이번에도 감정인식 논문입니다. 무슨 논문을 읽을까 서베이하다 발견한 베이스라인 후속 논문이라 읽게 되었습니다. 이 논문은 비디오는 크고 무거워지는데 기존의 멀티모달 감정인식 연구들은 application에는 뒷전이고 성능에만 관심있다는 것을 한계점으로 여기며 이를 개선하고자 나오게 되었습니다. 그럼 리뷰 시작하겠습니다.
<Intruduction>
기존의 멀티모달을 베이스로한 video emotion recognition은 3가지 한계점이 있다고 합니다.
- accoustic modalty feature가 보통 OpenSmile 툴킷 혹은 RNN을 베이스로한 딥러닝 네트워크로 추출된다는 것.
→ 위의 방식으로 추출된 feature는 multimodal recognition에 유용하지만 visual, textual modality와 비교했을 때 위의 feature를 이용할 경우 acoustic modality의 기여도는 상대적으로 낮아 비디오 감정인식 성능향상에 영향을 미친다는 한계가 있습니다.
2. 5g 네트워크로 인해 사람들이 쉽게 고화질의 비디오를 기록하고 공유할 수 있게 되었지만 최근 딥러닝 네트워크는 visual modality의 beffer performance를 이끄는데만 집중하기 때문에 복잡한 구조 때문에 비디오 처리나 저장 문제에는 대처하지 못하고 있다는 것.
3. 연구가 항상 아카데믹한 레벨에 머물고 있다는 것.
-> 대부분 non-end-to-end framework로 구성되어있고 복잡하고 느린 경우가 많은데, 이런 경우 멀티모달 비디오 감정 인식의 application을 방해한다고 합니다.
위의 한계점을 해결하기 위해서 이 논문에서는 multimodal video-to-emotion system을 통해서 비디오 원본을 input으로 받습니다.
논문에서의 모델 구조를 간단하게 요약하면 아래와 같습니다.
- hierarchical atention을 사용하여 오디오 모달리티의 각 spectral patch에 대한 feature를 추출한다. 이를 통해 audio modality가 좀더 성능에 기여할 수 있도록 한다.
- 동시에, multi-branch feature learning, single-branch inference 구조를 채택했다. 이를 통해 visual modality의 프레임의 information을 추출할 수 있다. 그리고 inference model을 simplify할 수 있다.
- text modality에서는 texutal feature를 추출하기 위해서 alber를 채택하였다.
- visual, acoustic sequential information을 얻기 위해서 베이직 transformer를 사용한다.
- 마지막으로 multimodal fusion은 feedforward 네트워크를 통해 수행된다.
<Proposed method>
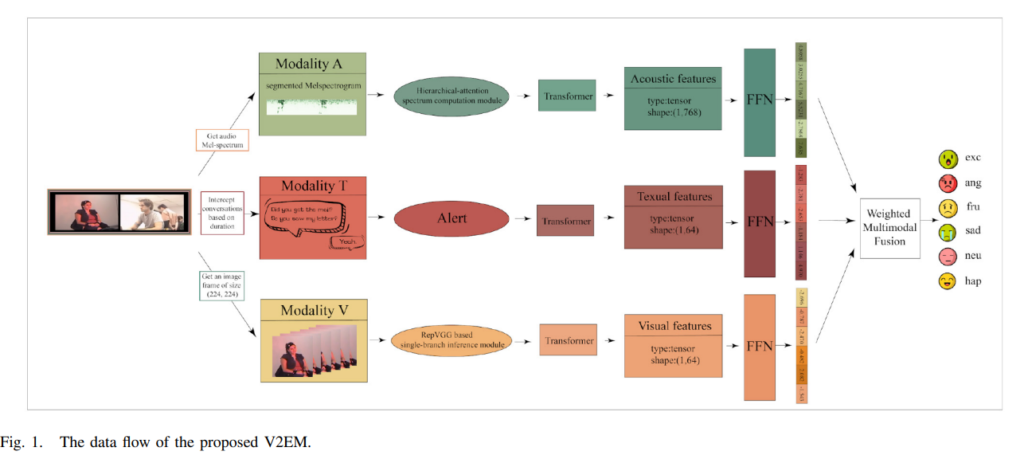
이 논문에서 제안한 V2EM(video-to-emotion multimodal model)은 [Fig 1]과 같스니다. visual, text, acoustic modality를 포함하는 비디오를 입력으로 받습니다. audio 모달리티의 spectral patch의 feature를 추출하기 위해서 hierarchical attention을 사용하고, video 모달리티의 frame 정보를 얻기 위해서 RepVGG-based single-branch inference module을 사용합니다.
- audio modality → hierarchical attention
- video modality → RepVGG
- text modality → albert
<The Hierarchical-Attention Spectrum Computing Module>
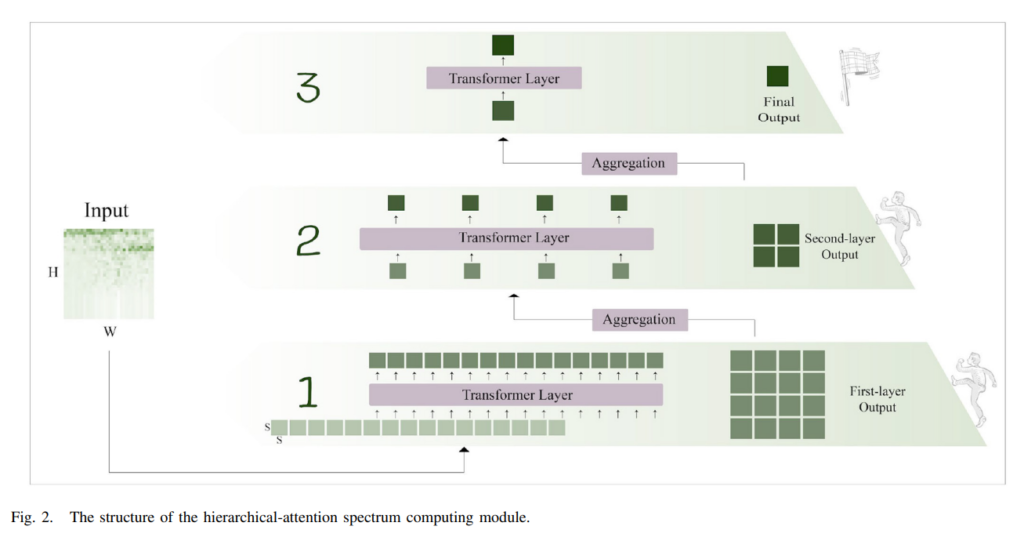
이 attetnion은 nesting transformer 논문에서 영감을 받았다고 합니다. nesting transformer는 이미지 분류에 사용되었는데 이를 spectrum에 맞춰 hierarchical-attention을 사용하였습니다. [Fig 2]를 통해서 hierarchical-attention의 구조를 확인할 수 있습니다.
input으로는 Mel-scale fileter bank를 통해서 얻은 spectrum이 들어옵니다. spectrum은 (H,W)로 reshape하게 되는데 이때 H와 W는 같습니다. 이후에는 16 patchs로 쪼개지는데 (S,S) shape을 가지며 S는 H의 4분의 1배입니다. 이렇게 쪼갠 작은 patch들을 first-layer spectrum map이라고 부릅니다.

patch들을 transformer layer에 넣는데, d 차원의 벡터로 임베딩햡니다. ([식 (1)] 참고)

임베딩 이후에 d 차원 벡터를 transformer를 이용하여 local self-attetnion acoustic feature를 추출합니다. 그 이후 LN, GELU 연산을 수행하여 첫 layer의 output을 얻습니다. (여기서 MSA는 multi-head attetnion을 의미합니다.)
[Fig 2]를 보면 인접한 4개의 patch들이 한 block으로 합쳐지는 것을 확인할 수 있는데 [식 (3)]을 통해 확인할 수 있습니다.I_2는 second-layer spectrum maps을 의미합니다.

위의 과정을 반복하여 마지막 spectum map을 얻습니다.
위의 과정을 전반적으로 요약하자면 2개의 블록으로 spectrum 정보를 추출하는 것이라 볼 수 있습니다.
<The RepVGG-Based Single-Branch Inference Module>

여기서는 멀티모달 감정 인식을 위해서 RepVGG에서 제안된 구조를 사용하는데 multi-branch feature learning과 single-branch inference 구조입니다. [Fig 3]을 통해서 그 구조를 시각적으로 파악할 수 있습니다. training, inference module은 visual modality에 적용이 되며, 3×3 convolution, 1×1 convolution, Identity, ReLU layer로 구성되어 있습니다.
[Fig 3]의 왼쪽을 보시면, spatial-visual feature가 주로 multi-branch와 multi-kernel convolution을 통해 학습 된다는 것을 알 수 있습니다. 입력으로 image frame이 들어오면, 3개의 브랜치를 통해서 multi-dimensional feature를 추출하는데, 3×3 convolution branch, 1×1 convolution branch, Identify branch로 추출합니다. 그런 다음에 middle feature는 ReLU의 입력으로 하여 융합하여 마지막 output을 얻습니다.
[Fig 3]의 오른쪽을 보시면, inference 절차를 보여줍니다. multi-branch 구조 대신 순수한 single-branch 구조를 선택하여 inference 합니다. 그리고 그림의 가운데는 training model에서 inference model로 parameter가 합쳐지는 과정을 자세히 보여주는데 3채널 input이 예시입니다.

구체적으로 말씀드리자면, training model에서 세 가지 branch 중에서 1×1 convolution kernel이 zero padding에 의해 3×3 convolution으로 변환되는 동안 3×3 convolution branch만 유지됩니다. 여기서 각 convolution은 BN 레이어를 포함합니다.
<The Fully Video-to-Emotion System>
논문에서 제안한 방법론이 아닌 다른 방법론은 비디오 감정 분석 과정에서 전처리 작업도 수행하지만 보통 비디오 처리 후에 modal 정보 파일을 저장하는 경우가 많습니다. 그러면 이런 과정에서 저장, 생성 및 호출로 인해 발생하는 메모리 및 효율성 낭비가 발생합니다. 논문에서는 이러한 불필요한 저장 공간 낭비를 줄임으로써 낭비 문제를 해결합니다. 논문에서는 시스템의 낭비를 줄이기 위해 사전 처리된 modal 정보를 V2EM 입력과 직접 상호작용하는 “fully video to emotion system”(FV2FES)를 설계하였습니다.

[Fig 4]는 데이터 업로드, feature extractor, 감정 예측을 포함한 전체 과정이 일관된 FV2ES의 데이터 흐름을 보여줍니다. FV2ES에서는 먼저 비디오와 비디오의 전체 대화 텍스트 그리고 오디오 Mel-spectrogram을 입력으로 받습니다. 그와 동시에 이미지 프레임은 전처리되어야 하는데요. 예를 들어서 IEMOCAP 데이터셋에서는 2인 대화 영상을 제공합니다. 이를 등장인물에 따라 1인 프레임으로 나눕니다. 긴 비디오는 computational overhead를 유발할 수 있기 때문에 이를 해결하기 위해서, 전체 비디오를 몇 개의 짧은 비디오 segment로 나눕니다. 동시에 타임라인을 사용하여 3가지 모달리티의 데이터를 align합니다. 같은 time을 가지는 text, spectrum, image frame을 선택하여 V2EM의 입력으로 들어갑니다. 그러면 V2EM을 통해 그 기간의 감정 예측을 얻을 수 있습니다. 마지막으로 여러 개의 짧은 비디오의 감정 예측값을 입력 비디오의 감정 예측 결과로 취합니다.
<Experiments And Analysis>
<matrix>
평가 matrix로 weighted accuracy와 f1 score를 사용하였습니다. W_{acc}는 [식 (4)]와 같습니다.

여기서 P는 전체 positive를, TP는 true positive, N은 전체 negative를, TN은 true negative를 의미합니다.
<result>

[Table 2]는 IEMOCAP 데이터셋에서의 성능 측정 결과 입니다. 논문에서 제안한 것이 성능이 높게 나왔다는 것을 확인할 수 있습니다.

[Table 3]는 CMU-MOSEI에서의 성능 측정 결과를 나타냅니다. 역시나 논문의 저자가 제안한 방법론이 제일 성능이 높고 speed 또한 빠른 것을 확인할 수 있습니다.
<ablation study>

ablation study를 IEMOCAP 데이터셋에서 실행한 것에 대한 성능 결과를 [Table 4]로 확인할 수 있습니다. Baseline에서 V와 A는 VGG16모델을 사용하였고, T로는 Albert모델을 사용하였습니다. V+A(Ours)+T에서 A는 hierarchical-attention spectrum computing module을 사용하였고, V(Ours)+A+T에서 V는 RepVGG를 베이스로한 single branch inference module을 사용하였습니다. V(Ouers)+A(Ours)+T는 위의 두가지를 사용한 것이구요.
결과를 보면 역시나 논문에서 제안한 방법론을 모두 사용한 것이 성능이 높은 것을 확인할 수 있습니다. max와 average를 둘다 리포팅 한 이유를 살펴보면 baseline의 max가 논문의 제안한 방법론의 max보다 높아서 그런 것 같습니다.

위의 table은 CMU-MOSEI에서의 ablation을 진행했을 때의 성능입니다. 전반적으로 살펴보면 V+A(Ours)+T가 V(Ours)+A+T보다 성능이 더 높게 나온 것을 확인할 수 있습니다. audio modality가 전반적인 멀티모달 감정인식에 더 기여를 많이 했음을 알 수 있습니다.
또 살펴보면 V(Ours)+A+T가 baseline보다 낮은 것을 알 수 있는데요. 이를 논문에서는 baseline에서 사용한 VGG16과 구조가 비슷하여 성능이 썩 좋게 나오지 않은 것은 아닌가 추측합니다. 그러면 VGG를 쓰지 않은 것에 대한 이유가 필요한데요. 논문에서는 RepVGG의 의도는 효율성 개선을 위해서였기 때문에 성능 부족은 용인할 수 있다고 합니다.
이번에도 감정인식 논문을 읽었는데요. 확실히 한 분야의 논문을 계속 읽으니 논문에서 제시하는 바가 무엇인지 더 잘 와닿는 것 같습니다. 이상 논문 리뷰 마치겠습니다.
안녕하세요 김주연 연구원님 리뷰 잘 읽었습니다.
리뷰 읽으면서 어떤 이유에서 non-end-to-end framework로 연구가 진행되고 있다고 생각하는지에 대한 의견이 궁금합니다. 리뷰에서도 딱히 어떻게 해서 end-to-end라는 설명이 전혀 없는데, 그 이유가 궁금합니다.
다음으로 텍스트 모달리티는 그래서 어떻게 구성되고 학습되는지에 대한 설명이 없는 것 같습니다. Audio->Video->??? 순서로 설명되는 것 같은데, 내용이 나오지 않습니다. 혹시 논문에 없는건지 누락된건지 확인 부탁드립니다.
다음으로 학습을 그래서 어떻게 진행했다는건가요? 2개의 모듈과 시스템에 대한 설명은 있는데 end-to-end라면 어떻게 학습을 진행했다는 설명이 있을 것 같은데, 이 부분에 대한 설명이 전혀 없습니다. 학습 과정에 대한 설명 부탁드립니다.
댓글 감사합니다.
1) 음 사실 non-end-to-end framework로 연구가 진행되고 있다는 말은 논문에서의 생각인데요. 저는 요즘의 연구들이 절대 non-end-to-end framework라고 생각하지 않습니다. 실제로 이 논문에서 non-end-to-end framework 연구들에 대해서 말한 논문의 연도를 보면 2011, 2017, 2016 인데요. 제 생각에는 컨트리부션을 더 가져가고 싶어 그런것은 아닌가 싶습니다.
2) 논문에서도 비중있게 다루지 않아 저도 제대로 언급하지 못한 것 같습니다. 죄송합니다. text 모델은 단순히 사전학습된 albert모델을 사용합니다.
3) 학습 과정에 대한 설명이 별로 없다는 것에 저도 동의하는 부분입니다. 이 논문이 감정인식 베이스라인 논문을 인용한 논문인데, 코드도 완전 동일하게 가져다 사용하고 거기에 audio, video부분만 고쳐 사용하였습니다. 베이스라인 논문과 동일한 학습 과정을 가진다고 생각하시면 편할 것 같습니다.
안녕하세요 김주연 연구원님 좋은 리뷰 감사합니다.
table 1,2의 V2EM 방법론이 결국 video에는 RepVGG, audio에는 hierarchical attention, text에는 albert를 적용한 방법론으로 이해하였습니다.
그러면 이때, table 4, 5에서 V와 A는 저자의 방법론을 적용하여 비교한 결과를 볼 수 있는데, T에 대해서는 모두 baseline과 동일하다고 보면 되는 건가요? 논문에서 video, audio는 설명이 있었는데 text는 alert를 이용한 feature extraction을 진행했다는 언급만 있어 논문 자체에서 새로운 방식을 제안한 것이 아닌 것으로 보면 되는 것인지 궁금합니다.
댓글 감사합니다. 네 맞습니다. t에 대해서는 논문에 저자도 그리 언급하지 않고 있고 albert로 feature를 추출했다 정도만 파악하고 계시면 될 듯 합니다.
안녕하세요 김주연 연구원님 리뷰 감사합니다.
우선 기존 연구와는 다르게 대규모의 Video만을 사용할 때 어떻게 하면 조금 더 가볍게 감정인식을 수행할 수 있을지에 대한 방법론으로 이해하였는데요.
그런데 이게 보면 Loss 와 같은 수식이 나와있지 않고, 각 모달리티의 피처를 추출하는 방법만 나와있어서,, 이 모달을 어떻게 합치고 학습되는 지에 대한 내용 파악이 어렵네요.. 특히 비디오와 오디오 피처 추출의 경우 모델이 어떻게 구성되어 있는지 까도 나와있는데, 그 이후의 아키텍처는 저자가 설명을 빠뜨린건 지 의문이 들어서.. 어떻게 학습이 진행되는지 추가로 설명이 필요할 것 같습니다.
그리고 두번째, 테이블 2에서 (테이블 3도 마찬가지) 2개를 제외한 나머지 방법론의 speed가 누락된 이유가 있나요? 기존 연구들은 너무 성능에만 집중하고 있다고 언급한 데에 비해 정작 스피드는 결국 하나랑만 비교하고 있는 상황이라, 실제 이 논문이 정말 다른 거에 응용에 초점을 둔 게 맞는지 의문이 드네요….
댓글 감사합니다.
1) 우선 이 논문은 감정인식 논문의 베이스라인을 인용한 논문인데요. 논문에서 이 모델들을 합치는 것을 크게 다루지 않아 코드를 살펴봤는데 단순히 concat하는 방식으로 합쳐집니다. 제가 설명이 부족했던거 같네요.
2) 흠 이 부분에 대해서는 깊게 생각하지 못했는데 홍주영 연구원님 덕분에 자세히 볼 수 있게 되었네요. 2개를 제외한 나머지 방법론의 speed가 누락된 이유는 나와있지는 않아 파악이 어렵습니다. 그런데 여기에 제 생각을 써보면, 가장 최신의 방법론이 fe2e여서 이것만 비교한것은 아닌가…싶기도 합니다..(물론 이것만으로는 설명이 부족하다고 생각합니다)