo-label(y_*)를 생성하며 loss를 계산하며 loss 계산 식은 다음과 같습니다. unlabeled instances에 대해 최종적으로 pseudo label 값으로 예측하도록 하며 labeled data를 통해 보간한 small part가 최종 pseudo label에 영향을 미치지 않는다고 가정하여, new features에 대해서도 같은 pseudo label로 예측하도록 loss를 계산합니다. 따라서 α는 충분히 작아야겠죠.
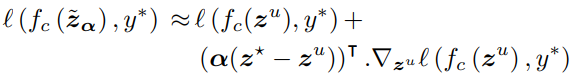
- Finding α
앞서 말씀 드린것처럼 α는 충분히 작은 수 이므로 e(hyper-parameter)보다 작다는 기준이 있습니다. 따라서 e보다 작은 범위 내에서 최적값을 찾게됩니다. 수식은 아래와 같은데, 앞선 loss 식의 2번째 식(r.h.s=right hand side)과 같습니다. 즉 이 r.h.s를 최대화 하는 α를 찾게되는것인데요 feature mixing에 대한 영향력을 범위(e) 내에서 최대화하기 위한 접근이라고 이해하시면 됩니다.
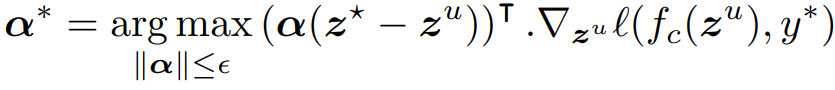
또한 위의 수식을 연산가능하도록 변형한것은 아래와 같습니다. 두 수식은 의미적으로는 같다고 생각하시면 됩니다.
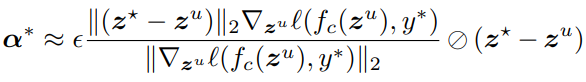
- Candidate selection
본 논문의 최종적인 데이터 선별 수식은 아래와 같습니다. 먼저 아래의 수식을 통해 예산 B보다 많은 후보 I를 선정하고, 이후 K-means 알고리즘을 통해 B개의 그룹으로 clustering하여 B개의 instances를 최종 선별합니다.
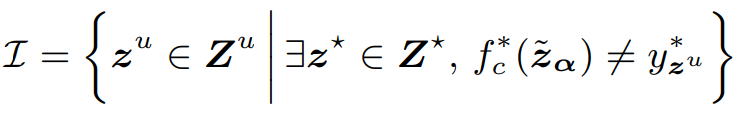
- Algorithm

Proof

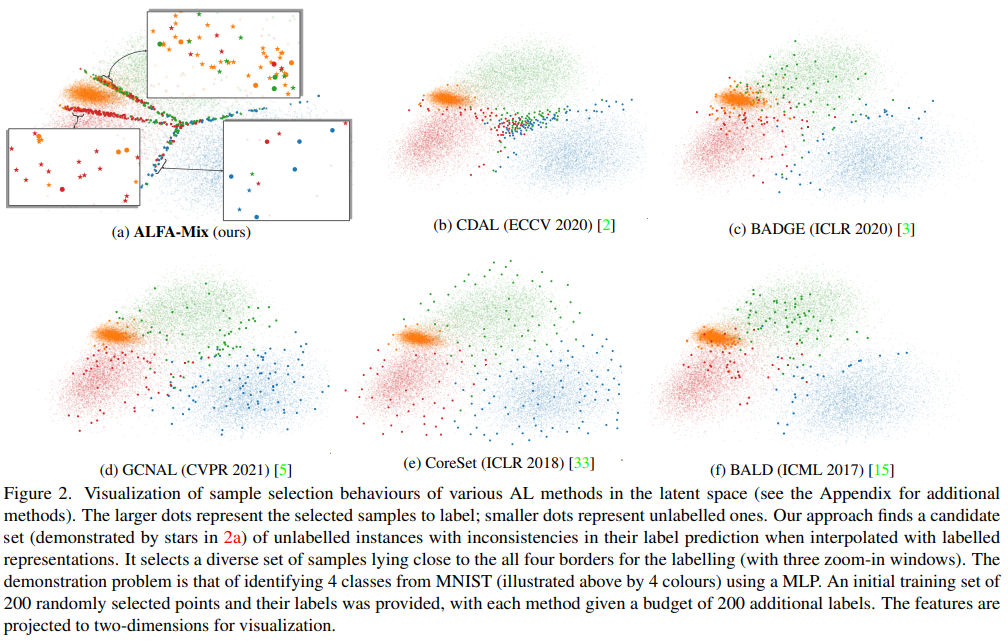
실험의 비교에 사용된 방법론들은 다음과 같다 uncertainty 기반의 방법론인 BALD, Adversarial Deep Fool와 distribution 기반의 Coreset, hybrid 방법론인 BADGE, CDAL 등이 있다. GCNAL은 model 기반 방법론이며 앞선 Figure2를 보았을때 분포를 반영하는 distrubution 기반과 유사하다고 볼 수 있다.
실험은 MNIST, Mini-ImageNet, DomainNet-Real 등에 적용하였으며 실험 결과는 아래와 같다.
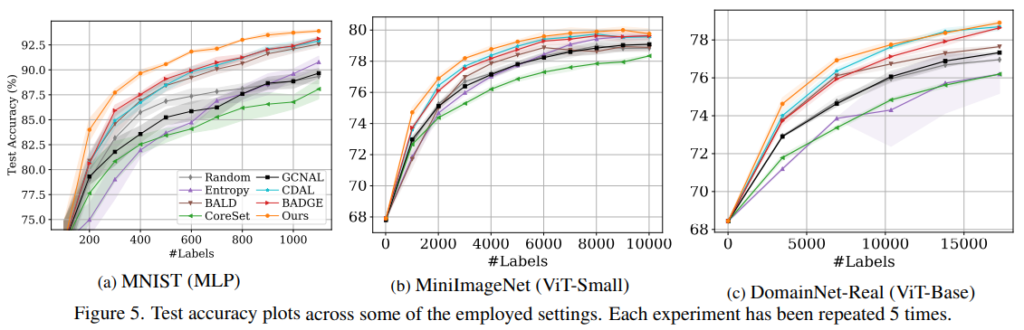
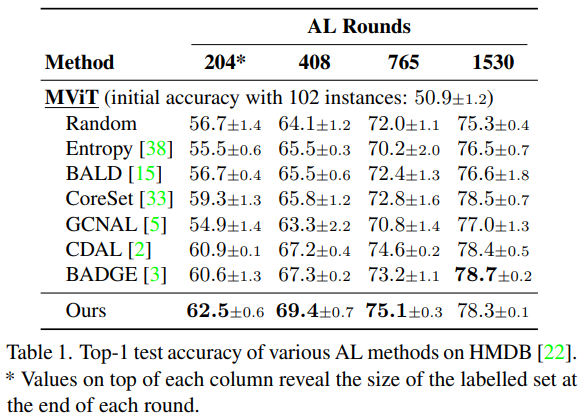
뿐만 아니라 HMDB 데이터셋에 대해 activity recognition을 진행하였는데 그 결과는 아래와 같다.
Reference
[1] Deep Batch Active Learning by Diverse, Uncertain Gradient Lower Bounds
안녕하세요 황유진 연구원님, 좋은 리뷰 잘 읽었습니다.
해당 리뷰를 읽고 제가 이해한 바에 따르면 다음과 같습니다.
active learning은 학습시킬 데이터를 선별하는 과정이며, 학습의 주체인 모델이 능동적으로 training set을 구축하여 학습을 진행한다. 따라서 AL은 학습 성능 향상에 크게 기여할 수 있는 데이터를 선별해야 한다.
기존 AL의 대표적인 접근법 2개로는 :
1. uncertainty based: 특정 unlabeled instance가 얼마나 가치있는지(informative) 측정하는 방법으로, 모델이 확실하게 예측하지 못하는 데이터를 고가치 데이터로 판별.
2. distribution-based: 어떤 training set의 분포가 얼마나 다양한지 확인하는 방법.
이 있다.
제안된 Active Learning by Feature Mixing 방법은 Low-data regime(모델 초기화시 사용하는 labeled data가 적은 상황)과 self-trained vision transformers와 잘 작동하며, 기존 방법론들(BALD, Adversarial Deep Fool, Coreset, BADGE, CDAL)에 대해 SOTA를 달성했다는 contribution이 있다.
Active Learning by FeAture Mixing 은 unlabeled instances의 정보량(informative)을 측정하기 위해 교란된(변형을 가한, perturbed) 버전의 입력에 대한 예측 변동성을 이용하며, 교란(perturbed)을 가하는 방법으로 feature mixing을 사용한다.
Feature mixing은 labeled instances와 unlabeled instances를 convex combinations(interpolation)으로 진행한다.
new feature를 이용해 모델의 확신도를 측정하려는 시도는 모델의 잘못된 예측의 원인이 인식하기 어려운 새로운 feature 때문이라는 가정을 기반으로 한다.
해당 리뷰에 대해 제가 올바르게 이해한 것인지 궁금합니다.
리뷰를 읽다보니 다음과 같은 궁금증이 생겼습니다.
figure2에서 latent space의 sample selection visualization을 보면, ALFM 방식은 데이터가 특정 구간에 상당히 뭉쳐있는 것처럼 보입니다. uncertainty 기반 방법론이 데이터 편향성을 보이는걸로 알고 있는데 이보다 ALFM의 데이터 분포가 더 뭉쳐있는 이유와(K-means를 기반으로 클러스터링했기 때문일까요?), 데이터 편향에 의한 문제점을 논문에서는 다루지 않는지 궁금합니다.
우선 이해한 내용을 적어주신것에 틀린 정보는 없는것으로 판단됩니다!
선별된 데이터가 결정경계에 가까운, uncertainty가 높은 데이터를 다수 선별함을 알 수 있습니다.
이는 feature 정보량을 증폭해 학습을 하여 각 class의 대표성을 충분히 학습해, 쉬운 데이터에 대해 uncertainty가 낮다고 잘 계산했다고 이해할수도 있습니다. 따라서 데이터 편향이라기 보다는 uncertainty 측정이 잘 되었다고 볼 수 있습니다.
안녕하세요 황유진 연구원님 좋은 리뷰 감사합니다.
어떻게 feature를 혼합할 생각을 했는지 참 신기함이 드네요.
그런데 feature를 혼합하는 기준에 대해 설명해주실 수 있을까요?
labeled와 unlabeled 를 혼합할 때 클래스는 고려하지 않는지 궁금합니다. 가령 A라는 클래스에 속할 확률이 큰 unlabeled sample만 골라서 클래스 A를나타내는 labeled sample과 결합하는 것인지 그 결합의 기준이 궁금해지네요.
그리고 혹시 해당 논문은 ViT를 Backbone으로 사용하는 건가요?
그림 5에서 (MLP) (ViT) 의 차이가 무엇인지도 궁금합니다.
1. feature 혼합을 위해 labeled data의 각 클래스를 대표하는 Z*를 생성하고 해당 대표 feature를 이용해 new feature를 생성합니다.
2. 그림5의 MLP와 ViT는 backbone 차이를 의미합니다.