본 논문은 deep depth completion of a single rgb-d image라는 이름에서도 느껴지듯이 단일 RGB-D image의 depth channel 정보를 채우기 위한 방법을 제안하는 논문이다. 보통의 depth camera는 shiny, bright, transparent, 그리고 distant한 표면같은 부분의 depth를 알아내는데 어려움이 있다고 한다. 이런 어려움이 있는 경우에, 단일 RGB image만을 input으로 하여 depth를 추정하기 위한 dense surface normals와 occlusion boundary를 예측하는 deep network를 제안하였다. 이렇게 예측한 정보와 RGB-D camera로 촬영된 raw depth 정보를 함께 사용하여 모든 pixel에 대한 depth를 추정하는 것을 목표로 하였다. 다양한 실험을 통해 본 논문에서 제안하는 deep depth estimation network가 효과적으로 depth completion을 할 수 있음을 보였다.
Introduction
depth를 sensing하여 적용하는 분야가 자율주행, scene reconstruction, AR(Augmented Reality)와 같은 분야로 확장되어 사용되고 있다. 하지만 Microsoft Kinect, Intel RealSense와 같은 commodity-level의 RGB-D camera가 제공하는 depth images에는, surface가 glossy, bright, thin하거나 camera로 부터 거리가 너무 가깝거나 먼 경우에 missing data가 존재하게 된다. 이러한 문제는 특히 박물관 같은 넓은 공간이거나, 표면이 shiny하거나, 강한 빛을 받을 때 특히 많이 발생하게 된다. 아래 Figure 1에서 보면, 집에서 rgb-d camera로 얻은 depth값을 시각화 한 것이다. 왼쪽의 Sensor Depth를 보면 depth image의 많은 부분이 depth를 표현하지 못하고 있는 것을 확인할 수 있다. 특히 강한 빛이 들어오는 창문이나, camera로부터 먼 거리에 있는 영역들에 대한 depth정보가 손실되어있다.

본 논문에서 제안하는 network의 목적은 위에서 언급한 상용화 되어있는 depth camera를 가지고 획득한 RGB-D image의 depth정보를 보완하는 것이다. 논문에서는 depth completion이라는 표현을 사용한다. 쉽게 말해 빈 depth공간을 채우겠다는 뜻이다. 이전에는 빈 holes를 채우기 위해 extrapolating(interpolation과 반대로 데이터 범위 외 값을 추정)을 사용한 hand-crafted 기반의 방법론이 제안되었고 논문이 나올 당시에는 deep networks를 사용하여 depth를 추정하는 방법론들이 제안되었다고 한다. 하지만 해당 방법들이 가진 challenges로 인해 depth completion을 위해 사용되지 않았다고 한다.
우선 dataset의 문제인데 completed한 depth image를 가진 large-scale의 RGB-D image pair가 없었다. 빈 hole같은 pixel에 대한 GT정보가 없었다는 뜻이다. 따라서 대부분의 depth estimation 방법론들은 RGB-D camera로 capture되는 영역의 pixels에 대해서만 train과 evaluation이 진행되었다. 이러한 unobserved한 경우에는 충분한 정보를 가지고 있지 않기 때문에 complete하게 depth를 보완할 수 없다. 본 논문에서는 72개 real-world 환경에서 large-scale surface reconstruction을 통해 계산된 completed depth images와 align을 맞춘 105,432장의 RGB-D images를 dataset으로 사용하였다.
새로 제안한 dataset을 통해 fully convolutional network를 학습시켜 RGB-D에서 depth를 direct하게 예측하는 것을 기대했지만, Figure 1에서 아래 행과 같이 빈 공간이 큰 경우에는 잘 작동하지 않았다. 단일 영상 기반으로 절대적인 depth를 추정하는 것은 쉽지 않은 task이다. 따라서 본 논문에서는 예측 난이도를 줄이기 위해 surface normal과 occlusion boundaries와 같은 depth의 local differential properties를 예측하도록 하는 network를 학습시키고 global optimization을 통해 absolute depth를 찾았다. 여기서 surface normal은 depth estimation과 관련이 있으며 points들을 연결한 mesh와 같은 각 표면에 대해 수직하는 normal vector를 표현한 것이고, occlusion boundary는 scene structure를 파악하기 위한 중요한 edge와 같은 특징 경계를 의미한다.

사실 RGB-D input을 사용하여 depth image를 completing하기 위한 end-to-end network에 대한 previous work가 없고 본 논문이 처음으로 제안하는 것이다. 처음에는 직관적으로 RGB와 depth를 input으로 하는 network가 잘 작동할 것이라 생각하여 학습시켜보았다고 한다. 하지만 depth를 input으로 함께 사용하는 경우, depth정보가 없는 빈 hole을 단순히 주변 depth정보를 복사하거나 interpolation하는 방식으로 network가 학습하게 되었다고 한다. 이 부분에서 depth를 예측할 때 사실 주변 물체의 depth와 비슷한 depth값을 가지지 않을까..?하는 의문이 생기기도 했지만, 2d image에서 나타나는 depth정보는 3d에서와 다르게 근처 pixel에 대해서도 서로 다른 depth를 가질 수 있을 것이라는 생각했고 실험적으로 좋은 결과를 보였다고 하니 지켜봐야할 것 같다. 또한 color와 depth의 misalignments를 맞추는 것도 어려움이 있다. 따라서 아래 Figure 2에 나타나있는 것 처럼, 본 논문에서 제안하는 network는 input으로 RGB image만을 사용한다. network는 학습을 통해 local surface normals와 occlusion boundaries를 예측하게 된다.

local surface normals와 occlusion boundaries를 예측한 이후 예측한 값들과 sensor input을 합쳐 complete한 depth를 알아낼 수 있도록 한다. RGB color에서만 local features를 예측하는 것이다. scene에서의 전반적인 coarse-scale의 structure는 regularization된 global optimization을 통해 input detph에서 reconstruct 된다.
전반적으로 RGB-D depth completion을 구성할 때 크게 2 stage의 algorithm으로 나눠진다고 할 수 있다. 우선 1. RGB에서 surface normals와 occlusion boundaries를 예측하고, 2. 예측한 값들과 depth정보를 활용하여 global surface structure를 optimization하는 과정으로 나눌 수 있다. 실험적으로 해당 방식이 다른 방식보다 상대적으로 좋은 결과를 보였고, 단일 RGB를 network의 input으로 하기때문에 observed depth정보에 independent하여 depth sensor정보에 대해 학습할 필요가 없다는 장점도 존재한다.
Related Work
Depth estimation
monocular color image로부터 depth estimation을 하는 것은 computer vision 분야에서 지속적으로 문제가 제기되어왔다. 기존 초기 모델들의 경우 hand-tuned 기반 모델이거나 surface orientation을 찾아 depth를 추정하는 방식이었다. 이후에는 machine learning을 이용하여 depth를 추정하는 방법론들이 제시되었고 최근에는 deep network를 사용한 방법론들이 나오기 시작했다. 하지만 이러한 방법론들은 모두 단지 상용 RGB-D camera를 통해 얻은 raw depth를 reproduce하기 위해서만 학습되었다. 본 논문에서는 depth sensor가 추정하지 못한 pixel에 대한 depth를 새롭게 prediction하는 depth completion을 목표로 하였다.
Depth inpainting
제안되었던 많은 방법론들은 RGB-D images의 depth channel 중 비어있는 holes를 채워넣기 위해 제안되었다. 그리고 최근에는 auto-encoders나 GAN architecture를 활용하여 color images를 inpainting하는 목적으로 많은 방법론들이 제안되었다고 한다. inpainting이 무엇인지에 대해 찾아보니 영상에서 손상되거나 누락된 부분을 채워 완전한 이미지를 만드는 이미지 복원 프로세스인 것을 알게되었다.

하지만 기존 inpainting을 위한 방법론들은 color image에 대해 연구되었고 depth image를 inpainting하는 방법에 대해서는 연구된 전례가 없었다. depth image에는 rgb color image에서 만큼 충분한(강한?) feature가 없고 큰 training dataset도 없기 때문에 depth를 inpainting하는데 어려움이 존재한다.
Depth super-resolution
몇몇의 제안된 연구들은 high-resolution color를 이용하여 depth images의 spatial resolution을 향상시키는 것을 목표로 하는 방법론들이었다. 비록 몇 가지 방법론들이 depth completion을 위해 사용되었으나, 이러한 super-resolution에도 challenges가 존재했다. 기존 방법론들은 complete하고 regular하게 sampling된 저해상도의 spatial resolution을 향상시키는 것이 목적이다. 하지만 본 논문에서는 비교적 complex하고 큰 사이즈의 빈 holes를 채우는 것을 목적으로 하기 때문에 large-scale content와의 합성된 정보가 필요하다는 차이점이 존재한다.
Depth reconstruction from sparse samples
기존에는 sparse한 depth 측정 정보를 augment하여 color images로 부터 depth reconstuction을 하는 연구가 진행되었다. 이러한 방법론들은 본 논문에서 하고자하는 idea와 일부 비슷한 부분이 있다. 하지만 기존 방법론들의 motivation은 robot에서 power를 줄이기 위함과 같이 cost를 줄이기 위함이었고, depth cameras에서 흔하게 발생하는 missing data를 complete하는 것은 아니었다.
Method
본 논문에서는 단일 RGB-D image를 이용하여 depth completion을 하기 위한 deep network를 어떻게 사용할지 고민하였다. “depth completion을 위한 training data를 어떻게 얻을지”, “어떤 depth representation을 사용할지”, “color와 depth에서의 cues를 어떻게 합칠지”에 대해 집중했다고 한다.
Dataset
우선 RGB-D image와 pair인 depth image를 만들어내는 것이 문제였다. low-cost의 RGB-D camera로 얻은 Image와 동시에 higher cost depth sensor로 얻은 Image의 align을 맞추는 방법이 있었지만 cost가 크고 time-consuming한 방법이었다.
따라서 여기서는 large environments에 대해 multi-view RGB-D로 scan한 데이터로부터 surface meshes를 reconstruction하는 방법을 사용하였다. Matterport3D, ScanNet 등과 같이 여러 종류의 데이터들 중 Matterport3D를 사용하였다.

Matterport3D을 이용한한 각 scene은, points를 연결하여 방마다 1~6백만개의 triangle mesh M을 만들었다. 그리고 completed depth image D*를 얻기위해 image viewpoint의 camera pose에서 reconstructed된 mesh M을 rendering 한다. 이 과정을 통해 추가적인 데이터 수집을 하지 않고 RGB-D에서 pair한 D*(completed depth image)을 얻을 수 있다. 아래 Figure 3에서는 dataset에서 depth image completion의 예시를 보여준다.

항상 completion이 잘 되는 것은 아니지만, deep network를 training하기 위해 필요한 dataset을 구성하는데는 좋은 특징을 보인다.
우선 completed depth images는 일반적으로 holes가 거의 없다. 왜냐하면 multi-viewpoints에서 관측되었고 모든 camera viewpoints에서 관측된 결과들이 합쳐져 surface reconstruction에 도움을 주었기 때문이다(노란색 view 정보 등). 결과적으로 어떤 view에서 멀리 떨어져 있지만 다른 view에서 관측 가능한 범위인 경우에 completed depth image에 포함될 수 있는 것이다. 그리고 raw depth image에서 missing pixel 중 64.6%가 reconstruction process에 의해 filled되었다고 한다.
그리고 일반적으로 completed depth images는 가까운 close-up surface에 대해서는 원본 resolution을 그대로 replicate하지만, 먼 surface에 대해서는 더 좋은 reoslution을 보인다. surface reconstruction은 depth camera의 resolution과 비슷한 3D grid size로 구성되기 때문에 일반적으로 completed depth images에서 resolution의 손실은 없다. 하지만 동일한 3D resolution은 view plane에 projection될 때 camera로부터 멀리 떨어진 surface에 대해 더 효과적으로 higher pixel resolution을 나타낸다. 결과적으로 completed depth images는 high resolution mesh를 rendering할 때 subpixel antialiasing을 활용하여 원본보다 미세한 resolution을 얻을 수 있다. Figure 3의 rendered depth를 보면, 뒤쪽에 작은 쇼파나 시계?와 같은 detail을 확인할 수 있다.
그리고 completed depth images는 일반적으로 원본보다 noise가 적다. surface reconsturction algorithm은 filtering과 averaging을 통해 multi-view cameras에서 noisy한 depth samples를 결합하기 때문에, 본질적으로 surface의 noise를 제거할 수 있다. 특히 noise가 많은 4m이상의 distant observation에서 중요한 역할을 한다고 한다.
본 논문에서는 총 117,516장의 completion한 RGB-D images를 dataset으로 하였고 105,432장을 training, 12,084장을 test set으로 나누었다.
Depth Representation
Method 처음에 언급했던 것처럼 어떤 geometric representation이 본 논문에서 제안하는 deep depth completion에 가장 적합할지에 대한 고민이 필요하다. 직관적인 방법으로 raw depth와 color에서 completed depth를 regressioin하는 network를 설계하는 방법이 있다. 하지만 absolute depth는 object sizes, scene categories와 같은 추가적인 정보가 필요할 수 있기 때문에 monocular images에서 예측하는 것은 어렵다. 대신 본 논문에서는 각 pixel에서 visible surface의 local properties를 예측하고, 예측한 결과에서 depth문제를 다시 해결할 수 있게 network를 train시킨다. 기존 연구에서는 깊이를 간접적으로 표현한 방식들이 존재했는데, 아래 experiment부분에서 저자가 실험을 통해 잘 수행되지 않는다고 말했다.
대신 본 논문에서는 surface normals와 occlustion boundaries를 예측하는데 focus를 맞춘다. surface normals는 mesh의 법선에 해당하는 특성으로 해당되는 pixel의 local neighborhoods에만 의존한다. 또 surface normal은 color image에서 직접 관측할 수 있는 local영역에서의 조도 변화와 관련이 있다. 이러한 이유로 color images에서의 surface normals prediction은 좋은 결과를 보였다. occlusion boundaries의 경우에도 edge와 같은 pixel의 local patterns를 생성하므로 일반적으로 deep network로 detect할 수 있다.
중요한것은 어떻게 predicted된 surface normals와 occlusion boundaries를 사용하여 complete depth images를 완성할 수 있는가이다. 이론적으로 surface normals와 occlusion boundaries에서만 depth문제를 해결하는 것은 불가능하다. 예를 들어 아래 Figure 4(a)에서 보면 주어진 surface normals만을 근거로 가운데 window를 통해 본 뒤의 벽의 depth를 추론하는 것은 불가능하다. 왜냐하면 뒤의 벽이 보이는 영역은 camera view 기준으로 window크기만큼으로 고정되어 occlusion boundaries에 의해 contour형태로 닫혀있으며 이 외의 벽의 다른 영역에 대한 depth는 알 수 없기 때문이다.

하지만 Figure 4(b)에서 보면 real-world scenes의 경우 image 영역이 occlusion boundaries에 의해 contour형태로 둘러 쌓여 raw depth observation이 전혀 포함되지 않을 가능성은 낮다. 빨간색 영역이 missing depth영역이다. 분홍색 화살표는 surface normals와 depth를 통합할 수 없는 경로를 의미한다. 하지만 real-world에서는 일반적으로 connected neighboring pixels(바닥, 천장 등)를 통해 depth를 통합할 수 있는 경로(초록색 화살표)가 많이 존재한다는 의미이다. 실험적으로 predicted surface normals와 occlusion boundaries를 활용하여 depth문제를 해결하는 것이 가장 괜찮은 depth completion을 할 수 있다는 것을 알 수 있었다.
Network Architecture and Training
depth completion을 위해 predicted surface normals와 occlusion boundaries를 예측하기 위한 deep network를 학습시키는 가장 좋은 방법에 대해서도 고민이 필요하다.
본 논문에서는 normal estimation과 boundary detection 모두에서 경쟁력있는 성능을 보이는 사전에 제안된 deep network architecture를 사용한다. 이 model은 VGG-16에 symmetry encoder와 decoder가 있는 backbone을 사용한 fully convolutional neural network이다. 그리고 short-cut connections와 maxpooling, unpooling을 통해 local image features를 학습할 수 있다. 학습할 때 GT로는 reconstructed된 mesh에서 surface normals와 boundaries를 사용한다.
이전에 진행되었던 surface normal estimation방법과는 다르게, 저자의 주요 목표는 raw observed depth images의 holes 내부에 존재하는 pixels에 대해서만 normals를 에측하도록 network를 학습시키는 것이다. 이러한 holes 내부 pixels들의 color appearance 특성은 빛이 나거나 camera로부터 멀리 떨어져있는 경우처럼 다른 pixels들과 다를 수 있기 때문에, network는 이러한 pixels들에 대해서만 regression해야된다고 생각할 수 있다. 하지만 생각해보면 당연하게 빈 Holes에는 pixel값이 거의 없기 때문에 training data가 제한적이다.
저자는 observed pixels를 raw sensor와 rendering된 mesh를 통해 얻은 depth data가 있는 pixel로 정의하고, unobserved pixels는 rendering된 mesh의 depth는 있지만 raw sensor로 부터 얻은 depth는 없는 pixel로 정의한다. 주어진 pixels 집합들(observed, unobserved, 둘 다)에 대해 backpropagation 중 다른 pixel의 gradient를 masking하여 해당 pixels들에 대해서만 loss를 계산한다.
결과적으로는 모든 pixels들로 train된 model이 observed, unobserved pixel중 하나만 사용한 것보다 좋은 성능을 보인다.
raw RGB-D image에서 surface normals를 예측하기 위해 가장 좋은 방법은 4 channel(RGBD)를 모두 제공하여 normal channels를 regression하는 것이라 생각할 수 있다. 하지만 해당 방식을 적용했을 때 observed depth 정보 없이는 안 좋은 결과를 보이는 것을 발견했다고 한다. observed depth가 있는 pixel에 대해 Normals를 예측하는 것은 좋지만 holes에 있는 pixel, 즉 depth completion에 필요한 pixel에 대한 normals를 예측하는 것은 좋은 결과를 보이지 않는다. 일반적으로 network가 observed depth를 가진 pixel을 포함하는 extra channel이 주어지더라고 depth보다 color에서 normals를 더 잘 예측하는 방법을 배운다고 한다. 아래 Figure 5에서 보면 color만으로 큰 holes에서 예측된 normals가 depth에서 예측되는 것보다 눈에 띄게 낫고, color와 depth 모두에서 예측되는 것보다고 좋다는 것을 확인할 수 있다.

이 결과는 color만으로 surface normals를 예측하고 observed depth를 regularization에만 사용하도록 network를 훈련할 수 있다는 것을 보여준다. 이렇게 depth없는 prediction과 depth로 optimization을 하는 방법은 두 가지 이유로 설득력이 있다는 것을 설명할 수 있다. 우선 prediction network는 다른 depth sensor에 대해 다시 train될 필요가 없다. 그리고 optimization은 다양한 depth observation을 정규화하도록 일반화 할 수 있다고 한다.
Optimization
surface normal image N과 occlusion boundary image B를 예측한 후 depth image D를 완성한다. objective function은 weighted sum of squared error로 계산되며 아래 식(1)과 같다.
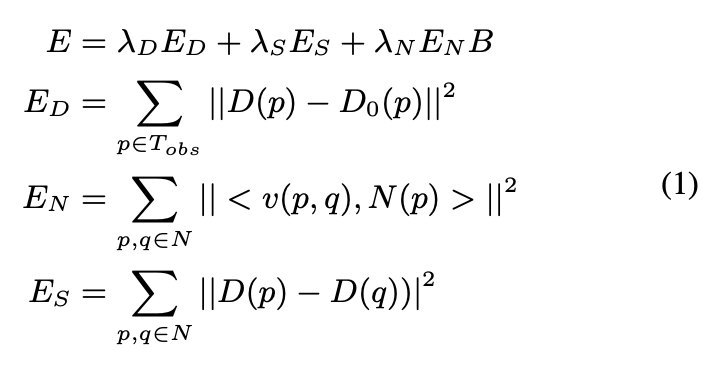
ED는 pixel p에서 추정된 depth D(p)와 observed raw depth D0(p)사이 거리를 의미하고, EN은 추정된 depth와 predicted surface normal N(p)사이의 consistency를 의미하고, ES는 인접한 pixels들이 같은 depth를 가지도록 한다. B ∈ [0,1]은 pixel이 occlusion boundary에 있을 것으로 예측된 확률(B(p))를 기반으로 normal term의 가중치를 조절한다. 이 objective function은 EN에서 dot product를 하는 tangent vector v(p,q)의 normalization때문에 non-linear하다. 하지만 vector normalization을 통해 linear한 formation으로 근사할 수 있다고 한다. 이 근사치는 depth가 작을수록 tangent 접선이 짧고 EN term이 작아질 수 있기 때문에 scaling error에 sensitive할 수 있지만 depth completion에서 observed raw depth와 일관성을 유지하려 하므로 큰 문제가 되지 않는다고 한다. 이러한 linearization approach는 제안된 방법에서 중요한 역할을 한다. surface normals와 occlusion boundaries는 surface geometry의 local properties만 포착하기 때문에 비교적 쉽게 추정할 수 있다. 그리고 global optimization을 통해서 일관된 solution을 이용해 모든 pixels에 대한 depth completion을 할 수 있다.
Experimental Results
network는 아래 그림과 같은 SUNCG dataset에서 pre-trained되었고 본 논문에서 제안한 dataset에 fine-tuning하였다.
본 논문에서는 depth sensor에서 unobserved한 pixel에 대해 depth를 추정하는 것이기 때문에, 기존 observed된 pixel에 대해서만 depth estimation하는 방법들과 다르게 test depth image에서 unobserved한 pixel에 대해서만 depth prediction을 진행했다. 아래 Table 1에서 보면 depth completion에서 성능지표는 이전 depth prediction에 사용하는 standard한 지표로 median error relative to the rendered depth(Rel)과 root mean squared error in meters(RMSE)를 사용하였고 예측된 pixel의 depth가 특정 간격(δ)내 있는 비율에 대해서도 측정했다. surface normal prediction을 평가할 때에는 mean, median errors와 일정 threshold보다 적은 degree의 예측된 normals가 있는 비율에 대해서도 reporting하였다.

Table 1에서는 input이 depth, color, 둘 다 중 어떤 유형의 input이 network에 가장 적합한지 결과를 보여준다. 직관적으로 color, depth 둘 다 입력하는 것이 좋을 것 같지만 오히려 color만 제공되었을 때 surface normals를 더 잘 예측하는 방법을 학습한다는 것을 알 수 있다. 이러한 차이는 observed, unobserved, 모든 pixel에 대해 train하는 경우 모두 동일하다고 한다. network가 observed depth에서 interpolation하는 법을 빠르게 학습하기 때문에, large holes에서 새로운 depth를 합성하는 법을 배우는데 방해가 될 수 있어 이러한 결과를 보인다고 생각한다.

Table 2에서는 network가 예측하기 가장 좋은 depth representation 방법에 대한 실험을 나타낸다. D는 absolute depth, N은 surface normals, DD는 8방향의 depth derivatives이며 이것들을 예측하기 위해 network를 train하고 다양한 조합을 사용하여 위의 수식(1)을 최적화하여 depth completion을 한다. 결과적으로 predicted normals(N)의 depth에 대한 solution이 가장 좋은 결과를 보이는 것으로 알 수 있다. normals가 상대적으로 예측하기 쉬운 surface의 orientation만을 나타내기 때문에 좋은 결과를 보였다고 생각한다. B는 occlusion boundary로 첫 행을 제외한 결괄르 보면 predicted occlusion boundaries 근처의 surface normals의 효과를 낮추는 것이 optimize하기 좋은지 비교한 것이다. 결과를 보면 boundary prediction을 한 것이 결과를 더 좋을 결과를 보인다. 이것은 아래 Figure 6에 나타난 것처럼 엄청 큰 차이를 느낄 순 없지만 surface normal이 noise가 있거나 부정확한 pixel에 대해 평균적으로 정확하게 예측하고 있음을 보여준다.
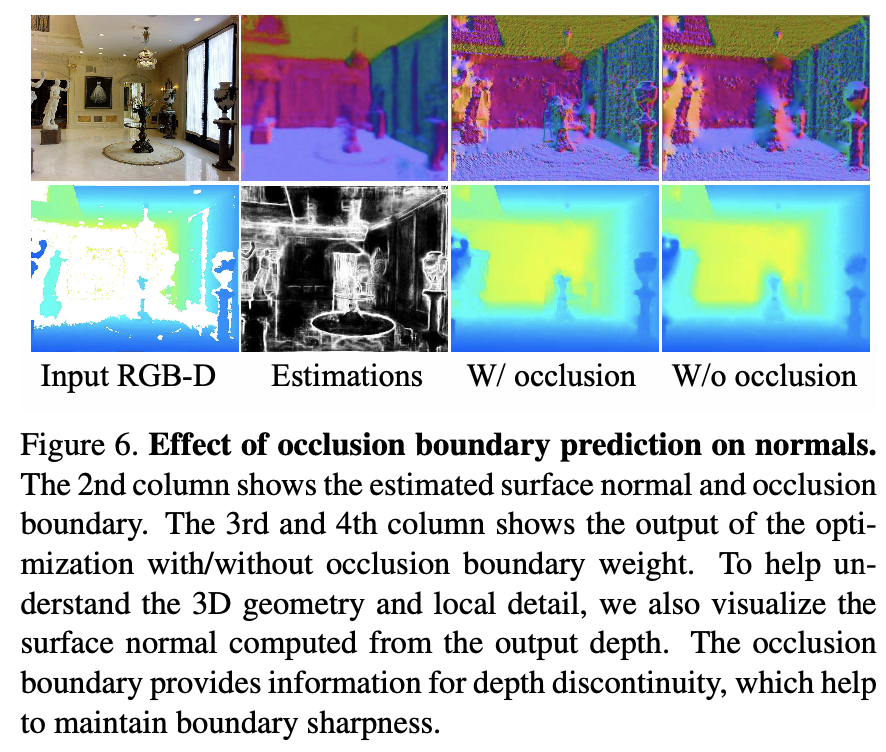
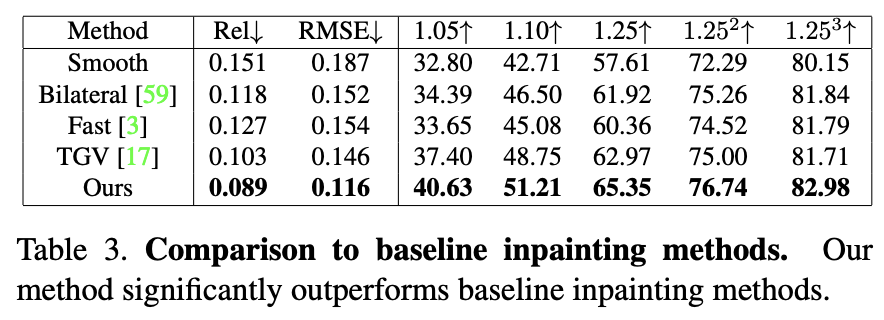
Table 3은 deep inpainting을 위한 방법론들과 비교 결과를 보여준다. 이 실험은 잘 알려진 방법론들이 새로운 dataset에 대한 문제가 얼마나 어려운지 기준을 알기위해 수행한 방법이다. 결과적으로 본 논문에서 제안하는 방법이 다른 기존 방법론들에 비해 좋은 결과를 보인다는 것을 확인할 수 있고 deep network를 통해 surface normals를 예측하는 훈련을 하여 data기반 depth completion하는 방법을 배운다고 알 수 있다.

아래 Table 4는 color만으로 depth를 추정하는 이전 방법과 본 논문에서 제안한 방법을 비교한 결과이다. observed depth pixel이 unobserved depth pixel보다 좋은 결과를 보인다. 이전 방법론들은 입력 depth가 없기 때문에 서로 다른 문제를 해결하는 방법이므로 가볍게 보면 좋을 것 같다. Figure 9에서 보면 본 논문에서 제안하는 방법이 raw depth만 주어진 pixel에서도 scene의 structure와 미세한 details를 가장 잘 표현했다는 것을 확인할 수 있다. 이러한 결과는 surface normals를 예측하는 것이 depth estimation을 위한 효과있는 접근방법이라는 것을 시사한다.


Conclusion
본 논문에서는 RGB-D camera로 얻은 RGB-D image의 depth completion을 하기 위한 deep learning framework에 대해 설명한다. 크게 두 가지 contribution을 제공하는데, 우선 surface normals와 occlusion boundaries를 예측한 다음 depth completion을 하는 2가지 process를 제안한다. 그리고 large-scale surface reconstruction에서 rendering된 data에 대해 complete depth image하는 방법을 학습한다. 다양한 test를 통해 depth inpainting과 estimation에서의 이전의 baseline approach보다 좋은 성능을 보였다. 논문을 읽을 때 솔직히 이해하기 좀 어려웠다. 본 논문을 통해 noise가 많은 raw depth 정보를 통한 depth completion task에 대해 접할 수 있었던 것 같아 견문을 넓히는 경험이 되었다고 생각한다.
좋은 리뷰 감사합니다.
리뷰 작성하는데 공을 들여서인지 많은 시간을 소요했을 것 같은 기분이 드네요.
리뷰를 읽으면서 두 가지 궁금증이 생겼는데, 리뷰 내용 중 “저자는 observed pixels를 raw sensor와 rendering된 mesh를 통해 얻은 depth data가 있는 pixel로 정의하고, unobserved pixels는 rendering된 mesh의 depth는 있지만 raw sensor로 부터 얻은 depth는 없는 pixel로 정의한다. 주어진 pixels 집합들(observed, unobserved, 둘 다)에 대해 backpropagation 중 다른 pixel의 gradient를 masking하여 해당 pixels들에 대해서만 loss를 계산한다.” 라고 적힌 부분이 이해가 잘 안가네요.
일단 observed pixel과 unobserved pixel의 정의 자체는 이해를 했는데, 그 다음 문장에 주어진 pixel 집합들(observed, unobserved, 둘 다)~~ 에서 저 둘다 라는 표현이 observed+unobserved 라는 것을 의미하나요?
그럼 pixel 집합을 크게 (observed인 경우, unobserved인 경우, 그리고 둘이 모두 해당되는 경우)로 나누는 것인건가요? 그럼 여기서 observed와 unobserved 차이가 raw sensor의 정보 유무의 차이인데 둘다 라는 경우는 어떻게 성립이 되는것인가요? 둘 중 한가지만 성립이 되는 것 같은데 둘다 성립되는 경우는 없을 것 같아서요. 만약 둘다 라는 표현이 observed + unobserved의 의미가 아니라면 앞선 궁금증은 오해에서 비롯된 것 같네요.
그리고 두번째로는 “backpropagation 중 다른 pixel의 gradient를 masking하여 해당 pixels들에 대해서만 loss를 계산한다” 라는 내용인데, 이 부분에 대해서 구체적인 설명이 리뷰에는 제가 보지 못한 것 같아서 더 자세하게 설명해줄 수 있나요? 여기서 말하는 다른 픽셀이라는 것이 무엇이며, 이 픽셀들의 gradient를 마스킹한다는 의미는 더더욱 무엇인가요? 주어들에 대한 구체적인 예시 및 마스킹 과정 등을 설명해주면 좋을 것 같습니다.
그리고 개인적으로 리뷰를 읽으면서 드는 전체적인 느낌은 논문의 내용을 정리해서 글을 작성한다기 보다는 논문에 명시된 내용을 직독직해하는 기분이 조금 드는 것 같아요. 물론 리뷰 내용이 상당히 디테일하고 꼼꼼해서 리뷰를 읽은게 아닌 제가 직접 논문을 읽은 듯한 기분이 들기도 하여 좋았지만, 저자의 말을 옮겨서 작성한 듯한 표현 혹은 문장 구조 때문인지 종종 리뷰 내용 중 전달하는 내용이 무엇인지 이해하기 어려운 부분들이 나타나기도 하네요. (물론 이번에 리뷰로 작성하신 논문 자체가 다루는 내용이 어려워서 더 그렇게 느꼈을 수도 있었겠네요ㅎㅎ;)
제 개인적으로는 한 섹션이 하나씩 끝나거나 중요한 부분의 설명이 마치면 해당 내용에 대해 간략하게 정리요약 해주는 글을 작성하는 것이 남한테도, 그리고 본인이 나중에 리뷰를 찾아서 다시 읽을 때도 이해하는데 도움이 더 잘 됐던 것 같아요. 도경님도 한번 각 섹션에 대한 내용 요약을 리뷰 중간중간에 작성하시거나 혹은 다른 더 좋은 방법을 찾으신다면 지금보다 더 좋은 리뷰를 작성하실 수 있을 것 같아요.
댓글 감사합니다.
우선 observed, unobserved, both의 경우 이해하신 것과 같이, 어떤 pixel은 observed이고 어떤 pixel은 unobserved일 것입니다. 둘 다라는 것은, 앞 부분에서 주어진 pixel 집합(set)이라고 했기 때문에 어떤 pixel 집합속에는 observed, unobserved, 혹은 observed와 unobserved pixels가 모두 포함되어있을 수 있는 경우를 의미합니다. observed는 observed pixel로 구성된 pixel set이고, unobserved 는 unobserved pixel로 구성된 pixel set이 되겠네요. 제가 다시 읽어보았을 때 오해할 수 있는 소지가 있겠네요… 저도 처음에 ‘둘 다’라는 경우가 모호할 것 같아서 집합이라는 표현으로 표현했는데 부연설명이 있었으면 좋았을 것 같네요.
두번째로 질문주신 부분에 대해서는 바로 위의 내용과 관련이 있는데요, 간단히 설명하면 loss 계산 시 observed, unobserved, both와 같은 경우에 해당되는 pixel에만 backpropagation을 한다는 의미로 이해했습니다. 만약 해당 pixel이라는 것이 observed pixel이라고 했을 때, observed pixel set에서 observed, unobserved pixel들 중 unobserved pixel이 다른 pixel을 의미하는 것이고, unobserved pixel에 대해 masking하여 observed pixels에 대해서만 backpropagation을 진행한다는 의미입니다. ‘다른’, ‘해당’같이 명시적으로 표시하지 않아서 이해가 어려웠을 것 같네요..
좋은 피드백 감사합니다!
안녕하세요 좋은 리뷰 감사드립니다.
우선은 해당 분야에 대한 이해도가 낮아 실험 부분의 평가 metric에 관해 질문드리고 싶습니다. Rel과 RMSE에 관해서는 알겠는데 ‘예측된 pixel의 depth가 특정 간격(δ)내 있는 비율’이 무었인지 정확히 이해가 가지 않습니다. 예를 들어 1.05↑로 표시된 결과는 각 픽셀별로 depth를 예측할 때 GT의 1.05배 이내에 예측값이 존재하는 경우인가요?
이전까지 3D Detection분야의 논문을 리뷰해주시면서 point cloud의 특성에 관해 설명해주셨는데 이번 리뷰에 등장한 depth 정보가 특정 환경으로 인한 missing data가 발생한다는 점이 point cloud와 비슷하다는 생각이 들었습니다. 그렇다면 김도경 연구원님께서는 point cloud의 missing data를 보완하기 위한 방법론을 탐색하기 위해 이 논문을 읽게 되신 건지 궁금합니다.
댓글 감사합니다.
우선 metric의 경우, threshold를 지정하여 accurcay를 비교한 값입니다. 조금 더 자세히 설명하면 gt와 depth estimation한 값 중 큰 값을 분자, 작은 값을 분모에 두어 1보다 큰 값을 얻도록 합니다. 예측한 depth 값의 min, max값이 threshold 범위 내 일 경우 True positive로 정의하게 됩니다.
point cloud나 rgbd 데이터 모두 depth 정보를 가지고 있는데, sensor에서 측정한 raw data의 경우 depth정보의 noise가 많고 loss가 많이 있는 것으로 알고 있습니다. 이러한 depth 정보를 보완하는데 도움이 될 것이라 생각했고, 제안서를 위해 논문 survey를 하면서 접하게 되어 읽어보게 되었습니다.
감사합니다.