이번에 소개드릴 논문은 CVPR2022에 게재된 SimMIM이라는 논문입니다. 논문에서 다루는 task는 Masked AutoEncoder + Self-supervised Learning이며 방법론 자체에 큰 아이디어가 있다기 보다는 SSL based MAE에 대한 흔히 할 수 있는 생각들에 대해 직접 다양한 실험을 진행하며 더 단순하고 쉬운 MAE 방법론을 제안한 논문입니다.
Intro
본 논문의 시작은 Self-supervised Learning에서 pretext task로 image inpainting을 수행하게 된 계기 및 해당 컨셉이 NLP와 Vision에서 어떻게 활용되었는지, 왜 Vision 분야에서는 그동안 NLP 분야와 달리 좋은 성능을 보이지 못하였으며 지금은 왜 잘 보이는지 등에 대한 전반적인 설명을 다루고 있습니다. SSL 기반 MAE 분야쪽에 대해 관심은 있었지만 어디서부터 봐야할지 잘 모르시겠는 분들은 “masked autoencoder are scalable visual learners” 논문을 읽으셔도 되지만, 본 논문으로 시작해도 괜찮을정도로 인트로의 요약이 잘 정리되었습니다.
아무튼 Intro 내용을 요약하면 다음과 같습니다.
- 창조할 수 없는 것에 대한 것은 이해할 수도 없다는 개념으로, 모델이 마스킹된 영역에 대한 이해가 충분하다면 생성도 할 수 있을 것이라는 가정 아래에 pretext task로 masked signal modeling이라는 것이 제안됨.
- NLP는 이러한 컨셉을 활용해 상당히 큰 이점을 얻고 있지만, Vision 분야에서는 예상보다 기대에 못 미치는 효과를 봤었음. 이러한 결과가 나오게 된 계기로 3가지 이유가 있다고 합니다.
- 먼저 NLP는 상당히 high level의 semantic information을 담고 있지만, Vision 분야는 매우 low level의 semantic information을 가지고 있다는 점.(문장 내 단어 하나하나는 가지고 있는 의미가 상당히 크지만, 이미지 내 픽셀 하나하나는 가지고 있는 의미가 상당히 적음.) 이런 관점에서 low level information을 예측하는 것이 과연 high level information을 요구하는 visual task 수행에 이점이 있을까? 라는 의문.
- NLP와 달리 Vision 분야에서 이미지는 상당한 locality를 가지고 있음. 즉 주변 이웃 픽셀들이 모두 비슷한 정보를 가지고 있기 때문에, 마스킹된 영역을 보완하는데 있어 의미론적인 부분을 판단하는 것이 아닌, 주변 이웃 픽셀에 정보를 복사하여 복원하는 식으로의 학습이 진행되므로 처음 의도한 대로의 pre-training이 되지 않음.
- visual signal의 경우 연속적인 값인 반면, text token의 경우에는 이산적인 값임. NLP 분야에서의 성공적인 학습이 이 연속적인 데이터를 활용하는 visual signal에 어떻게 적용하면 좋을지에 대한 방법이 필요로 함.
- 먼저 NLP는 상당히 high level의 semantic information을 담고 있지만, Vision 분야는 매우 low level의 semantic information을 가지고 있다는 점.(문장 내 단어 하나하나는 가지고 있는 의미가 상당히 크지만, 이미지 내 픽셀 하나하나는 가지고 있는 의미가 상당히 적음.) 이런 관점에서 low level information을 예측하는 것이 과연 high level information을 요구하는 visual task 수행에 이점이 있을까? 라는 의문.
- 그래서 최근에 방법론들은 위에 내용들을 고려하여, 연속적인 컬러 정보에 대하여 컬러 코드북을 만든다거나, 추가적인 네트워크를 활용해 이산적인 토큰으로 만든다는 등 NLP 분야와 Vision 분야 간에 도메인 차이를 극복하여 Vision에서도 성공적인 사전 학습이 진행되도록 함.
- 하지만 본 논문에서는 이러한 흐름과 반대로 훨씬 단순한 프레임워크를 가지면서도 pretraining 효과는 좋은 방법론을 찾고자 하였으며, 그 결과 랜덤 마스킹의 비율, 마스킹 영역 복원을 위한 디코더 구조, regression 하는 값 자체 등등 다양한 측면에서 보다 간편하고 효율적인 방법들을 발견함.
인트로 내용은 다음과 같이 정리할 수 있을 듯 합니다. 보다 자세한 내용은 실험 섹션에서 다루도록 할게요.
Method
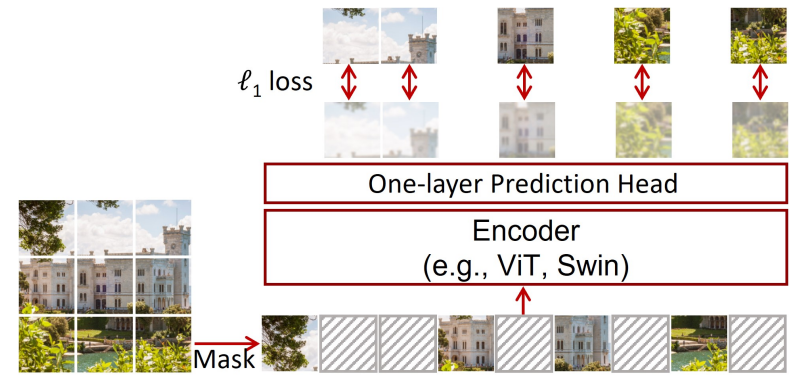
Masked Image Modeling(MIM)을 수행하는데 있어 전체 파이프라인은 크게 4가지로 나눌 수 있습니다.
- Masking strategy
- Encoder Architecture
- Prediction Head
- Prediction target
일단 마스킹 전략은 전체 영상에 대해서 몇 % 영역을 마스킹할 것인지에 대한 masking ratio, 마스킹을 하는 방식을 랜덤하게 할 것인지 정 중앙에 crop할 것인지 등등 마스킹 과정의 전반적인 부분들을 모두 masking strategy라고 봐주시면 될 것 같습니다.
또한 Encoder Architecture의 경우 보통 MAE에서는 Vision Transformer를 많이 활용하고 있기 때문에, 본 논문에서도 ViT와 Swin Transformer를 활용하였다고 합니다.
세번 째인 prediction head의 경우 앞서 Encoder를 통해 잘 만들어진 token들을 통해 마스킹된 영역들에 대한 복원을 수행하는 디코더 단계라고 보면 되겠습니다. 하지만 이후 내용에서 알 수 있듯이, 본 논문에서는 단순히 하나의 linear projection 만으로도 이 디코더의 역할을 수행하여 성공적인 pretraining을 할 수 있다고 주장합니다.
마지막으로 Prediction target은 pretext task로 마스킹된 영역을 복원할 때 어떤 대상을 복원하는 것으로 목표를 잡느냐는 의미입니다. 보통 일반적으로는 마스킹된 RGB 픽셀 값을 예측하는 것이 일반적이지만, 인트로에서도 말씀드렸다시피 RGB 픽셀 값들은 연속적인 값들이기 때문에 이들에 대해 후처리를 하여 군집을 형성한다거나, 이산적인 토큰으로 만들어 이들을 예측하도록 한다면 보다 더 유의미한 사전학습이 되지 않을까? 라고 생각하며 기존 연구들이 수행되었습니다.
하지만 본 논문에서는 단순히 raw rgb pixel 값을 예측하는 것만으로도 충분히 좋은 사전 학습이 된다고 하며, 오히려 후처리 과정이나 추가적인 네트워크를 필요로 하는 기존 방법들은 사전 학습 하는 과정에서 많은 연산량을 잡아먹는다고 합니다.
보다 자세한 내용들은 바로 아래에서 다루도록 하겠습니다.
Masking Strategy
먼저 마스킹 하는 방식 및 비율에 대한 실험들을 어떻게 진행하였는지에 대한 내용들을 확인해보겠습니다. 가장 처음으로는 patch-aligned random masking 방식이 있는데, vision transformer가 원래 영상 자체를 처음 patch 단위로 쪼개서 연산하기 때문에 이러한 패치 단위로 랜덤하게 마스킹을 하는 것을 의미합니다.(기존 MAE에서의 마스킹 방식과 동일하다고 보시면 될 것 같네요.)
본 논문에서는 ViT 뿐만 아니라 Swin Transformer 백본도 실험을 하고 있기 때문에 ViT의 경우에는 Default masked patch size를 32×32, Swin Transformer의 경우에는 4×4~32×32까지 다양하게 실험을 진행하였다고 합니다.
또한 다른 마스킹 방식으로는 이전 연구들 중에 central region masking, complex block-wise masking strategy 들이 있는데, 해당 방법론들에 대하여 마스킹 패치 사이즈의 16×16, 32×32으로 각각 설정하여 실험을 진행하였다고 합니다.

Prediction Head
Prediction Head의 경우 Encoder에서 타고 나온 feature map을 입력으로 삼아서 최종적인 reconstruction target을 추론하기 위한 레이어입니다. 일반적으로 기존의 연구들은 Auto-encoder 형식을 차용해 많은 레이어로 구성된 decoder를 만들어서 마스킹된 영역을 복원하는 것이 특징이었습니다.
하지만 본 논문에서는 앞에서도 말씀드렸다시피, prediction head를 매우 가볍게 만들어도 사전 학습을 하는데 있어 큰 성능 감소가 없다고 설명을 하며 여기서 말하는 매우 가볍게는 linear projection 1개만을 의미한다고 보시면 됩니다. 물론 비교 실험을 위하여 2-layer MLP, inverse Swin-T, inverse Swin-B 등 다양한 모델들로 실험을 진행하였다고도 합니다.
Prediction Targets
해당 섹션은 Pretext task로 마스킹된 영역을 복원하는 관점에서 어떤 값을 복원할 것인지에 대한 내용입니다. 가장 직관적이며 일반적인 경우는 마스킹된 영역의 RGB color pixel 값을 바로 regression하는 것입니다. 보다 디테일하게는 보통 ViT가 입력 영상의 해상도 대비 x16 다운 샘플링된 feature를, Swin Transformer와 같은 일반적인 backbone들은 입력 영상 해상도 대비 x32배 다운샘플링된 feature를 생성하게 됩니다.
이것을 다시 원본 영상의 해상도와 동일한 해상도로 맞는 3채널 RGB 영상으로의 복원을 위해서 1×1 convolution을 적용하여 3072 = 32 x 32 x 3 의 차원을 가지는 feature map을 만들어줍니다.
본 논문에서 또 한가지 실험한 점은 32배 다운샘플링된 feature map에 대해 위에서 설명드린 것처럼 1×1 conv layer 하나만으로 upsampling을 하는 경우 외에도, x4, x8, x16, x32배 다운샘플링된 multi-scale feature map에 대해서 원본 입력 영상을 down-sampling하여 비교하는 방식으로도 학습을 수행하였다고 합니다.
예측된 결과와 원본 raw rgb image 사이에 regression은 아래 수식과 같이 L1 loss를 활용하였습니다.
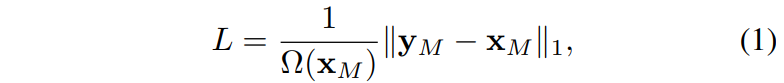
x와 y는 각각 input image, predicted value를 의미하며,M은 masked pixel을, 옴은 요소들의 숫자를 의미합니다. 본 논문에서는 단순히 L1 loss 뿐만 아니라 L2, Smooth L1 loss 등에 대해서도 실험을 진행하였다고 합니다.
Other Prediction Targets
위에서 말한것처럼 Raw rgb image 값을 곧바로 복원하는 방법 외에도 또 다른 target을 예측하는 방식들이 있을 수 있습니다. 가장 대표적인 방법들로 본 논문에서 실험한 종류들은 아래와 같습니다.
- Color Clustering – iGPT라는 논문에서, 상당히 많은 양의 RGB 데이터 셋에 대해 K-means clustering을 적용하여 512개의 color codebook을 만들었습니다. 즉 모델은 마스킹된 영역에 대응되는 color codebook을 예측하여 실제 raw rgb image의 code와 비교하는 방식으로 학습이 진행됩니다.
- Vision tokenization – BEiT라는 논문에서, discrete VAE(dVAE)라는 명칭의 네트워크를 활용하여 이미지를 dVAE token으로 변환하는 방법을 처음 제안하였습니다. 이 token은 마치 continuous 성질을 지니는 image의 특징을 nlp의 이산적인 토큰 방식처럼 적용하기 위함이며, 학습 목표도 마스킹된 영역에서의 Vision token과 실제 raw image의 vision token이 서로 같도록 학습하는 것을 의미합니다.
- Channel-Wise bin color discretization – R, G, B 각각의 채널들은 각각 별도로 구분을 지을 수 있는데, 각 채널을 동일한 bin(e.g., 8, 256 개)으로 이산화하는 과정을 의미합니다.
여기서 Color Clustering과 Vision tokenization은 각각 학습을 위한 전처리 과정(대용량 영상에서 codebook을 수집하는 과정 혹은 영상 토큰화를 위한 변환 모델의 사전 학습 과정)이 요구된다는 단점이 존재합니다.
Evaluation
그럼 이 논문의 메인 내용들이 담긴 실험 섹션에 대해서 다루고 리뷰 마치도록 하겠습니다. Ablation study에 대한 실험 설명을 드리기 전에 먼저 학습 및 평가 등등에 대한 실험 세팅에 대해서 가볍게 다루고 넘어가겠습니다.
본 논문에서는 Ablation study 실험에 Swin-B backbone을 default backbone으로 활용하였으며, 앞에 내용에서도 확인하셨따시피 본 논문은 상당히 많은 양의 실험을 ImageNet-1K에서 진행하기 때문에 실험에 들어가는 시간을 줄이고자 입력 이미지 해상도를 224×224가 아닌 192×192로 활용하였다고 합니다.
마스킹 전략으로는 마스킹 전략에 대한 ablation study 실험을 제외하고는 모두 random masking (32×32 patch size)를 default로 활용하였으며, 마스킹 ratio는 60%로 활용하였다고 합니다. 또한 linear prediction head를 통해 192×192 영상을 reconstruction 하였으며, 마스킹된 픽셀 예측의 목적 함수로 L1 loss를 활용하였습니다.
또한 평가는 ImageNet-1K에 대한 classification task를 fine-tuning하는 방향으로 진행합니다. 보다 자세한 학습 과정(옵티마이저, 에포크, lr, data augmentation 등등은 해당 논문의 Setting 서브 섹션을 참고 부탁합니다.)
Ablation Study – Masking Strategy
먼저 첫번째 실험은 마스킹 전략에 대한 Ablation study입니다. 결과는 아래 표 1과 같습니다.
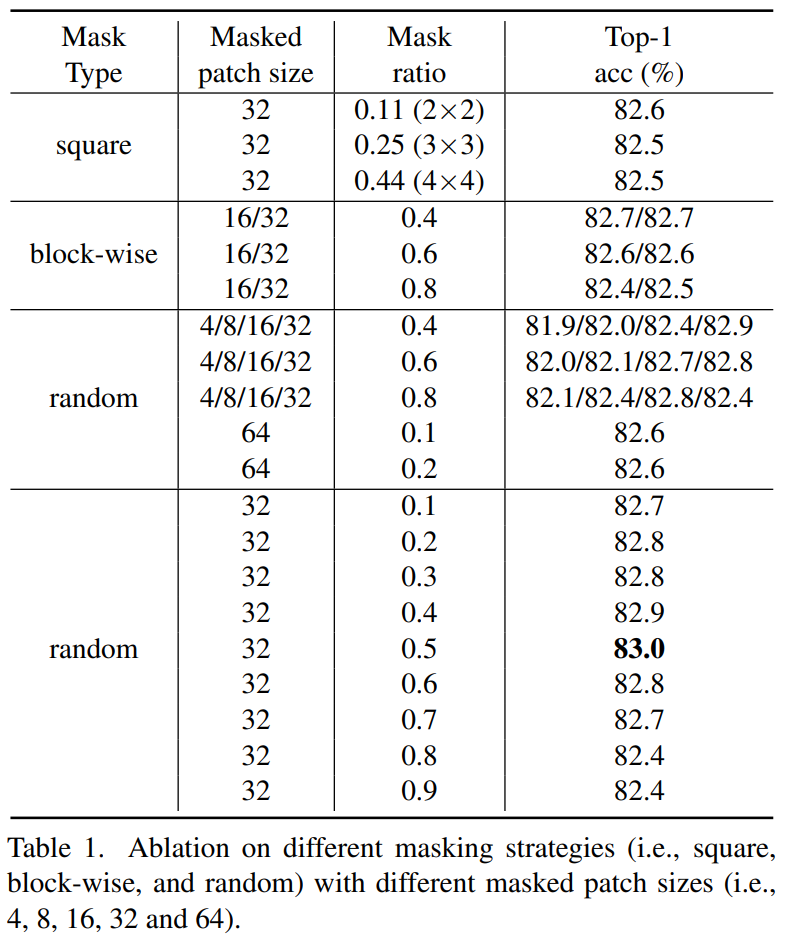
일단 이 표에 대하여 첫번째로 보셔야할 점은 본 논문에서 제안하는 방법이 random masking 전략을 취했을 때, 더욱 특별히 설계한 마스킹 기법들(예를 들면 block-wise 방식)보다 0.3% 더 좋은 성능을 보여주고 있다는 점입니다.
또한 두번째로는 masked patch size를 32×32로 꽤 높게 잡았을 경우 mask ratio가 0.2~0.7까지는 대부분 비슷비슷한 성능을 보여주면서 상당히 안정적으로 학습이 잘 된다는 모습을 보여주고 있습니다.
저자는 이러한 경향성이 나타난 이유로, 충분히 넓은 영역의 마스킹을 적용할 경우 마스킹된 패치 중심의 픽셀과 visible patch 사이에 적당한 거리가 유지되기 때문에, 모델이 주변 이웃 픽셀에 대한 정보만을 복사하는 식으로 학습하는 것이 아닌 더 넓은 영역에 대한 의미론적인 부분을 학습할 수 있기 때문이라고 주장합니다.
물론 이러한 관점에서 접근하였을 때, masked patch size를 줄이고 대신 masking ratio를 키우면 비슷한 효과를 볼 수 있다고 합니다. 이는 테이블 중앙에 random 4/8/16/32에 대하여 각각 0.4, 0.6, 0.8의 서로 다른 마스킹 ratio를 적용하였을 때 작은 마스크 크기를 가지는 실험들은 masking ratio를 0.4에서 0.8로 키웠을 때 성능이 증가하는 반면, 32처럼 마스킹 사이즈가 큰 경우 0.8 보다 0.4 마스킹 ratio에서 더 좋은 fine-tuning 성능을 보여주는 모습입니다.
불론 그렇다고 해서 마스킹 사이즈를 항상 키우면 좋은 것은 아닌게 64까지 키웠을 때는 마스킹 ratio를 0.1로 작게 하더라도 성능이 82.6의 애매한 성능을 달성하였다고 합니다.\
위에 표 1의 내용은 결국 마스킹된 patch의 중심으로부터 가장 가까이 있는 visible patch 혹은 pixel 사이에 평균거리(AvgDist)가 모델의 사전 학습에 상당히 중요한 요소이며, 이 평균거리는 마스킹 ratio의 비율 및 masked patch size를 통해 결정될 수 있다는 것입니다.
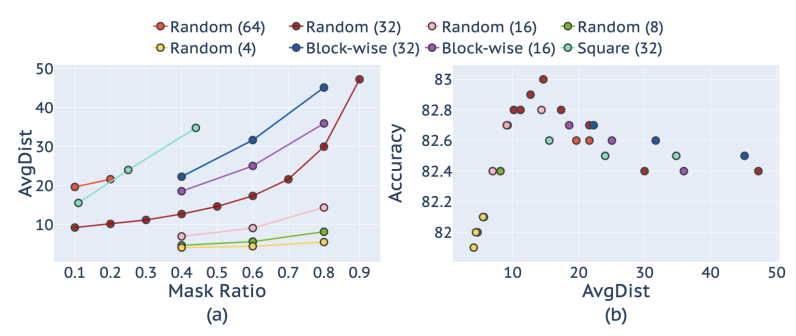
이러한 관점에서 저자는 표1의 관측치를 위에 그림3과 같이 AVGDist와 Mask Ratio(& patch size) 사이에 관계 그리고 Accuracy와 AvgDist 사이에 관계를 그래프로 나타내었습니다.
보시다시피 패치사이즈가 큰 경우 mask ratio를 낮게 설정하였음에도 불구하고 Avg Distance가 제법 큰 것을 볼 수 있으며, patch size가 4, 8로 상대적으로 작은 경우는 mask ratio를 0.8까지 했음에도 불구하고 AvgDist가 10 이하인 것으로 관측됩니다.
그리고 이러한 Avg Dist는 10 이하로 작을수록 fine-tuning 성능에 drop이 발생하지만 그렇다고 20 이상 높다고 해서 또 fine-tuning 성능이 큰 것은 아닌 것으로 관측됩니다. 결국 10~20 사이에 적절한 AvgDist를 가지는 것이 ImageNet-1K classification 성능에 한해서는 가장 좋은 모습을 보여주고 있긴 한데, 이게 또 패치사이즈에 따라서 성능 차이가 존재하기도 하니 대충 이러한 흐름이구나~ 라는 식으로만 이해하시면 좋을 듯 합니다.
Prediction Head
다음은 Prediction Head에 대한 Ablation study 결과입니다.
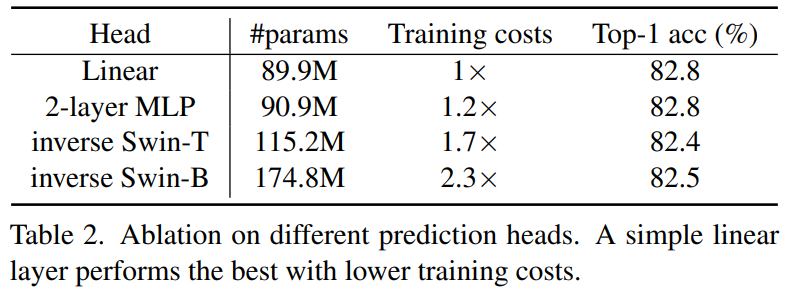
실험 종류로는 Linear Head(1 layer), 2-layer MLP, inverse Swin-T, inverse Swin-B 로 구성되어있으며, 점점 더 복잡한 구조로 가다보니 실제 학습에 필요한 파라미터 역시 89.9~174.8로 점차 커지는 모습입니다.
Linear와 inverse Swin-B의 경우 거의 2배 가까이 되는 학습 파라미터 양, 그리고 Training Cost가 차이남에도 불구하고 실제 down-stream task인 classification accuracy는 Linear model을 활용하는 것이 더 좋은 성능을 달성한 모습입니다.
즉 표2의 결과는 마스킹된 영역에 대해 보다 더 정확하게 reconstruction을 하는 것은 더 좋은 down-stream task 성능을 불러오는 것이 아니라는 것을 보여주는 좋은 결과 중 하나로 풀이됩니다. 이러한 결과가 나타나게 된 이유로 저자가 추측하는 바는, Decoder의 구조가 더 복잡해지게 되면 pre-training 과정에서의 masking된 영역을 복원하는데 encoder 대비 decoder가 차지하는 비율이 더 커질 것이지만, 결국 down-stream task에서는 decoder를 빼고 encoder만을 활용하기 때문에 성능 향상에는 큰 메리트가 없다는 것입니다.
즉 결국 우리가 사전 학습에서 원하는 것은 encoder한테 더 좋은 pre-training weight을 부여하는 것이지만, 디코더의 레이어 수가 증가하는 등 더욱 복잡해지게 되면 encoder에서 배워야할 좋은 의미들이 decoder로 분배될 수 있다는 점인 것이죠.
또한 2-layer MLP에 대한 실험은 옛날에 SimCLAR 논문이었던 것 같긴 한데.. 레이어를 1개만 활용하는 것이 아닌 2개를 활용하여 latent feature를 조금 더 pre-text target에 초점을 맞추어 학습을 시키게 되면 linear probing evaluation metric에서 큰 이점이 된다~ 라는 내용이 있어서 그 관측이 Masked Image Modeling에도 적용되는지를 판단하고자 해당 실험을 넣었다고 합니다. 근데 결과론 적으로는 성능에 유의미한 차이가 발생하지 않았기 때문에, 본 논문에서는 1-layer head를 default로 적용하였다고 하네요.
Prediction Resolution
다음은 Prediction Resolution 관련 실험입니다.
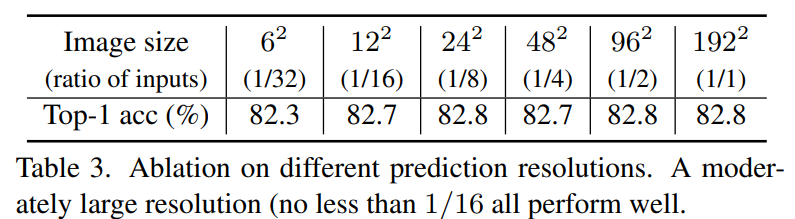
결론부터 요약하자면 6×6 사이즈를 제외하고는 모두 유사한 성능을 보였다는 점입니다. 결국 6×6은 너무 압축된 영상 해상도이기 때문에 복원 관점에서 너무 많은 양의 정보가 손실되어 좋은 학습이 어려웠다고 볼 수 있겠습니다.
근데 그렇게 따지면 12×12도 작은 사이즈인 것은 마찬가지기 때문에.. 해상도가 12×12 미만만 아니면 상관없더라 라는 식으로 치부하기에는 모호한 부분들이 많이 남아있습니다. 저자도 이를 의식하였는지 본 결과는 ImageNet Classification에 대해서만 실험한 것이기 때문에, Object Detection이나 Semantic Segmentation과 같은 task에서는 또 다른 결과가 나타날 수 있으며 future work로 남겨두었다고 언급하네요.
Prediction Target
다음은 Prediction Target에 대한 실험 결과로 표5에서 확인하실 수 있습니다.
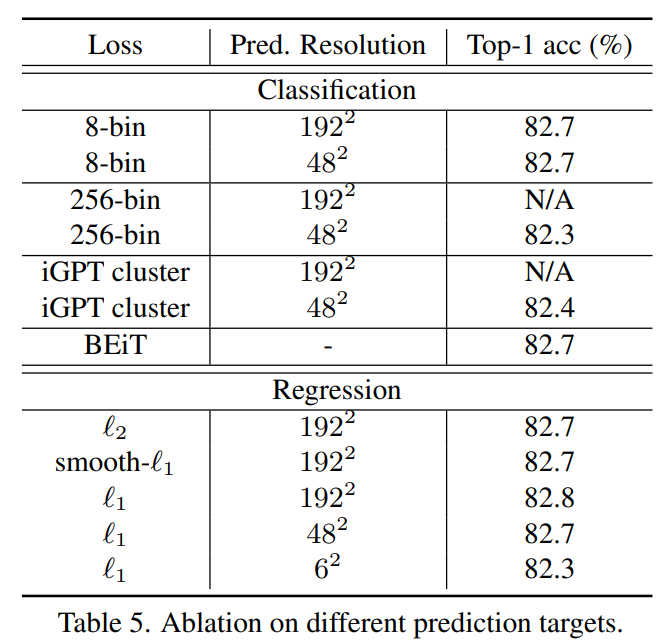
Loss 컬럼에서 8-bin, 256-bin은 Channel-Wise bin color discretization을 나타낸 것이며, cluster와 BEiT는 각각 K-means cluster, Vision Tokenizor 끼리의 비교를 의미합니다. 그외에 L2, smooth l1, l1 loss도 있구요.
위에 표에 대한 요약은 대략적으로 다음과 같습니다.
- L1 loss, L2 loss, smooth-l1 loss는 모두 좋은 성능을 보여준다. 그래서 어떤 것을 픽해도 크게 문제될 것은 없음.
- clustering 기법 혹은 BEIT 등은 오히려 성능에 drop을 가져왔으면 가져왔지 향상은 가져오지 않는다.
- Color discretization의 경우도 L1 loss와 비슷한 성능을 보이기는 하지만 discretization을 몇으로 할지에 대한 튜닝에 민감한 결과를 보인다.
논문에서는 결과적으로 추가적인 방법들이 성능이 크게 향상시키지는 않으며 오히려 해당 과정을 적용시에 전처리 과정 혹은 추가적인 네트워크가 필요하다는 점에서 학습에 불편한 요소들이 있으므로 그냥 단순히 raw rgb를 예측하는 것이 좋다고 주장합니다.
Quantitative Result
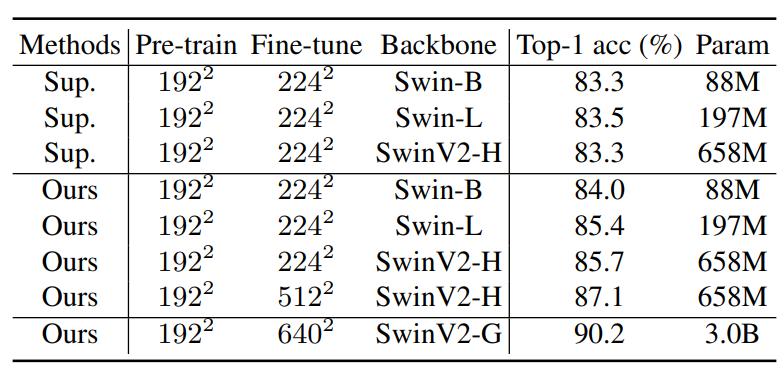
다음은 Ablation study가 아닌 타 방법론들과의 성능 비교를 한 결과입니다. 표6은 ViT 백본에 대한 결과, 표7은 Swin Transformer에 대한 결과입니다.
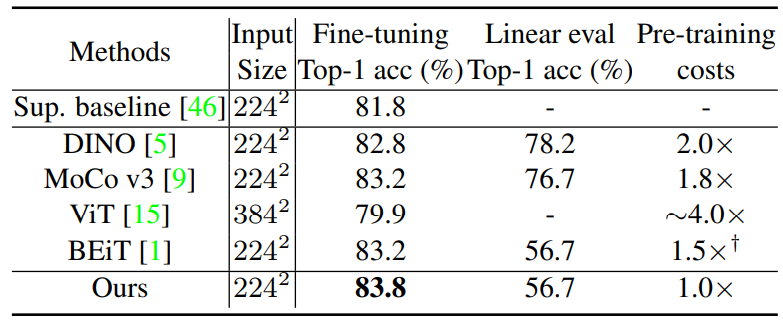
먼저 표6을 살펴보시면 본인들이 제안하는 방법은 그 당시 SOTA였던 BEiT와 비교하였을 때 0.6% 더 좋은 정확도를 보이면서 동시에 사전 학습에 들어가는 코스트 역시 가장 적은 값을 지닌다고 설명합니다.
또한 표7에서는 기존의 연구들이 ViT 기반 백본들만을 활용해서 Pre-training을 하였다면 본 논문에서는 Swin Transformer 역시 MIM 기반 Pretraining이 잘 적응한다는 것을 보여주는 것이 아닐까 합니다.
보다 구체적으로 Swin Transformer의 크기가 더 커지면 커질수록, 그리고 입력 해상도가 커지면 커질수록 더 좋은 성능을 보여주고 있으며 Supervised 방법론과 비교해서도 큰 성능 차이를 보여주고 있습니다.
또한 SwinV2-G의 경우 ImageNet-22K로 더 큰 학습 데이터 셋으로 학습하여서인지 90%를 넘는 성능대를 보여주고 있네요.
결론
본 논문은 생각보다 방법론 자체가 특별하다기보다는 실험을 많이 수행하여 Masked AutoEncoder 관련 실험을 진행하는 연구자들에게 많은 영감을 준 논문이 아닌가 싶습니다.
약간 Masked Autoencoder의 학습 효과를 더 높이기 위해서 사람들이 다양한 방향으로 실험을 진행하고 논문을 쓰고 있을텐데, 해당 논문에서 이미 그 궁금증을 다 풀어버린듯한? 느낌이 강하게 들정도로 다양한 측면에서 성능에 영향을 줄법한 요소들을 다 다룬 것이 이 논문의 가장 큰 핵심일 것 같네요.
좋은 리뷰 감사합니다.
MAE 기법에 다양한 마스킹 기법을 적용해본 실험과 encoding 된 feature를 다양한 prediction target을 적용한 실험 결과를 확인할 수 있는 논문인 것 같습니다.
AVG dist와 Mask ratio 사이에 상관관계가 있다는 것을 실험적으로 보여주었는데, pixel 사이에 평균거리(AvgDist)는 마스킹 되지 않은 픽셀들간의 거리인가요??(즉, 마스킹되는 비율을 의미하는 것인지 궁금합니다.)
글을 잘못 읽으신 것 같네요.
“위에 표 1의 내용은 결국 마스킹된 patch의 중심으로부터 가장 가까이 있는 visible patch 혹은 pixel 사이에 평균거리(AvgDist)가 모델의 사전 학습에 상당히 중요한 요소이며, 이 평균거리는 마스킹 ratio의 비율 및 masked patch size를 통해 결정될 수 있다는 것입니다.” << 이게 리뷰 내용인데 여기서 pixel 사이에 평균거리라는 것을 단독으로 보시면 안되고 그 앞에 문장, 즉 마스킹된 patch 중심으로부터 가장 가까이 있는 visible patch(or pixel)사이에 거리 == avgdist 라는 의미입니다
리뷰 잘 봤습니다.
MAE에 관련된 여러 실험들과 기초적인 내용을 파악할 수 있는 좋은 논문인거 같네요. 나중에 기회가 되면 읽어봐야겠습니다.
Table 2에서 Prediction Head Ablation study에 대한 질문이 있습니다. 결국 downstream task에서 좋은 성능을 내기 위해선, pretraining 단계의 decoder에 비해 encoder의 비율이 높아야 한다. 즉 decoder를 간단하게 구성해야한다고 이해했습니다.
그런데 파라미터 수 때문에 나온 실험결과가 아닌, Prediction Head로 선택된 4가지 모델의 구조 자체가 달라서 우연(?) 에 의해 나온 결과는 아닐까요 ? 직관적으로 생각해보면 reconstruction을 잘 하는 모델의 encoder가 downstream task에서도 더 잘 작동할 거 같아서요,, 어떻게 생각하시나요?
아니죠. 권석준 연구원이 말한것처럼 기존 연구들은 reconstruction을 잘하는 모델이 downstream task에서 더 잘 작동하지 않을까요? 라는 관점으로 접근하였기 때문에 decoder를 transformer block을 여러겹 쌓아서 만들었습니다.
그렇게 할 경우 당연히 reconstruction은 잘 수행하게 되지만, 오히려 그렇게 진행하다보니 encoder에서 semantic한 정보를 더 잘 보지 못하더라도 더 많은 레이어로 구성된 decoder에서 encoder의 부족한 부분을 보완하여 복원을 수행하기 때문에 실제 encoder에서는 더 좋은 weight을 가질 수 있는 기회가 빼앗기게 된다는 것이 저자의 주장입니다.
따라서 이것이 단순히 architecture 관점에서 우연이라고 하더라도, 보통은 decoder의 구조가 상대적으로 더 커지거나 복잡해져야만 그렇게 생각할 수 있는 것이지, 기존의 복잡한 decoder를 단순히 1개의 fc layer로 대체하였는데 성능이 더 좋아지는 경우에는 모델 구조 자체가 달라져서 발생한 우연이라고 치부할 수 없다는 것이 제 생각입니다.
리뷰 잘 봤습니다.
쏟아져 나오는 MAE 논문들 중에서 나름의 길잡이가 되어줄 수 있는 논문이라는 생각이 듭니다.
한가지 질문이 있습니다. Decoder를 MLP로 대체하는 실험은 결국 Encoder의 표현력을 더욱 쪼인다는 느낌으로 이해해도 될까요? (아니면 그것을 기대하는지)
매우매우 정확합니다.
리뷰를 잘쓰니 이해력도 좋군요.
사실 리뷰에 제가 그 표현을 그대로 쓴 것 같긴하지만..
논문 리뷰 잘 읽었습니다.
MAE에 대해서 인트로에서 잘 요약해주셔서 읽는데 도움을 많이 받았습니다.
해당 모델에 대한 Loss function에 대해 질문이 있습니다.
제가 생각하기에는 L2 loss 같은 경우 outlier에 대해 민감하므로 해당 masking strategy를 사용하면 학습을 할 때 분명 noise가 많아져서 비교적 noise에 강인한 L1 loss 를 사용하는 것이 맞다고 생각이 드는데, smooth L1 loss와 비교를 하였음에도 불구하고 L1 Loss 를 사용한 이유는 성능 부분에서 L1 loss가 좀 더 잘 나와서 그런 건지 궁금합니다. SSD 실험을 할 때에도 L1 loss, L2 loss에 대한 각각의 장점을 가지고 만들어진 smooth L1 loss가 좀 더 성능이 좋을 줄 알았는데, SSD 실습을 할 때 제공된 코드에는 L1 loss 를 사용한 부분에 대해서도 의문이 있었습니다. 실질적으로 smooth L1 loss가 아닌 L1 loss를 사용하는 이유가 있을까요?
* SSD 코드를 제공한 github에서 issue 내용 중 L1 Loss 가 좀 더 성능이 좋았다고 합니다.
감사합니다.
좋은 질문이네요.
물론 각각의 Loss가 가지는 장단은 댓글에도 남겨주셨다시피 뚜렷한 차이를 가지고 있지만, 해당 논문에서의 task(즉 마스킹된 부분을 복원하는 목적 함수)에서는 L1 loss, L2 loss, Smooth L1 loss 어떤 것을 적용한다 하더라도 모두 동일하거나 매우 유사한 성능을 보여주었습니다.(정확도 0.1%정도 차이)
따라서 본 눈문에서는 L1 loss, L2 loss, Smooth-L1 loss 이 셋 중에 무엇을 사용하더라도 상관이 없었을 것입니다. 그렇다면 왜 L1 loss를 사용했을까요? 제가 논문을 봤을 땐 따로 그럴 듯한 이유가 없었던 걸로 봤는데, 제가 생각해도 그냥 L1 loss가 단순해서 고른게 아닐까 싶습니다.
이 논문의 핵심은 복잡한 방식이 아닌, 단순 명료한 기법들을 조합해서 최대한 간결하게 사전 학습을 시켜보자는 것이기 때문에, 상대적으로 복잡?한 smooth L1 loss 보다는 L2 loss를, 또 L2 loss보다는 더 간단한 L1 loss를 채택한 것이 아닐까 싶습니다.
그리고 이전의 관련 논문들은 L2 loss를 활용했기 때문에 나름대로 그들과의 차별점을 보이고 싶어서 L1 loss를 채택한 걸 수도 있구요^^