제가 이번에 리뷰할 논문도 위치인식 task에 transformer를 이용한 방법론 입니다.
Abstract
위치인식 태스크는 복잡한 도로 장면을 방해하는 요소들(하늘, 땅, textureless의 벽, 자동차, 사람 등)로 인해 오차가 발생합니다. 따라서 저자들은 정확한 위치인식을 위해 관련있는 영역의 정보만을 통합하여 활용하는 것이 중요다하고 하며, 이를 위해 TransVPR이라는 vision transformer기반의 위치인식 모델을 제안하였습니다. TransVPR은 transformer의 특징을 이용한 것으로, transformer의 여러 레벨에 대한 attention을 통해 여러 영역에 집중할 수 있고, 이를 결합하여 global한 이미지 representation을 만들어냅니다. 또한, transformer로부터 출력된 토큰은 key patch로 여겨져 re-rank에 사용됩니다. 이러한 TransVPR은 end-to-end로 학습이 되며 여러 벤치마크에 SOTA를 달성하였다고 합니다.
Introduction
우선 Visual Palce Recognition(VPR)은 일반적으로 이미지 retrieval을 이용합니다. 위치를 알고자하는 쿼리 이미지와 GPS 정보가 있는 데이터베이스 이미지의 유사도를 측정하여 유사한 영상으로부터 쿼리영상의 위치를 알아내는 방식입니다. 이때 VPR에서 사용되는 이미지 representation은 (1)global image feature(이미지를 전체적인 정보를 압축하여 특징벡터로 추상화 한 것으로, 전체에 대한 벡터정보이다보니 기하학적 정보를 담지 못함.)와 (2)patch-level descriptor(local 정보.패치에 대한 설명자로, 매칭 알고리즘을 통해 이미지 쌍 사이의 공간적 매칭이 가능. )로 일반적으로 global feature를 이용하여 retrieval을 수행한 후, patch-level descriptor를 이용하여 re-ranking을 하는 것이 일반적이라합니다. 최근 연구 중 Patch-NetVLAD라는 방법론이 존재하는데, 이는 global feature와 patch-level descriptor를 융합할 수 있는 방법론으로, 여러 밴치마크에 대해 SOTA를 달성하였습니다. 그러나 Patch-NetVLAD는 모든 영역을 인코딩하므로, 유의미하지 못한 영역(하늘, 땅, textureless의 벽, 자동차, 사람 등)의 정보가 포함되어 견고성이 떨어지는 문제가 있다고 합니다. 저자들은 관련이 있는 영역만을 식별하여 선택적으로 정보를 인코딩하는 것이 중요하다고 주장하며 비전 분야에서 활발하게 연구가 되고있으며 좋은 성능을 보여주는 transformer를 도입하여 transformer의 장점을 이용하고자 하였습니다. transformer는 self-attention 연산을 통해 global한 정보를 동적으로 모으고 유의미한 정보를 선택할 수 있다고합니다. 이렇듯 transformer를 적용하여 제안한 TransVRP는 다음의 contribution을 가집니다.
- transformer 기반의 네트워크인 TransVPR를 제안하여 적응적으로 구분력 있는 이미지 representation을 추출.
- 의미적으로 서로 다른 영역에 집중하는 multi-level attention을 융합하여 이미지의 representation 강화.
- 기하학적 검증을 위해 transformer의 마지막 레이어에서 출력된 토큰을 patch-level descriptor로 사용.
Method
TransVPR은 vision transformer로부터 patch-level과 global representation을 함께 추출하는 방식입니다. 과정을 먼저 설명드리면 입력 이미지는 얕은 CNN을 통과하여 얻은 feature를 transformer의 입력 토큰으로 사용합니다. multi-layer의 attention을 병합하여 global feature를 생성하고 유의미한 패치를 감지합니다.
1. Patch Descriptor Extraction
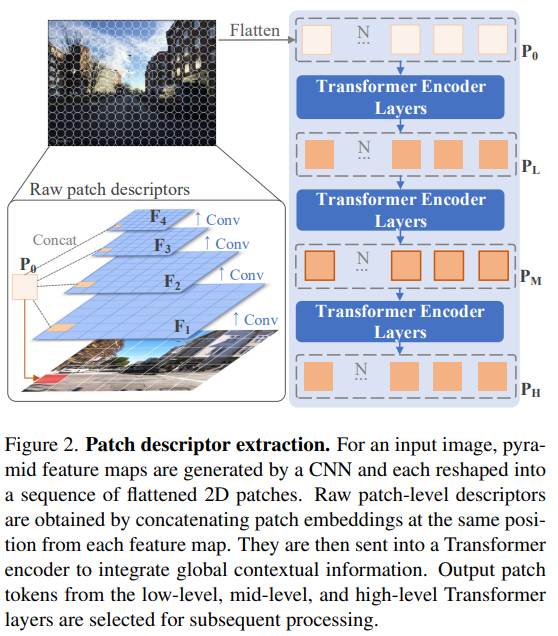
위의 [Figure 2]와 같이 입력 이미지에 4 layer의 CNN을 적용하여 patch-level features를 추출합니다. 식으로 표현하면 아래와 같고, 이때 Conv는 3×3커널을 사용하며 채널수는 {64,128,256,512}가 되도록 하는 feature map { \mathbf{F_1},\mathbf{F_2},\mathbf{F_3},\mathbf{F_4} }를 구합니다.
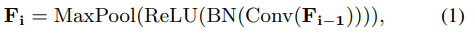
이후 각 feature map에 패치 임베딩을 적용합니다. 각 featuer \mathbf{F_i}∈\mathbb{R}^{H_i⨉W_i⨉C_i}는 2D로 flatten \mathbf{F'_i}∈\mathbb{R}^{N⨉(R^2_i·C_i)} 됩니다. 이때 (R_i,R_i)는 feature map 패치의 해상도이며, 패치의 수는 N=H_iW_i/R^2_i이 됩니다. 패치의 수를 유지하기 위해 R_i=R_{i-1}/2로 정해졌으며, flatten된 patch는 다른 level의 patch들과 concat되어 raw patch descriptor \mathbf{P_0}∈\mathbb{R}^{N⨉D}가 되어 transformer에 입력으로 들어갑니다.
이후 global 정보를 통합하기 위해 raw patch descritpor는 class 토큰과 합쳐져 Transformer의 인코더로 들어갑니다. 이때 positional encoding을 수행하지 않는데, 이는 CNN을 통과하며 공간 위치정보가 암시적으로 인코딩 될 수 있으며, 조금 더 유연하게 공간 정보를 활용하고자 이를 이용하지 않았다고 합니다.
2. Multi-Level Attention
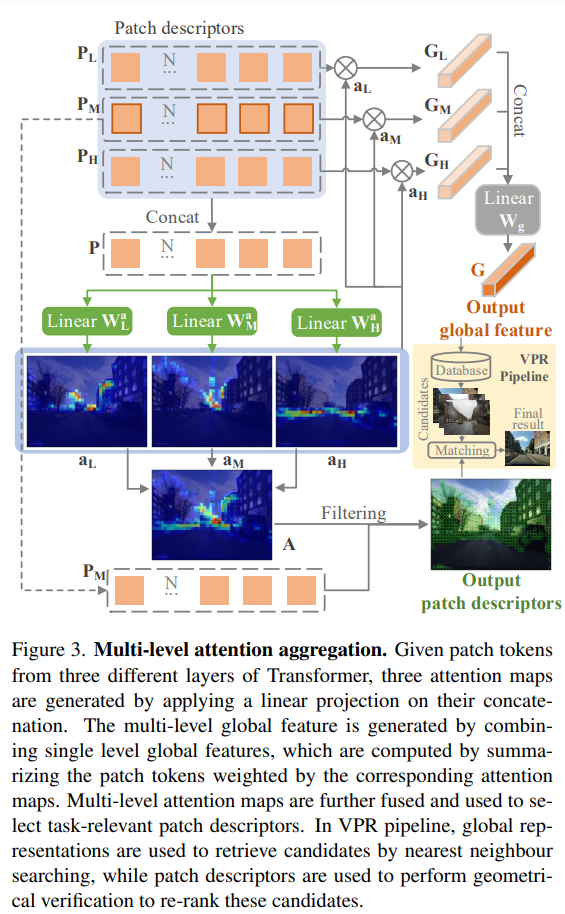
transformer는 layer가 깊어질 수록 attention 거리가 증가하여 전체 영역을 인식할 수 있어진다고 합니다. 즉, layer마다 포착하는 스케일이 달라지기 때문에 여러 level의 레이어를 통합하고자 row/middle/high-level 3개 레이어의 출력 패치를 이용하였다고 합니다. 각 레이어로부터 나온 토큰은 \{ \mathbf{P_L,P_M,P_H} \}로 표현할 때, 그룹 토큰 \mathbf{P} 는 아래의 식으로 구해진다고 합니다.
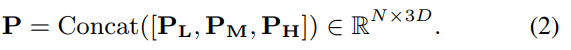
각 레벨마다 attention mask가 예측되며, 이는 각 토큰에 인코딩된 정보가 장소 인식에 중요한지를 나타냅니다. attention mask는 아래의 식으로 구할 수 있으며, 여기서 i=\{L,M,H\}가 됩니다.
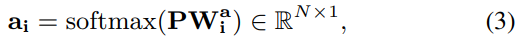
이후 3개의 attention map을 아래의 식(4)의 방식으로 합쳐 하나의 multi-level attention map을 생성합니다.
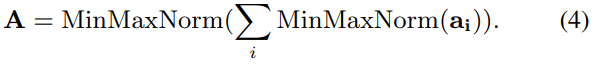
3. Final Image Representation
Key-Patch Descriptor
모든 레벨의 토큰 패치를 descriptor로 이용하는 것이 가능하지만, 실험적으로 middle-level의 패치(\mathbf{P_M})이 안정적인 결과를 나타내어 \mathbf{P_M}를 이용하였다고 합니다. key-patch는 attention 스코어 \mathbf{A}가 임계치인 \tau보다 큰 경우로 정의되며 이를 이용하여 기하학적 검증을 하게 됩니다.
Global Image Features
위의 [Figure 3]에서 확인할 수 있듯이 각 레벨의 global feature \mathbf{G_i}는 각 레벨의 패치 토큰 \mathbf{P_i}에 해당하는 가중치\mathbf{a_i}를 부여하여 계산됩니다. 최종적으로 global image representation은 아래의 식(6)의 후처리를 통해 얻어집니다. 이때 \mathbf{W_g}는 차원을 줄일 때 사용할 수 있는 학습 가능한 matrix입니다.
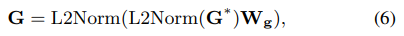
Training
학습에 사용한 loss는 triplet margin loss로, 위치인식에서도 많이 사용되는 loss입니다.
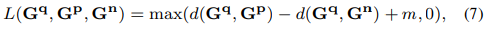
위의 식에 달린 윗첨자 q는 query, p는 positive, n은 negative로, query와 positive의 거리는 가까워지고, query와 negative의 거리는 멀어지도록 학습하며, m은 사전에 정의된 margin을 나타내는 상수입니다.
Experiments
Dataset
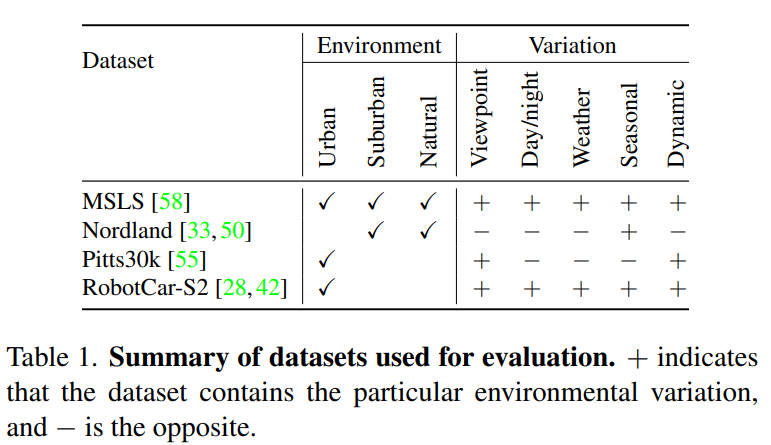
공개 데이터셋(MSLS, Nordland, Pitts30k, RobotCar Seasons v2)을 이용하여 학습 및 평가를 진행하였다고 합니다. MSLS의 train set을 이용하여 학습한 뒤 MSLS 및 Nordland에 대하여 평가를 하였고, Pitts30K의 train set으로 학습한 뒤에는 Pitts30k, RobotCar Seasons v2로 평가하였다고 합니다. 이때 MSLS 학습 데이터는 GPS 정보와 나침반 각도도 제공되어 positive 샘플이 query와 가장 유사한 시야를 가진 이미지로 학습이 되고, Pitts30k는 각도 정보가 제공되지 않아 weakly supervised positive mining 방식(netvlad에서 제안된 방식으로, 정확한 하나의 positive가 아닌, 여러 positive 후보를 가져와 쿼리의 representation과 가장 가까운 이미지를 positive로 함)을 이용하였다고 합니다. 아래의 표는 데이터셋에 대한 정보를 표로 정리한 것입니다.
성능은 위치인식에서 가장 많이 사용되는 NetVLAD와 SFRS, 그리고 global한 정보와 local한 정보를 2-stage 방식으로 이용하는 위치인식 SOTA 방법론들(Patch-NetVLAD, DELG, SP-SuperGlue)과 비교하였다고 합니다.(여기서 intro에서 언급한 Patch-NetVLAD도 포합되었습니다.)
Results
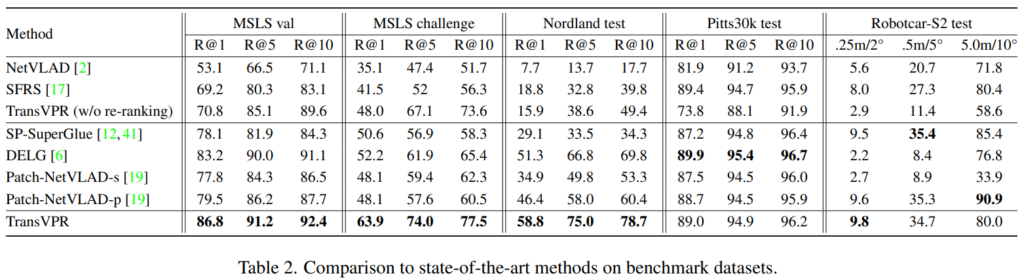
위의 [Table 2]는 TransVPR과 기존 연구들과이 성능 비교 결과로, 대부분의 밴치마크에서 SOTA를 달성하였습니다. 특히 MSLS, MSLS_challenge, Mordland에 대해 두번째로 좋은 성능을 나타내는 DELG와 비교했을 때 Recall@1에 대해 3.6%, 11.7%, 7.5%의 성능 향상을 보여 다른 방법론들과 비교햇을 때 성능이 크게 좋아진 것을 확인할 수 있습니다. Pitts30k와 Robotcar-S2에 대해서는 SOTA보다는 조금 낮지만 경쟁력 있는 성능을 달성하였고, weakly supervised 방식을 이용하였다는 점에서 더 정확한 supervised 방식을 이용한다면 성능 향상이 더 일어날 수 있을 것이라고 주장하였습니다.

위의 [Figure 5]는 challenghe한장면에 대한 결과를 시각화한 것으로, 다른 방법론들은 모두 잘못된 이미지를 반환한 것을 확인할 수 있다. 특히 Ours(TransVPR)은 고유한 영역(변하지 않는, 유의미한 영역)을 기반으로 매칭을 잘 수행할 수 있음을 보였다.
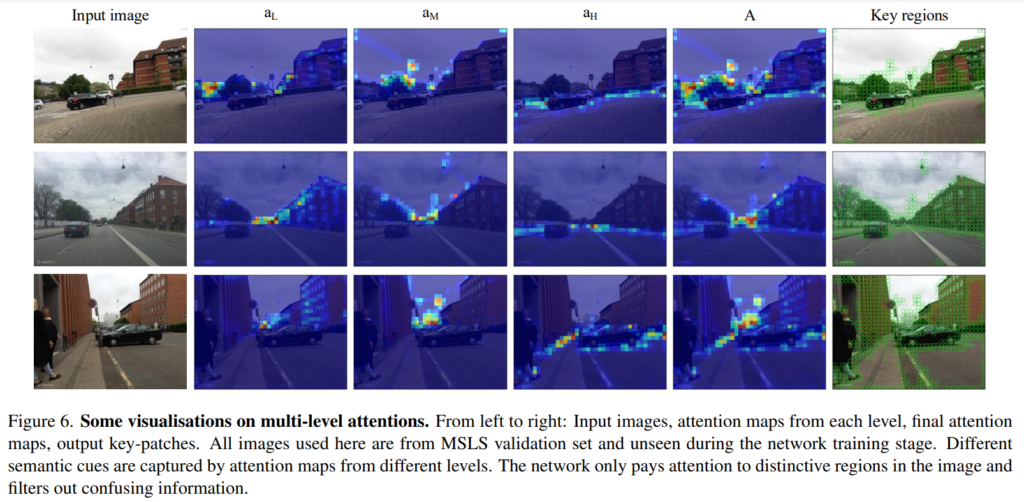
또한, [Figure 6]을 통해 학습된 attention map이 level마다 서로 다른 영역에 집중하고있음을 보였다. low-level은 주로 건물의 표면, 작은 물체와 texture 영역에 집중하며, middle-level은 가로등이나 나무와 같이 공중에 달려있는 물체 등의 영역에 주로 집중하며, high-level은 지면의 윤곽이나 차선의 윤곽선에 집주하고 있는 것을 확인할 수 있습니다. 특히, 모든 level에서 위치 인식을 방해하는 하늘, dynamic object(사람이나 차량), textureless한 벽에는 낮은 스코어가 부여되는 것을 확인할 수 있습니다.
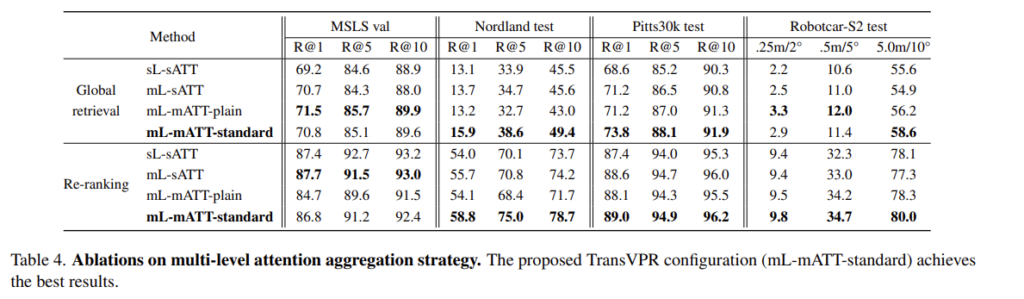
- sL-sATT: single-level & single attention map
- mL-sATT: multi-level & single attention map
- mL-mATT: multi-level & multiple attention maps
을 의미하며, multi-level&multiple attention을 이용하는 것이 가장 좋은 결과를 가져오는 것을 확인하실 수 있습니다.
이번에 리뷰한 논문도 transformer를 활용하여 위치인식을 수행하였습니다. 최근에 리뷰한 논문들을 통해 transforemr를 이용할 경우 attention map을 이용하여 더 유의미한 곳에 집중할 수 있으며, local한 정보 뿐만 아니라 global한 정보도 통합하여 추출할 수 있다는 점이 공통적으로 이야기하는 장점인 것 같습니다. 이상 리뷰를 마치겠습니다.
리뷰 잘 봤습니다.
혹시 마지막 그림에 attention map 을 시각화 하는 방법이나, 코드는 저자가 언급하고 있나요?? 개인적으로 궁금해서 질문 드립니다,,!
그리고 여기서 low-level이 texture 영역에 집중하는건 알겠는데, mid-level 이 공중의 물체에 집중하고 high-level이 윤곽에 집중하는 이유가 무엇인가요??? 뭔가 의미적으로 매치가 잘 되지 않아서 질문 드립니다.
감사합니다.
attention map을 시각화하는 방법이나 코드를 논문이 언급하고 있지는 않습니다. 그러나 논문의 깃허브가 존재하므로 링크를 공유해드리도록 하겠습니다.
https://github.com/RuotongWANG/TransVPR-model-implementation
또한, 두번째 질문은 제가 말을 헷갈리게 작성한 것 같습니다. mid-level은 공중의 물체에 집중, high-level은 윤곽에 집중한다기 보다 mid-level은 일정한 영역을 통해 볼 수 있는 객체(dynamic object가 아닌. 가로등이나 나무, 공중의 객체)를 보고, high-level은 넓은 영역을 볼 수 있어 도로나 건물과 같이 넓은 범위를 인지해야 알 수 있는 윤곽 정보를에 집중할 수 있다는 것으로 이해하시면 될 것 같습니다.
좋은 리뷰 감사합니다.
row/middle/high-level 3개 레이어의 출력 패치를 사용하였다고 했는데, 실험 결과로 row, middle, high-level 단독으로 사용했을 때, 혹은 두가지를 섞어 사용했을 때의 성능은 리포팅이 되어있을까요? (시각화 한 것을 보면 굳이 성능 리포트를 안한거 같기는 한데 궁금해서 여쭤봅니다)
또한 transformer layer를 더 통과할 수록 global한 정보를 더 가지고 있을 것이라 생각하는데 그래서 시각화를 보면 점점 attention 하는 것이 넓어지는 것을 확인할 수 있는데 왜 middle-level이 공중에 달려있는 물체 등의 영역에 주로 집중하고, high-level은 지면의 윤곽이나 차선의 윤곽선에 집중하는 이유가 궁금합니다.
우선 제가 리뷰에 작성하지 않았지만 논문에 single-level과 multi-level에 대한 ablation study는 존재합니다. 그러나 논문과 supplemental을 확인해보았을 때 각각에 대한 비교 실험을 리포팅하지는 않을 것 같습니다.
또한, 이 질문도 위의 석준님의 질문과 동일한 질문인 것 같습니다. middle이 공중에 달린 물체 영역에 집중하기보다 나무, 가로등, 공중에 달린 물체 영역 등 객체를 인지하는 것으로 이해하시는 게 더 적절한 것 같습니다. 또한, high-level은 도로와 건물 등 넖은 영역을 보고 파악해야하는 윤곽선 등에 집중하는 것으로 이해하시면 될 것 같습니다. 다음에는 말을 더 명확하게 작성하도록 하겠습니다.?
이승현 연구원님 좋은 리뷰 감사합니다.
실험 결과를 보다 한가지 궁금한게 있는데 질문드리겠습니다!
global feature와 patch-level descriptor(local) 두 가지를 이용한다고 하셨는데,
혹시 각각의 요소에 대한 실험 결과는 없을까요?
VPR 태스크는 1) global feature를 통해 전체 DB 영상들과 비교하여 candidate를 찾고, 2)patch-level descriptor를 이용하여 candidate에 대해 re-ranking을 수행합니다. 전체 영상에 대한 retrieval과 re-ranking에 대한 성능 리포팅 결과를 제가 제외하고 작성하였는데 업데이트해두었습니다. 실험파트의 Table 4를 확인해주시면 감사하겠습니다. 다만 비교 결과가 다른 SOTA방법론들과의 비교가 아닙니다..