오랜만에 멀티스펙트럴 보행자 검출기 논문을 들고 왔습니다. 해당 논문은 KAIST와 FLIR에서 실험을 진행했으며, 새로운 패러다임을 제시한 점을 높이 평가되어 ECCV Oral로 선정된 방법론 입니다. 역시… 학회에서든 저널에서든 신규성을 인정 받는게 가장 높이 평가 받는 것 같습니다.
Intro
최근 멀티스펙트럴 기반의 보행자 검출기 태스크는 두 모달리티 간의 미정렬 문제를 해결하고자하는 움직임이 주를 이루고 있었습니다. 저희 연구실에서 작성한 MLPD [1] 또한, 두 모달리티 간의 미정렬 문제를 해결하고자 모델의 구성에서 집중하는 것이 아닌 미정렬을 순응하고 각 모달리티 별 가상의 미정렬 데이터 증강 기법을 추가하여 해소하고자 했습니다.
MLPD에서 해결하고자 한 문제가 미정렬 문제였기에 각 모달리티 영상들을 의도적으로 움직여 미정렬을 모사한 데이터 셋을 만들어 미정렬에 대한 강인성 실험을 진행했습니다. 허나, 예상한 바와는 다르게 기존 SOTA 모델 대비 큰 성능 개선이 없었으며, 모델 구조 측면에서 미정렬 문제를 해결한 AR-CNN [2]에 비해선 오히려 낮은 성능을 보였습니다.
MLPD는 미정렬 모사 실험에서는 낮은 성능을 보였지만 다른 모델 대비 좋은 성능을 보이는 것이 사실입니다. 그럼 어떤 부분에서 좋은 성능을 보인 것일까요? MLPD는 SSD 기반의 half-way 모델에서 2가지 부분에서 변화를 주었습니다. 하나는, 각 모달리티 간 특징 추출을 개별적으로 진행하다가 detection head에서 융합을 진행합니다. 남은 한가지는 미정렬을 모사한 증강 기법과 이에 대한 Multi-label prediction 기법으로 각 모달리티 별로 어노테이션이 진행된 GT를 기반으로 학습을 진행하여 모달리티 별 특성을 높이는 방법을 사용합니다.
앞서 언급한 MLPD의 2가지 특성은 모두 모달리티 별 특성을 집중한다는 공통점이 있습니다. 모달리티 특성 별로 집중을 극대화한 점이 MLPD가 이전 SOTA 모델을 앞도는 성능을 보여준 것으로 판단됩니다. 그럼, 각 모달리티 별 학습을 진행하고 예측값을 합치는 late-fusion이 가장 좋다는 걸까요?
사실 그렇지도 않습니다. 여러분도 아시는 바와 같이 RGB는 조도가 낮은 상황에서 오검출률이 높아지고, Thermal 영상은 컨텐츠 정보가 부족하여 밤/낮 상관없이 사람과 유사한 형태를 띄는 경우에 사람이라고 오검출하는 경우가 발생합니다. 이러한 두 모달리티의 특성 때문에 확실히 두 정보를 함께 사용했을때, 좋은 결과를 보입니다. (이는 half-way 논문에서 충분히 설명했다고 생각합니다.)
두 모달리티의 특성을 살리되, 두 정보를 함께 사용해야하는 모순적인 상황인데 어떻게 해야하는 걸까요?
이번에 소개해 드릴 논문이 이에 대한 해답으로 향하는 방향을 제시한다고 생각합니다. 해당 논문은 각 모달리티 별로 학습된 검출기와 두 모달리티를 퓨전한 검출기의 결과값을 앙상블하는 방법을 제안합니다.
Method
해당 논문의 기법은 매우 간단합니다. 각 검출기 별로 예측된 값을 재조정하는 앙상블 혹은 late-fusion 기반의 방법론을 제안합니다. 그렇기에 모델 측면에서의 방법론은 아닙니다.

방법은 아주 간단합니다. ALG 1. 에서 보이는 바와 같이 각 모달리티 별로 학습된 모델의 예측값을 기반으로 다시 NMS를 진행하는 방법을 이용합니다. 단, NMS를 그대로 사용하는 경우에는 각 모달리티에서 나온 공통으로 나온 케이스 중 가장 높은 스코어를 정답으로 수용하기 때문에 앞서 언급한 각 모달리티의 특성을 고려한 확률이라고 보기 어렵습니다. 저자가 제안한 ProbEn은 NMS를 개선하여 각 모달리티 특성을 고려한 확률 앙상블 기법을 제안합니다. 자세한 방법은 차차 설명하도록 하겠습니다.
+ 여기서 이야기하는 확률은 class score와 bbox에 대한 확률을 모두 포함합니다.
+ ALG 1을 풀어서 설명하면 각 모달리티 별로 예측한 값들을 모두 담은 set D를 기반으로 NMS을 진행합니다. 가장 높은 class score를 가진 결과값대로 정렬을 진행하고 이 중 가장 높은 스코어를 가진 bbox와 IoU가 0.5 이상으로 겹치는 케이스는 제거하는 방식이 NMS에 해당합니다. ProbEn은 가장 높은 스코어를 가진 bbox와 IoU가 0.5 이상인 케이스를 제거하는 것이 아니라 모달리티 별로 클래스 스코어 퓨전 및 bbox 퓨전을 수행합니다. 해당 부분이 ProbEn이 제안한 방법입니다. 이후, 설명드리는 내용들은 모두 해당 부분에서 수행되는 연산입니다.

앞서 이야기한대로 NMS만을 이용할 경우, 각 모달리티의 특성을 고려한 스코어가 아닌 더 강한 모달리티의 확률을 그대로 사용합니다. 그렇기에 저자는 예측 확률 앙상블을 위해 여러가지 기법을 적용해봅니다. 대표적인 예시로 fig 3에서 보이는 바와 같이 RGB는 컨텐츠 정보가 풍부하기 때문에 제대로 찾는 방면에 Thermal에서는 낮은 화질과 적은 컨텐츠 정보로 인해 작은 크기의 사람은 잘 찾지 못하는 문제를 보입니다. 이러한 특성 때문에 두 모달리티의 특성을 함께 고려하여 찾아야만 합니다. 저자는 이를 해소하기 위해 가장 간단하게 두 스코어를 평균을 내리는 방법(fig 3-(c))을 사용합니다. 이럴 경우, 빨간 박스에서 보이는 바와 같이 한 모달리티에서 스코어가 낮을 경우 오히려 스코어가 떨어지는 문제가 있습니다. 각 모달리티의 특성(확률)을 고려하여 스코어를 융합하는 방법이 필요합니다.
Probabilistic Ensembling (ProbEn). 사실 저자는 한가지 강력한 제약을 걸어둔 상황에서 융합 방법을 제안합니다. 강력한 제약은 아래의 수식 1에 해당합니다.
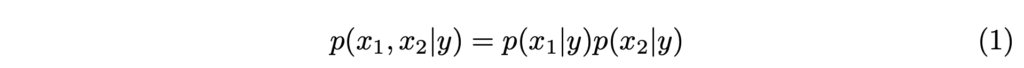
두 모달리티 x_1, x_2 의 예측 확률은 독립적이라는 전제하에서 두 모달리티는 퓨전한 확률은 각 모달리티 별 확률을 곱한 값과 동등하다는 전제를 잡고 진행됩니다.
+ 사실, 해당 부분에 대해서는 조금 모호한 감이 있지만 결과(성능)가 좋기 때문에 수용하는 쪽으로 생각이 기울어져 있습니다. 그리고 저자도 위 전제에 대해서 설명은 하고 있지만 각 모달리티 별 특성을 독립이라고 주장하는 내용이 끝입니다. 질문하지 마십쇼…
그럼 두 모달리티 x_1, x_2 를 이용하여 label y를 예측하는 모델 입장에서의 확률를 정리하면 아래의 수식 2와 같이 정리 할 수 있죠.
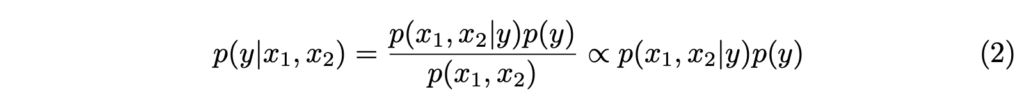
+ p(x_1,x_2) 는 이미 알고 있는 값(영상 정보)이기에 생략이 가능하는 것으로 판단하고 적용한 것 같습니다.
그럼 수식 2를 기반으로 수식 1을 적용하면 다음과 같이 정리할 수 있습니다.
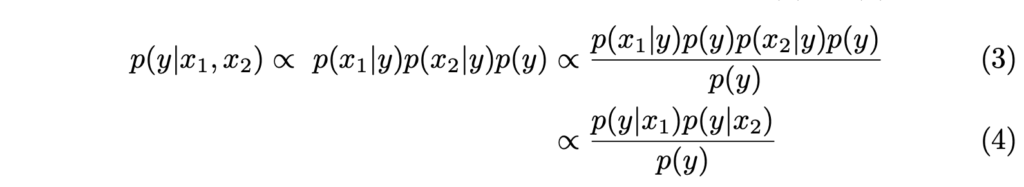
최종 정리된 수식 4와 같이 각 모달리티 별로 예측된 확률을 모두 곱하고, 이들에 대한 모든 확률으로 나눠주면 각 모달리티를 고려한 확률이라고 볼 수 있는거죠.
수식 4를 일반화하여 정리하면 아래 수식 5와 같이 정리됩니다.
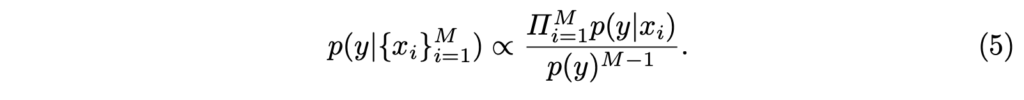
연산을 쉽게 적용하기 위해서 아래와 같이log를 적용하여 합 연산을 이용합니다.
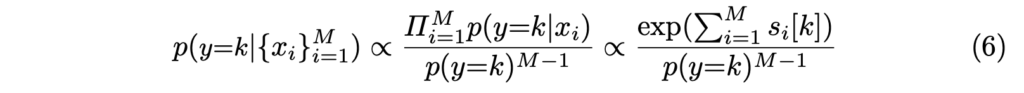
+ 여기서 p(y)는 표본(=배치)을 이용하여 y가 될 확률을 구합니다. (저자는 배치에서 예측된 모든 확률을 곱하는 방식(log->합)을 이용합니다.)
Bounding Box Fusion. 저자는 추가로 모달리티 별로 예측된 바운딩 박스을 퓨전하는 방법도 제안합니다. 허나, 바운딩 박스에는 따로 확률값이 없기 때문에 어떤 예측값이 신뢰도가 높은 결과인지 판단하기가 어렵습니다. 이러한 문제 때문에 저자는 이전 연구 (Gaussian negative log likelihood (GNLL))를 기반으로 트릭을 적용합니다.
GNLL에서는 각 바운딩 박스에 대한 offset만 예측하는 것이 아니라, 불확신성 \mu, \sigma 를 예측합니다. 해당 예측값을 기반으로 수식 4를 적용하여 아래의 수식처럼 바운딩 박스의 불확신성에 대한 확률을 퓨전하는 방법을 제안합니다.
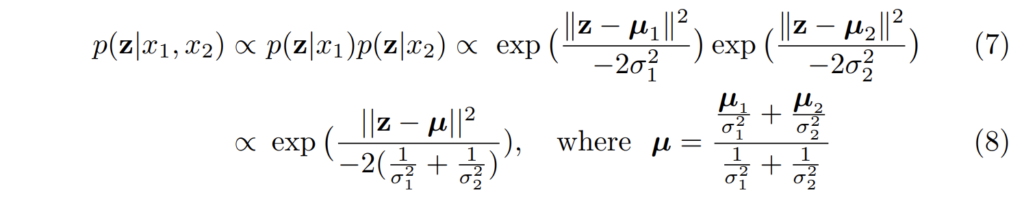
Experiment
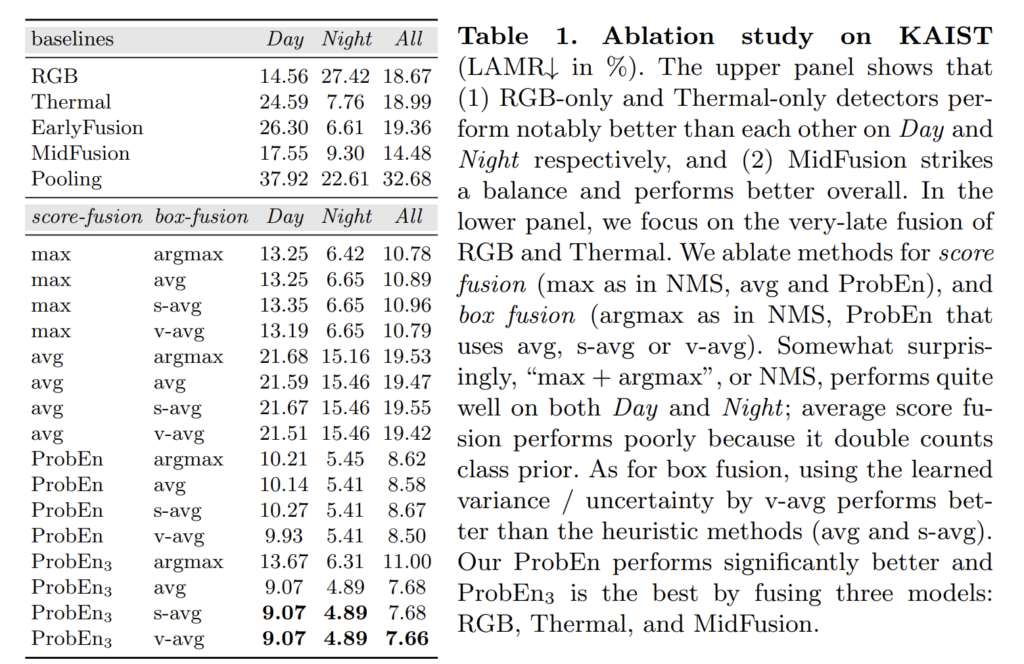
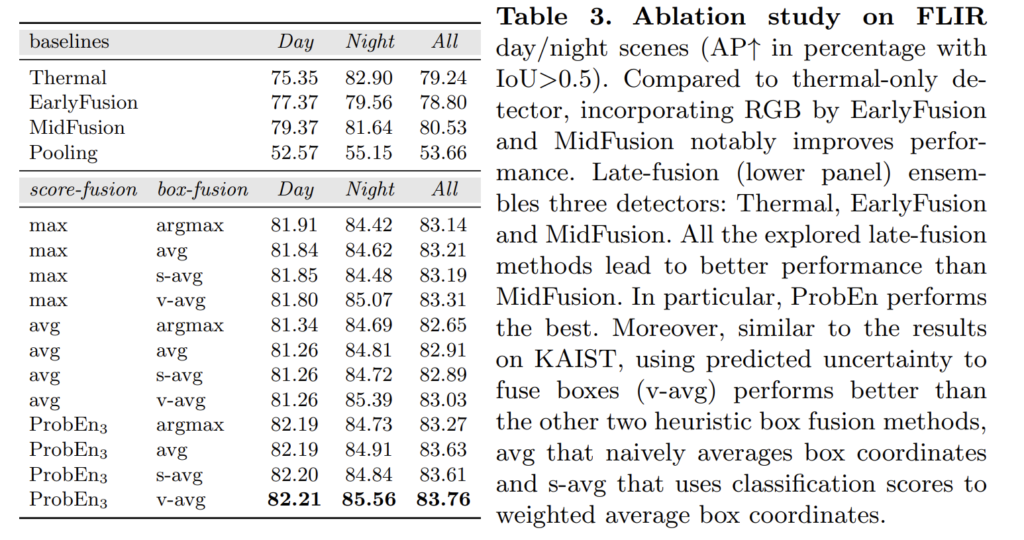
Tab 1의 s-avg는 스코어를 기반으로 바운딩 박스의 불확실성 확률로 사용한 경우이며, v-avg는 GNLL을 이용한 경우입니다.
Tab 1이 정말 놀라운게 위 실험 중 ProbEn은 RGB: 18.67, Thermal:18.99 결과만을 이용하여 실험한 결과에 해당합니다. late-fusion만을 이용해서 진행한 실험만으로 최초 8.50을 찍은 것도 놀랍지만, 단순하게 max-argmax만 이용한 경우에서도 10.78 찍은 건 진짜 놀라운 결과입니다. ProbEn_3 는 MidFusion: 14.48도 함께 퓨전한 경우로 7.66으로 이미 MLPD를 넘은 성능을 보여줍니다… ㄷㄷ
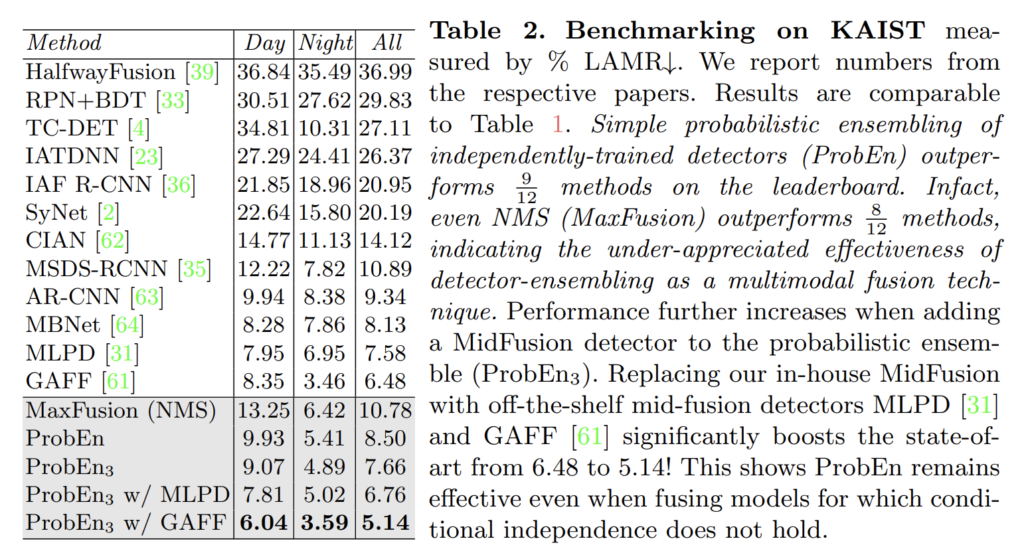
저자는 추가로 단순한 MidFusion이 아닌 MidFusion 기반의 SOTA 모델 MLPD, GAFF를 추가하여 실험을 진행하였고 최대 5.14라는 성능을 보여줍니다.
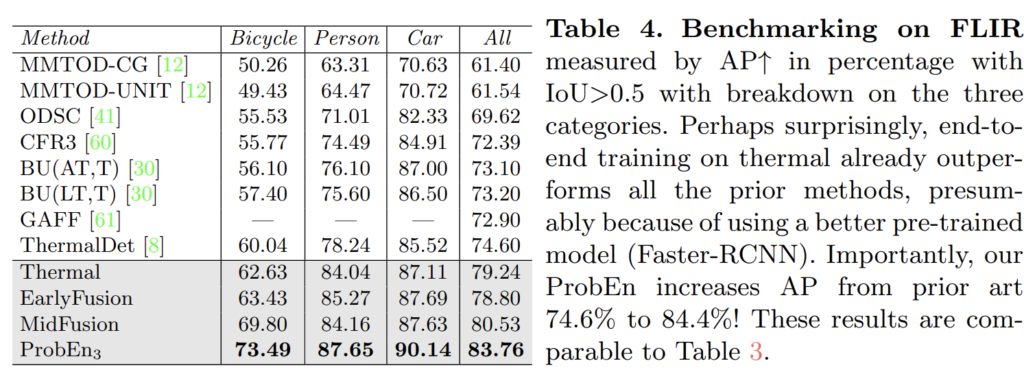
마지막으로 미정렬 이슈가 큰 FLIR에서도 높은 성능을 보여주는 결과를 보여줍니다.
[1] Kim, Jiwon, et al. “MLPD: multi-label pedestrian detector in multispectral domain.” IEEE Robotics and Automation Letters 6.4 (2021): 7846-7853.
[2] Zhang, Lu, et al. “Weakly aligned cross-modal learning for multispectral pedestrian detection.” Proceedings of the IEEE/CVF international conference on computer vision. 2019.
해당 논문은 멀티스펙트럴 검출기 연구의 새로운 방향성을 제시한 방법론입니다. 다른 면으로는 태스크가 포화되었다고 판단했는데 아직도 두 특성을 제대로 고려하지 못했다는 판단도 들긴 합니다. 또한 멀티스펙트럴 검출기 이외에도 센서 퓨전 기반의 방법론의 방향성을 제시한 방법론으로 보이기도 합니다.
리뷰 잘 읽었습니다.
본 논문에서 말하고 있는 멀티모달에서의 미정렬 문제라는 것이 RGB-Thermal 에서 각 영상이 데이터셋 취득 당시 하드웨어적인 이슈로 정확히 같은 영역을 포착하는 것이 아닌 살짝의 차이가 있는(=misalignment) 것을 뜻하는 단어가 맞나요??
넵 맞습니다.
안녕하세요. 좋은 리뷰 감사합니다.
해당 논문은 제가 다음 번에 MS-DETR 후에 읽을 논문 리스트였는데.. 이미 연구원님께서 두 논문 다 리뷰해주셔서 큰 도움이 될 것 같습니다.
논문을 읽다보니 결국 ProbEN에서 핵심적인 내용을 잡자면 각 모달리티의 bbox, classification score 확률을 토대 공통적인 NMS를 진행한다고 되어있는데, 이것이 모달리티의 특성을 잘 살리기 위함인 것은 어느정도 납득이 되나, 말씀해주신바와 같이 저조도 환경에서는 밤에서의 RGB 영상을 입력으로 받는 모델의 성능이 낮은데, 그렇다고 해당 모델에서 classification score도 낮다는 것이 보장이 될때만 가능한 방법이 아닌가하는 의문도 듭니다. 분명 Thermal input based model에 비해서는 확률이 낮을 것이지만, 그것이 잘 걸러질 수 있을까하는 생각이 들기 때문인데, 그래도 첫 줄에 작성해주신 바와 같이 방법론이 새롭고 참신해야만 좋은 논문이 되는 것 같습니다.
좋은 리뷰 감사합니다!
‘저조도 환경에서는 밤에서의 RGB 영상을 입력으로 받는 모델의 성능이 낮은데, 그렇다고 해당 모델에서 classification score도 낮다는 것이 보장이 될때만 가능한 방법이 아닌가하는 의문도 듭니다. ‘ 라는 포인트에 대해 제 생각을 전달해드리자면,
저조도 환경에서는 밤에서의 RGB 영상에서 높은 classification score이 발생할 가능성이 있으나, 저조도로 인한 형태의 불분명 혹은 학습 시, 발생하는 오검출 케이스에 대한 예민성으로 인해 높은 classification score는 예외 케이스일 가능성이 높다고 봅니다.
좋은 리뷰 감사합니다.
late fusion으로 bbox fusion과 probabilistiic ensembling을 통해 좋은 성능을 보인것이 놀랍네요
간단한 질문인데 두 모달리티 간 미정렬 문제를 해결하고자 했다는 부분에서 미정렬이라는 것이 두 모달리티 간 촬영된 위치에 따른 차이인지, 아니면 아래 설명하신 내용을 보면 모달리티 영상을 의도적으로 움직여 미정렬을 모사했다고 하여 blur같은 형태를 말씀하는 것인지 궁금합니다!
감사합니다.
– ‘간단한 질문인데 두 모달리티 간 미정렬 문제를 해결하고자 했다는 부분에서 미정렬이라는 것이 두 모달리티 간 촬영된 위치에 따른 차이인지, 아니면 아래 설명하신 내용을 보면 모달리티 영상을 의도적으로 움직여 미정렬을 모사했다고 하여 blur같은 형태를 말씀하는 것인지 궁금합니다! ‘
->
질문의 의도가 무엇인지 파악하지 못하겠습니다. 어느 부분에서 언급한 미정렬 문제인지 알려주시면 답변에 용이할 것 같습니다.
추측으로 답변을 해보자면, 해결하고자 한 미정렬 이슈는 KAIST PD 셋(약간의 미정렬)과 FLIR(평행한 시스템 구조로 인한 미정렬) 모두 포함합니다.
미정렬을 모사한 실험은 미정렬 강인성을 보이기 위해 AR-CNN에서 처음 진행한 실험으로 한 모달리티의 영상 픽셀을 조금씩 밀어서 미정렬을 모사한 데이터 셋입니다.
– ‘간단한 질문인데 두 모달리티 간 미정렬 문제를 해결하고자 했다는 부분에서 미정렬이라는 것이 두 모달리티 간 촬영된 위치에 따른 차이인지, 아니면 아래 설명하신 내용을 보면 모달리티 영상을 의도적으로 움직여 미정렬을 모사했다고 하여 blur같은 형태를 말씀하는 것인지 궁금합니다! ‘
->
질문의 의도가 무엇인지 파악하지 못하겠습니다. 어느 부분에서 언급한 미정렬 문제인지 알려주시면 답변에 용이할 것 같습니다.
추측으로 답변을 해보자면, 해결하고자 한 미정렬 이슈는 KAIST PD 셋(약간의 미정렬)과 FLIR(평행한 시스템 구조로 인한 미정렬) 모두 포함합니다.
미정렬을 모사한 실험은 미정렬 강인성을 보이기 위해 AR-CNN에서 처음 진행한 실험으로 한 모달리티의 영상 픽셀을 조금씩 밀어서 미정렬을 모사한 데이터 셋입니다.
안녕하세요. 좋은 리뷰 감사합니다!
URP 과정에서 해당 논문의 확률 기반 앙상블 식이 잘 이해가 되지 않았는데, 리뷰를 보니 조금 이해가 되는 것 같습니다.
해당 논문에서 [0.7, 0.8]과 같이 각 논문이 높은 confidence로 예측을 수행하면, 앙상블 결과가 약 0.9로 더욱 강한 confidence를 내는 것을 보였는데, 제 의문은 각 모델이 [0.3, 0.4]와 같이 0.5 미만의 낮은 confidence를 가지면 오히려 fused score가 낮아지는 문제가 있다는 점 입니다.
실제로 제가 해당 식을 구현하여 KAIST PD 문제에 적용하였을 때, confidence가 낮은 예측들이 앙상블을 거치며 threshold 미만으로 confidence score가 하락하면서 정확도가 낮아져 최종 발표에 사용하지 못하였는데, 혹시 이런 문제는 어떤 방향으로 접근하여 해결해야 할지, 혹시 논문에 이 부분에 대한 언급이 있는지 궁굼합니다!
감사합니다.
좋은 질문 감사합니다.
근데 질문에 답변을 드리기 앞서서 먼저 확인해야하는 내용이 있는 것 같네요. 논문에서 제안한 수식을 지오님께서 구현한 코드가 제대로 구현되었는지에 대한 여부를 먼저 확인해보는 것이 우선인 것 같습니다.
코드 공유해주시면 확인해보겠습니다.