안녕하세요. 요즘 여전히 학습 관련된 논문을 많이 찾아보고 있습니다. 이번 논문은 CVPR workshop 논문인데, 내용이 괜찮은 것 같아서 한번 들고 와봤습니다. (논문 끝나자마자 제안서 작업으로 바쁘니… 겸사겸사 간단한걸로 ㅎㅎ;;) “L3D-IVU Workshop”에 제출되었던 논문이고, “Workshop on Learning with Limited Labelled Data for Image and Video Understanding”가 주제입니다.
Introduction
Self-supervised video representation learning에 대해서 연속해서 리뷰를 쓰고 있어서 이제 많이 익숙하실 거라고 생각하는데요. 대부분의 연구가 크게 2가지 흐름을 가지고 연구가 수행되고 있습니다.
- Pretext-task를 이용한 학습
- Contrastive learning을 이용한 학습
- 기타 (Feature 레벨의 분포를 이용한 학습)
각각의 방법론들 마다 약간의 차이가 존재하는데요. 오늘 논문에서 다루는 부분은 “Contrastive learning을 이용한 학습”에 속합니다. 일단 기본적으로 이 논문은 **[NeurIPS 2020] Self-supervised Co-training for Video Representation Learning**에서 알아낸 내용을 바탕으로 시작을 합니다.
다양한 선행 연구들을 바탕으로 video representation learning에서 hard-positive example을 고르는 것. 논문에서는 mining이라고 표현을 하는데요. 이 mining이 중요하다는 것이 입증되었습니다. 그 대표적인 예시가 위의 링크를 달아둔 CoCLR인데요. CoCLR에서는 RGB에서 사용할 hard-positive를 Motion 정보를 가진 optical-flow에서 가져오고, Optical-flow에서 사용할 hard-positive를 RGB에서 가져오는 식의 학습 방법을 가지고 이 방식이 꽤 인상깊은 성능 향상을 보여주었습니다.
이 논문에서는 CoCLR의 mining 과정이 한번만 수행되는 것이 False positive를 선택하는 것에서 부족하다는 점에서 착안하여 Cascade Positive Retrieval (CPR)을 제안하고, positive example mining 시스템 자체를 분석한 내용을 담고있습니다. 논문에서 제안하는 CPR은 이름에서 볼 수 있듯이 서로 다른 뷰에서 cascade stage를 거쳐서 positive example을 refine해가며 마이닝 하는 모듈인데요. 기존의 CoCLR가 반대되는 모달리티에서만 고려했다면, 이 방법론은 나의 현재 모달리티도 고려하는 방식이라고 보면 좋을 것 같습니다. 사실 Workshop논문이라 Contribution이 그렇게 많지는 않고 모듈 하나를 잘 제안했다 정도인데요. 그래도 요약을 해보면 아래와 같습니다.
- 기존 SSL 방법론에 쉽게 적용할 수 있는 Cascade Positive Retrieval 제안
- 제안하는 CPR에 대한 광범위한 분석 및 실험
- 마이닝 품질을 측정하기 위한 두가지 메트릭을 활용한 실험
- SOTA
Proposed Method
Instance Discrimination
Instance Discrimination(contrastive loss)기반의 방법론들에서 InfoNCE Loss를 이용했을 때 좋은 성능을 보이는 것이 여러 연구들을 통해 입증되었습니다. 제가 리뷰했었던 self-supervised video representation learning 연구들에서도 모두 InfoNCE Loss를 사용했었고요.
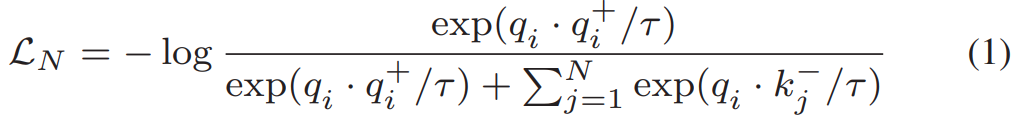
학습 자체는 모르시는 분들이 없겠지만… [수식 1]과 같이 수행이 됩니다. 비디오 V에서 클립 v_i가 샘플링되고 이 클립들 끼리 학습을 수행하는데요. 당연히 ‘+’가 붙을 경우 positive clip이고 ‘-’가 붙을 경우 negative sample 입니다. 이때 negative sample들은 query와 동일한 비디오가 아닌 클립셋으로 구성이 되고요.
Multi-instance Discrimination
InfoNCE는 negative clip이 여러개 존재하는 경우의 학습입니다. 만약 positive set이 여러개라면 어떻게 해야할까요? 이러한 학습도 지원하는 Loss가 있습니다. 바로 Multi-Instance InfoNCE (MIL-NCE)입니다.
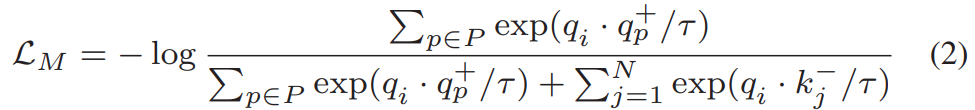
여기서는 negative만 set으로 만들어서 쓰는 것이 아니라, P라고 positive set을 함께 사용합니다. 이 셋은 augmentation된 쿼리 비디오와 함께 같은 라벨을 가진 다른 클립을 포함합니다. 예를 들어서 “펜싱” 카테고리라고 가정을 하면, 해당 비디오에 augmentation이 적용된 클립과 “펜싱” 라벨을 가진 다른 비디오들을 묶는다고 보면 됩니다.
Cascade Positive Retrieval
Introduction에서도 간략하게 소개했지만, 기존의 contrastive loss를 사용하는 SSL의 문제점 중 하나로 false negative와 non-augmented positive sample의 부족이 지적되어 왔습니다. CoCLR가 서로 다른 모달리티로 부터 positive sample을 추출하는 방식으로 이 문제를 일부 해결했습니다. 하지만 서로 다른 모달리티에서 추출하는 방식 자체에서 문제가 발생합니다.
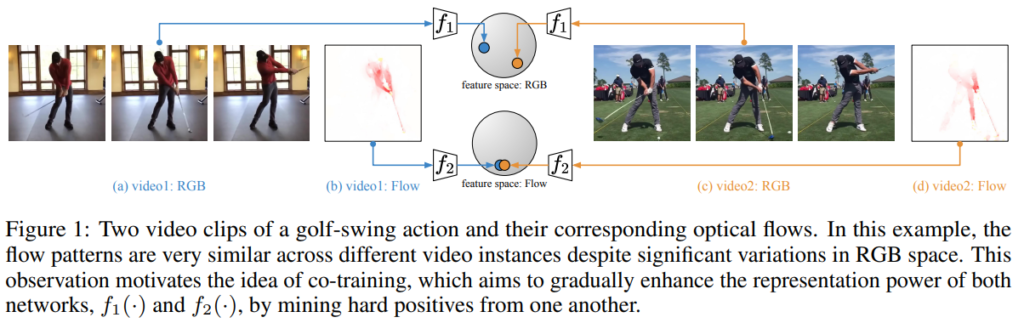
문제 정의로 넘어가기 전에 워낙 방법론이 간단하면서 CoCLR를 이해해야 알 수 있어서… 리마인드를 잠깐 해보자면… CoCLR에서 위와 같은 상황이 있다고 가정을 해봅시다. 두 비디오 모두 골프를 치는 영상에 대한 비디오이지만, 실내에서 치느냐 실외에서 치느냐에 따라 RGB에서의 표현력의 차이는 크게 발생합니다. 하지만 optical flow의 관점에서 보게된다면 두 비디오는 상당히 유사하다고 보일 수 있죠. 하지만 이 부분에서 거꾸로도 생각을 해보면 반대의 문제가 발생합니다. 골프 말고 비슷한 액션끼리는 어떨까요? 크리켓과 야구는 결국 휘두르는 움직임이 똑같을텐데 이러한 차이는 구분할 수 있을까요?

이러한 문제에 대한 예시는 [그림 2]에서 확인할 수 있는데요. 빨간색 글씨가 잘못 마이닝된 결과입니다. 베이스라인 방식이 CoCLR를 기준으로 하고 있는데요. 보면 이제 체리피킹이긴 하겠지만 대부분의 경우가 잘못 탐지된 것을 볼 수 있습니다. 이는 위에서 간단하게 설명했듯이 CoCLR의 방식에 따른 문제인데요. CoCLR가 RGB에 해당하는 hard-positive를 마이닝 할 때, optical flow에서만 보기 때문에 비슷한 액션들이 상당히 많은 데이터셋의 특성상 실제로는 다른 비디오가 선택되기 때문입니다.
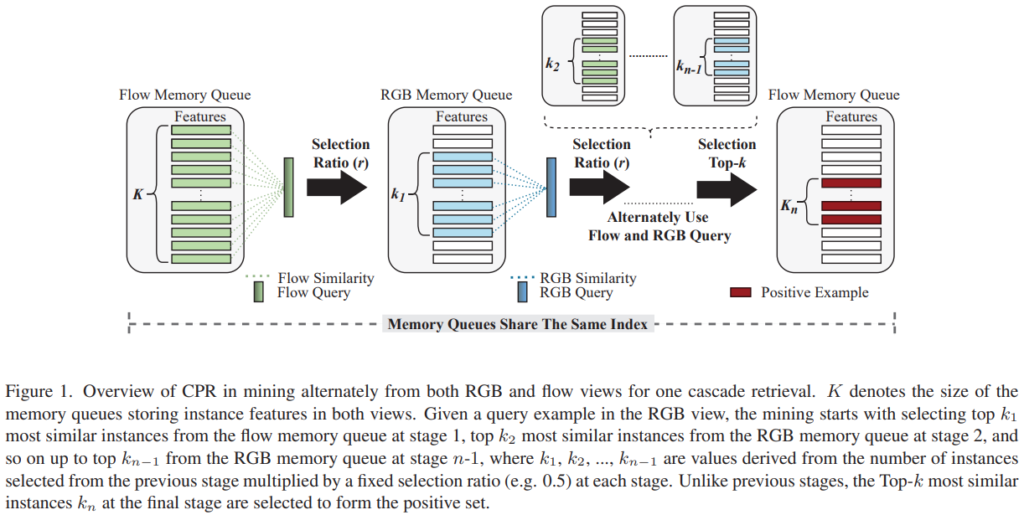
이러한 문제점들을 해결하기 위해 CPR에서는 multi-view(RGB와 Flow 모두 고려)의 장점을 도입해서 이 문제를 해결합니다. [그림 1]이 간단한 적용 예시 구조도인데요. Cascade의 뜻을 생각해보면 알 수 있는데 단계적으로 계속 걸러내는 형태의 구조를 가지고 있습니다. 먼저 Flow를 기반으로 positive sample의 후보군을 선정하면, 그 후보군에서 RGB 기반으로 한번 더 걸러냅니다. 논문에서는 이걸 스테이지라고 부르고, 스테이지 내에서는 일정 비율을 거르는 형식으로 작동하지만, 최종 스테이지에서는 top-k를 고르는 형태로 hard-positive example을 선별합니다.

구조에 대한 Pseudo code도 제공하는데요. 사실 코드도 제공하는 논문이라 그거 보는게 더 편할 수도 있습니다. 기본적으로 다른 방법론들에 적용할 수 있지만, 보면 알겠지만 변수가 많습니다. 그만큼 하이퍼 파라미터도 상당히 많아지고요. 코드 자체는 관심 있으시면 찾아보시면 좋을 것 같습니다.
Experiments
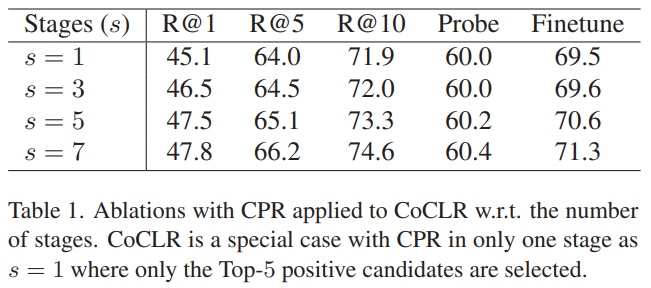
[표 1]은 스테이지의 갯수에 따른 성능 차이입니다. 스테이지가 깊어질수록 성능이 오르는 것을 볼 수 있는데요. 일단 학습 과정에서 100epoch의 학습을 고정했기 때문에 학습 시간에 따른 수렴 차이의 문제는 아닙니다. 이를 고려해보면 Refinement의 관점에서 positive sample의 정확도가 높아지기 때문에 성능이 오른다. 즉, 실제로 CoCLR가 한쪽 모달리티만 고려하는 것이 문제가 맞다는 것을 보여줍니다.
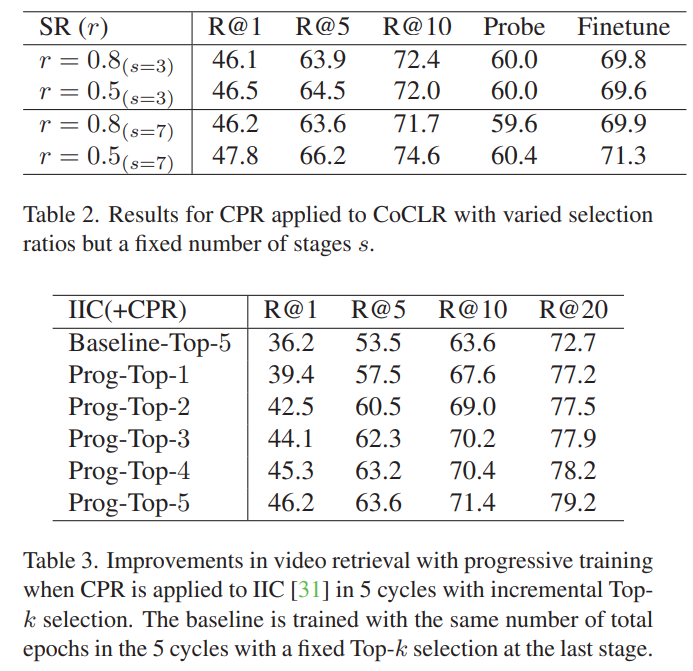
[그림 2]와 [그림 3]은 스테이지 내부에서 선택할 수 있는 수치에 따른 ablation인데요. 두가지를 선택할 수 있습니다. Stage에서 살려서 가져갈 positive sample의 비율과 최종적으로 선택할 top-k 값인데요. 이건 적당한 비율에 따른 문제라 그냥 이렇게 구현했구나 정도로 보면 좋을 것 같습니다. 다만, Baseline(CoCLR) 대비 성능 차이를 고려해보면 확실히 sampling 정확도가 좋아졌다는 것을 볼 수 있습니다.
[표 4]는 얼마나 positive sample을 잘 골랐는지에 대한 정량적인 지표를 계산한 결과인데요. CoCLR는 R@1에 대한 수치만 제시하여 비교하고 있습니다. 하지만 이 수치가 실질적으로 얼마나 많은 True positive를 가지는지 불분명하기 때문에 새로운 지표로 비교를 하고 있는데요.
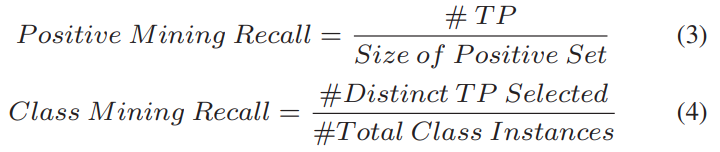
[수식 3]과 [수식 4]를 이용한 PMR(positive mining recall)과 CMR(class mining recall)을 새로운 메트릭으로 사용합니다. PMR은 선택된 positive set에서 최종적으로 선택된 top-k에서 TP의 비율을 측정하는 것이고, CMR은 1에포크에서 클래스끼리 구별이 된 TP의 비율을 의미합니다. 이러한 상황에서도 함께 비교를 해봐도 CPR을 적용했을 때 모든 지표에서 향상을 보이는 것을 확인할 수 있습니다.
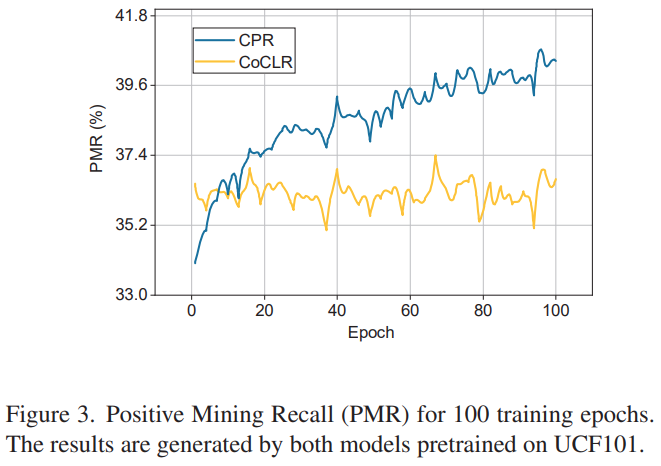
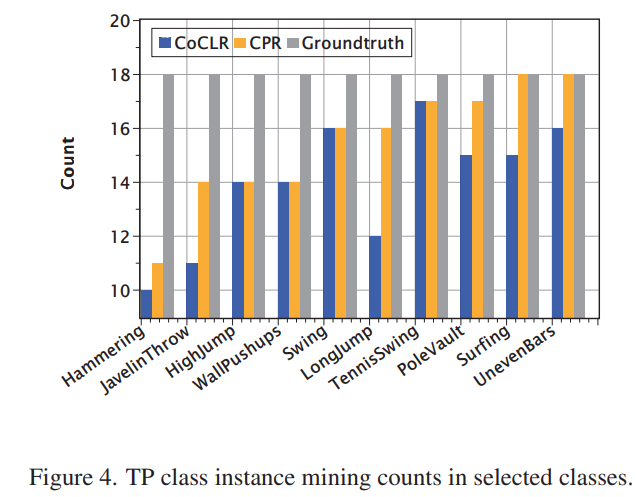
CoCLR와 CPR이 적용된 CoCLR의 비교 실험을 더 자세하게 보면 [그림 3]과 [그림 4]를 통해 볼 수 있는데요. CoCLR대비 CPR의 PMR이 학습을 거치면서 확실하게 개선(마이닝 과정의 정확도 개선)되는 것을 볼 수 있고, 클래스 별로 봐도 일부 클래스를 제외하면 더 골고루 선택하는 것을 볼 수 있습니다. 더 골고루 선택한다는 뜻은 비슷한 모션 정보를 가지고 있는 액션들 끼리도 충분한 구분력을 가지고 잘 구분했다는 뜻입니다.
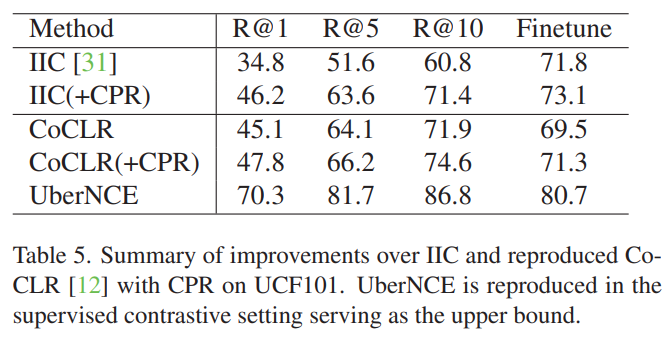
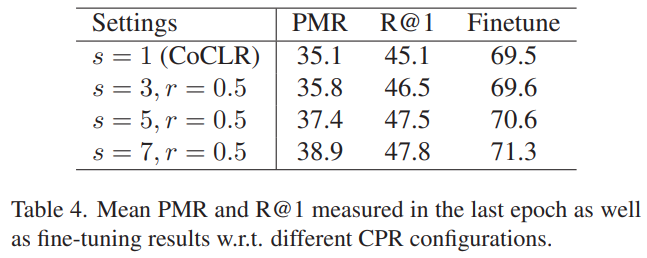
CoCLR 말고 다른 방법론에도 적용한 결과가 [표 5]입니다. IIC라는 방법론에 적용했을 때의 결과인데요. CoCLR에 적용한 결과와 마찬가지로 성능 향상이 있음을 볼 수 있습니다.

[그림 5]는 마이닝 결과인데, 참고하실 분들만 보고 넘어가시면 좋을 것 같습니다. (위의 3개가 Top-3 / 아래 3개가 Bottom-3)
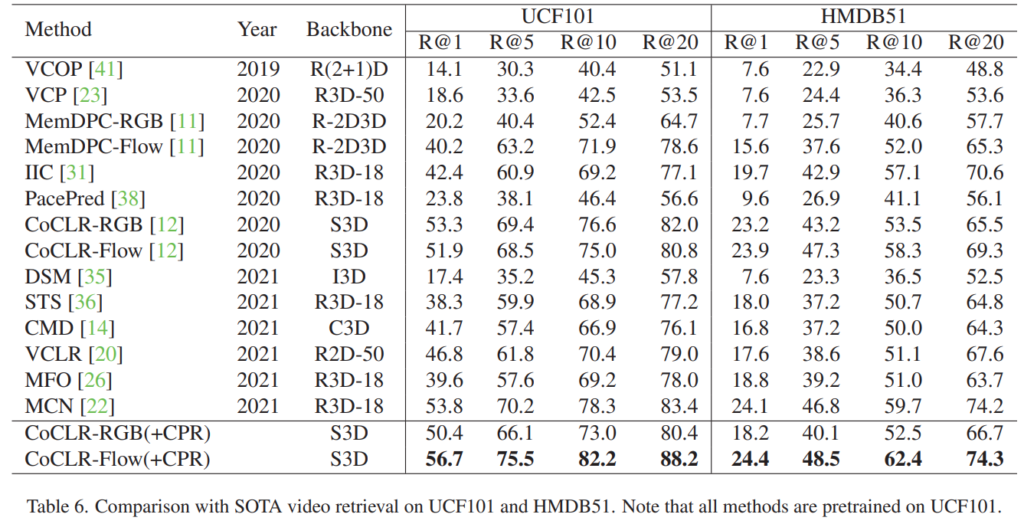
그래서 다른 방법론들과 retrieval에서 비교를 해보면 [표 6]과 같은데요. CoCLR방법론이 원래 성능이 꽤 좋은 방법론에 속하는데요. CPR을 적용하면 새로운 SOTA를 달성할 수 있음을 확인할 수 있습니다. 이는 특히 검색의 관점에서는 fine-tuning이 따로 필요한 것은 아니라서, 이러한 성능 향상이 결국은 CoCLR와 동일한 결론 “positive example을 잘 고르는 것이 중요하다”는 것을 보여줍니다.
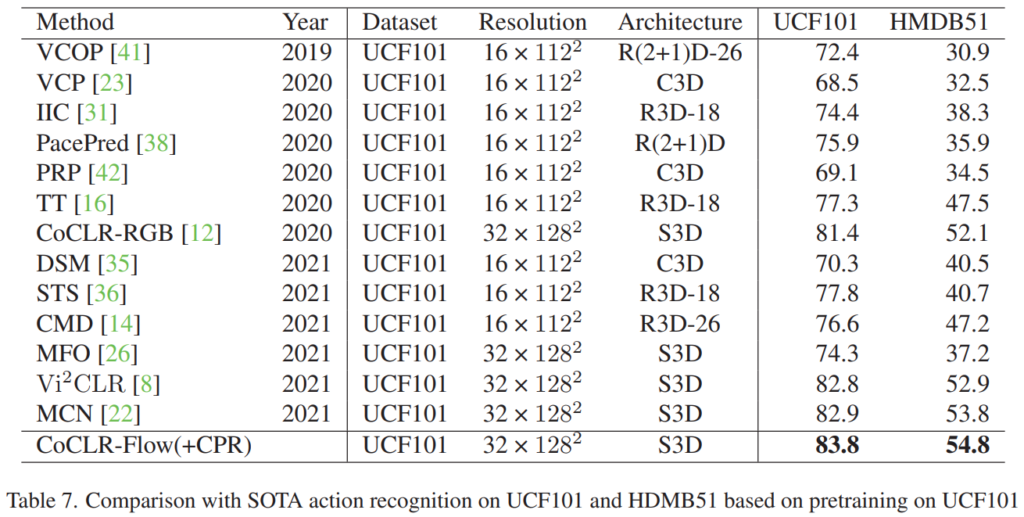
[표 7]은 video classification에서의 성능 비교인데요. 역시 CPR을 적용한 방법이 제일 좋은 성능을 보이는 것을 보이는 것 처럼 보이지만, 사실 CoCLR 성능 자체가 RGB / FLOW 성능이 각각 81.4% / 83.5%입니다. 새로운 SOTA를 달성한 것 처럼 보이지만 원래 성능이 좋았다는 것인데요. 이 논문에서는 아마 이런 문제를 좀 숨기고자 표기를 안한건가… 싶기는 하네요.
Conclusion
CoCLR의 문제점을 잘 정리하고, 이를 해결해서 성능을 올려서 workshop 논문으로 들어간 것 같습니다. 제 입장에서도 이렇게 연계해서 생각을 못했을 뿐이지 부분 부분적으로는 모두 알고 있는 문제점이었는데, 이게 논문으로 보니까 이어지면서 문제 정의가 되는걸 보니 신기하네요.
좋은 리뷰 감사합니다.
CoCLR의 RGB, Flow alternate 속 또 다른 alternate를 집어 넣어 성능이 올라간 느낌의 논문인 것 같습니다.
표 6에서 CoCLR-RGB는 RGB+Flow feature로 학습된 CoCLR에 RGB feature만을 넣어 추출한 feature로 retireval 한 성능으로 알고 있습니다. 혹시 CoCLR-RGB에 CPR을 붙이는 경우 백본이 같음에도 불구하고 성능이 크게 떨어지는 것 같은데, 저자가 이에 대한 분석을 하고 있는지 궁금합니다.
workshop 논문이라 분석하시는 부분과 같이 설명 없이 넘어가는 애매한 부분이 있는 것 같습니다. 표 7과 같이 CoCLR 성능 자체를 숨기는 부분도 있는 것 같고요. 제가 판단해보면, 표7에서도 RGB+CPR 성능이 없는 것을 보아, RGB로 inference할 때 CPR이 방해하는 요소가 존재하는 것 같습니다.
리뷰 잘 읽었습니다.
Cascade Positive Retrieval (CPR)은 본 논문에서 처음 제안되는 task 인가요? task 자체에 대한 설명이 조금 부족해 보이는데 task에 대한 자세한 설명 부탁드립니다.
감사합니다.
Task 자체는 일반적인 Contrastive self-suprvised learning입니다.