저번 PointNet에 이은 PointNet++이다. 이전 PointNet에 이어 같은 해에 나온 PointNet++이다. PointNet 이전에는 point sets에 대한 deep learning 연구가 거의 없었다. PointNet이 point cloud 데이터를 다른 형태로 변환하지 않고 raw point data를 활용한 최초의 연구이다. 하지만 PointNet에서 서로 거리를 두고 있는 points간의 local한 특징 정보를 잡아내지 못하여 미세한 pattern을 파악하기 어렵고 일반화된 정보를 복잡한 complex scenes로 인식하는 문제가 존재했다. 본 논문에서는 input points에 PointNet을 재귀적으로 적용하는 hierarchical neural network인 PointNet++을 제안한다. points들 간의 거리 공간을 의미하는 metric space에서의 distance를 활용함으로써 network는 local feature를 학습할 수 있다. 또 일반적으로 point set은 다양한 densities로 sampling되어 uniform한 densities로 학습된 network에서 성능 저하를 보인다는 관찰을 하였고, 이를 해결하기 위해 multiple scales에서의 feature를 적응적으로 combine하기 위한 새로운 set learning layer를 제안하였다. PointNet++이 deep point set feature에 대해 효율적으로 학습할 수 있음을 실험적으로 보였고 3D point clouds benchmark에서 sota를 달성하였다.
Introduction
Euclidean space에 존재하는 points들은 3D scanner를 통해 얻을 수 있는데 이러한 3d point cloud 데이터는 permutation invariant해야한다. PointNet에서 언급했던 것처럼 sensor를 통해 얻은 point cloud는 순서가 없이 sensing되는 대로 point를 얻게된다. 따라서 이런 순서가 정해지지 않은 points들을 처리할 때, 어떤 물체가 translation이나 rotation과 같은 작은 변화에도 같은 물체라고 판별할 수 있어야한다. 즉 어떤 순서에도 같은 결과를 보여야 한다는 뜻이다. 또한 distance metric을 통해 예측한 local neighborhoods는 locations에 따라 서로 다른 결과 특성을 보일 수 있다. 왜냐하면 points들이 위치 공간에 따라 uniform하게 분포하지 않아 density가 일정하지 않기 때문이다.
이전에는 point sets에 대한 deep learning 연구가 거의 진행되지 않았다. 본 논문이 나오기 불과 몇 개월 전(같은 저자이긴 하다) PointNet이 point sets을 direct하게 사용한 최초의 모델이었다. PointNet에서의 아이디어는 각 point들의 spatial encoding을 학습한 후, 모든 각각의 point features를 aggregate하고 symmetric function인 max pooling을 통해 global feature를 추출하였다. 최대값만 살리는 max pooling의 특성 상 local한 정보들은 소실될 수 밖에 없었다. 하지만 local structure를 활용하는 것은 중요한 것으로 입증되었다. CNN에서도 regular한 grid에서 정의된 data를 input으로 하여 다양한 크기의 resolution을 통해 local한 특징을 추출하였고 성능 향상을 이루었다.
본 논문에서는 hierarchical neural network 구조인 PointNet++을 통해 hierarchical 방식으로 point sets을 처리하는 방식을 제안하였다. PointNet++의 기본적인 아이디어는 simple하다. 먼저 points들을 distance metric에 따라 서로 겹치는 local regions로 분할한다. 그리고 CNN과 유사하게, 작은 neighborhoods에서 fine geometric structures를 포착하는 local features를 추출한다. 이러한 local features는 hierarchical하게 반복되면서 더 큰 단위로 grouping되고 higher level features를 알아낼 수 있도록 전달된다. 이러한 과정은 전체 point set의 features를 얻을 때 까지 반복된다.
PointNet++는 크게 두 가지 issue를 다룬다.
1. 어떤 방식으로 point set을 partitioning할지
2. 어떤 방식으로 local feature learner를 통해 point sets이나 local features를 추상화할지
partition을 할 때 local feature learner로는 PointNet을 사용한다. PointNet은 unordered point sets을 가지고 semantic feature extraction을 하는데 효과적인 architecture라는 것이 실험적으로 입증되었고 input data의 손상에도 강인하게 동작한다. 기존 PointNet은 local point나 features를 higher level로 표현하기 때문에 본 논문에서 제안하는 PointNet++은 PointNet을 partition된 point set에 반복적으로 적용한다.
첫 번째 issue인 overlapping partition하는 방식에 대해서도 알아보자면, 중심 위치와 scale을 포함한 parameters를 통해 주변 구(ball) 형태의 공간에 대해 partition한다. 전체 point set을 cover하기 위해 centroids는 input point sets 중 서로 가장 먼 points를 선택하는 FPS(Farthest point sampling) 알고리즘 방식을 사용하였다. 기존 3차원 volumetric CNN에서 고정된 stride로 공간을 scan하는 것과 비교하면 해당 방식은 input data와 metric모두를 고려하였기 때문에 더 효과적이다.
local neighborhood의 적절한 ball size를 결정하는 것 또한 input point의 non-uniformity와 복잡한 feature scale 때문에 어려운 문제이다. 본 논문에서 input point set은 서로 다른 위치(공간)마다 다양한 variable density를 가진다고 가정하는데 아래 Figure 1에서 보이는 것처럼 real data에서 일반적으로 나타나는 상황이다.

즉 input point set이 기존 regular grid안에서 uniform한 density로 정의되는 CNN input data와는 다르다는 것을 확인할 수 있다. CNN에서는 kernel size에 따라 local partition scale을 정의할 수 있고 작은 크기의 kernel을 사용하는 것이 detail한 특성을 고려하기 때문에 성능 향상에 도움이 된다는 것을 알 수 있었다. 하지만 본 논문에서 point set에 대한 실험에서는 이에 반대되는 결과를 보였는데, small neighborhood 부분은 sampling 부족으로 인해 너무 적은 points로 구성될 수 있으며 이것으로 인해 PointNet이 pattern을 포착하는데 어려움이 있을 수 있다고 한다.
본 논문의 중요한 contribution은 PointNet++이 mutiple scales의 주위 neighborhoods를 활용하여 detail한 정보를 capture하고 더 강인함을 보였다는 점이다. 실험적으로 PointNet++이 point sets을 효과적으로 처리할 수 있음을 보였고 3D point cloud benchmark에서 sota를 달성하였다.
Problem Statement
X = (M, d)가 euclidean space인 Rn에서 discrete metric space라고 하자. 이때 M⊆Rn은 points의 집합이고 d는 distance metric이다. euclidean space에서 M의 density는 모든 공간에서 uniform하지 않는다. 본 논문에서는 이러한 X(input point clouds)를 input으로 하고(각 point에 대한 추가적인 features도 함께) X의 semantic 정보를 생성하는 함수 f에 관심을 둔다. 여기서 함수 f는 X에 label을 부여하는 classification function 혹은 per point label에 label을 부여하는 segmentation function을 의미한다.
Method
본 논문에서 제안하는 network는 hierarchical structure를 추가한 PointNet의 확장 버전이라고 보면 될 것 같다.
Review of PointNet: A Universal Continuous Set Function Approximator
이전 PointNet에 대해 간단하게 알아보고 넘어가자. xi∈Rd에서 unordered point set인 {x1, x2, …, xn}가 주어졌을 때, 아래 수식 (1)과 같이 point set을 vector로 mapping하는 set function f : X→R를 정의할 수 있다.
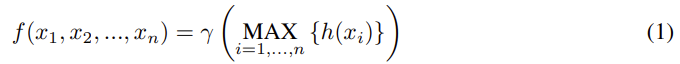
수식에서 γ와 h는 MLP layer를 의미한다. set function인 f는 input point에 대해 permutation invariant하고, point xi가 h를 통과한 결과는 points의 spatial encoding을 한 결과로 해석할 수 있다. PointNet은 benchmark에서 주목할만한 결과를 보였지만 서로 다른 scales에서 local context를 파악하는데는 어려움이 있다. 본 논문에서는 hierarchical feature learning framework를 통해 이러한 어려움을 해결하고자 하였다.
Hierarchical Point Set Feature Learning
PointNet에서는 하나의 max pooling을 통해 전체 point set을 aggregate하였다.하지만 본 논문에서 제안하는 PointNet++의 경우 hierarchical grouping points를 구축하고 계층을 따라 점점 더 큰 local regions를 추상화(abstract) 하게된다.
아래 Figure 2에서 볼 수 있듯이 network의 hierarchical structure는 여러 set abstraction levels로 구성되어있다.
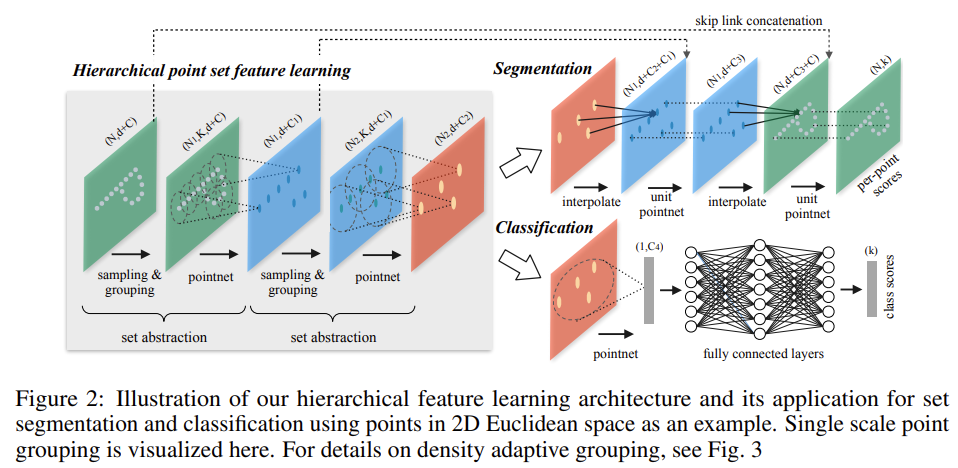
각 level에서 points는 set abstraction을 통해 추상화 된 적은 수의 points를 가지는 새로운 point set으로 생성된다. set abstraction level은 Sampling layer, Grouping layer, PointNet layer 이렇게 3개의 key layers로 구성되어있다. Sampling layer는 input points 중 local regions의 centroids를 정의하는 points들을 선택한다. 이때 이전 point clouds의 대표성을 잃지 말아야한다. Grouping layer는 centroids 주변의 neighboring points를 찾아 local region sets를 구성하게된다. PointNet layer는 mini-PointNet을 이용하여 local region patterns를 feature vectors로 encoding하는 역할을 하게된다.
set abstraction level은 N x (d + C) matrix를 input으로 한다. 이때 N은 points이고 d는 d-dimension coordinate(x,y,z 좌표), C는 C-dimension point feature를 의미한다. set abstraction layer를 거치고 나면 N’개의 subsampled points를 얻게 되고 C’의 dimension feature vectors를 가지는 N’ x (d + C’) matrix로 변환된다. 이제 아래에서 각 layer들에 대해 좀 더 자세히 알아보자.
Sampling layer
input points가 {x1, x2, …, xn}로 주어졌을 때, 반복적으로 farthest point sampling(FPS)를 사용하여 전체 점들 중 euclidean distance가 가장 먼 점 {xi1 , xi2 , …, xim}을 선택한다. random sampling과 비교하였을 때 FPS를 사용하는 것이 동일한 centroids 수가 주어졌을 때 전체 point set에 대한 적용 범위가 더 좋고, 더 일반적이고 대표성을 띄는 points를 얻을 수 있다.
Grouping layer
Grouping 단계에서는 sampling 단계에서 얻은 centroids와 주변 points들을 grouping 해준다. Grouping layer의 input은 N x (d + C)의 point set과 N’ x d의 centroids coordinates(x,y,z 좌표)이다. output은 N’ x K x (d + C)크기의 point sets group이며, 여기서 각 group은 local regions를 의미하고 K는 centroids주변의 points 수를 의미한다. K는 group에 따라 다른 수를 가지지만 뒤의 PointNet layer에서 group의 points 수(K)에 관계없이 고정된 크기의 local region feature vector로 변환해준다.
Centroids 주변 points들을 정의하는 방법도 2가지가 있는데 ball query와 KNN이 해당하는 방법이다. 우선 ball query방식은 반지름 r을 설정하고 centroid를 기준으로 반지름 내 모든 points들을 neighborhoods로 정의한다. 다른 방식인 k nearest neighbor(kNN) search 방식은 centroid에 대해 가장 가까운 k개 points를 neighborhoods로 정의한다. PointNet++에서는 ball query방식을 채택하였는데, kNN과 비교하였을 때 ball query방식은 local neighborhood를 fixed region으로 정의할 수 있기 때문에 전체 space에 걸쳐 local region feature를 더 일반화할 수 있어 local pattern인식이 중요한 semantic point labeling에 유용하다. 또한 density가 일정하지 않은 point cloud의 경우 group별로 범위가 달라지는 문제를 방지할 수 있다.
PointNet layer
마지막으로 PointNet layer에서는 각 group의 centroid와 주변 point feature vector를 PointNet에 통과시켜 하나의 feature vector를 생성한다. input은 N’개 local region의 points들을 포함한 N’ x K x (d + C)크기의 matrix이다. 각 local region마다 output은 centroid와 centroid 주변 점들을 encode한 local feature에 의해 추상화된다. output size는 N’ x (d + C’)으로 각 group마다 하나의 vector가 나오는 것을 이해할 수 있다. 위의 Figure 2를 보면 더 쉽게 이해할 수 있다.
그리고 이때 local region에 포함되는 points들은 절대적인 x,y,z coordinate가 아니라 centroid와의 상대적인 좌표값으로 변환된다.
xi(j) = xi(j) – x^(j) for i = 1,2,…,K and j = 1,2,…, d. x^은 centroid의 coordinate.
이를 통해 local region에서 points들 간의 위치적 관계에 대한 정보를 파악할 수 있다.
Robust Feature Learning under Non-Uniform Sampling Density
지금까지 앞에서 언급했던 것처럼 point set은 서로 다른 영역에서 non-uniform한 density를 갖는 것이 일반적이다. 위의 Figure 1에서도 확인할 수 있는 결과이다. 이런 non-uniform한 특성이 point set feature learning에 중요한 문제를 야기할 수 있다. 예를 들어 dense한 data에서 학습된 feature는 sparse하게 sampling된 영역에서 정보가 부족하다고 느끼고 일반화되지 않을 수 있다. 또한 sparse한 point cloud에 대해 학습된 model은 다른 분포의 data로 인해 세밀한 local structures를 인지하지 못할 수 있다.
이상적으로는 dense하게 sampling된 영역에서 finest details를 포착하기 위해 가능한 조밀하게 point set을 보기를 바라지만, low density를 가지는 영역에서는 적은 sampling으로 인해 local pattern이 손상될 수 있어 사용하지 않는다. 이를 해결하기 위해 본 논문에서는 point cloud를 다양한 density로 sampling하여 학습하고, 또 서로 다른 scales의 영역에서 다양한 scale의 point cloud에서 feature vector를 sampling하여 적응적으로 학습하였다. 이를 density adaptive PointNet layer라고 하고 hierarchical architecture를 가진 network를 PointNet++이라고 칭한다. PointNet++에서 Figure 3에서 보이는 것과 같이 local 영역을 grouping하고 local point density에 따라 feature를 combine하는 MSG와 MRG 2가지 유형의 density adaptive layer를 제안한다.
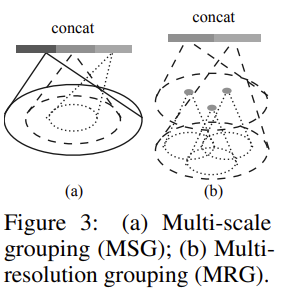
Multi-scale grouping(MSG)
Figure 3의 (a)에서 보이는 것이 Multi-scale grouping(MSG)이다. MSG는 multi scale patterns를 효과적으로 포착하기 위하여 grouping 단계를 서로 다른 scales로 여러 번 적용하여 하나의 centroid에 대해 여러 scale의 point group을 얻는 방법이다. 그런 다음 PointNet에 따라 각 scale의 feature를 추출하게된다. 각 point groups에서 추출한 feature vector를 concat하여 multi-scale feature vector를 얻게된다. 이때 각 point group은 ramdom하게 dropout ratio(theta)를 선택하여 해당하는 비율에 맞게 random하게 [0,p] where p≤1의 비율로 down sampling하여 각 point group마다 서로 다른 scale로 non-uniform한 density를 가지도록 해주었다. 실제로는 빈 point sets이 생성되지 않도록 p=0.95로 설정해주었다. 이러한 과정을 통해 다양한 sparsity와(theta로 인함) 다양한 uniformity(drop out을 통해)를 가지는 points들을 얻을 수 있다. test의 경우 모든 points를 유지한다. MSG의 경우 centroids와 그 주변 points들이 모두 PointNet을 통과해야하기 때문에 연산량이 많아 비효율적이고 time-consuming하다는 단점이 있다.
Multi-resolution grouping(MRG)
MSG는 computational cost가 크다. 특히 low level에서는 많은 centroid points가 존재하기 때문에 상당히 많은 시간이 소요된다는 단점이 있기 때문에 이러한 문제를 보완하기 위해 Multi-resolution grouping(MRG)를 제안하였다. MRG는 서로 다른 scale에서 얻은 feature를 concat하여 multi-scale feature vector를 얻는다. 위의 Figure 3의 (b)에서 보면 알 수 있듯이, 첫 번째 vector는 local group에 해당하는 전체 points들에 대해 PointNet을 통과한 feature vector가 되고 두 번째 vector는 local group에 대해 이것보다 낮은 하위 level의 sub-region에서 얻은 feature를 얻는다.
만약 input으로 들어오는 local region의 point density가 낮다면 sparse한 points를 가져 sampling이 어려운 첫 번째 vector보다 두 번째 vector 정보에 더 큰 가중치로 의존하게 되고, 반대로 local region의 density가 높은 경우 첫 번째 vector가 세밀한 detail한 정보를 제공할 수 있다. 따라서 두 vector를 함께 이용하면 다양한 density의 point cloud에 대응 할 수 있다.
MSG와 비교하였을 때 MRG 방법은 low level에서 large scale의 neighborhoods에 대한 feature extraction을 하지 않아도 되기 때문에 연산량 측면에서 효율적이다.
Point Feature Propagation for Set Segmentation
set abstraction layer를 거치게되면, original point set은 subsample되어 point cloud의 크기가 줄어들게 된다. 하지만 semantic point labeling을 해야하는 segmentation task의 경우 모든 original points에 대한 point features를 필요로 한다. set abstraction을 하기 위해 모든 points들을 centroid로 하여 sampling하는 방법도 있지만 높은 computation cost를 요구한다. 다른 방법으로는 down-sampling한 points에서 원래 points로 interpolation하여 up-sampling하는 방법이 있다.
본 논문에서는 distance 기반의 interpolation과 위의 Figure 2에 나타나있는 skip link concatenation을 사용한 hierarchical propagation strategy를 적용하였다. 구체적으로 많은 interpolation 방법들 중 k nearest neighbors를 기반으로 하는 거리 값의 역수 형태로 가중치를 부여하는 interpolation방법을 사용하였고 수식 (2)에 표현되어있다. p=2, k=3을 default로 사용하였다.

또한 down-sampling전 set abstraction level의 feature vector를 skip connection 방식을 통해 concat하여 정보를 보충해주었다. 이렇게 concat된 feature는 CNN에서 1×1 convolution과 비슷한 역할을 하는 unit pointnet을 통과한다. 이러한 interpolation 과정은 original points 수가 될 때까지 반복해주었고 결과로 나온 feature vector로 segmentation을 수행하게 된다. Figure 2의 segmentation부분을 다시 보면 이해가 수월할 것이다.
Experiments
본 논문에서 PointNet++은 MNIST(2D objects), ModelNet40(3D rigid objects), SHREC15(3D non-rigid objects), ScanNet(3D scenes) dataset에 대한 평가를 진행했다.
Point Set Classification in Euclidean Metric Space
MNIST와 ModelNet40에 대해 point set classification을 evaluate했다.
MNIST image는 2d image의 좌표를 512개의 2D point cloud로 변환하여 사용하였다. 아래 Table 1을 보면 hierarchical architecture를 가진 PointNet++이그렇지 않은 PointNet보다 약 30%가량 낮은 error rate를 보인다. hierarchical structure가 local한 영역의 특징을 포함시켜 성능에 영향을 주었다는 것을 알 수 있다. PointNet(vanila)모델의 경우, 기존 PointNet 모델에서 spatial attention역할을 하는 transformation network를 사용하지 않은 네트워크이다. 또한 기존 CNN 기반 모델들과 비교해도 raw point cloud를 input으로 하는 Ours(PointNet++)가 더 좋거나 견줄만한 성능을 보였다. 많은 성능 차이를 보이지는 않았지만 point cloud를 사용하여 다른 가공한 방식과 비슷한 결과를 보였다는 것 자체만으로 매력적인 contribution으로 다가온다.

ModelNet40은 40개 categories에 대한 3D CAD model 데이터 셋이다. CAD model은 mesh 형태를 가지고 있기 때문에 mesh surface에서 1024개의 3D point cloud를 sampling하여 PointNet++의 input으로 사용하였다. 모든 points들은 반지름이 1인 unit ball안에 들어오도록 normalize해주었다. 아래 Table 2에서 확인해보면 기존 point cloud기반의 방법론들은 다른 형태의 input을 사용한 방식에 비해 좋은 성능을 보이지 못하였지만, 본 논문에서 제안하는 PointNet++의 경우 더 좋은 성능을 보인 것을 확인할 수 있다. 특히 기존 3d classification task의 sota모델이던 image input을 사용하는 MVCNN보다 좋은 성능을 보였다. 맨 아래 행의 Ours(with normal)은 더 좋은 성능을 내기 위해 points의 수를 5,000개로 하여 더 많은 point feature를 추가적으로 사용한 방식이다.

sensor를 통해 얻은 real world의 point data는 위의 Figure 1에서도 확인할 수 있는 것처럼 irregular한 특징을 가지기 때문에 sampling하는데 어려움이 있다. 본 논문에서는 multiple scale에서 neighborhood points를 선택하고 multi-resolution에 따라 weight를 주는 방식을 통해 문제를 해결하였다고 density adaptive layer(MSG, MRG)에서 설명하였다.
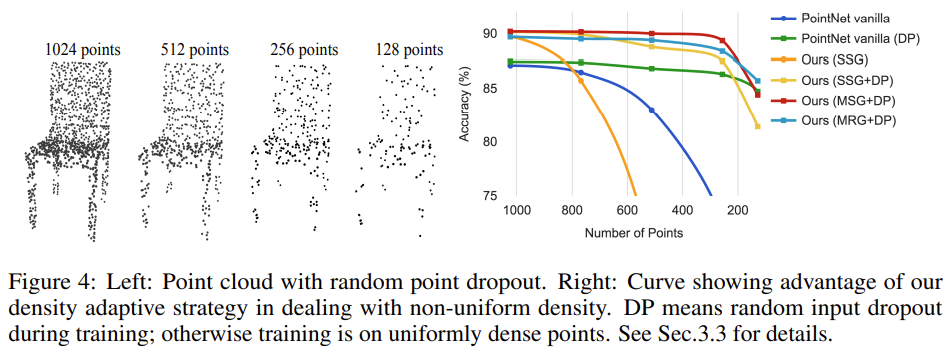
아래 Figure 4에서는 ModelNet40을 이용하여 density adaptive layer의 성능을 측정하는 ablation study를 진행한 것 같다. 우선 왼쪽 그림을 보면 network가 non-uniform하고 sparse한 data에 대해 robustness를 보임을 증명하기 위해 1024개 points부터 512, 256, 128개 points까지 random하게 down-sampling한 모습이다. 오른쪽의 그래프를 함께 보면, 빨간색의 MSG+DP와 하늘색의 MRG+DP의 경우 multi-scale로 학습되어 sampling된 points 수에 관계없이 robust함을 보이는 것을 확인할 수 있다. 여기서 DP는 training 시 random하게 input을 dropout한 것을 의미한다.
파란색과 초록색 그래프를 비교해보면 DP, 즉 random dropout의 차이일 뿐인데 point 수의 변화에도 robust한 것으로 보아 random dropout의 효과를 쉽게 이해할 수 있다. 주황색의 SSG는 PointNet++에서 multi-scale로 grouping한 것이 아니라 각 level에서 single scale로 grouping한 모델인데 sampling points의 수가 줄어들수록 exponential하게 성능 하락을 보여 sparse sampling density 일반화가 되지 않은 것을 알 수 있다. SSG에 DP를 추가한 노란색 그래프의 경우 random dropout을 추가하는 것만으로도 sparse한 data의 robust함을 보이는 것을 알 수 있다.
Point Set Segmentation for Sementic Scene Labeling
semantic scene labeling task에 대해서도 평가를 진행하였다. ScanNet은 1513개의 indoor환경에 대한 3d point cloud로 되어있다. 각각의 points에는 해당 point가 어떤 object에 포함되는지 sementic labeling이 되어있다. 아래 Figure 5를 보면 ScanNet에서 sampling density가 달라지는 경우에 robust한 결과를 보이는 지 확인하기 위한 그래프이다. 노란색 bar가 ScanNet을 non-uniform하게 sampling한 density로 test한 결과이다. 기존의 방법론인 3DCNN, PointNet보다 좋은 성능을 보이는 것을 알 수 있다. 또한 SSG, MSG+DP, MRG+DP로 ablation 결과도 비교해 볼 수 있다. 먼저 SSG의 경우 non-uniform한 경우에 성능 차이가 많이 나는 것을 알 수 있다. MSG와 MRG의 경우 sampling density변화에 더 강인한 것을 알 수 있는데 sparse하게 sampling된 경우에도 feature를 잘 추출할 수 있다는 것으로 해석할 수 있다. random dropout을 적용한 uniform한 training data와 non-uniform하게 scan한 data사이에 domain gap이 존재함에도 불구하고 MSG와 MRG에서 그리 크지 않은 성능 하락을 보인 것으로 미루어보아, density adaptive layer가 다양한 density의 데이터에 대해 강인하다는 것을 알 수 있겠다. 한가지 아쉬운 점은 위에서 MSG와 MRG를 설명할 때 MSG는 연산량이 많아 이를 보완하기 위해 효율적인 MRG를 제안하였는데, 성능 차이만 비교했다는 점이다. 두 방법을 사용하였을 때 속도가 어느정도 차이 나는지 reporting을 해주었더라면 더 좋았을 것 같다. 얼마나 속도 차이가 나는지는 모르겠으나 non-uniform한 결과를 보면 성능 차이가 좀 느껴져서 효율성에 의문을 가질 수도 있을 것 같다.

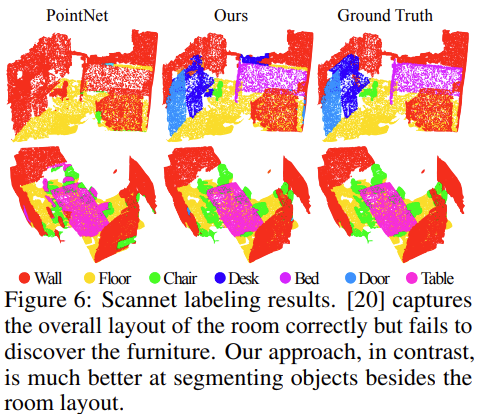
아래 Figure 6에서는 Scannet에서의 PointNet++의 segmentation 결과를 보이고 있다. 맨 오른쪽이 GT이고 가운데가 본 논문에서 제안한 PointNet++이다. 기존 방법론인 PointNet의 경우 전체적으로 잘 segmentation한 것으로 보이지만 desk나 door와 같은 가구들을 포착하지 못하였다. Ours(PointNet++)의 경우 전체적으로 GT와 유사하게 좋은 성능을 보여주었다.
hierarchical structure를 통한 local feature를 학습하는 것이 전체적인 scene을 이해하는데 중요한 영향을 미쳤다고 생각된다.
Point Set Classification in Non-Euclidean Metric Space
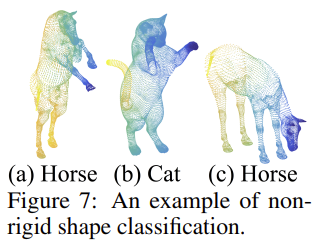
SHREC15는 50개의 categories를 가지는 1200개 shape의 objects들이 다양한 pose 형태를 띄고 있다. 아래 Figure 7에서는 non-rigid shape classification 결과를 보여준다. (a)와 (c)가 잘 분류된 case인데 서로 다른 pose를 취하고 있는 경우에도 같은 class로 잘 분류하였다.
아래 Table 3에서는 metric space에 대한 ablation study이다. 먼저 euclidean metric space는 우리가 흔히 알고있는 x,y,z 좌표 공간을 의미한다. non-euclidean metric space는 구의 곡면을 따라 생성되는 공간과 같은 좌표 공간을 의미한다. non-rigid shape의 경우 non-euclidean metric space를 metric space로 했을 때 주변 neighborhood points를 sampling할 때 더 좋은 성능을 보일 것이라고는 직관적으로 예상할 수 있을 것이라 생각한다. 말 그대로 non-rigid하다보니 mesh를 그리는 것처럼 곡률 형태의 surface를 가질 것이기 때문이다. 또한 특정 pose에 영향을 받지 않도록 x,y,z의 형태가 아닌 multi scale의 intrinsic point features를 input으로 하였을 때 더 좋은 성능을 보이는 것을 확인할 수 있다. x,y,z의 feature는 pose변화에 민감하게 반응한다고 한다. 이전 sota인 DeepGM과 비교해보면 intrinsic features가 non-rigid shape classification에 중요한 역할을 한다는 것을 파악할 수 있을 것이다. 여기서 intrinsic features는 논문에서는 WKS, HKS, multi-scale Gaussian curvature라고 언급하였는데 이것들은 non-rigid 3d shape에서 중요한 역할을 하는 feature라고 생각하면 될 것 같다.

Feature Visualization
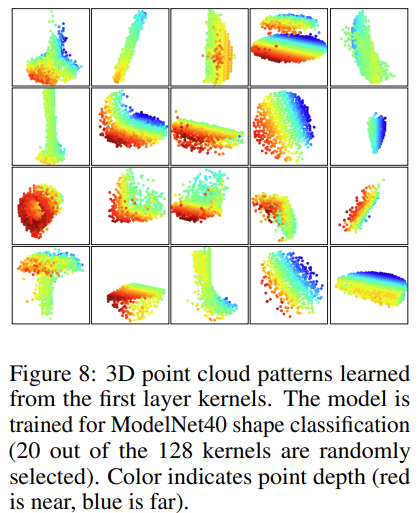
아래 Figure 8은 PointNet++의 첫 번째 layer kernel을 거친 이후 ModelNet40의 3d point cloud classification 결과를 visualize한 것이다. point의 색깔은 depth를 의미하며 빨간색은 가까운 points, 파란색은 먼 points를 의미한다. 결과를 보면 object의 특징을 잘 포착한 것으로 판단된다.
Conclusion
본 논문에서는 PointNet에 이어서 sampling 3d points를 처리하기 위한 neural network architeture인 PointNet++을 제안하였다. PointNet++은 입력되는 point set의 partitioning을 반복하면서 hierarchical features를 효율적으로 학습한다. non-uniform한 point sampling issue를 해결하기 위해 두 개의 set abstraction layers를 사용하여 local point density에 따라 multi-scale information을 aggregate한다. 결과적으로 3D point cloud benchmark에서 sota를 달성할 수 있었다. 마지막으로 저자는 MSG와 MRG를 사용함에 있어 inference speed를 가속화 하는 방법에 대해 생각해 볼 가치가 있다고 주장한다.