Abstract
논문의 저자들은 기존에 semantic segmenataion에 사용되던 per-pixel 예측을 object detection에 사용하는 fully convolutional one-stage object detector(FCOS)를 제안합니다. 이 당시 대부분의 SOTA detector는 anchor-based로, 사용자가 사전에 정의한 형태의 anchor box들로 bbox를 추론하는 방법론이었습니다. 반면에, 논문에서 제안하는 FCOS는 anchor free(proposal free) 방법론입니다. FCOS는 anchor box를 사용하지 않음으로써, 학습 시 anchor box와 gt의 overlapping계산과 같은 복잡한 계산을 피할 수 있습니다.
Introduction
Object deteciton은 이미지에서 대상의 위치에 해당하는 bounding box와 종류에 해당하는 label을 예측하는 task입니다. 이 논문이 나올 당시의 object detection 알고리즘은 Faster R-CNN, SSD, YOLOv2 등이 있었는데, 이들은 모두 anchor 기반으로 사전에 정의된 anchor box로 detection을 수행합니다. 그러나 anchor box 기반의 detector는 몇 가지 단점이 존재하는데, 저자는 다음과 같은 네 가지 문제를 지적하였습니다.
- detection model의 성능이 anchor box의 크기, 종횡비, 개수와 같은 hyperparameter에 민감함
- 고정된 모양의 박스를 사용하기 때문에 shape variation이 큰 small object는 찾기 어려움
- 높은 recall을 위해 많은 수의 anchor box를 사용하여 과도한 negative sample이 생성됨
- anchor box를 사용하면 anchor box와 GT의 IOU 계산과 같은 복잡한 연산을 수행해야 함
이러한 배경에서, 연구자들은 semantic segmentation, depth estimation, keypoint detection task에서 좋은 성능을 보였던 FCN 구조에 주목하였고, FCN의 per-pixel prediction을 object detection에 적용하게 되었습니다. 이때, 픽셀 별 classfication을 수행하는 semantic segmentation과 달리 object detection에서는 box를 나타내는 4D vector를 추가하였습니다.

[그림 1]의 왼쪽 이미지와 같이 FCOS는 물체의 한 점을 기준으로 박스의 경계까지의 거리인 l, t, r, b를 추정합니다. 이때 [그림 1]의 오른쪽 이미지와 같이 하나의 점이 여러 물체에 속해 있는 경우가 발생할 수 있습니다. 이러한 경우, 여러개의 경계값을 추정해야 하기 때문에 논문에서는 FPN구조를 사용하여 다양한 크기의 feature를 사용하고, 그 중 각 feature map이 커버하는 최소 영역을 기준으로 하여 물체를 검출하습니다. 또한 center-ness를 통해 물체의 중심에서 멀리 떨어진 박스를 제한하는 방법을 사용하였습니다.
Method
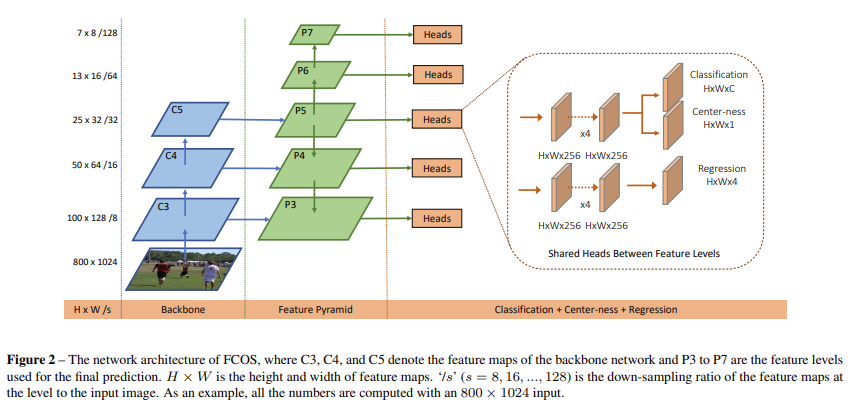
FCOS의 전체적인 구조는 [그림 2]와 같습니다. Backbone에서 3가지 크기의 feature를 추출하고 이 feature를 이용하여 5단계의 Feature Pyramid를 생성합니다. Feature Pyramid를 통해 각 Head를 얻고, 여기서 박스와 클래스를 예측합니다.
Fully Convolutional One-Stage Object Detector
Backbone의 conv 레이어 i에서 나온 feature map을 F_i, 각 이미지의 ground truth는 B_i라고 할 때, B_i는 B_i=(x_0^{(i)},y_0^{(i)},x_1^{(i)},y_1^{(i)},c^{(i)})\in \R^4 \times\{1,2,...\ C\}입니다. 즉, GT는 각각의 클래스에 대해 x_0^{(i)},y_0^{(i)},x_1^{(i)},y_1^{(i)} 라는 bounding box 정보를 가지고 있는데, 이때 (x_0,y_0), (x_1, y_1)은 각각 bbox의 좌상단, 우하단의 좌표값을 의미합니다.
저자들은 feature map 상의 한 점 (x, y)에서 박스를 추정하는 방법으로 다음과 같은 방식을 제안하였습니다. (x, y)가 GT box에 속하면 positive sample로 간주하고, (x, y)가 GT box에 속하지 않는다면 negative sample로 간주하고 배경 클래스인 0값을 부여합니다. 이때, (x, y)에서 bounding box의 크기를 예측하는 방법은 [수식 1]과 같습니다.
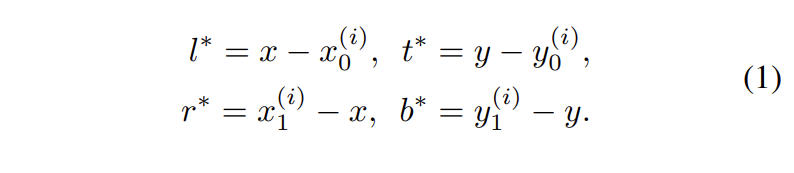
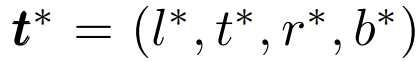
[식 1]을 이용하여 prediction과 target인 GT 간의 차이인 t^*를 구할 수 있습니다.
(x, y)가 여러 개의 bounding box에 속해 있는 경우, 이를 ambiguous sample이라 하고 이 경우에는 가장 작은 영역을 가진 박스를 선택합니다. 이때 multi-level prediction을 사용하여 성능에 큰 영향을 주지 않았다고 합니다.
FCOS는 가능한 많은 foreground sample을 regressor의 학습에 사용하고자 하였습니다. 저자들은 anchor-based 방법론에서 충분한 IOU를 가진 sample들만 positive sample로 취급하여 학습에 사용하는 것과 달리, FCOS는 배경을 제외한 모든 샘플을 학습에 사용하였기에 더 높은 성능을 낼 수 있었다고 주장합니다.
Network Outputs
FCOS의 마지막 layer는 클래스 수만큼의 차원을 가지는 벡터 p와 박스를 의미하는 4D 벡터 t^∗=(l^∗,t^∗,r^∗,b^∗)를 예측합니다. 또한 multi-classifier를 사용하는 대신, 클래스 수 만큼의 binary classifier를 사용하였고, exp(x)를 사용하여 regression target의 범위를 (0, \infty)으로 설정하였습니다.
하나의 위치에서 여러 개의 anchor box를 사용하는 방법들에 비해 FCOS는 한 위치에서 anchor 없이 regression을 진행하기 때문에 anchor box배 적은 output variable을 가집니다.
Loss Function
FCOS에서 사용되는 training loss는 [수식 2]와 같이 정의됩니다.
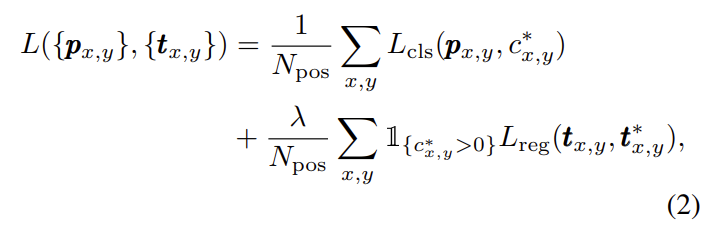
저자들은 classification을 위한 Loss로 Focal loss를 사용하였고 Regression을 위한 Loss로 IOU loss를 사용하였으며, 각 Loss는 positive 샘플의 개수로 나누어 normalization을 진행하였습니다. 또한, \lambda를 이용하여 regression loss의 가중치를 조절하였습니다.
Multi-level Prediction with FPN for FCOS
저자들은 위의 설명된 FCOS에는 다음과 같은 2가지의 문제점이 발생할 수 있으며, 이를 FPN구조로 해결할 수 있음을 주장합니다.
- cnn의 마지막 feature map의 large stride가 BPR(Best Possible Recall)을 낮춤
- 한 픽셀에서 GT box가 겹치는 경우, 모호함 발생
문제점 (1)은 FCOS의 마지막 feature map에서 큰 output stride를 가지게 되고, 작은 물체들은 해당 feature map에서 찾기 어려우므로 recall이 낮아진다는 것을 의미합니다. Anchor based detector는 recall이 낮아지면 IoU threshold를 낮춰 recall을 증가시킬 수 있는 반면, FCOS는 IoU를 계산하지 않기 때문에 이러한 방법을 사용할 수 없습니다.
이에 저자들은 FPN들 사용하여 서로 다른 output stride를 가지는 feature map을 생성하고, 작은 output stride를 가지는 feature map에서 작은 물체를 찾고, 큰 output stride를 가지는 feature map 에서 큰 물체를 찾게 하여 이러한 문제는 해결하였습니다. FPN을 FCOS 모델에 적용하였을 때, Anchor based 모델인 RetinaNet 보다 더 좋은 BPR 성능을 얻을 수 있음을 실험적으로 확인하였습니다.
문제점 (2)는 [그림 1]의 오른쪽과 같이 한 점이 겹쳐진 두 bounding box에 속하게 될 때, 어떤 bounding box와 class를 대상으로 학습을 해야하는 지에 대한 모호성을 의미합니다.
저자들은 서로 다른 두 박스 를 각각 서로 다른 scale의 feature map에서 찾음으로써 이러한 문제를 해결하였습니다.
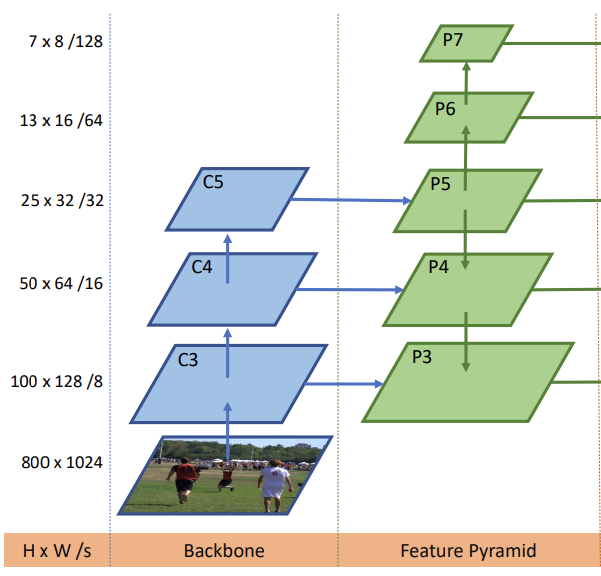
[그림 3]에서 P_3 ~ P_7은 서로 다른 크기의 feature입니다. P_3, P_4, P_5 는 각각 C_3, C_4, C_5에 1 x 1 convolution을 적용하여 얻고 P_6, P_7은 P_5에 stride 2를 차례대로 적용하여 만들었습니다. 결과적으로는 그림에서 볼 수 있듯이 P_3=8, P_4=16, P_5=32, P_6=64, P_7=128의 s를 가집니다.
FCOS는 기존 anchor based detector와 달리, 각 level의 feature에서 bounding box의 regression 범위를 제한하였습니다. 각 bounding box 까지의 거리를 l^∗,t^∗,r^∗,b^∗라고 하면 i 번째 feature 에서 (l^*, t^*, t^*, b^*)>m_i, (l^*, t^*, t^*, b^*)<m_{i-1}범위의 sample들은 negative로 취급하였습니다. 이 논문에서는 m_2~m_7의 값을 0, 64, 128, 256, 512, inf로 사용하였습니다. 만일 multi-level prediction을 사용함에도 한 위치에서 여러 개의 박스가 할당된다면, 가장 작은 면적의 GT를 선택하였습니다.
Center-ness for FCOS
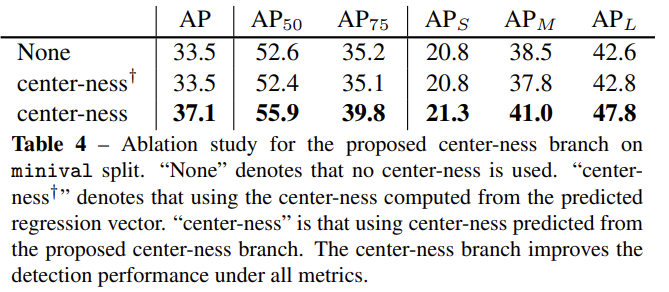
FCOS에 multi-level prediction을 사용해도, FCOS와 anchor 기반의 디텍터와의 성능 차이가 있었다고 합니다. 저자들은 그 이유를 FCOS는 상대적으로 low-quality의 bounding box를 예측하기 때문이라고 분석하였습니다. 이러한 box들은 실제 물체의 중앙점에서 멀리 떨어진 경향이 있어 저자들은 center-ness를 도입하여 중심에 가까운 박스에 더 큰 값을 부여하는 방법을 사용하였습니다.

center-ness는 물체의 중심점과의 거리를 0과 1사이로 정규화하여 어떤 박스가 중심점과 가깝다면 1에 가까운 값을 배정하고, 중심정과 멀다면 0에 가까운 값을 갖도록 만듭니다.
center-ness는 [식 3]과 같이 나타낼 수 있습니다. center-ness를 classification score 출력에 곱해주게 되면 마지막 layer의 NMS과정에서 중심에서 먼 박스는 걸러지게 됩니다.
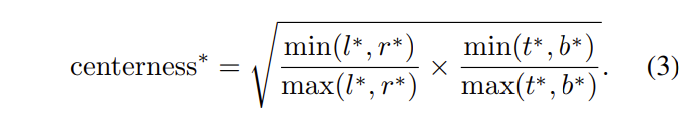
Experiments
실험은 COCO데이터셋에서 진행되었고, 모델의 backbone으로는 ResNet-50을 사용하였습니다.
Multi-level Prediction with FPN

[표 1]은 multi-level prediction을 통해 FCN-based detector의 낮은 recall 문제를 해결하는 실험 결과를 나타냅니다.
RetinaNet은 anchor-based 방법론으로 GT와 anchor box와의 IoU에 따라 positive sample을 결정하게 됩니다. 이때, IoU threshold를 낮추면 low-quality matches를 포함하게 되어 Recall이 높아지는 결과를 확인할 수 있습니다.
반면에 FCOS는 Recall을 조절하는 방법으로 FPN을 사용하여 Recall값을 조절한 결과를 보였습니다.

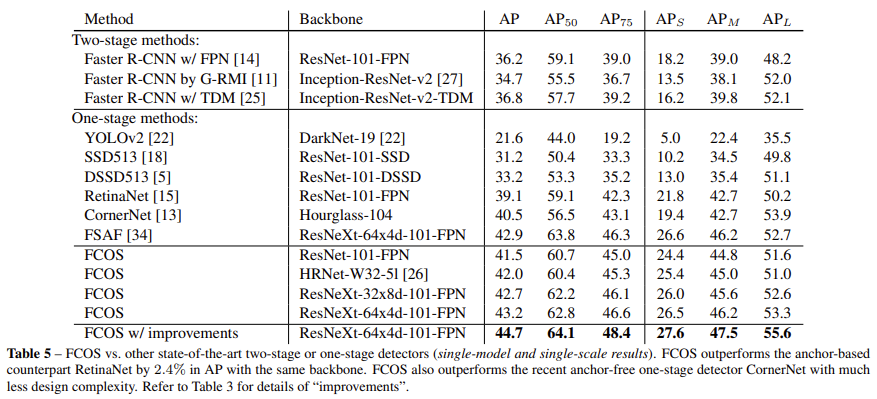
Comparison with State-of-the-art Detectors
안녕하세요. 리뷰 감사합니다
1) x_0^i에서 i는 클래스를 의미하는 걸까요?
2) 실험 table2에 대해서 설명이 전혀 없는데 Amb. Samples와 (diff)는 뭐가 다른걸까요?
감사합니다
GT 부분의 x_i를 말씀하시는 거라면 i는 layer를 의미합니다.
table 2는 FPN의 사용 우뮤에 따른 ambiguous sample의 비율입니다.
리뷰 잘 읽었습니다.
리뷰를 읽다보니 각 이미지의 ground truth가 B_i라고 하셨는데, i가 conv 레이어를 의미하므로 하나의 GT를 각 레이어의 해상도에 맞추어 GT를 정해주는 것인지 궁금합니다.
또한, ambiguous sample일 경우, 가장 작은 영역의 박스를 선택하는 이유가 무엇인지 알 수 있을까요??
마지막으로, RetinaNet에서 가장 좋은 성능을 보이는데, 그렇다면 이 논문은 어떤 점에서 자신들의 방법론이 좋은 성능을 보였고 의미는 연구라고 이야기하나요??
1. layer의 output, 즉 head에 따라 GT가 다르게 정해지는 것으로 보아 각 레이어의 downsampling rate(stride)에 따라 GT를 결정한다고 이해하였습니다.
2. ambiguous sample은 하나의 픽셀이 두 가지 이상의 GT를 가지고 있어 어떤 GT와 매칭해야 하는지 모호한 상황에 놓인 샘플을 의미합니다. 이때 박스의 크기에 따라 서로 다른 feature map에서 해당 질문의 답변은 홍주영 연구원님께 드린 답변을 함께 참고해 주시면 감사하겠습니다.
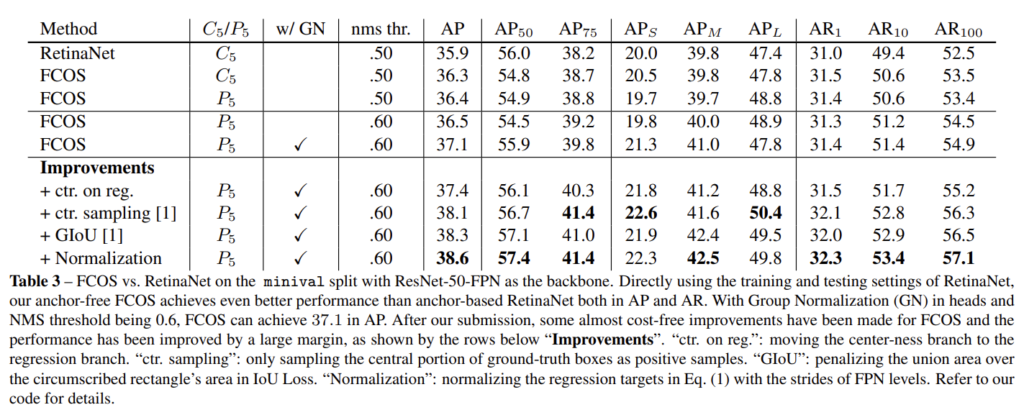
3. RetinaNet에서 가장 좋은 성능을 보인다고 하셨는데 Table 1은 precision이 아닌 단순 recall을 리포팅하여 IoU, FPN에 따른 Recall 변화를 의미합니다. Table 5를 보시면 저자들이 제안한 FCOS 방법론이 가장 좋은 성능을 보이는 것을 확인할 수 있습니다.
안녕하세요 천혜원 연구원님 리뷰 감사합니다.
우선 질문에 앞서 리뷰 작성과 관련된 언급을 먼저 드려야 할 것 같습니다.
1. 글 내부에서 수식을 사용하고자 할 때, [latex] x_1, x_2 [/latex] 이 태그를 사용할 경우, Notion에서와 같이 인라인 수식을 표기할 수 있습니다. 이 점을 참고하여 글을 작성하시면 더욱 가독성 좋은 리뷰가 될 것 같습니다.
2. 현재 천혜원 연구원님이 작성한 리뷰 중 Experiment 이후에는 테이블 외에는 그 어떤 언급도 없습니다. 그렇다는 건, 독자로 하여금 테이블만으로 해당 방법론이 얼마나 가치있는 지를 충분히 설득해야만 할텐데.. 평가 지표에 대해서도 잘 모르는 상황이라… 게다가 Ablation study 역시 자신의 방법론에 있어 어떤 부분이 효과적임을 보여주고 싶은지 이해가 안되는 상황입니다. 해당 실험을 통해 저자가 보이고자 하는 내용을 반드시 작성 부탁드립니다.
방법론에 대한 설명 물론 중요합니다만, 그 방법론이 효과적임을 증명하기 위해서는 논문에 있어서 실험 파트는 없어서는 안될 부분입니다. 이 점 반드시 이해하시고 다음 리뷰에서는 조금 더 나은 글이 되길 바라겠습니다.
이제 리뷰 내용에 대해 질문을 드리려고 하는데요.
그림 1의 오른쪽 그림과 같이 Bbox가 겹치는 상황에 대한 질문입니다. 여러 개의 bbox가 있을 경우, Fully Convolutional One-Stage Object Detector
해당 섹션에서 “가장 작은 영역을 가진 박스를 선택하며, multi-level prediction을 사용하여 성능에 큰 영향을 주지 않았다고 합니다” 라고 하셨는데요. 그렇다는 건 학습 중에는 가장 작은 박스만 선택되는 걸까요? 큰 박스가 선택되기 위해서는 어떤 기법이 적용되는지는 논문에 적혀있을까요? 그리고 Multi-level prediction이 무엇인가요? 아마 여러 conv에서 나온 feature를 사용했다는 것 같습니다만 명확히 서술되어 있지 않아 추가 설명이 필요할 것 같습니다. 그리고 이어지는 multi-level prediction이 성능에 영향을 주지 않는다는 것이 무엇을 의미하는 지도 혹시 추가 설명을 부탁드려도 될까요? 가장 작은 영역을 가진 박스 선택과 multi-level prediction이 어떤 관계이며 성능에 영향을 준다는 의미가 와닿지 않아서 이렇게 길게 질문을 드립니다.
안녕하세요 홍주영 연구원님 좋은 피드백 감사합니다. 앞으로의 리뷰에 반영하도록 노력하겠습니다.
질문해주신 내용 중 multi-level prediction 학습에 가장 작은 박스만 선택되는 것이 맞습니다. 학습 시 multi-level prediction, 즉, 여러 scale의 feature map을 사용하기 때문에 하나의 map에서 찾은 box중 가장 작은 것을 선택합니다. 큰 박스는 더 deep한 feature map에서 찾을 수 있겠죠. [그림 1]의 오른쪽에 위치한 그림과 같이 서로 다른 크기의 물체가 존재할 때, 이를 [그림 2]의 feature pyramid에서 찾는다고 가정한다면, [그림 1]의 두 물체는 각각 서로 다른 feature에서 detect될 것입니다.
원문을 그대로 작성하자면 “we will show that with multi-level prediction, the number of ambiguous samples can be reduced significantly and thus they hardly affect the detection performance.”로, multi-level prediction을 사용하여 ambiguous sample의 수가 줄어들고, 이로 인해 detection의 성능 저하가 발생하지 않기에 performance가 떨어지지 않는다는 관점에서 이해하였습니다.
안녕하세요. 리뷰 감사합니다.
저 또한 FCOS와 같은 방식의, Anchor based 방법이 아닌 모델들에 대해 찾아보고 있는데, 현재 리뷰에 따르면 NMS 등의 보정 작업 등은 소개되고 있지 않은데? 해당 모델에서 사용된 Prior knowledge method 들에는 어떤 것들이 있나요?
anchor 기반 방법론들과 동일한 방식으로 NMS를 수행하게 됩니다. 차이점이 있다면 Confidence Score를 구하는 경우 Classification Head로부터 생성된 값에 Center-ness 값을 곱하여 사용한다는 것입니다. table 3에 nms threshold에 따른 성능을 비교하고 있으니 참고하셔도 좋을 것 같습니다.
리뷰 감사합니다. 전에 서베이할 때 FCOS3D라는 모델이 있었는데 FCOS에 대해 알 수 있게되었네요.
experiments에서 Table 1에서는 RetinaNet이 FCOS에 비해 더 좋은 성능을 보이는데 저자는 어떤 contribution을 위해 해당 모델과 비교한 것인가요?
그리고 앞에 introduction에서 기존 anchor based 모델인 Faster RCNN, SSD, YOLO v2등을 언급했는데 이러한 모델들과의 fps비교한 결과는 혹시 포함되어있지 않나요?
– table 1은 앵커 기반 RetinaNet에서 IoU에 따른 recall 변화와, 앵커 프리 방법론인 FCOS의 small recall 문제를 FPN을 사용하여 해결한 것을 보이기 위한 실험 결과입니다. 앵커 박스를 사용하지 않아 recall값을 조절할 방법이 없었는데 FPN 구조로 다양한 크기의 feature map에서 박스를 추론함으로써 Recall이 증가했다는 것을 보이고 있습니다.
– Table 5에서 여러 anchor based모델과의 AP를 비교한 결과는 보여주고 있으나 논문에서 별도로 fps를 비교한 결과는 없었습니다.
안녕하세요 좋은 리뷰 감사합니다 !
충분한 IOU를 가진 sample들만 positive sample로 취급하여 학습에 사용하는 기존의 anchor-based 방법론에 비해 FCOS가 background를 제외한 sample을 모두 학습에 사용하기 때문에 더 높은 성능을 낼 수 있는 것이라고 하셨는데 이를 읽고 단순히 생각해보았을 때 gt box와 충분한 IOU를 가지는 sample들로 학습을 하는 것이 좀 더 높은 성능을 낼 수 있지 않을까라는 의문이 듭니다. 이 점에 대해서 어떻게 생각하시는 지 궁금합니다.
또 한 가지는 multi-level prediction을 사용함에도 한 위치에서 여러 개의 박스가 할당된다면, 가장 작은 면적의 GT를 선택하는 것인데 이를 centerness와 같이 생각을 해보았을 때 가장 작은 면적의 GT가 중심점이 멀리 떨어진 경향을 보인다면 어떻게 처리하는지에 대한 궁금증이 생겨 질문드립니다. 감사합니다.
1. ‘FCOS는 배경을 제외한 모든 샘플을 학습에 사용하였기에 더 높은 성능을 낼 수 있었다고 주장합니다.’라는 문장을 보고 질문을 주신 것 같습니다… 우선 해당 부분에 모호한 표현을 작성한 점 죄송합니다… 본문에서는 anchor 기반의 방법론보다 많은 양의 foreground sample을 확보할 수 있다는 의미에서 작성하였습니다. 질문해 주신 부분에 관해서는 ‘anchor based’방법론은 gt와 충분한 IOU를 가지는 hard positive한 sample을 사용하지만 fcos는 학습되는 sample의 개수가 증가하여 보다 다양한 상황의 sample을 가지고 학습하였기에 더 높은 성능을 달성할 수 있지 않았을까…라고 생각합니다.
2. centerness는 중심점의 위치에 따라 confidence score에 추가적으로 부여되는 가중치라고 생각할 수 있습니다. 따라서 regression+classification을 통해 box를 예측하고 만일 이 box가 centerness값이 매우 낮아 centerness * class score값이 threshold 이하인 경우 해당 box는 nms수행 시 negative로 분류될 것입니다.