Before Review
요즘 Self-Supervised 기반의 Video Representation Learning 논문을 계속 읽고 있는데 조금 부족한 부분을 느꼈 습니다. 제가 정작 기본적인 SSL framework에 대해서는 이해가 떨어지는 느낌을 받았다는 것 입니다.
요즘 비디오 분야에서 2D Encoder + Transformer 구조가 많이 등장하면서 2D Encoder 부분에 SimCLR나 MoCo 같은 framework를 많이 사용하고 있습니다. 그런데 이 SimCLR나 MoCo와 같은 구조의 특징이나 implementation detail을 제가 놓치고 있었습니다.
따라서 이번 방학이 지나기 전에 한번 제대로 정리하고자 SSL의 대장(?) 논문들을 method 위주로 정리하였습니다. 따라서 실험 내용 보다는 방법론의 개념 그리고 implementation detail에 집중하여 리뷰를 작성하도록 하겠습니다.
참고로 아래에 등장하는 연구들의 순서는 아무 상관 없이 제가 임의로 나열 한 것 입니다.
리뷰 시작하겠습니다.
Self Supervised Learning
A Simple Framework for Contrastive Learning of Visual Representations (SimCLR)
딥러닝의 거장 Geoffrey Hinton 교수님의 SSL 연구 입니다. 저자가 주장하는 핵심 아이디어는 3가지 라고 정리할 수 있습니다.
- Composition of data augmentation plays a critical role in defining effective predictive tasks
- Introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations
- Contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning
정리하면 data augmentation을 같이 해주는 것이 중요하고, Backbone representation에 대해 nonlinear transformation을 가한 representation을 가지고 contrastive learning을 하는 것이 성능 향상에 중요하며, 매우 큰 배치 사이즈와 긴 학습 시간이 중요하다고 주장합니다.
아직 SimCLR framework를 모르기 때문에 위에서 얘기 하는 게 정확히 무슨 의미인지 모를 수 있습니다. 구조가 복잡한 것도 아니니 바로 설명해보도록 하겠습니다.
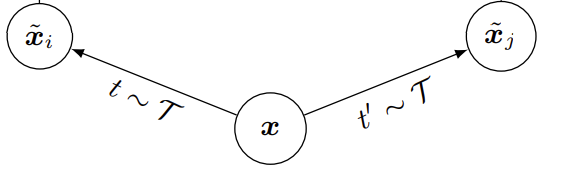
입력 데이터 x가 들어오면 data augmentation을 서로 다르게 두 번 진행해줍니다. 여기서 point는 하나만 하는 게 아니라 서로 각각 stochastic하게 진행해주는 것 입니다. 동일한 x에 대해서 augmentation을 진행한다면 augmentation 된 두 데이터는 \tilde{x}_{i} 와 \tilde{x}_{j}는 positive의 관계에 있습니다.
여기서 Positive라는 것은 두 데이터가 유사하다는 의미이고, Negative라는 것은 두 데이터가 유사하지 않는다는 것 입니다. 일반적으로 Positive/Negative Pair를 활용한 metric learning 혹은 representation learning은 이 pair를 구성하는 것이 굉장히 중요합니다. 그 중에서도 어려운 Negative(비슷하게 생겼지만 엄연히 다른 관계인)를 잘 구성해야 더욱 풍부하게 학습을 할 수 있습니다.
그런데 SimCLR에서는 이런 pair 문제를 굉장히 간단하게 풀어버립니다. Batch 단위로 학습을 진행한다고 했을 때 N개의 sample이 있다고 가정하겠습니다. Batch 안에 있는 데이터들은 서로 다른 두 가지의 augmentation이 적용되기 때문에 2N개의 데이터를 가지게 됩니다. 이 2N개의 데이터를 살펴보도록 하겠습니다.
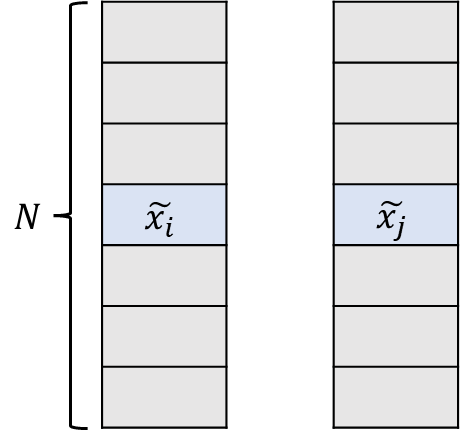
결국 같은 데이터에 대해서 augmentation이 된 pair가 아니면 전부 Negative의 관계에 있겠네요. 저기 파란색으로 칠해진 데이터들은 서로 Positive이고 파란색과 회색은 서로 Negative 입니다. 그러면 배치안에 있는 임의의 데이터는 2개의 positive sample을 가지게 되고 2N-2개의 negative sample을 가지게 됩니다.
다시 SimCLR의 구조로 돌아와서 결국 배치안에 있는 모든 N개의 데이터를 각각 augmentation 2번 태워주고 Image-level의 2D Encoder를 태워줍니다.
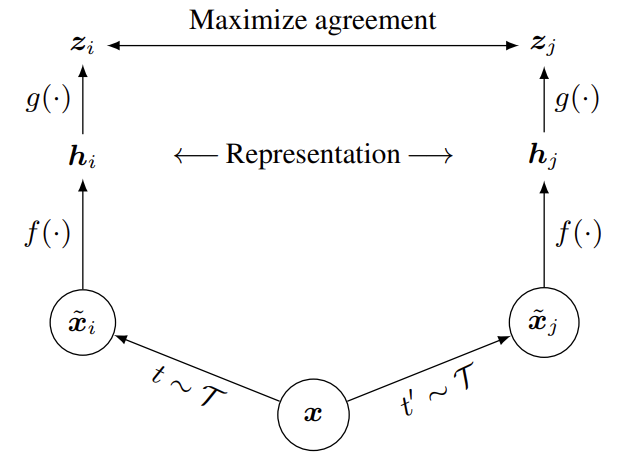
h_{i}=f(\tilde{x}_{j}) 인데, 여기서 사용되는 Encoder f는 ResNet-50을 사용합니다. GAP를 거치고 나온 embedding을 사용해서 feature의 차원을 2048이라고 합니다. 이 embedding을 바로 사용해서 contrastive learning을 하는 것이 아니라 다시 latent space로 embedding을 시켜준다고 합니다.
- z_{i}=g(h_{i})=W^{(2)}\sigma(W^{(1)}\cdot h_{i})
\sigma은 ReLU activation 입니다. 여기서 SimCLR의 특이한 점은 latent space로 다시 한번 embedding 시켜줄 때 Non-linear한 구조를 사용한다는 것 입니다. SimCLR의 실험 부분을 보면 확인할 수 있지만 확실히 Linear transformation 하는 것보다 더 좋은 representation을 얻을 수 있다고 합니다.
자 이렇게 해서 배치에 존재하는 모든 데이터 N개에 대해서 2쌍의 augmentation view를 가지고 새로운 latent space로 embedding 시켜주면 2N개의 z_{i} latent vector를 얻을 수 있습니다.
그리고 나서 contrastive learning은 normalized temperature-scaled cross entropy loss (NT-Xent)를 가지고 진행이 됩니다. Loss 함수의 formulation은 아래와 같습니다.
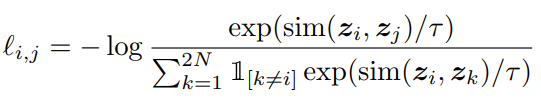
여러 블로그나 유튜브 영상을 참고하면 단순히 softmax의 확률 값을 최대로 키우는 것이 목적이다 정도로 짧게 설명하는데 저는 잘 이해가 가질 않아서 toy example 하나를 가져와서 이해해봤습니다. 배치 사이즈 N=2인 상태를 가지고 예시를 들어보겠습니다. 배치 사이즈 N=2라면 우리는 4개의 embedding z_{1},z_{2},z_{3},z_{4}을 얻을 수 있습니다.
이때 z_{1}기준으로는 z_{2}와 positive 관계에 있으며 z_{3},z_{4}와는 negative 관계에 있습니다. 그리고 l_{1,2}를 위의 formulation 대로 계산하면 아래와 같이 나와야 합니다.
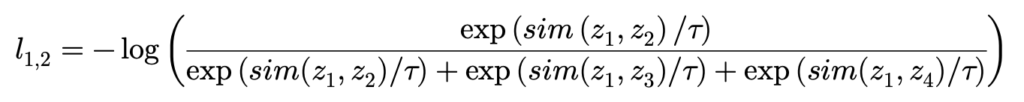
위의 loss 함수가 최소가 되려면 \frac{\exp \left( sim\left( z_{1},z_{2}\right) /\tau \right) }{\exp \left( sim(z_{1},z_{2})/\tau \right) +\exp \left( sim(z_{1},z_{3})/\tau \right) +\exp \left( sim(z_{1},z_{4})/\tau \right) }이 1에 수렴해야 합니다.
이는 두가지의 방향성을 가지고 있습니다.
- \exp \left( sim\left( z_{1},z_{2}\right)/\tau \right) \rightarrow \infty : positive pair간의 representation similarity가 무한대로 수렴하면 1에 수렴합니다.
- \exp \left( sim\left( z_{1},z_{3}\right)/\tau \right) \rightarrow 0 , \exp \left( sim\left( z_{1},z_{4}\right)/\tau \right) \rightarrow 0 : negative pair간의 representation similarity가 0으로 수렴하면 1에 수렴합니다.
결국 NT-Xent Loss를 최소화 하는 방향은 positive pair와의 representation similarity는 maximize 시키고 negative pair와의 representation similarity는 minimize 시킵니다.
조금 어렵게 설명했는데 사실 이렇게 생각해도 됩니다. z_{1} 기준으로 positive인 z_{2}가classification label이 되는 것 입니다. Representation similarity는 이제 probability가 되는 것이고 z_{1} 기준으로는 가장 닮아 있는 z_{2}를 classification label 인셈 치고 classification loss를 설계하는 것 입니다.
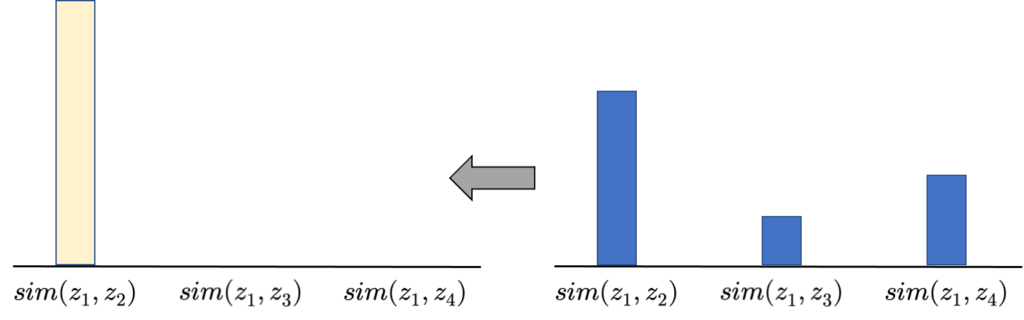
이 또한 classification 과정에서 probability를 높이는 방향은 z_{1}과 z_{2}의 representation similarity를 높이는 방향입니다. Contrastive Learning에 사용되는 Loss까지 알아 봤으니 이제 SimCLR의 전체 구조에 대해서 다시 한번 정리하고 MoCo로 넘어가보도록 하겠습니다.

SimCLR의 learning algorithm 입니다. 입력으로 들어온 x_{k}에 대해 first, second augmentation을 각각 stochastic하게 적용하고 latent space로 projection 시켜서 z_{2k-1} , z_{2k}를 만들어 냅니다. Projection 된 두 embedding 끼리의 유사도는 s_{i,j}=z^{T}_{i}z_{i}/\parallel z_{i}\parallel \parallel z_{j}\parallel 와 같이 cosine 유사도를 통해 계산합니다.
NT-Xent Loss는 l(i,j)와 l(j,i)가 다른 값으로 계산됩니다. 따라서 배치내에 존재하는 모든 augmented sample을 가지고 loss를 계산하면 \frac{1}{2N} \sum^{2N}_{k=1} \left[ l(2k-1,2k)+l(2k,2k-1)\right] 이렇게 계산이 됩니다.
방법론에 대해서는 모두 설명했습니다. 논문에는 관련하여 흥미로운 실험들이 많지만 지금 리뷰에 담지 않도록 하겠습니다. 궁금하신 분들은 직접 논문을 읽어 보시길 바랍니다. 저는 Implementation Detail만 살펴보고 다음 방법론으로 넘어가도록 하겠습니다.
Implementation Detail
SimCLR는 Negative Pair 문제를 매우 큰 배치 사이즈로 해결하였습니다. 이때 large batch size로 학습할 때 기존의 SGD/Momentum 계열의 optimizer는 불안정하다고 합니다. 이유는 나와있지 않지만 어찌됐든 LARS라는 optimizer를 사용했다고 합니다. Batch Normalization 같은 경우도 분산학습을 할 때는 device 마다 BN mean / variance를 계산하는 것이 아니라 모든 device에서 통일된 BN mean과 variance를 사용해주었다고 합니다.

나머지 detail은 위의 글을 그대로 첨부하도록 하겠습니다.
Momentum Contrast for Unsupervised Visual Representation Learning (MoCo)
구글에 SimCLR가 있다면 페이스북에서는 MoCo가 있습니다. 두 기업의 SSL 싸움이라니 가슴이 웅장해집니다. MoCo 역시 굉장히 간단한 아이디어로 설계 되었습니다. MoCo는 처음 논문에 등장하였을 때는 성능이 그리 높지 않았지만 후에 최적화 과정을 거치면서 MoCov2가 나오게 되었고 SimCLR와 거의 비슷한 성능을 가져가는 SSL framework 입니다.
MoCo는 쉽게 정리하면 Contrastive Learning을 위한 Dynamic Dictionary를 구성하는 방법을 다루는 연구입니다.
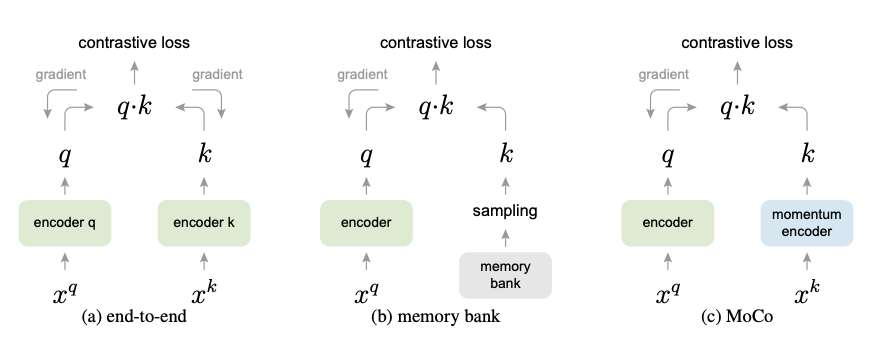
MoCo를 이해하기 위해서는 (a) end-to-end 방식과 (b) memory bank 방식을 이해해야 하고 그 방식들의 한계점을 이해해야 합니다.
(a) end-to-end 방식은 제가 바로 위에서 설명한 SimCLR와 동일한 구조 입니다.
모든 데이터로부터 gradient를 전달받아 encoder를 update 시키죠. 그런데 사실 이부분은 SimCLR의 명확한 한계점 입니다. Memory가 너무 많이 필요합니다. SimCLR 논문에서 배치 사이즈의 default setting은 4096개 입니다.
이건 기업 레벨이나 대형 연구실 레벨에서나 돌릴 수 있는 수준이지 소형 규모의 GPU로는 사실 학습조차 불가능 합니다. SimCLR의 forward 과정을 간략하게 정리하면 4096x3x224x224 -> 4096×2048 -> 4096×128 이런 수순으로 데이터가 처리 되는데 이걸 매 배치마다 진행해야 하니 GPU memory가 상당히 많아야 합니다.
(b) memory bank 방식은 일단 모든 데이터셋의 representation을 학습 전에 다 만들어 놓고 학습을 시작하는 것 입니다.
예를 들면 이미지넷으로 사전학습된 ResNet50을 가지고 학습에 사용할 모든 이미지에 대해 일단 backbone embedding을 만들어서 보관하는 것이죠. 그리고 나서 query는 비교적 적은 mini-batch를 가지고 나서 memory bank에 있는 embedding 들과 similarity를 계산하고 contrastive learning을 하는 것 입니다.
이때 memory bank는 update 되지 않습니다. 그저 backbone embedding으로 고정하고 학습을 계속 진행하는 것이죠. 그러면 query encoder는 비교적 적은 sample을 가지고 gradient를 tracking 하기 때문에 memory 관점에서는 효율적이지만 encoder가 update 될 수록 inconsistency 문제가 발생합니다.
무슨 의미냐면 memory bank에 있는 embedding 들은 이미지 넷으로 사전학습된 backbone을 가지고 만들어진 고정된 embedding인 반면 계속해서 update 되는 query encoder를 통해 나온 query들의 representation은 memory bank에 있는 representation과는 level이 맞지 않는 것이죠. 그렇기 때문에 memory bank 방식은 memory 관점에서는 효율적이지만 학습 과정에서 발생하는 inconsistency 문제가 존재합니다.
이에 MoCo는 위의 문제들을 해결하기 위한 간단한 아이디어 두가지를 제안합니다.
일단 MoCo는 메모리 문제를 해결하기 위해 일단 memory bank 방식을 사용합니다. 하지만 MoCo에서 memory bank는 고정되지 않습니다. 바로 queue 형태로 학습 중간중간에 update 시켜 안의 내용들을 변화하게 만듭니다.
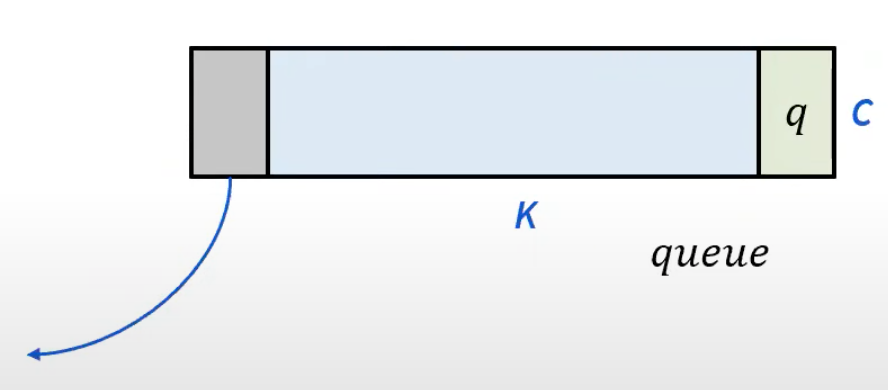
memory bank의 사이즈가 K라고 가정했을 때 K 보다 훨씬 작은 현재의 배치 사이즈 N 만큼 계속 deque 되는 것이죠. 현재 들어온 배치가 enqueue 되고 가장 오래된 sample들은 dequeue 되는 방식 입니다. 오래된 sample들을 dequeue 하는 것은 결국 consistency를 맞춘다는 관점에서도 합리적입니다. dequeue가 될 정도로 오래 있었다면 그들의 representation은 지금 들어오는 query의 representation과는 level이 맞지 않기 때문입니다.
일단 이렇게 memory bank를 queue의 구조로 설계하여 consistency 문제를 어느정도 해결 할 수 있었습니다.
하지만 이렇게 enqueue, dequeue 시키는 것만으로는 inconsistency 문제를 완전히 해결할 수 없습니다. 결국 memory bank에 있는 sample들도 나름 자체적으로 query encoder와 비슷한 space로 projection을 시킬 수 있어야 하는데 이를 위해 고안한 것이 momentum encoder 입니다.
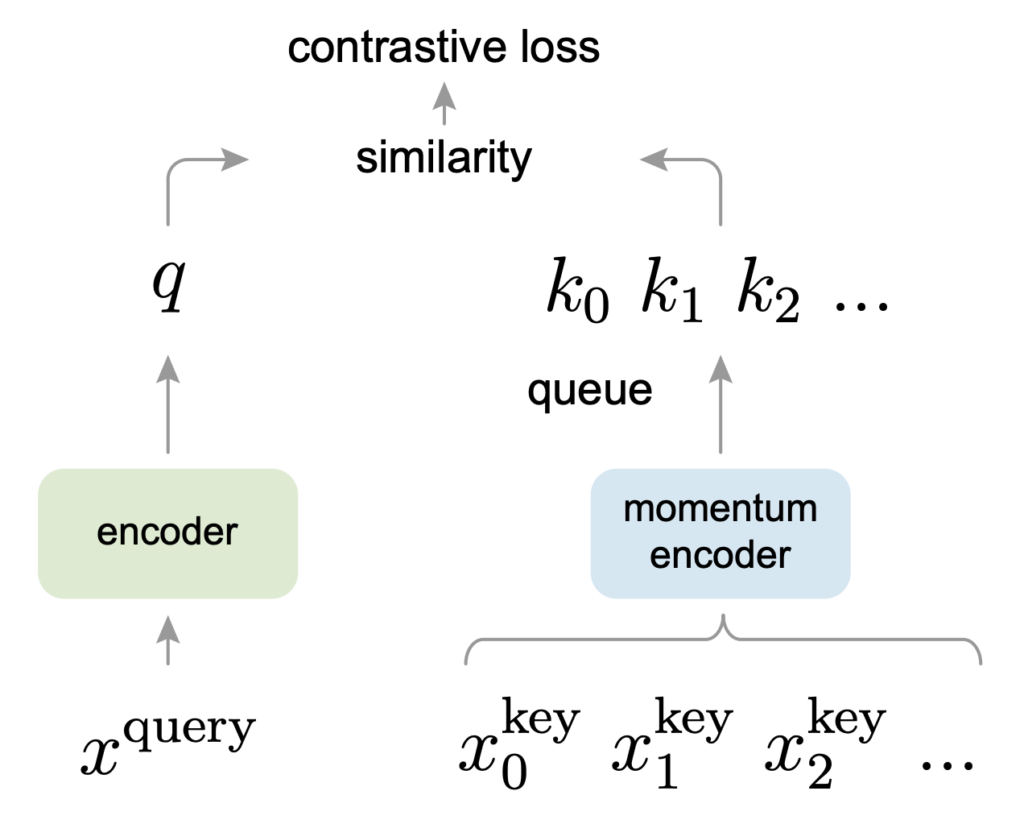
query encoder는 batch size가 비교적 작기 때문에 그대로 gradient 기반으로 update를 하면 되지만 memory bank를 담당할 encoder는 gradient로 update 하기 어렵습니다. 계속 얘기했지만 memory 문제 때문이죠. 그럼 query encoder를 그대로 동일하게 쓰면 되지 않느냐 라고 생각할 수 있지만 이는 생각보다 성능이 좋지 않다고 합니다.
따라서 저자는 gradient가 아닌 moving average를 토대로 update하는 momentum encoder를 제안합니다. Moving average는 그냥 model weight에 대해서만 연산을 진행하는 것이기 때문에 memory bank에 있는 sample을 가지고 backpropagation 하는 것 보다 훨씬 적은 연산량을 가져갈 수 있습니다.
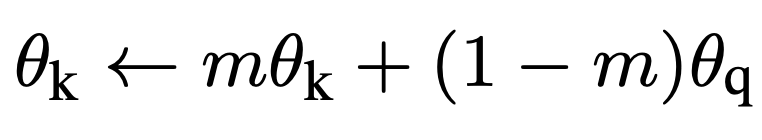
여기서 \theta_{k} 는 key encoder, \theta_{q}는 query encoder의 weight 입니다.
이때 m=0.999을 default setting으로 가져가는데 이는 key encoder의 weight를 중점적으로 유지하되 query encoder의 weight를 천천히 반영하겠다는 의미입니다. 이렇게 moving average 방식으로 update 되는 key encoder 덕분에 MoCo에서는 memory bank와 query 간의 inconsistency 문제를 어느정도 해결할 수 있었습니다.
MoCo도 SimCLR와 같이 굉장히 간단합니다. 아래 알고리즘을 통해서 다시 한번 MoCo를 정리해보도록 하겠습니다.

일단 key encoder의 초기 weight는 query encoder와 동일하게 세팅해주고 있네요.
그리고 데이터로더에서 x를 받아오면 stochastic하게 두번의 augmentation을 가해 query와 key를 만들어내고 있습니다. 그리고 query와 key는 각각의 encoder를 통과해 projection 됩니다. 다음으로 positive logits, negative logits를 만들고 있는 부분이 있는데 아마 이 부분이 저렇게 의사코드만 보면 조금 이해하기 어려울 수 있습니다. 아래 그림을 통해 살펴보면
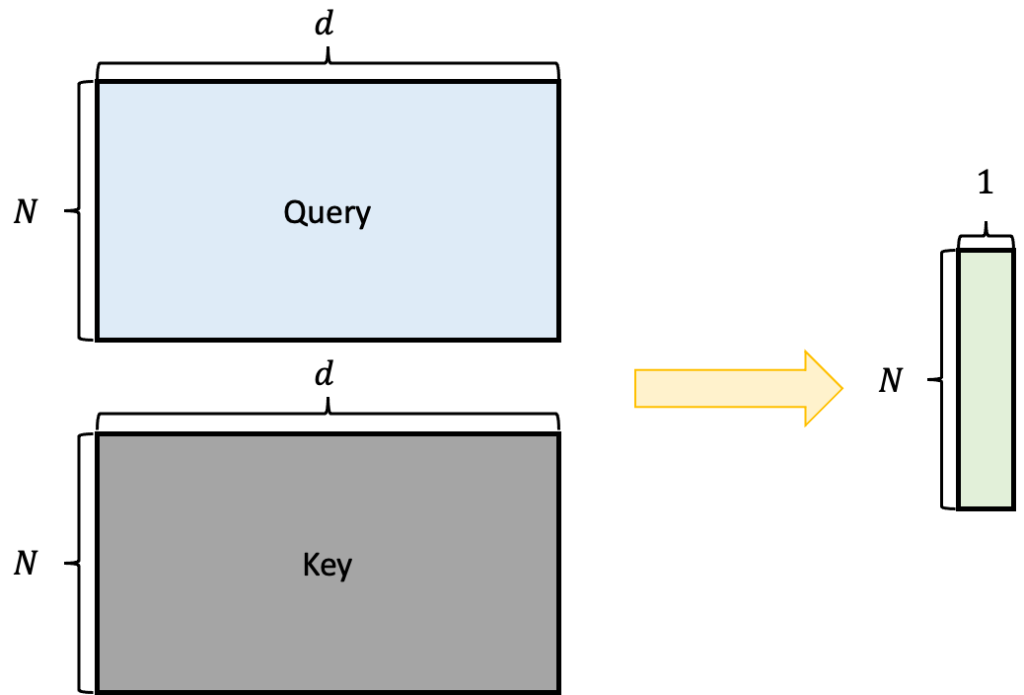
일단 Query와 Key를 가지고 동일한 행에 대해서 vector 끼리 내적을 합니다. 동일한 행에 대해서 내적을 했기 때문에 서로 positive pair 끼리 연산을 했다고 보시면 됩니다.
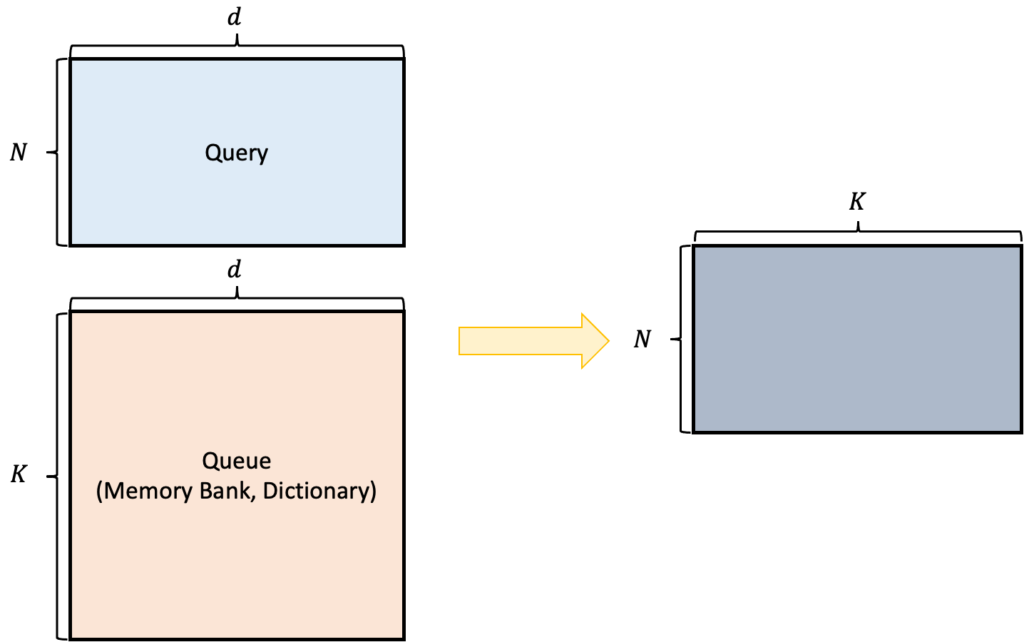
다음으로 Query와 Queue 간의 연산입니다. Query N \times d 그리고 Queue를 전치시켜서 d \times K 형태로 만들고 행렬 곱을 취해주면 N \times K 의 행렬이 나오는데 이 행렬이 의미하는 건 뭘까요? Query 기준으로 Memory Bank에 있는 데이터는 모두 다른 sample들 입니다. 고로 negative 관계이죠. 따라서N \times K 의 행렬이 담고 있는 값은 negative pair간의 내적 값을 담고 있습니다.
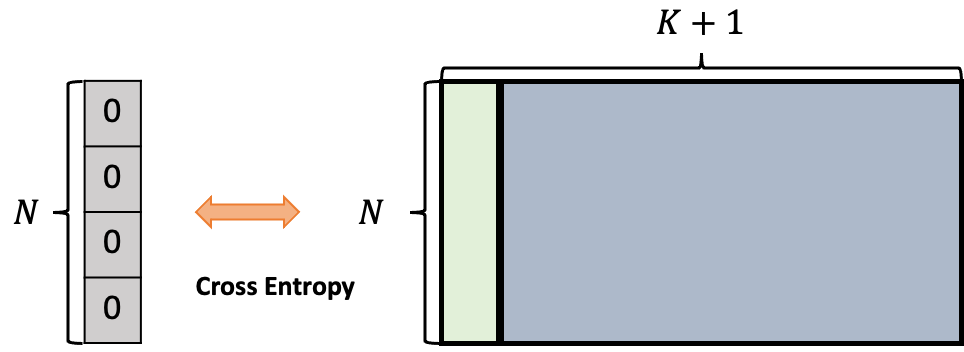
그리고 positive 와 negative pair간의 연산 결과를 concat 하여 logit을 만들어줍니다. 그리고 나서 0으로 채워진 target 값을 만들어주고 cross entropy loss를 태워주면 InfoNCE Loss의 형태로 contrastive learning을 할 수 있습니다.
지금 모든 배치에 대해서 첫 번째 열에 해당되는 logit들은 모두 positive pair로 만들어진 값들이 입니다. 우리의 target은 0번째 index가 target class라 얘기해주고 있고요. 즉, positive logit에 해당되는 softmax값이 최대가 되는 방향으로 gradient가 전달될 것이고 이는 positive pair에 해당되는 projection 끼리 representation 유사도가 최대가 되는 방향을 의미합니다.
그리고 나면 Queue는 현재의 key를 enqueue 시키고 가장 마지막에 있는 sample들을 dequeue 시켜 update 합니다.
Implementation Detail
중요하게 봐야하는 detail은 배치 사이즈, queue의 사이즈, momentum 계수, 그리고 augmentation 종류 입니다.
배치사이즈는 기본으로 256을 사용하였고, queue의 사이즈는 65536, momentum 계수는 0.999 그리고 augmentation 종류는 pytorch torchvision에서 가능한 random resize, random color jittering, random horizontal flip, random grayscale conversion을 사용했다고 합니다. SimCLR와 다르게 MoCo v1에서는 ResNet-50 백본으로부터 나온 feature를 projection 시키기 위해 128차원으로 투영 시키는 Linear Layer 하나만을 사용했다고 합니다. 물론 성능이 안나와서 MoCo v2에서는 Layer2개에 ReLU를 사용하는 non-linear transformation으로 바꾸긴 합니다.

나머지 detail은 원문을 첨부하도록 하겠습니다. 생각보다 ImageNet 1M 학습에 많은 GPU를 필요로 하진 않는 모양입니다.
BYOL, SwAV 등 논문을 더 소개하려고 했는데, 사진도 안 올라가고 엑스 리뷰 사이트가 불안정한 것 같아서 이번 리뷰는 여기까지 끊고 가도록 하겠습니다.
리뷰 읽어주셔서 감사합니다.
안녕하세요.
가슴이 웅장해지는 두 대기업의 SSL 경쟁 흥미롭게 읽었습니다. 좋은 리뷰 감사합니다.
특히 SimCLR의 Loss 함수를 예시를 들어 설명해주셔서 이해를 쉽게 할 수 있었던 것 같습니다.
SimCLR에서 Batch Size가 Supervised Learning에 비해 큰 편이 좋다고 주장하는 것은 뒤에서 설명하신 Batch 안의 Augmentation된 2N 개의 데이터를 활용하여 2N-2개의 negative pair를 생성하는데 N이 클수록 더 많은 Neg Pair가 생성되는 것 때문인가요? 혹은 큰 batch size가 좋은 별개의 이유가 있는 것인가요?
감사합니다!
지도학습도 배치사이즈가 크면 좋긴합니다.
제가 강조하고 싶었던 것은 자기지도학습에서는 배치사이즈가 크리티컬 하다는 것을 강조하고 싶었던 것 입니다.
N이 클수록 우리가 임의로 샘플링한 콘텐츠와 negative 관계에 가지는 샘플들이 추출될 포텐셜이 높기 때문이라 생각하시면 됩니다.
추가적으로 배치사이즈와 관련하여 이론적으로 궁금하시다면 https://proceedings.mlr.press/v162/yuan22b.html
이 논문을 한번 읽어보시길 추천드립니다(읽을 수 있다면..ㅋㅋ)