안녕하세요. 이번 주차 X-Review에서는 Streaming video에서 action을 다루는 두 가지 task와 각 task에서의 방법론을 각각 하나씩 소개해드리려고 합니다. 두 task와 각 방법론은 아래와 같습니다.
- Online Action Detection (OAD) – [ICCV 2021] OadTR: Online Action Detection with Transformers
- Online Temporal Action Localization (OnTAL) – [PR 2022] 2PESNet: Towards online processing of temporal action localization
이번 학기 캡스톤 수업에서 더욱 빠른 범죄 대응을 위한 지능형 CCTV를 만들어보려고 구상중인데, 실시간으로 들어오는 프레임들로부터 특정 action을 인지하거나 더 나아가 구간을 찾는 일은 기존처럼 offline 환경에서 연구되던 task들로는 해결하기 힘듭니다.
기존 TAL은 offline 비디오를 다루며 이는 학습, 추론 시 하나의 비디오를 통째로 받아 공간적으로나 시간적으로 전체 맥락 정보를 파악하여 task를 수행할 수 있다는 장점이 있습니다. 하지만 online 상황에서는 현재 시점까지의 프레임까지만 가진 채로 action을 인지하거나 구간을 찾아야한다는 강력한 제한이 생기게 되어 OAD, OnTAL과 같은 조금은 다른 접근 방식이 요구됩니다.
각 task에 대해 우선 간략히 요약하여 설명드리자면, OAD는 실시간으로 들어오는 프레임들이 background인지, 아니면 하나의 action에 속하는지 단순 분류하는 것입니다. 이 때 입력되는 프레임들을 시계열 데이터로 취급하여 RNN 기반의 layer를 사용한다면 접근 가능한 과거 프레임들의 temporal 정보를 활용할 수 있겠죠.
이와 다르게 OnTAL은 프레임 별로 어떤 action인지 찾는 것은 맞지만, 궁극적으로는 그렇게 찾은 action 프레임들의 시작과 끝을 의미론적으로 파악하여 하나의 ‘구간’을 만들어내는 것이 목적입니다. 이번 리뷰에서는 OAD task 관련 방법론을 먼저 소개해드리고, OnTAL 방법론은 다음 편에서 다뤄보도록 하겠습니다.
실생활에 비디오 관련 인공지능 기술을 접목시키고 활용한다는 관점에서 보면, 아직 갈 길이 멀지만 online setting에서의 task 수행이 굉장히 큰 강점으로 작용할 것이라는 생각이 드네요.
더욱 자세한 이야기들은 논문([ICCV 2021] OadTR: Online Action Detection with Transformers)에서 저자의 설명과 함께 알아보겠습니다.

1. Introduction
Introduction은 OAD task에 대한 간단한 소개와 함께 시작합니다.
OAD의 목적은 미래 시점의 프레임에 접근할 수 없는 스트리밍 비디오 속에서 어떤 action이 일어나고 있는지 분류하는 것입니다. 추후에 더욱 발전한다면 자율 주행에서의 general한 상황 판단이나 CCTV 감시, 이상상황 탐지 등에 적용될 수 있을 것입니다.
Online 상황이라는 것 자체가 미래 프레임까지 전부 보고 action 여부를 판단하는 것이 아니기 때문에 현재 시점의 프레임과 더불어 이미 주어진 과거 시점 프레임의 귀한 정보들을 잘 활용하는 것이 굉장히 중요하겠죠. 제가 연구실에 처음 들어온 뒤 비디오 관련 task들을 찾아보다가, 비디오에 semantic segmentation이 적용되어 있는 동영상을 본 적이 있습니다. 어차피 픽셀 하나하나에 segmentation 라벨을 붙여줘야 한다면, 프레임 별로 가져와서 각 이미지에 segmentation을 수행하며 쌓아가는 것과 무엇이 다른지 잘 이해가 안되었던 적이 있습니다.
그런 관점에서 OAD도 마찬가지로 2D backbone을 활용하여 각 프레임마다 독립적으로 feature를 추출하고 어떠한 action인지 분류하여 수행할 수 있는 것은 사실입니다. 하지만 비디오의 인접한 프레임들은 일반적으로 큰 redundancy를 가지고 있고, 프레임들이 시간 축을 따라 흘러갈 때 의미론적으로 연결되어 있기 때문에 추출한 feature를 기반으로 RNN 등의 layer를 사용하여 temporal information을 활용하는 것이 성능 면에서 더욱 유리하다는 점을 짚고 넘어가셨으면 좋겠습니다.
다시 Introduction으로 돌아와서, 그 당시까지 OAD 연구에는 과거 정보로부터 long-term historical information을 잘 활용하기 위해 대다수의 방법론이 RNN 기반의 architecture를 채택했습니다. 하지만 RNN은 병렬처리를 할 수 없고 gradient vanishing 현상이 발생할 수 있다는 단점을 가지고 있죠.
위와 같은 RNN의 단점을 보완하며 등장한 것이 바로 Transformer이고, 이미 DETR, ViT도 등장하여 vision 분야에서도 많이 쓰이던 시점이었습니다. 본 논문에서 Transformer를 사용하는 컨셉은 vision 분야에서 CNN의 단점을 지적하기보다는, 시계열 데이터를 처리하기 위한 RNN의 단점을 극복하겠다는 쪽에 조금 더 가까운 것 같습니다. 본 논문은 Transformer가 등장한 후 다양한 vision 분야에서도 Transformer가 적용될 때, OAD에서 이를 최초로 활용하였다는 것에 의미가 있다고 생각합니다.
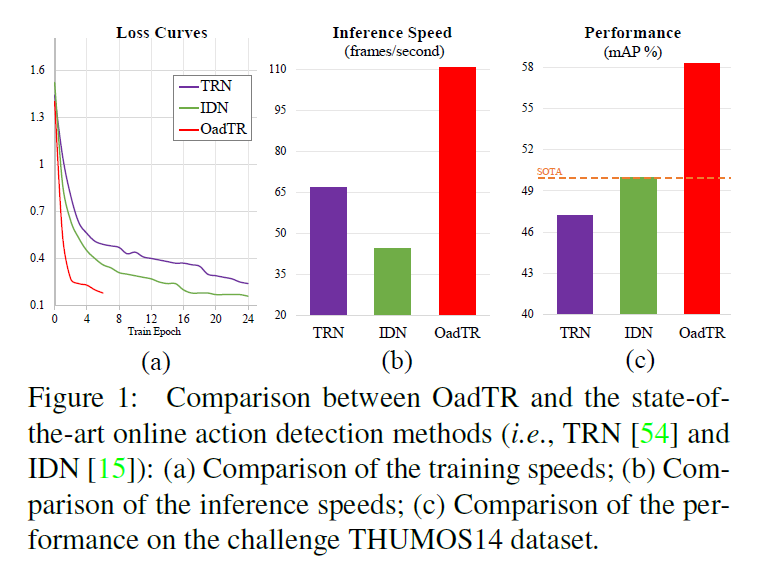
본 논문에서 OAD에 최초로 Transformer를 적용하였기에 방법론의 이름은 OadTR입니다. 그림 1은 RNN을 활용하여 OAD task를 수행하는 기존 SOTA 방법론인 TRN, IDN과 OadTR의 학습 추이, inference speed, 성능 비교 표입니다. 상대적으로 적은 epoch 내에 수렴하며 성능도 월등히 높고, inference 속도도 압도적인 것을 볼 수 있네요.
논문의 contribution을 정리한 뒤 방법론으로 넘어가겠습니다.
Contribution
- We are the first to bring Transformer into online action detection task and propose a new framework, OadTR
- We specially design the encoder and decoder of OadTR which can aggregate long-range historical information and future anticipations to improve online action detection
- OadTR significantly outperforms SOTA methods.
Related work는 먼저 기존 RNN 기반의 OAD 방법론들을 언급하고 있습니다. 이후 Temporal Action Localization은 비디오의 전체 구간을 보아야 수행 가능하기 때문에 online task에 적합하지 않다며 넘어가고, 마지막으로 vision 분야에서 Transformer의 활용에 대해 간단히 정리하고 있습니다. 참고로 OnTAL은 제가 다음 편에서 소개해드릴 논문에서 최초로 제안한 task이기 때문에 2019년 기준으로는 존재하는 OnTAL 방법론이 없었습니다.
2. Methodology
OadTR은 encoder-decoder 구조로 이루어져 있고, long-range historical relationship과 future information을 동시에 추출함으로써 현재 frame에 대한 action 구간을 분류합니다. 먼저 현재 프레임이 들어오면, ActivityNet v1.3으로 사전학습된 two-stream network나 Kinetics로 사전학습된 I3D backbone을 활용하여 프레임에 대한 feature를 추출합니다.
이후 task token을 clip-level feature로 embed하고, 추출해놓은 과거 프레임들의 feature와 함께 encoder에 태우게 됩니다. task token은 ViT의 class token과 같은 역할로 학습 가능하며, 과거와 현재 프레임 전체의 global temporal relationship 정보를 담고 있다고 볼 수 있습니다. [참고]
2.1 Problem description
계속해서 입력되는 streaming video V = \{f_{t}\}_{t=-T}^{0}라고 칭하겠습니다. 현재 시점의 프레임이 f_{0}이고 과거의 프레임 T개를 보는 것이므로 활용하는 프레임은 총 T+1개 입니다. 미리 말씀드리자면 데이터셋에 따라 T=31 또는 T=63을 활용했다고 하네요.
그리고 현재 프레임 f_{0}에 대한 ground truth action label y_{0} \in{} \{0, 1, \cdots{}, C\}로 주어지는데, 0번 인덱스는 background를 의미합니다.
2.2 OadTR
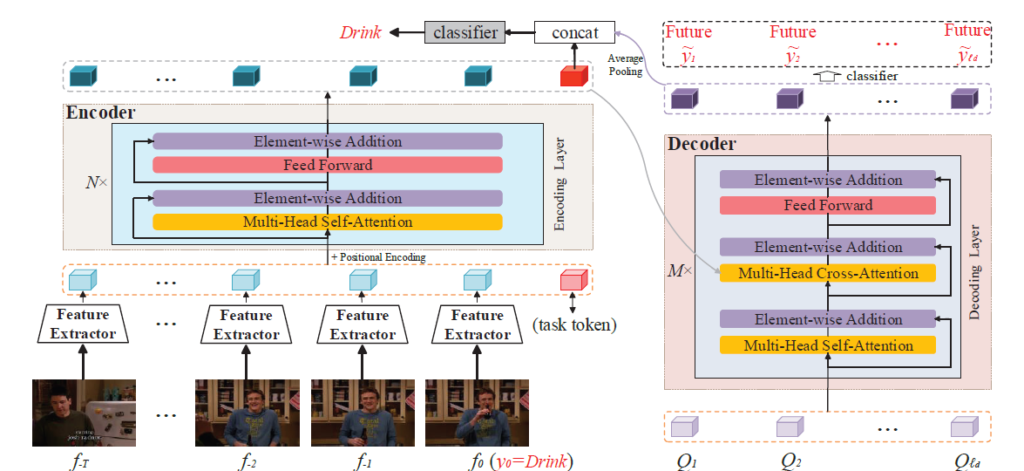
OadTR은 frame feature 간의 long-range contextual information을 잘 잡아내기 위해 그림 2와 같이 encoder-decoder 형태로 이루어져 있는데, 자세한 내용은 이제부터 알아보겠습니다. 사실 형태 자체는 original Transformer와 거의 동일하다고 볼 수 있습니다.
2.2.1 Encoder
현재 프레임이 들어오면, 앞서 말씀드린 feature extractor; two-stream network 또는 I3D가 각각 3072차원, 4096차원의 feature vector를 추출해냅니다. 이후 또 다른 FC layer를 태워 D차원의 feature로 만들고, 이전 프레임의 D차원짜리 feature들과 합쳐 F=\{token_{t}\}_{t=-T}^{0} \in{} \mathbb{R}^{(T+1) \times{} D}를 만듭니다.
그리고 어느 하나의 token에 편향되지 않는 representation을 학습하기 위해 global feature token_{class} \in{} \mathbb{R}^{D}를 아래와 같이 F에 붙여 \tilde{F}를 만들어줍니다. 논문에서는 task token이라고 칭하는데 notation은 token_{class}이네요.
- \tilde{F} = Stack(\{token_{t}\}_{t=-T}^{0}, token_{class}) \in{} \mathbb{R}^{(T+2) \times{} D}
다음으로 positional embedding은 sinusoidal input 대신 trainable embedding을 사용하였고, 이는 E_{pos} \in{} \mathbb{R}^{(T+2) \times{} D}와의 element-wise sum을 의미합니다.
수식은 아래와 같습니다.
- X_{0} = \tilde{F} + E_{pos}
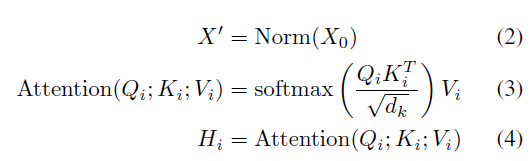
이후에도 마찬가지로 일반적인 Transformer encoder와 동일하게 동작합니다. X_{0}를 normalize하여 얻은 X'을 각 FC layer에 태워 Q_{i}, K_{i}, V_{i}를 만들고 총 N_{head}번의 multi-head self-attention 연산을 거쳐 H_{1}, H_{2}, \cdots{}, H_{N_{head}}를 얻을 수 있습니다.
이들을 concat한 뒤 다시 한 번 FC layer를 거쳐 \hat{H} \in{} \mathbb{R}^{(T+2) \times{} D}를 만들어주게 됩니다. 이후 아래 수식과 같이 FFN, LN, residual connection도 동일하게 적용됩니다.
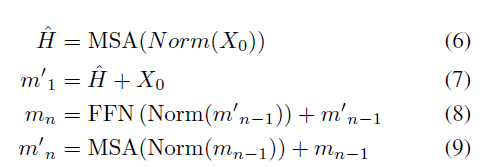
위 수식에서 n은 총 N개의 encoder block 인덱스를 의미하고, m_{N} \in{} \mathbb{R}^{(T+2) \times{} D}는 Encoder의 최종 output, 그 중 최종 output 중 task token 부분은 m_{N}^{token} \in{} \mathbb{R}^{D}이라고 칭하겠습니다.
2.2.2 Decoder
OadTR에서의 decoder는 과거, 현재 정보를 이용해 미래를 예측해내는 역할을 수행합니다. 하나의 Decoder layer에서 l_{d}개의 학습 가능한 decoder task token Q_{i} \in \mathbb{R}^{D'}, i=1, 2, \cdots{}, l_{d}를 입력받아 self-attention, encoder의 output과 cross-attention을 진행하면 결과적으로 decoder에서는 l_{d}개의 예측된 미래 token \tilde{Q}_{i} \in \mathbb{R}^{D'}, i=1, 2, \cdots{}, l_{d}를 얻을 수 있게 됩니다.
Decoder를 거쳐 나온 \tilde{Q}를 활용해 미래를 예측하고, 학습 중에는 미래 시점에도 접근할 수 있기에 예측한 값과 실제 미래 프레임의 label을 활용해 temporal 정보를 더욱 익힙니다. 미래를 예측한다는 것이 좀 뜬금없을 수 있는데, 사람이 영화를 볼 때 과거의 정보에만 의존하는 것이 아니라 가까운 미래에 일어날 일까지 예측해가면서 현재의 내용을 파악하기 때문에 위와 같이 decoder를 설계하였다고 합니다. 이에 대해 뇌 과학 논문을 인용하며 이야기하고 있었습니다.
2.2.3 Training
학습은 굉장히 간단합니다.
지금까지 얻은 것들을 정리해보면 encoder의 출력으로 얻은 task token m_{N}^{token}, decoder의 출력으로 얻은 미래 representation에 대한 예측 \tilde{Q}_{i} \in \mathbb{R}^{D'}, i=1, 2, \cdots{}, l_{d}가 있습니다.
우선은 현재 시점의 프레임에 대한 예측이 맞았는지 틀렸는지부터 학습해줘야겠죠. 그렇다면 현재 시점에 대한 예측p_{0} \in \mathbb{R}^{C+1}를 먼저 만들어야 하는데, 이는 아래 수식과 같습니다.
- \tilde{Q} = Avgpool(\tilde{Q}_{1}, \tilde{Q}_{1}, \cdots{}, \tilde{Q}_{l_{d}})
- p_{0} = softmax(Concat[m_{N}^{token}, \tilde{Q}]W_{c})
Decoder에서 예측한 미래 representation을 average-pooling한 \tilde{Q}와 task-related feature인 task token을 concat하고 FC layer, softmax를 거쳐 최종 class score를 얻는 것을 볼 수 있습니다.
일단 p_{0}를 생성하는 방식까지는 살펴보았고, OadTR에서는 decoder가 예측한 l_{d}개의 미래 representation에 대한 학습도 진행해줍니다. Inference할 때에는 미래에 접근할 수 없어 p_{0}을 이용해 prediction을 만들겠지만, 학습 시에는 offline setting이기 때문에 미래 프레임의 label을 이용합니다. i번째 예측에 대한 score는 아래와 같이 구해줍니다.
- \tilde{p}_{i} = softmax(\tilde{Q}_{i}W'_{c}), i=1, 2, \cdots{}, l_{d}
단순히 FC layer를 태워 분류하고 있습니다. i번째 예측에 대한 실제 라벨은 \tilde{y_{i}}라고 할 때, 최종 loss는 아래와 같습니다.
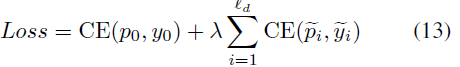
방법론은 이것으로 마치고, 실험 부분으로 넘어가도록 하겠습니다.
3. Experiments
본 논문에서는 OadTR의 성능을 평가하기 위해 HDD, TVSeries, THUMOS14 데이터셋에 대한 벤치마크를 진행하였습니다. Ablation도 일부는 세 가지 데이터셋 모두에 대해서 성능을 보여주며 다양하고 풍부한 실험 결과들을 분석하고 있습니다.
3.1 Dataset and setup
OAD task에 대한 첫 소개이다보니 각 데이터셋과 실험 설정들에 대해 간단히 알아보겠습니다.
HDD

HDD 데이터셋은 Honda Research Institute Driving Dataset의 준말로 약 104시간의 driving scene 비디오와 그에 해당하는 Camera, LiDAR, GPS, IMU, CAN 센서 값들로 구성되어 있습니다. 위 그림3과 같이 블랙박스의 시점으로 촬영되어 있어 차선 변경, 유턴, 좌회전/우회전, 주차 등 총 11개의 차량 action을 분류하는데에 사용한다고 보시면 됩니다. 학계에서 사용되는 train, evaluation section을 그대로 사용했다고 합니다.
본 논문에서 HDD 데이터셋의 visual 정보는 사용하지 않고 센서값들만 입력으로 주어 실험을 진행하였습니다.
TVSeries
TVSeries 데이터셋은 6개의 유명한 TV 시리즈 비디오들로 구성되어 있습니다. OAD task를 최초로 제안한 [ECCV 2016] Online Action Detection 논문에서 task와 함께 공개한 데이터셋이고, 한 시리즈 당 약 150분이기 때문에 총 길이는 약 16시간에 해당합니다.

위 그림 4와 같이 그리 복합적이지 않은 action 총 30가지 클래스들로 이루어져 있습니다. 전체 데이터셋에서 하나의 클래스는 최소 50회 이상 등장하고, 일반적으로 드라마나 시트콤은 일상에 가까운 영상들을 포함하기 때문에 앞서 살펴본 HDD 데이터셋보다는 더욱 제한 없고 다양한 범위의 background를 가지고 있습니다.
THUMOS14
THUMOS14 데이터셋은 Temporal Action Localization task에도 활용되어 이름이 익숙하실 것으로 생각됩니다. 본래는 untrimmed video에서의 Action Recognition을 위해 1010개의 validation 비디오와 1574개의 test 비디오로 구성되어 있는데 Action Recognition에서는 temporal annotation이 필요하지 않습니다.
반면 Temporal Action Localization이나 OAD에서는 temporal annotation이 필요하기 때문에 해당 annotation이 제공되어 있는 200개의 validation 비디오와 213개의 test 비디오만을 각각 학습, test 용으로 사용하고 있습니다. 멀리뛰기, 창 던지기, 테니스 스윙 등의 스포츠 관련 20개의 action 클래스로 구성되어 있습니다.
Evaluation metric
HDD와 THUMOS14 데이터셋은 기존과 동일하게 mAP를 평가지표로 사용합니다. OAD를 처음 제안한 논문에서 TVSeries 데이터셋과 함께 mean calibrated Average Precision(mcAP)까지 제안하여 학계에서는 TVSeries 데이터셋만 mcAP를 평가지표로 사용하는 점 참고하시면 좋을 것 같습니다.
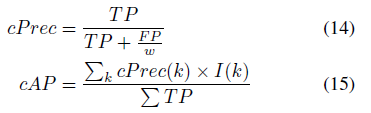
mcAP의 수식은 위와 같습니다. 우선 w는 negative frame과 positive frame간의 비율이고, I(k)는 프레임 k가 TP인 경우 1이 되는 indicator입니다. 상대적으로 background data가 많은 클래스가 있을 때, 해당 클래스에서는 일부 background 프레임들이 실제 TP보다 더 높은 confidence를 가지며 잘못 탐지되는 경우(FP)가 많아지게 됩니다. 이렇게 되면 AP가 감소하여 제대로 분석하기가 힘들어지는데, OAD 상황에서 만큼은 이를 방지하기 위해 FP를 w로 나눠주어 Precision 계산 시 positive와 negative의 weight를 동일하게 보정해주자는 것입니다.
3.2 Compared with state-of-the-art methods
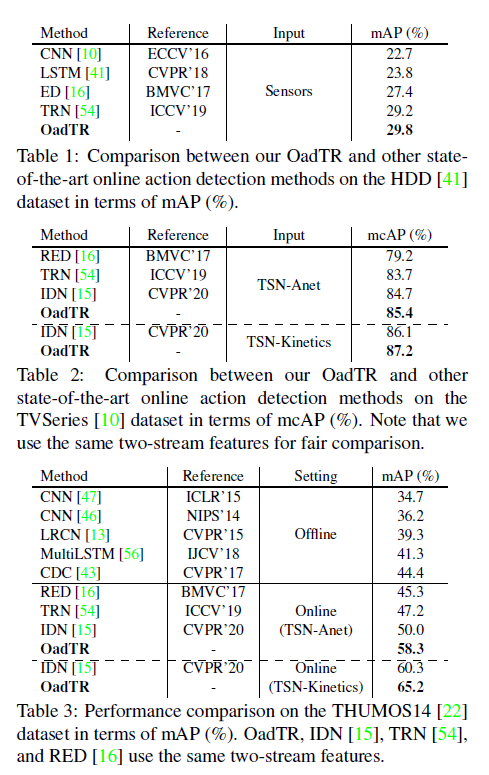
표 1, 2, 3은 각 데이터셋에 대한 벤치마크 성능입니다.
모든 section에서 OadTR이 가장 높은 성능을 보이는 것을 알 수 있습니다. 표 2, 3의 Online setting에서 점선은 backbone network, feature dimension 차이를 분리하기 위한 것이고, 대략 5~6년 전의 RNN 기반 Offline 방법론들보다도 훨씬 더 높은 성능을 보이는 것을 알 수 있습니다. 유난히 THUMOS 데이터셋에서의 성능 향상 폭이 두드러지네요.
표 3에서 CNN은 각각 two-stream network, I3D로 feature 추출 후 linear evaluation 성능인데 temporal information을 명시적으로 모델하지 않는 경우에는 성능이 상대적으로 낮을 것을 볼 수 있습니다.
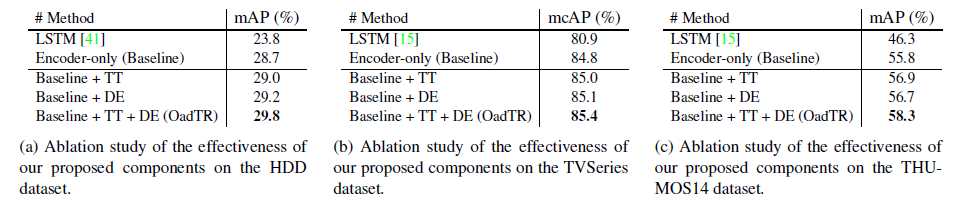
다음은 모듈 별 ablation 실험 관련 표 5입니다.
(a), (b), (c)는 각각 데이터셋에서의 성능이고 베이스라인은 Transformer encoder만을 활용하여 p를 만들어냈을 때의 성능을 의미합니다. TT는 task token 활용, DE는 decoder를 활용하여 미래 representation을 학습한 경우를 의미합니다.
TT를 사용하지 않는 경우 현재 프레임의 encoder output으로 분류를 하게 되는데 현재 프레임에 편향되지 않은 global representation을 담고 있는 task token을 분류에 사용하는 것이 성능이 더 높은 것을 알 수 있습니다. 이는 확실히 현재 프레임의 encoder output이 현재에 편향되어 있고, 이렇게 편향된 representation보다 과거 프레임 전반까지 아우르는 global task token을 활용하는게 더욱 좋은 표현력을 갖는다는 것을 입증하였다고 볼 수 있습니다.
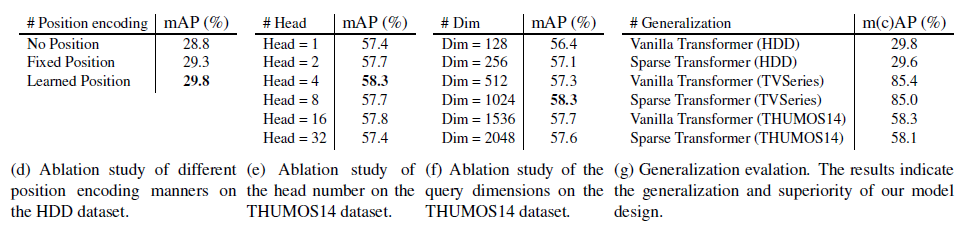
이어서 표 5에 더욱 많은 ablation 실험들이 있습니다.
Positional encoding 종류, Multi-head의 개수, decoder query dimension(방법론 부분에서 설명드린 decoder에 들어가는 task token dimension), Transfomer 모델에 따른 성능이 각각 표 5- (d), (e), (f), (g)에 해당합니다. 표 (g)에서 저자의 방법론을 Sparse Transformer에 적용하는 경우 Vanilla Transformer에서보다 큰 성능 하락 없이 연산량을 낮출 수 있음을 보여주고 있습니다.
이외에도 l_{d} 수, 하나의 head 내 layer 개수, pooling 방식에 따른 성능도 논문에 포함되어 있으니 궁금하신 분들은 찾아보시면 좋을 것 같습니다.
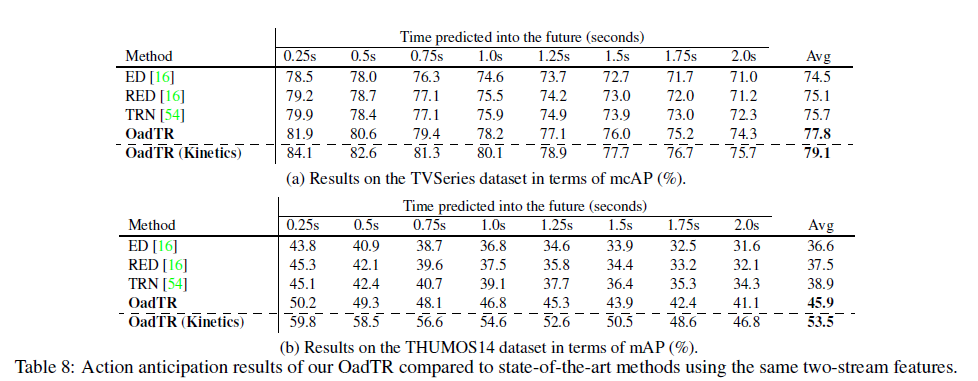
표 8은 현재까지의 프레임만을 보고 미래를 예측하여 학습에 사용하는 방법론들 간 예측된 미래에 대한 mAP 성능입니다. 나머지는 전부 RNN 기반 방법론들인데 Transformer로 넘어오며 예측된 미래에 대한 성능이 크게 향상된 것을 볼 수 있습니다. 추가로 Kinetics dataset으로 사전학습하면 성능이 크게 오른다는 점도 알 수 있습니다.
리뷰 초반에 보여드렸던 그림 1을 통해 높은 성능 뿐만 아니라 학습의 빠르고 안정적인 수렴과 좋은 inference time까지 가져갈 수 있다는 점이 인상깊었습니다.
4. Conclusion
방법론의 경우 기존의 Transformer를 잘 가져와 적용했다는 점과 task token의 활용, decoder를 활용하여 학습 중 접근 가능한 미래 frame을 참조하여 좋은 표현력을 만들어냈다는 것을 알 수 있었습니다. 방법론의 참신함도 좋지만 이에 대한 다양한 실험 결과들을 보여주고 있어 OAD 연구 동향의 기초를 다지는데 도움이 된 논문이었습니다.
여기까지하여 Part1 – OAD 부분을 마치고, 다음 편에서는 OnTAL task의 방법론에 대해 알아보도록 하겠습니다.
리뷰 마치겠습니다.
안녕하세요. 좋은 리뷰 감사합니다.
1) 제가 이해한 바로는 OAD는 background와 action으로 분류하는 것이고 OnTAL은 OAD에 구간을 찾는 것까지 추가한 것으로 이해하면 될까요?
2) 비디오의 인접한 프레임들이 redundancy를 가지고 있다는 의미는 t 시간의 프레임이 t+1 시간의 프레임과 비슷한 프레임일 가능성이 높다는 것을 말하는 걸까요?
3) HDD 데이터셋에서 visual 정보를 사용하지 않고 왜 센서값만 입력으로 주어서 실험을 진행했는지 이해가 가지 않습니다. 갑자기 센서? 하는 느낌도 들고요. 이 부분에 대해서 논문에서 언급한 부분이 있을까요?
감사합니다
1) OAD는 이진 분류는 아니고 데이터셋에 존재하는 action class와 background까지 합쳐 총 C+1개의 action 중 하나를 분류하는 task입니다. 이러한 OAD에 구간까지 잘 모델링하여 찾는 것이 OnTAL입니다.
2) 맞습니다 장면이 전환되지 않는 이상 인접한 프레임끼리는 시각적으로 굉장히 유사한 내용을 포함하게 됩니다.
3) HDD 데이터셋은 센서와 시각 정보 모두 포함하고 있는데, 다른 논문을 찾아보니 보통은 (Sensor) / (Sensor + Visual) / (Visual) 등 다양한 input을 주어 성능을 측정하고 있긴 합니다. 왜 저자가 Sensor 정보만 사용하였는지는 알 수 없었지만 Sensor 정보도 결국은 시계열 데이터에 해당하기 때문에 어느정도 납득하고 넘어가야할 부분인 것 같습니다.
리뷰 잘 봤습니다. 저도 OAD라는 task에 대해서는 이번에 처음 알게 된 것 같습니다.
방법론을 쭉 살펴봤을 때 사실 Transformer 구조를 사용한 것 말고는 별다른 구조가 없는 것 같습니다. 방법론은 그냥 OAD에 transformer 찍먹 해본 느낌인데 혹시 이것 말고 별다른 contribution이 있을 까요?
본 논문 기준으로는 아직 연구가 많이 진행이 안된 모양인데, 나중에 후속 논문도 리뷰해 주시면 좋을 것 같습니다.
Transformer를 잘 가져왔다는 것 자체가 큰 contribution으로 인정된 것으로 보입니다. class token이나 decoder 구조도 이미 존재하던 것들이라 독창적인 면에서는 조금 부족할 수 있지만, 본 방법론에 대해 다양한 실험을 제공했다는 점도 유의미하다고 생각하였습니다.
아무래도 코드가 존재하고 간단한 방법론 위주로 먼저 서베이했기 때문인데, 22년도, 23년도에도 OAD 연구가 진행되었는지 찾아보도록 하겠습니다.