
안녕하세요. 여덟 번째 X-review입니다. 이번에 소개해드릴 논문은 지난 주 Detr리뷰의 후속작인 Deformable detr으로, 핵심은 Detr의 약점으로 언급된 Small object detection의 성능을 높이고자 고안한 방법이 소개되고 있습니다. Detr에서는 FPN(Feature Pyramid Network) 등의 Multi-scale Feature map 간의 결합을 통해 해결하는 것을 추후 과제로 남겨두었는데 과연 저자는 해당 방식을 사용하였을까?에 초점을 맞춰 읽다보면 재밌게 읽으실 수 있을 것 입니다. 그럼 시작하겠습니다.
Abstract, Introduction
Detr에 대해 돌아보겠습니다. Detr의 핵심은 direct set prediction으로 object query들이 한번에 object를 찾아나서는. 마치 보물 사냥꾼이 보물을 찾아나서는 과정처럼 NMS, RPN과 같은 사람의 지식이 필요한 혹은 사전에 처리해야하는 과정이 필요로하지 않다는 점입니다. 바로 위에서 보물 사냥꾼이 보물을 찾아나선다고 했는데, Detr의 object query들은 처음에 임의의 위치에서 보물을 찾다가 Transformer Encoder를 통해 나온 Attention map을 토대로 보물이 있을만한 곳을 힌트로 얻고 그 근처 지역을 탐방하죠. 그렇게 Decoder에서는 Attention map과 object query가 Cross-attention (Detr에서는 이 과정을 다른 언급없이 Self-attention이라고 말했지만, Deformable Detr에서는 Cross-attention이라고 명합니다)을 통해 보물을 찾아나서고, object query 사이의 Self-attention을 통해 보물이 있을 것으로 추정하는 위치를 보정합니다.
또한 DETR에서 중요한 내용은 Bipartite matching, 이분매칭으로 보물 사냥꾼들이 각자 하나의 보물을 찾고자하는 과정을 거칩니다. 보물과 보물 사냥꾼이 각각 7개와 7명이 존재한다면, 각자 하나의 보물을 차지하는 것이 훨씬 좋겠죠? 이를 위해 Hungarian algorithm을 이용하여 Bipartite matching을 수행합니다. 자세한 과정은 이전 Detr 리뷰를 참고하시면 좋을 것 같습니다.
그렇다면 Detr은 장점만 존재할까요? 당연히 단점이 존재합니다. 우선 Multi-head Self-attention, MSA를 8번 반복하는 Transformer의 구조를 그대로 가져와 Pixel-by-Pixel 연산을 진행하기 때문에, O(H^2W^2C) 의 연산량을 필요로합니다. 많은 연산량과 동시에 Inductive bias로 인해 수렴에 오랜 시간을 필요로합니다. Deformable Detr에서는 직접적으로 Inductive bias를 언급하지는 않고, Normalized weight를 이유로 삼고 있습니다. Normalized weight에 대해서는 뒤에서 다시 살펴보도록 하겠습니다. 또한 처음에 언급한 것과 같이 Small object detection의 성능이 낮은 것을 문제로 삼습니다.
이는 Detr 논문에서도 이미 언급한 것으로, Detr은 CNN Backbone 을 통해 나온 Feature map에 대해 Self-attention을 진행하기 때문에 ( 3 \times 416 \times 416 일 때 Backbone을 통해 나온 Feature map은 2048 \times 13 \times 13 의 Resolution), Self-attention을 통해 나온 Attention weight들이 Small object를 보기에 유의미하기는 어렵습니다. 이 부분에 대해 한번 더 보자면, Row resolution의 Feature map에 대해 Self-attention을 진행한다는 것은 Receptive field 관점에서 Small object에 대해서는 유용하지 않겠죠. 조금 생각해보면 금방 눈치챌 수 있을 것입니다. 그리고 Detr은 Pixel-by-Pixel 연산으로 Feature map에 대해 Self-attention을 진행하며, 이는 ViT (입력 영상에 대해 Attention 진행)와는 다른 것을 상기하면 Feature map resolution이 왜 영향을 미치는지 이해하는 데에 좋습니다.
Introduction에서는 위에서 몇 번 언급한 Detr의 단점에 대해 언급하고 있습니다. 우선적으로 기존의 object detection 모델에 비해 모델의 수렴까지 훨씬 많은 Training Epoch를 필요로 한다는 점입니다. 실제로 Faster R-CNN에 비해 10-20배 많은 Epoch를 필요로 한다고 합니다. (Faster R-CNN: 50, Detr: 500) 물론 모델의 Inference time, 즉 FPS가 더 중요하다고 볼 수는 있지만, 일각에서는 많은 GPU, Computational cost를 필요로 하는 모델에 대해서도 문제점을 지적하는 것으로 보입니다. 이러한 Training Epoch에는 물론 Transforemr 기반 모델이 갖는 Inductive bias에 대해 생각해볼 수도 있습니다. 하지만 또 다른 시점에서는 CNN Backbone을 통해 나온 Feature map에 대해 Transformer 연산을 진행하고 있기 때문에, Inductive bias로 이야기를 끌고 가지는 않고 있습니다.
다음으로는, Detr 논문에서도 언급된 Small object detection 성능입니다. 위에서 언급했기에, 한 문장으로만 정리하자면 “High resolution Feature map에 대해 Transformer 연산을 진행하는 것은 Small object에 Attention map이 적절히 그려지기에 쉽지 않다.”로 볼 수 있겠네요. 그렇다고 Row resolution Feature map에서도 Attention을 진행하자니, O(H^2W^2)인 Computation을 생각하면 엄두가 안날 것 같습니다.
그렇다면 저자는 위의 문제들에 대해 어떠한 방식을 사용하고자 했을까요? Pixel-by-Pixel Attention은 부담스럽고, 그렇다고 Attention을 어떻게 줘야할지, 또한 Small object detection을 위해 정말로 Detr 논문에서 제안한 FPN 방식을 사용하는지에 대해 지켜보겠습니다.
Deformable Convolutional Network
저자는 다음 논문 [ICCV 2017] Deformable convolutional networks 에서 아이디어를 얻었습니다. Deformable convolution의 핵심은 굉장히 간단하고 직관적입니다. 아래 그림을 먼저 보겠습니다.
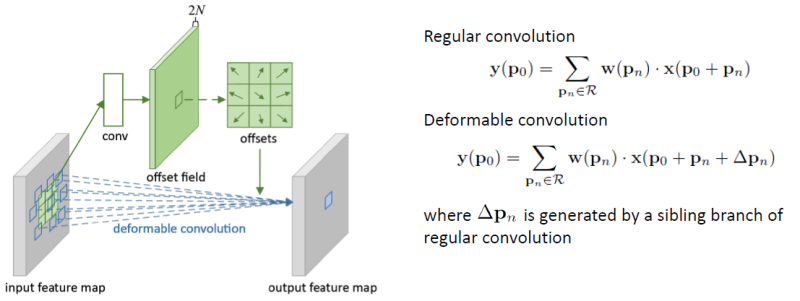
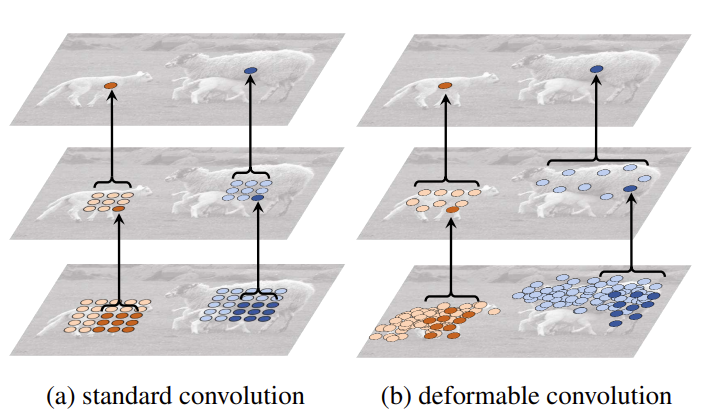

이해를 돕고자 위의 세 그림을 가져왔습니다. Deformable Convolutional Network (이하 DCN)의 저자는 CNN 방식이 기하학적으로 일정한 패턴을 가정하고 있기 때문에, Translation, Rotation 등의 이미지 변형에 대해 유연하지 못하다고 주장합니다. 이러한 한계는 추후 ViT의 초석으로 발전했다고도 볼 수 있는데, “CNN이 고정된 크기의 kernel을 사용하여 이미지를 훑고 있기 때문에, 커널 내의 Long-range dependencies를 학습할 수 밖에 없다. 따라서 비교적 앞단의 레이어의 Feature map은 Global information을 갖고 있지 않다.” IPIU에 제출한 제 논문에서도 주장한 바이며, 따라서 2D offset을 학습하는 Convolution 모델을 주장합니다.
아이디어의 핵심은 “Sampling grid에 2D offset을 더한다”인데, 조금 더 직관적으로 아래의 이미지와 함께 살펴보겠습니다.
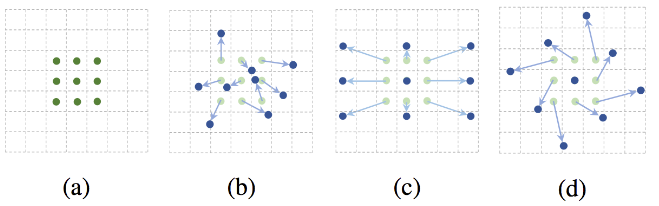
그림 (a)의 초록색 점이 기존 CNN의 sampling grid입니다. 3×3 kernel을 사용하여 Grid에 각각 해당하는 Pixel 들에 Weight을 곱한 후 더하는 연산으로 진행되겠죠. 당연한 이야기입니다. 이 점들에 초록색 화살표로 표시된 offset을 더한다면, (b)-(d)처럼 다양한 패턴으로 변형할 수 있습니다. 2D offset은 단순히 고정된 크기의 kernel 내에서만 학습하는 것이 아닌 kernel 내 sampling point 들이 마치 주변의 Feature point들의 위치를 가리키고 있는 것처럼 학습하는 방식을 의미합니다. 아마 익히 알고 있는 방법일 수도, 처음 들어보는 방법일 수도 있겠지만 (b)-(d) 점들이 초록색에서 파란색 점으로 이동하는 offset을 가지고 있다는 아이디어만 알고 넘어가도 좋을 것 같습니다.
그래도 조금 더 이야기해보자면, 첫 번째 그림처럼 Input Feature map에 대해 2d offset을 학습하는 Convolution을 추가적으로 구성하여, 각 Sampling grid 내 Sampling point 들이 offset을 통해 Feature point 들에 근접하도록 이동한 후 (해당 지점을 Sampling point라고 명합니다) 기존의 Weight 연산을 하고서, Input feature map과 더하여 Output Feature map을 내뱉도록 합니다. 이렇게 학습한다면 kernel 크기는 고정되어 있지만, 각 point들이 가리키는 점은 detection, classfication 등의 object가 있을법한 위치에 해당하겠네요. 굉장히 직관적이고 쉬운 아이디어입니다.
그렇다면 2D offset의 이동 반경에 대해 의문증이 들 수 있는데, offset은 정수가 아닌 실수 범위로, 즉 1, 2 Pixel 이동이 아닌 0.5 Pixel 이동이 가능합니다. 그렇기에 후에 Bilinear interpolation의 보간법을 활용하며, Training 과정에서는 2D offset을 학습하는 Convolution과 Output feature를 만드는 Convolution 둘 모두를 학습합니다. 이 정도쯤하면 Deformable Convolution의 기초 개념 정도는 짚고 넘어간 것 같습니다. Deformable Convolution을 object detection 관점에서 한 줄로 추리자면, “2D offset을 통해 kernel 내 point (Pixel) 들이 Feature point, 즉 object가 있을 법한 위치에서 연산을 하여 조금 더 object에 Attention 하고자 학습한다”라고 볼 수 있겠네요. 그렇다면 Deformable Convolution을 Deformable Detr에서 활용하는 방식은 어떨까요? 아래 방법론에서 살펴보겠습니다.
METHOD
Realted work는 위에서 언급한 Transformer (Attention mechanism)과 Deformable Convolution (Multi-scale Feature Representation)에서 이미 언급했기 때문에, 넘어가겠습니다. 사실 METHOD 이전에 우리는 REVISITING TRANSFORMERS AND DETR에서 Self-attention의 시간 복잡도 등을 수학적으로 되짚어 볼 필요가 있는데, 이는 아래 APPENDIX에서 다시 설명하겠습니다. 우선은 Deformable Detr의 Main concept이 궁금하니, 방법론을 살펴보겠습니다.
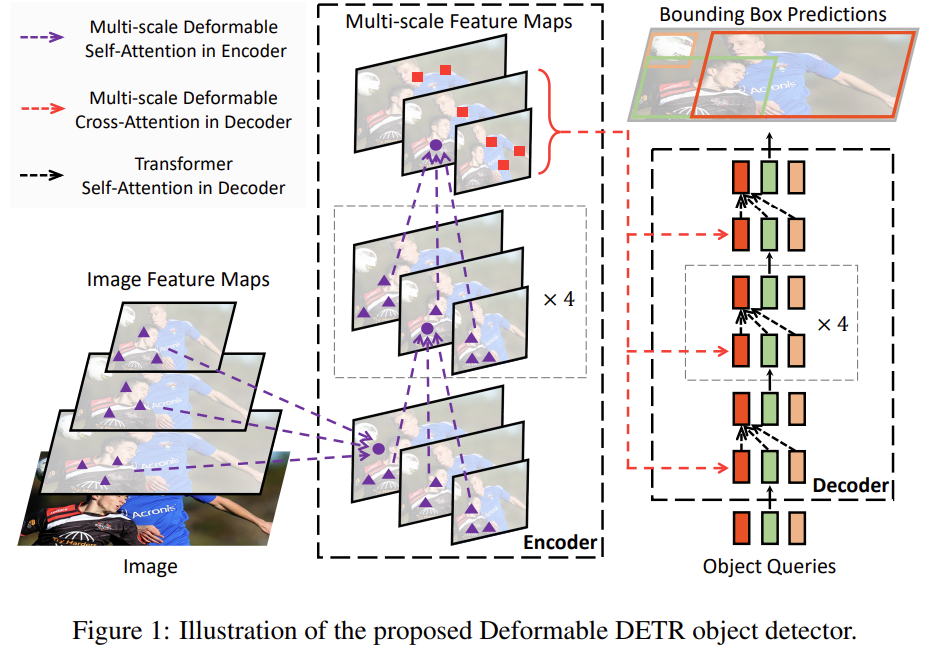
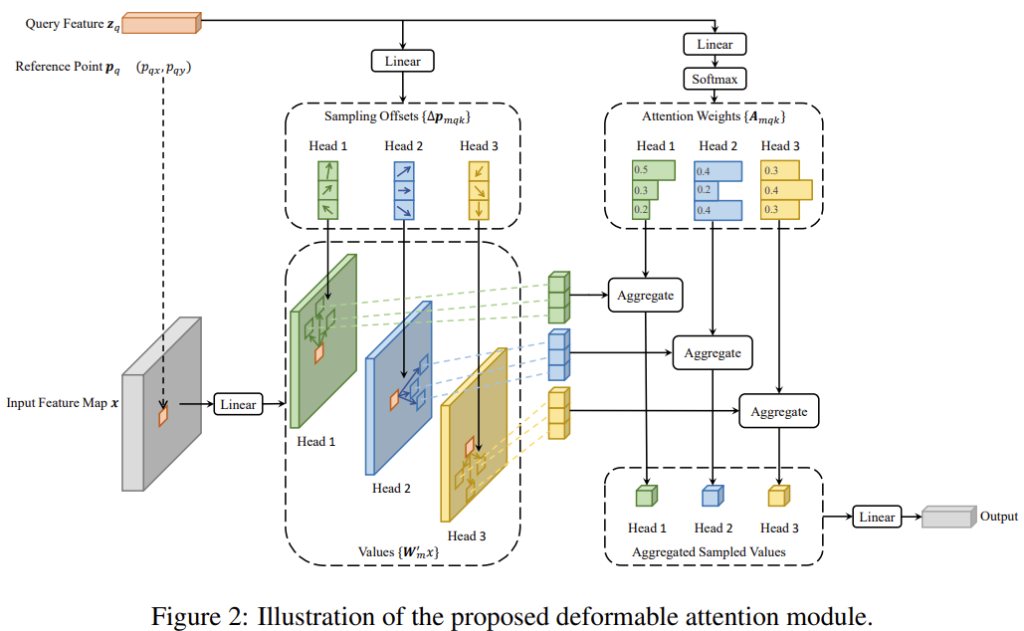
이전 Detr 논문을 소개하며 Detr의 작동 방식을 설명하였으니, Deformable Detr 만의 방식을 소개하고자 합니다. 이해를 위해 논문의 Figure 1,2를 가져왔으며, 먼저 Figure 1을 보겠습니다.
무엇보다 눈여겨 봐야할 점은 보라색 선으로 표현된 Multi-scale인데, Deformable Detr은 High resolution으로 인한 Small object detection 성능 하락을 해결하고자 Multi-scale Feature map로부터 Feature를 Self-attention 연산의 입력으로 활용합니다. Detr이 CNN Backbone을 통해 나온 한 Scale의 Feature map에 대해 Global한 Attention 연산을 진행한 것과는 결이 다른 모습을 볼 수 있습니다. 그렇다면 FPN 구조를 사용했나?하면, 당연히 그렇지는 않죠. FPN은 Multi-scale Feature map의 정보를 연산하여 (보통 Upsampling, Downsampling을 통한 Weight sum 연산을 진행합니다) 한 Feature map에서 Multi-scale Feature map의 정보를 가지고 있다는 특징을 갖고 있지만, Deformable Detr은 Multi-scale Feature map으로부터 Feature를 모두 사용합니다. 실험 파트에서 FPN에 대한 실험 결과를 소개하겠지만, 미리 살펴보자면 성능 차이는 없는 것을 알 수 있습니다.
아, 모두 사용한다는 말은 다시 정정하는 것이 좋겠네요. 그 이유로, 모두 사용한다고해서 그렇다면 Multi-scale Feature map (그림에서처럼 세 Feature map을 칭하겠습니다.) 의 모든 Pixel-by-Pixel Self-attention 연산을 진행하느냐하는 것은 아니기 때문입니다. 이는 Deformbale Self-attention으로, Computational cost를 고려할 때 Detr과 차별점이며 핵심이 되는 부분입니다. Deformable Detr은 Multi-scale Feature map에서 Attention 연산을 수행할 때, Query에 대해 Key가 모든 Pixel이 되는 것이 아니라, Deformable Convolution을 통해 학습딘 Sampling points들에 대해서만 Attention 연산을 진행합니다.
해당 내용은 위에서 설명한 Deformable Convolution이 이해가 되었다면, 크게 어렵진 않을 것 입니다. 예를 들어보겠습니다. 300 x 300 Resolution Feature map에서, 하나의 Pixel (0,0으로 두겠습니다)에 대해 Key가 다른 모든 Pixel로 둔다면 Attention 연산은 300 x 300번 수행될 것 입니다. 하지만 만약 하나의 Pixel에 대해 Deformable Convolution을 통과한 후 학습된 Sampling point를 4개로 잡고 해당 Sampling points에 대해서만 Attention 연산을 진행한다면? 300 (Query) x 4 (Key)의 연산만 수행하면 됩니다. 직관적인 예시로봐도, 연산량이 굉장히 줄어든 것을 확인할 수 있습니다. Sampling point 수에 따라 연산량과 성능이 다를 수 있다고 생각이 들지만, 그에 해당하는 실험은 없어서 다소 아쉽습니다. 실험은 Multi-head attention의 반복 수를 8, Sampling key points의 수를 4로 설정한 후 진행합니다.
그럼 이제는 Multi-scale Deformable Selt-attention을 합쳐서 이해를 해보겠습니다. Figure 1에서 Encoder 아랫단의 동그라미를 Query라고 할 때, Key는 해당 이미지의 모든 Pixel이 아닌 이제는 다른 Scale의 Feature map을 먼저 보고, 각 Feature map에서 정해진 수의 Sampling point를 뽑습니다. Encoder에서도 마찬가지로, Multi-scale Feature map으로부터 뽑았으니 (예를 들어 총 9개의 Feature map이 있다고 할 때), Encoder에서도 처음에는 하나의 Feature map이 여러 Feature map (7개, 1,2,3 -> [1], 2,3,4 -> [2], …, 7,8,9 -> [7])이 존재할 것이며, Encoder를 통과하며 다시 Sampling points들에 대해 연산이 진행됩니다. 해당 연산이 진행된 이후 Decoder로 Key가 넘겨질 때, 다시 Multi-scale Feature map의 Sampling points들만 Cross-attention 연산을 진행하게 됩니다. Cross-attention이라 함은 Attention map과 object query간의 연산을 의미하며, 이는 Detr 과정과 동일하므로 다시 한번 설명하진 않겠습니다.
결국 Deformable detr과 Detr은 Key로 사용하는 Pixel들을 얼만큼 사용하는지에 따라 나뉩니다. 모든 Pixel과의 Attention 연산을 진행하는 것이 성능적으로 더 좋다고 생각할 수 있으나, 초기에 Normalized된 Weight를 생각하면 꼭 그렇지만은 않은 것을 실험에서 확인하실 수 있습니다. 이제 Figure 2를 통해 Deformable Attention에 대해 조금 더 자세히 알아보겠습니다.
Figure 2는 Deformable Detr의 Encoder 부분에 대한 설명을 담고 있습니다. Output으로 나오는 부분이 결국 Decoder의 Key로 사용되는 부분이겠죠. Encoder에서 우선적으로 보이는 부분은 Reference Point입니다. Reference Point란 Sampling을 하기 위한 기준점으로, 해당 Point로부터 주변에 얼만큼 offset을 가져가야할지, 얼만큼 떨어진 곳에서 Sampling을 해서 Attention을 할지를 결정합니다. 일종의 Feature라고 생각하시면 편할듯합니다. Deformable Convolution의 kernel이 들어갔을 때, 해당 kernel이 Reference Point가 되어, Sampling point를 뽑는 작업과 동일합니다. (이 말이 이해가 어렵다면, 이렇게 생각해보겠습니다. 위에서 우리가 (a) – (d)의 기존 CNN과 Deformable Convolution에 대해 설명했을 때, 원래의 초록색 점은 Reference Point입니다. 얼마나 offset을 가져가야할지를 결정하게 만들죠. 그렇게 이동한 점이 바로 Sampling point가 되겠죠. Reference Point로부터 Sampling point를 계산하여 결정한다! 라고 생각하면 좋을 것 같습니다. 일종의 쿼리 역할을 하는 것이죠)
다시 Figure 2를 살펴보면, Input Feature map에서 Query (Reference Point)로부터 Linear 레이어를 통해 Sampling offset을 뽑게 됩니다. 해당 offset은 Sampling point를 결정짓는 것으로, 위에서 이미 언급했듯이 Bilinear interpolation을 통해 결정됩니다. 자, 이 과정을 간단한 수식 하나로 정리해볼까요? Reference Point (기준점) + Sampling offset (얼만큼 이동할지) = Sampling points. 어렵지 않게 생각하실 수 있을 것으로 기대합니다.
해당 Sampling point로부터 Feature를 뽑으며 (value), 이제 Attention weight와 Aggregation 작업을 통하면, Aggregated Sampled Values를 얻을 수 있습니다. 이 때, 다시 눈여겨볼 점으로 기존 Self-attention에서는 Query와 Key의 내적 연산을 통해 Attention weight을 구하는 반면, Deformable Detr은 Query (Reference Point)에 Linear 레이어 (+ Softmax)를 통해 Attention weight을 구합니다. 해당 과정이 실제 Attention이라고 볼 수 있냐는 질문에 대해, 사실 실험 단에서 성능 차이는 없었지만 속도가 조금 더 빨랐다고합니다.
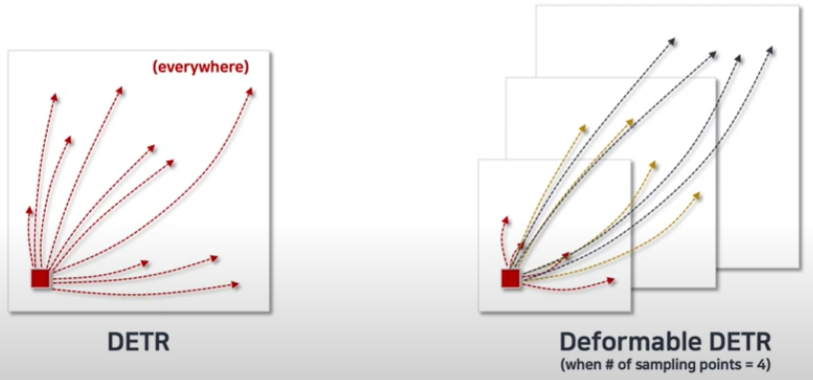
이제는 그렇게 Aggregation을 하고나면, 최종적인 Attention value를 얻고, Output으로 사용합니다. 아래는 논문에 나온 그림은 아니지만, 이해에 도움이 될 수 있을 것이라 생각하여 들고 왔습니다. Detr과 Deformable Detr의 차이가 보이시나요? 몇번이고 언급하지만, Sampling point가 4로 지정되어있다면 다른 Scale의 Feature map에 대해서도 Sampling point를 추출합니다. 이 때, 한가지 짚고 넘어가자면 각 Feature map은 모두 Scale이 상이하기 때문에 Pixel 좌표 x, y는 0~1 사이로 Normalized 하여 연산합니다.
그렇게 Output이 나오면, 이제는 해당 Output으로 Decoder에서 object query와 Cross-attention 연산을 진행합니다. Cross-attention에서는 각 object query를 linear 레이어에 태워 Reference point를 산출합니다. 어? 이 과정이 Encoder와 상이하네요. Encoder에서는 Reference point와 Query가 같았다면, 지금은 object query를 linear 레이어에 태운 Reference point로부터 Sampling points를 추출합니다. 물론 어려울 수 있으니, 다시 예를 들어보죠. object query는 보물 사냥꾼이라고 했습니다. 우리는 object라는 보물을 찾아 떠나야하죠. 그런 object query들을 linear 레이어에 태워 Reference point를 뽑는다면? 정확히 한 Pixel마다 한 명의 보물 사냥꾼이 기다리고 있진 않겠죠. 학습 과정에서 보물이 있을법한 곳을 알게 되니, 그러한 위치에 Reference point들, 즉 보물 사냥꾼들이 기다리고 있을 것 입니다.
그렇다면 Reference point가 Encoder와 Decoder에서 어떻게 다른지, 눈치 채셨나요? Encoder에서는 각 Pixel 모두를 Reference point로 두고 2D offset을 계산하는 반면, Decoder에서는 Reference point 자체가 이제는 object가 있을 법한 위치, 즉 특정 픽셀에 많이 몰릴 수 있다는 것을 염두해둬야합니다. 하지만, object query들끼리 이미 Self-attention을 통해 Bipartite matching으로 중복을 제거하고 (이 부분은 Detr 리뷰를 참고해주시길 바랍니다), 또한 예시로 픽셀은 300 x 300인 반면 object query는 300개에 불과하니 (Detr에서는 object query 수를 100으로 지정했습니다.) 한 지점에 막 몰리지만도, 또는 전체적으로 봤을 때는 Sparse한 부분도 있겠죠. 이제는 각 Reference point에서 Sampling point를 산출하여 Encoder와 동일한 Multi-head Self-attention을 수행합니다.
사실 이번 논문은 해당 Contribution이 끝입니다. 논문에서는 Detr과의 연산량 비교, Deformable Detr의 과정을 수식으로 적어놓고 (사실 위에서는 아래에서 설명하겠다고 말은 했습니다만,) 복잡하게 말은 했지만, 사실은 설명에서는 필요성을 크게 못느꼈습니다. Detr 수식에서 Deformable Convolution에서 사용된 offset 연산을 더한 수식을 적어놓은 것이 끝이였고, O(N_qC^2 + N_kC^2 + N_qN_kC) 인 Self-attention에서 N_q = N_k > C 여서.. 등등의 많은 수식들이 있습니다만, 결국에는 우리의 300 x 300 이미지에서의 예시가 조금 더 와닿았습니다. 만약 궁금하시다면 Transformer의 Self-attention에 대해 수식적으로 이해한 뒤 읽어보시면 대략적으로 어떤 느낌인지 와닿을 것 입니다. 실험을 통해 다시 살펴보겠습니다.
Experiments
자, 그럼 실험으로 넘어오겠습니다. 실험에서는 Detr과의 비교가 주된 관심사였기 때문에, Detr과 마찬가지로 COCO 2017 Dataset을 활용하였으며, ImageNet Pre-trained ResNet-50을 Backbone 네트워크로 사용했습니다. Multi-scale Feature map을 사용할 때, Sampling Points 수를 4로 고정하였으며, (이 점이 제가 위에서도 언급한 부분인데, Point 수에 따른 Ablation Study가 없는 것이 아쉽습니다) 주목할 점으로는 object query를 Detr에서 100개 사용한데 비해 Deformable Detr에서는 300개를 사용했습니다. 이 점도 조금 의아한 부분인데요, 먼저 저의 고찰을 살펴보죠. object query 수를 사전에 정한다는 것이 이미 Prior-Knowledge를 사용한 것이 아닌가? Post-processing을 거친 것이 아닌가?하는 의문증이 듭니다. 또한, Detr에서는 100개의 Object query임에 (COCO dataset은 평균적으로 한 이미지 내 7개 정도의 Object가 존재한다고 합니다) Background에 대한 추가적인 Log scale-term 등의 보정 작업을 거쳤는데, 왜 300개나 늘렸지?하는 생각이 듭니다. 어쨋든, V100 환경에서 실험했다고 하네요. 이제 실험 결과를 살펴보곘습니다. 먼저 Detr과의 비교입니다.
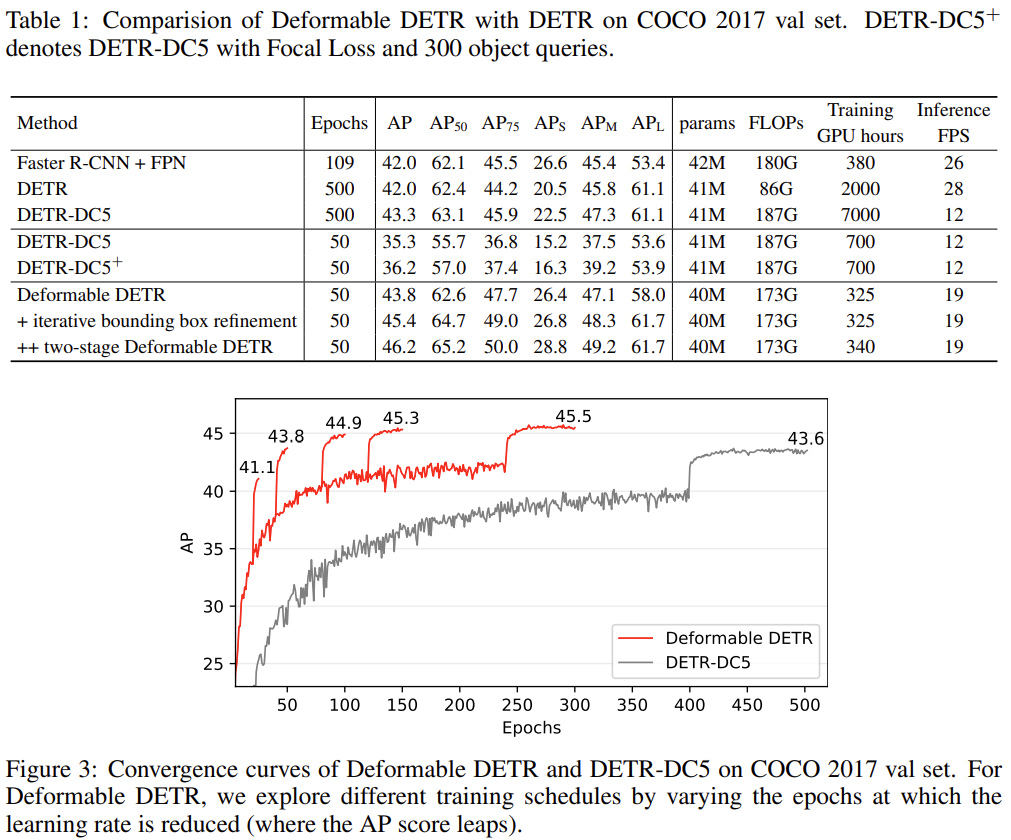
DETR-DC5는 Backbone 마지막 단에 Dilation을 추가한 모델을 의미합니다. DETR-DC5+는 Pair comparison을 위해 object query 수 등의 implementation detail을 Deformable-Detr과 맞춘 방법을 의미합니다. 또한 Deformable DETR에 +iterative bounding box refinement와 ++two-stage Deformable DETR을 확인할 수 있는데, 이는 저자가 성능 향상을 위해 추가적으로 고안한 방법입니다. iterative bounding box refinement는 Decoder에서 bounding box의 offset을 보정해주는 추가적인 레이어를 사용한 방법이며, 두 번째는 Encoder를 학습하여 object query를 랜덤하게 설정하지 않고 RPN이 object가 있다고 예측하는 지점을 초기 Feature 지점으로 사용한 two-stage 방식을 의미합니다.
표에서 Epoch와 Training GPU hours를 중점적으로 살펴보면 되는데, DETR 대비 Deformable DETR이 1/10인 50번의 Epoch로 1.8%의 AP 향상을 보임을 알 수 있습니다. DETR과 DETR-DC5 방법이 각각 2000, 7000 시간이 소요된다니.. 어마무시하네요. 또한 추가적인 Trick을 사용한 iterative bounding box refinement와 two-stage Deformable DETR을 모두 사용했을 때, 약간의 학습 시간 (15시간)이 추가되지만, 2.4AP가 향상된 모습을 확인할 수 있습니다.
그보다도 가장 중요시 살펴 볼 부분은 AP_s 입니다. Deformable Detr에서 Detr의 Small object detection에서의 성능을 문제점으로 지적했는데, 어느 정도의 성능 향상이 일어났는지를 살펴보면, 베이스 모델 (Detr, Deformable Detr)에 비하면 약 5.9AP의 향상이 오른 것을 확인할 수 있습니다. 굉장한 수치네요. Multi-scale Feature map을 사용한 것만으로도 이렇게 높은 성능을 얻을 수 있다는 점이 실로 놀랍습니다. 마지막으로 FPN을 사용했을 때와, Backbone에 따른 Ablation Study를 보고 마무리 짓겠습니다.
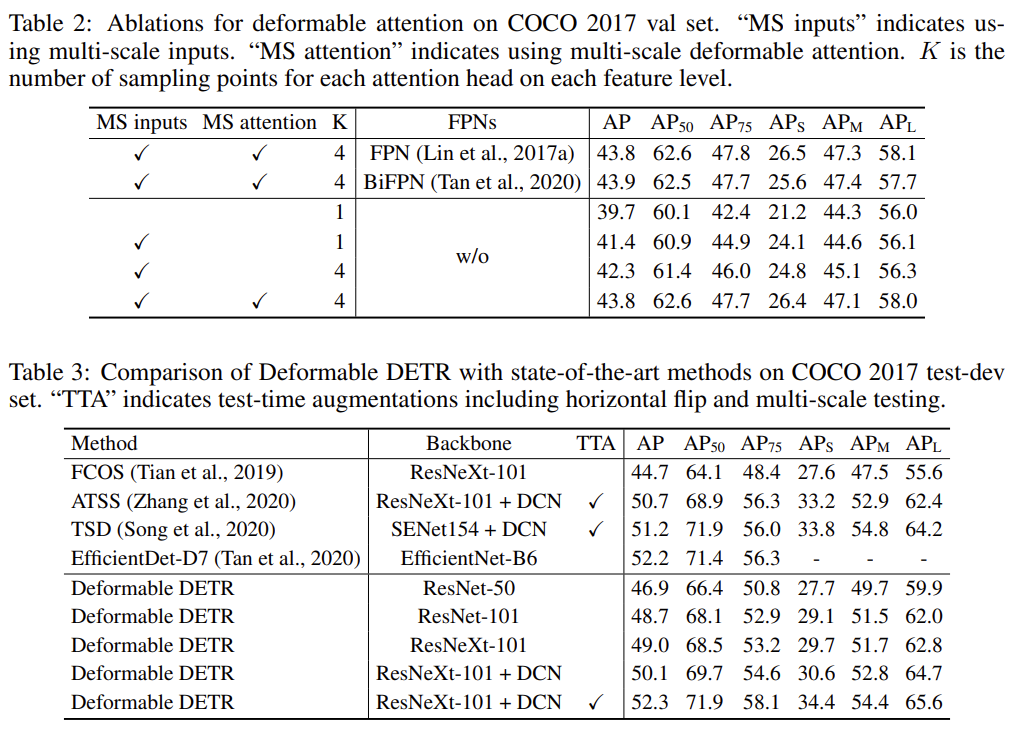
사실 이번 Ablation study에서는 할 말이 많이 없습니다. 주로 볼 점은 FPN을 사용했을 때와 하지 않았을 때의 성능 차이가 없다 (43.8 AP), 긜고 Backbone과 Data agumentation에 대해 Test-time augmentation을 가져갔을 때의 성능 차이를 보이는데, 저자가 보여주고자 했던 바는 아무래도 Deformable Detr + ResNeXt-101 + DCN + TTA 시, 당시 SotA에 비해 높은 성능을 보임을 말하고 싶은 것 같습니다. 그보다도 위에서 언급한 Detr과 Deformable Detr의 성능 비교가 이 논문을 이해하기 위한 핵심이 아닌가 싶네요.
마무리하며, 이번 논문의 핵심은 이전에 리뷰한 Detr의 성능과 속도를 어떻게 끌어올렸는지가 핵심이 되는 것 같습니다. 이번 논문 리뷰보다 추후 소개할 MS-DETR 논문이 기대가 되는 것 같습니다. 그렇다면 이상으로 리뷰 마치도록 하겠습니다.
좋은 리뷰 감사합니다.
간단히 이해한 내용이 맞는지 확인하고 싶어 질문드리겠습니다! detr과 deformable detr을 비교하면서 보니 좋았던 것 같습니다. 위에 introduction에서 detr은 많은 training epoch을 필요로 하고 small object detection 성능이 낮은 것을 지적하면서 시작하는데, 실험 부분에서 보니 detr에 비해 절반 이상 training time이 줄어든 것을 확인할 수 있었습니다. 이러한 이유로 deformable attention을 적용하면서 sampling된 pixel에 대해서만 보기 때문에 줄어든 것이라고 이해하는 것이 맞을까요?
감사합니다.
네 정확합니다. CNN Backbone 마지막 단 Feature map에 대해, DETR은 300×300 Feature map에 대해 Attention 연산을 진행하면 300 x 300으로, 9만번의 Attention 연산이 진행되겠지만, Sampling points만으로 Attention 연산을 진행하면 [Sampling points]번의 Attention 연산만 진행하면 됩니다. 추가적으로, Sampling points는 Multi-scale Feature map에서 추출하기 때문에, Small object에 대한 성능도 개선할 수 있었습니다.
안녕하세요 이상인 연구원님 좋은 리뷰 감사합니다.
intro만 읽었을 때는 분명 FPN을 사용한 Multi-scale Feature map을 이용한 방법론인데 pixel-by-pixel연산을 수행한다고 해서 높은 computation cost는 어떻게 해결할 지 의문이 들었는데 끝까지 읽고 나니 일정한 수의 sampling key point만을 사용하여 연산을 확 줄인 것이 인상적이었습니다.
또한 모든 픽셀의 정보를 사용하는 것과 특정한 픽셀만 사용하는 것 중 막연하게 더 많은 픽셀을 key로 사용하면 더 좋은 성능이 나오지 않을까 하는 기대를 했었는데 꼭 그렇지 않은 것을 확인할 수 있었네요. 연구원님의 생각과 같이 다양한 수의 sampling key point로 실험하면 어떤 결과가 나올 지 궁금해지네요
크게 중요하진 않지만 실험 결과를 보고 궁금해진 것이 있습니다. Table 1을 보면 DETR에 비해 Deformable DETR에서 AP_L의 성능은 오히려 떨어진 것을 볼 수 있는데 DETR은 high resoltion feature, 즉 큰 물체를 보는 feature에서 모든 pixel을 고려하고, Deformable DETR은 같은 resolution의 feature를 사용하더라도 지정된 개수의 pixel만을 고려하기 때문에 이런 결과가 나온 것이 아닌가 생각했는데 이상인 연구원님의 생각은 어떠신지 궁금합니다. ㅎㅎ
네 우선 질문 감사합니다.
먼저, 정확히 말하자면 FPN 방식을 사용하진 않습니다. Multi-scale Feature map의 Resolution을 그대로 가져갔을 때의 Sampling Key points를 추출하기 때문입니다. (FPN은 Up-down sampling을 통해 Feature map 간의 연산으로 특정 Resolution에서 Feature를 추출하는 구조입니다)
네. 저도 더 많은 픽셀을 Key로 사용했을 때, 혹은 Multi-scale Feature map의 수를 달리 했을 때의 성능도 궁금하긴 하네요. 아마 그 이유가 있을 것 같은데, 언급이 안되어 있어 아쉽습니다.
AP_L의 성능이 낮은 이유에 대해서는, 아마도 All Pixel-by- All Pixel 연산을 한 DETR의 성능이 조금 더 좋을 수 있지 않았을까하는 고찰이 듭니다. 혜원님의 생각이 일리 있는 것으로 보입니다.
안녕하세요 상인 연구원님 리뷰 잘 읽었습니다
덕분에 제가 오해한 부분을 정정할 수 있었습니다. 저는 Deformable attention에서 feature map에서 추출되는 sampling point간의 attention을 구한다고 생각했었는데 feature 내 모든 픽셀과 sampling point간의 attention을 구하는 거였군요!
이렇게 기존의 모든 픽셀에 대해 pixel-by-pixel 에 대한 attention을 수행하지 않고도 detection의 성능은 높게 유지하면서 간단하게 하는 deformable attention 방법의 효과를 확인할 수 있는 연구네요.
다만 저도 sampling point에 대한 실험이 없다는 게 아쉽네요..
질문이 하나 있는데요..!! Reference point라는 것은 실제로 이미지 내 객체가 존재하는 곳에 찍히는 점들로 모델 학습 시 GT로 주어지는 점일까요? 그리고 이는 이미지 내의 객체 하나에 대한 sampling points인 건가요? 객체가 여러개인 경우 4개만으로 모든 게 커버가 될지에 대한 의문이 들어서 질문합니다. 또한, 이미지의 픽셀 하나를 모든 feature map의 4 포인트들과 attention을 수행해야하는 이유가 있을까요? 그냥 각 pixel과 sampling points간의 attention을 각 feature map에 대해 개별적으로 진행하는 것과 어떻게 다를지가 궁금합니다.
감사합니다.
안녕하세요. 리뷰 읽어주셔서 감사합니다.
워낙 예전에 쓴 리뷰 글이라.. 잘 생각이 나진 않지만 Reference Point가 우선 GT로 주어지는 점은 아닙니다. 물론 4개로 커버되는 것이 불충분할 수는 있으나, Reference Point가 말 그대로 대표되는 점들이기에 그 객체를 이해하기엔 충분할 것이라는 실험적인 결론이지 않을까 싶습니다.