Abstract
이 논문에서 저자들은 CleanUNet이라는 raw waveform을 입력으로 하는 speech denoising 모델을 제안한다. CleanUNet은 bottleneck부분에 self-attention을 결합한 인코더-디코더 구조를 기반으로 한다. CleanUNet은 두 가지 loss를 사용해 optimize되는데, 하나는 waveform에서, 다른 하나는 multi-resolution spectrogram에서 정의된다. Speech denoising 분야에서, CleanUNet은 여러 sota 알고리즘 이상의 성능을 보여 주었다.
1. Introduction
Speech denoising은 녹음된 speech에서 배경 잡음을 제거하는 task입니다. 신호의 intelligibility를 유지하면서도 배경 잡음을 없애주는 작업이기에, 여러 음성 application에 활용되어 왔습니다. 이전까지는 denoising에 전통적인 신호처리 방법론을 사용하였습니다. 대표적인 방법론으로는 Wiener filtering방법론이 있으며, 이는 단순한 필터링 기반의 방법론입니다. 그러나 이러한 방식은 non-stationary한 noise에는 잘 작동하지 않는다는 문제점이 있었다고 합니다.
DNN은 1980년대부터 음성 향상을 위해 도입되었습니다. 현대에 이르러, 모델의 연산 능력이 향상됨에 따라 더 많은 분야에서 DL방식이 사용되었고, speech denoising 역시 DNN을 이용한 방식이 널리 사용되기 시작하였습니다. DNN을 사용한 speech denoising은 깨끗한 음성 신호를 GT로, 소음이 포함된 음성 신호를 입력으로 하는 supervised 방식으로 학습이 진행되며, 이러한 방법론은 사용되는 음성 feature에 따라 magnitude of spectrogram, noisy spectral feature를 사용하는 time-frequency과 raw waveform을 사용하는 waveform domain으로 분류됩니다.
저자들은 waveform domain에서의 speech denoising 모델인 CleanUNet을 제안합니다. CleanUNet은 raw waveform을 입력으로 하는 waveform domain 방법론으로, 대략적인 구조는 U-Net을 기반으로 하였으며 크게 incoder, decoder, bottleneck으로 구성되어 있습니다. 특히, bottleneck에서 masked self attention을 사용하여 bottleneck의 representation을 개선하고 sota의 성능을 달성하였습니다. 또한 encoder, decoder 모두 convolution 연산으로 이루어져 있어 모델의 latency가 원본 오디오의 time 축 waveform과 bottleneck의 representation에 의해서만 결정된다는 특징이 있습니다. 더 자세한 구조와 이를 이용한 실험들은 아래에서 확인해 보도록 하겠습니다.
2. Model
2.1 Problem Settings
논문에서 수행하고자 하는 speech denoising은 단일 채널로 수집된 음성 신호를 denoise하는 것이며 수식으로 표현하면 아래와 같은 상황으로 나타낼 수 있습니다.
길이가 T이고, 잡음이 포함된 음성 신호를 x_{noisy}\in R^T이라 할 때, x_{noisy}는 clean 음성 x와 잡음 x_{noise}를 합성한 것으로 x_{noisy} = x + x_{noise}로 나타낼 수 있습니다. 즉, speech denoising은 x_{noisy}를 모델 f에 입력했을 때 예측값인 x\hat이 x와 같아지도록 하는 f를 찾는 것으로 정리하자면 [식1]과 같이 나타냅니다.
\hat x = f(x_{noisy}) \approx x \tag{1}2.2. Architecture
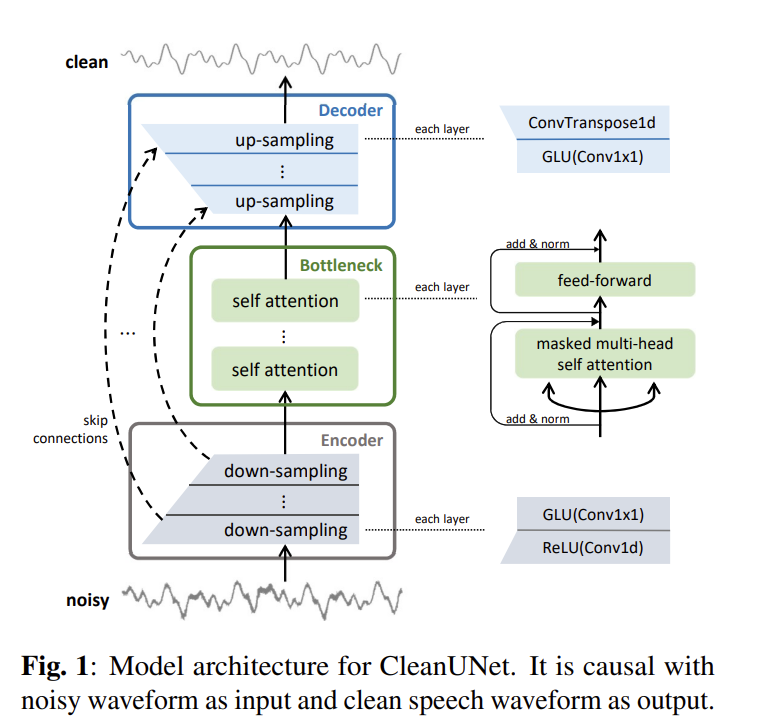
CleanUNet 모델의 구조는 UNet의 구조를 바탕으로 하고 있으며 [그림1]과 같습니다. UNet에 대한 설명은 홍주영 연구원님의 리뷰에 설명되어 있으니 여기서는 생략하도록 하겠습니다.
모델은 인코더, 디코더 및 이들 사이의 bottleneck으로 이루어져 있습니다. 인코더와 디코더는 같은 수의 레이어를 가지며 skip connection으로 연결되어 있습니다.
Encoder
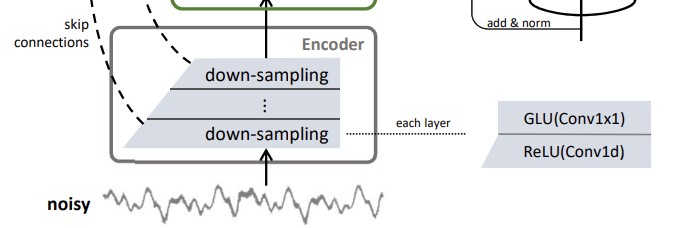
Encoder
먼저 encoder를 살펴보겠습니다. 인코더는 총 D개의 레이어로 이루어져 있고, 각 층은 Conv1d과 ReLU 및 Conv1×1, GLU로 구성됩니다. Conv1d를 사용하는 이유는 speech가 1차원 배열로 이루어진 데이터이기 때문입니다. Encoder의 conv1d에서는 feature의 downsampling이 진행되고, conv1d는 GLU에 의해 감소된 feature의 채널 수를 증가시킵니다.
Decoder
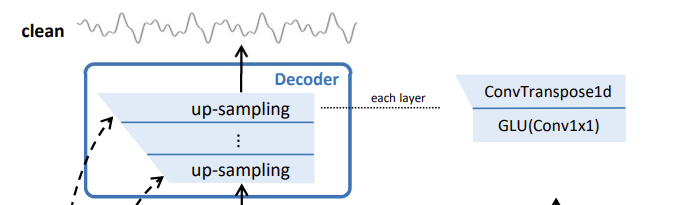
다음으로는 decoder를 살펴보겠습니다. decoder에서는 encoder, bottleneck으로부터 전달된 feature로부터 clean speech waveform을 생성하며, encoder와 대칭적인 구조로 이루어져 있습니다. Depth와 Stride등의 하이퍼파리미터는 encoder와 동일한 값을 사용하였습니다. 즉, 각 decoder 레이어는, 역순으로 encoder 레이어에 대응됩니다. 예를 들자면, decoder의 마지막 레이어는 encoder의 첫 레이어와 대응 관계에 있습니다. 이때 encoder와 decoder의 각 레이어는 대응되는 레이어와 skip connection으로 연결됩니다.
Bottleneck
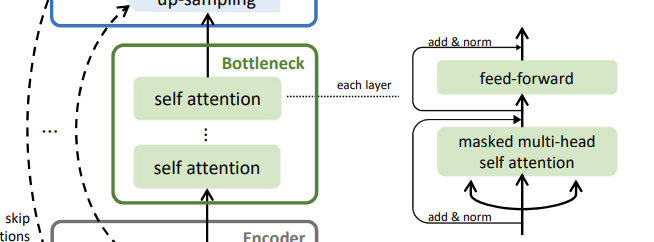
해당 논문에서 제안된 방법론이자, 기존 UNet과의 차이점인 bottleneck입니다. bottleneck은 N개의 self-attention block으로 이루어져 있으며, self-attention block은 multi-head self attention과 position-wise fully connected layer로 이루어져 있습니다. 각 레이어를 통과한 feature는 skip connection으로 연결되어 있고, 이후에 layer normalization을 진행합니다. 각 multi-head self attention은 8개의 head와 512의 차원 수를 가지고 있으며, 모델의 casuality를 위해 attention map에 masking을 진행하였습니다.
2.3. Loss Function
CleanUNet에 사용되는 loss는 GT x와 denoised speech \hat x사이의 l_1 loss와 STFT loss의 합으로 이루어져 있습니다.
s(x;\theta)=|STFT(x)|일 때, 즉, x의 frequency 영역에서의 linear scale spectrogram의 magnitude라고 한다면 위의 STFT loss에 해당하는 수식은 [식 2]과 같이 정의됩니다. 이때 \theta는 STFT에 사용되는 하이퍼파라미터로 hop size, window length 등을 나타냅니다.
M\hbox-STFT(x,\hat x)=\sum^m_{i=1}\bigg({{\parallel s(x;\theta_i)-s(\hat x;\theta_i)\parallel_F}\over \parallel s(x;\theta_i)\parallel_F}+{1\over T}\bigg\|{\log{{s(x;\theta_i)}\over{s(\hat x;\theta_i)}}}\bigg\|_1\bigg)\tag{2}최종적으로 stft loss와 waveform간의 l_1 loss 를 결합한 loss 함수는 다음과 같이 정의되었습니다.
L = {1\over2}M\hbox-STFT(x,\hat x)+\parallel x-\hat x\parallel_1 \tag{3}Experiment
실험은 총 DNS, Valentini 그리고 저자들의 자체 데이터셋으로 진행되었으며, sota모델과의 성능 비교실험, 모델 구조에 따른 ablation study를 진행하였습니다.
Evaluation
denoising의 성능을 평가하기 위해 아래와 같은 metric을 사용하였다고 합니다.3
- Perceptual Evaluation of Speech Quality (PESQ)
- Short-Time Objective Intelligibility (STOI)
- Mean Opinion Score (MOS)
이중 PESQ는 음질을 평가하는 metric으로 기준 음성(GT)와 평가 대상(denoised speech)를 입력으로 두 신호의 차이를 계산하고, 이를 다시 인지 모델에 입력하여 -0.5~4.5사이의 값을 출력합니다. 이때, 4.5에 가까울수록 더 좋은 음질을 가지고 있는 것이라고 합니다.
STOI는 음성의 명료도를 평가하는 지표로, PESQ와 마찬가지로 목표 신호와 추정된 신호 사이의 유사도를 평가하며, 100에 가까울수록 denoising이 잘 진행된 것이라고 합니다.
MOS는 여러 사람이 주관적인 평가를 진행하고 그 결과를 통계적 방식으로 산출한 평가 지표입니다. 이 논문에서는 총 15명의 채점자가 test data 100개를 랜덤으로 선정하여 음성 신호의 왜곡이 있는지, 노이즈, 전체적인 음질에 1~5의 점수를 매기는 방식으로 진행하였습니다.
3.1. DNS
DNS 데이터셋은 speech enhancement를 위한 데이터셋으로 약 500시간의 음성과 다양한 상황의 noise를 포함하고 있습니다. 모델의 입력으로 사용되는 noisy 데이터는 clean speech에 랜덤한 크기의 noise를 합성하여 생성되는데, 그 과정을 간단히 나타내자면 다음과 같습니다.
- SNR(Signal to Noise Ratio)를 (-5~25dB)범위에서 랜덤하게 생성
- new_noise = noise * SNR
- noisy = clean_speech + new_noise
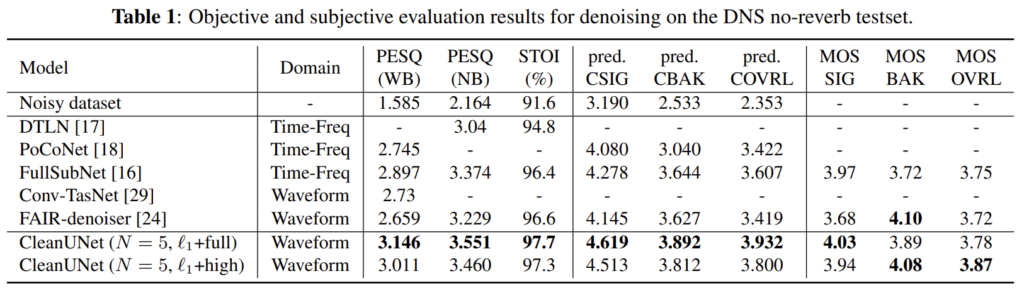
[표1]은 DNS 데이터셋으로 평가를 진행한 결과입니다. PESQ와 STOI를 살펴보면, CleanUNet이 기존 sota모델들과 비교했을때 가장 좋은 성능을 내는 것을 확인할 수 있습니다.
3.2 Valentini
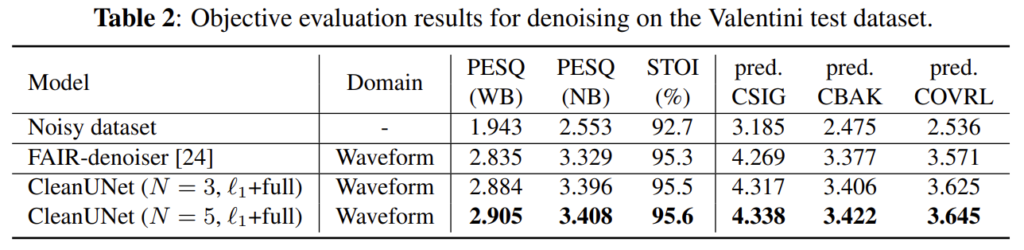
Valentini dataset의 평가 결과입니다.
3.3. Internal Dataset
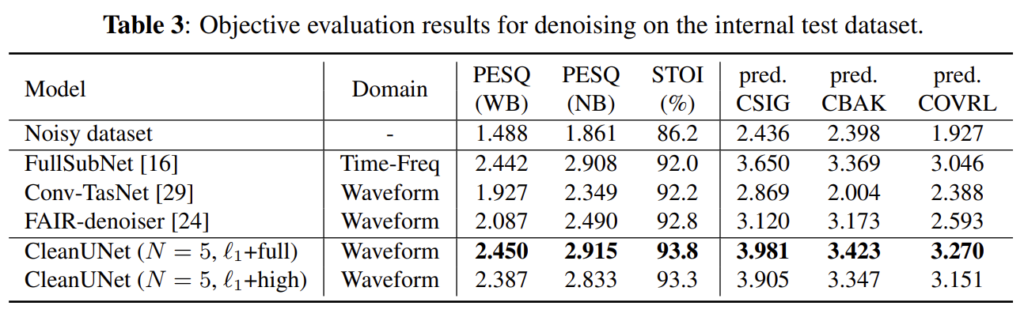
저자의 자체 데이터셋으로 실험한 결과입니다. augmentation방식을 DNS와 동일한 방식을 사용하였습니다.
Ablation Studies
모델의 하이퍼파라미터와 loss의 기능을 알아보기 위한 ablation study 결과입니다.
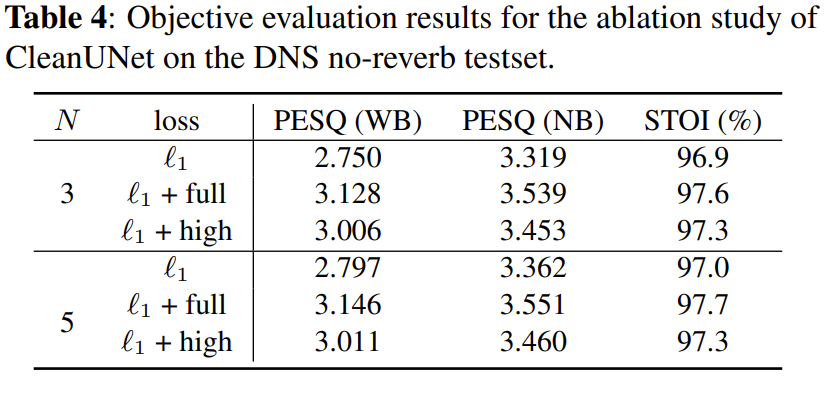
N은 bottleneck의 self-attention block의 개수로 전체적인 결과를 보았을 때, 3개에서 5개로 증가했을 때 더 좋은 결과를 보입니다.
loss는 MSTFT없이 l_1은 l1 loss를 단독으로 사용한 경우, l_1 + full은 [식1]과 같이 사용한 경우, l_1 + high는 high-band STFT loss로 전체 frequency 중 사람의 음성이 주로 분포하는 중간 부분만을 고려한 경우입니다.
Inference Speed and Model Footprints

같은 waveform domain의 speech denoising 모델인 FAIR-denoiser과 CleanUNet과의 inference time을 RTF로 비교하였습니다.
안녕하세요. 좋은 리뷰 감사합니다.
리뷰를 읽다가 궁금한 것이 있는데 굳이 masked multi-head self attention을 사용한 이유가 있을까요? 그냥 multi head self attention을 사용해도 성능이 나왔을거 같은데 이거와 비교한 실험은 없을까요?
감사합니다.
본문에서는 모델의 causality를 위해 masked multi-head self attention을 사용했다고만 언급되어 있으며 masking을 진행하지 않은 경우와의 비교 실험은 진행하지 않았습니다.
좋은 리뷰 감사합니다.
self attention block에서 mutl-head self attention를 사용하는 구조를 가지는데 multi-head를 사용했을 때 time consuming한 문제가 있을 수도 있겠다고 생각했습니다. 관련하여 speed에 대한 언급은 없었나요?
그리고 raw waveform의 경우 데이터의 형태는 어떤 모습인지 궁금합니다. 예를 들어 image의 경우는 pixel value를 사용하는데 raw waveform은 어떤 값을 사용하는지 궁금합니다.
김사합니다.
본 논문의 실험 결과가 성능 위주로 리포팅되어 있어 speed에 관한 언급은 없었습니다.
raw waveform의 형태는 음성 signal의 amplitude 값을 의미합니다. 아래의 답글을 참고하시면 좋을 것 같습니다.
리뷰 잘 봤습니다.
사실 저번 세미나때 들으면서 근본적인 의문점이 하나 있었습니다.
아시다시피 이미지의 경우 각 pixel의 밝기값을 가지고 연산을 진행하는데, 그렇다면 이 음성데이터의 경우에는 각 값이 무엇을 나타내는건가요?
음의 높이?? 세기??
감사합니다.
음성 데이터의 각 값은 해당 시간에 오디오 신호의 진폭 값입니다. 소리는 진동에 의한 공기 밀도(압력)의 변화로 인해 발생하는데. 이를 마이크를 통해 측정했을 때 센서에서 측정된 전압의 변화량이며 최종적으로 기록되는 오디오 정보는 [-1, 1] 범위로 정규화된 값입니다. 마지막에 말씀해 주신 부분 중 음의 세기에 해당한다고 생각하지면 될 것 같습니다.
논문 리뷰 잘 읽었습니다.
혜원님의 논문을 읽고 두 가지의 질문이 생겨 댓글을 남기게 되었습니다.
1. TABLE1, 2, 3에 있는 CSIG, CBAK COVRL은 혹시 어떤 것에 대한 예측을 하는 것인지 궁금합니다
2. TABLE4에 대한 내용 중, Bottleneck에 대한 self-attention block 같은 경우는 표를 살펴봤을 때 3개에서 5개로 증가하였을 때, 더 좋은 결과를 보인다고 하셨는데 그럼 무조건 다다익선인가요? 단지 block 의 개수가 많아졌다고만 해서 좋은 결과를 이루었는지 궁금합니다.
감사합니다.
1. CSIG, CBAK, COVRL은 각각 SIG(음성 신호의 왜곡 정도), BAK(background noise의 왜곡 정도), OVRL(전체적인 오디오의 품질)을 conposite parameter를 통해 객관적으로 평가한 지표입니다. 0~5 범위의 값을 가지며 5에 가까울수록 좋은 품질을 나타낸 것이라고 생각하시면 됩니다.
2. 일단 논문에 나온 실험은 N=5, 3인 경우만 리포팅 되어 있어 정확한 경향성은 파악할 수 없을 것 같습니다.
그러나 블록이 증가했음에도 성능 향상이 미비한 점, STOI와 PESQ의 경우 거의 비슷한 성능을 보이는 것으로 보아 더 많은 attention block을 사용해도 더 이상의 성능 향상을 기대할 수 없을 것으로 생각됩니다.
아마 block의 개수가 많아져서 더 좋을 것이다! 라고 확답하기에는 무리가 있지 않을까 싶네요…ㅎㅎ