이번에 작성하게 될 논문은 AAAI2023 oral paper로 선정된 논문으로 task는 object tracking 관련 논문입니다. object tracking에 관심이 생겨서 읽게 된 논문은 아니고, 성능 향상을 위해 self-attention 적용 방식의 변화 및 Masked autoencoder 기법을 적용하였기에 한번 읽어보게 되었습니다.
Intro
일단 Visual object tracking이라는 분야는 연속적인 프레임으로 구성된 비디오가 제공되었을 때 임의의 특정 물체에 대하여 바운딩 박스를 추론하는 것을 의미합니다. 그럼 이게 object detection이랑 어떤 차이가 있는지?에 대해서 간략하게 말씀드리면, object detection은 단순히 single image를 활용하는 반면에 tracking은 이전 프레임에서 추정한 object 영역(이를 template이라고 부르겠습니다.) 과 현재 프레임의 이미지(이를 search image라고 부르겠습니다.)가 입력으로 활용하여, 현재 프레임의 이미지에서 이전 프레임의 object와 동일 대상의 위치 박스를 찾는다는 점이 차이점이겠습니다.
아무튼 이러한 visual object tracking의 경우 20년도까지만 해도 CNN 기반의 방법론들을 많이 활용하였는데, 특히 weight를 공유하는 Siamese Network를 통해 feature를 추출하고 이러한 fetaure들 간에 correlation을 계산함으로써 tracking을 수행하는 방법론들이 대세를 이루었습니다.
또한 최근에는 Transformer를 통해 templet image와 search image 사이에 correlation을 계산하는 방식이 좋은 성능을 보여주었다고 합니다. 즉 object tracking 분야의 연구 흐름은 template image와 search image 사이에 correlation 계산이 중요하며 이때문에 두 영상 사이에 correlation 및 aggregation을 잘 수행하기 위하여 attention 연산을 어떻게 잘 설계할 수 있을까에 초점이 맞춰지고 있다고 보시면 될 것 같습니다.
그러다보니 최근 object tracking 논문들은 Cross attention, Mix attention 등등 여러가지 attention 기법들을 꾸준히 제안하고 있는데, 이러한 현 상황에 대해 논문의 저자는 재밌는 주장을 합니다. 바로 기존의 제안된 cross-attention, mix-attention 등등은 모두 연산 방식이 동일하거나 기존 self-attention의 부분 집합 중 일부일 뿐이라는 주장을 하는 것이죠.
저자는 무작정 template image와 search image 사이에 correlation 및 aggregation을 계산하기 위해서 attention 연산을 남용하지 말고, 기존 transformer의 self-attention의 메카니즘이 왜 visual object tracking에 잘 동작하는지에 대하여 다시 한번 고민합니다.
그리고 이러한 고민 끝에 저자는 search image와 연관성 있는 token(즉 search token)이 visual tracking에 상당한 영향력을 미치고 있으며, template image와 연관성 있는 token(template token)의 경우에는 맨 마지막 단에 항상 버려진다는 것을 발견하게 됩니다.
즉 search token이 visual tracking에서 가장 중요한 역할을 수행하는 것으로 볼 수 있을텐데, 이 search token의 표현력에 관여하는 연산은 다음 두가지 입니다. 하나는 template token과에 cross-attention 연산이며, 다른 하나는 search token 내부의 self-attention이죠.
여기서 저자는 실험적으로 self-information을 aggregation하는 것이 cross-information을 aggregation하는 것보다 훨씬 더 중요하다는 사실을 확인하게 됩니다. 물론 cross-information이 필수적이라는 사실은 변함이 없지만, 그렇다고 cross-information을 보다 잘 aggregation하기 위해 노력을 하기 보다는, 기본적인 부분만 적용하고 오히려 self-information을 보다 잘 aggregation하는 방향이 더 좋다는 것이 저자의 주장 같습니다.
이러한 분석들을 바탕으로, 저자는 search token의 표현력에 영향을 미치는 self-information과 corss-information의 표현력 향상을 위한 correlative masked modeling 기법 기반 decoder를 새롭게 제안합니다. 사실 뭐 그렇게 대단한 모듈은 아니고 masked autoencoder 형식인데 이제 template token과 search token을 입력으로 활용해서 각각 원래 이미지로 reconstruction하는 기존 MAE 기법과 유사합니다.
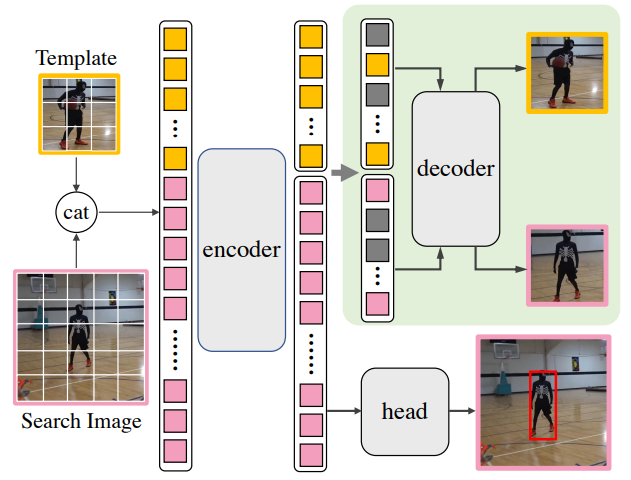
그림1을 보면 훨씬 더 쉽게 이해하실 수 있을 것 같습니다. template image와 search image를 concat하여 VIT 기반의 encoder를 태워서 각각 template token과 search token을 계산합니다. 그리고 나서 이제 기존의 object tracking 방법론들은 template token은 버려둔 체 search token만을 head layer에 태워서 객체를 검출하게 됩니다.
여기서 본 눈문의 경우에는 template token과 search token의 표현력 향상을 위하여 따로 ViT decoder를 두었으며, 각각의 token들은 모두 masking이 되어 각 영상을 다시 복원하는 식의 pretext task를 수행합니다. 즉 object tracking과 reconstruction을 동시에 수행하는 multi-task learning인 것이죠.
그리고 이 decoder를 활용한 reconstruction 과정은 training 과정에서만 필요한 것이기 때문에 실제 추론 과정에서는 deocder를 뺀, encoder 만을 활용하게 되므로 추론 과정에서도 빠르고 가볍게 활용할 수 있다는 장점이 존재합니다.
Method
본격적인 방법론에 들어가기 앞서 잠시 transformer tracking에 대한 수식 설명을 조금 다루고 가겠습니다.
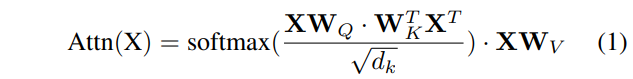
위에 수식 1은 transformer의 self-attention 연산을 나타낸 것입니다. X라는 token이 들어오면 각각 query, key, value로 값을 변경해주는 learnable weight 들이 존재로 하며, query와 key token들 사이에 dot product 및 softmax 연산을 수행, 그리고 이렇게 확률값을 가진 weighted vector를 value vector에 곱해주게 되면 attention이 적용되는 것이죠.
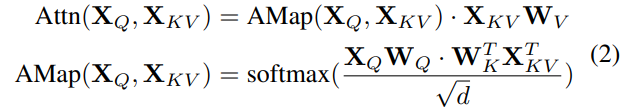
그럼 이번엔 object tracking 관점에서의 attention 연산을 살펴보겠습니다. 수식 2번이 바로 object tracking에서 주로 활용하는 방식인데, Attention 연산 과정에서 X라는 토큰 하나만 들어오는 것이 아닌 X_{Q}, X_{KV} 로 2개가 들어옵니다.
X_{Q}, X_{KV} 는 각각 쿼리에서 계산된 토큰, key와 value에서 계산된 토큰을 의미하는데, 이들이 각각 무엇을 지칭하는지는 밑에서 다룰 예정이니 일단 수식이 어떻게 계산되는지만 가볍게 보시면 됩니다.
자 그러면 이제 object tracking의 과정 및 구성에 대해서 다시 간단히 소개드리면 첫번째로 정보를 aggregation하는 transformer backbone과 둘째로 실제 객체의 bounding box 정보를 추정하는 box head로 나뉘어져 있다고 했습니다. 그리고 이 backbone의 입력으로 들어오는 이미지는 우리가 찾아야할 대상을 의미하는 template image(z)와 찾아야할 영역을 의미하는 search image(s)로 구성되어 있습니다.
각각의 영상을 ViT의 입력으로 활용하기 위해서 projection layer를 태워 token으로 만들어야 하며 이때 해당 token에 대한 표기를 X_{z}, X_{s} 라고 하겠습니다. 그럼 이제 tracking 과정에서 template token과 search token 사이에 정보를 aggregation하는 과정을 packed self-attention(PSelf-Attn)이라고 하는데 해당 과정은 다음과 같습니다.
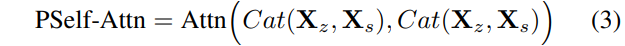
여기서 Cat은 Concatenation을 의미하며 template token과 search token을 단순히 concat한 것을 의미하죠. 그리고 이 수식 3번은 수식2에 첫번째 라인과 매칭해서 봤을 때 수식2의 X_{Q}, X_{KV} 는 모두 template, search toekn의 concat된 결과를 의미합니다.
Analysis on Attention
일단 위에서 설명한 PSelf-Attn이 Object tracking에서 흔하게 사용하는 attention 기법인 듯 합니다. 그리고 해당 attention 기법은 크게 4가지 요소에 대하여 고려를 할 수 있는데 이에 대한 부분은 아래 그림과 같습니다.
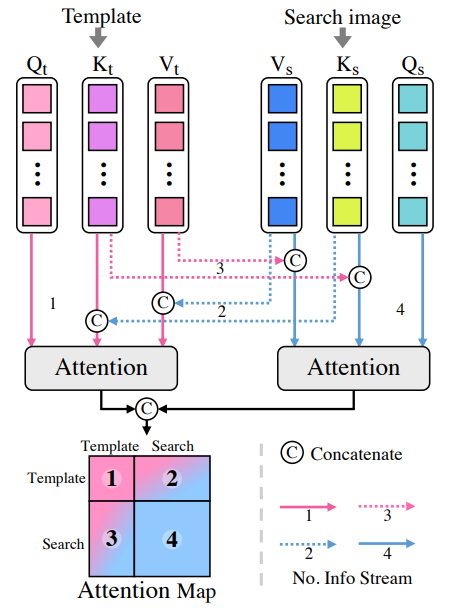
그림2 아래 Attention MAP이라고 적혀있는 부분에 숫자 1,2,3,4가 있는데 각각의 숫자가 의미하는 바는 다음과 같습니다.

즉 1번은 template에 대한 self-attention, 2번은 template에 대한 cross-attention, 3번은 search image에 대한 cross-attention, 4번은 search image에 대한 cross-attention을 의미하죠. 자 그러면 여기서 과연 visual object tracking을 잘 수행하는데 있어서 저 1,2,3,4 번의 과정이 모두 필요한 것일까요?
이에 대한 궁금증을 해결하고자 논문에서는 위에 각각의 과정에 대한 ablations study를 아래 그림 3과 같이 진행하였습니다.
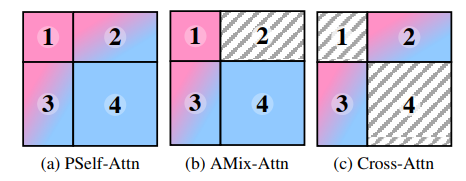
보시면 a의 PSelf-Attn은 위에서 언급한 4가지 특징을 모두 가지고 있으며, AMix_Attn은 2번 cross-information aggregation on template을 제거한 것이며, Cross-Attn은 template과 search image의 cross-attention만 존재하는 attention map을 의미합니다.
단순하게 생각하였을 때는 template과 search image의 self/cross 모두를 고려한 PSelf-Attn이 가장 좋은 성능을 보여줄 것으로 기대가 되지만, 놀랍게도 실제 결과는 그렇지 않았습니다. 각각의 attention case에 대한 ablation 표를 아래에서 확인하실 수 있는데, 결론부터 말씀드리면 PSelf-Attn보다 AMix-Attn 즉 2번을 제외하고 1,3,4번만 가져간 방식이 매우 큰 폭의 성능 향상을 보여주었습니다.
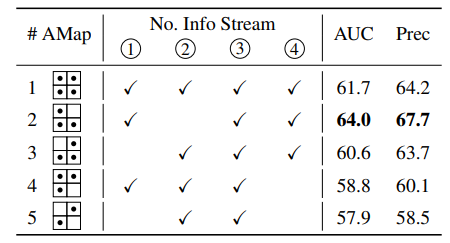
일단 성능이 가장 떨어지는 5번부터 하나씩 살펴보겠습니다. 5번의 경우에는 cross-information 정보만을 서로 주고 받는 것을 의미하는데, 해당 attention 과정은 template image와 search image 사이에 상관성을 계산한다는 관점에서 반드시 들어가야만 하는 연산인 것은 맞으나, 실제 tracking 관점에서 cross information 보다는 self-information이 훨씬 더 중요하다라는 것을 정량적 결과를 토대로 확인할 수 있습니다.
그리고 3번과 4번 실험의 경우에는 각각 template에 대한 self-attention(1)과 search image에 대한 self-attention 연산(4)이 제거된 실험을 의미하는데, 이 경우에 template에 대한 self-attention보다는 search image에 대한 self-attention 연산이 성능에 더 중요한 영향을 미친 것으로 확인할 수 있습니다.
사실 그것은 그럴 수 밖에 없는 것이, 맨 처음 그림1에서 보셨듯, 결국 template image에 대한 token은 search image에 대한 토큰의 표현력을 향상시킬 때 관여하는 역할일 뿐 최종적으로 해당 task에서 하고자 하는 것은 search image 내에서 object를 찾는 것이기 때문에 box head에 search token만이 활용되는 모습입니다. 따라서 search token에 대한 attention 연산이 빠지게 되면 정보의 표현력이 떨어져서 성능 향상에 보다 더 직접적인 영향을 주는 모습입니다.
그리고 1번 실험과 3번 실험을 놓고 보았을 때 역시 그래도 template token에 대한 self-attention이 없는 것 보다는 있는 것이 더 성능 향상에 영향을 주는데(AUC 기준 61.7 vs 60.6) 이는 3번 과정에서 search token에 대해 template token이 cross-attention 연산을 수행할 때 template token이 더 좋은 표현력을 가지게 되면서 간접적으로 search token에 영향을 주는 것으로 판단됩니다.
그리고 마지막으로 재밌는 점은 2번 실험과 1번 실험에 대한 비교인데, 결국 template token에 대한 cross attention은 오히려 없는 것이 꽤나 큰 폭의 성능 향상을 유발시켰다는 점입니다. 이에 대해서 구체적으로 왜 template에 대한 cross-attention(2)이 성능에 지대한 영향을 미쳤는가에 대해서 논문이 따로 밝히는 점은 없습니다. 논문에서도 그냥 단순히 template feature에 많은 노이즈가 발생하는 것 같다는 식에 모호한 문장만을 적어놓았는데, 구체적인 원인은 밝혀지지 않았지만, 아무튼 visual tracking 분야에서 만큼은 무지성 cross-attention은 지양해야할 것으로 판단됩니다.
Correlative Masked Modeling
자 그러면 위에 실험을 토대로 visual object tracking 성능에 큰 영향을 주는 요소들은 크게 3가지라는 것을 확인했습니다. 하나는 template token에 대한 self-attention, 둘째는 search token에 대한 cross-attention, 마지막으로 search token에 대한 self-attention 입니다.
그럼 이제 성능 향상을 위해서라면 위에 3가지 방향에 대한 representation을 향상시키는 것이 매우 중요한 요소라는 점이 밝혀진 것을 확인할 수 있습니다. 따라서 본 논문에서는 표현력 향상을 위해 21~22년도 유행하던 Masked Autoencoder 기반의 representation learning을 활용하게 됩니다.
한가지 재밌는 점이라면, masked autoencoder를 활용한 self-supervsied learning의 경우 보통 downstream task를 수행하기 전에 좋은 initial weight을 찾기 위한 pretaining 기법으로 많이 연구되고 있었습니다. 하지만 본 논문에서는 visual-object tracking을 학습하기 전 pretraining으로 쓰는 것이 아닌, object tracking 학습과 동시에 진행하는 마치 multi-task learning으로 활용한다는 점에서 제법 재밌는 차이라고 볼 수 있을 듯 합니다.
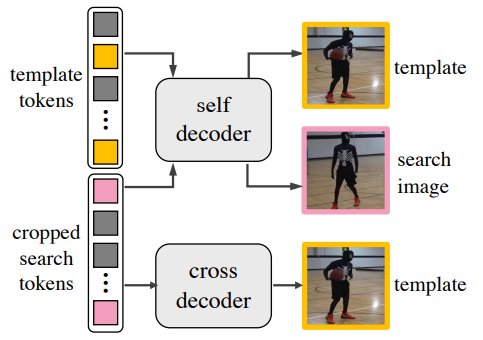
그림1에서도 보셨겠지만, 본 논문은 encoder에서 타고 나온 template과 search token에 대해 추가적인 decoder를 따로 두어 각각의 영상들을 reconstruction하게 됩니다. 이때 디코더는 2가지 종류로 나뉘는데 하나는 self-decoder, 다른 하나는 cross decoder입니다.
이게 지금 그림도 애매하고, 본 논문의 설명도 모호해서 정확하지는 않지만, decoder의 명칭만을 놓고 봤을 때는 template token과 search token이 각각 개별적으로 self-decoder에 들어간 후 각각 개별적으로 template image와 search image를 reconstruction 하는 것으로 판단됩니다. 만약 concat을 하였거나 cross-attention이 들어가서 두 token들이 융합되었으면 self-decoder가 아닌 cross-decoder라는 이름을 붙이지 않았을까 하네요.
그리고 cross decoder의 경우에는 두 종류의 token을 융합해서 만든것이 아닌, search token으로 template 영상을 복원하기 때문에 cross-deocder라고 명칭을 지은 듯 합니다. 이렇게 search token으로 template 영상을 reconstruction하는 것은 #3의 cross-information 향상에 도움이 된다고 합니다. 그외에 self-decoder는 #1과 #4의 각 토큰별 information 향상에 도움이 되는 것으로 의도한 것이구요.
실제 학습 방식은 기존 MAE와 동일하게 75%를 masking하였으며 loss function 역시 MSE로 동일합니다.
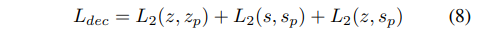
Experiments
그럼 실험 섹션 간단하게 훑은 뒤 리뷰 마무리 짓도록 하겠습니다.
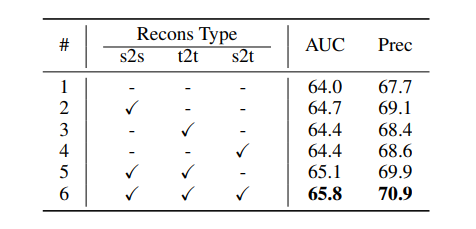
먼저 위에 표는 decoder를 통해 reconstruction하는 대상 및 경우의 수 에 대한 ablation study입니다. 결과론적으로 search image를 통해 search image를 reconstruction 하는 것, template image를 통해 template image를 reconstruction 하는 것, search image를 통해 template image를 reconstruction하는 것 각각을 적용한 것이 하나도 적용하지 않은 것 대비 성능 향상에 이점이 있었으며, 특히 s2s가 다른 두 요소보다 성능 향상에 더 크게 동작하는 것을 확인하실 수 있습니다. 이는 search token의 표현력을 증가시키는게 확실히 중요하다라는 것을 또 확인할 수 있는 부분이네요.
그리고 결과적으로 3가지 요소를 모두 고려해서 적용하면 AUC와 Prec 모두 좋은 성능을 보여준다는 이쁜 ablation study 모습입니다.
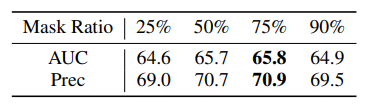
그리고 위에 표는 masking ratio에 따른 성능 결과를 나타낸 것으로 기존 original 방법론과 동일하게 75%로 하였을 때 가장 좋은 성능을 보여주고 있습니다. 50%랑 75%랑 성능 차이가 그리 크지는 않은 모습이네요.
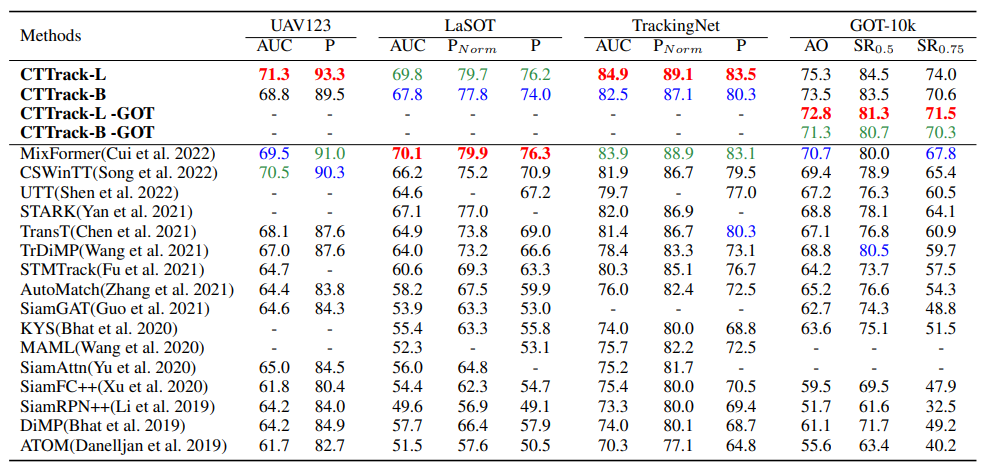
위에 표는 SOTA 방법론들과의 비교 결과입니다. CSWinTT와 MixFormer가 22년도 가장 최신 Object Tracking 방법론으로 transformer와 attention 연산에 초점을 둔 방법론처럼 보입니다. 본 논문의 경우 저 2가지 쟁쟁한 방법론과 비교하여 LaSOT 데이터 셋을 제외하면 모든 데이터셋, 모든 지표에서 SOTA 성능을 보여주고 있습니다.
저기 CTTrack-B(or L) – GOT라고 명시된 부분은 GOT-10K 데이터 셋으로 학습한 것을 의미하는데, 저것이 명시되지 않은 경우에는 외부 데이터 셋을 활용해서 학습을 하는 것을 의미하기에 성능이 높은 것을 볼 수 있으며 공평한 비교를 위해서는 GOT 표기가 되어 있는 것으로 비교하면 됩니다.
물론 fair한 비교를 하더라도 꽤 준수한 성능을 보여주고 있습니다. 근데 방법론들 별로 모델의 크기나 속도 차이는 알수 없기 때문에 단순히 성능만으로 좋고 나쁨을 따지기는 어려워 보입니다.
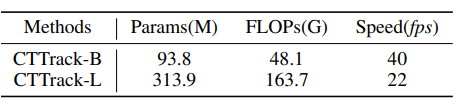
그래도 본 논문에서 제안하는 CTTrack-B의 경우 40FPS 정도의 속도는 보여주고 있기에 실시간 추론 가능성에 대해서 큰 부담은 없어보이긴 합니다.
결론
Attention 연산을 일단 붙일 수 있는 곳은 다 가져다가 붙이면 좋은 결과가 나오더라… 라는 것이 흔히 생각하기 쉬운 방향인데 본 논문에서는 attention 연산이 활용되는 지점이 분명 좋고 나쁨이 있을 것이라고 판단한 게 꽤나 재밌는 연구 방향이었던 것 같습니다.
다만 왜 #2를 없에는 것이 좋은 성능을 미치는가?에 대한 이론적 뒷받침을 확인할 수는 없었기에 조금 아쉬울 따름입니다만, 그래도 attention 연산 방식에만 집중하던 본 task의 요즘 연구 방향성에 대해 다르게 생각할 것을 제시함과 동시에 성능 향상 폭이 좋았기 때문에 oral paper가 될 수 있었던 것이 아닐까 생각합니다.