
오늘 리뷰할 논문도 요즘 제가 진행중인 실험과 방향성이 비슷한 논문입니다.
Mutual Learning에 대해 찾아보다가 Knowledge Distillation 까지 확장해서 논문을 물색하던 도중 ‘Cross-Image’ 라는 키워드가 뭔가 흥미로워 보여서 읽게 된 논문입니다.
그럼 리뷰 시작하도록 하겠습니다.
1. Introduction
Computer Vision 분야에서 Semantic Segmentation task는 매우 활발하게 연구가 진행되고 있습니다.
요즘 대표적으로 높은 성능을 달성하는 모델로는 DeepLab, PSPNet, HRNet 과 같은 CNN기반의 모델 뿐 아니라, transformer 구조를 기반으로 한 모델도 많이 존재하죠.
하지만 이렇게 높은 성능을 달성하는 모델들은 computational cost가 매우 비싸다는 치명적 단점이 존재합니다. 그렇기 때문에 real-world나 mobile device에 해당 모델들을 사용하는데에는 한계가 존재하죠.
그래서 최근 연구들은 Knowledge Distillation (이하 KD) 방식을 사용하게 됩니다.
(사실 ‘최근’ 이라고 표현하기엔,,, 몇 년이 지났긴 하죠)
KD 에 대해서 처음 들어보신 신입 연구원분들은 신정민 연구원이 리뷰한 Mutual Learning 의 글 상단에 관련 설명이 있으니 참고 하셔도 좋을 거 같습니다.
(++ 구글에도 많은 자료들이 존재합니다)
그런데 사실 KD Semantic Segmentation 에 적용되기 전 Classification task에서 많이 연구되었던 분야입니다. 학습 기법을 제안하는 논문들은 보통 ImageNet 등의 대표적인 dataset으로 Classification 성능을 벤치마킹 하기 때문입니다.
Classification에 적용되는 기법을 Semantic Segmentation 에 그대로 적용하기엔 근본적인 문제가 존재합니다.
Segmentation은 Classification과 달리 decoder를 통해 구조를 가지는 output이 생성되기 때문에 픽셀들끼리의 correlation과 dependency가 매우 중요하게 됩니다.
사실 위 단락에서 말씀드린 내용은 너무나도 당연한 이야기이고,
이전 연구들에서도 해당 내용을 토대로 해서 픽셀들끼리의 correlation과 dependency를 고려할 수 있는,
Semantic Segmentation에서의 Knowledge Distillation 기법들이 많이 제안되었습니다.
디테일에 따라 조금씩 다르지만 앞선 방법들은 student가 teacher를 닮아가는 방향으로 학습이 진행된다는 공통점을 가지고 있습니다.
단일 image input에 대해 teacher의 예측을 student로 전이하는 방식이고, 사실 해당 내용이 Knowledge Distillation의 핵심적인 모토이죠.
본 논문에서는 기존의 KD 방식들에 공통적인 문제가 있다고 주장합니다.
student가 teacher를 닮아가는(=모방해가는) 과정은 좋은데, 해당 과정이 individual data samples 에 대해서 수행되기 때문에 cross-image 에서의 의미적인 관계를 무시하는 문제가 있다고 합니다.
음.., 직관적으로 잘 와닿지는 않으니 일단 관련된 그림을 한번 살펴보겠습니다.
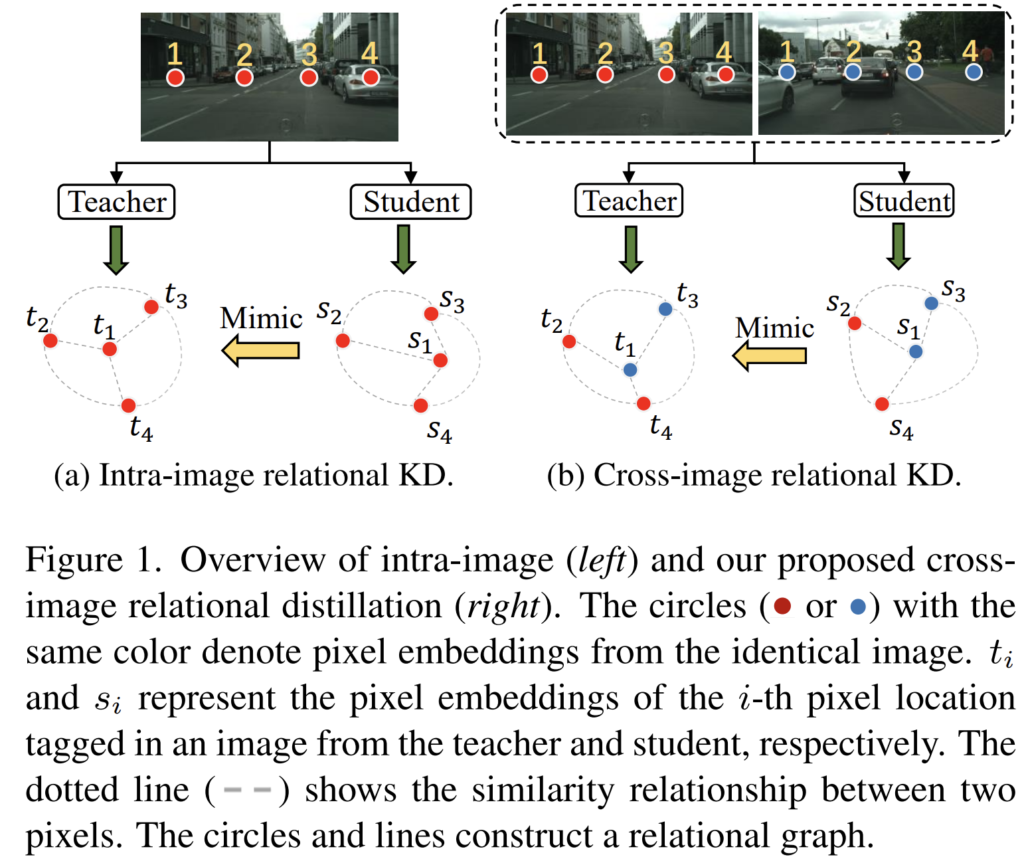
그림 1의 (a)는 기존의 KD 방식이고, (b)는 본 논문에서 주장하는 KD 방식입니다.
(a)에서는 한장의 image에 대해 student가 teacher를 닮아가는 방식으로 학습이 이루어집니다.
student의 s1,s2,s3,s4가 teacher의 t1,t2,t3,t4의 분포를 모방해 나갑니다.
(한장의 image 에 대해 수행되는 것은 위 단락에서 언급한 individual data samples 과 매칭되겠네요.)
그에 반해 (b) 에서는 한장이 아니라 2장의 image에 대해서 pixel의 분포가 고려되고 있습니다.
여기서 핵심은 한장의 image에 대해서가 아니라 여러장(cross-image) 에 대해 고려된다~ 라는 포인트인거 같네요.
우선 이정도로만 짚고 넘어가도록 하겠습니다. 계속해서 비슷한 내용들이 반복될테니 말이죠.
어쨋든 본 논문에서는 이러한 cross-image에서의 semantic 관계를 고려해야 한다는 점을 핵심으로 삼아
Cross-Image Relational Knowledge Distillation (CIRKD) 라는 학습 기법을 주장하게 됩니다.
그리고 해당 기법은 전체 training images에 걸쳐 global pixel relations를 의미있는 정보로 구성합니다.
해당 단락을 통해 본 논문에서 언급하는 여러장(cross-image) 이라는 것이 전체 학습 이미지를 나타내는 것임을 알 수 있네요.
다시 정리하자면 앞선 방식들은 1장의 image에 대한 정보가 teacher->student로 KD 되었다면,
본 논문에서는 1장이 아니라, 여러장(cross-image)에서의 global pixel relation을 담은 정보 또한 KD 된다고 볼 수 있습니다. 이것이 본 논문의 첫 번째 contribution 입니다.
그리고, 다양한 이미지들 사이의 구조화된 관계(structed relation) 를 잘 활용하기 위해
i) pixel-to-pixel distillation
ii) pixel-to-region distillation
을 제안합니다.
i) pixel-to-pixel distillation 는 픽셀 임베딩 간의 유사도 분포를 distillation 하는 것입니다.
쉽게 말해서, 공간적(spatial)인 정보를 고려한 것이 아니라 단순하게 pixel 단위에서 teacher의 예측값을 student에게
distillation하는 것이라고 생각하시면 됩니다. 이렇게 단순 pixel값 전이는 대부분의 KD에서 사용되고 있죠.
그리고 ii) pixel-to-region distillation은 i)을 보완해 줍니다. 단순 pixel값 전이는 공간/영역적인 정보를 고려하지 못하기 때문에 이를 보완하는 것이라고 볼 수 있죠.
공간/영역 임베딩은 동일한 class의 픽셀 임베딩을 average pooling하여 생성되며, 이는 해당 class의 feature-center를 의미합니다.
그리고 pixel-to-region의 관계는 픽셀과 class별 prototypes 간의 상대적 similarity를 나타내게 됩니다.
(해당 부분에 대해 충분한 이해가 부족해서 설명이 부족한 거 같습니다…
아래 method 부분에서 추가적인 설명을 드릴 예정이고, 해당 단락에 대한 논문의 표현도 첨부하겠습니다)
The region embedding is generated by averagely pooling pixel embeddings from the same class and represents that class’s feature center.
The pixel-to-region relations indicate the relative similarities between pixels and class-wise prototypes.
어찌됐건, 위에서 설명드린 2가지의 distillation을 함께 사용하는 것이 두 번째 contribution 입니다.
첫 번째 contribution에서 여러장(cross-image)에서의 global pixel relation을 고려해야 한다고 설명드렸습니다.
학습 과정에서 이러한 cross-image relation을 고려할 수 있는 간단한 방법은 현재의 mini-batch 에서의 이미지들 끼리의 relation을 고려하는 것입니다.
하지만 Segmenation task의 특성 상 memory 문제 때문에 보통은 그렇게 크지 않은 batch size를 사용하게 되고, 충분히 많은 global pixel relation을 고려할 수 없게 됩니다.
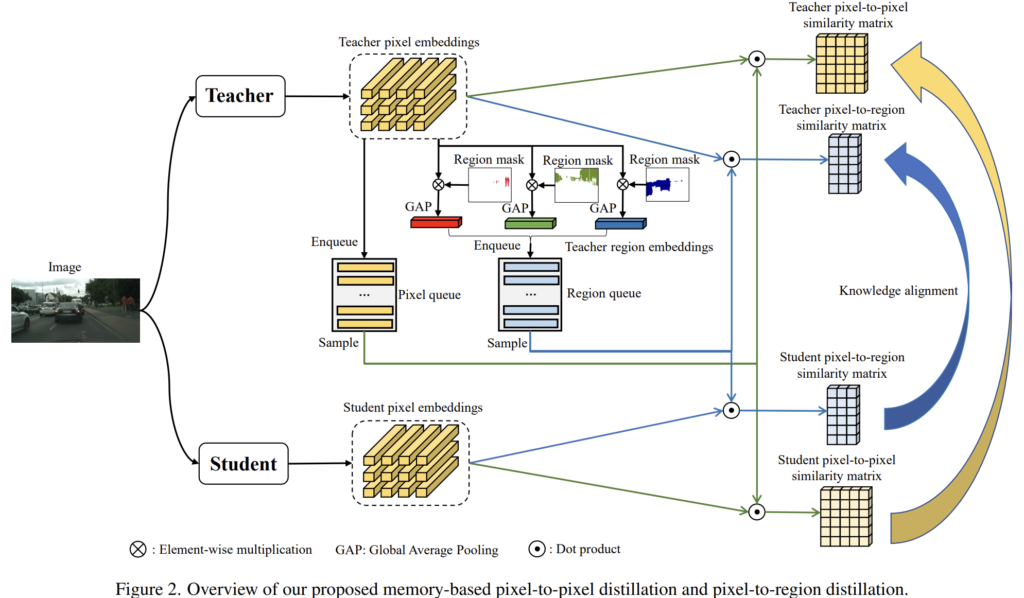
작은 batch size에서도 많은 이미지들의 relation을 고려하고자 본 논문은 기존의 Self-Supervised learning 논문에서 사용하는 방식을 모티브 삼아 memory bank에 pixel queue와 region queue를 도입하여 long-range pixel relation 을 위한 큰 규모의 임베딩을 저장하게 됩니다.
memory bank의 queue 내부에 저장되어 있는 임베딩은 미리 pretrained된 teacher model에 의해 생성되므로 distillation이 진되는 과정에서 변화 없이 동일하게 유지됩니다. 그리고 학습 과정 시 mini-batch의 teacher embedding과 student embedding을 anchor로 간주한 뒤 memory bank의 queue에서 대조적인(contrastive) 임베딩을 무작위로 샘플링해서 pixel-to pixel과 pixel-to-region 의 유사도 분포를 모델링합니다. 그리고 KL-Divergence를 사용해서 student를 teacher의 분포와 유사하게 만들게 됩니다.
본 논문의 contribution은 아래와 같습니다.
- 단일 이미지가 아닌, 여러 이미지들 사이의(cross-image) global 관계를 고려한 Segmentation KD 를 수행하기 위한 Cross-Image Relational Knowledge Distillation (CIRKD) 를 제안.
- memory bank의 pixel queue와 region queue 를 사용한 pixel-to-pixel & pixel-to-region Distillation
- SOTA
음.. Introduction에서 기존 방법론들의 문제 정의와 이를 해결한 본 논문의 방식의 큼직한 contribution을 설명하고,
자세한 내용은 Method 부분에서 식과 함께 설명 드리려고 했는데
본의 아니게 Introduction 내용이 방대해진 거 같네요…
아래에서 설명 드릴 내용과 위의 Introduction 내용과 함께 읽으시면 이해 하는데에 도움이 되리라 생각됩니다.
2. Method
<Preliminary>
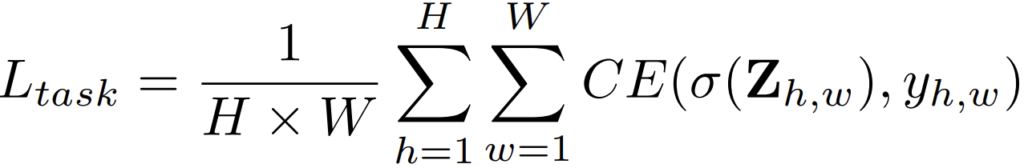
Z_{h,w} 는 모델이 예측한 logit map으로 h*w*c의 shape을 가집니다.
C는 class의 수로, Segmenation의 전체 class 수를 의미합니다.
그리고 y_{h,w}는 gt label, \sigma는 softmax function을 의미합니다.
Segmentation 이라는 것이 결국 pixel단위로 어떤 class인지를 예측(classification) 하는 task이기 때문에
pixel별로 cross-entropy loss를 계산합니다.
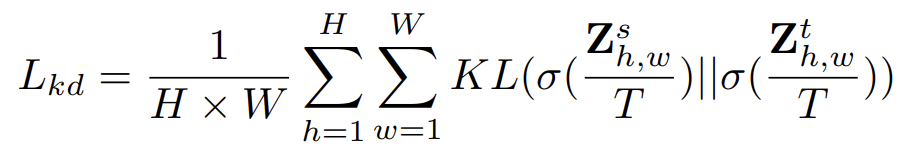
T는 temperature 라고 하는 가중치를 의미하는데, 이전 연구들에서 T=1이 충분히 좋은 값임을 증명해 냈다고 합니다.
그리하여 위 식은 Student와 Teacher가 각각 예측한 logit map의 유사도를 계산하는 loss라고 생각할 수 있습니다.
<Motivation (remind)>
Introduction에서 꽤나 자세하게 설명을 드렸지만 한번 더 본 논문의 motivation에 대해 간략하게 설명 드리겠습니다.
기존의 Segmenation KD 방법론들에서는 cross-entropy loss인 L_{task} 를 사용해서 단순 픽셀값 전이가 이루어 지는 연구들이 대부분이였습니다.
그리하여 spatial relation을 고려한 KD 방식들이 등장을 했고, 본 논문에서도 pixel-to-pixel Distillation 뿐만 아니라 pixel-to-region Distillation를 사용해서 spatial 정보 또한 전이를 해 주는 방식을 사용했지요.
하지만 spatial 정보를 고려하는 다른 KD 방법론들과의 차별점 또한 존재합니다.
앞선 방법론들은 1장의 image에 대해 KD를 수행하지만, 본 논문은 여러장의 cross-image에서의 semantic 정보를 사용해서 global pixel 정보를 고려한것이지요.
(여기서 global은 spatial 공간으로의 global이 아닌, train dataset 전체적인 관점에서의 global로 생각하시면 됩니다)
2.1 Mini-batch-based Pixel-to-Pixel Distillation
학습 시에는 데이터가 mini-batch 별로 들어오게 되겠죠?
이때의 mini batch를 x_n 이라고 하겠습니다. (n=1~N, N=batch size)
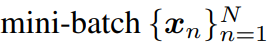
그리고 해당 input을 통해 모델은 feature map인 F_n을 출력합니다.
이때 shape은 H x W x d 가 되고, d는 채널의 수 입니다.
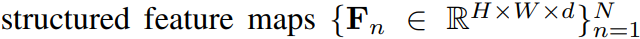
그리고 생성된 feature map F_n 을 channel축을 기준으로 spatial 한 공간 단위로 L2 normalization을 수행해서 pixel embedding을 얻을 수 있습니다.
아래 그림이 pixel embedding의 구조입니다. H x W x d 의 shape을 가집니다.
그리고 이를 vector 형태로 shape을 변경해서 아래처럼 표기를 할 수 있습니다.
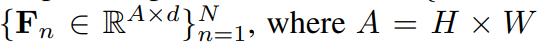
앞서 말씀드렸다시피 본 논문에서는 1장의 이미지가 아니라, 여러 장의 cross-images 에서 semantic 한 정보를 활용한다고 하였습니다. 이를 위해서 본 논문에서는 similarity matrix를 아래와 같은 방식으로 계산하였습니다.
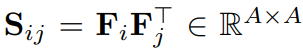
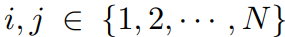
계산된 similarity matrix S_{ij}는 mini-batch N 내의 i번째 pixel embedding과 j번째 pixel embedding의 상관성을 고려해주는, 즉 본 논문의 표현을 빌리자면 global pixel relation을 고려하는 matrix 입니다.
이후, 앞서 preliminary에서 정의한 L_{kd} 를 사용해서 mini-batch에서의 pixel-to-pixel distillation을 수행하는 loss를 설계하였습니다.
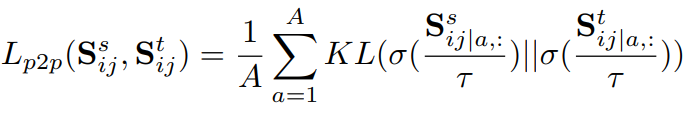
위 식에서 S_{ij|a,:} 는 similarity matrix S_{ij} 의 a-th row vector를 의미합니다.
그리고 S_{ij}위에 첨자? 로 붙은 s와 t는 각각 student, teacher를 의미합니다.
결론적으로, mini-batch에 대해 student와 teacher 모델이 각각 similarity matrix를 계산하고,
이를 row-vector 단위로의 유사도 loss 계산을 통해 student가 teacher의 global pixel relation을 모방해 나가는 것입니다.
위 식 3을 적용한 mini-batch 에서의 loss는 아래와 같습니다.
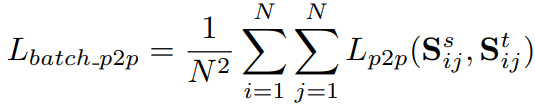
2.2 Memory-based Pixel-to-Pixel Distillation
위 2.1절에서 설명드린 mini-batch based loss도 물론 특정 batch size에 대해 global pixel relation을 잘 포착합니다.
하지만 앞서 말씀드렸다시피 Semantic Segmentation 분야에서는 batch size가 그렇게 크지 않기에 충분한 global pixel 정보를 잘 반영하지는 못합니다.
이를 해결하고자 이전 mini-batches들에서 생성된 대량의 pixel embedding을 memory bank에 저장할 수 있는 온
online pixel queue를 설계합니다.
semantic segmentation 에서는 image에 대해 pixel단위로 dense하게 예측을 진행합니다.
하지만 이미지 내 same object region에 있는 pixel들은 대부분 동일한 class를 가지겠죠.
따라서 이렇게 모든 pixel embedding을 pixel queue에 저장하게 되면 중복되는 정보를 학습하기 때문에 distillation 과정의 속도가 매우 느려지게 됩니다. 또한 마지막 배치 여러 개를 pixel queue에 저장하면 pixel embedding 의 다양성이 부족해지게 됩니다. (dense pixel의 수는 매우 많지만, class의 수는 한정적이므로)
이를 해결하고자 pixel queue에 모든 pixel embedding을 저장하는 것이 아니라, class 별로 N_p개 만큼의 pixel embedding만을 저장하게 됩니다. 만들어지는 class-aware pixel queue의 shape은 아래와 같습니다.
C는 class의 수 입니다.
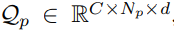
만약 모든 pixel embedding을 저장했다면 shape은 C x A x d 가 되었겠지만, (A = H x W)
class별로 N_p개 만큼의 pixel embedding만을 저장하므로 위와 같은 shape이 되는 것입니다.
class별 N_p개는 mini-batch의 각 image에 대해 random으로 sampling 됩니다.
그렇다면 위에서 설명드린 이 pixel queue를 teacher와 student가 개별적으로 가질까요?
결론부터 말씀드리면 아닙니다.
학습 시 distillation process가 진행될 때 teacher에서 생성된 pixel embeddings 중 일부(N_p)가 랜덤으로 pixel queue에 enqueue 되고, student는 teacher와 해당 queue를 공유합니다.
queue는 distillation 과정 시 “first-in-first-out” 방식으로 update 됩니다.
이제 queue를 통해 어떤식으로 loss가 계산되는지 알아봅시다.
우선 2.1절과 동일한 과정을 통해 teacher와 student 각각 1장의 이미지에 대해
A x d 의 shape을 가지는 pixel embedding이 생성됩니다.
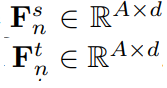
2.1에서는 mini-batch 내에서의 global relation에 집중했다면,
본 절에서는 더 큰 규모인 memory bank에 pixel queue와의 global relation에 대해 집중해야겠죠?
이를 위해 pixel queue Q_p 에서 K_p개 만큼의 contrastive embeddings 인
v_k 을 샘플링하게 됩니다.
이 때 pixel queue Q_p 내에는 d의 길이를 가지는 embedding이 C x N_p 개 만큼 저장이 되어있는데, class의 수를 동일하게(class-balanced) K_p개를 임의로 샘플링한다고 보시면 됩니다.
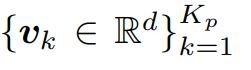
v_k 는 길이가 d인, K_p의 vector 형태입니다.
그리고 이를 matrix 형태로 표현하면 아래와 같습니다.
shape은 K_p x d 의 형태입니다.
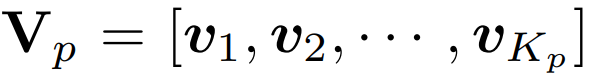
위 식의 V_p가 의미하는 바를 다시 짚고 넘어갈 필요가 있을 거 같습니다.
teacher와 student에서 각각 생성된 pixel embedding은 이미 구해진 상태입니다.
그리고 2.1에서는 위 pixel embedding을 mini-batch(4,8,,) 내에서 서로의 관계를 계산하였습니다.
즉 설정한 batch size 내의 관계만 포착하게 된다는 것이죠.
하지만 pixel queue Q_p는 distillation 과정 시 계속해서 update(enqueue) 되고, 점점 더 규모가 커집니다. 그리고 해당 queue에서 class-balanced하게 sampling한 constrastive embedding의 집합 V_p 를 생성하게 됩니다.
V_p는 batch size와 관계없이 점점 더 많은 양의 이미지들 사이에서 global relation을 반영하고 계산한다는 의미가 되겠죠.
2.1에서 mini-batch 내의 similarity matrix를 생성한 거 처럼,
본 절에서도 V_p내의 contrastive embeddings 과, student와 teacher에서 만든 pixel embedding(anchor) 사이의 similarity matrix P를 계산하게 됩니다. 아래와 같습니다.
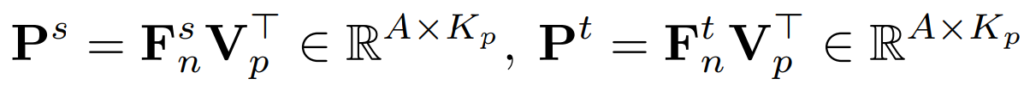
그리고 이를 사용한 loss는 아래와 같습니다.
2.1절에서 사용한 loss와 같은 형태입니다.
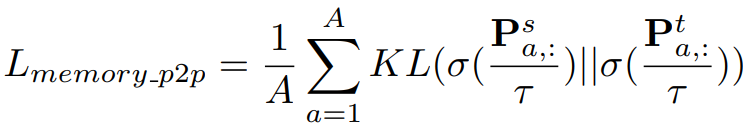
2.3 Memory-based Pixel-to-Region Distillation
앞선 과정들을 통해 여러 장의 cross-image에 대한 관계를 고려한 학습을 설계하였습니다.
하지만 저자는 pixel 단위로의 embedding 계산과 유사도 loss는 이미지의 content를 충분히 반영하지 못한다고 하며 pixel-to-region 관계의 distillation을 설계합니다. 앞 문장은 꽤나 직관적으로 와닿으리라 생각됩니다.
과정은 2.2와 유사합니다.
차이점이라면 pixel queue 대신, region embedding을 가지는 region queue를 만든다는 것입니다.
region embedding은 이미지에서 semantic class의 featuer center를 의미합니다.
식 적으로 표현하면 특정 class c에 속하는 모든 pixel embedding을 average pooling 함으로써 region embedding을 구하게 되고, 이를 통해 region queue Q_r 을 구성하게 됩니다.
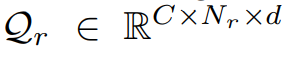
C는 class의 수를, N_r은 각 class별 region embedding의 수를 나타냅니다.
그리고 2.2와 마찬가지로 class-balanced 하게 K_r개 만큼의 contrastive region embedding r_k를 Q_r에서 샘플링 합니다.
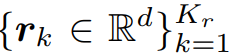
이를 matrix 형태로 표현하면 아래와 같습니다.
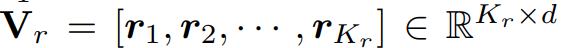
V_r내의 contrastive region embeddings 와, student와 teacher에서 만든 pixel embedding(anchor) 사이의 similarity matrix R를 계산하게 됩니다.
그렇게 되면 R은 pixel과 region의 관계를 모델링한 것이 되겠지요.
식은 아래와 같습니다.
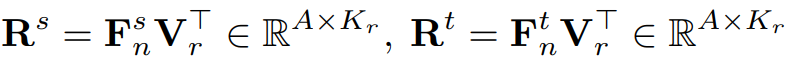
그리고 이를 사용한 loss는 아래와 같습니다.
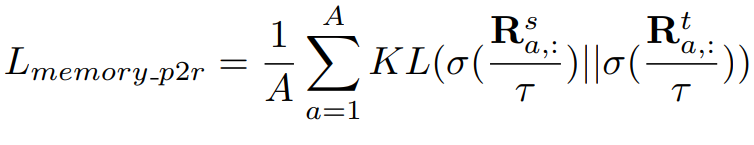
2.4 Overall Framework / Loss
위에서 설명드린 모든 loss들을 조합하여 student network를 학습하게 됩니다.
식은 아래와 같습니다.
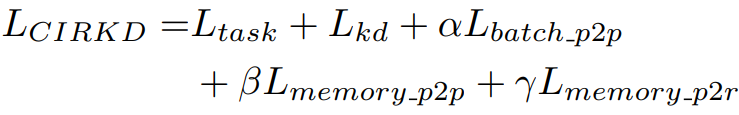
loss 5개는 각각 위에서 설명드린 식 1,2,4,6,8에 매칭됩니다.
그리고 \alpha, \beta, \gamma는 각각 1, 0.1, 0.1로 설정하긴 했는데, 0.1~1의 범위 내의 값에서는 성능이 대부분 유사하게 나왔다고 합니다.
추가적으로 전체적인 pipeline에 대한 알고리즘은 아래와 같습니다.

3. Experiment
실험은 Semantic Segmentation task에서 많이 사용되는 (1)Cityscapes, (2)CamVid, (3)Pascal VOC 데이터셋에 대해서 평가가 진행되며, 평가 지표는 각 class별 IOU의 평균인 mIOU로 측정이 됩니다.
그리고 본 논문은 모델을 제안한 것이 아니라 Teacher-Student 구조인 KD 학습 방식을 제안한 논문이기 때문에,
Teacher와 Student 모델의 경우 기존의 유명한 모델들을 활용하고 해당 모델에 본 논문의 KD 방식을 적용하여 다른 KD 방식들과의 성능 비교를 진행하였습니다.
Teacher 모델의 경우 모든 실험에서 동일하게 ResNet101을 backbone으로 하는 DeepLabV3 모델을 사용하였고,
student 모델의 경우 scale에 따라 여러 모델을 선정하여 실험을 진행하였습니다.
<Cityscapes>
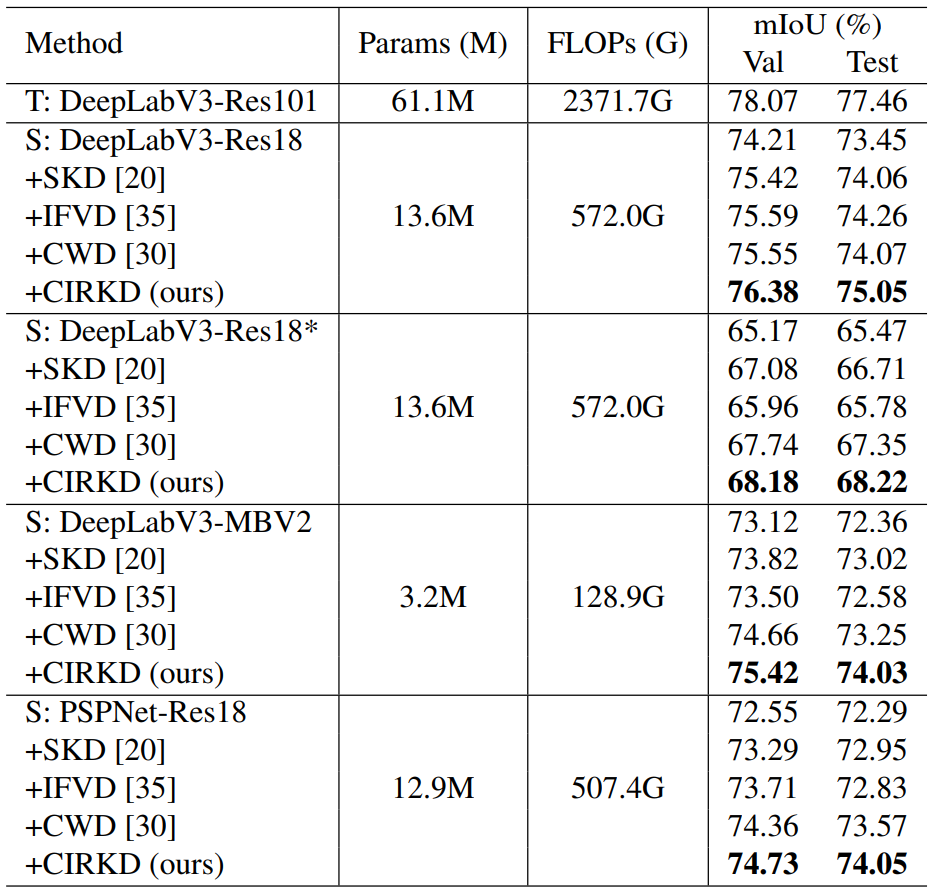
위는 Cityscapes 데이터셋에서의 실험 결과입니다.
Student 모델로 Teacher와 유사한 DeeplabV3를 사용했을때 뿐만 아니라 구조가 상이한 PSPNet의 경우에도 성능 향상폭이 꽤나 존재하는 것을 볼 수 있습니다.
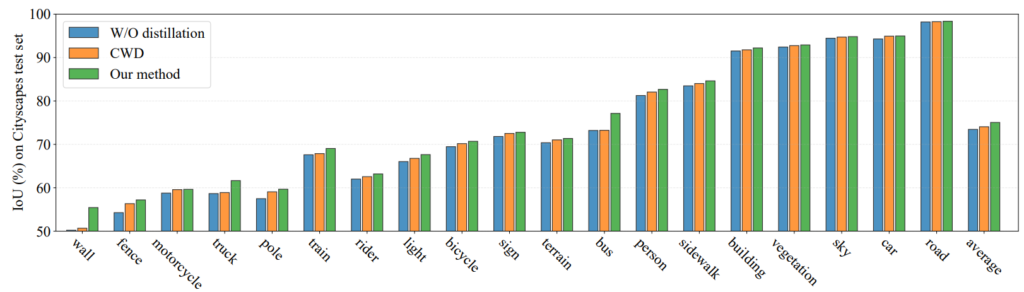
위 figure는 각 class별 성능 향상의 폭을 나타낸 그래프입니다.
모든 class에서 성능 향상이 일어났고, 특히 IOU가 낮은 class쪽에서 향상폭이 인상적입니다.
wall 클래스에 대해서 살펴보시면 distillation을 진행하지 않았을때와 CWD 기법에 비해 꽤나 큰 성능 향상폭을 보이는 것을 볼 수 있습니다.
정성적 결과는 아래와 같습니다.

3번째 row에 트럭을 보시면 흰색 바탕처럼 넓게 트럭의 옆면이 존재합니다.
다른 방법론들에 비해 Ours에서 훨씬 더 좋은 결과가 나타나는데 이는 아마 Pixel-to-Region Distillation 을 통해 region 영역에 대한 정보를 distillation 한 결과이지 않을까~ 라고 개인적으로 추측 해 봅니다.
<CamVid, Pascal VOC>
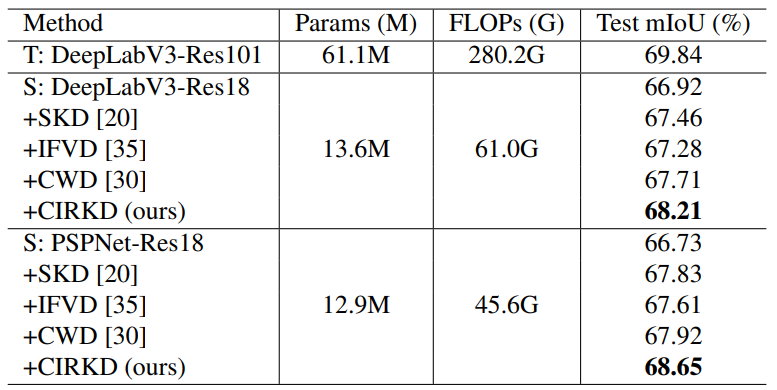
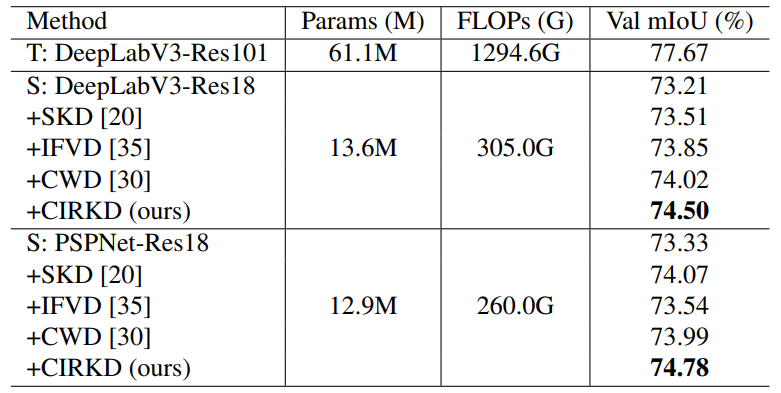
해당 dataset에 대해 특별히 분석적인 내용은 없고,
앞선 Cityscapes 데이터셋에서와 유사한 결과를 나타냅니다.
<Ablation Study>
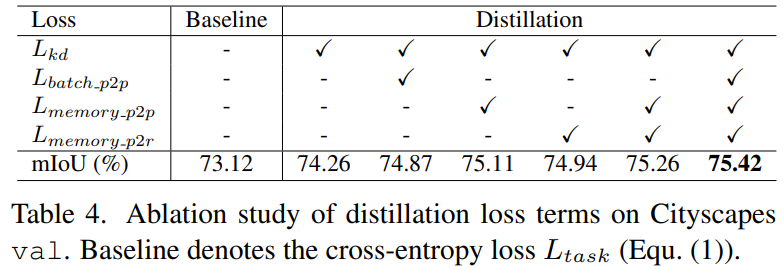
우선 각 loss term 에 대한 Ablation Study 결과입니다.
전체적으로 봤을 때 각 loss term 들이 모두 다 성능 향상에 기여한 것을 알 수 있습니다.
Mutual Learning에서 흔히 사용되는 L_{kd}(식 2) 를 적용했을 때 우선 성능 향상 폭이 1.14로 제일 크네요.
그리고, Distillation 영역의 3번째 column과 4번 column을 봤을 때 L_{memory-p2r} 보다 L_{memory-p2p} 의 성능 향상폭이 큰 것으로 보아 pixel-to-pixel distillation이 조금 더 학습에 효과적으로 작용했음을 알 수 있습니다.
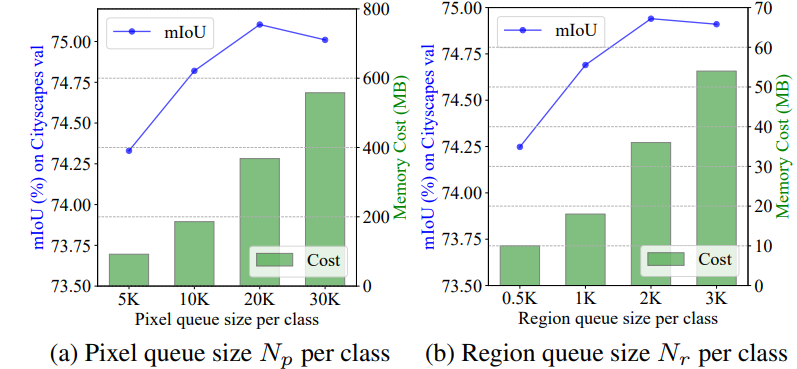
다음은 pixel queue와 region queue의 사이즈 별 성능 향상도입니다.
보시다시피 사이즈가 커질수로 성능 향상이 일어나는것을 볼 수 있네요.
queue의 사이즈가 크다는 것은 더 많은 이미지들 사이의 global information을 반영하는 것이므로 성능이 향상된것이지요.
그런데 꼭 큰게 좋은것만은 아니네요. 각각 30K, 3K 에서는 이전 사이즈보다 성능에 살짝은 drop이 있습니다.
네, 이렇게 오늘 리뷰 작성이 모두 끝났네요.
제목을 보고 흥미롭게 덤볐는데 양이 너무 방대하고, 꼼꼼하게 읽지 않았을 때 이해하기 힘든 부분도 많아서 꽤나 읽는데에 시간이 오래 걸렸습니다.
본 논문에서 similarity matrix의 계산, cross-image 사이에서 global relation 고려, pixel-to-region distillation 등 새롭게 접한 내용들이 많아서 이해하는 데에는 시간투자를 좀 많이 하긴 했는데 생각보다 값졌고 흥미로웠습니다.
특히 similarity matrix 를 적용시킨 논문은 제가 처음 읽어봤는데 흐름정도는 대충 알게 된 거 같아서 좋네요.
제 실험에 적용할 게 있을지는 잘.. 모르겠지만 아무튼 꽤나 흥미로웠던 논문이였습니다.
그럼 리뷰 마치겠습니다. 감사합니다.
안녕하세요. 좋은 리뷰 감사합니다.
intoroduction을 길게 작성하여서 contribution을 이해하는데 도움이 많이 되었습니다. 궁금한 점이 있는데요. memory bank라는 거는 학습 전에 미리 데이터셋으로부터 만들어두는 것인건가요?? 아니면 학습 하는 중간 중간 계속 갱신이 되는 건가요? 이 개념을 잘 알지 못해서 헷갈려 질문합니다
memory bank는 self-supervised learning (SSL)학습 기법에서 제안된 방식이며 본 논문 저자는 해당 개념을 가져와 사용하였습니다. 기존 SSL에서 memory bank의 정확한 동작 과정에 대해서는 정확히 알지 못하지만, 본 논문에서는 미리 만들어 놓는 것이 아닌, 매 iteration이 지날 때 마다 얻은 embedding 정보를 반복해서 update 시킵니다.
안녕하세요 좋은 리뷰 감사합니다.
제가 익숙한 classification task 기반의 KD 는 teacher 모델의 표현력을 student가 학습하는 방향으로 학습이 진행되었던것같습니다. 혹시 cross-image에서의 의미적인 관계라는 것이 어떤것일까요? segmentation task에 항상 쌍의 이미지가 필요하지는 않는데 혹시 자율주행 분야를 위한 부가정보일까요?
cross-images 는 1장의 단일 이미지에 대한 정보가 아닌 2장 이상(다다익선) 에 대한 정보를 함께 고려하겠다는 뜻입니다. 그리고 2장 이상의 많은 이미지에 대한 global sematic relation(의미적 관계)라는 것은 본 논문에 직접적인 표현은 없지만 아마 데이터셋 전체에 대한 특징, 공통적인 특징 등으로 생각 하시면 될 거 같습니다.
결국 저자는 1장의 이미지에 대한 예측값만으로 KD를 수행하는 것 보다, 이에 더해 데이터셋 전체의 global relation 정보까지 student가 teacher를 모방했으면 하는것이지요.