목적:
instance leverl의 uncertainty를 측정하여 object detector를 학습하기 위한 정보가 가장 많은 이미지를 선택하는 모듈, Multiple Instance Active Object Detecion (MI-AOD) 제안.
간단한 원리 소개:
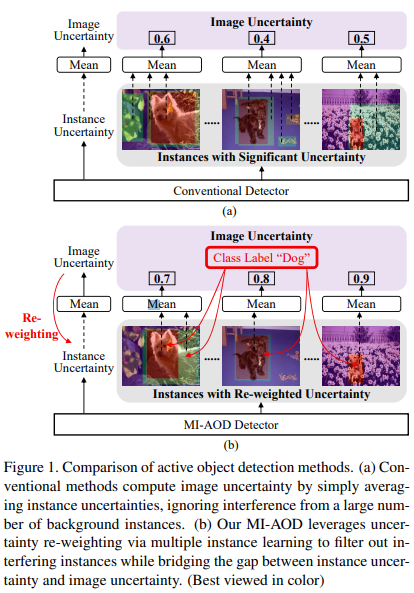
MI-AOD는 하나의 unlabeled image를 instance bag으로 하며 image에 속한 feature anchor를 instance로 취급함. 최종적인 image의 uncertainty는 instance re-weighting을 통해 noisy instance에 대핸 중요도를 줄임으로서 image level uncertainty와 실질적인 instance uncertainty의 gap을 줄임(Figure 1 참조). Figure 1에서 알 수 있듯이 기존 방법론(a)의 경우 모든 instance에 대한 평균이 이미지의 uncertainty라면, 제안하는 방법론을 통해 이미지에 해당하는 instance에 가중치를 주어 uncertainty를 계산함으로서 더 효과적인 이미지 데이터 가치판단이 가능함.
Proposed method의 설명:
데이터의 가치를 인공지능 모델이 직접 판단하여 학습의 효율성을 극대화하는 active learning과 active object detection 문제를 해결하기 위해서는 두가지 문제를 해결해야한다.
(a) labeled sets으로 학습된 detector를 어떻게 이용하여 unlabeled instances의 uncertainty를 측정할 것인가?
(b) 어떻게 image에 속한 noisy를 제거하고 해당 image의 uncertainty를 정확하게 추정할 것인가?
MI-AOD는 위 두 문제에 대해 다음과 같이 해결했다.
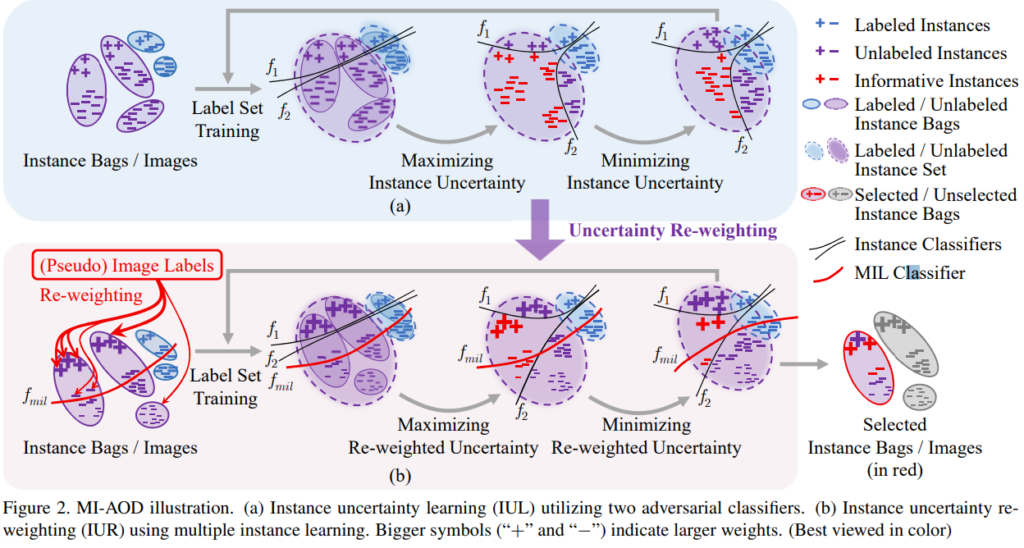
첫번째 문제를 위해 MI-AOD는 instance uncertainty learnings을 통합했다. Figure 2(a) 와 같이 해당 과정을 통해 labeled set과 unlabeled set이 aligning 되었다. 두 번째 문제를 위해 MI-AOD는 MIL을 labeled 와 unlabeled set에서 instance re-weighting을 통해 uncertainty를 추정하는 과정에 도입했다. 이 re-weighting은 지도학습 기반의 image classification loss를 통해 진행되었다.
제안하는 아키텍쳐는 크게 두가지 단계로 개발되었는데 instance uncertainty learning(IUL)와 instance uncertainty re-weighting(IUR)이다. 두 모듈의 기본적인 학습과정은 이미 앞서 언급된 Figure 2의 (a)과 같으며 labeled data로 초기화 후, uncertanty 가 높은 데이터가 많아지도록 경계를 학습하고 이후 uncertanty data가 적어지도록 안정화하는 과정을 거친다.
IUL:
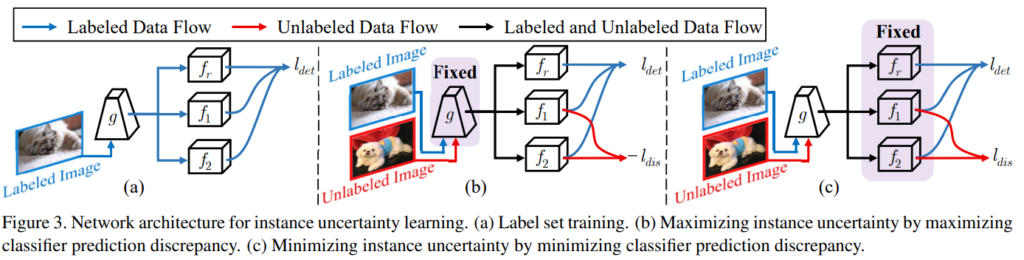
먼저 instance의 uncertainty를 학습하기 위해 Labeled set을 통한 모델 학습과정을 거친다. 학습을 위해 두개의 classifiers(f1, f2)와 하나의 bounding box regressor(fr)를 갖는데 FIgure3의 (a)에 해당한다. g는 feature extractor이며 이에 대한 학습 loss는 focal loss로 구성된다.
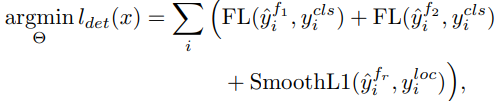
이후 instance uncerainty를 maximizing 한다. 이때 uncertainty를 의도적으로 조정하는 과정에서 backbone에 대한 잘못된 학습을 유도할 수 있기 때문에 extractor인 g는 freeze 한다. 이후 두 classifier의 출력값이 차이가 최대화되도록 loss를 구성하여 학습한다.
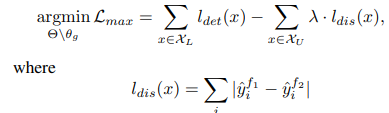
마지막으로 uncertainty 간극을 안정화하는데 이때는 앞서 추가한 L_dis loss가 다시 최소화되어 두 classifier의 예측값이 같아지도록 한다. 이는 직관적으로 정상적인 모델 학습 방법이므로 다시 extractor g를 학습하도록 freeze를 해제한다.
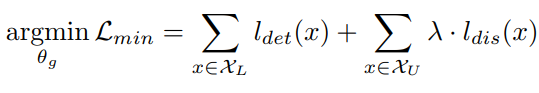
IUR:
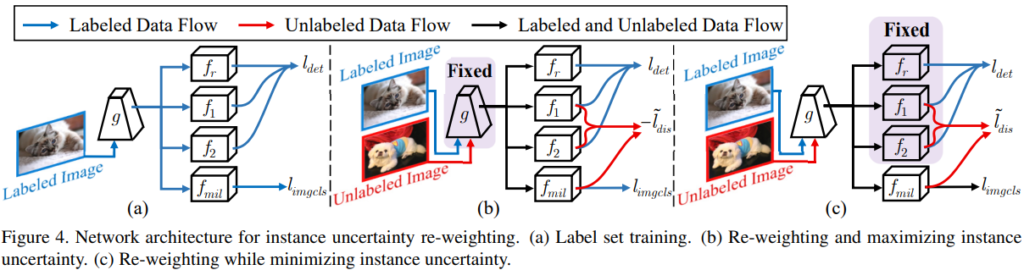
단순히 이미지 uncertainty가 높다고 유용한 데이터가 아닐 수 있다. 즉 단순히 background noise로 구성된 이미지여서 uncertainty가 높을 수 있다는 소리다. 본 논문은 이러한 상황에서 instance에 대한 가중치 조정을 통해 실제 이미지의 uncertainty가 높은 고가치 데이터인지, 혹은 단순히 background noise로 구성된 데이터인지 구분하고자 하였다. 이를 위해 논문이 제안한 해법은 Multiple Instance Learning(MIL)이다. 전체적인 학습과정은 위의 IUL에 따르지만 하나의 classifier, f_mil이 더 추가되었다. MIL은 re-weights를 위해 classification loss를 이용한다. 이때 사용되는 loss는 아래와 같다.
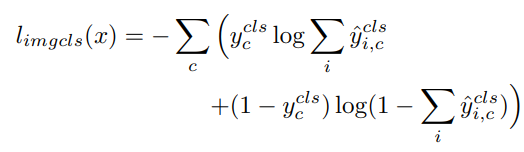
이때, multiple instance를 갖는 이미지에 대한 class score인 y는 다음과 같이 계산된다.
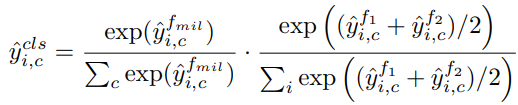
실험결과:
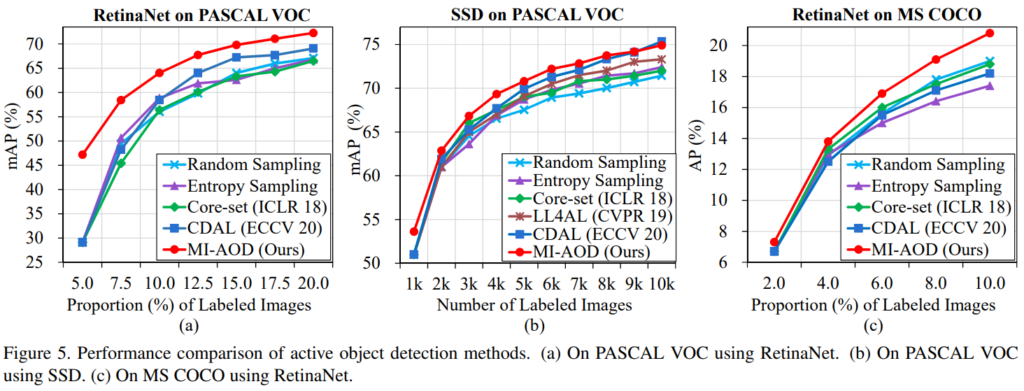
실험은 PASCAL VOC 2007과 2012 데이터셋, MS COCO 에 대해 진행되었다. RetinaNet(ResNet-50)과 SSD(VGG-16) 모델을 통해 object detection을 진행하였으며 매 사이클마다 unlabeled data의 2.5%를 추가하였으며 training set의 20% 사이즈에 도달 할 때까지 반복했다. 비교된 방법론은 Core-set, LL4AL, CDAL이다. 먼저 PASCAL VOC에 대한 실험은 Figure5와 같은데 제안하는 방법론이 다양한 세팅과 데이터셋에서 비교적 높은 학습 효율을 보임을 알 수 있다. 또한 Challenging dataset이라 평가되는 MS COCO에서도 제안하는 방법론이 기존 방법론대비 높은 학습효율을 보임을 확인할 수 있다.
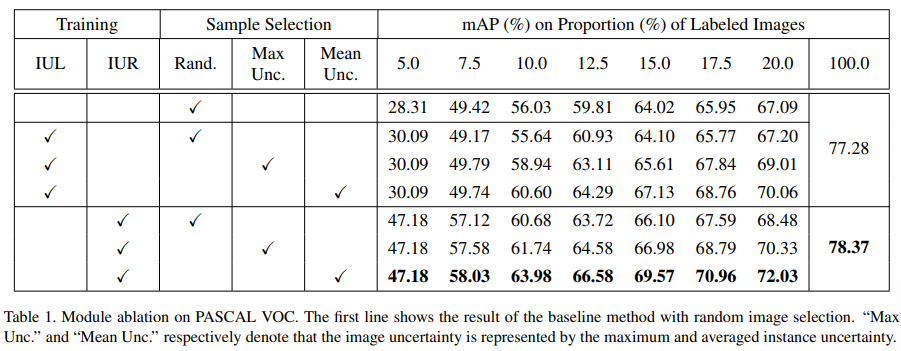
다음은 Ablation Study를 포함한 정량적 성과지표이며 제안하는 instance uncertainty learning(IUL)과 최종적으로 제안하는 instance uncertainty re-weighting(IUR)에 대해 진행하였다. 실험 결과 최종 모듈인 IUR이 가장 좋은 성능을 보임을 알 수 있으며, 이는 아래의 정성적 평가에서도 확인할 수 있다.

Figure 6을 통해 re-weighting을 하여 instance noisy를 제거한 가치판단 과정인 IUR이 각 이미지의 핵심 object에 가장 높은 가중치를 보임을 알 수 있다.
리뷰 잘읽었습니다.
해당 기법은 클래스 스코어만 고려하여 불확신성을 계산하는 건가요?
만약에 그렇다면 bbox의 불확신성을 고려하는 방법론은 아직 없는 건가요?
넵 bounding box의 class score 를 이용합니다. bounding box 에 대한 불확실성을 고려하는 논문은 찾아보고 있는 중입니다 ㅎㅎ
황유진 연구원님 좋은 리뷰 감사합니다.
Active Learning을 Object detection으로 확장한 방법론인 것 같습니다.
그런데 background noise가 어떤 것인지 예시를 알 수 있을까요?
배경임에도 불구하고 object 처럼 잡히는 instance 들이라고 생각하면 될까요?
넵 말씀해주신 상황도 noise instance라고 생각하시면 되구요 의미가 없는 instance box가 다 이에 해당한다고 생각하시면 됩니다