제가 이번에 리뷰할 논문도 Cross-view Geo-localization 논문입니다. 제가 이 논문을 리뷰하게 된 이유는, 해당 논문이 해결하고자 하는 것이 두 영상의 FoV 차이 문제인데 열화상과 RGB 영상도 FoV 차이가 발생할 수 있고, 이를 해결하고자 하는 방식이 어떻게 보면 두 영상이 공유하고있는 시야에 차이가 있을 경우에 적용 가능하지 않을까 하는 생각이 들어 이 논문을 리뷰하게 되었습니다.
Cross-view Geo-localization은 도로 뷰와 항공 뷰 이미지 간의 retrieval을 수행하는 태스크 입니다. 이 논문은 사람이 영상을 이해할 때, 영상에 나타난 물체를 고려할 뿐만 아니라 일부분이 보이는 랜드마크도 고려하여 영상을 이해한다고 합니다. 특히 항공뷰는 360°의 FoV(fiedl of view)를 가지고 도로 뷰 영상은 제한된 FoV를 가진다는 특징이 있어 이를 해결하는 것이 중요하다고 이야기합니다. 그러나 기존의 연구들은 위치를 알고자 하는 쿼리 영상(도로 뷰)의 local feature를 이용한 매칭을 이용하였고, 이는 랜드마크와 같이 중요한 부분이 일부만 보이거나 항공 뷰 이미지의 중요한 정보가 나무 등으로 가려진 경우 부적절하다고 합니다. 따라서 저자들은 local한 속성과 global한 속성을 모두 고려하는 방법론을 제안하였습니다. global 정보를 추론 한 다음, local 정보와 융합하여 두 도메인간의 매칭을 위해 공동의 representation을 이용하는 방식으로, 저자들의 주장으로는 처음으로 global-local representation을 함께 학습하는 방식이라 합니다. 또한, 데이터 증강 기법도 제안하였다고 합니다.
본 논문의 contribution을 정리하면
- Cross-view Geo-localization을 위해 공동의 representation (local-global)을 학습하는 방식을 제안하여, 전체적인 장면을 이해하고 매칭을 할 수 있도록 함.
- 새로운 데이터 증강 기법을 제안하여 빠른 추론이 가능하도록 함.
- 실험을 통해 CVACT(cross-view localization에 많이 사용) 데이터셋에서 성능 향상을 확인하였고, SOTA를 달성함.
Approach
1. Siamese framework for geo-localization
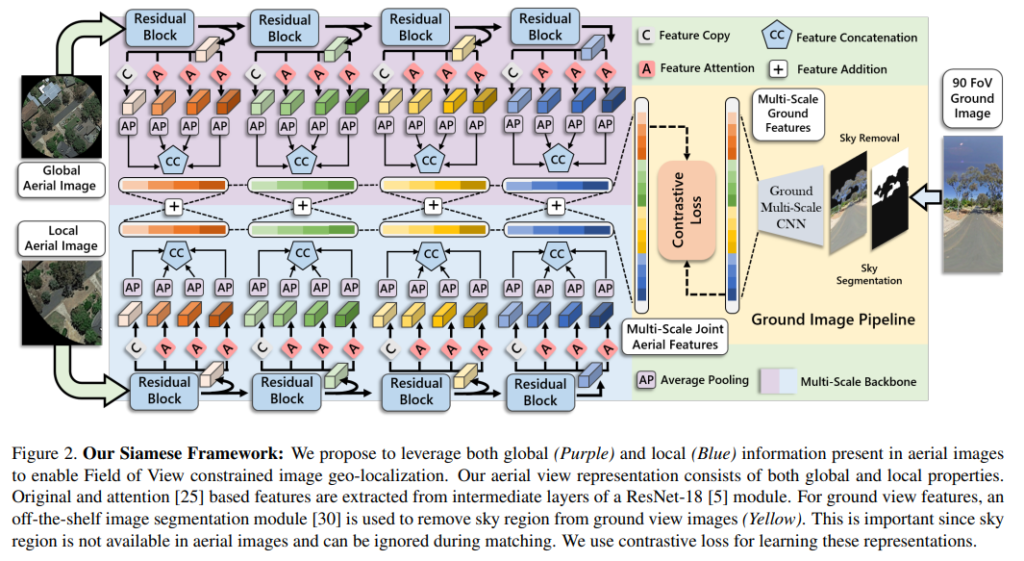
위의 그림2가 전체적인 파이프라인을 나타내는 그림으로, Siamese 네트워크 파이프라인을 이용하여 항공 뷰 이미지로부터 global한 feature를 추출한뒤 파이프라인에 통합하여 FoV에 제약이 있는 이미지(도로 뷰, 쿼리 이미지)에 영상 이해에 활용한다고 합니다.

위의 그림3은 입력 이미지에 대한 정보로, FoV가 각각 90°/70°일 때의 도로뷰 영상(I_g)과 전체 항공 영상(I_{ag}), 항공 영상에서 제한된 FoV를 보는 영상(I_{al})이 있습니다.
Objective Function
학습에는 metric learning 함수를 이용하여 positive pair는 가까워지고 negative pair는 서로 멀어지도록 global-local representation을 함께 학습하였다고 합니다. (아래 식)
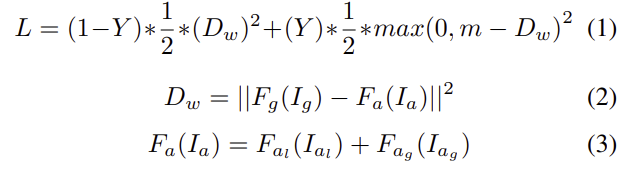
여기서 m은 미리 정한 margin, F_g는 도로 뷰 영상 I_g로부터 feature를 추출하는 feature extractor, F_a는 항공 뷰 영상 I_a로부터 공동의 global-local feature를 추출하는 feature extractor입니다. 또한,F_{al}은 local한 항공 이미지 I_{al}로부터 local한 feature를 추출하는 함수이고, F_{ag}은 global한 항공 이미지 I_{ag}로부터 global한 feature를 추출하는 함수를 의미합니다. 공동의 global-local feature는 F_{al}(I_{al})과 F_{ag}(I_{ag})를 합친 것(식 3에 해당)이고, Y는 positive인지 negative인지를 나타내는 이진값, D_w는 도로 뷰 영상과 항공 뷰 영상의 representation의 거리의 제곱 오차를 나타냅니다.
Multi-scale CNN backbone
여러 해상도에서의 특징을 추출하기 위해 multi-scale CNN 백본을 이용하였다고 합니다. 백본으로 ResNet-18을 이용하였고, attention 매커니즘을 활용하여 여러 스케일에서 feature를 추출하였다고 합니다.(위의 그림2 참고) attention은 채널 축과 공간 축으로 모두 적용을 하였고, 각 스케일마다 원본 feature 하나와, attention을 적용한 feature 3개를 구하였다고 합니다.
2. Orientation robust data augmentation
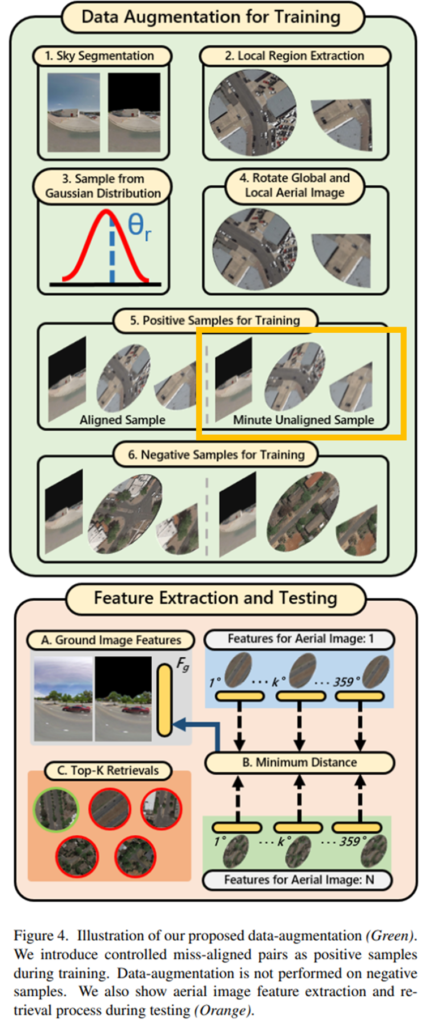
본 논문의 contribution 중 하나인 데이터 증강 기법에 대한 설명입니다. 이미지의 align이 잘 맞지 않는 문제가 있어 기존의 방법론들은 다른 방향으로 여러번 feature를 추출하였다고 합니다. 여러 방향에서 feature를 추출하는 방식은 연산량이 증가한다는 문제가 발생하고, 이는 방향에 강인한 geo-localization을 통해 줄일 수 있다고 합니다. 저자들은 훈련 과정에 의도적을 alignment가 맞지 않는 영상을 positive pair로 이용함으로써 정렬되지 않은 샘플과 매칭을 하도록 하였다고 합니다. (그림4의 노란색 박스 친 부분이 이에 해당함. ) miss-alignment는 평균값이 0인 가우신안 random 변수의 분산 파라미터 σ를 이용하여 강도롤 조절한다고 합니다.
Experiment
실험 파트로, 제안한 방법들의 효과를 CVUSA와 CVACT 데이터셋으로 평가하였다고 합니다. 실험을 통해 주변 랜드마크를 추론할 수 있음을 확인하였다고 합니다.
Dataset
CVUSA와 CVACT 데이터셋은 35,532개의 train 크로스 뷰 이미지 쌍과 8,884개의 test 이미지 쌍으로 구성되어 있다고 합니다. 이때 도로 뷰 영상은 파노라마이미지로 구성되어있으나, 저자들은 FoV가 작은 상황에서도 잘 작동하는지 확인하기 위해 FoV를 조절한 이미지를 생성하였다고 합니다.
Comparision with SOTA
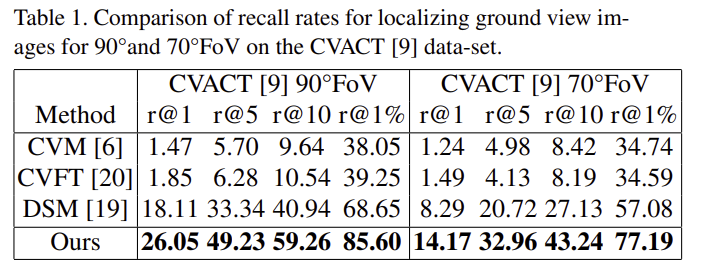
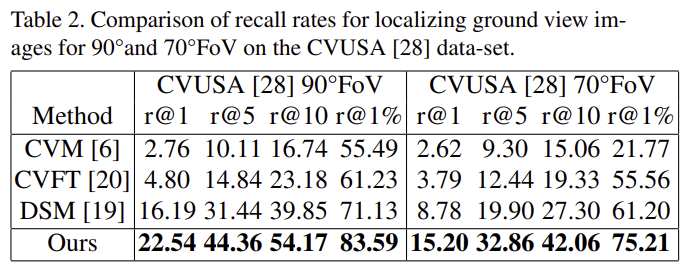
위의 표1과 표2는 각각 CVACT 데이터와 CVUSA 데이터에 대한 SOTA 방법론과의 정량적 비교 결과입니다. 두 데이터셋 모두 FoV가 90°, 70°일 때, 모두 SOTA를 달성하였습니다.
아래의 그림은 정성적 결과로, 그림에 잇는 <는 영상의 FoV를 의미합니다.

Ablation study
CVACT 데이터셋에서 ablation study를 수행하였다고 합니다.
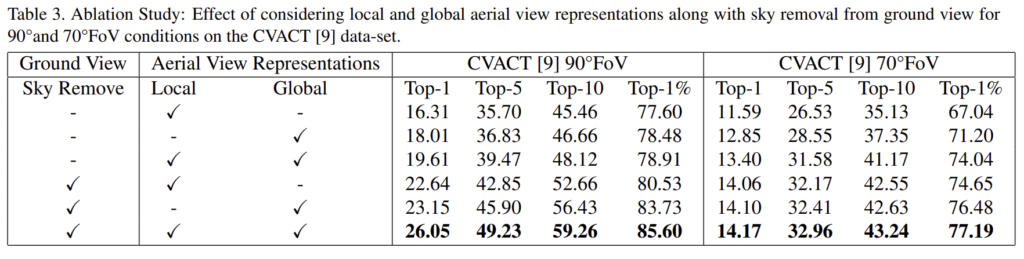
- Effect of sky removal: 항공뷰 영상은 하늘에 해당하는 영역이 없으므로, 도로 뷰 영상에서 하늘에 해당하는 영역을 0으로 처리할 경우 성능이 향상되었다고 합니다. (표3)
- Effect of global and local aerial features: global feature만 이용하는 것이 local feature만 이용하는 것 보다 성능이 좋았으나 모두 다 사용하는 것이 가장 성능이 좋았다는 것을 실험을 통해 보였습니다.(표3)
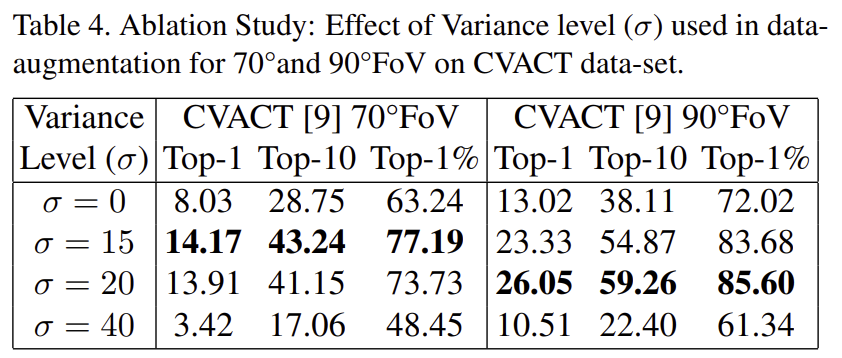
- Effect of variance strength (σ): positive 샘플에 align이 맞지 않는 쌍을 넣을 때, 그 강도를 σ로 정하였는데, σ에 따른 성능을 비교하였다고 합니다. 70°는 15, 90°는 20으로 설정한 값에서 가장 좋은 성능을 얻었고, 90°보다 70°에서 더 작은 이유는 FoV 자체가 작으면 겹칠 수 있는 영역이 줄어들기 때문이라고 합니다.(표4)
Large Field of View Image Geo-localization
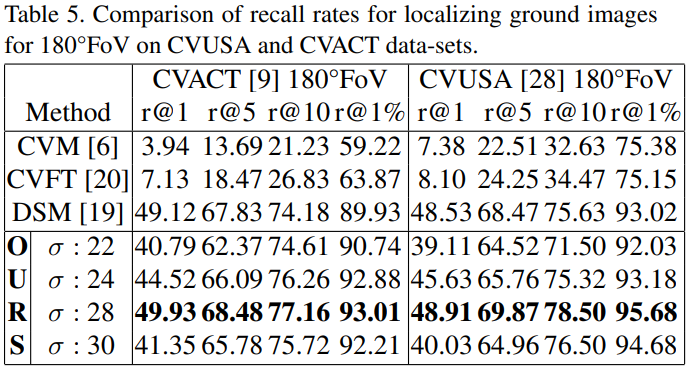
아래의 표5는 180°의 FoV를 갖는 경우에 대한 실험 결과로 SOTA 방법론과 비교했을 때 차이가 크지는 않았다고 합니다. 또한 σ값에 크게 영향을 받는 것을 확인할 수 있었습니다.
안녕하세요. 좋은 리뷰 감사합니다.
Table 1을 보면 CVACT[9] 70도FoV에서 성능 보면 CVM, CVFT, DSM이랑 성능 차이가 아주 많이 나는 것을 확인할 수 있습니다. 이렇게 성능 차이가 많이 나는 것은 거의 처음봐서 그런데 승현님께서는 이 이유가 모델의 어떤 부분 때문에 차이가 많이 나는 것이라고 생각드시나요??
감사합니다.
Table5의 경우 동일한 방법론들로 실험을 수행하였고, Table1과 table 5의 차이는 도로뷰 영상(쿼리)의 FOV입니다. Table1의 결과는 아무래도 시야각이 작아 약간만 틀어져도 겹치는 영역이 급격히 줄어들며 기존 방법론들은 이에 대한 고려를 하지 않았기 때문에 크게 성능이 차이가 난 것으로 보입니다. (해당 논문은 공중 영상도 특정 각도를 보는 경우와 전체를 보는 경우를 고려하였으며, positive pair의 항공뷰 영상도 각도를 돌려가며 학습하는 방법도 활용하여 이러한 상황에 대처하고자 하였습니다.)
안녕하세요 승현님 좋은 리뷰 감사합니다.
본 리뷰에서 global은 항공뷰 local은 FoV에 제약이 있는 이미지(도로 뷰, 쿼리 이미지) 로 사용되고 있는것이 맞는지요 ㅎㅎ 그렇다면 object function을 보시면 항공뷰 global, 항공뷰 local, 도로 뷰 모든 입력에 대해 각자 feature extractor가 하나 씩 있는 것인가요?
object function에서 positive와 negative를 구성하는 방법이 궁금합니다. 같은 부분에서 촬영 각도가 다른 부분을 positive 로 이용한다는 뜻인가요..?
본 논문 예시를 보면 나무와 같은 가변적인 물체에 대한 실험을 진행하기는 했지만 정확히 어떤 위치를 매칭점으로 잡고 있는지 궁금하네요.. 해당 시각화가 가능한지 궁금합니다
우선 해당 논문은 제한된 FoV를 갖는 도로뷰 이미지와 일반적인 항공뷰 영상(global )과 도로뷰와 동일한 영역을 보는 항공뷰 영상(local, 그림3의 Local 90 FoV와 Local 70 FoV에 해당) 3가지를 한쌍의 입력으로 이용합니다. 또한 말씀하신대로 3가지 영상이 각각 CNN을 통과하여 feature를 추출합니다. 다만 항공뷰 영상은 global과 local을 합친 공통의 feature라 세 영상이 각각의 feature extractor를 가진다고 할 수 있는지는 모르겠습니다..
positive와 negative를 구성하는 방법에 대해 질문해주셨는데, 저자들은 GPS 정보를 기반으로 Positive와 Negative를 구분하는 것으로 보입니다.
또한, 아쉽게도 매칭을 시각화 한 결과가 없습니다..
#
안녕하세요 이승현 연구원님, 좋은 리뷰 감사합니다.
결국 항공뷰 라는 데이터셋의 특성을 반영한 연구라고 볼 수 있을 것 같은데요. 그런데 연산량 증가의 이유로 여러 방향에서 feature를 추출하는 방식을 사용하지 않은 부분 중 “저자들은 훈련 과정에 의도적을 alignment가 맞지 않는 영상을 positive pair로 이용함으로써 정렬되지 않은 샘플과 매칭을 하도록 하였다” 라는 부분에 대해 예시를 함께 설명해주실 수 있나요? 1도 와 359도를 동시에 제공한 것이라고 생각하면 되나요?
학습 과정에서 우선 positive와 negative pair sample을 구축합니다. 이때, negative는 그대로 두고, positive 영상의 항공뷰는 가우시안 분포를 이용한 랜덤 함수만큼 rotation을 시킵니다. 이후, 정해진 각도에서 영상을 잘라 local 항공뷰를 만들어내게 됩니다.
이렇게 하면 도로뷰 영상이 바라보는 영역과 local 항공 뷰 영역이 달라지게 됩니다. align이 맞지 않는 데이터로 모델을 학습함으로써, test 과정에도 align이 맞지 않아도 retrieval이 잘 되도록 한 것으로 보입니다.
안녕하세요 ! 좋은 리뷰 감사합니다
데이터 증강 기법 부분에서 학습에 사용되는 데이터셋의 global 한 항공뷰 이미지와 local한 항공뷰 이미지 사이에 misalignment가 나타나는데 이를 align을 맞추는 과정을 거치는 것이 아니라 의도적으로 positive pair로 사용한다는 것으로 이해하는 것이 맞을까요 ?
SOTA 방법론과 비교한 실험 결과에서 같은 데이터셋에서 FoV 70과 90 모두에서 성능이 크게 올라가는 것을 보고 모든 FoV에서 같은 경향성을 가지는건가 생각한 것에 비해 마지막 Table5에서 FoV가 180까지 커졌을 때는 기존 방법론과 큰 차이가 없는데 이런 결과에 대해 어떻게 생각하시는지 궁금합니다
댓글 감사합니다.
우선, global한 항공뷰와 local한 항공뷰는 근본적으로 동일한 이미지에 대해 전체 영역을 사용하느냐, 일부 영역을 사용하느냐에 따라 달라지는 것이므로 misalignment가 나타난다고 하기는 어렵습니다. 여기서 이야기하는 misalignment는 항공뷰 이미지와 도로뷰 이미지간의 misalignment를 의미합니다.
또한, 두번째 질문에 대해서는 논문이 목적으로 한 것이, 작은 FoV를 가져도 잘 작동하도록 네트워크와 학습과정을 설계하였기 때문이라고 생각합니다. 리포팅되어있는 기존 방법론들은 FoV가 작아 겹치는 영역이 작아진다는 상황을 가정하지 않았고, 저자들의 방법론은 작은 FoV에도 잘 작동하도록 하기 위해 학습 과정에 misalignemt를 주는 등의 방식으로 학습을 하였기 때문에 이러한 상황에 대비가 되어 큰 성능 차이가 발생하였다고 생각합니다.