제가 이번에 리뷰할 논문은 저번에 리뷰한 task로, 위성 사진을 이용하여 현재 위치를 알아내는 Cross-view Geo-localization 분야의 논문입니다.
Abstarct
CNN 기반의 cross-view geo-localization은 polar transform에 의존하고, 전체 영역의 관계를 모델링하기 어렵다는 문제가 있습니다. 이에 저자들은 transformer 기반의 방법론(TranGeo)을 제안하여 전역 정보를 모델링할 수 있다는 점과 위치 정보를 명시적으로 인코딩할 수 있다는 transformer의 장점을 이용한였다고 합니다. 또한, 입력이 유동적일 수 있다는 transformer의 장점을 활용하고, 비균일한 crop방식(attend and zoom-in)을 제안하여 성능 저하를 최소화 하여 연산량을 줄이고, 의미 있는 정보가 많은 패치의 해상도를 키워 성능을 향상시켰다고 합니다.
Introduction
우선 이미지 기반의 Geo-localization은 위치를 알아내고 싶은 이미지를 쿼리 이미지로하고, GPS정보가 태그된 이미지를 reference 데이터베이스로 하여 쿼리 이미지의 위치를 알아내는 태스크입니다. 기존 연구들은 대부분 2-stream의 CNN 방식으로 이루어지며, metric learning loss를 이용하였다고 합니다. 그러나 Cross-view Geo-localization은 CNN 모델이 위치 정보를 명시적으로 인코딩하지 않기 때문에 위성 영상과 거리뷰 영상의 도메인 차이로 인해 어려움을 겪었다고 합니다. 이에, polar transform이라는 방식을 이용하여 위성 영상을 거리뷰 영상처럼 변형해주는 과정을 많이 사용하였으나, 이는 사전 지식에 의존하고 쿼리 이미지가 항공 영상의 중심에 있지 않을 경우 잘 작동하지 않는다는 문제가 있다고 합니다. 최근에는 transformer의 전역 모델링 능력과 self-attention 매커니즘으로 비전 분야에서 많이 사용되었고, transformer가 가지는 장점: 1) 위치 정보를 명시적으로 인코딩 할 수 있고 2) multi-head attention으로 인해 모든 패치간의 전역 상관관계를 모델링 할 수 있고 3) 각 패치에 위치가 임베딩되므로 패치의 입력을 변경하지 않고 임의의 패치를 제거(이 논문은 의미 없는 정보는 줄여 연산량을 줄이는 방식을 제안함.)할 수 있다는 장점이 있어 transformer를 이용하였다고 합니다.
그러나 기본적인 ViT는 학습 데이터의 크기(많은 학습데이터가 요구되는 것)와 메모리 연산량에 의한 제한이 있어 cross-view geo-localization을 위한 transformer(TransGeo)를 제안하였다고 합니다. 또한, 연산량을 유지하며 의미있는 정보의 해상도는 높이기 위해 attend and zoom-in이라는 방식도 제안하였습니다.
이 논문의 contribution을 정리하면
- pure transformer-based 방식을 제안 ⇒ polar transform이나 데이터 augmentation에 의존하지 않아도 됨.
- attention을 이용한 불균일한 crop 방식으로 무의미한 패치를 제거하고 유의미한 패치에 더 높은 해상도로 재할당하여 성능 향상
- urban과 rural dataset에서 SOTA 달성, CNN 방식과 비교했을 때 연산량과 GPU 메모리, 추론 속도 더 좋아짐
Method
1. Problem Formulation and Objective
문제를 식으로 정의하면 다음과 같습니다.
- 쿼리 이미지(거리뷰 이미지) : \{ I_s \}
- reference 이미지(항공 이미지) : \{ I_a \}
- 학습 목표: 각 쿼리 I_s 가 해당 GT 항공 이미지 I_a 에 가까운 임베딩 공간을 학습하는 것
- soft-margin triple loss: \mathcal{L}<em>{triplet} = log(1+e^{\alpha (d</em>{pos} - d_{neg})}) — 식(1)
이때, d_{pos},d_{neg}는 L2 distance, \alpha는 학습 속도 조절을 위한 하이퍼파라미터
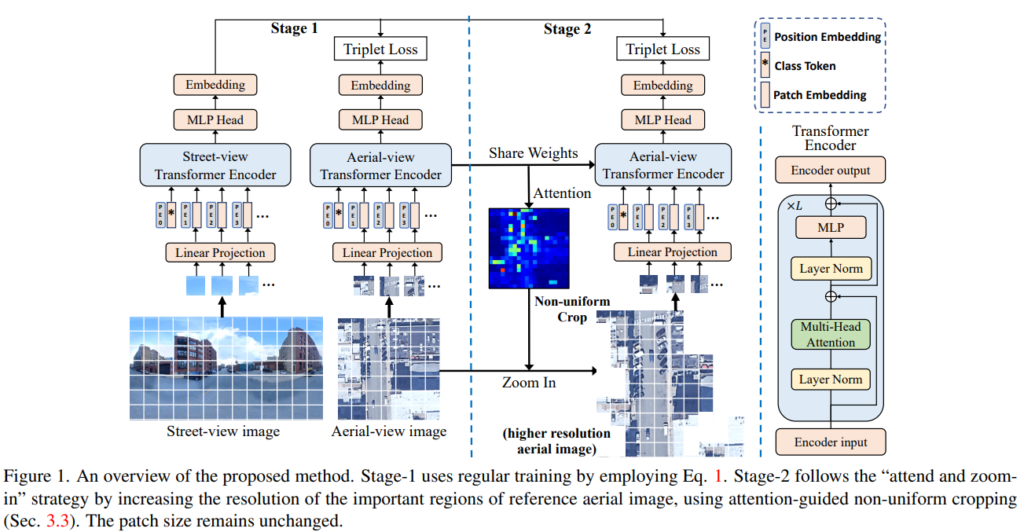
Overview
그림1을 통해 전체적인 파이프라인을 확인할 수 있습니다. Stage1은 2개의 Transformer encoder( T_s, T_a )를 개별적으로 학습시켜 거리와 항공 이미지의 임베딩 feature를 각각 만들어낸 후 soft-margin triplet loss(위에 정의함)를 이용하여 두 임베딩 feature가 positive는 가까워지고, negative는 멀어지도록 학습하는 과정이고, Stage2는 attention map을 활용하여 불균일한 crop을 통해 의미없는 패치를 지우고 의미있는 패치를 고해상도로 재할당하는 과정입니다.
2. Vision Transformer for Geo-localization
vision transformer는 pathc embedding, position embedding, multi-head attention으로 구성이 됩니다.
Patch Embedding
patch embedding은 이미지를 transformer encoder에 입력으로 넣어 줄 token으로 변경해주는 과정입니다. 그림1과같이 이미지를 N개의 PxP 패치, I_p ∈ \mathbb{R}^{N ⨉ (P⨉P⨉C)}(여기서 저자들은 P=16으로 이용하였다고 합니다)로 나누고, 이후 flatten하고 I_p ∈ \mathbb{R}^{N ⨉ P^2C}, linear projection을 통해 N개의 토큰 I_t ∈ \mathbb{R}^{N ⨉ D}를 생성합니다.
Class Token
학습 가능한 class토큰을 추가하여 마지막 layer의 출력 class token을 MLP head에 제공하여 최종 classification 벡터를 생성하고 이를 임베딩 feature로 사용하여 식(1)을 이용하여 학습을 진행합니다.
Learnable Position Embedding
각 토큰에 위치 정보를 임베딩하기 위해 position embedding을 추가합니다. 이때, 학습 가능한 행렬 \mathbb{R}^{(N+1)⨉D}을 이용합니다. 이때 (N+1)인것은, class token을 포함하였기 때문이라고 합니다. positional encoding을 통해 사전 지식 없이 기하학정 관계를 학습할 수 있다고 합니다. 또한 이 과정이 저자들이 제안하는 비균일 crop 방식(뒤에서 설명..)에 영감을 주었다고 합니다.
Multi-head Attention
3개의 학습 가능한 linear projection을 사용하여 입력을 query, key, value로 변환하고, D 차원의 Q, K, V로 표시한 다음 softmax(QK^T / D)V로 계산합니다.(transformer 방식을 생각하시면 됩니다.)
3. Attention-guided Non-uniform Cropping
사람은 이미지를 매칭할 때 일반적으로 가장 중요한 영역을 본 다음 중요한 영역에 집중하고 더 자세히 들여다보아 자세한 정보를 찾는다고 합니다. 따라서 저자들도 중요한 부분의 해상도는 높여서 의미있는 정보를 잘 찾을 수 있도록 하는 동시에 연산량이 너무 커지지 않도록 하기 위해 중요하지 않은 영역은 잘라내는 비균일 corpping 방식을 제안합니다.

항공뷰 transformer encoder의 마지막에 추출된 attention map을 이용합니다. class token에 해당하는 출력이 MLP head와 연결되므로, class token과 다른 모든 패치 token간의 상간관계를 attention map으로 선택하고 전체의 \Beta 비율(예를 들어 64%)을 유지하도록 하고 잘라냅니다. 이후이미지 해상도를 \root{\Gamma}배 증가시켜 \Gamma배 의패치를 확보합니다. 즉 최종적으로 \Beta\Gamma N 패치가 되므로 \Beta\Gamma =1이 되면 중요한 부분의 해상도만 높이고 연산량은 동일하게 할 수 있으며, \Gamma =1 이 되면 연산량을 줄여 계산 효율을 높일 수 있어집니다.
4. Model Optimization
augmentation 없이 모델을 학습하기 위해 정규화&일반화 기법인 ASAM을 이용하였다고 합니다. 식(1)에서 loss를 최적화하는 동시에 ASAM를 이용하여 모델이 부드럽게 수렴하도록 하였다고 합니다. loss의 sharpness는 아래의 식으로 정의가 됩니다.
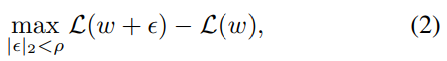
\epsilon 는 가중치 w에 대한 변동성이라고 합니다.
Experiment
Dataset and Evaluation metrics
널리 사용되는 밴치마크 CVUSA와 VIGOR를 이용하여 실험을 진행하였습니다.
- CVUSA dataset
- 35,532쌍의 학습 데이터와 8,884쌍의 테스트 데이터
- VIGOR dataset
- 4개 도시의 238,696개의 파노라마 이미지와 90,618개의 항공 이미지로 구성
- 각 항공 이미지에 대해 2개의 positive 파노라마만 선택하여 105,214개의 파노라마 생성
CVUSA는 쿼리 이미지가 항공 이미지의 중간에 오도록 정렬이 된 데이터셋이고, VIGOR는 정렬이 되지 않은 데이터셋이라고 합니다.
- Evaluation
top-k 이미지에 대한 recall accuracy를 측정합니다.
Comparison with State-of-the-art
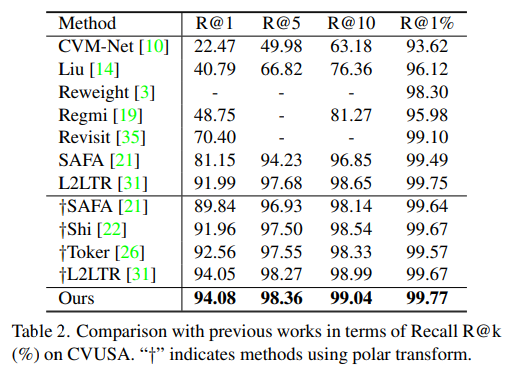
정렬이 된 데이터셋(CVUSA)에서 가장 좋은 성능을 보였습니다. †는 polar transformer를 적용한 것들로, polar transformer를 적용하지 않아도 저자들이 제안한 방식을 이용한다면 좋은 성능을 얻을 수 있다는 것을 확인할 수 있습니다.
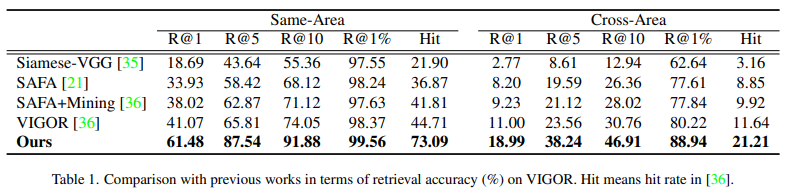
정렬이 되지 않은 VIGOR 데이터셋에서의 실험 결과로, 저자들이 제안한 방법이 가장 좋은 성능을 나타내는것을 확인할 수 있습니다. 특히, 정렬이 된 데이터셋은 성능 차이가 크지 않았으나, 여기서는 다른 방법론들과 성능 차이가 크게 나는 것을 확인할 수 있습니다.
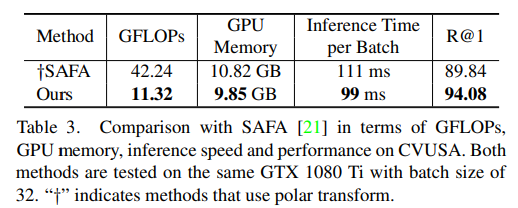
SOTA 방법론이 SAFA와 계산량을 비교한 결과입니다. 연산량과 메모리는 줄어들었으나 성능은 좋아진 것을 확인할 수 있습니다.
Ablation Study
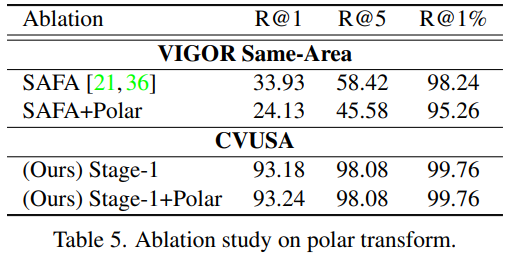
polar transformer의 사용 여부로 실험을 진행하였고, polar transformer를 사용할 경우 모두 성능이 좋아지는 것을 확인하였습니다. 그러나, 저자들이 제안한 방식은 사용하지 않아도 충분히 좋은 성능을 보였다고 합니다.
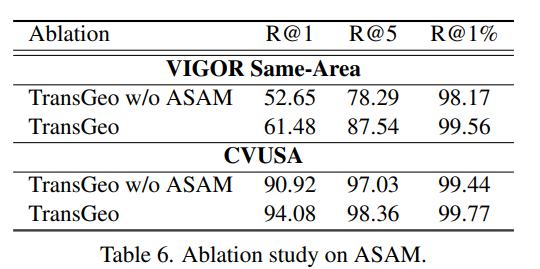
아래의 실험 결과는 각각 논문에서 제안한 각 과정에 대한 ablation study와 ASAM 사용 여부를 실험한 결과입니다.

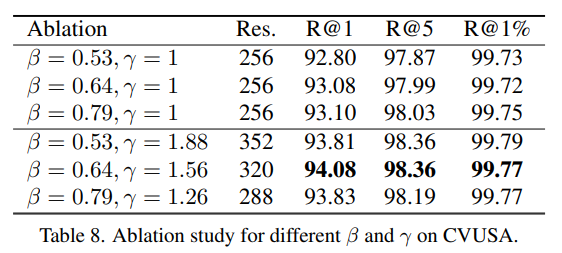
또한, \Beta, \Gamma를 다양하게 실험한 결과도 리포팅하였습니다.
Visualization
마지막으로 시각화 결과에 대한 내용입니다.
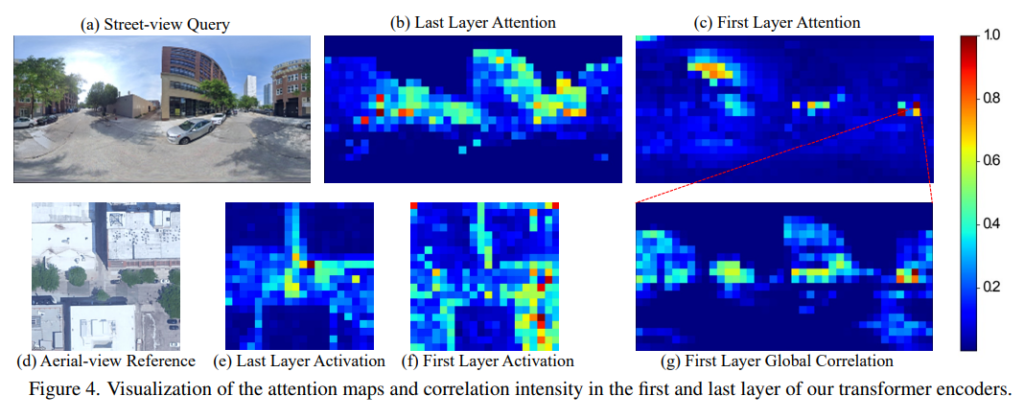
VIGOR에서의 attention map을 시각화한 결과입니다. 일반적으로 마지막 레이어에서의 attention이 이미지의 유의미한 영역과 잘 맞는 결과를 나타냅니다. 따라서 마지막 레이어의 attention map을 활용하는 것이 적절하다는 주장을 증명합니다. 또한, (g)는 (c)에서 가장 attention이 높은 패치를 선택하여 해당 패치와 첫번째 레이어의 다른 모든 패치들간의 상관과계를 시각화한 것으로, global하게 attention이 된 것을 통해 transformer 모델을 이용할 경우 global 상관관계를 학습할 수 있다는 것을 보여줍니다.
리뷰 잘 보았습니다.
한가지 궁금한 점이 있는데, 해당 논문의 2stage 경우에 aerial-view transformer encoder를 그럼 단순히 2번 태운거로 보면 될까요? 즉 전체 aerial 영상에 대해서 한번 통과해서 attention map을 추출하고 이를 통해 중요한 영역만을 살린 후 다시 동일한 aerial-view transformer encoder를 태운 것으로요.
그럼 2stage 과정에서 aerial-view transformer encoder가 계속 학습이 되는 것이라면 학습 방향성이 조금 모호해지지 않나요? 동일한 모델에 대해서 한번은 full image에 대한 attention map을 생성하는 역할을 계속 수행하고, 이와 동시에 masking된 영역에 대해서 또 토큰을 만드는 방향으로 이중적인 역할을 하는 것 같은데, 따로 마스킹 모듈을 두지 않고 shared weight과 구조를 활용한 이유에 대해 무엇인지 논문에 나와있을까요? 아니면 승현님의 생각이 궁금하네요.
코드를 확인해보니 stage1에서 한번 loss를 구하고 재할당 한 후 다시한번 가중치를 업데이트하는 것이 맞는 것 같습니다.
논문에는 ‘In practice, the attention maps only need to be computed once and can be saved during the stage-1 training, thus do not introduce additional computation cost. Since the streetview branch is unchanged, the inference speed for streetview query is the same as the stage-1 model, which is faster than typical CNN-based methods’라는 내용이 있습니다.
또한, 저는 1stage와 2stage에서의 arial-view에 대한 transformer encoder는 목적이 동일한 이미지에 대해 embedding feature를 추출하는 것으로 동일하기 때문에 shared weight 구조를 이용한 것으로 보입니다. (어떻게 보면 SSD300과 SSD500 차이라고 생각합니다)
다만 정민님이 이야기하신 것과 같이, 영향을 줄 수 있으므로, 이를 실험적으로 확인했으면 더욱 근거가 있는 주장이 될 수 있었을 것 같아서 아쉬운 점인 것 같습니다.
리뷰 잘읽었습니다.
굉장히 흥미로운 방법론 이네요.
해당 논문의 흥미로운 점이 다른 시각인데도 불구하고, VIT만 적용해도 높은 성능을 보인점이 흥미롭고
VIT 특성을 이용하여 attention map을 활용하여 고화질화 시킨 영상을 비균일 cropping 통해 다시 피쳐 추출한 점이 신반한 것 같습니다.
논문을 읽으면서 궁금한 점이 비균일 cropping 후, wight를 share하지 않고 별개의 모델을 적용한 실험 결과는 없었나요?
그리고 ASAM을 적용 여부에 따른 성능 개선이 크던데, 나중에 리뷰해주실거죠? ㅋㅋㅋㅋ
Cross-view Geo-Localization 태스크 자체가 다른 시각에 대한 retireval 방법론이라 저도 굉장히 신기하다고 생각하며 읽었습니다. 아쉽게도 비균일 cropping 후, wight를 share하지 않고 별개의 모델을 적용한 실험 결과는 논문과 supplemental을 확인해보았으나 발견하지 못하였습니다.. 아마 해상도를 높이기는 하지만 모델 자체는 동일한 목적을 가지고 있기 때문에 가중치를 share한 것으로 생각됩니다. 그리고 ASAM은 리뷰 작성 노력해보도록 하겠습니다…ㅎㅎ